vLLM v1 Core --- 系统级架构深度分析
分析范围:
vllm/v1/core/目录,14个Python文件,~7.9K行代码。Core 是 v1 推理系统的"大脑"------调度器决定每步执行哪些请求,KV Cache 管理器控制显存分配与回收。
Dark Terminal 风格架构图 10 张,见
diagrams/子目录。
一、整体架构概览
1.1 设计思路
v1 Core 采用 KV Cache 驱动调度架构:
- 调度与缓存强耦合:Scheduler 的每个决策都以 KV Cache 可用空间为硬约束
- Block 粒度管理:所有显存以 Block 为单位分配/回收/共享,类似虚拟内存的 Page
- Prefix Caching:基于 Block 内容哈希实现块级去重,相同前缀零额外开销
- 多类型缓存协调:Full Attention / Sliding Window / Chunked Local / Mamba 四种缓存策略共存
核心设计哲学:
- 永不 OOM:KV budget 约束保证显存不会溢出,不够就 preempt
- 最大化复用:Prefix Caching 块级去重,相同前缀只需计算一次
- Token 级调度:没有 prefill/decode 阶段概念,每步统一按 token 预算分配
- 策略可插拔:4种 SingleTypeKVCacheManager + 3种 Coordinator 适配不同模型
1.2 架构模式
| 模式 | 应用 |
|---|---|
| 策略模式 | 4种 SingleTypeKVCacheManager(Full/Sliding/Chunked/Mamba) |
| 协调者模式 | KVCacheCoordinator 统一多组缓存管理 |
| 享元模式 | BlockPool + Prefix Caching 块级复用 |
| 观察者模式 | KVCacheMetricsCollector 事件采集 |
| 工厂模式 | create_request_queue() / get_request_block_hasher() |
| 模板方法 | SingleTypeKVCacheManager(ABC) 统一接口 |
| 引用计数 | KVCacheBlock.ref_cnt 实现块共享 |
1.3 整体运行流程
EngineCore.step()
↓
Scheduler.schedule()
├── Phase 1: Schedule RUNNING (decode)
│ └── Compute num_new_tokens per request
├── Phase 2: Schedule WAITING (prefill/resume)
│ ├── Check KV budget: kv_cache_manager.allocate_slots()
│ ├── Check encoder budget: encoder_cache_manager.can_allocate()
