vLLM v1 Engine --- 系统级架构深度分析
分析范围:
vllm/v1/engine/目录,14个Python文件,~9.5K行代码。这是 vLLM v1 推理系统的"大脑与桥梁"------连接上层 API(OpenAI Server)与底层推理执行(Worker/ModelRunner)。
Dark Terminal 风格架构图 10 张,见
diagrams/子目录。
一、整体架构概览
1.1 设计思路
vLLM v1 Engine 采用 前后端分离 + 进程隔离架构:
- 前端(Frontend) :
AsyncLLM/LLMEngine面向调用方,负责请求预处理、输出组装、流式传输 - 后端(Backend) :
EngineCore/EngineCoreProc在独立进程中运行调度+执行循环 - IPC 桥梁 :
EngineCoreClient体系通过 ZMQ 或直接调用连接前后端 - 数据并行协调 :
DPCoordinator管理多 DP 副本的波式调度
核心设计哲学:
- 进程隔离:EngineCore 在独立子进程中运行,避免 GIL 干扰
- 零拷贝序列化:msgspec.Struct + array_like=True 实现 IPC 高效传输
- 波式 DP 调度:Data Parallel 使用 wave-based 协调,避免竞态条件
- 弹性扩展:Elastic EP 支持运行时 DP 副本动态增减
1.2 架构模式
| 模式 | 应用 |
|---|---|
| 前后端分离 | AsyncLLM(frontend) ↔ EngineCore(backend) |
| 代理模式 | EngineCoreClient → InprocClient/MPClient/DPClient |
| 模板方法 | EngineCore.step() 固定骨架,batch_queue 变体 |
| 策略模式 | 6种 CoreClient 实现,按场景选择 |
| 观察者模式 | _idle_state_callbacks 引擎空闲通知 |
| 享元模式 | mm_receiver_cache MM 特征缓存 |
| 工厂模式 | EngineCoreClient.make_client() |
1.3 整体运行流程
Client Request
↓
AsyncLLM.generate(prompt, sampling_params)
↓
InputProcessor.process_inputs()
→ validate, tokenize, MM features
↓
EngineCoreRequest (msgspec binary)
↓
CoreClient.add_request_async()
→ ZMQ ROUTER socket → EngineCoreProc
↓
EngineCore.add_request() → Scheduler.enqueue()
↓
EngineCore.step() loop:
1. Scheduler.schedule() → SchedulerOutput
2. Executor.execute_model() → ModelRunnerOutput (Future)
3. Scheduler.update_from_output() → EngineCoreOutputs
↓
