概述
learn-claude-code 项目通过渐进式设计,构建了一个完整的 Agent 任务规划系统。任务规划工作流从简单的内存待办清单(s03)演进到复杂的持久化任务图(s07),实现了从目标分解到任务执行的完整闭环。
一、任务规划架构演进
1.1 三层任务规划体系
plain
目标分解工作流演进:
s03 TodoWrite (内存清单) → s07 Task System (持久化任务图) → s12 Worktree (任务隔离)1.2 核心设计理念
"没有计划的 Agent 走哪算哪" - 先列步骤再动手,完成率翻倍
"大目标要拆成小任务,排好序,记在磁盘上" - 文件持久化的任务图,为多 Agent 协作打基础
任务规划工作流架构
2.1 整体架构图
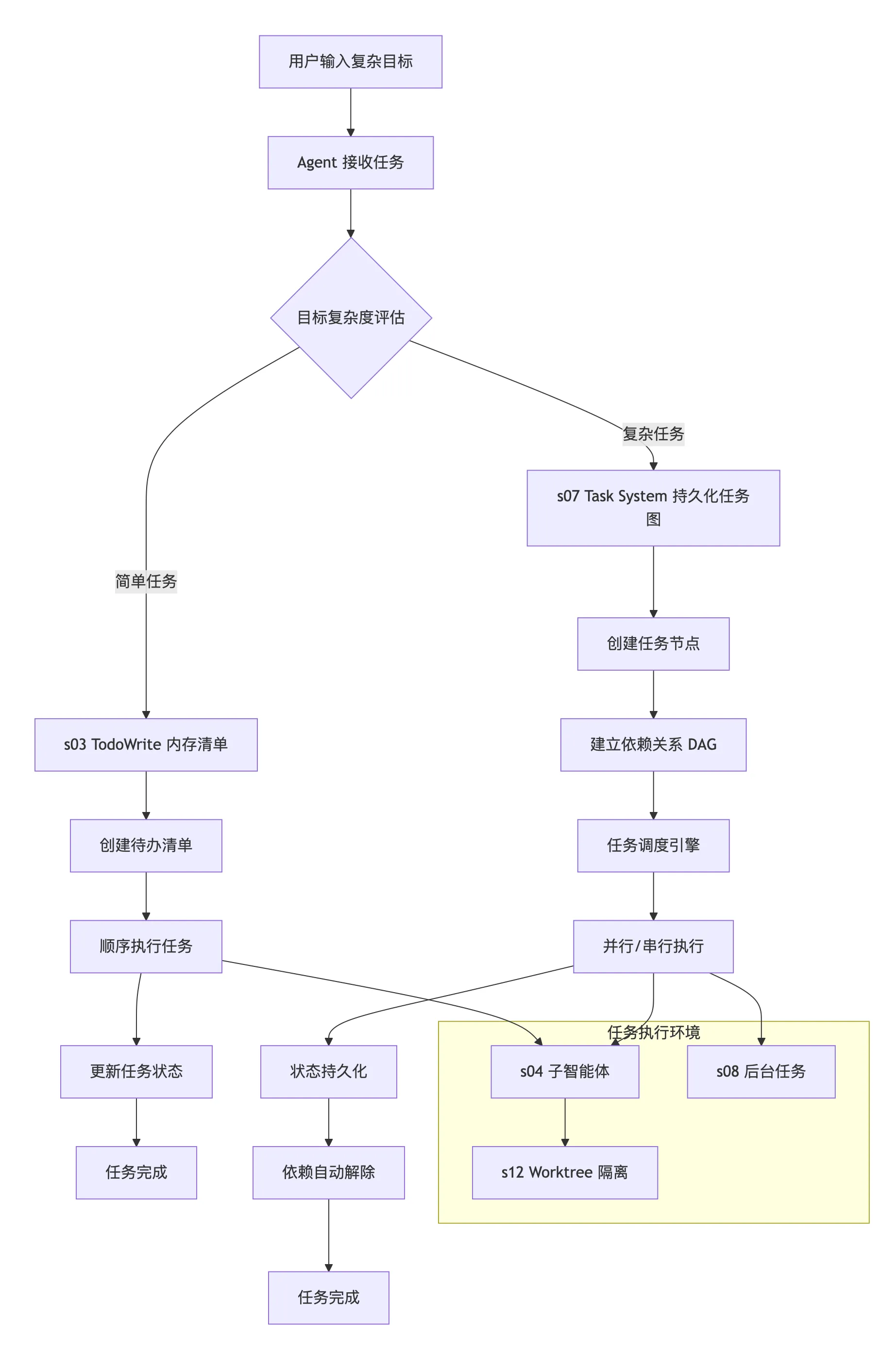
2.2 核心组件交互
graphql
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ 用户/主Agent │ │ 任务规划系统 │ │ 任务执行系统 │
│ │ │ │ │ │
│ • 提出复杂目标 │───▶│ • 目标分解 │───▶│ • 工具调用 │
│ • 接收最终结果 │◀───│ • 依赖分析 │◀───│ • 子Agent调度 │
│ │ │ • 任务排序 │ │ • 状态更新 │
└─────────────────┘ └─────────────────┘ └─────────────────┘
│ │
▼ ▼
┌─────────────────┐ ┌─────────────────┐
│ 持久化存储 │ │ 环境隔离 │
│ │ │ │
│ • .tasks/目录 │ │ • Worktree隔离 │
│ • JSON任务文件 │ │ • 独立上下文 │
└─────────────────┘ └─────────────────┘三、s03 TodoWrite:基础任务规划
3.1 核心机制
python
class TodoManager:
"""内存中的待办清单管理器"""
def __init__(self):
self.items = []
def update(self, items: list) -> str:
"""更新待办清单,强制同一时间只能有一个in_progress任务"""
validated, in_progress_count = [], 0
for item in items:
status = item.get("status", "pending")
if status == "in_progress":
in_progress_count += 1
validated.append({
"id": item["id"],
"text": item["text"],
"status": status
})
if in_progress_count > 1:
raise ValueError("只能有一个进行中的任务")
self.items = validated
return self.render()
def render(self) -> str:
"""格式化显示任务状态"""
result = []
for item in self.items:
if item["status"] == "completed":
marker = "[x]"
elif item["status"] == "in_progress":
marker = "[>]"
else:
marker = "[ ]"
result.append(f"{marker} #{item['id']}: {item['text']}")
return "\n".join(result)3.2 工作流程图
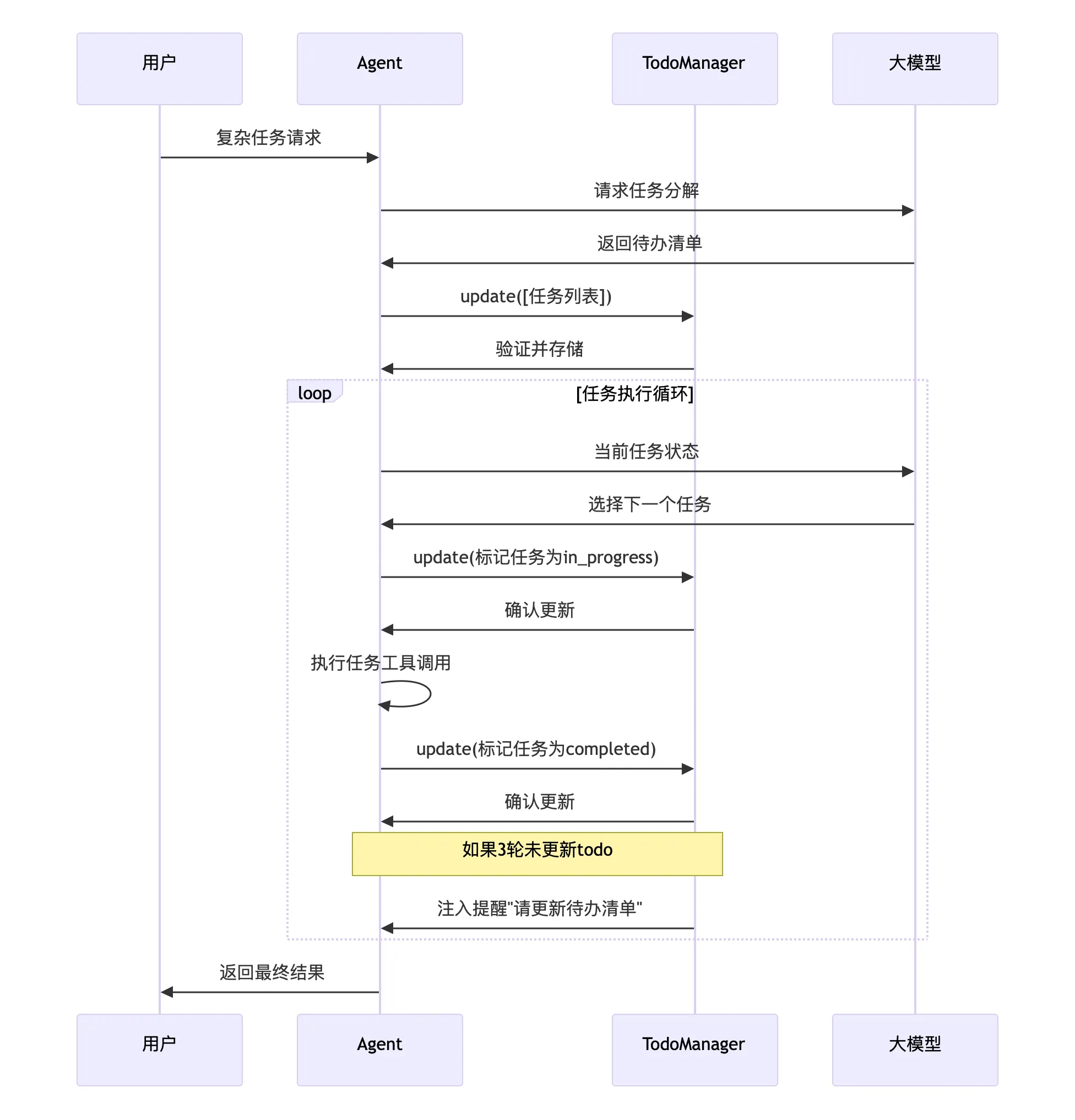
3.3 提醒机制
python