│ └── If exceeded: _preempt_request() -> free + requeue
└── Phase 3: Build SchedulerOutput
↓
Executor.execute_model(scheduler_output)
↓
Scheduler.update_from_output()
├── Accept/reject spec decode tokens
├── Check finish: stop/length/abort/error/repetition
└── _free_request() -> release KV blocks + encoder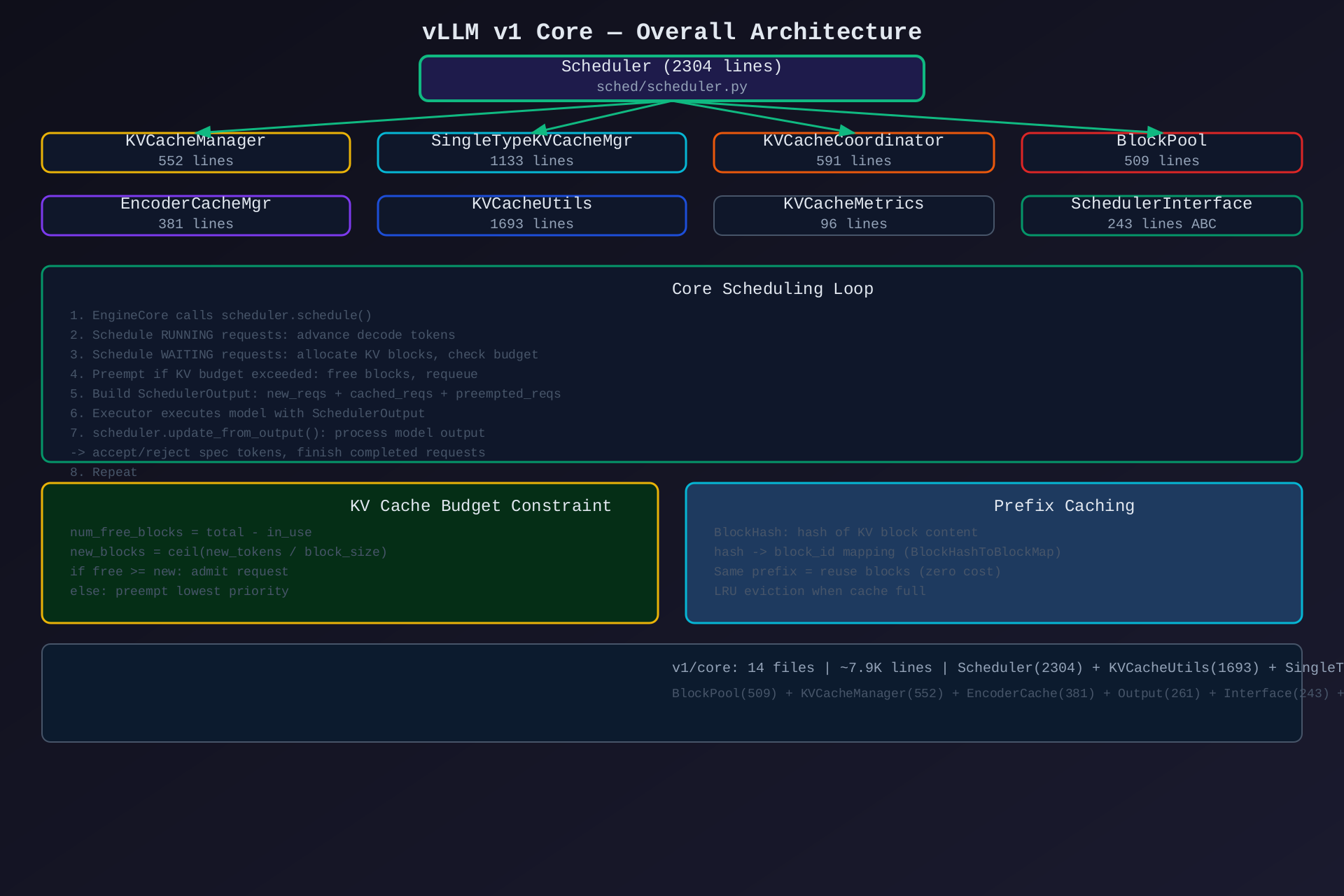
二、子模块划分
模块1:Scheduler(sched/scheduler.py,2304行)
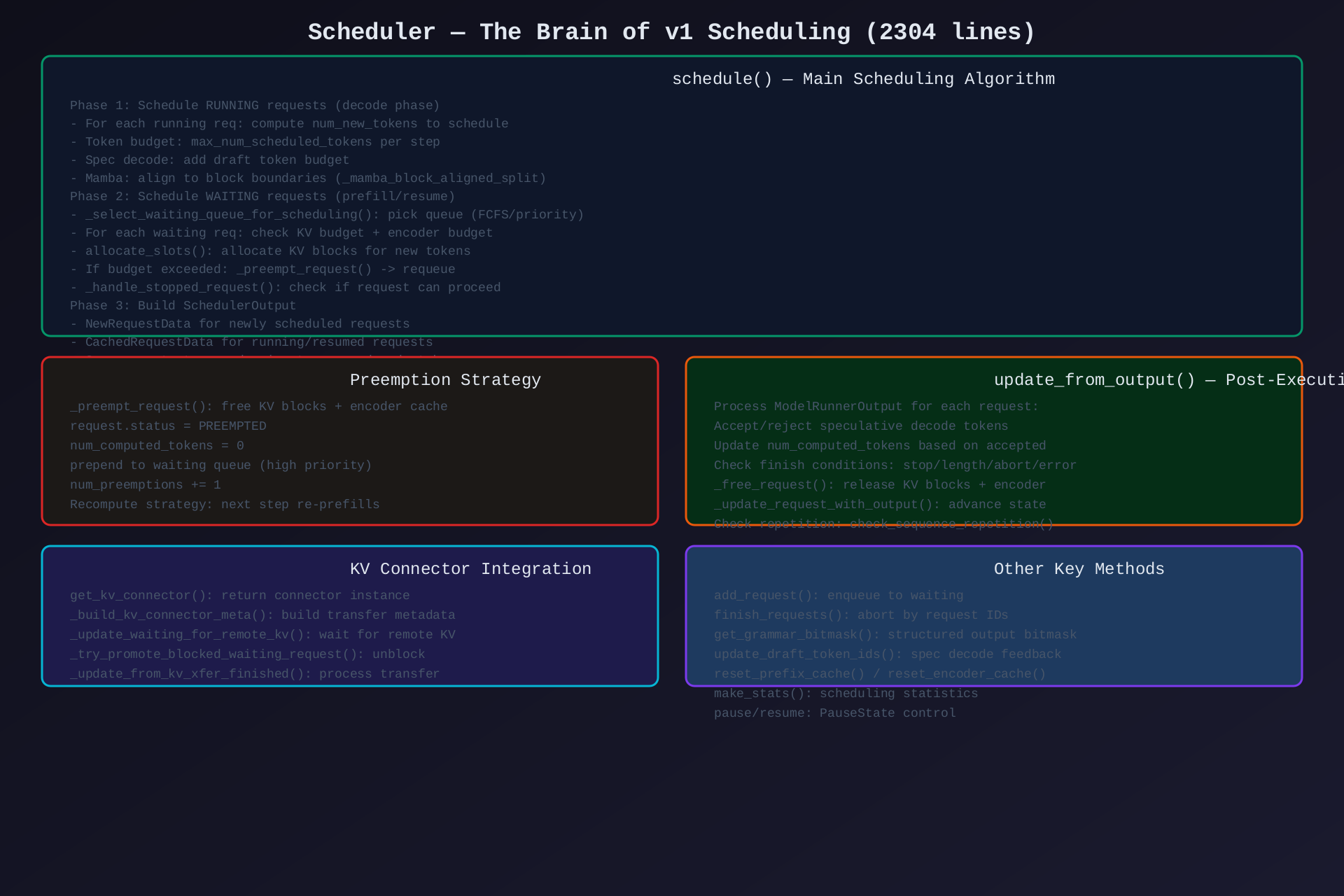
核心作用:v1 调度大脑------决定每步执行哪些请求、分配多少 token 预算、何时 preempt。
关键方法:
| 方法 | 说明 |
|---|---|
schedule() |
主调度算法:RUNNING→WAITING→build output |
_preempt_request() |
驱逐请求:free blocks + requeue |
_update_after_schedule() |
推进 computed_tokens |
update_from_output() |
处理模型输出:spec verify + finish |
add_request() |
入队新请求 |
finish_requests() |
按 ID 中止请求 |
get_grammar_bitmask() |
结构化输出 bitmask |
update_draft_token_ids() |
投机解码反馈 |
_mamba_block_aligned_split() |
Mamba block 对齐 |
_try_schedule_encoder_inputs() |
MM 编码器预算分配 |
_select_waiting_queue_for_scheduling() |
选择调度队列(FCFS/Priority) |
_handle_stopped_request() |
处理暂停请求 |
_update_waiting_for_remote_kv() |
等待远程 KV 传输 |
make_stats() |
调度统计 |
调度算法核心:
- RUNNING 优先:先调度运行中请求的 decode tokens
- Token Budget :每步最多
max_num_scheduled_tokens个 token - KV Budget 硬约束 :
num_free_blocks >= required_blocks - Preempt if exceeded:free 最低优先级请求的 KV blocks