ZMQ PUSH socket → CoreClient.get_output_async()
↓
OutputProcessor.process_outputs()
→ Detokenizer + LogprobsProcessor + RequestState
↓
RequestOutput → yield to client (streaming or full)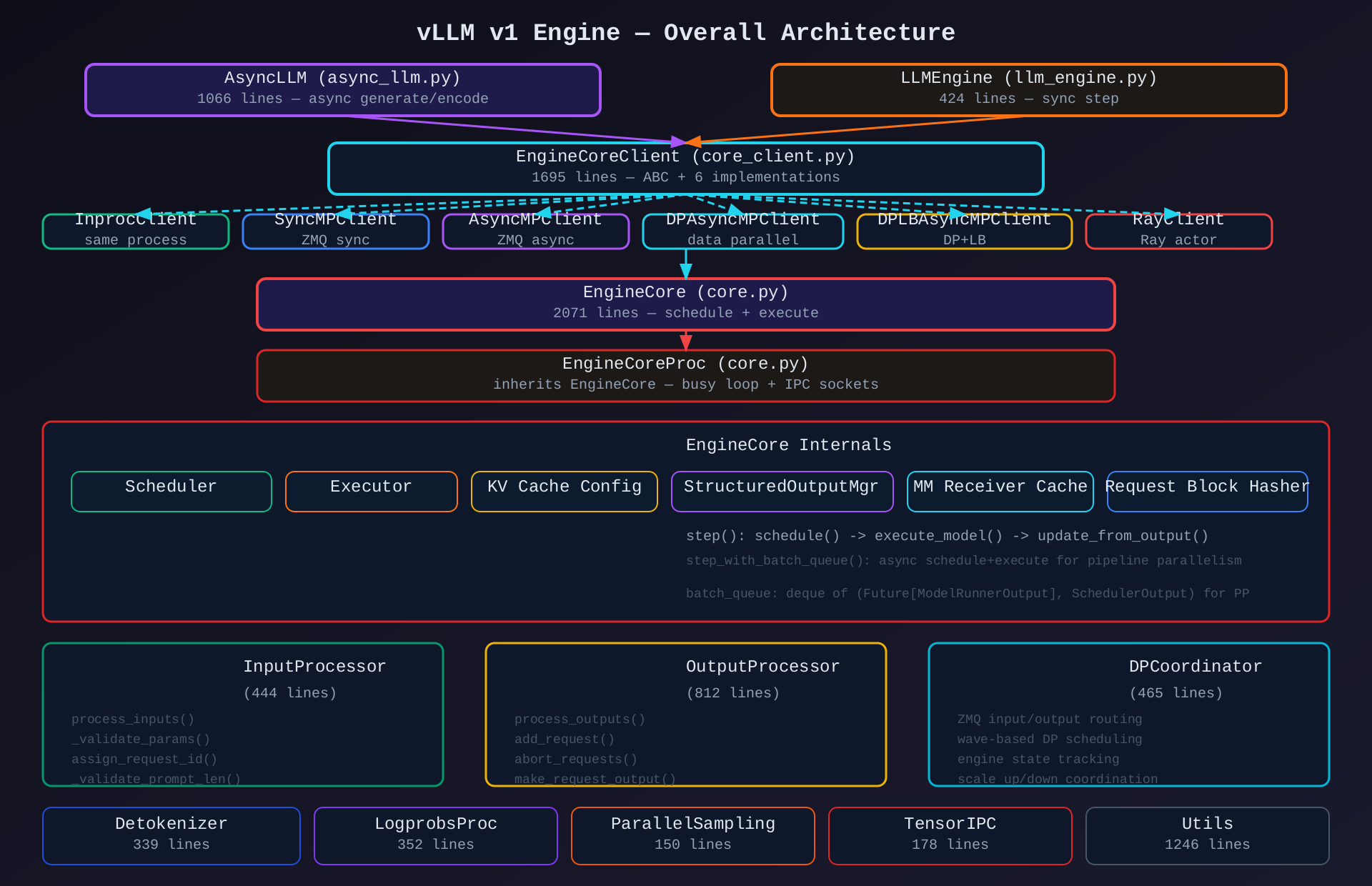
二、子模块划分
模块1:EngineCore(core.py,2071行)
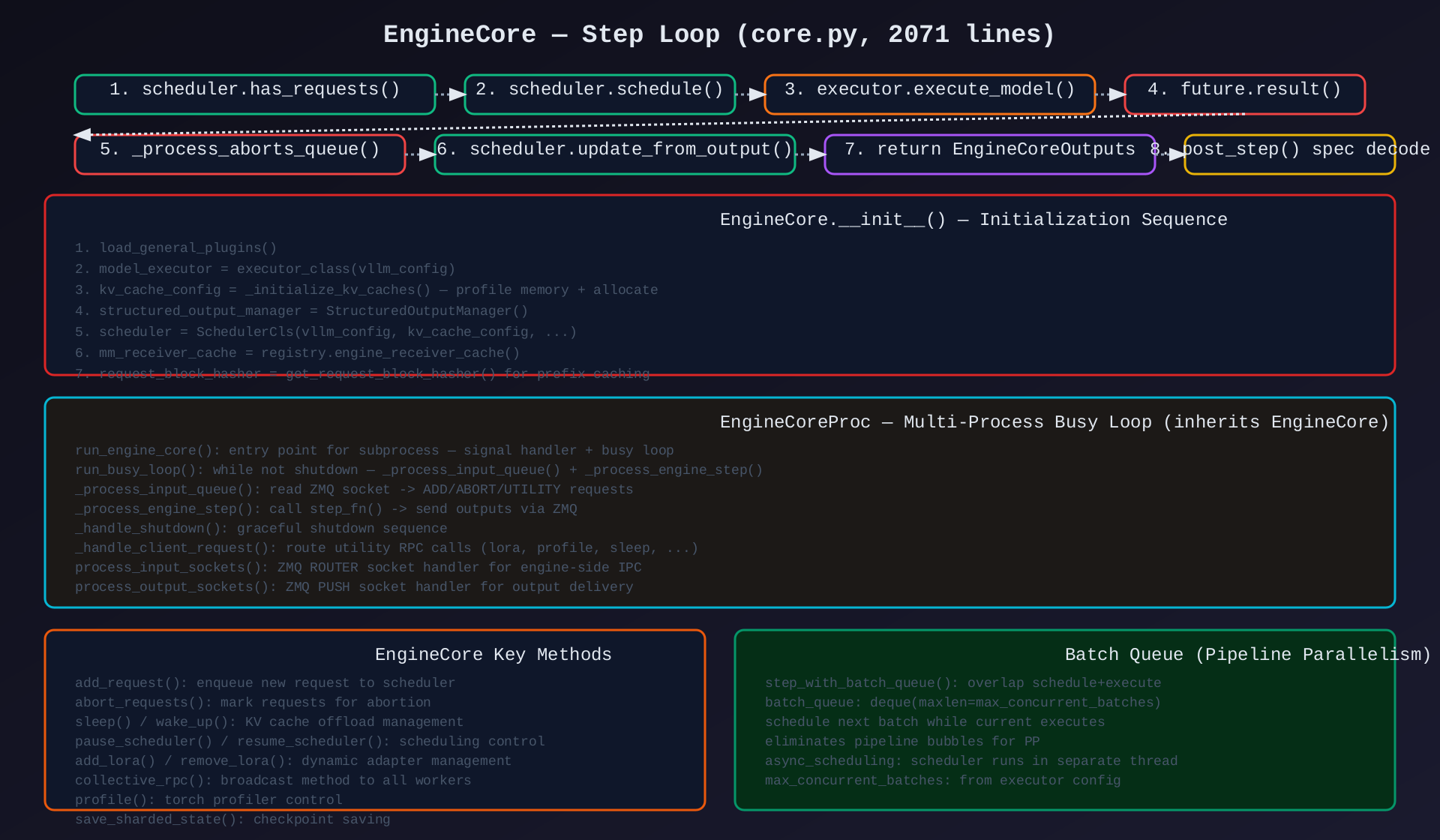
核心作用:v1 推理系统的核心引擎,持有 Scheduler + Executor,执行 schedule→execute→update 循环。
关键类/方法:
| 类/方法 | 说明 |
|---|---|
EngineCore.__init__() |
初始化:executor + KV cache + scheduler + structured_output + MM cache |
EngineCore.step() |
核心循环:schedule → execute_model → update_from_output |
EngineCore.step_with_batch_queue() |
PP 变体:异步 schedule+execute 消除 pipeline bubble |
EngineCore.add_request() |
向 scheduler 添加新请求 |
EngineCore.abort_requests() |
标记请求中止 |
EngineCore._initialize_kv_caches() |
内存探测 + KV cache 配置计算 |
EngineCore.sleep() / wake_up() |
KV cache offload/reload 控制 |
EngineCore.pause_scheduler() / resume_scheduler() |
调度器暂停/恢复 |
EngineCoreProc |
子进程版 EngineCore,ZMQ busy loop |
EngineCoreProc.run_busy_loop() |
while not shutdown: process_input + step |
EngineCoreProc._process_input_queue() |
读取 ZMQ 请求:ADD/ABORT/UTILITY |
EngineCoreProc._process_engine_step() |
执行 step + 发送 output |
EngineCoreProc.process_input_sockets() |
ZMQ ROUTER 处理 |
EngineCoreProc.process_output_sockets() |
ZMQ PUSH 发送 |
架构图 :见 02-engine-core-step-loop.svg
模块2:EngineCoreClient 体系(core_client.py,1695行)
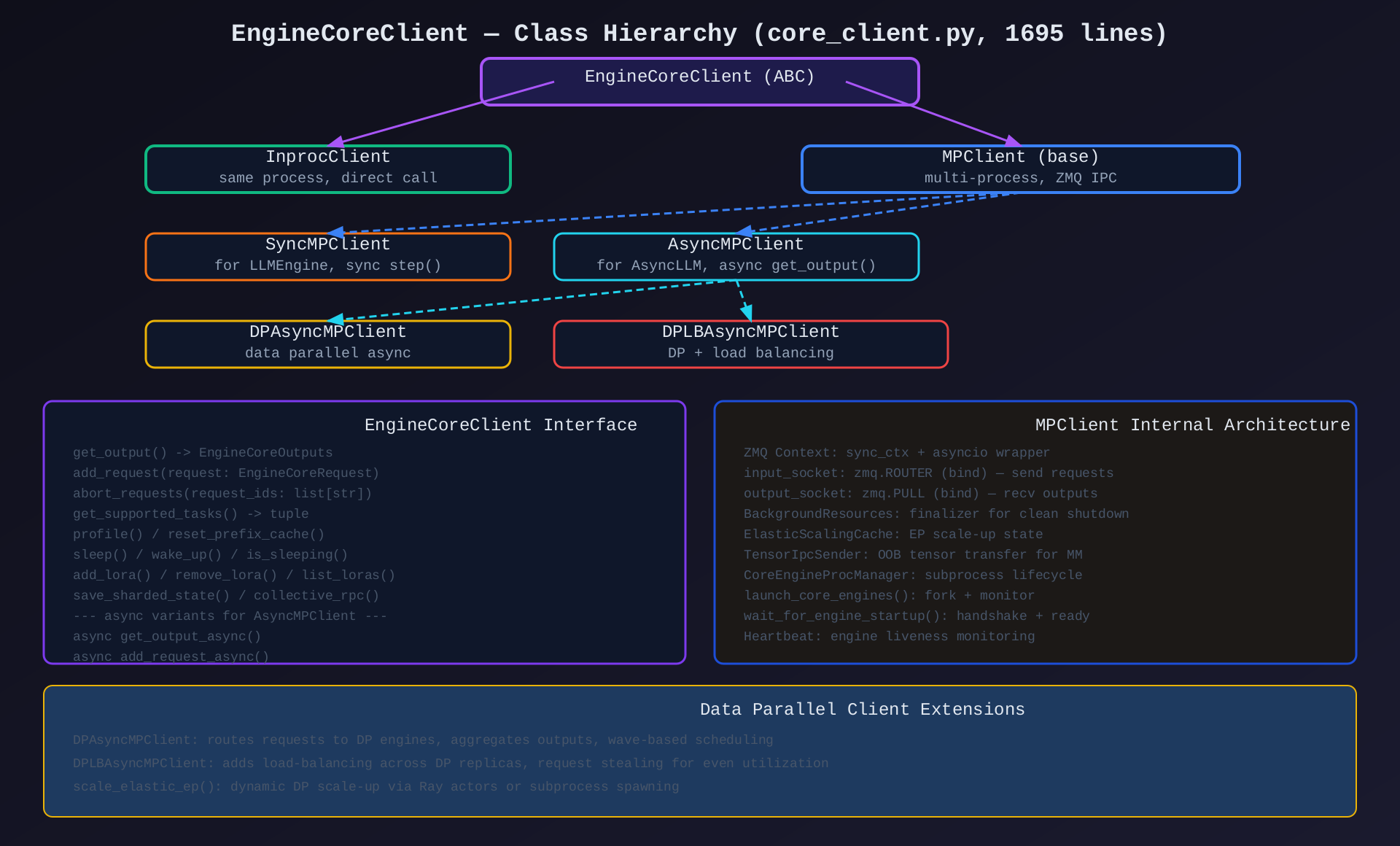
核心作用:前端与 EngineCore 的通信桥梁,提供同步/异步/进程内/多进程/数据并行多种通信方式。
