第2章:基于内存的只读文件系统
本章实例:MemReadFS ------ 支持多文件多目录的内存只读文件系统 本文是基于FUSE文件系统的第2篇文章。本篇将引入目录的概念,也就是在我们实现的文件系统中,不仅仅有文件,还有目录。
在上一章中,我们实现了一个极简的 HelloFS,它只有一个硬编码的文件。虽然它展示了 FUSE3 的基本工作流程,但距离一个真正的文件系统还有很大差距:它不支持多级目录、不支持多个文件、所有内容都是字符串常量硬编码的。
本章将引入文件系统最核心的数据结构概念------inode,并用 C++ 的标准库容器在内存中构建一棵完整的文件目录树。我们将实现一个支持多级目录浏览和多文件读取的只读文件系统 MemReadFS。
2.1 文件系统的核心数据结构
inode:文件的"身份证"
在 UNIX/Linux 文件系统中,inode(index node,索引节点)是描述文件的核心数据结构。每个文件或目录都对应一个唯一的 inode,它存储了文件的所有元数据:
- 文件类型:普通文件、目录、符号链接等
- 权限:读/写/执行权限
- 所有者:uid 和 gid
- 大小:文件内容的字节数
- 时间戳:访问时间(atime)、修改时间(mtime)、状态变更时间(ctime)
- 链接数:有多少个目录项指向这个 inode
- 数据位置:文件内容存储在哪里
关键点在于:inode 不包含文件名。文件名存储在目录中------目录本质上就是一个"名字到 inode 编号"的映射表。这意味着同一个 inode 可以有多个名字(这就是硬链接的原理)。
以本文实现的文件系统为例, Inode 的定义如下(在 memreadfs.cpp 中):
cpp
#define ROOT_INO 1
struct Inode {
ino_t ino; /* inode 编号 */
mode_t mode; /* 文件类型和权限 */
uid_t uid; /* 所有者用户 ID */
gid_t gid; /* 所有者组 ID */
off_t size; /* 文件大小 */
time_t atime; /* 访问时间 */
time_t mtime; /* 修改时间 */
time_t ctime; /* 状态变更时间 */
nlink_t nlink; /* 硬链接数 */
std::string data; /* 文件内容(仅普通文件) */
std::map<std::string, ino_t> children; /* 子目录项(仅目录) */
};由于我们只是演示文件系统的原理,所以数据结构的设计可能没有那么紧凑,在数据结构设计上使用了标准库的数据结构,这样可以简化开发。
data字段只对普通文件有意义,存储文件的全部内容。目录的data为空children字段只对目录有意义,存储名字到 inode 编号的映射。普通文件的children为空std::map而非std::unordered_map:目录项需要有序遍历(ls按字母排序输出),std::map天然有序ROOT_INO = 1:根目录的 inode 编号固定为 1(0 通常保留表示"无效 inode")- 三个时间戳 :
atime(最后访问)、mtime(内容修改)、ctime(元数据变更),这是 POSIX 标准要求的。
目录项(dentry)
目录项描述了"名字 → inode"的对应关系。一个目录可以包含多个目录项,每个目录项将一个文件名映射到一个 inode 编号。我们给出一个具体的例子,比如下面这个目录结构:
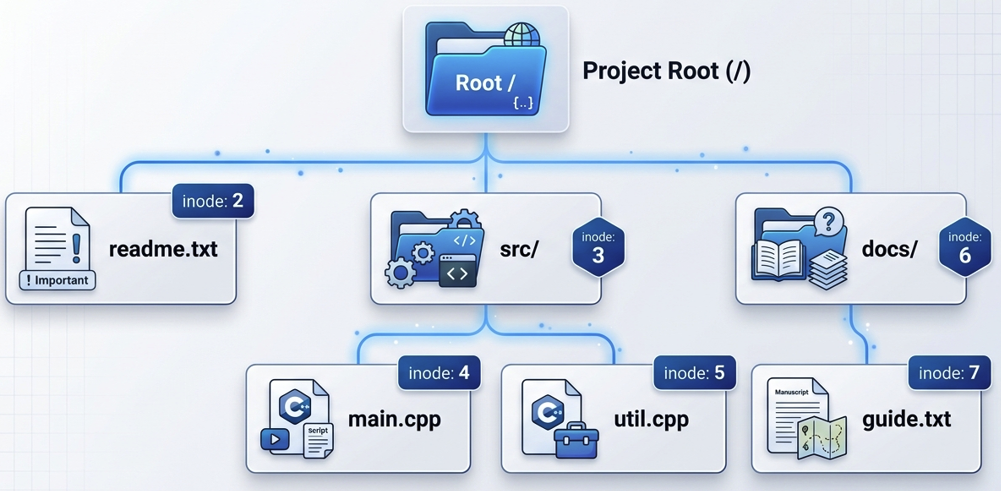
在这个文件系统中包含3个目录,4个文件。根目录(inode 1)包含1个文件和2个目录,其目录项表为:
| 文件名 | inode 编号 |
|---|---|
| readme.txt | 2 |
| src | 3 |
| docs | 6 |
src 目录(inode 3)包含2个源代码文件,其目录项表为:
| 文件名 | inode 编号 |
|---|---|
| main.cpp | 4 |
| util.cpp | 5 |
docs 目录(inode 6)包含一个文本文件,其目录项表为:
| 文件名 | inode 编号 |
|---|---|
| guide.txt | 7 |
2.2 构建内存文件树
了解了上述基本概念,接下来我们看看如何在内存中实现一个层级结构的文件系统。由于数据存储在内存中,在实现上能够方便很多,比如借助一些现有的数据结构,而不是把内存当成线性存储空间。
全局 inode 表
在《文件系统技术内幕》中我们介绍过Ext2文件系统的数据布局,知道在其中有一个inode表,inode在其中依次排开。在内存文件系统中,我们可以用一个全局的 std::unordered_map 来管理所有 inode,这样可以按需的分配内存,不会一下子使用太多内存,如下所示,我们通过两个变量来维护所有的inode信息:
cpp
static std::unordered_map<ino_t, Inode> inode_table;
static ino_t next_ino = 1; // inode 编号从 1 开始(0 通常保留)当然,我们也可以一次性的分配一大块内存,用于存储inode表,然后根据其偏移确定inode ID,这样实现会稍微复杂一些。
实例代码解析:make_inode 辅助函数
首先需要一个创建inode的功能,具体实现在memreadfs.cpp 中,该文件中提供了一个函数make_inode来简化 inode 创建:
cpp
static std::unordered_map<ino_t, Inode> inode_table;
static ino_t next_ino = ROOT_INO;
static ino_t make_inode(mode_t mode, const std::string &data = "") {
Inode inode;
inode.ino = next_ino++;
inode.mode = mode;
inode.uid = getuid();
inode.gid = getgid();
inode.nlink = S_ISDIR(mode) ? 2 : 1; // 目录初始 nlink=2,文件=1
inode.data = data;
inode.size = S_ISREG(mode) ? (off_t)data.size() : 0;
time_t now = time(nullptr);
inode.atime = now; inode.mtime = now; inode.ctime = now;
ino_t ino = inode.ino;
inode_table[ino] = std::move(inode); // 移动语义避免拷贝
return ino;
}
//在一个目录中添加一个项目,可以是子目录或者文件。我们这里使用了标准库的unordered_map容器,因此没有dentry的定义。
static void dir_add_child(ino_t parent_ino, const std::string &name, ino_t child_ino) {
inode_table[parent_ino].children[name] = child_ino;
if (S_ISDIR(inode_table[child_ino].mode))
inode_table[parent_ino].nlink++; // 子目录的 ".." 增加父目录 nlink
}要点解读:
S_ISDIR(mode) ? 2 : 1:目录的初始nlink为 2(自身的.和父目录中的条目),文件为 1std::move(inode):将临时Inode对象移入inode_table,避免拷贝data字符串的开销dir_add_child维护 nlink :每添加一个子目录,父目录的nlink加 1(因为子目录的..指回父目录)
实例代码解析:构建初始文件树
经过上面的准备,具备了基本功能。接下来我们构建一个图中所示的文件系统目录树。函数init_filesystem() 展示了如何用上述工具函数构建一棵完整的文件树:
cpp
static void init_filesystem() {
ino_t root = make_inode(S_IFDIR | 0755); // inode 1: /
ino_t readme = make_inode(S_IFREG | 0644,
"Welcome to MemReadFS!\n"
"This is an in-memory read-only filesystem built with FUSE3.\n");
dir_add_child(root, "readme.txt", readme); // / → readme.txt
ino_t src_dir = make_inode(S_IFDIR | 0755); // inode 3: /src/
dir_add_child(root, "src", src_dir);
ino_t main_file = make_inode(S_IFREG | 0644,
"#include <iostream>\n\nint main() {\n"
" std::cout << \"Hello from MemReadFS!\" << std::endl;\n"
" return 0;\n}\n");
dir_add_child(src_dir, "main.cpp", main_file); // /src/ → main.cpp
// ... 更多文件
}这种方式的优势是清晰直观:所有数据都在内存中,查找速度极快(unordered_map O(1) 查找)。缺点也很明显------重启后数据全部丢失。但对于本章的学习目的来说,这已经足够了。
