目录
- 经验风险最小化的契约
- 捷径学习:当相关性比因果更容易
- 因果图视角:稳定特征与虚假特征
- 分布偏移:推理能力的试金石
- 为什么ERM的归纳偏置不够
- 缓解策略:从数据增强到对抗训练
- 伪代码:捷径检测与OOD泛化测试
- 一个小小的停顿
- 悬而未决
- 停顿
论文的核心论点是:大型语言模型,无论训练在多少文本上,本质上都是在做统计模式匹配------它们学会了哪些词序列在训练语料里经常一起出现,然后在生成时复现这些模式。就像一只鹦鹉,听到了足够多的对话之后,能够在合适的时机说出"你好"或"再见",但它不理解这些词的意义
这个比喻很刺耳,因为它触及了一个更深的问题:统计相关性和因果理解之间,有一道鸿沟。
让我给你看一个更具体的例子。
2023年,Hodel和West做了一个简单的测试。他们拿GPT-3做字母串类比推理------这是Webb等人在2023年声称GPT-3已经"涌现"出类比推理能力的任务。
原始任务是这样的:
python
输入: abc → abd, kji → ?
期望输出: kjj这是一个简单的"最后一个字母后移一位"的规律。GPT-3在这个任务上表现很好。
然后Hodel和West做了最简单的变体:把字母串的长度从3改成4,或者把字母表的顺序稍微打乱。
GPT-3的表现立刻崩溃了。
不是"稍微下降",是崩溃------准确率从接近100%掉到接近随机猜测。而人类在这些变体上的表现几乎没有变化,因为人类理解的是规律本身,而不是特定长度、特定字母表上的表面模式。
这就是本章要讲的核心问题:当模型通过最小化训练误差来学习时,它学到的是什么?
经验风险最小化的契约


最小化训练误差 ≠ 真的理解了规律。模型可能只是"记住了答案"(过拟合),或者学到了表面模式而非底层机制

但这里有一个被忽视的前提:ERM优化的目标,和我们真正关心的目标,是同一件事吗?让我把这个问题拆开。

这两者不是一回事。统计学习理论的经典结果 ------比如Vapnik和Chervonenkis在1970年代建立的框架------关心的是泛化界(generalization bound) :

这个不等式告诉我们:如果假设空间不太复杂,训练误差低的模型,测试误差也会低 。但注意这里的假设:测试数据和训练数据来自同一个分布 D。这个假设在现实中几乎从不成立。
训练数据是你能收集到的数据------可能来自特定的医院、特定的时间段、特定的人群。测试数据是模型部署后遇到的数据------可能来自不同的医院、不同的季节、不同的人群。分布偏移(Distribution Shift)是常态,不是例外。而当分布偏移发生时,ERM学到的那些"在训练数据上有效的相关性",可能完全失效。
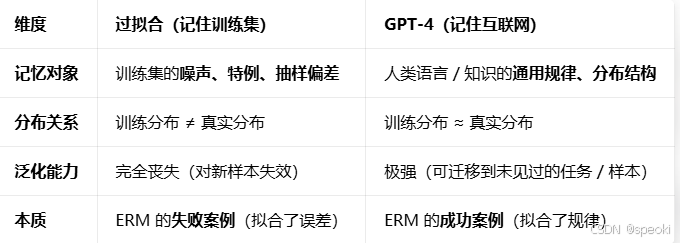
模型记住了训练集------我们叫它过拟合,这是错误,我们会惩罚它。
但如果模型记住了整个互联网呢?那我们叫它什么?GPT-4的训练数据规模约等于人类有史以来写下的文字的一个大样本。如果它"记住"了这些,和过拟合的本质区别在哪里?------是规模,还是别的什么?还有一个问题:当分布偏移 发生时,ERM失效。但人类面对分布偏移时,有时候也会失效------我们在陌生文化里判断错,在新领域里犯低级错误。那么,ERM的缺陷是机器学习独有的,还是所有归纳学习系统共有的?包括你自己?先把这个问题放着。
- 过拟合的本质:噪声记忆 + 分布割裂
过拟合是模型在有限训练集上,错误地将数据中的【噪声、特例、抽样偏差】当成了真实分布的规律。
目标偏离: ERM(经验风险最小化)的目标是拟合数据背后的真实分布,但过拟合时,模型拟合的是训练集的「专属误差」(比如样本标注错误、随机波动)。
分布割裂: 训练集分布 ≠ 测试集分布,模型记住的是训练集的「局部特征」,无法泛化到新样本。