关键类/方法:
| 类 | 说明 |
|---|---|
EngineCoreClient (ABC) |
抽象基类,定义 25+ 接口方法(sync + async) |
InprocClient |
同进程直接调用 EngineCore,用于 LLMEngine |
MPClient |
多进程基类,ZMQ IPC |
SyncMPClient |
同步 ZMQ,用于 LLMEngine 多进程模式 |
AsyncMPClient |
异步 ZMQ,用于 AsyncLLM |
DPAsyncMPClient |
数据并行异步,路由请求到 DP engines |
DPLBAsyncMPClient |
DP + 负载均衡,request stealing |
BackgroundResources |
ZMQ context + socket 清理 finalizer |
ElasticScalingCache |
EP 弹性扩展状态缓存 |
关键方法:
make_client(): 工厂方法,根据配置选择 client 类型make_async_mp_client(): 创建异步多进程 clientadd_request_async(): 异步发送请求到 EngineCoreget_output_async(): 异步获取推理输出scale_elastic_ep(): 动态调整 DP 副本数
架构图 :见 03-core-client-hierarchy.svg
模块3:AsyncLLM(async_llm.py,1066行)
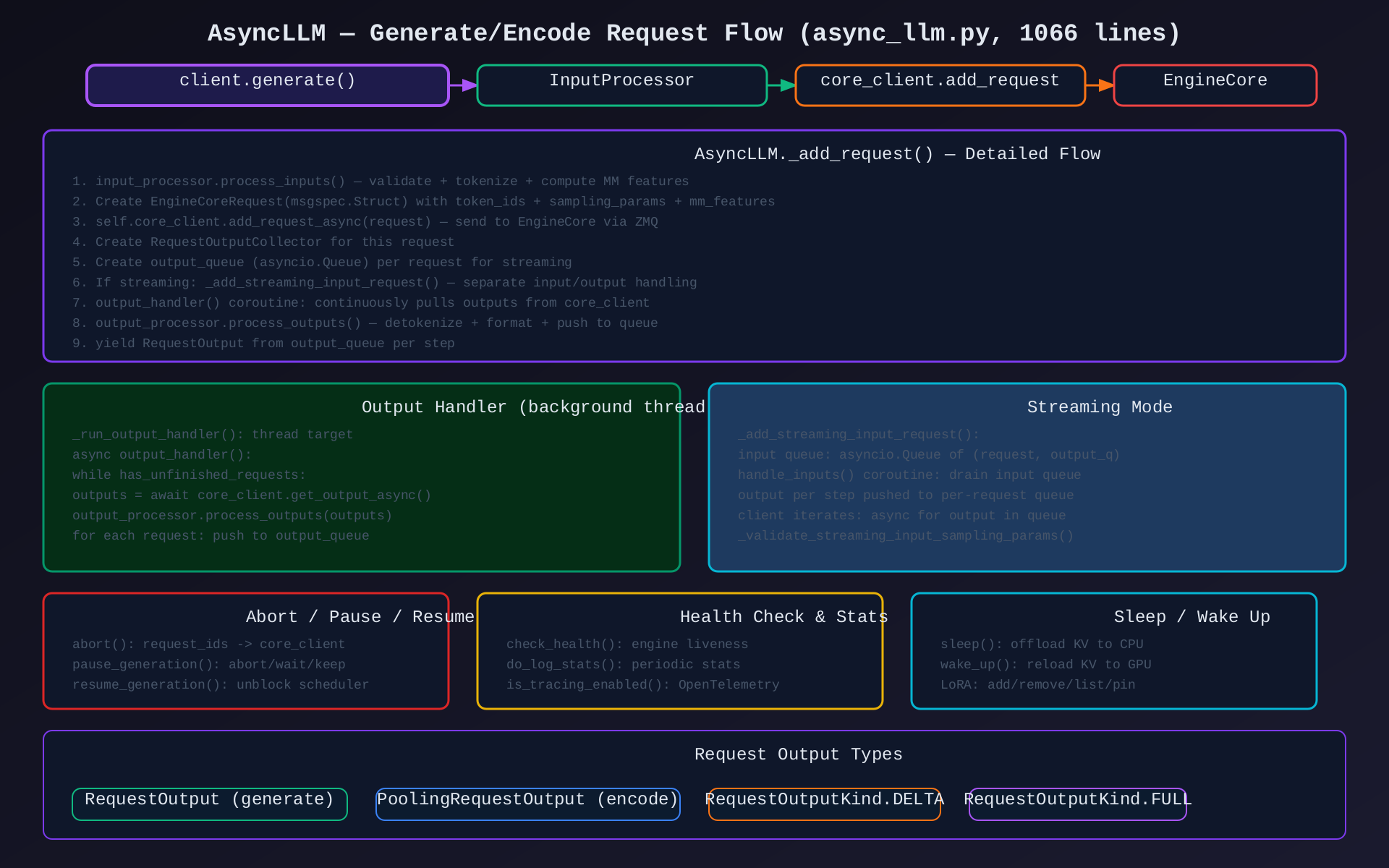
核心作用:异步推理接口,支持 streaming generate/encode,后台线程处理输出。
关键类/方法:
| 方法 | 说明 |
|---|---|
__init__() |
初始化:core_client + input_processor + output_processor + output_handler_thread |
from_vllm_config() |
工厂方法,从配置创建 |
from_engine_args() |
从命令行参数创建 |
generate() |
异步生成器,yield RequestOutput |
encode() |
异步 embedding 生成 |
_add_request() |
预处理 + 发送到 core_client |
_add_streaming_input_request() |
流式输入处理 |
_run_output_handler() |
后台线程入口 |
output_handler() |
异步协程:持续拉取 outputs |
abort() |
中止请求 |
pause_generation() / resume_generation() |
暂停/恢复生成 |
check_health() |
引擎健康检查 |
sleep() / wake_up() |
KV offload 控制 |
架构图 :见 04-asyncllm-generate-flow.svg
模块4:InputProcessor(input_processor.py,444行)
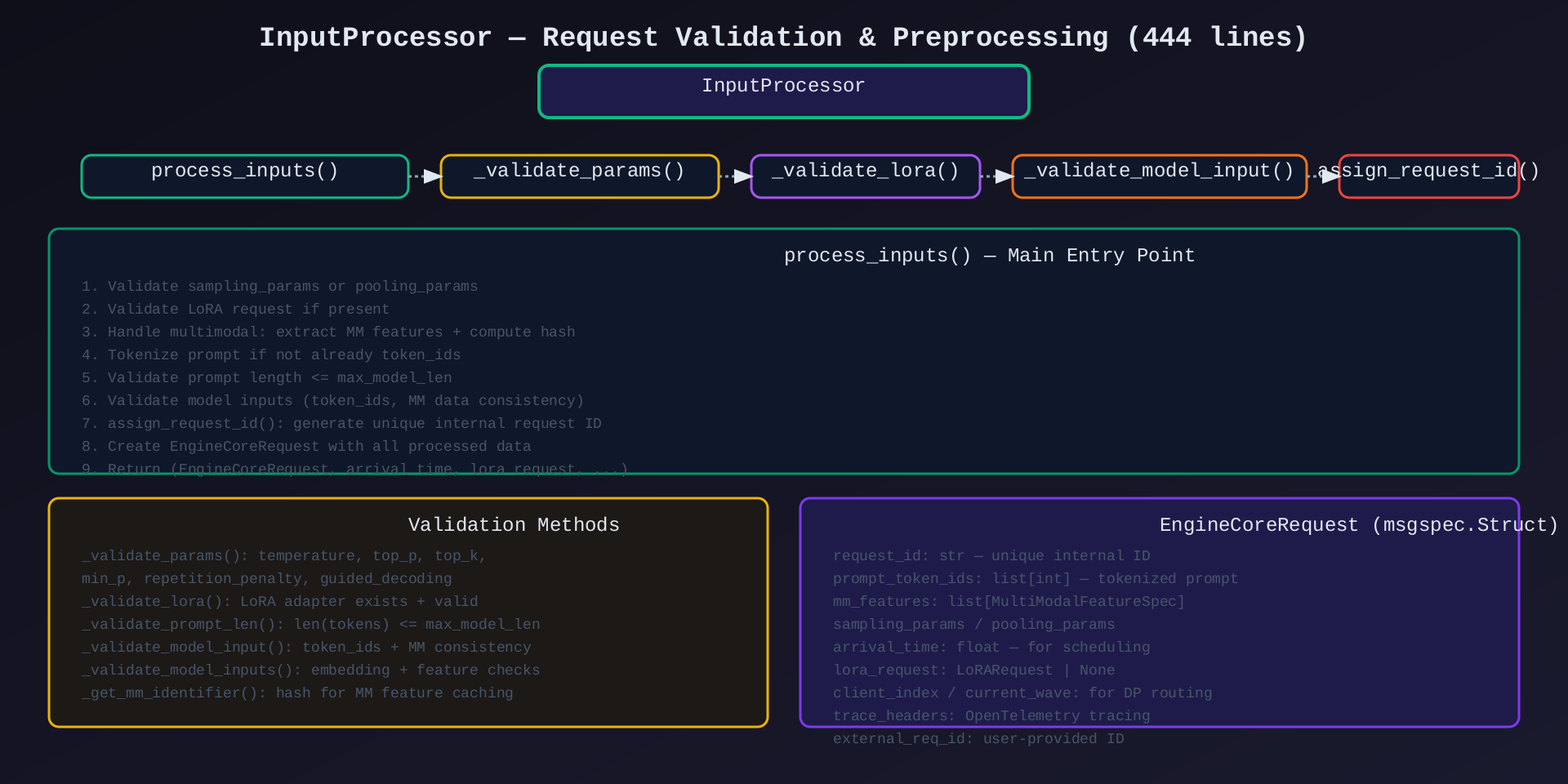
