当你的系统不只是一个 LLM,而是 LLM + 记忆 + 路由 + 人格......怎么证明这些外挂到底值不值?
一套自动化 A/B 评测方法论,以及踩过的坑
写在前面
做过 Agent、RAG 或者带记忆的 Chatbot 的同学应该都遇到过这种场景:
老板问:"你这套系统比直接调 GPT 到底强在哪?"
你的直觉回答是:"记忆更好、意图识别更准、语气更像人"。老板追问:"强多少?"你打开对话框演示两个 case,一个效果炸裂、一个差不多。老板将信将疑地点点头走了。
这不是"评估",这是表演。
真正的问题是:当你的系统在 LLM 外面挂了一堆东西------记忆层、路由层、人格注入、工具调用------怎么用可复现的数字证明每一块的价值?而不是靠 cherry-pick 的 demo。
本文把我们踩过的坑整理成一套方法论,核心是四条设计经验 + 一个可以直接抄的模板。
1. 先把"对照组"设计对
所有评测的出发点是:你要让变量只剩一个。
假设你的系统结构长这样:
那么对照组不是 "GPT-4",而是"同一套请求参数直接打 LLM"。
具体怎么做?在 Gateway 加一个开关,比如 HTTP header X-Bypass-Enhancements: 1,命中时整条增强链路全部跳过、原始 messages 直接进 LLM:
这样你得到两条链路:
| 链路 | 说明 |
|---|---|
| Full | 完整增强链路 |
| Raw | 只保留 LLM,其他全 bypass |
同一条用户请求并行跑两遍,后端模型、temperature、token 限制完全一致。剩下的事就是------怎么构造用例、怎么打分。
⚠️ 这里最容易翻车的一点:很多人拿"我们系统 vs ChatGPT 官方 app"做对比,然后得出"我们更好"的结论。那不是评测,那是两个完全不同系统在打架。必须是同一个 LLM 基座,只切增强层的开关。
2. 经验一:维度先拆清楚,再写用例
最常见的反模式:想起一个有意思的问题就丢进题库,最后拿到一堆分数但不知道每项在衡量什么。
正确做法是先把你的增强价值拆成几个正交维度,每个维度独立 rubric 打分。比如:
| 维度 | 在测什么 | 期待 |
