目录
[1.Attention Is All You Need](#1.Attention Is All You Need)
[2.A Gentle Introduction to Graph Neural Networks](#2.A Gentle Introduction to Graph Neural Networks)
摘要
本周进行论文阅读和学习,学习内容是论文Attention Is All You Need和A Gentle Introduction to Graph Neural Networks
1.Attention Is All You Need
学习阅读的论文为Attention Is All You Need
本文摒弃了传统的循环(RNN)和卷积(CNN)结构,提出了一个完全基于自注意力机制的Transformer模型,在机器翻译等序列转换任务上取得了更优的性能、更强的并行能力和更短的训练时间。
贡献
- 提出纯注意力序列模型架构:首次设计并验证了完全依赖自注意力机制,而不使用任何循环或卷积操作的编码器-解码器架构(Transformer),解决了RNN的顺序计算瓶颈。
- 设计了核心的注意力机制组件 :提出了缩放点积注意力 和 多头注意力,前者高效且稳定,后者允许模型同时关注来自不同表示子空间的信息。
- 展示了卓越的性能与通用性:在WMT英德/英法翻译任务上以更低的训练成本达到了新的SOTA;同时,在英语句法解析任务上表现出强大的泛化能力,预示了其作为通用序列建模基石的潜力。
问题背景与研究动机
问题定义 (Problem Definition):如何高效地对变长序列进行建模和转换(如机器翻译),并有效捕捉序列内部及序列间的长距离依赖关系?
现有方法的局限 (Limitations of Prior Work):
基于RNN/LSTM的模型:当时的主流方法。其核心瓶颈在于顺序计算------必须按时间步逐步处理序列,这严重限制了训练时的并行能力(无法同时计算所有时间步),且长距离依赖需要信息多次传递,容易衰减。
基于CNN的模型(如ByteNet, ConvS2S):通过卷积实现并行计算,但为了建立任意两个位置间的关联,需要堆叠多层O(n/k) 或 O(层),导致长距离依赖的路径仍然较长(见论文表1)。
注意力作为辅助:注意力机制已被广泛用于增强RNN/CNN模型,以解决长距离依赖问题,但始终作为"配角"与循环或卷积结构结合使用。
本文思路 (Overall Idea):既然注意力的优点在于能直接计算序列中任意两个位置的关系(复杂度O(1)),那能否让其"唱主角"?作者提出一个大胆设想:完全抛弃循环和卷积,仅用注意力机制来构建整个编码器和解码器。这样既能获得最强的并行能力(所有位置同时计算),又能使任意两个位置间的信号传递路径最短(仅一层),从根本上解决上述瓶颈。
整体架构
整体架构如论文 图1 所示,是一个经典的编码器-解码器结构,但内部组件全部革新。
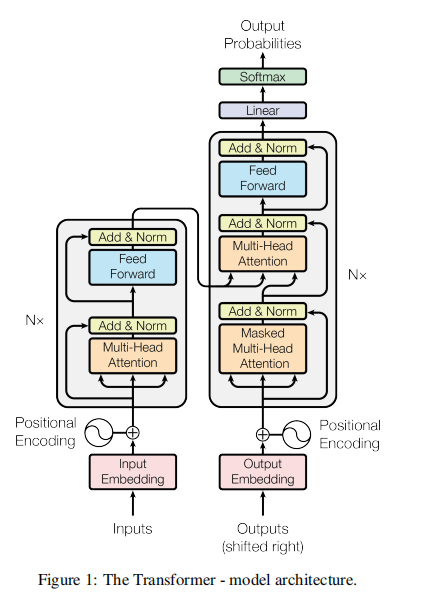
- 数据流 :
- 编码器 (左半部分):由N=6个相同层 堆叠而成。每层包含两个子层:1)一个多头自注意力机制 ,2)一个简单的位置全连接前馈网络 。每个子层外围都套有残差连接 (借鉴ResNet思想)和层归一化 。即输出为
LayerNorm(x + Sublayer(x))。 - 解码器 (右半部分):同样由N=6个相同层堆叠。每层包含三个 子层:前两个与编码器相同,第三个是编码器-解码器注意力层 (其
K, V来自编码器输出,Q来自解码器上一子层输出)。此外,解码器的自注意力子层被修改为掩码自注意力 ,确保在预测位置i时,只能看到位置< i的输出,保持自回归特性。
- 编码器 (左半部分):由N=6个相同层 堆叠而成。每层包含两个子层:1)一个多头自注意力机制 ,2)一个简单的位置全连接前馈网络 。每个子层外围都套有残差连接 (借鉴ResNet思想)和层归一化 。即输出为