核心作用:请求预处理------验证参数、分词、多模态特征提取、构建 EngineCoreRequest。
关键类/方法:
| 方法 | 说明 |
|---|---|
process_inputs() |
主入口:验证→分词→MM→构建请求 |
_validate_params() |
验证 sampling/pooling 参数 |
_validate_lora() |
验证 LoRA 适配器 |
_validate_prompt_len() |
检查 prompt 长度 ≤ max_model_len |
_validate_model_input() |
token_ids + MM 一致性检查 |
_validate_model_inputs() |
embedding + 特征检查 |
_get_mm_identifier() |
MM 特征缓存 hash |
assign_request_id() |
生成唯一内部请求 ID |
架构图 :见 05-input-processor.svg
模块5:OutputProcessor(output_processor.py,812行)
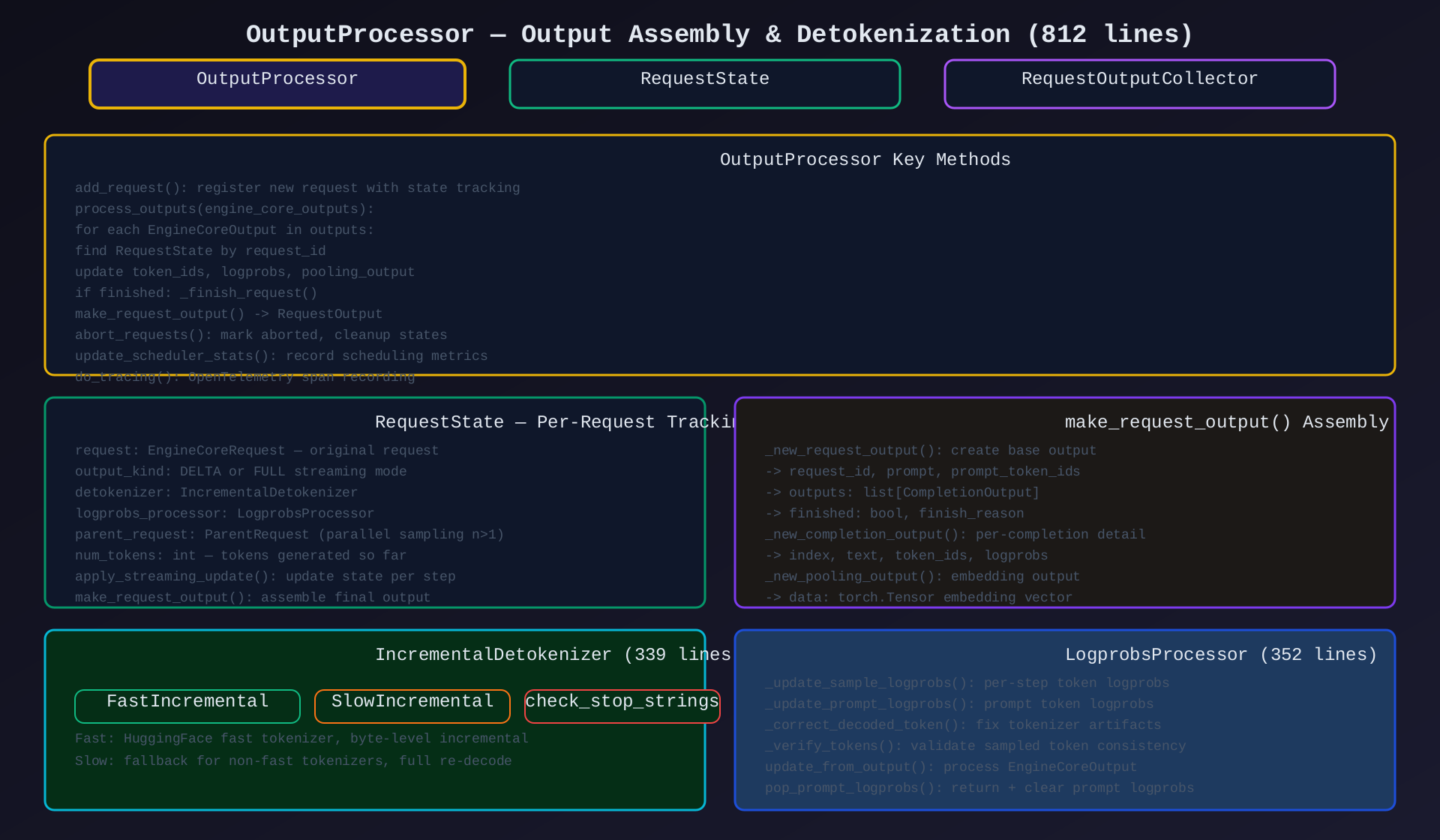
核心作用:推理输出后处理------解码 token、组装 logprobs、detokenize、构建 RequestOutput。
关键类/方法:
| 类/方法 | 说明 |
|---|---|
OutputProcessor |
输出处理主类 |
RequestState |
每请求状态跟踪(token 数、detokenizer、logprobs) |
RequestOutputCollector |
asyncio.Queue 包装,per-request 输出队列 |
StreamingUpdate |
流式更新数据 |
process_outputs() |
处理 EngineCoreOutputs → RequestOutput |
add_request() |
注册新请求 + 创建 RequestState |
abort_requests() |
中止请求 + 清理 |
make_request_output() |
组装最终输出 |
_new_request_output() |
创建基础 RequestOutput |
_new_completion_output() |
创建 CompletionOutput |
_new_pooling_output() |
创建 PoolingOutput |
_finish_request() |
请求完成处理 |
架构图 :见 06-output-processor.svg
模块6:DPCoordinator(coordinator.py,465行)
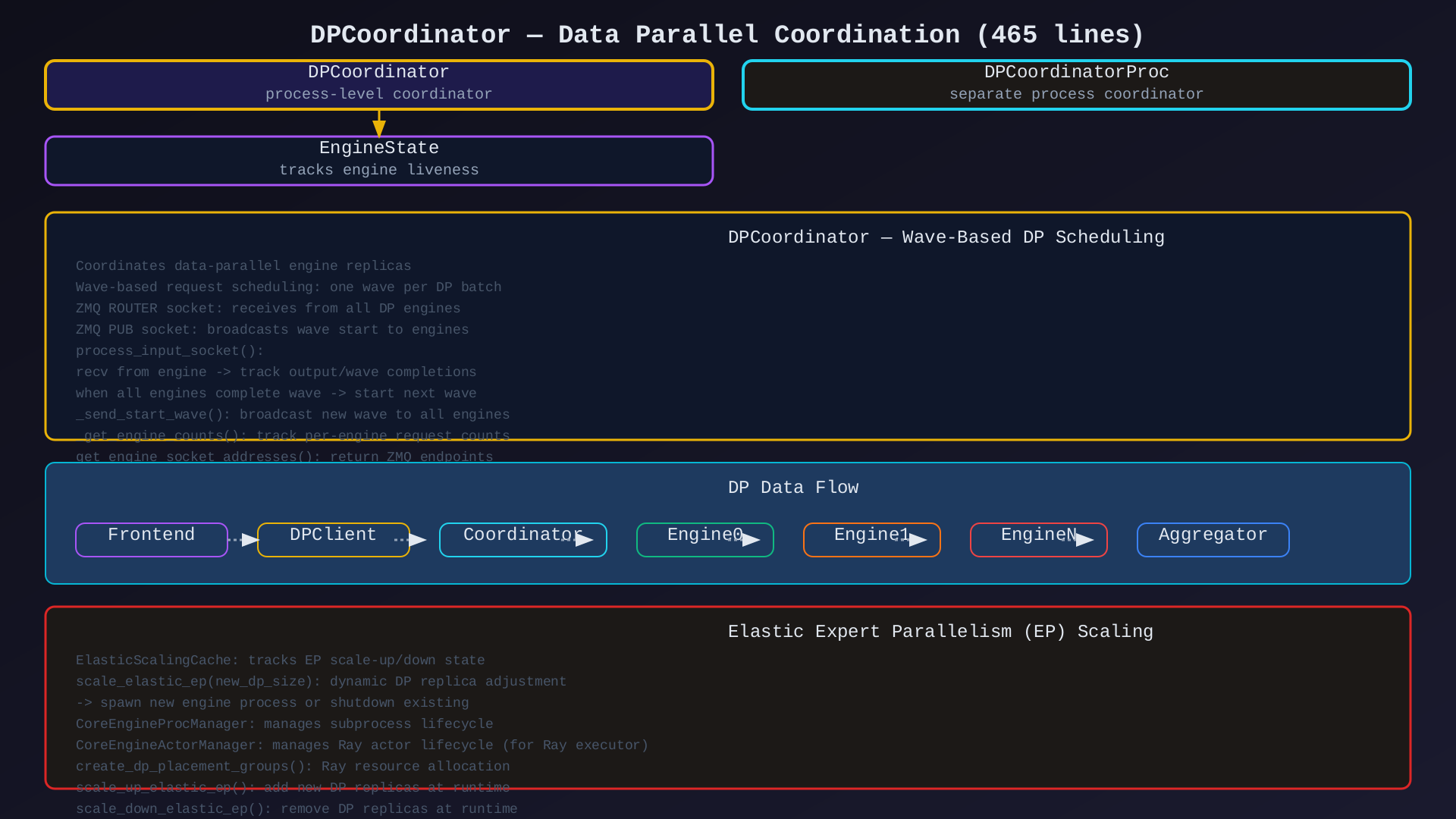
核心作用:数据并行协调------管理多 DP 引擎副本的波式调度、请求路由、弹性扩展。
关键类/方法:
| 类/方法 | 说明 |
|---|---|
DPCoordinator |
进程级 DP 协调器 |
DPCoordinatorProc |
独立进程协调器 |
EngineState |
引擎状态跟踪 |
process_input_socket() |
处理来自 DP engines 的输出 |