典型例子: 用 100 张猫的照片训练分类器,模型记住了每张照片的像素级细节(比如某张猫照片的背景是沙发),而不是「猫的通用特征」(耳朵、尾巴、体态)------ 换一张背景是草地的猫照片,模型就会误判。
- GPT-4 式「记住互联网」的本质:规律记忆 + 分布覆盖
GPT-4 的训练数据规模接近人类文本的「全局分布 」,它的「记忆」本质是对人类语言、知识、逻辑的结构化建模,而非像素级 / 字符级的逐字存储。
- 【目标对齐】 :预训练的目标是拟合人类语言的真实分布 ------ 包括语法规则、语义关联、常识逻辑、因果关系。互联网文本是人类认知的「大规模样本 」,其分布无限接近「人类语言世界的真实分布」。
- 【记忆的结构化】 :模型不是逐字背诵文本,而是将知识编码为向量空间中的关联结构。比如提到「鸟」,模型会激活「会飞、有翅膀、卵生」等关联特征,而不是记住某一篇关于鸟的文章的具体字句。
- 【泛化的前提】 :当训练数据分布 ≈ 真实世界分布时,「记住」分布规律 = 「掌握」泛化能力。这时候的「记忆」不是错误,而是归纳学习的基础------ 人类学习也是如此:我们通过阅读大量书籍(相当于「训练数据」),记住的不是每句话的文字,而是文字背后的知识和逻辑。

ERM 的缺陷:不是机器学习独有的,是所有归纳学习系统的固有约束
ERM(经验风险最小化)是机器学习的核心准则,但它在分布偏移时会失效 ------ 这个缺陷不是机器学习的专利,而是归纳学习的共性局限,人类的归纳学习同样受此约束。
1. 先明确:ERM 失效的本质是归纳学习的「分布假设前提」被打破
ERM 的成立,有一个核心前提:
训练集与测试集同分布(i.i.d. 假设)
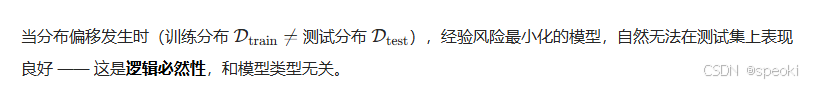
2. 人类的归纳学习:同样受「分布偏移」的制约
人类的学习本质上也是一种归纳学习 :我们从过往的经验(相当于「训练集」)中归纳规律,再用规律判断新事物(相当于「测试集」)。当新事物的分布偏离过往经验时,人类同样会失效。
文化差异的例子 :你在自己的文化中,归纳出「与人打招呼要握手」的规律(经验风险最小),但到了陌生文化(比如某些东南亚国家),人们习惯「合十礼」------ 此时「分布偏移」发生,你的「握手」规律失效,会犯「低级错误」。
新领域的例子 :一个擅长物理的科学家,在生物学领域会犯低级错误 ------ 因为他的「训练经验」(物理知识)的分布,和生物学的「测试分布」完全不同。
本质共性 :人类和机器学习一样,归纳的规律只在「经验分布覆盖的范围内」有效 。超出这个范围,归纳失效 ------ 这是休谟归纳问题的核心:我们无法从有限的经验中,推导出适用于所有情况的必然规律。
- 人类与机器的差异:不是「是否受约束」,而是「应对分布偏移的能力」
虽然 ERM 的缺陷是共性的,但人类和机器在应对分布偏移时的策略不同:
- 机器的应对方式:依赖算法优化 ------ 比如领域自适应(Domain Adaptation)、元学习(Meta-Learning)、自监督学习(Self-Supervised Learning),本质是扩大训练分布的覆盖范围,或学习「分布变化的规律」。
- 人类的应对方式:依赖认知灵活性 ------ 比如类比推理、抽象思维、常识迁移,本质是从已有经验中提取更底层的抽象规律,再迁移到新分布中。比如,人类可以从「握手、合十礼都是打招呼的方式」,归纳出「打招呼是表达友好的仪式」这一抽象规律,从而在新文化中快速适应。
捷径学习:当相关性比因果更容易
这里有一个思想实验。
假设你要训练一个模型识别"奶牛"。训练集里有1000张奶牛的照片,其中950张的背景是草地,50张的背景是沙滩(某个海边农场)。
ERM会学到什么?
