系列文章目录
B站视频内容智能分析系统(一):项目介绍与架构设计
文章目录
- 系列文章目录
- 前言
- 一、项目背景
- 二、系统全景
- 三、技术选型
- [1. 为什么选 DuckDB 而不是 MySQL](#1. 为什么选 DuckDB 而不是 MySQL)
- [2. 为什么选 ChromaDB 做向量存储](#2. 为什么选 ChromaDB 做向量存储)
- [3. LLM 选型:MiniMax + DeepSeek 双模型](#3. LLM 选型:MiniMax + DeepSeek 双模型)
- [4. 语音转写:faster-whisper + 云 ASR](#4. 语音转写:faster-whisper + 云 ASR)
- 四、数据流:从视频到问答
- [1. 数据采集链路(写入)](#1. 数据采集链路(写入))
- [2. 数据查询链路(读取)](#2. 数据查询链路(读取))
- [3. 三种查询模式](#3. 三种查询模式)
- 五、统一数据层
- [1. DuckDB 表结构](#1. DuckDB 表结构)
- [2. ChromaDB 向量存储](#2. ChromaDB 向量存储)
- 六、部署架构
- [1. 双环境策略](#1. 双环境策略)
- [2. 容器编排](#2. 容器编排)
- 七、最终效果展示
- 总结
前言
关注B站的朋友应该都有这种感觉------好的情感博主太多了,每个博主几百个视频,根本看不完。有时候想查一下"某个博主对冷暴力怎么看",或者"关于吵架后怎么和好有什么建议",只能一个一个视频去翻,效率极低。
作为一个程序员,我的第一反应就是:能不能搭一个系统,自动把这些视频内容变成可以搜索、可以问答的知识库?
于是就有了这个项目------B站视频内容智能分析系统。它能自动下载博主的视频,转写成文字,用大模型精炼总结,然后存入数据库。最后提供一个统一的问答入口,你可以用自然语言提问,系统自动帮你找到答案。
这个项目我断断续续做了好几个月,踩了不少坑,也有一些有意思的设计,打算写一个系列博客把它完整记录下来。这是第一篇,先讲讲整体架构和技术选型。
GitHub 地址:https://github.com/chaoge615-afk/content-analysis-system
一、项目背景
先说说为什么要做这个系统。
我关注了好几个B站的情感类博主,像"桃姐"、"安佳"之类的,每个博主都有几百个视频。这些视频里其实有很多实用的恋爱建议和人际关系技巧,但问题是:
- 视频太长了:一个 20 分钟的视频,你不可能每次都看完
- 内容分散:同一个话题(比如"吵架后怎么和好")可能分散在十几个博主的视频里
- 无法搜索:视频内容不像文章可以 Ctrl+F,想找特定建议只能凭记忆
我需要的其实是一个视频内容的知识检索系统------把视频里的核心观点提取出来,变成可以搜索、可以提问的结构化知识。
截图:系统最终效果------自然语言问答界面,展示 SQL 查询和语义查询两种回答