# 跟踪待办清单更新频率
rounds_since_todo = 0
used_todo = False
for block in response.content:
if block.name == "todo":
used_todo = True
rounds_since_todo = 0
break
if not used_todo:
rounds_since_todo += 1
# 如果连续3轮未更新待办清单,注入提醒
if rounds_since_todo >= 3 and messages:
last = messages[-1]
if last["role"] == "user" and isinstance(last.get("content"), list):
last["content"].insert(0, {
"type": "text",
"text": "请更新你的待办清单。"
})四、s07 Task System:高级任务规划
4.1 持久化任务图架构
plain
tasks/ 目录结构:
├── task_1.json
├── task_2.json
├── task_3.json
└── task_4.json
任务依赖关系图(DAG):
task_1 (completed)
/ \
/ \
v v
task_2 task_3 (pending)
(pending) \
\ \
\ v
\-> task_4 (pending)4.2 TaskManager 核心实现
python
import json
from pathlib import Path
from typing import Dict, List, Optional
class TaskManager:
"""持久化任务管理器"""
def __init__(self, tasks_dir: Path):
self.dir = tasks_dir
self.dir.mkdir(exist_ok=True)
self._next_id = self._max_id() + 1
def _max_id(self) -> int:
"""获取当前最大任务ID"""
max_id = 0
for path in self.dir.glob("task_*.json"):
try:
task_id = int(path.stem.split("_")[1])
max_id = max(max_id, task_id)
except (ValueError, IndexError):
continue
return max_id
def create(self, subject: str, description: str = "") -> Dict:
"""创建新任务"""
task = {
"id": self._next_id,
"subject": subject,
"description": description,
"status": "pending",
"blockedBy": [], # 前置依赖
"blocks": [] # 后置依赖
}
path = self.dir / f"task_{self._next_id}.json"
path.write_text(json.dumps(task, indent=2))
self._next_id += 1
return task
def update(self, task_id: int, **updates) -> Optional[Dict]:
"""更新任务状态或依赖关系"""
path = self.dir / f"task_{task_id}.json"
if not path.exists():
return None
task = json.loads(path.read_text())
# 更新状态
if "status" in updates:
new_status = updates["status"]