如果模型足够简单,它可能学到:"如果背景是草地,就预测奶牛"。这个规则在训练集上的准确率是95%------非常好。但这个规则捕获了"奶牛"的本质吗?显然没有。当你把这个模型部署到一个沙滩农场,它会把所有奶牛都分类错误。这就是捷径学习(Shortcut Learning)------模型学会了利用训练数据中的虚假相关性(spurious correlation),而不是真正的因果特征。
Geirhos等人在2020年的综述里系统地总结了这个现象。他们指出,捷径学习在深度学习里无处不在:
- 纹理偏见: ImageNet训练的模型更依赖纹理而非形状来分类,而人类恰好相反
- 背景依赖: 目标检测模型会利用背景统计(比如"船通常出现在水面上")作为捷径
- 数据集偏见: 情感分析模型会过度依赖某些高频词(如"terrible"、"amazing"),而忽略句子的整体语义
【为什么会这样?】
因为ERM没有区分**"有用的相关性"和"虚假的相关性"的机制。 只要某个特征在训练数据上和标签相关,ERM就会利用它------不管这个相关性在训练分布之外是否依然成立。
2022年,Puli等人的研究揭示了一个更深层的原因:即使在虚假特征(捷径)不提供任何额外信息的情况下------也就是说,【稳定特征】已经完全决定了标签------默认的ERM(梯度下降+交叉熵)仍然会优先依赖捷径。
为什么?因为梯度下降隐含地在最大化分类边界(margin)。而在线性可分的情况下,最大边界解往往是那个同时利用了稳定特征和捷径的解,即使只用稳定特征就能达到零训练误差。这不是过拟合------训练误差已经是零了。
这是归纳偏置**的问题:梯度下降+交叉熵的组合,天然地偏好某种类型的解,而这种解在捷径存在时,会过度依赖捷径。
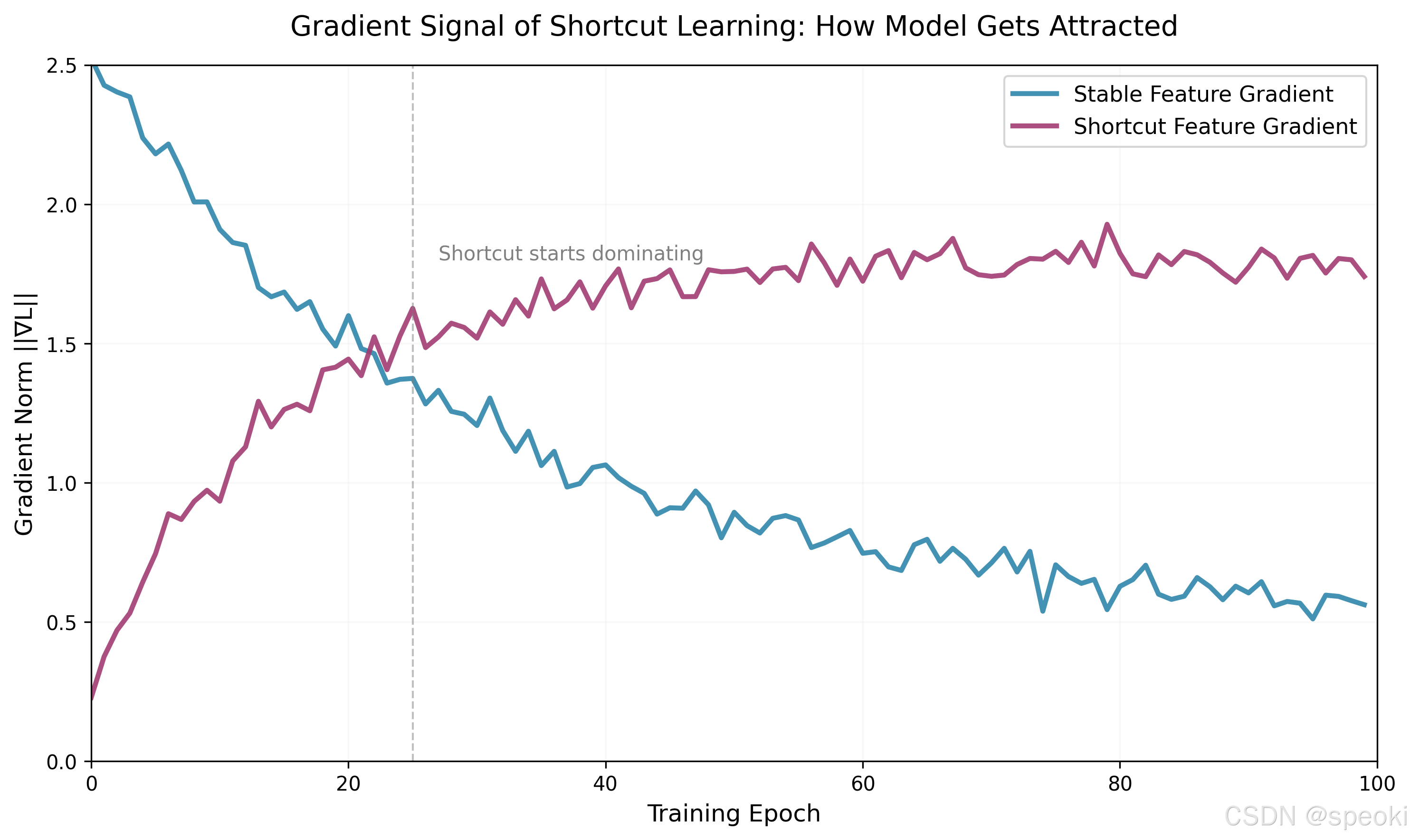
训练过程中捷径特征与稳定特征的梯度演化
图1:训练过程中,捷径特征的梯度范数快速增长并保持高位,而稳定特征的梯度逐渐衰减。这表明模型在优化过程中逐渐被捷径吸引,即使稳定特征已经足以完成任务。
让我用一个更形式化的框架来说明这一点。
因果图视角:稳定特征与虚假特征

但这个相关性不是因果的。 X c X_c Xc不决定 Y Y Y,是 Y Y Y决定了 X c X_c Xc在训练数据里的分布。

这是ERM的结构性限制:ERM优化的是 P ( Y ∣ X ) P(Y|X) P(Y∣X),而不是因果机制 P ( X ∣ Y ) P(X|Y) P(X∣Y)。
Pearl的因果阶梯告诉我们,要回答干预性问题("如果我把背景换成沙滩,模型还能识别奶牛吗?"),你需要的不是条件概率,而是因果模型。
但ERM只能访问观测数据,它无法区分相关性和因果性。
=========
模型的行为,在多大程度上可以被"记忆+检索训练数据中的模式"来解释?