二、系统全景
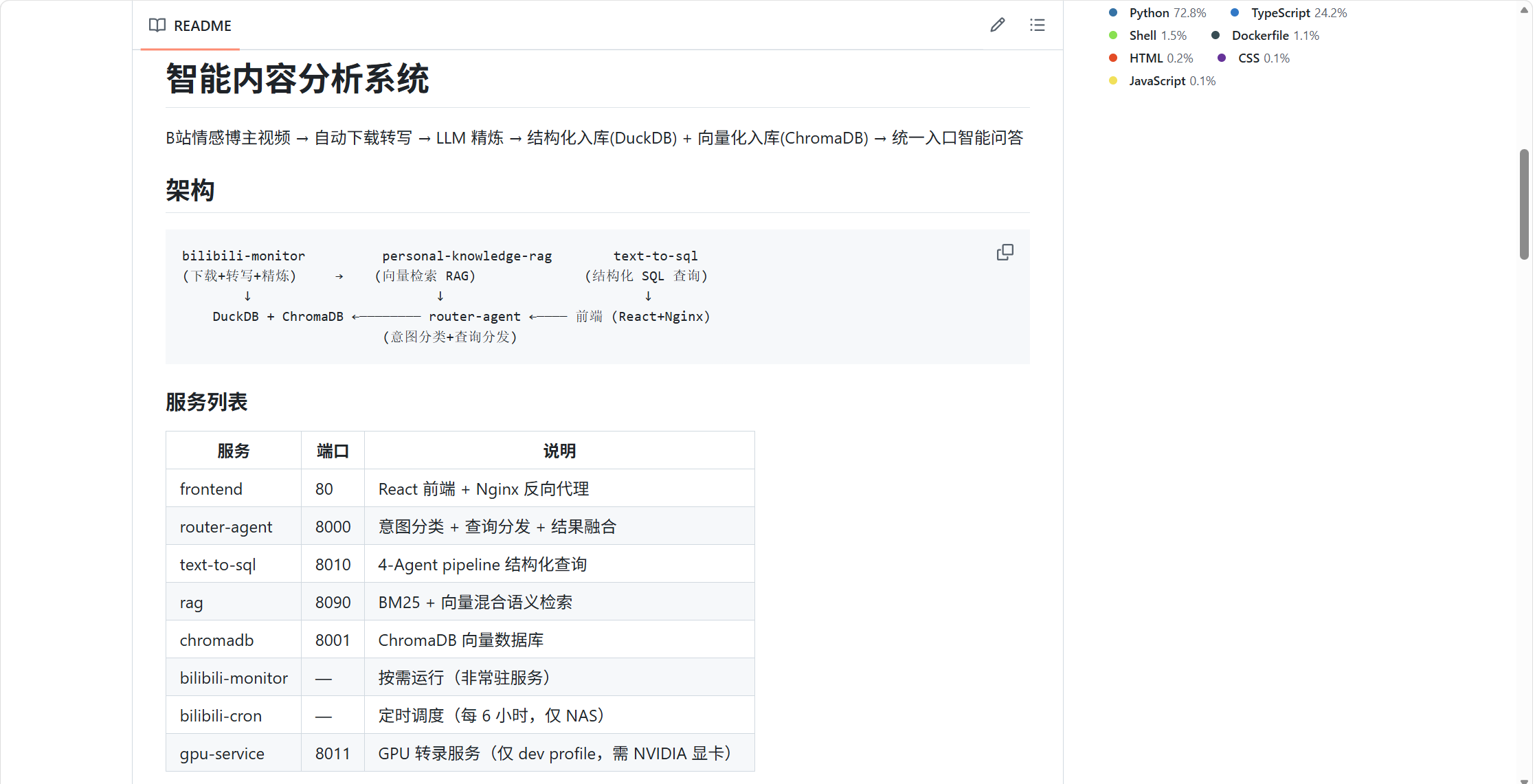
整个系统的核心链路可以用一句话概括:
B站情感博主视频 → 自动下载转写 → LLM 精炼 → 结构化入库 + 向量化入库 → 统一入口智能问答
画个架构图:
用户提问(自然语言)
↓
┌───────────────────────────────────────────────────────┐
│ 统一 Web 前端(React + Nginx :80) │
├───────────────────────────────────────────────────────┤
│ 路由 Agent(意图识别 + 查询分发 :8000) │
│ │
│ ┌─────────────┐ ┌──────────────┐ ┌───────────┐ │
│ │ Text-to-SQL │ │ RAG 知识库 │ │ B站监控 │ │
│ │ Pipeline │ │ System │ │ 采集 │ │
│ │ │ │ │ │ │ │
│ │ 4-Agent │ │ BM25+向量 │ │ 独立服务 │ │
│ │ 手写pipeline│ │ 混合检索 │ │ │ │
│ └──────┬──────┘ └──────┬───────┘ └─────┬─────┘ │
│ │ │ │ │
│ └────────┬────────┘ │ │
│ ↓ │ │
│ ┌────────────────┐ │ │
│ │ 统一数据层 │ ←──── 自动填充 ───┘ │
│ │ DuckDB+ChromaDB│ │
│ └────────────────┘ │
└───────────────────────────────────────────────────────┘整个系统由 5 个子项目 组成:
| 子项目 | 职责 | 端口 |
|---|---|---|
| bilibili-monitor | B站视频采集(下载+转写+精炼+入库) | 按需运行 |
| personal-knowledge-rag | RAG 语义检索(BM25+向量混合) | 8090 |
| text-to-sql | Text-to-SQL 结构化查询(4-Agent Pipeline) | 8010 |
| router-agent | 路由 Agent(意图分类+查询分发+结果融合) | 8000 |
| frontend | 统一前端(React 对话+管理面板) | 80 |
加上 ChromaDB 向量数据库和 GPU 转录服务,一共 7 个 Docker 容器,用 Docker Compose 统一编排。
截图:Docker 容器运行状态,7个容器全部 healthy
三、技术选型
1. 为什么选 DuckDB 而不是 MySQL
这是一个很多人会问的问题。我的数据量不大(几千个视频),用 MySQL 完全够,为什么选 DuckDB?