_send_start_wave() |
广播新 wave 到所有 engines |
_get_engine_counts() |
统计 per-engine 请求数 |
get_engine_socket_addresses() |
获取 ZMQ 地址 |
scale_up_elastic_ep() |
动态增加 DP 副本 |
scale_down_elastic_ep() |
动态减少 DP 副本 |
架构图 :见 07-dp-coordinator.svg
模块7:LLMEngine(llm_engine.py,424行)
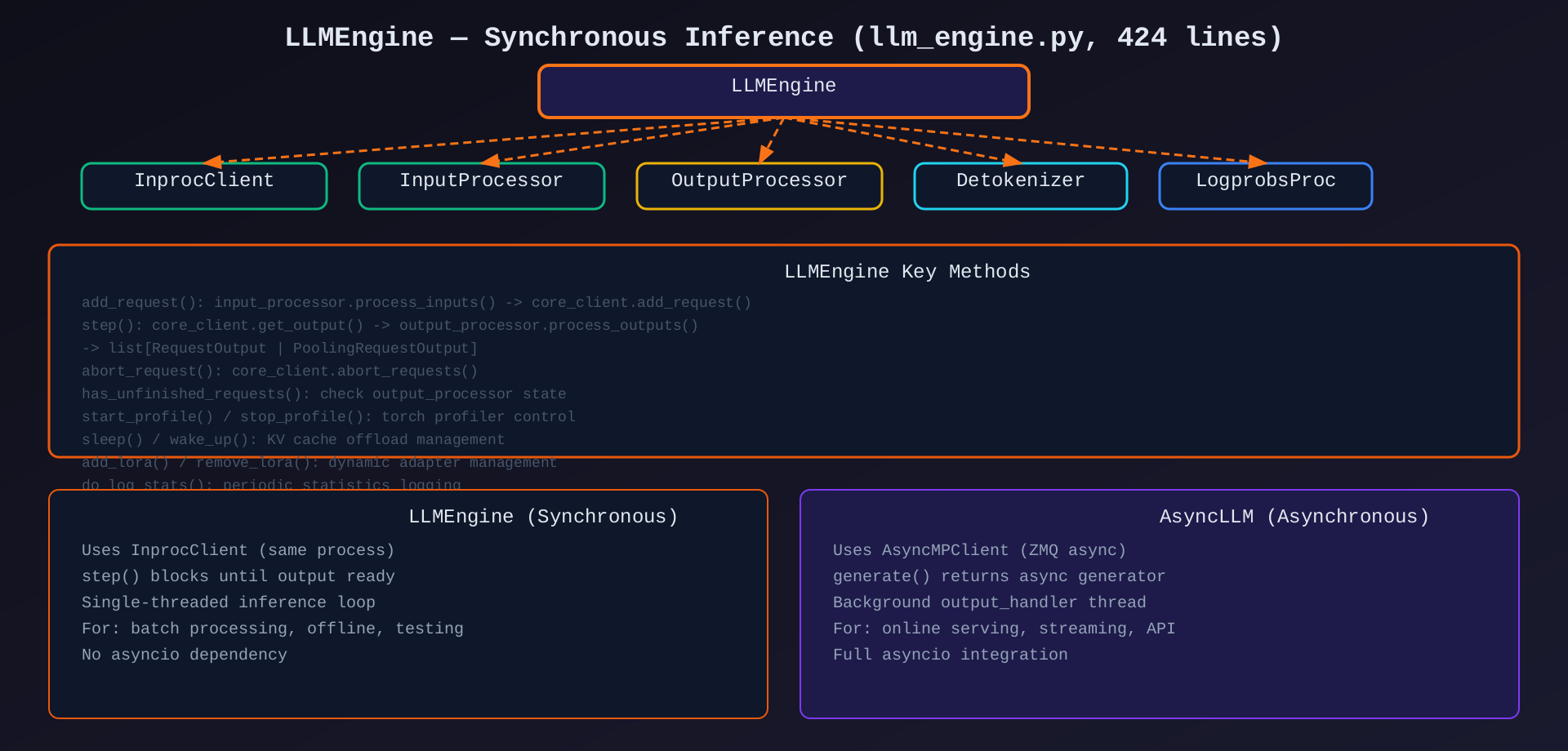
核心作用:同步推理接口,使用 InprocClient 直接调用 EngineCore。
关键方法 :add_request(), step(), abort_request(), has_unfinished_requests()
架构图 :见 08-llmengine-sync.svg
模块8:Detokenizer(detokenizer.py,339行)
核心作用:增量 detokenization------将 token IDs 转换为文本,支持 stop string 检测。
| 类 | 说明 |
|---|---|
IncrementalDetokenizer (ABC) |
增量解码基类 |
FastIncrementalDetokenizer |
HuggingFace fast tokenizer,byte-level 增量 |
SlowIncrementalDetokenizer |
非 fast tokenizer 回退,full re-decode |
check_stop_strings() |
检测停止字符串 |
模块9:LogprobsProcessor(logprobs.py,352行)
核心作用:处理采样 logprobs 和 prompt logprobs。
| 方法 | 说明 |
|---|---|
update_from_output() |
从 EngineCoreOutput 更新 logprobs |
_update_sample_logprobs() |
每步 token logprobs |
_update_prompt_logprobs() |
prompt token logprobs |
_correct_decoded_token() |
修复 tokenizer artifact |
_verify_tokens() |
验证采样 token 一致性 |
模块10:Engine Data Types(init.py,262行)
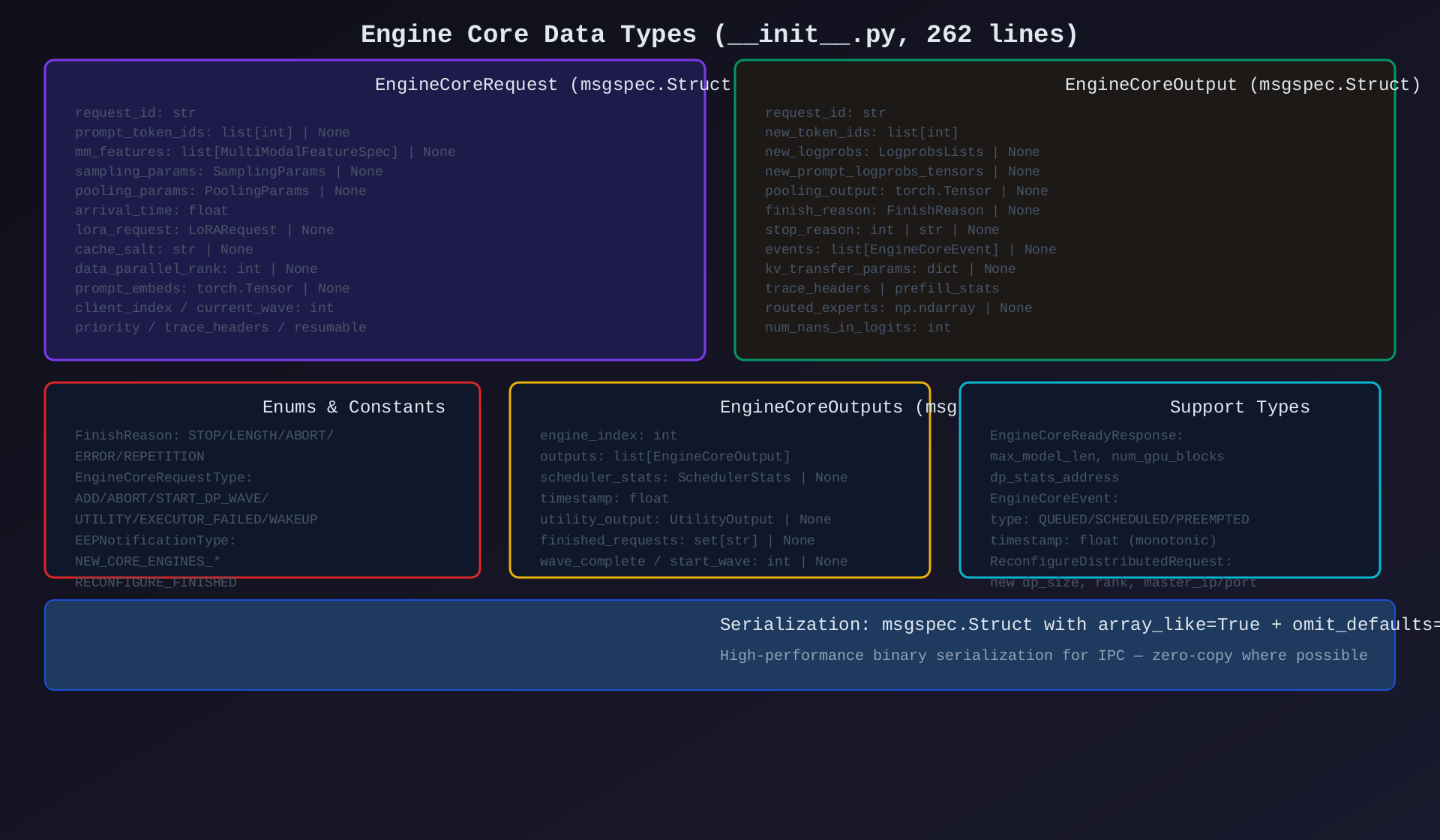
核心作用:定义所有跨模块传递的核心数据类型。
| 类型 | 说明 |
|---|---|
EngineCoreRequest |
前端→核心请求(msgspec.Struct) |
EngineCoreOutput |
核心→前端单请求输出 |
EngineCoreOutputs |
批量输出 + 调度统计 |
FinishReason |
完成原因枚举(STOP/LENGTH/ABORT/ERROR/REPETITION) |
EngineCoreRequestType |