他们的实验设计很巧妙。他们构造了一个完全可控的环境DataAlchemy,从头训练语言模型,然后系统地改变训练数据和测试数据之间的分布差异:
- **任务分布偏移:**训练时见过加法,测试时做乘法
- **长度分布偏移:**训练时见过3位数运算,测试时做5位数运算
- **格式分布偏移:**训练时见过"step 1, step 2"的格式,测试时换成"first, second"
结果是毁灭性的:CoT推理在所有三种分布偏移下都显著退化。 模型不是在"推理",而是在"模式匹配"------它学会了在训练数据里,什么样的输入对应什么样的推理链格式,然后在测试时复现这个格式。
当测试数据的分布和训练数据不同时,这个复现就失败了。
这和第一节里GPT-3在字母串类比上的崩溃是同一个现象:模型学到的是表面的统计规律,而不是底层的抽象规则。
但这里有一个更深的问题。
==Bender等人的"随机鹦鹉"批评,隐含了一个假设:如果模型只是在做统计模式匹配,那么它的能力是有上界的------它不能超越训练数据的统计结构。 ==但这个假设对吗?2023年,Wei等人提出了一个反驳:即使模型只是在做模式匹配,如果训练数据足够大、足够多样,模式匹配本身可能就足以产生看起来像"推理"的行为。这是一个关于 涌现(emergence)的争论:当模型规模和数据规模增长到某个临界点,是否会出现质变?
目前的证据是混合的。
一方面,我们确实看到了一些令人惊讶的能力------比如GPT-4在某些推理任务上的表现,已经接近人类平均水平。另一方面,这些能力在分布偏移下 的脆弱性,表明它们可能仍然是"复杂的模式匹配",而不是真正的抽象推理。关键的测试是:模型能否在训练数据从未见过的组合方式上,产生正确的行为?这就是下一节要讲的:分布偏移作为试金石。
分布偏移:推理能力的试金石
如果一个模型真的"理解"了它在做什么,那么当输入数据的分布发生变化时,它的性能应该优雅地退化 ------而不是崩溃。
这是一个可以被精确测试的假设。
分布内(In-Distribution, ID)性能 衡量的是模型在和训练数据相似的数据上的表现。这是标准的测试集评估。
分布外(Out-of-Distribution, OOD)性能 衡量的是模型在训练分布之外的数据上的表现。这才是真正的泛化能力。
让我给你看几个具体的例子,说明分布偏移如何暴露模型的脆弱性。
例子一:医学图像分割中的捷径
2024年,Woodland等人研究了深度学习模型在医学图像分割任务上的OOD检测 。他们发现:在肝脏分割任务上训练的模型,当遇到来自不同医院、不同扫描仪的图像时,性能显著下降。问题不在于图像质量------新的图像质量很好。问题在于模型学到了训练数据中的设备特异性伪影(device-specific artifacts)作为捷径 。
比如,某个特定型号的CT扫描仪会在图像的某个位置产生特定的噪声模式。模型学会了利用这个噪声模式来辅助分割------因为在训练数据里,这个噪声模式和肝脏的位置高度相关。但当换到另一个型号的扫描仪,这个噪声模式消失了,模型的分割准确率就崩溃了。
例子二:自然语言理解中的虚假相关
2023年,Shuieh等人系统地评估了三种后训练算法(SFT、DPO、KTO)在虚假相关性下的鲁棒性。
他们构造了数学推理、指令遵循、文档问答三类任务,并在数据中引入不同程度的虚假相关 (10% vs 90%)。
结果显示:所有模型在高虚假相关性下都显著退化 。 偏好学习方法(DPO/KTO)在数学推理任务上表现相对鲁棒,但在复杂的上下文密集型任务上,监督微调(SFT)反而更强。
这说明什么?说明没有一种训练方法能普遍地抵抗捷径学习。最佳策略取决于任务类型和虚假相关的性质。
例子三:CoT推理的分布脆弱性
回到Zhao等人的DataAlchemy实验。他们的核心发现是:CoT推理是训练数据分布的脆弱镜像 。当【任务、长度、格式】三个维度中的任何一个发生偏移,CoT的有效性都会显著下降。这表明模型学到的不是"如何推理",而是"在训练数据里,推理链长什么样 "。更糟糕的是,模型在分布偏移下的失败方式是**系统性的,**而不是随机的。它不是偶尔犯错,而是在特定类型的输入上一致地失败------因为那些输入触发了训练数据中不存在的模式。这三个例子指向同一个结论:分布偏移不是边缘情况,而是核心测试。 如果一个模型只在分布内表现良好,那么它学到的很可能是统计相关性,而不是因果机制。
图2:左图显示随着训练数据中捷径相关性增强,ID准确率提升但OOD准确率下降。右图显示泛化差距(ID-OOD)随捷径强度线性增长,当捷径相关性超过80%时,泛化差距进入危险区(>20%)。这量化了捷径学习对分布外泛化的破坏性影响。
为什么ERM的归纳偏置不够
ERM是一个合理的学习原则。问题在于:ERM配合标准的优化算法(梯度下降)和损失函数(交叉熵),产生的归纳偏置,不适合学习因果结构。
归纳偏置(Inductive Bias)是学习算法隐含的假设------它决定了在多个能够拟合训练数据的假设中,算法会选择哪一个。梯度下降+交叉熵的归纳偏置是什么?