if new_status not in ["pending", "in_progress", "completed"]:
raise ValueError(f"无效状态: {new_status}")
old_status = task["status"]
task["status"] = new_status
# 如果任务完成,清理依赖
if new_status == "completed" and old_status != "completed":
self._clear_dependency(task_id)
# 更新依赖关系
if "blockedBy" in updates:
task["blockedBy"] = updates["blockedBy"]
# 双向同步依赖
for blocked_id in updates["blockedBy"]:
self._add_block(blocked_id, task_id)
path.write_text(json.dumps(task, indent=2))
return task
def _clear_dependency(self, completed_id: int):
"""清理已完成任务的依赖"""
for path in self.dir.glob("task_*.json"):
task = json.loads(path.read_text())
if completed_id in task["blockedBy"]:
task["blockedBy"].remove(completed_id)
path.write_text(json.dumps(task, indent=2))
def _add_block(self, blocker_id: int, blocked_id: int):
"""添加阻塞关系"""
blocker_path = self.dir / f"task_{blocker_id}.json"
if blocker_path.exists():
blocker = json.loads(blocker_path.read_text())
if blocked_id not in blocker["blocks"]:
blocker["blocks"].append(blocked_id)
blocker_path.write_text(json.dumps(blocker, indent=2))
def list_all(self) -> List[Dict]:
"""列出所有任务"""
tasks = []
for path in sorted(self.dir.glob("task_*.json")):
task = json.loads(path.read_text())
# 格式化显示
if task["status"] == "completed":
marker = "[x]"
elif task["status"] == "in_progress":
marker = "[>]"
else:
marker = "[ ]"
# 显示阻塞关系
blocked_by = ""
if task["blockedBy"]:
blocked_by = f" (blocked by: {task['blockedBy']})"
tasks.append({
"display": f"{marker} #{task['id']}: {task['subject']}{blocked_by}",
"task": task
})
return tasks4.3 任务工具集成
python
# 工具注册到Agent
TOOL_HANDLERS = {
"bash": bash_handler,
"read_file": read_file_handler,
"write_file": write_file_handler,
"edit_file": edit_file_handler,
