Anthropic 昨天发布了 Claude Opus 4.7。我也在深夜爆肝实测了一轮。
这篇文章给大家介绍一下Claude Opus 4.7相比上一代Claude Opus 4.6有哪些变化、评分怎么样、以及和GPT-5.4的对比。
基准评分对比
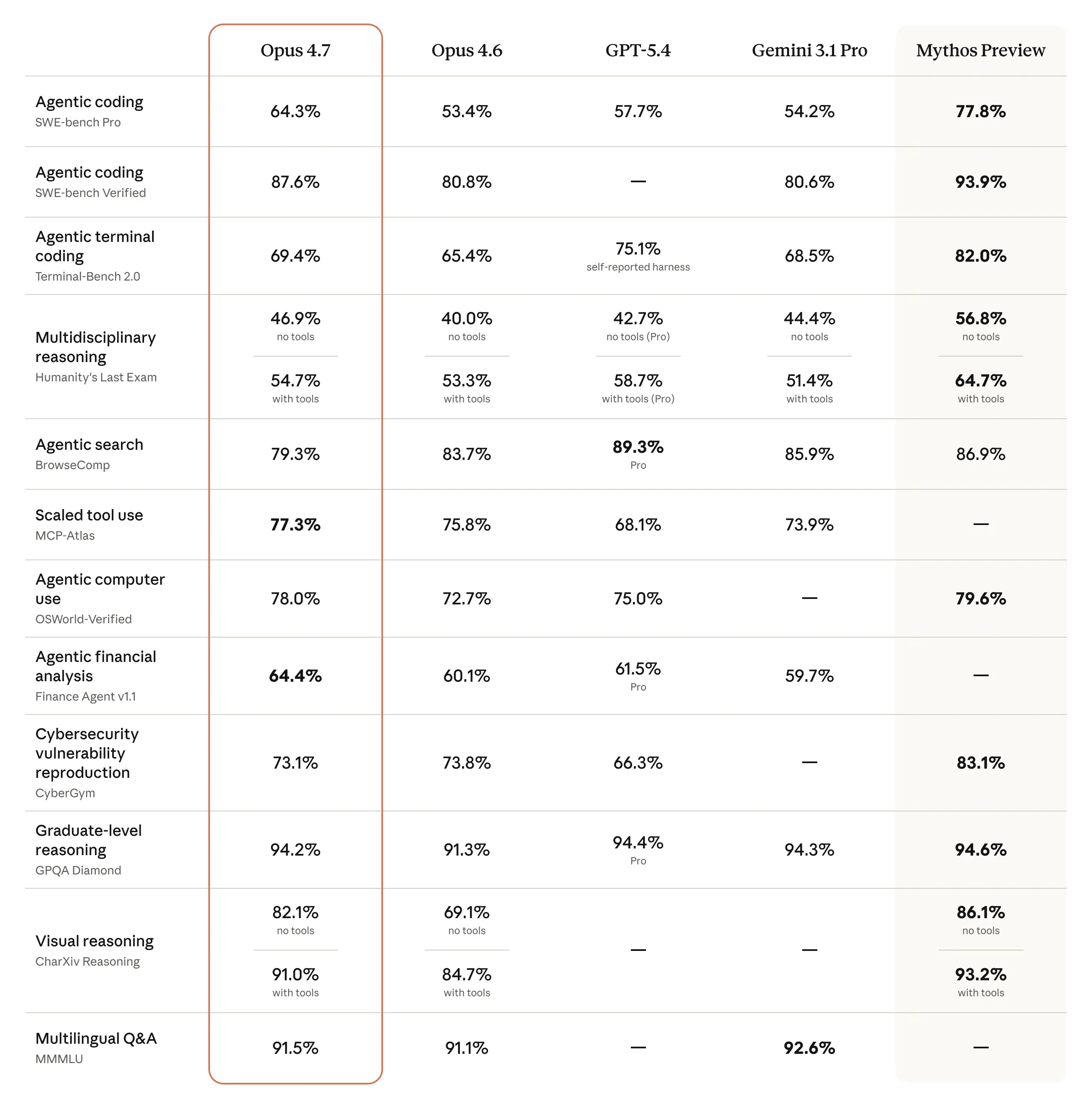
以上图片来自Anthropic 官方,采用的是最佳公开版本来做比较
从上面的榜单来看Opus 4.7 和 GPT-5.4 各有强项,但 Opus 4.7 整体更均衡一些。
在两者都有数据的 10 个项目里,Opus 4.7 领先 6 项,GPT-5.4 领先 4 项。
Opus 4.7 在 Agentic coding、工具调用、电脑操作、金融分析、安全漏洞检测 这些更偏 Agent 实战的项目上表现更强。
GPT-5.4 在 Terminal coding、搜索、多学科 with tools、GPQA 上更占优势。
下面说一下我的一些真实体验:
以下四个变化比较明显
第一,多步推理和长程任务能力更强了。
现在模型在给出回答之前,会先做一轮自我验证。
这意味着它在处理复杂问题、长链路任务时,更不容易中途跑偏,幻觉率和低级错误也会下降。
之前 Opus 4.6 在这一类任务里偶尔会出现"前面答得对,后面跑歪"的情况,4.7 在稳定性上明显好了不少。
第二,Coding Agent 指标提升。
这项提升,代表的不只是"会写代码",而是把代码任务整个跑完的能力更强了 。
比如读仓库、理解需求、改代码、调用工具、跑测试、修 bug,这整条链路的完成度更高。
从分数上看,它比 GPT-5.4 高出大约 6 个百分点;相比 Opus 4.6,也从 53 提升到了 64,进步很明显。
第三,Computer Use 追上来了。
这一项衡量的,其实是模型像人一样操作电脑 的能力。
比如看界面、点按钮、切换页面、填写表单、在多个软件和窗口之间完成任务。
这类能力对自动化办公、网页操作、后台系统处理都很关键。之前 GPT-5.4 在这块更强,这次 Claude 反超了一点。
第四,视觉分辨能力增强。
这个对前端和界面相关任务很有帮助。
比如你给它一张设计稿、截图或者产品界面,它对布局、层级、控件关系的理解会更准确。
对应到实际使用里,就是还原 UI、分析页面问题、根据截图改前端这类任务,表现会比上一代更好。
总结
Opus 4.7 的四个重点提升:
- 长链路更稳了------复杂任务不容易跑偏
- 工具调用更完整------Agent 场景下表现更好
- 代码组织更成熟------code review 结果比上一代明显进步
- 视觉分辨能力增强------前端UI布局设计提升了
从实测来看,Opus 4.7 在编程能力等方面确实都有实质性提升,尤其是长链路任务和前端还原这两块。
但要说全面碾压 GPT-5.4,还没到那个程度。不过话说回来,Opus 4.7 贵也是真的贵。
想第一时间收到更新,关注"北灵聊AI"