在【线性可分】的情况下,梯度下降会收敛到【最大边界解】(max-margin solution)------那个使得分类边界到最近训练样本的距离最大的解。这在很多情况下是好的。最大边界通常意味着更好的泛化------因为它对训练数据的小扰动更鲁棒。但在捷径存在的情况下,最大边界解往往是那个同时利用稳定特征和捷径 的解。
为什么?因为如果你同时用两个特征,你可以把分类边界推得更远------即使其中一个特征(捷径)在分布外会失效。Puli等人在2023年的研究精确地刻画了这个现象。他们证明:在一个简单的线性感知任务中,即使稳定特征已经完全决定了标签,梯度下降仍然会给捷径分配非零权重------因为这样可以最大化边界。
解决方案是什么?
**一个方向是改变归纳偏置。**比如,不追求最大边界,而追求均匀边界(uniform margin)------让所有训练样本到分类边界的距离尽可能相等。Puli等人提出的MARG-CTRL(Margin Control)就是这个思路。通过调整损失函数,鼓励模型产生均匀边界的解,从而减少对捷径的依赖。
**另一个方向是显式地建模因果结构。**这需要超越纯粹的观测数据,引入干预或反事实推理------这是第六章的主题。但即使不引入因果推理,我们也可以通过更聪明的训练策略来缓解捷径学习。
缓解策略:从数据增强到对抗训练
如果我们知道捷径在哪里,我们能做什么?
策略一:数据增强
最直接的方法是增加训练数据的多样性,打破虚假相关性。比如,在奶牛识别的例子里,如果你能收集到足够多的"奶牛在沙滩上"的图片,模型就不会过度依赖"草地背景"这个捷径。
但这个方法有两个问题:
第一,你需要知道捷径是什么。在真实场景里,捷径往往是隐蔽的------你不知道模型在利用什么虚假相关性。
第二,即使你知道捷径,收集足够多样的数据可能非常昂贵或不可行。
策略二:重加权训练样本
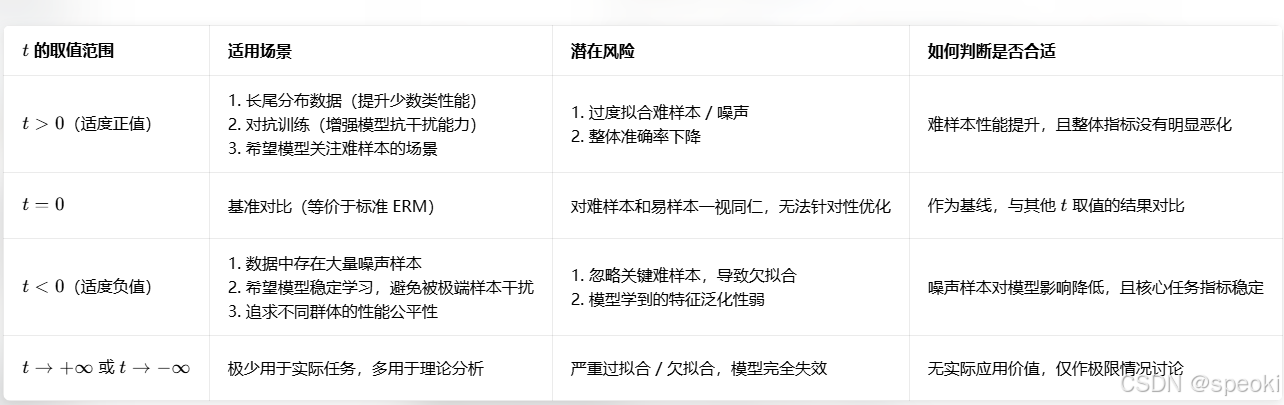
如果某些训练样本"太容易"------模型可以用捷径就预测对------那么降低这些样本的权重,强迫模型学习更难的样本。这是Li等人在2020年提出的Tilted ERM的思路。通过引入一个"倾斜"参数 ,调整每个样本的损失权重。


策略三:对抗训练
另一个思路是显式地生成**"对抗样本"**------那些模型会依赖捷径而失败的样本------然后在这些样本上训练。Sricharan和Srivastava在2018年提出:用GAN生成模型高置信度但实际上是OOD的样本,然后最大化模型在这些样本上的熵(不确定性)。这强迫模型不要对分布外的输入过度自信,从而减少对捷径的依赖。
策略四:因果正则化
如果我们有关于因果结构的先验知识,可以把它编码进正则化项。

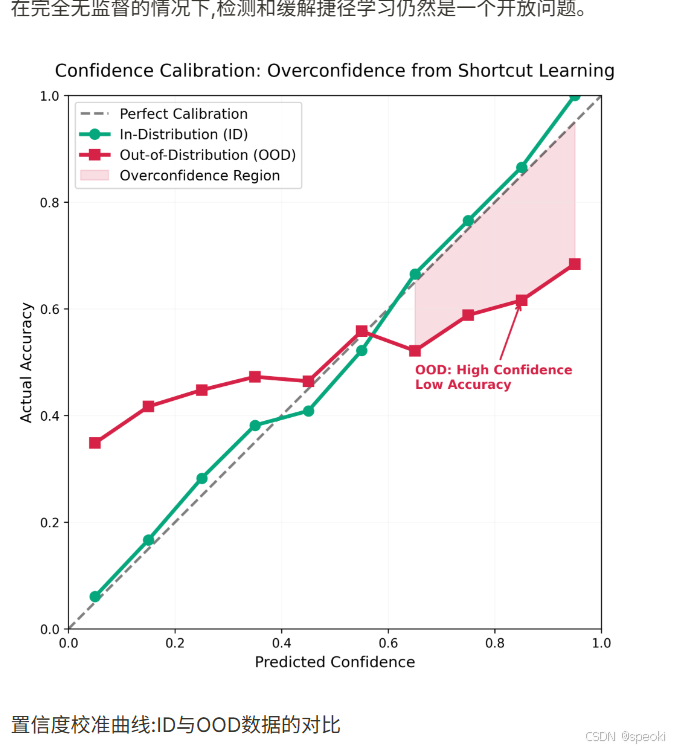
但这些方法都有一个共同的局限:它们需要某种形式的监督信号------要么是关于捷径的先验知识,要么是OOD数据,要么是人工标注的难样本。在完全无监督的情况下,检测和缓解捷径学习仍然是一个开放问题。
伪代码:捷径检测与OOD泛化测试
一个小小的停顿
让我梳理一下这一章做了什么。