原因很简单:
- 零运维 :DuckDB 是一个嵌入式数据库,不需要单独启动服务,一个
.db文件搞定。对于个人项目来说,少一个服务就少一份运维负担。 - 分析型查询快 :我们的查询主要是
COUNT、GROUP BY、ORDER BY这类聚合分析,DuckDB 是列式存储,天然适合这种场景。 - SQL 兼容:DuckDB 的 SQL 语法和 PostgreSQL 高度兼容,LLM 生成 SQL 时几乎不会出错。
- 轻量:DuckDB 的 Python 包只有几 MB,不像 MySQL 那样需要单独跑一个几百 MB 的 Docker 容器。
对于 Text-to-SQL 这种场景,LLM 生成的 SQL 需要快速执行并返回结果,DuckDB 的嵌入式特性让这一步非常丝滑。
2. 为什么选 ChromaDB 做向量存储
向量数据库有很多选择:Milvus、Qdrant、Weaviate、FAISS......
我选 ChromaDB 的理由:
- 够用就好:我的文档块数量大概在 1000-5000 这个量级,ChromaDB 完全扛得住。
- Metadata 过滤:ChromaDB 支持在检索时按 metadata 过滤(比如只看某个博主的内容、只看某个分类),这对我们的场景非常重要。后面会详细讲。
- 持久化简单:ChromaDB 支持本地文件持久化,数据存在一个目录下就行,不需要单独部署服务(虽然项目里还是用 Docker 跑了一个,方便远程访问)。
- Python 原生:ChromaDB 的 Python SDK 非常好用,几十行代码就能跑起来。
3. LLM 选型:MiniMax + DeepSeek 双模型
这个项目用了两个 LLM,各有分工:
MiniMax M2.7(Anthropic API 兼容接口):
- 用于意图分类 和 SQL 生成
- 这个模型在结构化任务上表现很好,分类准确率高
- 支持 Prompt Caching,可以节省 90% 的 API 调用费用
DeepSeek V4 Flash(OpenAI API 兼容接口):
- 用于内容精炼 和 RAG 问答
- 便宜且快(比 V4 Pro 便宜一半,快 43%)
- 精炼效果够用,对视频内容的总结和分类都很准确
两个模型都兼容 OpenAI 的 API 格式,所以代码里切换模型只需要改 .env 里的配置,不需要改代码。
bash
# .env 中的 LLM 配置
CHAT_API_KEY=sk-xxx # MiniMax API Key
CHAT_BASE_URL=https://api.minimaxi.com/anthropic
CHAT_MODEL=MiniMax-M2.7
REFINE_API_URL=https://api.deepseek.com/v1/chat/completions
REFINE_API_KEY=sk-xxx # DeepSeek API Key
REFINE_MODEL=deepseek-v4-flash4. 语音转写:faster-whisper + 云 ASR