- Spec Decode:draft token 预算额外分配
- Encoder Budget:MM 输入 token 独立预算
架构图 :见 02-scheduler.svg
模块2:KVCacheManager(kv_cache_manager.py,552行)
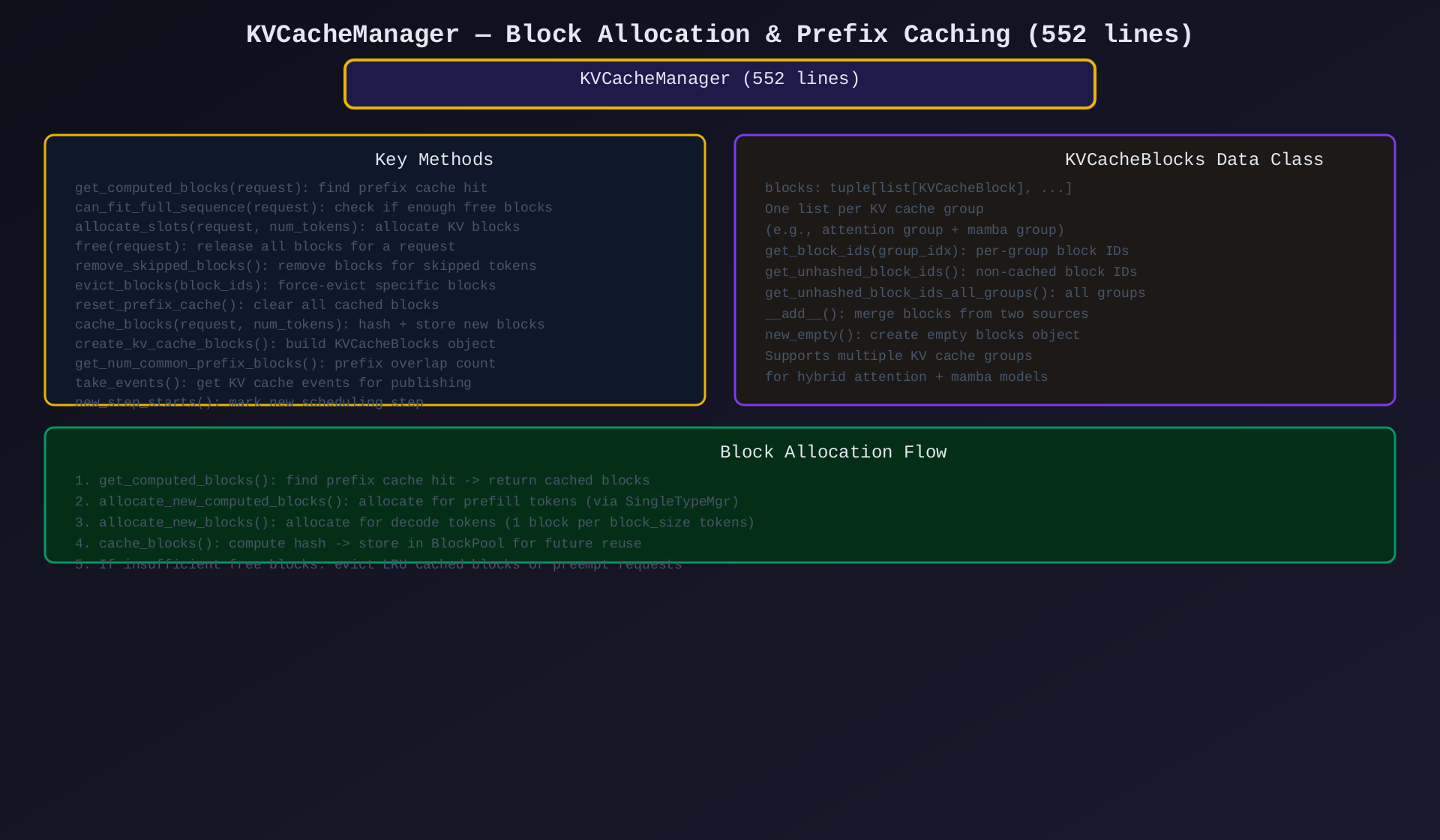
核心作用:Block 分配/回收/哈希的高层接口------管理多组 KV cache,协调 prefix caching。
关键类/方法:
| 类/方法 | 说明 |
|---|---|
KVCacheBlocks |
Block 数据容器,支持多组 |
KVCacheManager |
Block 管理主类 |
get_computed_blocks() |
查找 prefix cache 命中 |
allocate_slots() |
分配 KV blocks(通过 Coordinator) |
free() |
释放请求的所有 blocks |
cache_blocks() |
哈希 + 存储新 blocks |
evict_blocks() |
强制驱逐指定 blocks |
reset_prefix_cache() |
清空 prefix cache |
get_num_common_prefix_blocks() |
计算前缀重叠 |
create_kv_cache_blocks() |
构建 KVCacheBlocks 对象 |
new_step_starts() |
标记新调度步开始 |
架构图 :见 03-kv-cache-manager.svg
模块3:SingleTypeKVCacheManager(single_type_kv_cache_manager.py,1133行)
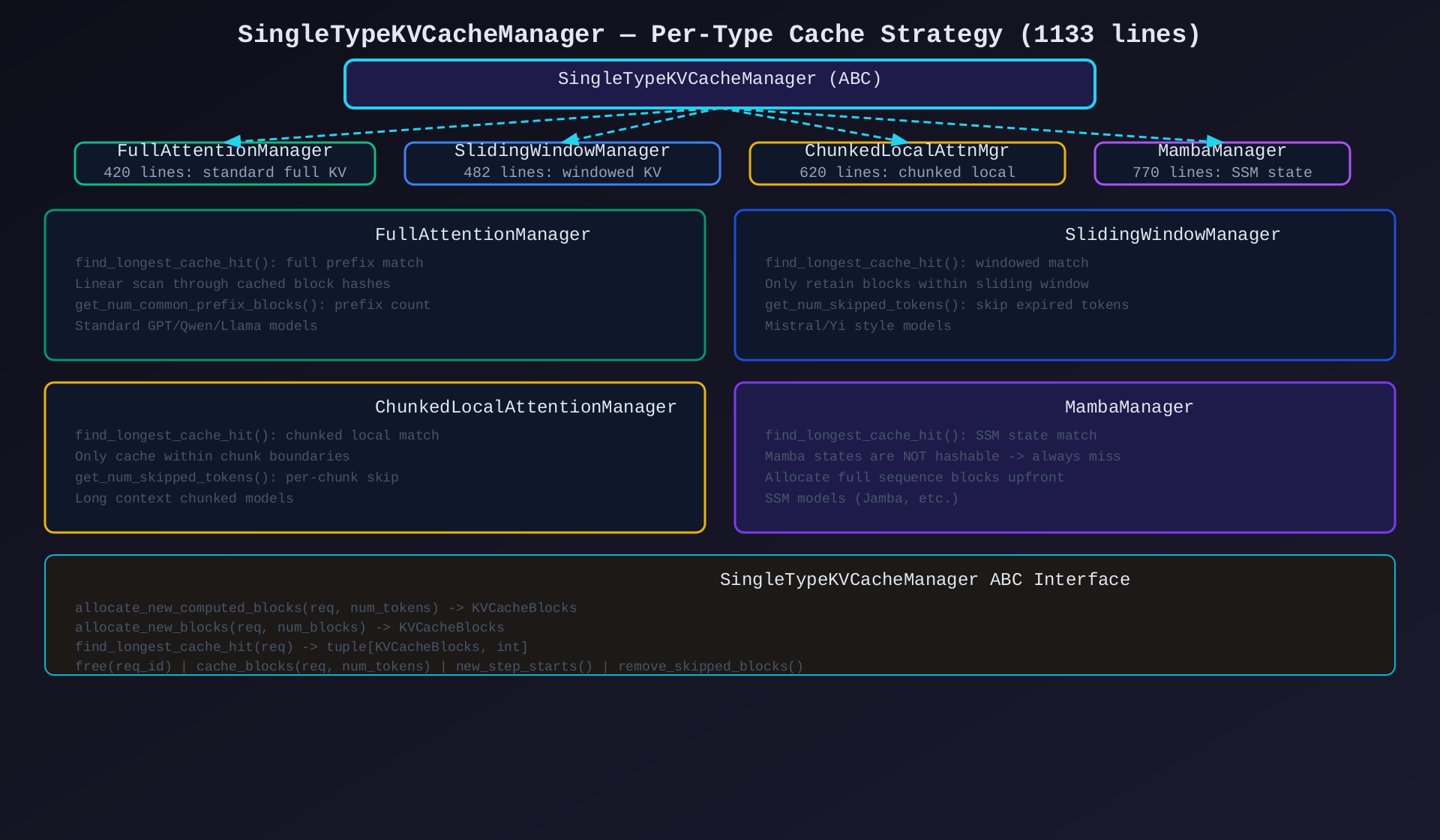
核心作用:每种 KV cache 类型的具体管理策略------统一 ABC + 4种实现。
4种实现:
| 实现 | 行数 | 适用模型 | 特点 |
|---|---|---|---|
FullAttentionManager |
420 | GPT/Qwen/Llama | 标准 full KV,线性扫描 prefix |
SlidingWindowManager |
482 | Mistral/Yi | 滑动窗口,仅保留窗口内 blocks |
ChunkedLocalAttentionManager |
620 | 长上下文模型 | 分块局部注意力,chunk 边界限制 |
MambaManager |
770 | Jamba/SSM | SSM 状态不可哈希,始终 miss |
ABC 接口:
| 方法 | 说明 |
|---|---|
allocate_new_computed_blocks() |
为 prefill tokens 分配 blocks |
allocate_new_blocks() |
为 decode tokens 分配 blocks |