经验风险最小化是监督学习的标准范式。它的理论保证建立在一个关键假设上:训练数据和测试数据来自同一个分布。
但这个假设在现实中几乎从不成立。分布偏移是常态,不是例外。
当分布偏移发生时,ERM学到的那些"在训练数据上有效的相关性"可能完全失效。这不是bug,这是ERM的结构性特征:ERM优化的是统计相关性,而不是因果机制。捷径学习是这个问题的具体表现:模型学会了利用训练数据中的虚假相关性,而不是真正的因果特征。更糟糕的是,即使虚假特征不提供任何额外信息,梯度下降+交叉熵的归纳偏置仍然会让模型依赖它们------因为这样可以最大化分类边界。
随机鹦鹉假说指出:大型语言模型可能只是在做复杂的统计模式匹配,而不是真正的推理。分布偏移下的脆弱性------比如CoT推理在任务、长度、格式偏移下的崩溃------支持了这个假说。缓解捷径学习的方法包括数据增强、样本重加权、对抗训练、因果正则化。但所有这些方法都需要某种形式的监督信号。在完全无监督的情况下,检测和缓解捷径学习仍然是开放问题。

悬而未决
- 大型语言模型的"涌现能力"是真正的质变,还是复杂模式匹配的量变?当模型规模继续增长,这个问题的答案会改变吗?
涌现能力(如思维链推理、上下文学习、跨领域迁移)的出现,直接依赖于模型参数量、训练数据量、计算量的指数级增长 。从技术原理看,大模型的本质是基于 Transformer 架构的概率模型 ,其所有能力都来自对训练数据中统计规律和语义关联 的建模------ 没有脱离 "模式匹配" 的全新机制。
例如,思维链推理的本质是模型学会了 "模仿人类的推理步骤":训练数据中包含大量 "问题 - 步骤 - 答案" 的文本序列,模型通过模式匹配,学会了生成符合逻辑的步骤序列,而非真正理解 "推理的本质"。
为什么说是质变:当规模突破某个阈值时,模型的能力会出现非连续的跃升 ------ 小模型完全不具备的能力(如复杂数学推理、代码生成),大模型突然具备了。这种 "阈值效应" 就是质变的体现 。
背后的原因是:小规模模型只能捕捉局部、浅层的模式 (如关键词匹配),而大规模模型能捕捉全局、深层的模式 (如语义逻辑、因果关联的统计近似)。这种深层模式匹配,在人类视角下就表现为 "智能行为"。
大概率不会------ 除非模型架构或训练范式发生本质性变革(如引入真正的因果推理模块、自主学习能力)。当前大模型的 "智能" 是统计智能 ,其上限是 "无限逼近训练数据的真实分布"。即使规模再增长,它依然是在优化 "预测下一个 token 的概率",没有跳出 "模式匹配" 的范畴。但规模增长会让质变的表现更显著 :模型的泛化能力更强、涌现的任务更多、模式匹配的精度更高,甚至可能出现人类暂时无法解释的 "超智能行为"------ 但本质仍是更复杂的模式匹配。
关键争议点
- 乐观派:认为涌现是通往通用人工智能(AGI)的必经之路,规模足够大时,模型会自发产生 "理解" 和 "意识"。
- 悲观派:认为涌现只是 "统计规律的极致体现",没有真正的智能,规模增长只是让模型更 "博学",而非更 "聪明"。
- 在完全无监督的情况下,是否存在通用的方法来检测捷径学习?还是说检测捷径本质上需要关于任务的先验知识?