- 核心思想 :该架构的宏观革命在于,用全局的、并行的注意力操作,完全取代了局部的、顺序的循环操作 。序列的"顺序"信息不再由计算步骤隐含,而是通过显式的位置编码注入。
核心组件
1. 缩放点积注意力 (Scaled Dot-Product Attention) 如论文 图2(左) 所示,这是构建一切的基础模块。
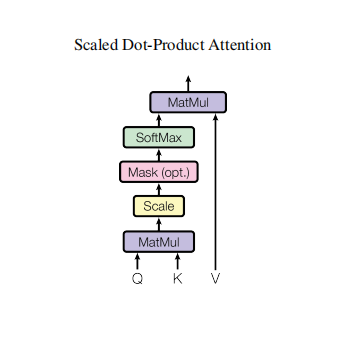
- 输入和输出 :输入为
Q(查询矩阵),K(键矩阵),V(值矩阵)。输出为一个加权和后的矩阵。 - 内部机理与设计动机 :
- 计算过程 :对于每个查询向量,计算它与所有键向量的点积,作为相关性分数。然后进行缩放 (除以 dk\sqrt{d_k}dk),再通过Softmax转化为权重,最后对值向量
V进行加权求和。 - 缩放因子的关键作用 :论文指出,当dkd_kdk较大时,点积结果在数量级上会很大,这将把Softmax函数推入梯度极小的区域(饱和区),不利于训练。缩放操作就是为了稳定梯度,确保注意力权重的有效学习。
- 为何用点积 :与"加性注意力"相比,点积注意力可以利用高度优化的矩阵乘法代码,实现极快的速度和空间效率。
- 计算过程 :对于每个查询向量,计算它与所有键向量的点积,作为相关性分数。然后进行缩放 (除以 dk\sqrt{d_k}dk),再通过Softmax转化为权重,最后对值向量
2. 多头注意力 (Multi-Head Attention) 如论文 图2(右) 所示,这是模型强大的关键。
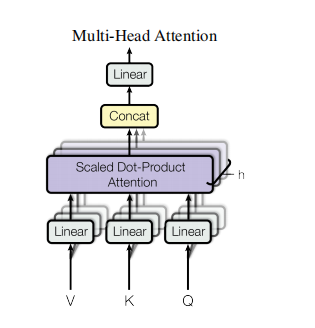
- 输入和输出 :输入同
Q, K, V,输出为多个头输出的拼接与线性投影。 - 内部机理与设计动机 :
- 并行多子空间 :模型不是用一个dmodeld_{\text{model}}dmodel维的注意力函数,而是将
Q, K, V通过hhh个不同的线性投影矩阵,分别投影到较低的维度(dk,dk,dvd_k, d_k, d_vdk,dk,dv)。然后在每个投影后的子空间(即每个"头")中独立进行缩放点积注意力计算。 - 动机与优势 :这允许模型联合关注来自不同表示子空间的信息。例如,一个头可以学习关注句法依赖,另一个头关注指代关系,再一个头关注局部短语结构。将所有头的输出拼接后再投影回原始维度,融合了这些不同类型的信息。这是单头注意力(本质是加权平均)无法做到的。
- 并行多子空间 :模型不是用一个dmodeld_{\text{model}}dmodel维的注意力函数,而是将
3. 位置编码 (Positional Encoding)
- 问题 :由于自注意力对输入序列的处理是排列不变的,它本身无法感知词序信息。
- 解决方案 :在输入词嵌入向量上,加上一个与位置相关的编码向量。论文采用了正弦和余弦函数 的固定编码方案:
- 设计动机 :
- 能够表示任意长度的序列,且具有周期性,可能有助于模型外推到比训练序列更长的序列。
- 对于固定的偏移量k,
可以表示为
- 实验表明,可学习的位置嵌入效果相当,但正弦版本具有上述理论优势。
关键公式与算法
缩放点积注意力 Attention(Q, K, V) = softmax(QK^T / sqrt(d_k)) V
- 公式的目标 :计算一组查询向量
Q相对于所有键值对(K, V)的上下文感知表示。 - 各部分的含义 :
QK^T:计算查询与所有键的相关性分数矩阵。分数越高,表示该查询与对应键的匹配度越高。sqrt(d_k):缩放因子,用于控制点积的幅度,防止梯度消失。softmax(...):将分数归一化为概率分布(注意力权重),权重和为1。(...) V:用注意力权重对值向量V进行加权求和。直观上,输出就是所有值向量的"软选择"或"软聚焦",聚焦程度由查询与键的匹配度决定。
- 公式的直觉 :你可以把
Q看作"我想找什么",K是"我有什么标签",V是"我存储的实际信息"。模型通过计算Q和每个K的匹配度(点积),来决定从每个V中取多少信息来组合成最终答案。