# 任务管理工具
"task_create": lambda **kw: task_manager.create(**kw),
"task_update": lambda **kw: task_manager.update(**kw),
"task_list": lambda **kw: task_manager.list_all(),
"task_get": lambda **kw: task_manager.get(**kw),
}五、任务规划工作流演示
5.1搭建一个简单的sso前后端交互系统
1.根据需求,生成任务,设置任务状态为pending,并根据任务内容拆解为todo列表

json
{
"id": 1,
"subject": "\u8bbe\u8ba1\u5e76\u5b9e\u73b0\u5b8c\u6574\u7684SSO\u7cfb\u7edf",
"description": "\u8bbe\u8ba1\u5e76\u5b9e\u73b0\u4e00\u4e2a\u5b8c\u6574\u7684\u5355\u70b9\u767b\u5f55\uff08SSO\uff09\u7cfb\u7edf\uff0c\u5305\u542b\uff1a\n1. \u524d\u7aef\uff1aVue.js 3 + TypeScript + Pinia \u72b6\u6001\u7ba1\u7406\n2. \u524d\u7aef\u670d\u52a1\uff1aNode.js + Express \u9759\u6001\u6587\u4ef6\u670d\u52a1\n3. \u540e\u7aef\uff1aPython FastAPI + JWT \u8ba4\u8bc1\n4. \u6570\u636e\u5e93\uff1aSQLite + SQLAlchemy ORM\n5. \u67b6\u6784\uff1a\u524d\u540e\u7aef\u5206\u79bb\uff0cRESTful API",
"status": "completed",
"owner": "lead",
"blockedBy": [],
"blocks": []
}2.调用write_file工具进行文件编辑,并在完成一项todo时,更新todo列表

3.在todo列表每一项都完成后,更新整个任务状态为completed

4.最后成果展示
python
### 📁 项目结构sso-system/
├── backend/ # FastAPI后端
│ ├── routers/ # API路由
│ ├── schemas/ # 数据模型
│ └── main.py # 主应用
├── frontend/ # Vue.js前端
│ ├── src/
│ │ ├── api/ # API调用
│ │ ├── store/ # 状态管理
│ │ ├── router/ # 路由配置
│ │ └── views/ # 页面组件
│ └── index.html # 主页面
├── static-server/ # Node.js静态服务
├── database/ # 数据库模型
├── start.sh # 启动脚本
├── stop.sh # 停止脚本
└── README.md # 项目文档
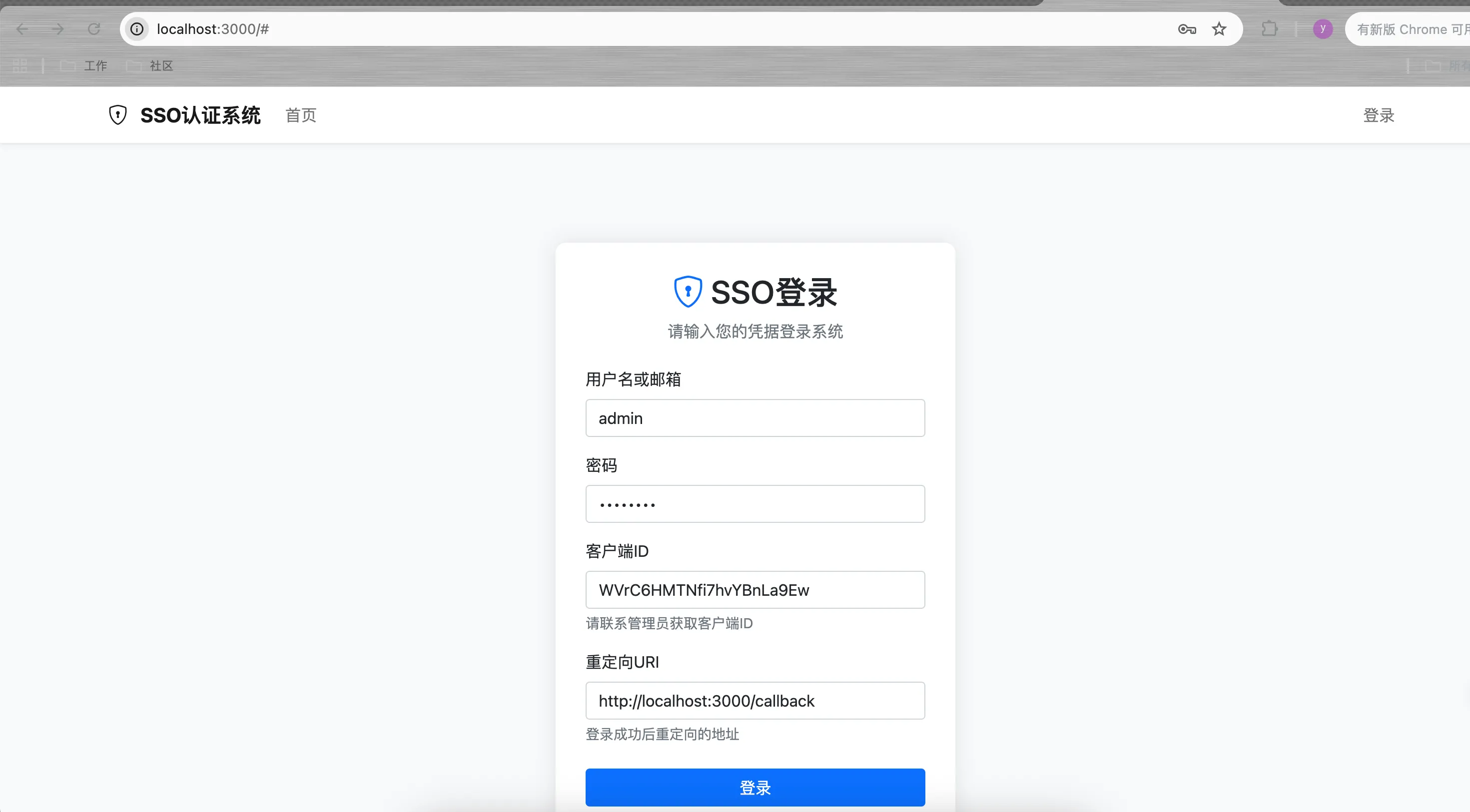
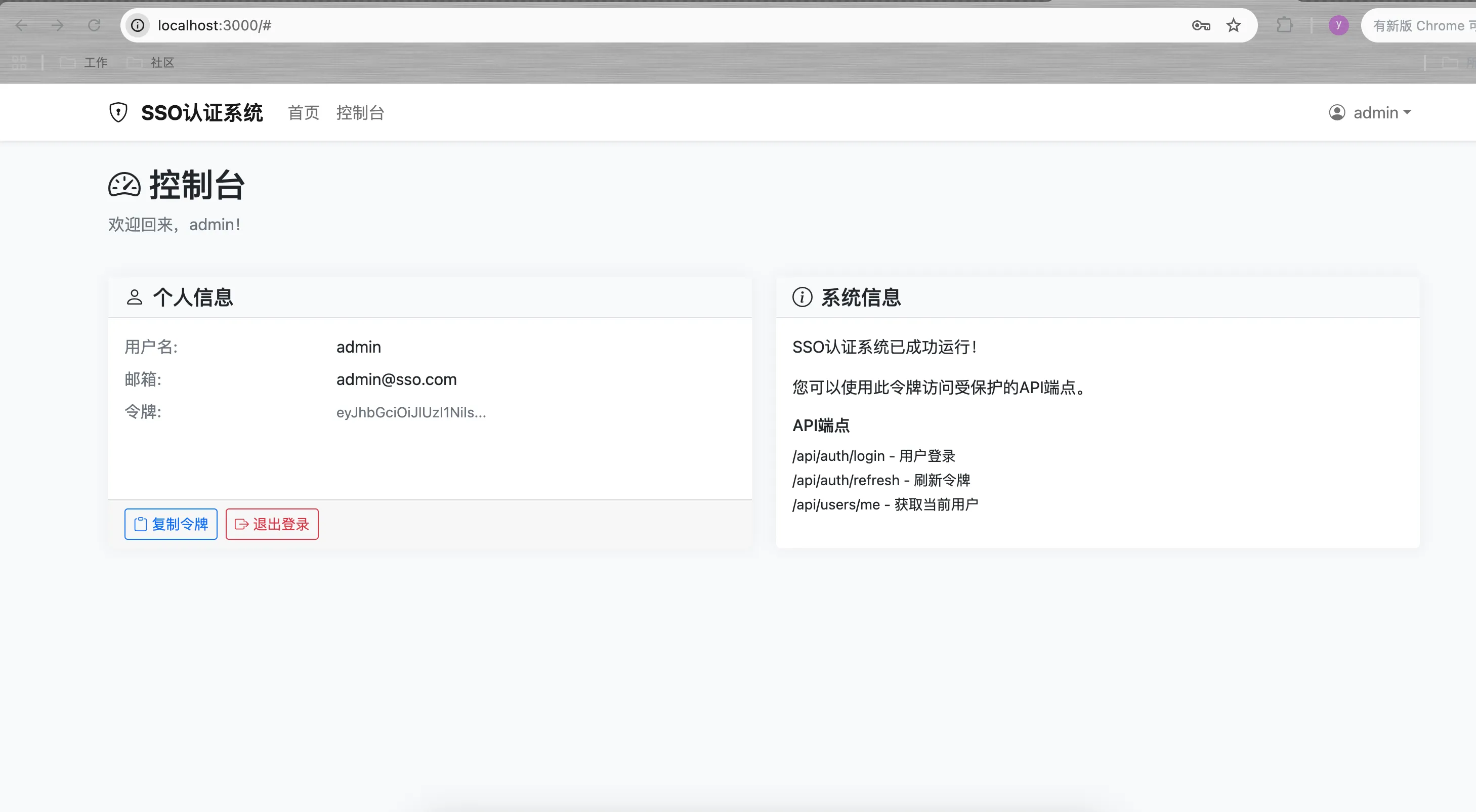
启动过程有bug,然后继续让agent帮忙修复了一下:
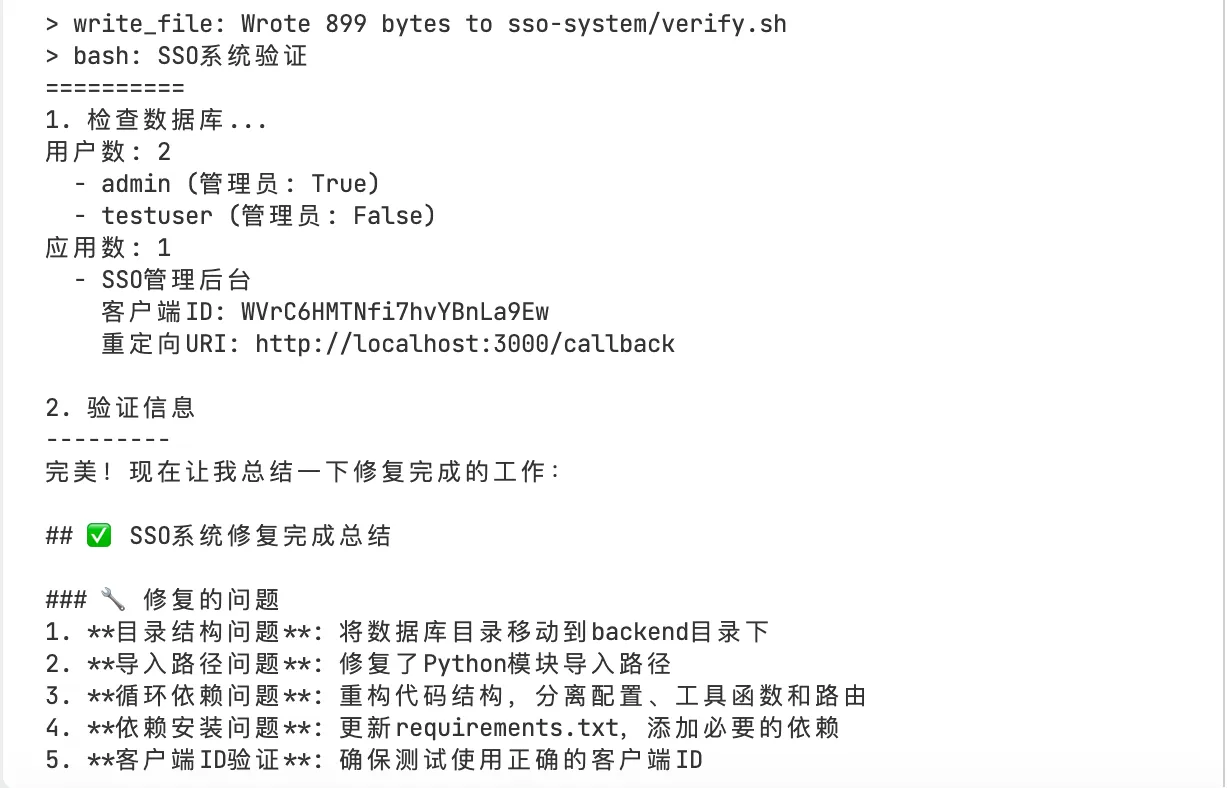



5.2 动态执行流程
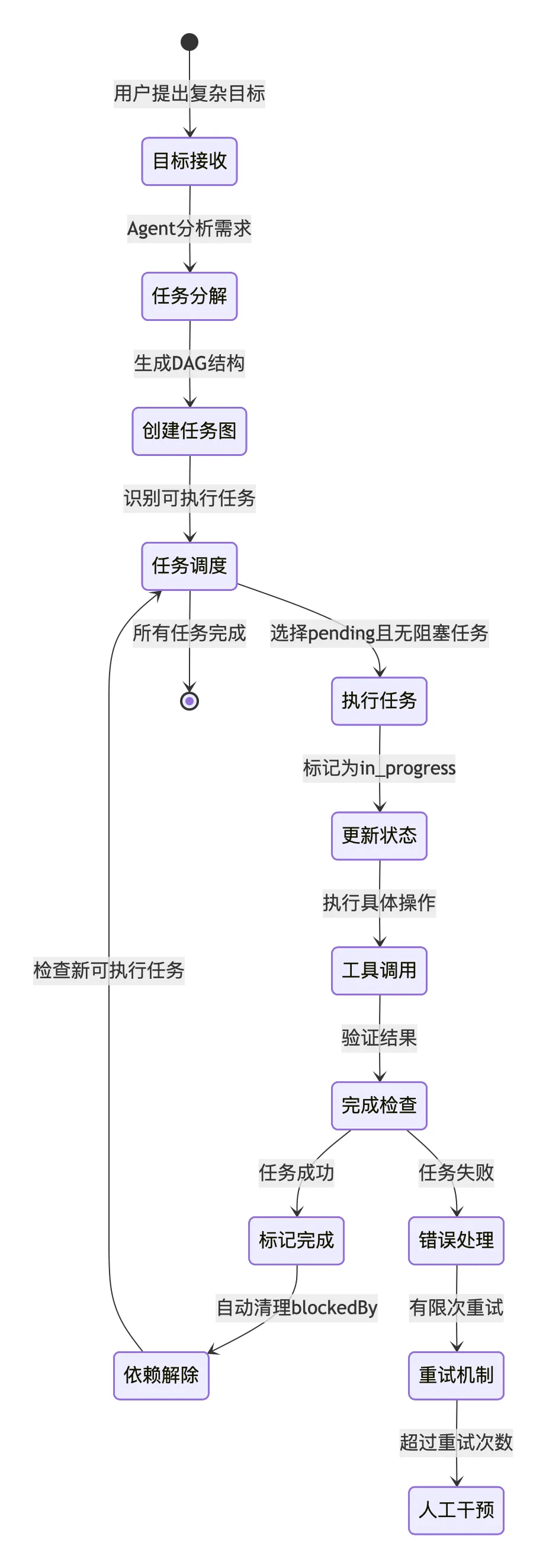
六、总结
learn-claude-code 项目的任务规划工作流体现了从简单到复杂的渐进式设计:
- s03 TodoWrite:提供基础的待办清单管理,解决"注意力漂移"问题
- s07 Task System:升级为持久化任务图,支持依赖管理和并行执行
- 完整工作流:目标分解 → 任务创建 → 依赖分析 → 调度执行 → 状态更新 → 依赖解除
这种设计使得Agent能够处理复杂的多步骤任务,同时保持上下文清晰、状态持久化,为后续的多Agent协作和长期任务管理奠定了基础。
通过运行提供的示例,可以验证任务规划系统如何将复杂目标分解为可执行的任务序列,并按照依赖关系有序执行,最终完成整体目标。
备注:
在调试过程中,发现该开源项目支持的是Anthropic兼容格式的api(https://api.deepseek.com/anthropic)
而DeepSeek官方提供的api格式为(https://api.deepseek.com/chat/completions),直接调用DeepSeek-V3.2模型无法调通,所以让AI帮忙写了一个适配器,
python
#!/usr/bin/env python3
"""
Model Adapter - 统一模型接口,支持 Anthropic 和 OpenAI/DeepSeek
"""
import os
from abc import ABC, abstractmethod
from typing import List, Dict, Any, Optional
from dataclasses import dataclass
@dataclass
class ToolCall:
"""统一工具调用格式"""
id: str
name: str
input: Dict[str, Any]
@dataclass
class ModelResponse:
"""统一模型响应格式"""
content: List[Any]
stop_reason: Optional[str]
text: Optional[str] = None
class BaseModelClient(ABC):
"""模型客户端抽象基类"""
@abstractmethod
def create_message(self, model: str, system: str, messages: List[Dict],
tools: List[Dict], max_tokens: int = 8000) -> ModelResponse:
pass
@abstractmethod
def format_tool_result(self, tool_use_id: str, content: str) -> Dict:
pass
class AnthropicClient(BaseModelClient):
"""Anthropic 客户端适配器"""
def __init__(self, api_key: str, base_url: Optional[str] = None):
from anthropic import Anthropic
self.client = Anthropic(api_key=api_key, base_url=base_url)
def create_message(self, model: str, system: str, messages: List[Dict],
tools: List[Dict], max_tokens: int = 8000) -> ModelResponse:
response = self.client.messages.create(
model=model,
system=system,
messages=messages,
tools=tools,
max_tokens=max_tokens
)
# 提取文本内容
text = None
for block in response.content:
if hasattr(block, 'text'):
text = block.text
break
return ModelResponse(