find_longest_cache_hit() |
查找最长 prefix 缓存命中 |
free() |
释放请求 blocks |
cache_blocks() |
哈希 + 存储 blocks |
remove_skipped_blocks() |
移除跳过的 blocks |
get_num_skipped_tokens() |
计算可跳过的 token 数 |
架构图 :见 04-single-type-kv-cache-manager.svg
模块4:BlockPool(block_pool.py,509行)
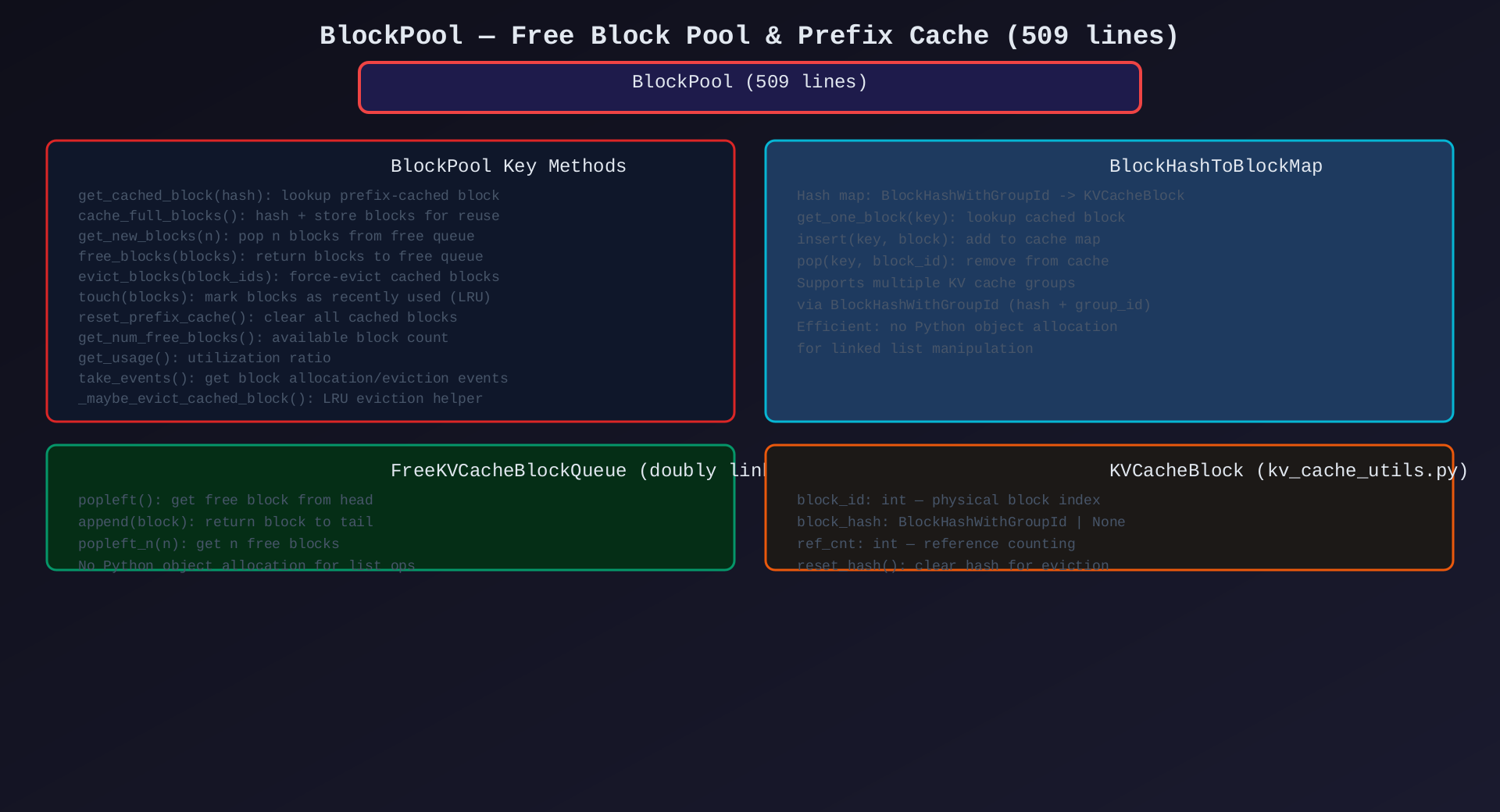
核心作用:空闲 block 池 + prefix cache 存储------物理 block 的生命周期管理。
关键类/方法:
| 类/方法 | 说明 |
|---|---|
BlockPool |
Block 池主类 |
BlockHashToBlockMap |
hash → block 映射(prefix cache) |
FreeKVCacheBlockQueue |
双向链表空闲队列(零 Python 对象分配) |
get_new_blocks(n) |
从空闲队列取 n 个 blocks |
free_blocks() |
归还 blocks 到空闲队列 |
get_cached_block(hash) |
查找 prefix-cached block |
cache_full_blocks() |
哈希 + 存储到 cache map |
evict_blocks() |
LRU 驱逐 cached blocks |
touch() |
标记最近使用(更新 LRU) |
reset_prefix_cache() |
清空所有 cached blocks |
get_num_free_blocks() |
可用 block 计数 |
take_events() |
获取 block 事件(分配/驱逐) |
架构图 :见 05-block-pool.svg
模块5:KVCacheCoordinator(kv_cache_coordinator.py,591行)
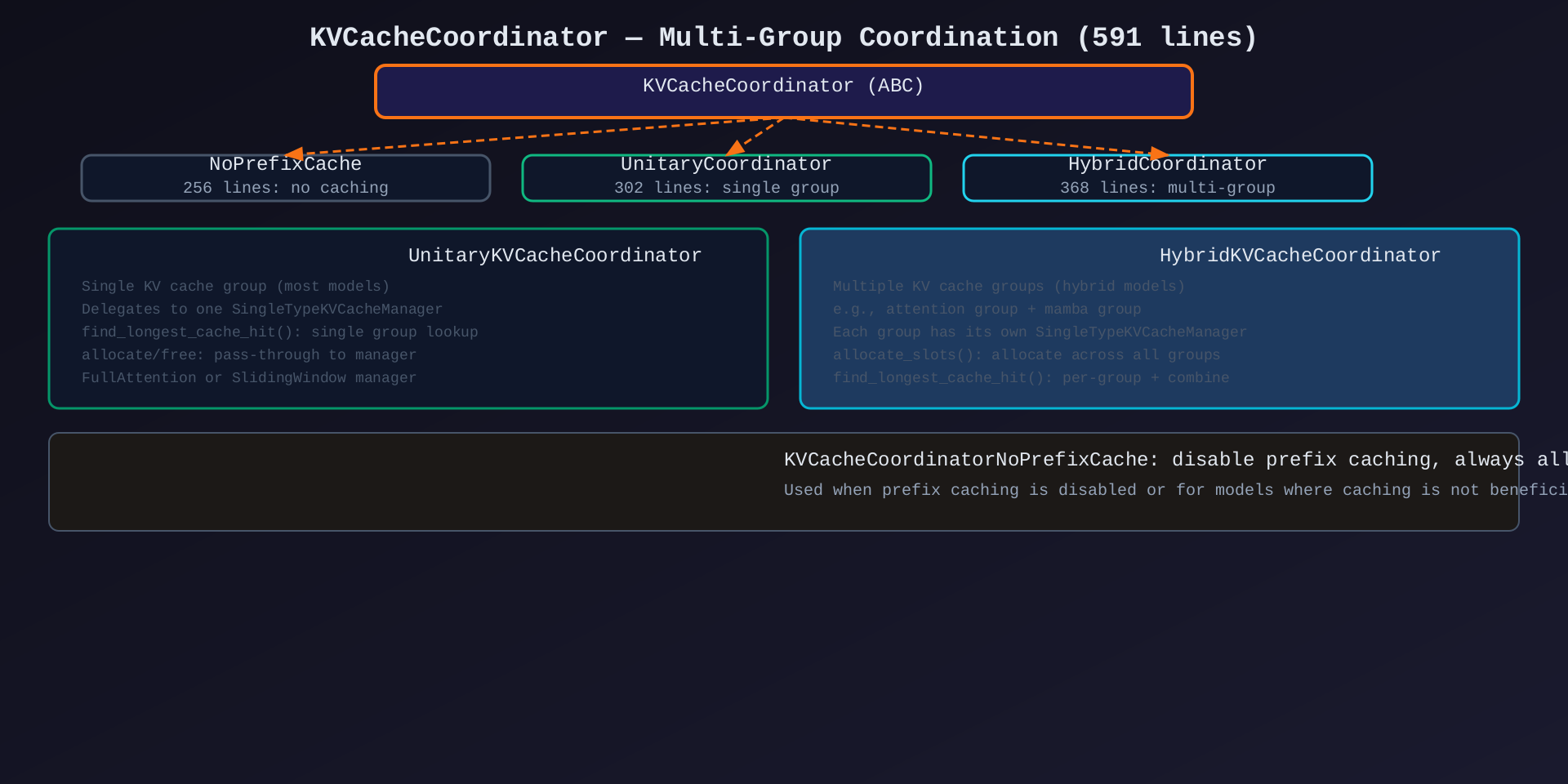
核心作用:多组 KV cache 的协调管理------统一接口,内部委托给多个 SingleTypeKVCacheManager。
3种实现:
| 实现 | 行数 | 适用场景 |
|---|---|---|
KVCacheCoordinatorNoPrefixCache |
256 | 禁用 prefix caching |
UnitaryKVCacheCoordinator |
302 | 单组 KV cache(大多数模型) |
HybridKVCacheCoordinator |
368 | 多组 KV cache(attention + mamba hybrid) |
架构图 :见 06-kv-cache-coordinator.svg