请求类型(ADD/ABORT/UTILITY/...) |
EngineCoreEvent |
时间戳事件(QUEUED/SCHEDULED/PREEMPTED) |
UtilityOutput |
RPC 调用响应 |
EngineCoreReadyResponse |
引擎启动就绪响应 |
架构图 :见 09-engine-data-types.svg
模块11:支持模块
| 模块 | 行数 | 核心作用 |
|---|---|---|
| TensorIPC (tensor_ipc.py) | 178 | OOB 张量传输,用于多模态 tensor 的跨进程传递 |
| ParallelSampling (parallel_sampling.py) | 150 | n>1 并行采样,ParentRequest 拆分为多个子请求 |
| Utils (utils.py) | 1246 | CoreEngineProcManager/ActorManager、ZMQ 地址管理、引擎启动握手 |
| Exceptions (exceptions.py) | 18 | 自定义异常类型 |
三、模块调用关系与数据流
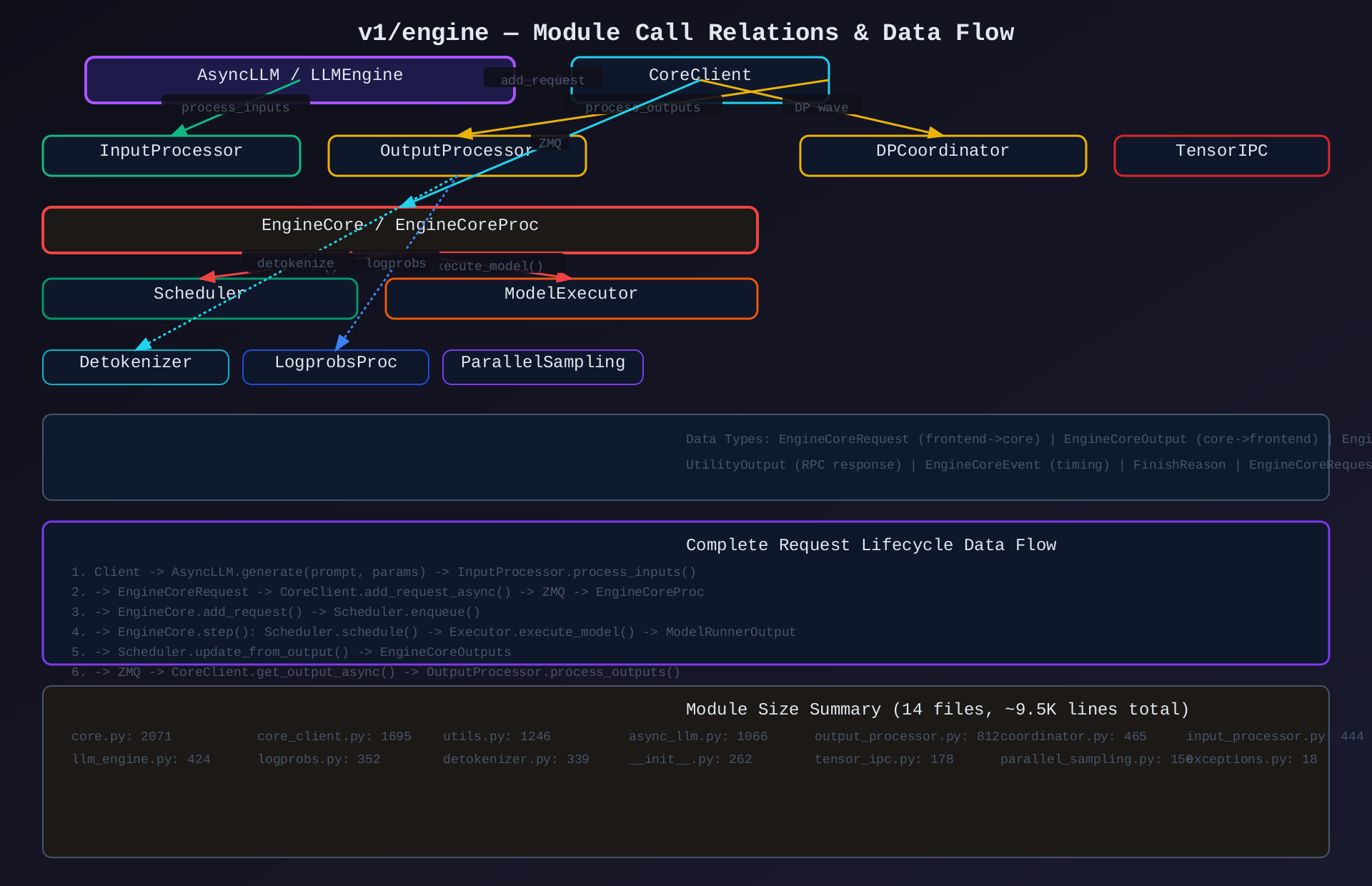
3.1 主要调用链
AsyncLLM
├── InputProcessor.process_inputs() → 验证+分词+MM
│ └── 返回 EngineCoreRequest
├── AsyncMPClient.add_request_async() → ZMQ 发送
│ └── EngineCoreProc._process_input_queue()
│ └── EngineCore.add_request() → Scheduler
├── AsyncMPClient.get_output_async() ← ZMQ 接收
│ └── EngineCoreProc._process_engine_step()
│ └── EngineCore.step() → schedule+execute+update
└── OutputProcessor.process_outputs() → 组装输出
├── Detokenizer.update() → token→text
├── LogprobsProcessor.update() → logprobs 处理
├── ParallelSampling.get_outputs() → n>1 合并
└── RequestState.make_request_output() → RequestOutput3.2 数据类型流转
Client Input
→ str prompt + SamplingParams
→ InputProcessor
→ EngineCoreRequest (msgspec binary)
→ ZMQ IPC
→ EngineCore
→ Request (v1/request.py)
→ SchedulerOutput
→ ModelRunnerOutput
→ EngineCoreOutput
→ EngineCoreOutputs (batch)
→ ZMQ IPC
→ EngineCoreOutputs
→ OutputProcessor