content=response.content,
stop_reason=response.stop_reason,
text=text
)
def format_tool_result(self, tool_use_id: str, content: str) -> Dict:
return {
"type": "tool_result",
"tool_use_id": tool_use_id,
"content": content
}
class OpenAIClient(BaseModelClient):
"""OpenAI/DeepSeek 客户端适配器"""
def __init__(self, api_key: str, base_url: Optional[str] = None):
from openai import OpenAI
# 为 DeepSeek 确保 base_url 正确
if base_url and "deepseek.com" in base_url and not base_url.endswith("/v1"):
base_url = base_url.rstrip("/") + "/v1"
self.client = OpenAI(api_key=api_key, base_url=base_url)
def _convert_tools_to_openai(self, tools: List[Dict]) -> List[Dict]:
"""将 Anthropic 格式工具转换为 OpenAI 格式"""
openai_tools = []
for tool in tools:
openai_tools.append({
"type": "function",
"function": {
"name": tool["name"],
"description": tool["description"],
"parameters": tool["input_schema"]
}
})
return openai_tools
def _convert_messages_to_openai(self, messages: List[Dict]) -> List[Dict]:
"""将 Anthropic 格式消息转换为 OpenAI 格式"""
openai_messages = []
for msg in messages:
role = msg["role"]
content = msg["content"]
if isinstance(content, list):
# 处理复杂内容
text_content = []
tool_calls = []
tool_results = []
for item in content:
if isinstance(item, dict):
if item.get("type") == "text":
text_content.append(item.get("text", ""))
elif item.get("type") == "tool_use":
# 收集工具调用
tool_calls.append({
"id": item["id"],
"type": "function",
"function": {
"name": item["name"],
"arguments": item.get("input", "{}")
}
})
elif item.get("type") == "tool_result":
# 收集工具结果
tool_results.append({
"tool_use_id": item["tool_use_id"],
"content": item["content"]
})
if role == "assistant":
# 处理 assistant 消息
assistant_msg = {"role": "assistant"}