位置前馈网络 FFN(x) = max(0, xW_1 + b_1)W_2 + b_2
- 公式的目标:对自注意力子层的输出进行非线性变换和特征整合。
- 各部分的含义 :这是一个两层的全连接网络,中间有ReLU激活。它对序列中的每个位置独立、相同地进行变换。
- 公式的直觉 :自注意力层主要负责聚合 信息(不同位置间的交互),而FFN层则负责加工和提炼每个位置上的聚合后信息。你可以将其看作在每个位置上的一个小型"感知机",用于增强模型的表示能力。
思考
-
优点与创新点:
- 范式转移:这是最根本的贡献。它证明了一种完全不同的序列建模路径的可行性,彻底打破了RNN/CNN的统治地位。其思想的影响远超NLP,波及CV、语音、强化学习等领域。
- 卓越的效率-性能比:通过极致的并行化设计,在取得顶级性能的同时,训练速度大幅提升,极大地加速了后续研究的迭代。
- 架构的简洁与模块化:编码器层和解码器层的设计高度一致和简洁(注意力 + FFN + 残差 & 归一化),使其易于理解、实现和扩展。
- 可解释性的曙光:多头注意力机制的可视化,为理解这个"黑箱"模型如何工作提供了难得的窗口,推动了可解释AI的发展。
-
局限性:
- 计算与内存复杂度 :自注意力的计算复杂度是序列长度nnn的二次方 O(n2)O(n^2)O(n2)。这对于处理长文档、高分辨率图像或长视频构成了根本性挑战。这是后续众多"高效Transformer"变体(如Longformer, BigBird, Linformer等)致力解决的核心问题。
- 位置编码的固有限制:无论是正弦还是可学习的位置编码,在推理时都难以泛化到远长于训练时见过的序列长度。对于需要极强长度外推能力的任务,这是一个瓶颈。
- 失去的归纳偏置 :RNN天然具有局部性 和顺序性 的归纳偏置,CNN具有平移不变性 和局部性 偏置。Transformer几乎放弃了所有结构性偏置,完全从数据中学习。这既是其强大表示能力的来源,也意味着它在小数据场景下可能不如带有合适归纳偏置的模型高效。
- 自回归解码的延迟:解码过程仍然是自回归的(逐词生成),无法做到完全并行,这在实时应用中是延迟的来源。
《Attention Is All You Need》是一篇思想性、实用性和影响力都达到顶峰的杰作。它不仅提出了一个在特定任务上更优的模型,更提供了一种全新的、强大的建模范式,其影响之深远,在论文发表七年后回看,仍然觉得难以置信。它完美地诠释了:一个简洁而深刻的核心思想(自注意力),足以撼动一个领域乃至整个AI研究的基石。
2.A Gentle Introduction to Graph Neural Networks
学习阅读的论文为A Gentle Introduction to Graph Neural Networks
本文全面介绍了图神经网络的基本概念、核心架构、设计选择及其在实际问题中的应用,通过从简到繁的构建过程和一个互动实验平台,帮助读者建立对 GNN 如何运作的深刻直觉
贡献
- 系统化梳理了GNN的基础:清晰定义了图数据(节点、边、全局上下文)的表示方法,并分类阐述了图级、节点级和边级三类预测任务。
- 深入拆解了GNN的核心架构:以"消息传递"框架为线索,循序渐进地讲解了从最简单的"图无关"网络,到包含邻域聚合的图卷积网络(GCN),再到融合节点、边、全局信息的复杂图网络(Graph Nets)的完整演进过程。
- 提供了实证设计与互动分析平台 :文章提供了一个基于分子气味预测任务的互动实验平台,让读者能够直观探索GNN深度、嵌入维度、聚合函数和消息传递类型等关键设计选择对模型性能与表示学习的影响。
问题背景与研究动机
- 问题定义 (Problem Definition) :现实世界中许多对象(如社交网络中的用户、分子中的原子)及其间的关系(如友谊、化学键)天然地以图的形式存在。如何设计能够直接处理这种非欧几里得数据结构、并利用其内部关系进行预测的神经网络模型?