2.3 实现核心回调
本章实现的回调函数与上一章一致,主要是读取目录、读取文件、获取属性和打开文件等接口。但是,由于存在目录嵌套的情况,路径变得复杂了,因此需要我们实现对路径解析的功能。
实例代码解析:路径解析 resolve_path
在 FUSE3 的高级 API 中,所有回调函数都以完整路径字符串作为参数(如 /src/main.cpp)。以下是 memreadfs.cpp 中的路径解析实现:
cpp
/* 路径分割:将路径按 '/' 分割为组件列表 */
static std::vector<std::string> split_path(const std::string &path) {
std::vector<std::string> components;
std::istringstream ss(path);
std::string component;
while (std::getline(ss, component, '/')) {
if (!component.empty() && component != ".") // 跳过空串和 "."
components.push_back(component);
}
return components;
}
/* 路径解析:从根 inode 出发,逐级查找,返回目标 inode 指针 */
static Inode* resolve_path(const char *path) {
if (strcmp(path, "/") == 0)
return &inode_table[ROOT_INO];
Inode *current = &inode_table[ROOT_INO]; //找到根目录的inode
std::vector<std::string> components = split_path(path);
for (const auto &comp : components) { //接下来逐级查找
if (!S_ISDIR(current->mode))
return nullptr; // 中间路径组件不是目录
auto it = current->children.find(comp);
if (it == current->children.end())
return nullptr; // 找不到该名字
current = &inode_table[it->second]; // 进入子 inode
}
return current;
}要点解读:
- 两步式设计 :先用
split_path将路径拆为组件列表(如/src/main.cpp→["src", "main.cpp"]),再逐级遍历。这种分离使得路径解析逻辑更清晰 component != ".":跳过当前目录引用,处理/src/./main.cpp等路径- 空串跳过 :处理
//src///main.cpp中的多余斜杠 - 时间复杂度 O(d) :d 是目录层级数。每一级需要在
std::map中查找(O(log n)),总复杂度为 O(d × log n) - 返回裸指针 :直接返回
inode_table中元素的地址,调用者可以直接修改 inode(后续章节的写操作用到)。在真实的文件系统中,路径解析结果通常会被缓存(Linux 内核的 dentry cache)以避免反复遍历。
实例代码解析:getattr() --- 从 inode 填充 stat
有了路径解析函数后,接下来我们看看几个回调函数的实现。首先是getattr() 函数,该函数获取文件/目录的属性。该函数的功能变成了"查 inode + 填 stat"的简单映射。以下是 memreadfs.cpp 中的实现:
cpp
static int memread_getattr(const char *path, struct stat *stbuf,
struct fuse_file_info *fi)
{
(void)fi;
memset(stbuf, 0, sizeof(struct stat));
Inode *inode = resolve_path(path); //根据路径查找具体的inode
if (!inode) return -ENOENT;
stbuf->st_ino = inode->ino;
stbuf->st_mode = inode->mode;
stbuf->st_nlink = inode->nlink;
stbuf->st_uid = inode->uid;
stbuf->st_gid = inode->gid;
stbuf->st_size = inode->size;
stbuf->st_atime = inode->atime;
stbuf->st_mtime = inode->mtime;
stbuf->st_ctime = inode->ctime;
/* 目录的 size 设为子项数 * 平均目录项大小(仅为展示用) */