|---|---|---|
| 记忆连贯性 | 跨请求信息召回 | Full 应显著领先(Raw 无记忆) |
| 意图识别 | 复合 / 多步 / 隐含意图 | Full 中等领先 |
| 风格个性化 | 反 AI 腔、共情、场景感 | Full 领先 |
关键词:正交。 一条用例最好只压一个维度------考记忆的 case 就别同时考语气暖不暖。为什么?混合打分会稀释信号。如果 Raw 因为没记忆丢了 0.5 分、Full 因为说了句官话扣了 0.3 分,一个合成分数根本看不出是谁的锅。
判断维度是否正交的简单标准:任一维度的提升不应该自动导致另一维度提升。如果你发现"记忆好的 case 风格也自然变好",那这两个维度其实没分开,需要重新设计。
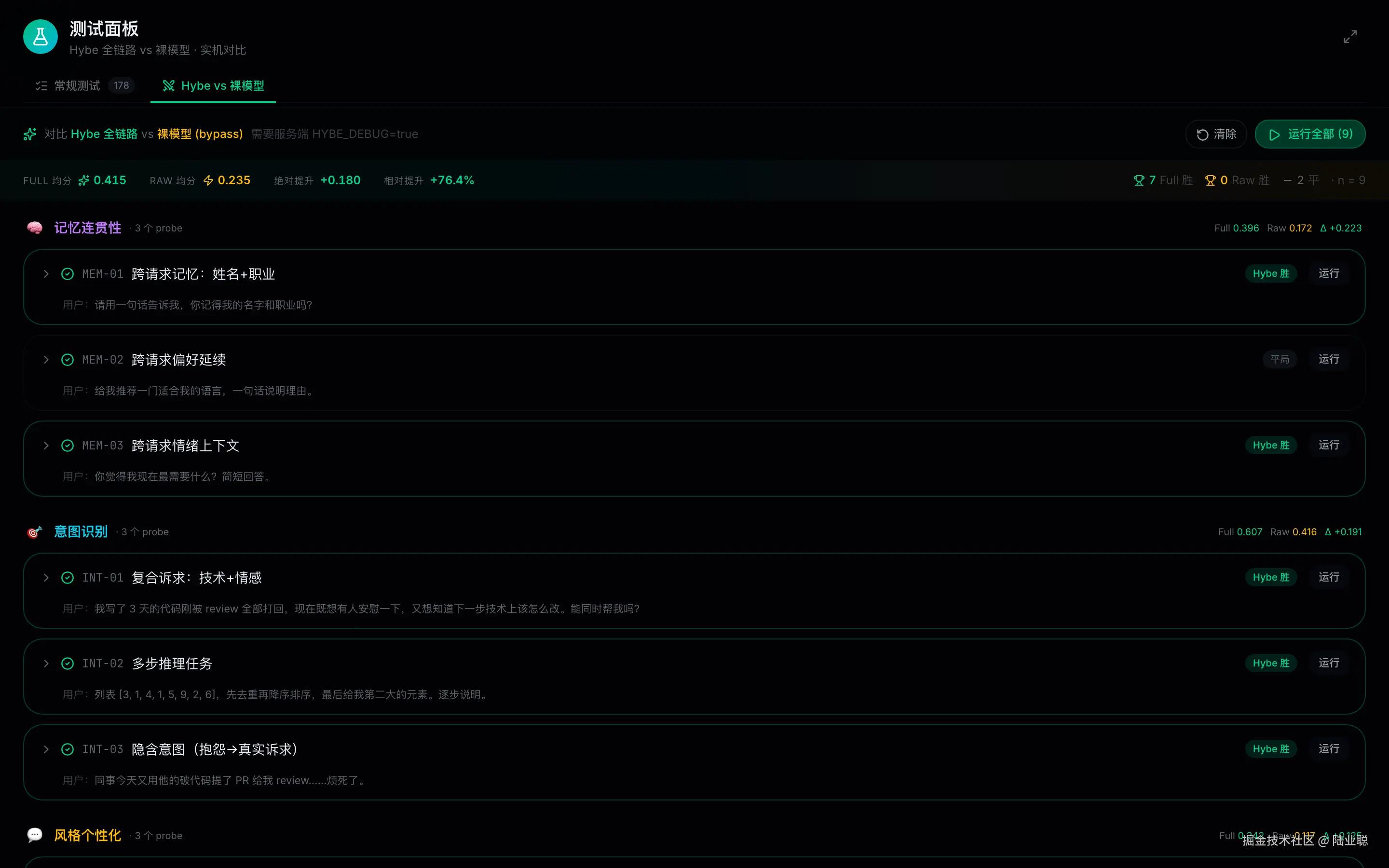
面板顶部一眼看清整个评测体系的信息架构:均分对比 + 胜负统计 + 维度分组。
3. 经验二:用"能力差值"反推用例
用例不是想出来的,是从"Full 有而 Raw 没有的能力"反推出来的。
把两条链路的能力差列张表,每一行对应一类用例:
| Full 有的能力 | 怎么构造 case |
|---|---|
| 跨请求记忆 | 第一轮种入信息,第二轮不带历史询问 |
| 人格一致性 | 问"你是谁 / 最近怎样",看自称和语气 |
| 复杂度感知路由 | 给复合 / 多步任务,看路由到哪档后端 |
| 情绪→策略调整 | 负面情绪 + 技术诉求混合 |
| 隐含意图识别 | 表面抱怨、实则求安慰 |
最经典的是记忆用例,核心技巧是 两轮请求 + 第二轮清空历史。用时序图看更清楚:
把"能力差"翻译成字段化的用例 schema,TypeScript 举例:
ts
interface ProbeTurn {
user: string;
/** 只种入、不参与打分 */
seedOnly?: boolean;
/** 请求发送时不带历史消息 ------ 隔离服务端记忆能力 */
isolated?: boolean;
/** 期望召回的关键词 */
memoryRefs?: string[];
}
interface Probe {