→ RequestOutput / PoolingRequestOutput3.3 关键交互模式
| 交互 | 方式 | 数据 |
|---|---|---|
| AsyncLLM → InputProcessor | 方法调用 | prompt + params → EngineCoreRequest |
| AsyncLLM → CoreClient | ZMQ async | EngineCoreRequest (binary) |
| CoreClient → EngineCoreProc | ZMQ ROUTER/PUSH | EngineCoreRequest / EngineCoreRequestType |
| EngineCore → Scheduler | 方法调用 | Request → SchedulerOutput |
| EngineCore → Executor | 方法调用 | SchedulerOutput → FutureModelRunnerOutput |
| EngineCore → CoreClient | ZMQ PUSH/PULL | EngineCoreOutputs (binary) |
| CoreClient → AsyncLLM | async queue | EngineCoreOutputs |
| AsyncLLM → OutputProcessor | 方法调用 | EngineCoreOutputs → RequestOutput |
| DPCoordinator ↔ Engines | ZMQ PUB/SUB | wave signals |
3.4 完整请求生命周期
- 入站 :
AsyncLLM.generate(prompt, params)→InputProcessor.process_inputs() - 预处理 :validate → tokenize → MM features →
EngineCoreRequest - 发送 :
CoreClient.add_request_async()→ ZMQ →EngineCoreProc - 入队 :
EngineCore.add_request()→Scheduler.enqueue() - 调度 :
EngineCore.step()→Scheduler.schedule()→SchedulerOutput - 执行 :
Executor.execute_model()→ModelRunnerOutput - 更新 :
Scheduler.update_from_output()→EngineCoreOutputs - 回传 :ZMQ →
CoreClient.get_output_async()→EngineCoreOutputs - 后处理 :
OutputProcessor.process_outputs()→ Detokenize + Logprobs - 交付 :
RequestOutput→ yield to client
四、设计模式总结
| 模式 | 应用位置 | 说明 |
|---|---|---|
| 前后端分离 | AsyncLLM ↔ EngineCore | 前端处理 I/O,后端处理推理 |
| 代理模式 | EngineCoreClient | 6种实现屏蔽 IPC 细节 |