视频内容要变成文字,需要语音转写。我做了三级回退:
- GPU 转写(开发机):用 RTX 4060 + faster-whisper,一个 20 分钟的视频几秒钟就能转完
- 云 ASR(NAS):用硅基流动的 SenseVoiceSmall 模型,免费!但有月度预算控制
- CPU 转写(兜底):NAS 上没有 GPU,用 faster-whisper CPU 模式,一个视频大概 3-5 分钟
faster-whisper 相比原版 Whisper,用的是 CTranslate2 引擎,CPU 上快了 4 倍,内存占用也小了很多。这对我的 NAS(只有 8GB 内存)来说非常重要。
云 ASR 用的硅基流动 SenseVoiceSmall 模型是免费的,但我还是做了月度预算控制------万一哪天用的太多也不至于出问题。
四、数据流:从视频到问答
1. 数据采集链路(写入)
数据从视频到入库,经过 6 个步骤:
B站情感博主视频
↓
① WBI签名API → 拉取新视频列表
↓
② yt-dlp → 下载音频(m4a格式,比视频小很多)
↓
③ 语音转写(faster-whisper / 云ASR)→ 语音转文字
↓
④ DeepSeek API → 精炼生成三段式摘要
(核心观点 + 案例摘要 + 可行动建议)
↓
⑤ 分流写入:
├── DuckDB:结构化元数据(标题、UP主、分类、时长等)
└── ChromaDB:向量存储(转写全文 + 精炼摘要的 Embedding)
↓
⑥ QQ Bot 通知采集完成精炼的结果是一个三段式摘要,长这样:
核心观点:
- 女生不回消息时不要焦虑追问,可能原因包括忙碌、话题无趣或测试
- 最佳应对是冷静给予空间,过几小时再自然开启新话题
案例摘要:
- 博主分享了一个学员案例:连续发了20条消息追问,结果被拉黑
可行动建议:
- 保持情绪稳定,不要把所有注意力放在一个人身上
- 过 2-3 小时后用轻松话题重新开启对话除了摘要,LLM 还会自动从 31 个情感分类中选择一个最合适的(比如"恋爱技巧"、"分手挽回"、"情感心理"等),这个分类会写入 DuckDB 和 ChromaDB 的 metadata,后面查询时可以按分类过滤。
2. 数据查询链路(读取)
用户提问后,系统会自动判断走哪个通道:
用户问题
↓
路由Agent → MiniMax M2.7 意图分析
↓
┌─────────────────────────────────────┐
│ ① 结构化查询 → Text-to-SQL → DuckDB│
│ ② 语义查询 → RAG 检索 → LLM │
│ ③ 混合查询 → SQL + RAG 并行 │
└─────────────────────────────────────┘3. 三种查询模式
这个路由设计是我觉得最有意思的部分。
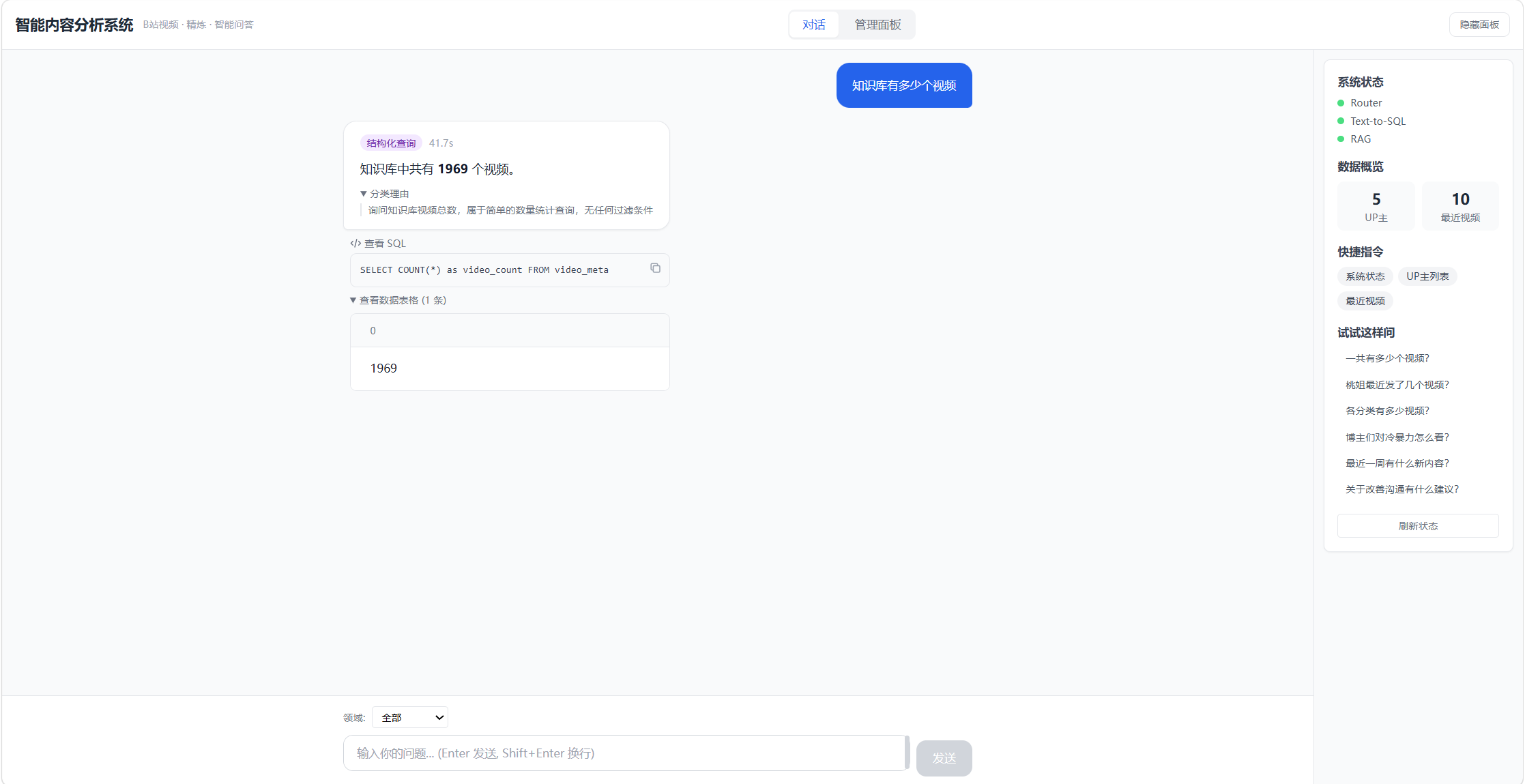
结构化查询(structured) :
涉及数量统计、时间排序、比较等,走 Text-to-SQL 通道。
问:"桃姐最近发了几个视频?"