if text_content:
assistant_msg["content"] = "\n".join(text_content)
else:
assistant_msg["content"] = None
if tool_calls:
# 将 JSON input 转换为字符串
import json
for tc in tool_calls:
if isinstance(tc["function"]["arguments"], dict):
tc["function"]["arguments"] = json.dumps(tc["function"]["arguments"])
assistant_msg["tool_calls"] = tool_calls
openai_messages.append(assistant_msg)
elif role == "user" and tool_results:
# 处理用户消息中的工具结果
# OpenAI 需要每个工具结果作为独立消息
for result in tool_results:
openai_messages.append({
"role": "tool",
"tool_call_id": result["tool_use_id"],
"content": result["content"]
})
# 如果还有文本内容,添加为用户消息
if text_content:
openai_messages.append({
"role": "user",
"content": "\n".join(text_content)
})
else:
# 普通用户消息
if text_content:
openai_messages.append({
"role": role,
"content": "\n".join(text_content)
})
else:
# 简单内容
openai_messages.append({
"role": role,
"content": content
})
return openai_messages
def create_message(self, model: str, system: str, messages: List[Dict],
tools: List[Dict], max_tokens: int = 8000) -> ModelResponse:
# 转换工具格式
openai_tools = self._convert_tools_to_openai(tools)
# 转换消息格式
openai_messages = [{"role": "system", "content": system}]
openai_messages.extend(self._convert_messages_to_openai(messages))
response = self.client.chat.completions.create(
model=model,
messages=openai_messages,
tools=openai_tools if tools else None,
max_tokens=max_tokens
)
message = response.choices[0].message
content = []
# 处理文本内容
if message.content:
content.append({"type": "text", "text": message.content})
# 处理工具调用
if message.tool_calls:
for tool_call in message.tool_calls:
import json
content.append({
"type": "tool_use",
"id": tool_call.id,
"name": tool_call.function.name,