if (S_ISDIR(inode->mode))
stbuf->st_size = (off_t)(inode->children.size() * 24);
return 0;
}对比 HelloFS 的 getattr :HelloFS 中是硬编码的 if/else,这里变成了通用的 resolve_path + 字段拷贝。路径解析将"查找逻辑"抽离出来,getattr 只负责将 inode 数据搬到 struct stat 中,职责单一。目录的 st_size 设为 children.size() * 24,模拟真实文件系统中目录项占用的空间。
实例代码解析:readdir() --- 遍历目录子项
由于在目录的inode中通过 children 存储着所有的目录项。因此在readdir() 我们只需要遍历目录的 children 映射,使用 filler 函数逐个添加。以下是 memreadfs.cpp 中的实现:
cpp
static int memread_readdir(const char *path, void *buf,
fuse_fill_dir_t filler, off_t offset,
struct fuse_file_info *fi,
enum fuse_readdir_flags flags)
{
(void)offset; (void)fi; (void)flags;
Inode *dir = resolve_path(path); //找到目录对应的inode
if (!dir) return -ENOENT;
if (!S_ISDIR(dir->mode)) return -ENOTDIR; // 不是目录,返回专用错误码
filler(buf, ".", nullptr, 0, (fuse_fill_dir_flags)0);
filler(buf, "..", nullptr, 0, (fuse_fill_dir_flags)0);
for (const auto &entry : dir->children)
filler(buf, entry.first.c_str(), nullptr, 0, (fuse_fill_dir_flags)0);
return 0;
}对比 HelloFS :HelloFS 中 readdir 是硬编码三行 filler,这里变成了 for 循环遍历 children。因为 std::map 有序,ls 会自动按字母序输出文件名。注意新增了 -ENOTDIR 错误码------对非目录路径执行 readdir 应返回此错误而非 -ENOENT。
实例代码解析:open() 与 read() --- 通用化读取
打开文件实际上并没有什么实质性的动作,核心在于检查期望打开的文件是否存在。如果不存在需要给调用者返回一个错误码。
cpp
static int memread_open(const char *path, struct fuse_file_info *fi)
{
Inode *inode = resolve_path(path);
if (!inode) return -ENOENT;
if (S_ISDIR(inode->mode)) return -EISDIR; // 不能 open 目录为文件
if ((fi->flags & O_ACCMODE) != O_RDONLY) return -EACCES;
return 0;
}现在 read 可以读取任意文件,因为文件内容统一存储在 inode->data 中。增加了 -EISDIR 检查防止对目录执行 read。偏移量和长度处理逻辑与 HelloFS 完全相同------这是 FUSE read 回调的标准模式。
cpp
static int memread_read(const char *path, char *buf, size_t size,
off_t offset, struct fuse_file_info *fi)
{
(void)fi;
Inode *inode = resolve_path(path);
if (!inode) return -ENOENT;
if (S_ISDIR(inode->mode)) return -EISDIR;
if (offset >= inode->size) return 0; // EOF
if (offset + (off_t)size > inode->size)
size = inode->size - offset;
memcpy(buf, inode->data.c_str() + offset, size);
return (int)size;
}高级 API vs 低级 API
在前面我们提到了高级API的概念,这里我们简单解释一下。FUSE 提供两种 API 模式,也即高级(high level)API和低级(low level)API,两者的解释如下:
- 高级 API(路径模式):回调函数接收完整路径字符串,libfuse 帮我们维护路径到 inode 的映射
- 低级 API (inode 模式):回调函数接收 inode 编号,需要我们自己实现
lookup()回调
高级 API 更简单直观,适合快速开发和学习;低级 API 性能更好(避免重复路径解析),适合生产环境。本书前几章使用高级 API,后续章节在需要时会介绍低级 API 的用法。
2.5 完善 init 回调
FUSE3 提供了 init() 回调函数,在文件系统挂载完成后、开始处理请求之前调用。我们可以在这里初始化文件树:
cpp
static void *memread_init(struct fuse_conn_info *conn,
struct fuse_config *cfg)
{
cfg->kernel_cache = 1; // 启用内核缓存
init_filesystem();
return NULL;
}kernel_cache = 1 告诉内核可以缓存文件内容,对于内容不会变化的只读文件系统,这可以显著提升性能------重复读取同一文件时,内核直接从缓存返回,不需要再调用我们的 read() 回调。
2.6 深入理解 fuse_fill_dir_t
接下来我们介绍一下 readdir 回调中的第三个参数,其类型为fuse_fill_dir_t,它是用于填充目录项的函数指针,定义如下:
cpp
typedef int (*fuse_fill_dir_t)(void *buf, const char *name,
const struct stat *stbuf, off_t off,
enum fuse_fill_dir_flags flags);参数说明:
- buf :传递给
readdir的不透明缓冲区指针,直接传给filler即可 - name:目录项的名字
- stbuf :可选的
stat结构体指针。如果提供,内核可以避免对该项单独调用getattr - off:下一个目录项的偏移量。设为 0 表示不使用偏移量模式(一次性返回所有条目)
- flags :可以设置
FUSE_FILL_DIR_PLUS来启用 readdirplus 模式
返回值:0 表示成功,1 表示缓冲区已满(应停止添加条目)。
当目录包含大量文件时(如数万个文件),应考虑使用偏移量模式来支持分批返回,避免一次性分配过多内存。本章的示例目录较小,使用简单模式即可。
2.7 测试与验证
本章实例编译运行方法与第一章一样,这里不再赘述。编译运行 MemReadFS 后,可以使用以下命令进行测试:
bash
# 浏览目录结构
$ tree /tmp/memreadfs
/tmp/memreadfs
├── docs
│ └── guide.txt
├── readme.txt
└── src
├── main.cpp
└── util.cpp
# 读取文件
$ cat /tmp/memreadfs/readme.txt
Welcome to MemReadFS!
This is an in-memory read-only filesystem built with FUSE3.
$ cat /tmp/memreadfs/src/main.cpp
#include <iostream>
int main() {
std::cout << "Hello from MemReadFS!" << std::endl;
return 0;
}
# 查看详细属性
$ ls -la /tmp/memreadfs/
total 0
drwxr-xr-x 4 user user 0 Jan 1 00:00 .
drwxrwxrwt 8 root root 160 Jan 1 00:00 ..
drw-r--r-- 2 user user 0 Jan 1 00:00 docs
-rw-r--r-- 1 user user 74 Jan 1 00:00 readme.txt
drw-r--r-- 2 user user 0 Jan 1 00:00 src
# stat 显示 inode 信息
$ stat /tmp/memreadfs/readme.txt
File: /tmp/memreadfs/readme.txt
Size: 74 Blocks: 0 IO Block: 4096 regular file
Inode: 2 Links: 1尝试写入操作应该会失败,因为我们没有实现任何写入回调:
bash
$ echo "test" > /tmp/memreadfs/test.txt
bash: /tmp/memreadfs/test.txt: Function not implemented这正是预期的行为------我们还没有实现写入操作,这将在下一章实现。
本章完整代码
完整代码见 code/ch02_memreadfs/memreadfs.cpp 和 code/ch02_memreadfs/CMakeLists.txt。