模块6:EncoderCacheManager(encoder_cache_manager.py,381行)
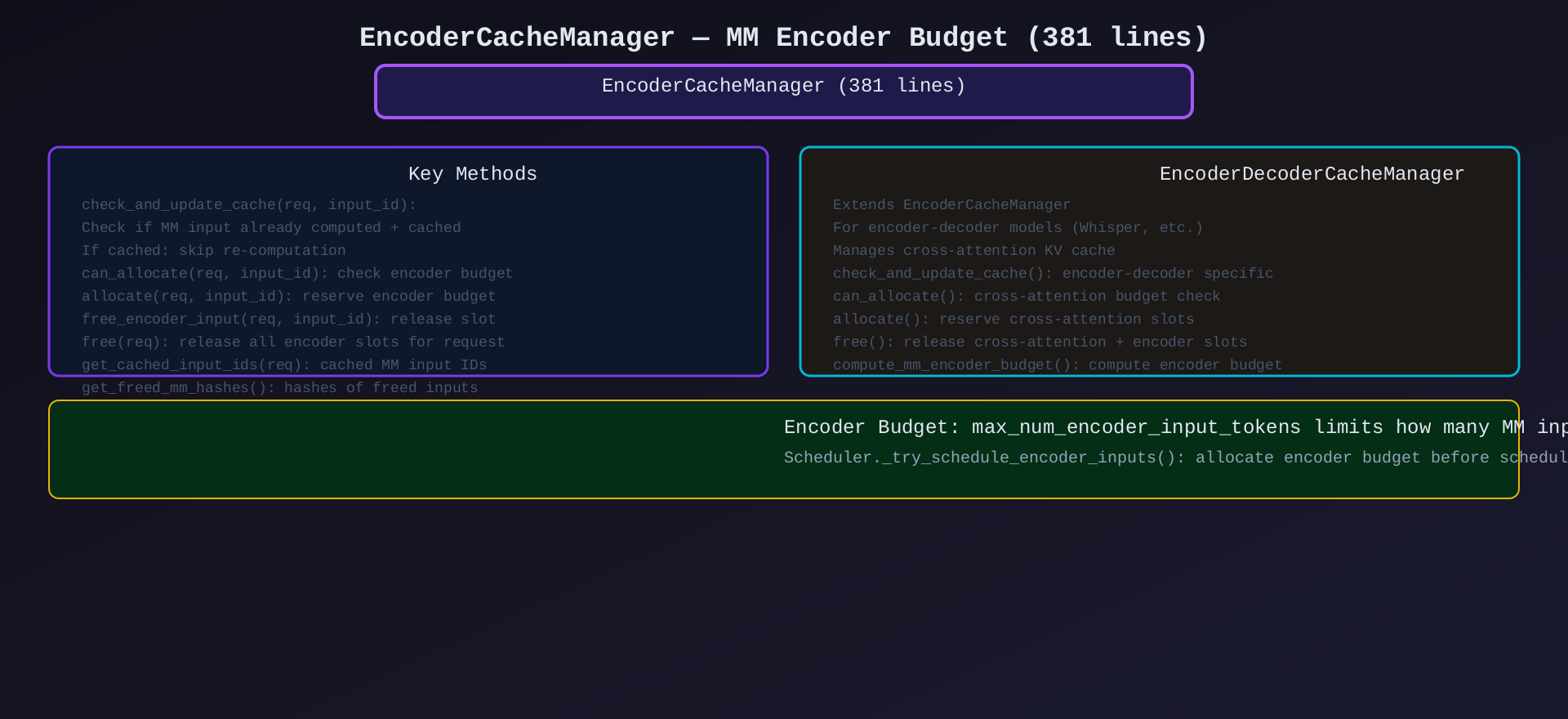
核心作用:多模态编码器预算管理------控制每步 MM 输入的计算量。
关键类/方法:
| 类/方法 | 说明 |
|---|---|
EncoderCacheManager |
编码器缓存管理 |
EncoderDecoderCacheManager |
编码器-解码器扩展(Whisper 等) |
check_and_update_cache() |
检查 MM 输入是否已缓存 |
can_allocate() |
检查编码器预算 |
allocate() |
预留编码器预算 |
free_encoder_input() |
释放单个编码器 slot |
free() |
释放请求的所有编码器 slots |
compute_mm_encoder_budget() |
计算 MM 编码器预算 |
架构图 :见 07-encoder-cache-manager.svg
模块7:SchedulerOutput & Data Types(sched/output.py 261行 + sched/interface.py 243行)
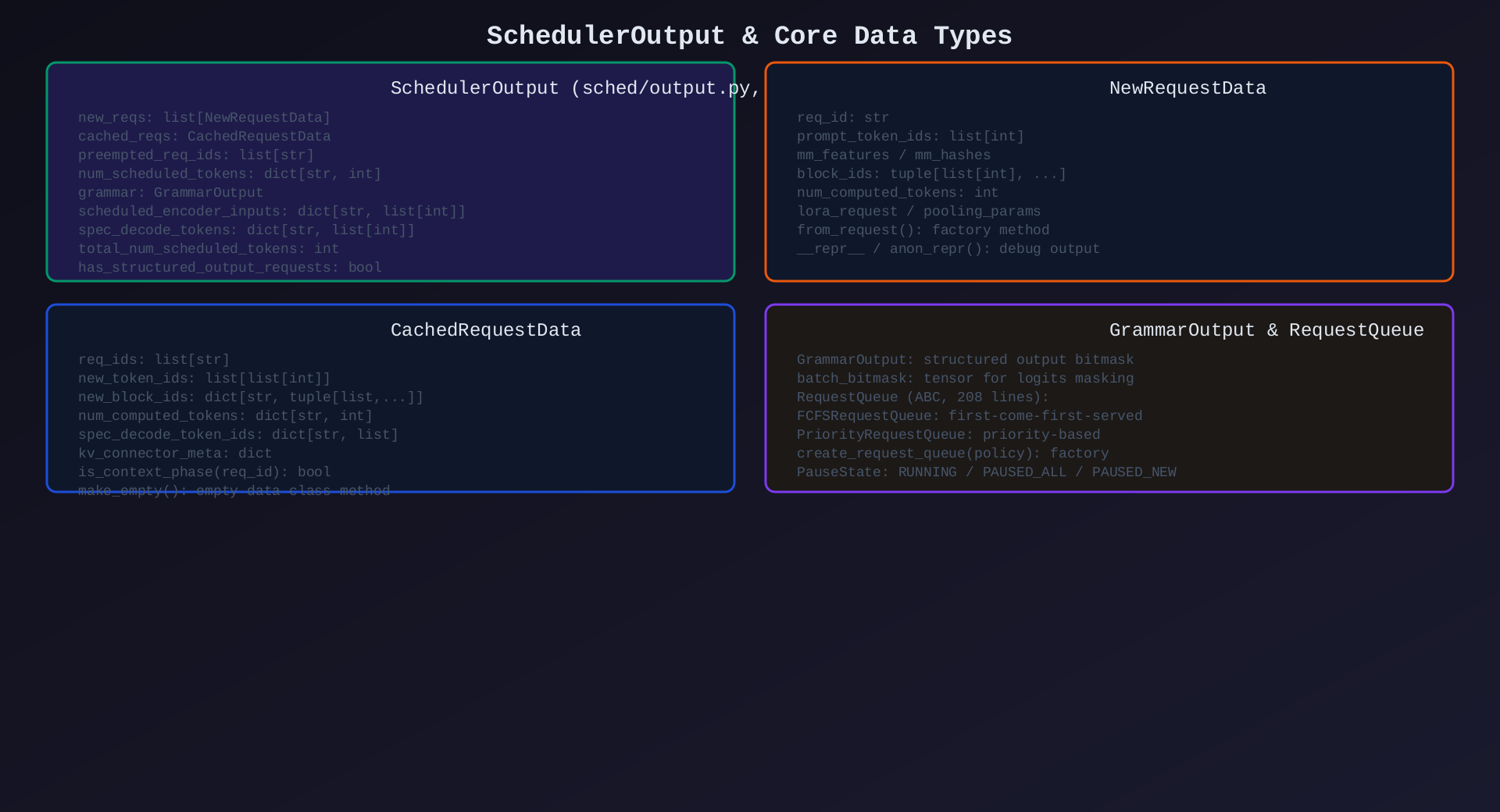
核心作用:调度器输出的数据结构------连接 Core 和 Worker 的契约。
关键类型:
| 类型 | 说明 |
|---|---|
SchedulerOutput |
调度器完整输出(new + cached + preempted) |
NewRequestData |
新请求数据(token_ids, block_ids, mm_features) |
CachedRequestData |
运行/恢复请求数据(new_tokens, new_blocks) |
GrammarOutput |
结构化输出 bitmask |
PauseState |
暂停状态(RUNNING / PAUSED_ALL / PAUSED_NEW) |
SchedulerInterface(ABC) |
调度器抽象接口 |
架构图 :见 08-scheduler-output-data-types.svg
模块8:KVCacheUtils(kv_cache_utils.py,1693行)
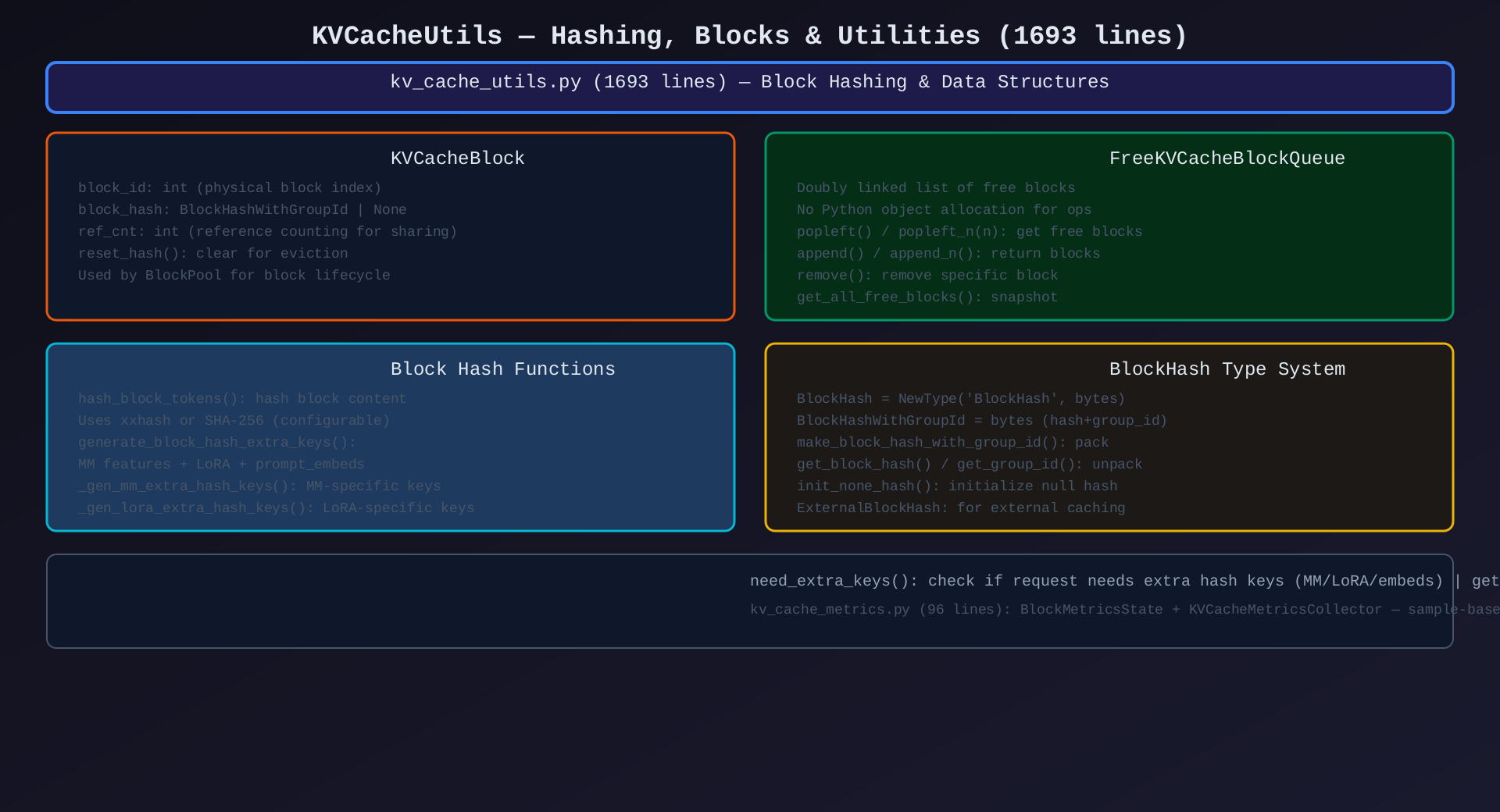
核心作用:Block 哈希计算、数据结构定义、辅助函数------整个 KV cache 系统的基础设施。
关键组件:
| 组件 | 说明 |
|---|---|
KVCacheBlock |
物理块(block_id + hash + ref_cnt) |
FreeKVCacheBlockQueue |
双向链表空闲队列 |
BlockHash / BlockHashWithGroupId |
块哈希类型 |