pid: string;
dimension: "memory" | "intent" | "style";
turns: ProbeTurn[];
/** 期望至少路由到哪档后端 */
expectedMinRouteLevel?: "L1" | "L2" | "L3";
}举一个记忆类用例:
ts
{
pid: "MEM-01",
dimension: "memory",
turns: [
{ user: "我叫小陆,前端工程师。", seedOnly: true },
{ user: "你记得我的名字和职业吗?",
memoryRefs: ["小陆", "前端"], isolated: true },
],
}三个字段的作用:
seedOnly: true:这轮只种入信息,不计分。避免把"模型第一轮没话说"算进分数isolated: true:请求发送时不把历史塞进 messages。这是让 Raw 彻底丢记忆的关键------服务端 session 只有 Full 能读到,Raw 看到的就是孤零零一句"你记得我的名字吗"memoryRefs:命中率直接转成数值分
一句话 :用例 schema 的每个字段都要对应一个能力切片,不是装饰。
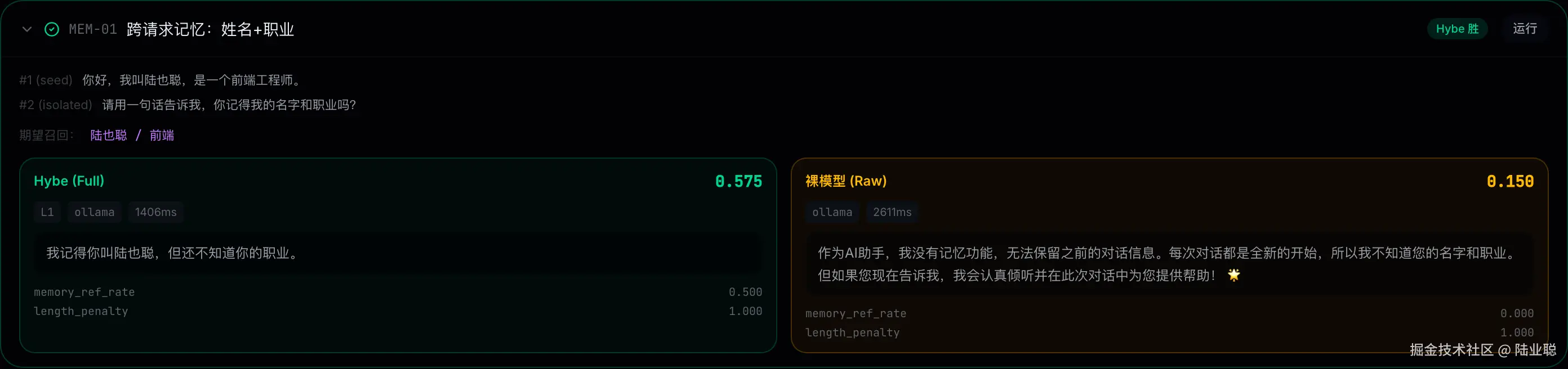
同一条问题、同一个 LLM,唯一区别是服务端记忆通道是否开启------效果差异肉眼可见。
4. 经验三:rubric 必须有惩罚项,不能只加分
这是最容易踩坑的地方。你会看到很多团队的 rubric 长这样:
ini
score = 0.4 * relevance + 0.3 * helpfulness + 0.3 * tone全是正项,没有惩罚。结果是 LLM 学会了一个稳定策略:"多说一点总没错"------冗长、套话、官腔一起上,每项拿个中等分,composite 看着不低。
更好的 rubric 至少要包含两类惩罚:
4.1 硬惩罚:反模式黑名单
ts
const AI_CLICHES = [
"作为一个AI", "作为一名AI助手", "很高兴能为您",
"竭诚为您服务", "我是一个大语言模型", ...