"input": json.loads(tool_call.function.arguments)
})
stop_reason = "tool_use" if message.tool_calls else "end_turn"
return ModelResponse(
content=content,
stop_reason=stop_reason,
text=message.content
)
def format_tool_result(self, tool_use_id: str, content: str) -> Dict:
return {
"type": "tool_result",
"tool_use_id": tool_use_id,
"content": content
}
def create_model_client() -> BaseModelClient:
"""工厂函数:根据环境变量创建对应的模型客户端"""
provider = os.getenv("MODEL_PROVIDER", "").lower()
# 检查可用的API密钥
has_anthropic_key = bool(os.getenv("ANTHROPIC_API_KEY"))
has_openai_key = bool(os.getenv("OPENAI_API_KEY"))
has_deepseek_key = bool(os.getenv("DEEPSEEK_API_KEY"))
# 如果没有指定provider,根据可用的API密钥自动选择
if not provider:
if has_anthropic_key:
provider = "anthropic"
elif has_openai_key or has_deepseek_key:
provider = "openai" # 默认为openai,因为DeepSeek也使用OpenAI的接口
else:
raise ValueError("No API key found. Please set ANTHROPIC_API_KEY, OPENAI_API_KEY, or DEEPSEEK_API_KEY")
if provider == "anthropic":
api_key = os.getenv("ANTHROPIC_API_KEY")
base_url = os.getenv("ANTHROPIC_BASE_URL")
return AnthropicClient(api_key=api_key, base_url=base_url)
elif provider == "openai" or provider == "deepseek":
api_key_openai = os.getenv("OPENAI_API_KEY")
api_key_deepseek = os.getenv("DEEPSEEK_API_KEY")
base_url_openai = os.getenv("OPENAI_BASE_URL")
base_url_deepseek = os.getenv("DEEPSEEK_BASE_URL")
# 根据 provider 优先选择对应的环境变量
if provider == "deepseek":
api_key = api_key_deepseek or api_key_openai
base_url = base_url_deepseek or base_url_openai
else:
api_key = api_key_openai or api_key_deepseek
base_url = base_url_openai or base_url_deepseek
return OpenAIClient(api_key=api_key, base_url=base_url)
else:
raise ValueError(f"Unknown model provider: {provider}")