→ SELECT COUNT(*) FROM video_meta WHERE up_name = '恋爱教头桃姐'
→ 结果:8个语义查询(semantic) :
涉及观点、建议、内容理解等,走 RAG 通道。先用 BM25+向量混合检索找到相关文档,再让 LLM 基于这些文档生成回答。
问:"博主们对冷暴力怎么看?"
→ BM25 检索关键词匹配的文档
→ 向量检索语义相似的文档
→ 混合排序 + metadata 过滤
→ LLM 基于检索结果生成回答,附带来源引用混合查询(hybrid) :
同时需要数据和内容理解,两个通道并行执行,最后 LLM 融合结果。
问:"桃姐最近聊了什么话题?她关于吵架的建议是什么?"
→ SQL 先查出桃姐最近的视频列表
→ RAG 在这些视频中检索吵架相关的内容
→ LLM 融合生成完整回答五、统一数据层
所有子项目共享同一个数据层,这是架构的核心。
1. DuckDB 表结构
DuckDB 里存的是结构化数据,主要三张表:
sql
-- video_meta:视频元数据
CREATE TABLE video_meta (
bvid TEXT PRIMARY KEY, -- 视频BV号
up_name TEXT, -- UP主名称
up_uid TEXT, -- UP主UID
title TEXT, -- 视频标题
publish_date DATE, -- 发布日期
category TEXT, -- 内容分类(31个情感分类)
duration INT, -- 时长(秒)