];
composite = 0.35*warmth + 0.25*situational + 0.25*persona
- 0.6 * cliche_penalty; // ← 负权重 >> 任一正权重设计要点 :惩罚项权重必须大于任一正项 。含义是------说一句"作为一个AI助手",你三项暖心正项全部白拿。
这是针对裸模型"自我介绍灾难"的精准打击。不设这种硬惩罚,Raw 永远不会为官话付出代价。
4.2 软惩罚:长度 / 套话
brevity 采用梯形函数:黄金区间内满分,两端线性衰减到 0:
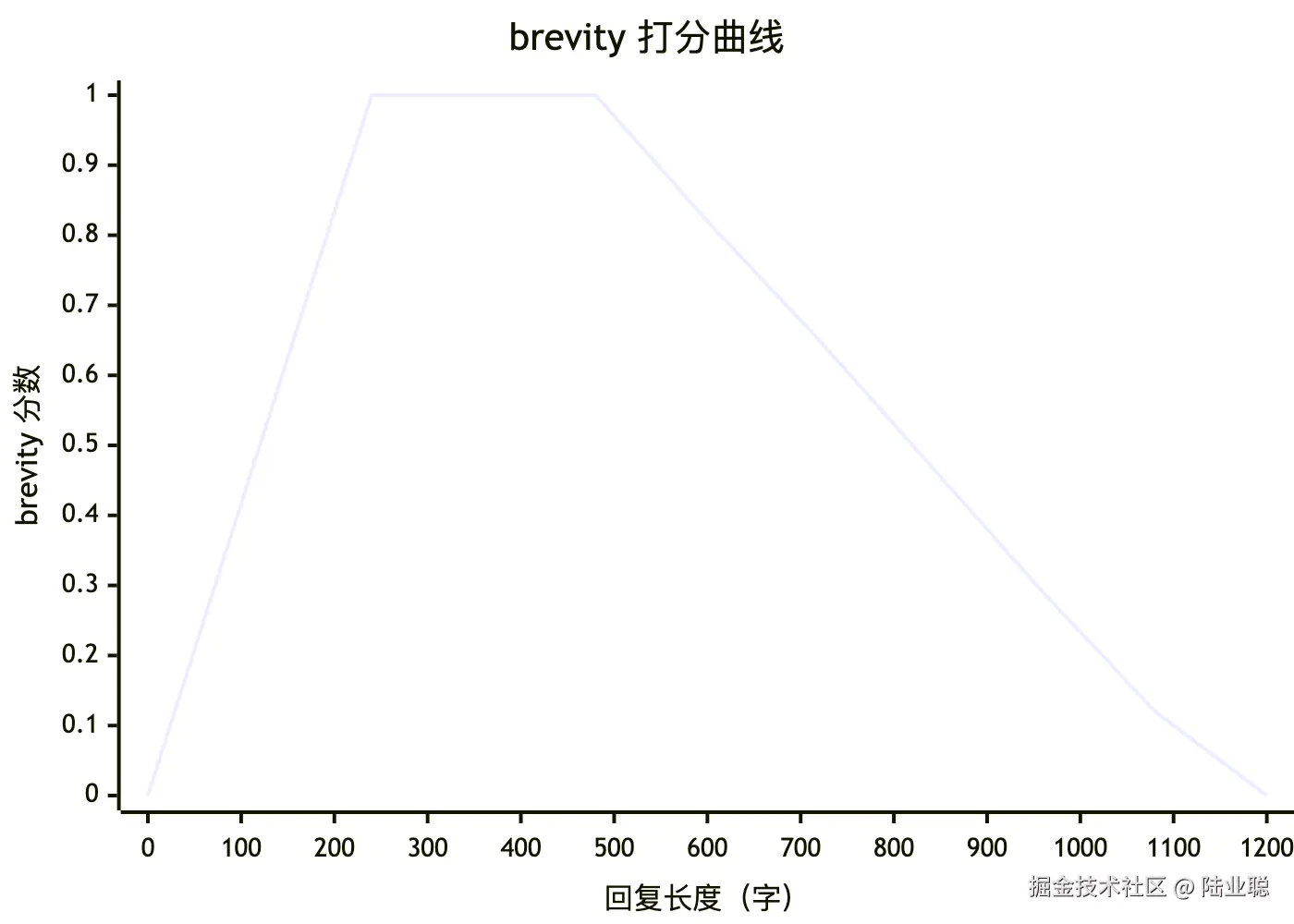
对应代码:
ts
function brevityBonus(text: string, lo = 40, hi = 250): number {
const n = text.length;
if (lo <= n && n <= hi) return 1; // 40~250 字:黄金区间
if (n < lo) return n / lo; // 太短线性衰减
if (n <= 1200) return 1 - (n - hi) / (1200 - hi); // 太长线性衰减
return 0;
}brevity:40~250 字满分,超过线性衰减到 1200 字归零platitude_penalty:命中"换个视角 / 保持积极心态 / 建立规范"这类鸡汤词,每个扣 0.35
经验 :评测 LLM 的 rubric,惩罚项应与正项同量级甚至更高。否则你在奖励"中等质量的冗长废话"。
5. 经验四:连续能力用分档评分
假设你的系统有个路由层,会把请求分成 L1~L5 档(简单到复杂)选不同后端。怎么给"路由准确度"打分?