hash_block_tokens() |
块内容哈希(xxhash/SHA-256) |
generate_block_hash_extra_keys() |
MM/LoRA/embeds 额外哈希键 |
get_request_block_hasher() |
请求级哈希器工厂 |
need_extra_keys() |
检查是否需要额外哈希键 |
架构图 :见 09-kv-cache-utils.svg
模块9:RequestQueue(sched/request_queue.py,208行)
核心作用:请求队列管理------FCFS 和 Priority 两种策略。
| 实现 | 说明 |
|---|---|
FCFSRequestQueue |
先来先服务(默认) |
PriorityRequestQueue |
优先级调度 |
模块10:辅助模块
| 模块 | 行数 | 职责 |
|---|---|---|
sched/utils.py |
130 | 重复检测、stop 检查、列表操作 |
sched/async_scheduler.py |
60 | 异步调度器(覆盖 _update_after_schedule) |
kv_cache_metrics.py |
96 | Block 生命周期指标采集 |
三、模块调用关系与数据流

3.1 主要调用链
Scheduler.schedule()
├── kv_cache_manager.new_step_starts()
├── For RUNNING requests:
│ └── compute num_new_tokens (token budget)
├── For WAITING requests:
│ ├── kv_cache_manager.allocate_slots()
│ │ ├── coordinator.allocate_new_computed_blocks()
│ │ │ └── single_type_mgr.allocate_new_computed_blocks()
│ │ │ └── block_pool.get_new_blocks() / get_cached_block()
│ │ └── coordinator.allocate_new_blocks()
│ ├── encoder_cache_manager.can_allocate()
│ └── If exceeded: _preempt_request()
│ ├── kv_cache_manager.free()
│ │ └── coordinator.free() -> single_type_mgr.free()
│ │ └── block_pool.free_blocks()
│ └── encoder_cache_manager.free()
└── Build SchedulerOutput
└── NewRequestData + CachedRequestData + GrammarOutput