summary TEXT, -- LLM生成的三段式摘要
tags TEXT, -- 标签
created_at DATETIME -- 入库时间
);
-- up_info:UP主信息
CREATE TABLE up_info (
uid TEXT PRIMARY KEY,
name TEXT,
total_videos INT,
last_update DATE
);
-- query_log:查询日志
CREATE TABLE query_log (
id INT PRIMARY KEY,
question TEXT,
route_type TEXT, -- structured/semantic/hybrid
response_time FLOAT,
created_at DATETIME
);2. ChromaDB 向量存储
ChromaDB 里存的是向量化的文档内容,用于语义检索:
collection: "video_knowledge"
├── document: 转写全文 / 精炼摘要文本
├── embedding: BAAI/bge-large-zh-v1.5 向量(SiliconFlow API)
└── metadata:
├── source: 文件路径
├── bvid: 视频BV号
├── up_name: UP主名称
├── category: 内容分类
├── content_type: "full" / "summary" / "chunk"metadata 里存了 up_name 和 category,这样在检索时可以直接过滤,比如"只看桃姐的视频"或"只看分手挽回分类的内容"。
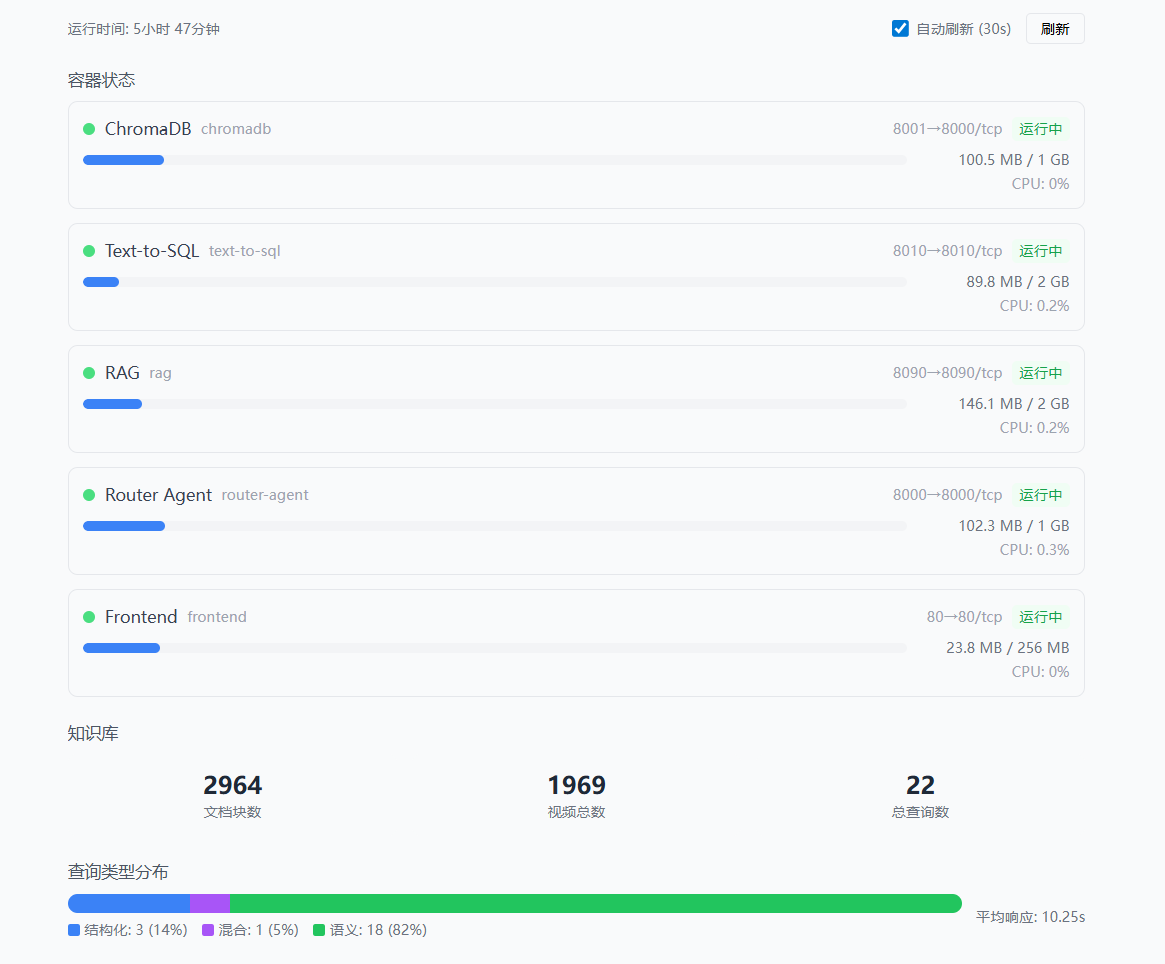
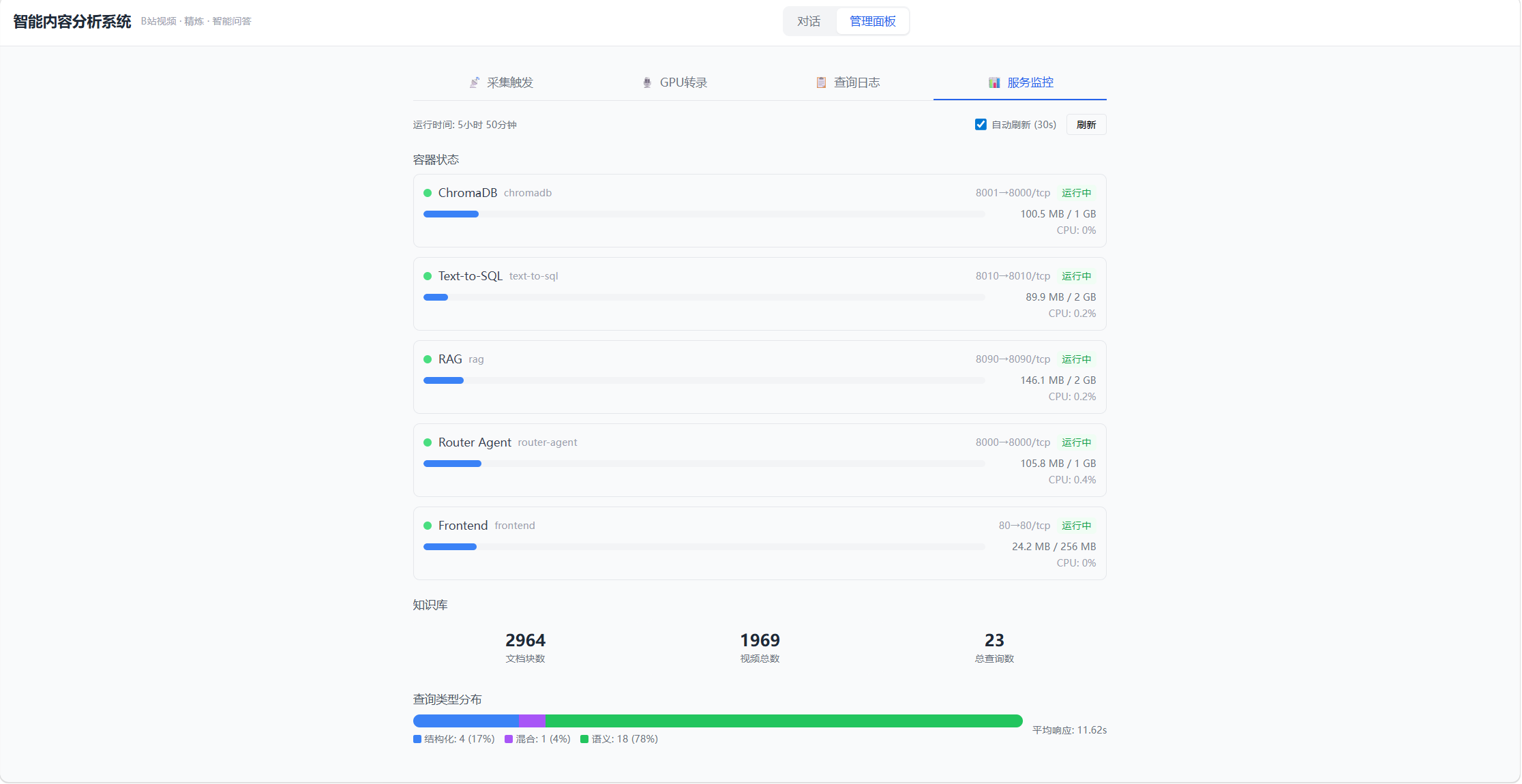
目前知识库里有 1148 个视频 ,1760 个文档块,分布在 31 个情感分类中。
六、部署架构
1. 双环境策略
这个项目我在两个环境上跑:
| 配置 | 本地电脑(开发) | NAS(生产) |
|---|---|---|
| CPU | AMD Ryzen 7 8845H | Intel N150 |
| 内存 | 24GB | DDR4 8G |
| GPU | NVIDIA RTX 4060(8GB显存) | 无 |
| 用途 | 开发调试 + GPU 转写 | 7×24 运行 + 定时采集 |
代码完全一致,环境差异全部走 .env 配置文件 + Docker profiles。下班后在本地开发,push 到 GitHub;上班时 NAS pull 下来部署。
bash
# 本地开发(含 GPU 转录服务)
docker compose --profile dev up -d
# NAS 生产(含定时调度)
docker compose --profile nas up -d2. 容器编排
7 个容器的内存分配(NAS 只有 8GB,每一兆都要精打细算):
| 容器 | 端口 | 内存限制 | 说明 |
|---|---|---|---|
| frontend | :80 | 256m | React + Nginx |