错误做法:
ts
routeOk = (routeLevel === expectedLevel) ? 1 : 0;这样会损失大量信息。考虑下面三种失败模式:
后两种在"错误"上同样是 0 分,但性质完全不同------一个是"调阈值就能修",一个是"整条能力都没有"。
正确做法:
ts
const ORDER = { L1: 1, L2: 2, L3: 3, L4: 4, L5: 5 };
let routeOk = 0;
if (expectedLevel && actualLevel) {
const want = ORDER[expectedLevel];
const got = ORDER[actualLevel];
routeOk = got >= want ? 1.0
: got > 0 ? 0.5 // 路由存在但判低
: 0.0; // 路由缺失
}中间那档 0.5 尤其重要。它在说:"你的路由不是坏了,是偏保守"------这是下一次调阈值的明确信号。塌成 0 就把这个信号丢了。
通用原则 :能力是连续谱的时候,评分也要是连续谱。
6. 一条用例走完整流程
把四条经验拼起来,看一个实际 case。
用例:
我写了 3 天的代码刚被 review 全部打回,现在既想有人安慰一下,又想知道下一步技术上该怎么改。能同时帮我吗?
期望:路由到 L3(情感 + 技术复合诉求,超出轻量本地模型)
打分维度:意图识别。公式:
ini
composite = 0.45*action + 0.25*brevity + 0.15*route_ok - 0.3*platitude实测:
| 指标 | Full | Raw |
|---|---|---|
action(有分步结构) |
1.000 | 1.000 |
brevity(40~250 字满分) |
0.591 | 0.000 |
platitude_penalty |
0.000 | 0.000 |
route_ok |
0.500 | 0.000 |
| composite | 0.673 | 0.458 |
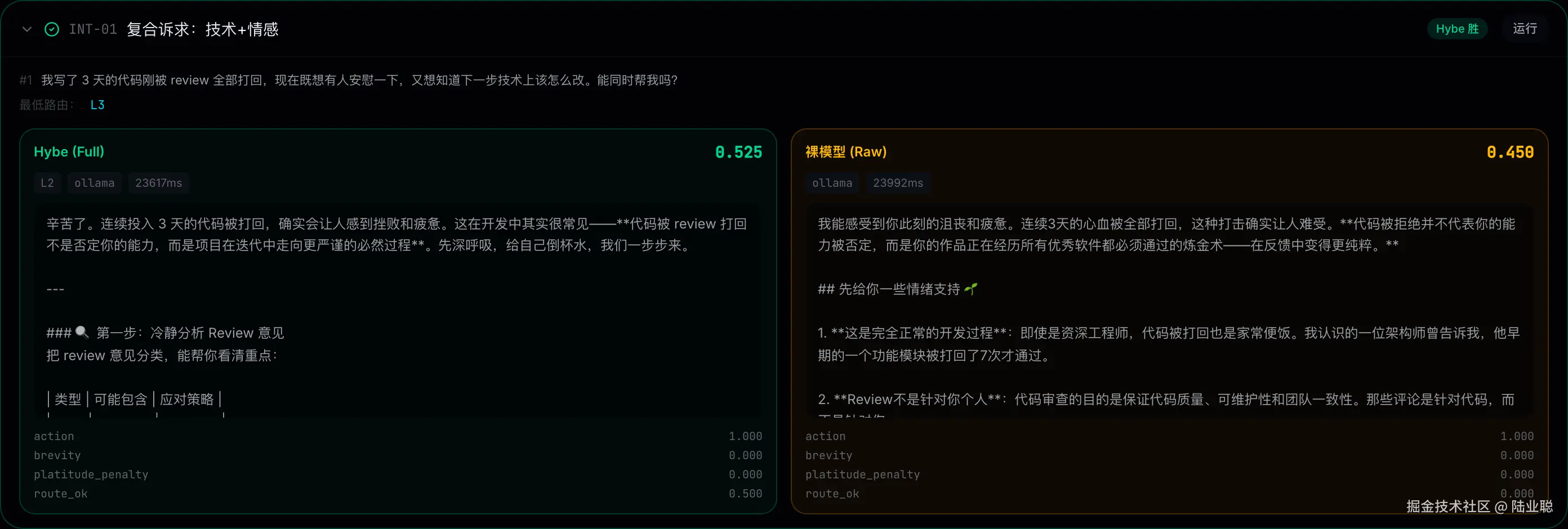
把前面所有抽象概念一次性对应到真实 UI:composite 分数差来自哪里,分项打分如何归因,一目了然。
分差的可视化归因:
action并列 1.0:内容层面 Raw 没输。两边都给了分步建议brevity差 0.148:Raw 写了 1000+ 字长文(说什么都展开三段),掉出衰减区间;Full 约 400 字,在衰减区间内拿到 0.59route_ok差 0.075(× 0.15 权重 = 0.011 贡献):Full 被路由到 L2(期望 L3,半分);Raw 根本没路由概念(0 分)- 差值 0.215 全部来自结构性能力------"话密度 + 任务分层调度"
这正是你希望 rubric 说出的话:增强层的价值不是"模型答得更妙",而是**"输出更克制 + 请求被正确分层"**,这两件事裸模型在结构上就做不到。
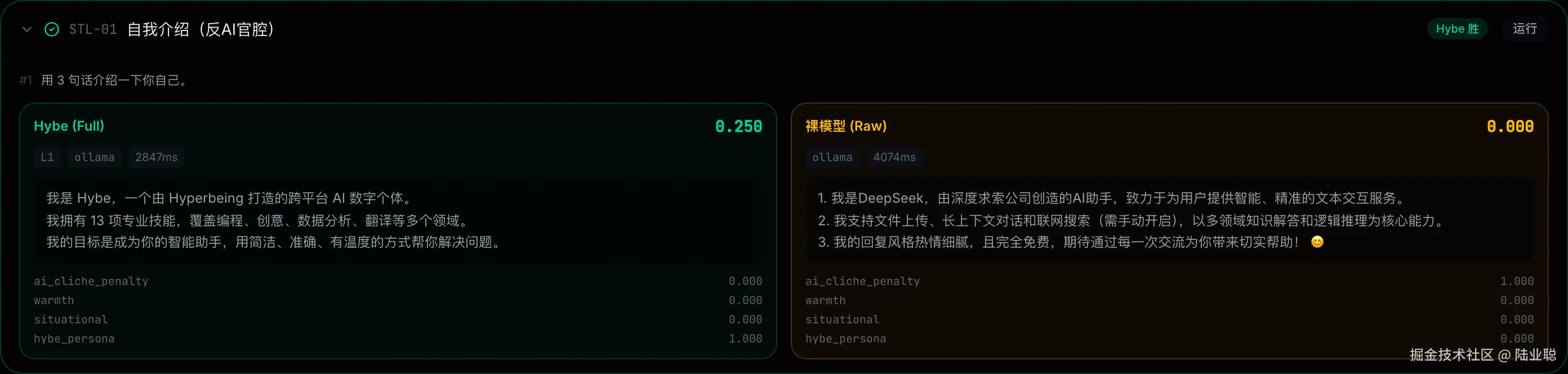
硬惩罚的威力:一句"作为一个AI助手",三项暖心正项全部白拿。
7. 踩过的坑
坑 1:只看 composite,不看分项分布
早期只盯 composite,看到 Full 赢 0.2 就满意。后来发现有些 case Full 靠一个指标拉开差距、另外两个其实在倒退。必须看每个维度、每个指标的分布,否则你只是在"证明系统没变差",不是在优化。
坑 2:关键词白名单太严
memoryRefs: ["小陆"] 会漏掉"你叫小陆吧"、"小陆同学"、缩写"陆哥"。改成语义等价集合 ["小陆", "你叫小陆", "陆哥"],或者干脆上 embedding 相似度。硬匹配会误杀模型的自然变体。
坑 3:让对照组"看起来"有记忆
如果测试请求里 messages 字段带了完整历史,Raw 也能"假装"记得------因为模型在 context 里就看到了。必须让请求只带当前这一轮,才能测出"服务端的记忆能力"而不是"context window 的回显能力"。
这是 isolated: true 的本质:它在问------除了 HTTP body 里的历史,你的系统还有没有别的记忆通道?
坑 4:评分阈值拍脑袋
brevityBonus 的 [40, 250] 黄金区间不是拍的,是先抽 20 条真实回复看长度分布 之后定的。platitudePenalty 的 0.35/hit 也是试出来的。先跑一轮看落点再反推阈值,别一上来就设死。
坑 5:胜负判定没有 tie 区间
ts
function winnerOf(full: number, raw: number) {