Scheduler.update_from_output()
├── Accept/reject spec tokens
├── kv_cache_manager.cache_blocks()
│ └── coordinator.cache_blocks() -> single_type_mgr.cache_blocks()
│ └── block_pool.cache_full_blocks()
├── _free_request() for finished
│ ├── kv_cache_manager.free()
│ └── encoder_cache_manager.free()
└── Return updated state3.2 数据类型流转
Request (from EngineCore)
→ Scheduler.add_request()
→ RequestQueue (waiting)
→ schedule(): allocate KV blocks
→ SchedulerOutput
→ EngineCore → Executor → Worker
→ ModelRunnerOutput
→ Scheduler.update_from_output()
→ Request finished or advancing3.3 关键交互
| 调用方 | 被调用方 | 数据 | 方式 |
|---|---|---|---|
| Scheduler | KVCacheManager | allocate/free/cache blocks | 方法调用 |
| KVCacheManager | Coordinator | per-group operations | 委托 |
| Coordinator | SingleTypeKVCacheManager | per-type operations | 委托 |
| SingleTypeMgr | BlockPool | get/free/cache blocks | 方法调用 |
| Scheduler | EncoderCacheManager | allocate/free encoder slots | 方法调用 |
| Scheduler | RequestQueue | add/pop/prepend requests | 方法调用 |
| Scheduler | KVCacheUtils | hash computation | 函数调用 |
| Scheduler | sched/utils.py | repetition/stop checks | 函数调用 |
四、设计模式总结
| 模式 | 应用位置 | 说明 |
|---|---|---|
| 策略模式 | 4种 SingleTypeKVCacheManager | 每种缓存类型独立策略 |
| 协调者模式 | KVCacheCoordinator | 统一多组缓存管理 |
| 享元模式 | BlockPool + Prefix Caching | 块级去重复用 |