- 现有方法的局限 (Limitations of Prior Work) :标准的深度学习模型(如CNN、RNN)是为网格化(图像)或序列化(文本)数据设计的。它们无法自然地处理图数据的两个关键特性:1) 变长的邻居结构 (每个节点的邻居数可变),2) 置换不变性(图的结构不依赖于节点的排列顺序)。直接将图表示为邻接矩阵输入传统网络会面临计算效率低和缺乏置换不变性的问题。
- 本文思路 (Overall Idea) :文章提出,GNN 的本质是一种保持图对称性(置换不变性)的、可优化的图属性(节点、边、全局上下文)变换 。其核心思路是采用"图进,图出"的架构,通过消息传递机制,让图中相邻的元素交换并聚合信息,从而逐步构建出蕴含局部与全局结构的节点/图表示
整体架构
文章并非介绍单一架构,而是展示了GNN设计空间的演进路径,整体遵循从简单到复杂的逻辑。
- 最简单的GNN :将节点、边、全局属性视为独立集合,分别用多层感知机(MLP)进行变换,完全不利用图的连接性。
- 引入池化进行预测 :在预测阶段,通过池化操作在不同属性间路由信息。例如,要预测节点属性但只有边特征时,可以聚合相连边的信息到目标节点。
- 在层内引入消息传递:将池化思想融入GNN层内部,使节点嵌入能够根据其邻居的信息进行更新。这是现代GNN(如GCN)的核心。消息传递分为三步:收集邻居信息、聚合(如求和、求均值)、通过更新函数(如MLP)生成新嵌入。
- 融合边与全局表示 :更先进的架构(如Graph Nets)允许边、节点和全局上下文 (或称"主节点")之间进行双向信息交换。全局上下文作为图中所有元素的桥梁,有助于捕捉远程依赖关系1
核心组件
消息传递机制
- 输入和输出:输入是带有节点特征、边特征和全局特征的图。输出是更新后(特征维度可能变化)但连接结构不变的图。
- 内部机理与设计动机 :
- 收集 :对于目标节点(或边),识别其直接相邻的节点(或边)。这通过图的邻接关系实现,通常使用邻接表高效存储。
- 聚合 :将收集到的邻居特征合并为一个向量。常见操作有求和 、求均值 、取最大值 。设计动机在于需要一个对邻居顺序不敏感(置换不变)且能处理变长输入的可微操作。求和能保留分布的全貌,均值提供归一化视图,最大值突出最显著特征。
- 更新 :将目标节点自身的特征与聚合后的邻居特征组合(如拼接),然后送入一个可学习的更新函数(如MLP),产生该节点新的表示。这使得节点的最终表示编码了其局部子图的结构信息
核心思想:通过堆叠消息传递层,节点可以接收到来自 K 跳之外邻居的信息,从而获得更全局的视图
思考
-
优点与创新点:
- 无与伦比的教学清晰度:文章采用"分阶段构建"的叙述方式,将复杂的GNN概念拆解成易于理解的模块,是深度学习领域不可多得的优秀教程。
- 理论与实践的完美结合:不仅有清晰的概念阐释,还提供了可交互的实证研究平台,让抽象的设计选择(如聚合函数、深度)产生了具体、直观的性能反馈,极大地强化了学习效果。
- 覆盖全面且前沿 :不仅涵盖了GCN、MPNN、Graph Nets等核心架构,还延伸讨论了图注意力网络(GAT)、图的生成模型、可解释性、采样与批处理等高级或实践话题,为读者指明了进一步探索的方向1。
-
局限性与可商榷之处:
- 侧重经典架构:作为入门教程,它深度聚焦于基于消息传递的GNN范式。对于更前沿的、可能挑战此范式的架构(如基于子图或图同构测试的模型)着墨相对较少。
- 任务类型单一:互动实验仅围绕一个图级分类任务展开。虽然结论具有启发性,但在边预测、节点聚类等其他类型任务上,某些设计选择(如聚合函数)的最佳实践可能有所不同。
- 对归纳偏置的强调:文章精辟地指出了GNN的"关系归纳偏置",但可以更深入地对比其他架构(如Transformer)在处理图数据时隐含的不同偏置