**核心结论:**完全无监督下,不存在通用的捷径学习检测方法;检测捷径本质上依赖任务的先验知识
原因拆解: 捷径学习的定义依赖先验知识
捷径特征的本质是 "在训练分布上与标签相关,但在真实分布上无关的特征"。判断一个特征是 "捷径" 还是 "稳定特征",必须【依赖对任务本质的先验认知】。例如:判断 "鸟" 的任务中,"蓝色背景" 是捷径 ------ 这是因为人类知道 "鸟的本质特征是羽毛、翅膀,而非背景颜色"。如果没有这个先验知识,模型无法区分 "蓝色背景" 和 "羽毛" 哪个是捷径。
无监督场景下的困境
无监督学习的目标是学习数据的内在结构 ,没有 "标签" 作为参照。此时,"捷径" 的定义本身就模糊了 ------ 什么是 "与标签无关的特征"?没有标签,就无法判断特征的 "有用性"。即使某些方法能检测出 "模型依赖了某个简单特征"(如通过特征重要性分析),也无法确定这个特征是 "捷径" 还是 "真实结构的一部分"。
现有检测方法的局限性
目前的捷径检测方法,本质上都依赖间接的先验信息:
-
**领域自适应方法:**依赖 "源域和目标域的分布差异" 这一先验;
- 核心问题:源域和目标域的数据分布不同,但任务相同。比如:用 "晴天的猫图片"(源域)训练分类器,要在 "雨天的猫图片"(目标域)上准确分类 ------ 此时 "天气" 就是捷径特征,模型容易依赖 "晴天背景" 判断猫。
- 核心思路:通过对齐源域和目标域的分布,让模型忽略 "领域专属的捷径特征",只学习 "跨领域的稳定特征"。
- 依赖的先验假设:"源域和目标域的分布差异是由捷径特征导致的,稳定特征在两个域中分布一致"。
- 典型实现:
- 特征对齐:用对抗学习(如 DANN)让源域和目标域的特征在隐空间中无法区分;
- 权重迁移:冻结预训练模型的底层特征(稳定特征),只微调上层(任务相关特征)。
- 一句话总结:强行让模型 "看不见" 源域和目标域的差异,只能学通用特征。
-
**不变风险最小化(IRM):**依赖 "不同环境下,稳定特征的预测结果一致" 这一先验;
-
核心问题:传统 ERM 会依赖 "某个环境下的捷径特征",比如在 "蓝色背景的鸟图片" 环境中,模型学 "蓝色背景";在 "绿色背景的鸟图片" 环境中,模型学 "绿色背景"。
-
核心思路:要求模型学到的特征,在所有环境中都能稳定预测标签------ 只有 "因果稳定特征" 能满足这个条件,捷径特征会因为环境变化而失效。
-
依赖的先验假设:"存在一组稳定特征,在不同环境下与标签的因果关系不变;捷径特征的相关性会随环境变化"。
-
典型实现:
- 构建多个 "环境"(比如不同背景的鸟图片数据集),模型需要同时在所有环境中最小化风险,并且满足 "特征到标签的映射函数在所有环境中相同"。
- 一句话总结:让模型在多个环境中 "交叉验证",只有稳定特征能通过所有环境的考验。
-
**因果推断方法:**依赖 "因果图结构" 这一先验。
- 核心问题:直接从 "因果" 层面区分 "稳定特征(因)" 和 "捷径特征(相关但非因)"。
- 核心思路:先构建因果图(Causal Graph),明确变量之间的因果关系(比如:鸟→有羽毛;背景颜色→与鸟无关),然后通过干预操作(do-calculus) 强制模型只使用因果特征。
- 依赖的先验假设:"我们已知或能推断出任务的因果图结构"------ 比如知道 "羽毛" 是鸟的因,"背景" 不是。
- 典型实现:
- 因果表征学习:将输入数据分解为 "因果因子" 和 "混淆因子(捷径)";
- 后门调整:阻断捷径特征到标签的路径,只保留因果路径

这些方法都不是 "完全无监督" 的,而是隐含了对任务的假设。
在无监督学习中,模型可能会依赖数据的冗余特征(如图片的像素噪声、文本的高频词汇)来学习结构。但这种依赖是否属于 "捷径学习",取决于下游任务的需求 ------ 如果下游任务需要的是核心结构,那么冗余特征就是捷径;如果下游任务需要的是表面特征,那么冗余特征就是有用特征。
结论:检测捷径的核心是 "任务的本质",而任务的本质只能通过先验知识定义。完全无监督下,不存在通用的检测方法。
- ERM的归纳偏置(最大边界)在什么条件下是有益的,在什么条件下是有害的?是否存在一个统一的框架来刻画这个权衡?