| 引用计数 | KVCacheBlock.ref_cnt | 共享块的安全释放 |
| 模板方法 | SingleTypeKVCacheManager(ABC) | 统一接口+差异化实现 |
| 工厂模式 | create_request_queue() | 按策略创建队列 |
| 观察者模式 | KVCacheMetricsCollector | Block 生命周期事件 |
| LRU 缓存 | BlockHashToBlockMap + FreeQueue | 驱逐策略 |
五、关键指标
| 指标 | 数值 |
|---|---|
| Core 总代码量 | ~7.9K 行(14 文件) |
| Scheduler | 2304 行(最大文件) |
| KVCacheUtils | 1693 行 |
| SingleTypeKVCacheManager | 1133 行 |
| Coordinator | 591 行 |
| BlockPool | 509 行 |
| KVCacheManager | 552 行 |
| 缓存策略类型 | 4 种(Full/Sliding/Chunked/Mamba) |
| Coordinator 类型 | 3 种(NoCache/Unitary/Hybrid) |
| 队列策略 | 2 种(FCFS/Priority) |
| Block 哈希算法 | xxhash(默认)/ SHA-256 |
六、架构亮点与设计权衡
亮点
- KV Cache 驱动调度:以显存为硬约束,确保永不 OOM
- 4种缓存策略可插拔:Full/Sliding/Chunked/Mamba 适配所有模型
- Prefix Caching 块级去重:相同前缀零额外开销,显著降低延迟和显存
- Token 级统一调度:没有 prefill/decode 阶段概念,通用覆盖 chunked prefill + spec decode
- 引用计数块共享:prefix-cached block 可被多个请求安全共享
- Hybrid Coordinator:attention + mamba 多组缓存统一协调
- FreeKVCacheBlockQueue:零 Python 对象分配的链表操作
权衡
- Scheduler 耦合 KV Manager:调度器直接操作缓存管理器,未来可能需要抽象
- SingleTypeKVCacheManager ABC 过重:find_longest_cache_hit() 每种实现都很长
- Mamba 无 prefix caching:SSM 状态不可哈希,始终 miss
- Preempt = 重新计算:preempted 请求的 KV blocks 全部释放,下次从头重算
- Coordinator 层次多:Scheduler→Manager→Coordinator→SingleTypeMgr→BlockPool 五层委托
报告生成时间:2026-04-19 | 代码版本:vllm main branch