| router-agent | :8000 | 1g | 路由 Agent |
| text-to-sql | :8010 | 2g | SQL 生成 Pipeline |
| rag | :8090 | 2g | RAG 检索 |
| chromadb | :8001 | 1g | 向量数据库 |
| bilibili-monitor | --- | 4g | 按需运行,跑完退出 |
| bilibili-cron | --- | 128m | 每6小时触发采集 |
常驻服务大概 6.4G,bilibili-monitor 只在采集时启动,跑完自动退出释放内存。
七、最终效果展示
说了一堆架构,来看最终效果。
对话界面------支持自然语言问答和斜杠命令:
管理面板------可以手动触发采集、管理 Cookie、查看 GPU 状态:
服务监控------实时显示各容器的运行状态和资源使用:
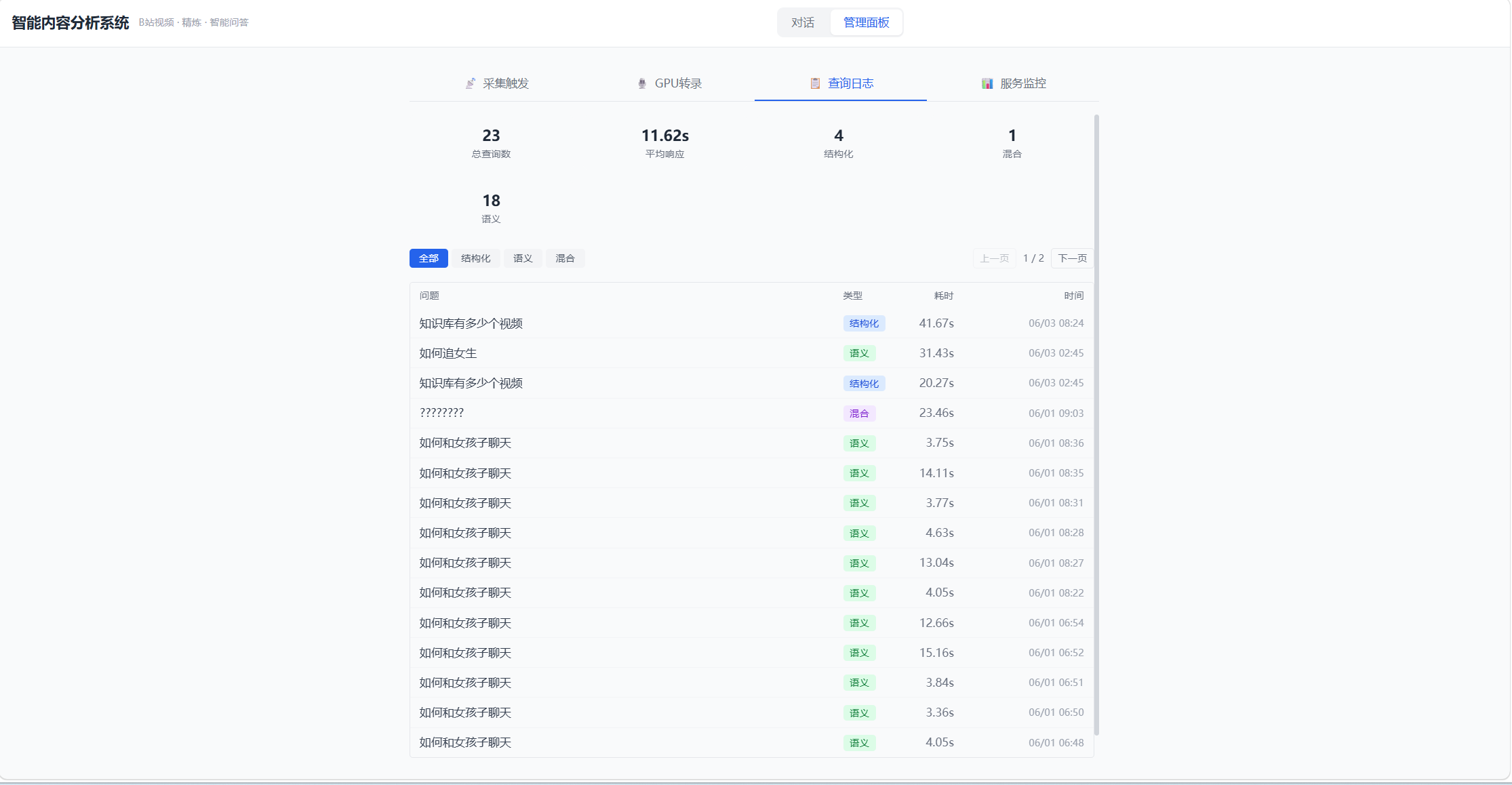
查询日志------记录所有历史查询,支持按路由类型过滤:
总结
这就是整个系统的全貌。从 B站视频采集到智能问答,涉及了 5 个子项目、7 个 Docker 容器、2 个 LLM、2 种数据库。后面会逐篇拆解每个子项目的实现细节,包括采集策略、转写方案、精炼 Prompt 设计、Text-to-SQL Pipeline、RAG 混合检索、路由 Agent 等等。下一篇先从 Docker Compose 部署开始讲。