"梯度下降隐含最大化分类边界",是支持向量机(SVM) 的核心思想
- 分类边界的margin(间隔):指分类超平面到最近样本点的距离。margin 越大,模型的泛化能力越强。
- 梯度下降 + 交叉熵的优化过程,会倾向于选择 margin 最大的解------ 因为更大的 margin 意味着更小的分类风险,在训练数据上更稳定。
**最大边界何时有益?**当训练分布与真实分布一致,且不存在捷径特征时,最大边界是有益的。
有益的核心条件:
- i.i.d. 假设成立:训练集和测试集同分布;
- 特征是稳定的因果特征:模型依赖的特征与标签有真实的因果关系。
最大边界何时有害?
当训练分布中存在捷径特征时,最大边界是有害的。
- 有害的核心条件:
- 存在捷径特征:捷径特征与标签的相关性高于稳定特征;
- 梯度下降的归纳偏置偏好 "同时利用稳定特征和捷径特征的解"------ 这个解的 margin 往往比 "只用稳定特征的解" 更大。
- 此时,最大边界解意味着:
模型过度依赖捷径特征,虽然在训练集上 margin 很大(表现好),但在测试集上(分布偏移时)泛化能力极差。例如:模型同时利用 "羽毛" 和 "蓝色背景",得到的分类边界 margin 更大,但换了非蓝色背景的鸟图片,模型就会误判。
是否存在统一的权衡框架?
目前存在理论框架,但尚未完全统一。主流的框架是结构风险最小化(SRM) 和因果风险最小化(CRM) 的结合:

- 如果我们用纯粹随机的数据训练一个神经网络,它会学到什么样的"捷径"?这个思想实验能告诉我们关于捷径学习的本质吗?

- 人类学习是否也存在捷径学习?如果存在,人类是如何克服它的?这对设计更好的机器学习算法有什么启示?
人类学习中普遍存在捷径学习
人类的归纳学习与机器学习的本质相似 ------ 都是从有限经验中总结规律,因此必然会依赖 "捷径"。常见的例子:
刻板印象:看到 "东北人" 就认为 "能喝酒"------ 这是将 "地域" 作为判断 "酒量" 的捷径特征,忽略了个体差异。
幸存者偏差:看到 "成功人士都早起",就认为 "早起是成功的原因"------ 这是将 "早起" 作为判断 "成功" 的捷径特征,忽略了其他核心因素(如能力、机遇)。
应试教育的 "套路":学生通过背 "题型模板" 来解题,而非理解知识点 ------ 这是将 "题型" 作为解题的捷径特征,忽略了知识的本质逻辑。
人类如何克服捷径学习?核心是 4 种能力,这是机器学习目前缺乏的
(1) 因果推理能力
人类能区分 **"相关性" 和 "因果性"------ 知道 "蓝色背景" 和 "鸟" 是相关关系,而 "羽毛" 和 "鸟" 是因果关系。这种能力来自于对世界的物理直觉和逻辑推理 **。
例如:我们不会认为 "下雨时打伞的人多" 意味着 "打伞导致下雨",因为我们理解 "下雨是打伞的原因"。
(2) 元认知能力(反思能力)
人类能监控自己的学习过程,发现自己依赖了捷径,并主动纠正。
例如:学生考试后会反思 "我这次是靠模板做对的,还是靠理解做对的?",并调整学习策略。
(3) 抽象思维能力
人类能从具体经验中提取抽象的、通用的规律,并迁移到新场景中。
例如:我们从 "鸟会飞、飞机也会飞" 中,抽象出 "飞行需要升力" 的规律,而不会依赖 "翅膀" 这个捷径特征 ------ 因此我们能理解 "没有翅膀的火箭也能飞"。
(4) 社会文化的约束
人类的学习是社会化的,通过教育、交流,我们会继承前人的知识和经验,避免重复犯错。
例如:老师会告诉学生 "不要死记硬背,要理解知识点",帮助学生规避 "套路学习" 的捷径。
对机器学习的启示:要让模型克服捷径学习,需要赋予它人类的核心能力

人机学习的本质差异
机器学习是 "被动优化" :模型的目标是拟合数据,依赖捷径是 "最优解";
人类学习是 "主动探索":人类的目标是理解世界,依赖捷径是 "权宜之计",会主动反思和纠正。
停顿
经验风险最小化 是监督学习的标准范式。它的理论保证建立在一个关键假设上:训练数据和测试数据来自同一个分布。
但这个假设在现实中几乎从不成立。分布偏移是常态,不是例外 。当分布偏移发生时,ERM学到的那些"在训练数据上有效的相关性"可能完全失效。这不是bug,这是ERM的结构性特征:ERM优化的是统计相关性,而不是因果机制 。捷径学习是这个问题的具体表现:模型学会了利用训练数据中的虚假相关性,而不是真正的因果特征 。更糟糕的是,即使虚假特征不提供任何额外信息,梯度下降+交叉熵的归纳偏置仍然会让模型依赖它们------因为这样可以最大化分类边界。
随机鹦鹉假说指出:大型语言模型可能只是在做复杂的统计模式匹配,而不是真正的推理。分布偏移下的脆弱性------比如CoT推理在任务、长度、格式偏移下的崩溃------支持了这个假说。
缓解捷径学习的方法包括【数据增强、样本重加权、对抗训练、因果正则化】。但所有这些方法都需要某种形式的监督信号。在完全无监督的情况下,-【检测和缓解捷径学习】仍然是开放问题。