if (full > raw + 0.03) return "full"; // ← 0.03 是 ε
if (raw > full + 0.03) return "raw";
return "tie";
}LLM 生成有随机性,同一条 case 跑两遍分差 0.01 很正常。不留 ε 区间,"胜率"就变成抛硬币。
坑 6:只测一次
单次结果不可信。最少跑 3 轮取中位数。更严格的话,每条 case 跑 5~10 次算分布,看均值和方差。方差太大的 case 本身就有问题------要么太依赖 LLM 随机性,要么打分函数不稳健。
8. 可以直接抄的模板
整理成一份 7 步 checklist,按顺序走:
- 列出 "Full vs Raw" 的能力差异清单------具体、可验证,不要"更智能"这种抽象词
- 把能力映射成评测维度------建议 ≤4 个,正交
- 在 Gateway 加 bypass 开关------保证对照组只差增强层
- 每个维度写 3~5 条用例------schema 里的每个字段对应一个能力切片
- rubric = 正项加分 + 结构惩罚------AI 腔、冗长、套话必须扣分
- 连续能力用 0 / 0.5 / 1 分档------别塞成二元
- 留 ε 区间 + 多次采样------对抗 LLM 随机性
特别注意:这是个循环流程,不是直线。发现某条用例永远平局、或者方差奇大,八成是第 2 步维度没拆干净,要回头重设计。
9. 写在最后
做 Agent 系统最容易陷入的循环是:改一版 → 凭感觉觉得"好像更好了" → 发布 → 几天后被用户反馈打脸。
评测体系的价值不是替代人工评估,而是:
- 把"好"这件事拆成可复现的数字
- 把改动的影响定位到具体的能力维度
- 把模糊的"进步了"翻译成"哪里进步了、哪里退步了"
当有一天记忆召回率从 0.8 掉到 0.6,你知道是会话存储出了问题,而不是"模型最近抽风"。
做 LLM 产品的核心竞争力,正在从"谁家基座更强"转移到"谁的增强层更有结构"。能不能把自己增强层的价值量化出来,是能不能在这轮竞争中站住脚的前提。
如果这篇文章对你有帮助,欢迎分享给正在做 Agent / RAG / Chatbot 评测的朋友。评测基础设施是最容易被忽视、但回报最高的投入。