| 策略模式 | InprocClient/MPClient/DPClient | 按场景选择通信方式 |
| 模板方法 | EngineCore.step() | 固定流程,step_with_batch_queue 变体 |
| 工厂模式 | make_client() / from_vllm_config() | 运行时选择实现 |
| 观察者模式 | _idle_state_callbacks | 引擎空闲事件通知 |
| 命令模式 | EngineCoreRequestType | ADD/ABORT/UTILITY 命令序列化 |
| 享元模式 | mm_receiver_cache | MM 特征缓存复用 |
| Finalizer 模式 | BackgroundResources | weakref.finalize 确保 ZMQ 清理 |
| Wave 模式 | DPCoordinator | 批量波式 DP 调度,避免竞态 |
五、关键指标
| 指标 | 数值 |
|---|---|
| 总代码量 | ~9.5K 行(14 文件) |
| 最大文件 | core.py (2071 行) |
| 客户端类型 | 6 种 |
| IPC 机制 | ZMQ (ROUTER/PUSH/PULL/PUB/SUB) |
| 序列化 | msgspec.Struct (binary, zero-copy) |
| DP 协调 | wave-based scheduling |
| 弹性扩展 | Elastic EP (subprocess / Ray actor) |
| 流式支持 | asyncio.Queue per-request |
| 增量 detokenization | Fast + Slow 两种实现 |
六、架构亮点与设计权衡
亮点
- 进程隔离:EngineCoreProc 在子进程运行,避免 GIL,前后端独立
- msgspec 二进制序列化:array_like=True + gc=False,IPC 吞吐极高
- 6种 Client 灵活选择:从同进程调试到分布式负载均衡全覆盖
- Wave-based DP:避免 DP 竞态,确保所有 replica 同步
- Elastic EP:运行时 DP 副本动态增减,适应负载变化
- 增量 Detokenizer:byte-level 增量解码,避免 full re-decode
- Streaming 原生支持:asyncio.Queue + output_handler 线程,零延迟交付
权衡
- ZMQ 复杂性:多 socket 类型 + handover + 最终器清理逻辑复杂
- EngineCore 双模式:step() vs step_with_batch_queue() 增加维护负担
- DPAsyncMPClient 层次深:4层继承(MPClient→AsyncMPClient→DPAsyncMPClient→DPLBAsyncMPClient)
- OutputProcessor 职责多:detokenize + logprobs + parallel sampling + streaming 全在一个类
- Handshake 协议:启动握手(startup_handshake)逻辑分散在 core.py 和 utils.py
报告生成时间:2026-04-19 | 代码版本:vllm main branch