前言
在做这套东西前,我一直是有个疑虑的。ai 这些持续的习惯、记忆积累是否是无用功,会不会刚做的差不多,这个工具就过时了,又要花时间切一套新的重新积累(比如之前的 cursor)。而且多设备的记忆并不同步,做这件事的性价比可能并不高。
但最近我有了另一条思路:可以将记忆做成一个完整的项目,给不同的平台做不同的适配方案。这样一来,切换工具时只需要让 ai 处理一下适配层即可,可以放心的存储记忆或者迁移。
并且同样的,你的 skills、agents 乃至于临时搓的工具脚本,都可以纳入这个架构下。切换设备时,只需要你把这个仓库 clone 下来,就能拥有和之前完全相同的能力了。
原理
claude code、codex 等工具,一定是有一个记忆文件的,用于存储你强调的习惯
在 claude code 中为:根目录/.claude/CLAUDE.md
在 codex 中为:.codex/AGENTS.md
我们可以利用这个机制,将这些入口,都软链至我们的记忆项目,这样一来,无论在哪个平台运行 ai,都能进入到这个项目的入口中,载入我们的记忆。
渐进式披露上下文
渐进加载是指,claude 会开始对话时,会自动读取 文件,将其加入上下文并开始对话。随后每读取文件夹时,都会尝试加载该文件夹下的 claude.md 并加入上下文中。
我们可以将记忆项目进行合理的规划与分层,使记忆结构更加有条理,方便管理
渐进机制仅在 claude code 存在,在非 claude 平台,比如 codex,就只能靠提示词进行约束了,例如:
##claude.md 规则
进入目录时,必须先读取当前目录下对应 claude.md
原则:先读 claude.md,再读写具体文件 --- 没有例外,违反此规则 = 任务失败
不过目前看下来效果还不错,codex 能完全遵守该规则去读文件
项目结构
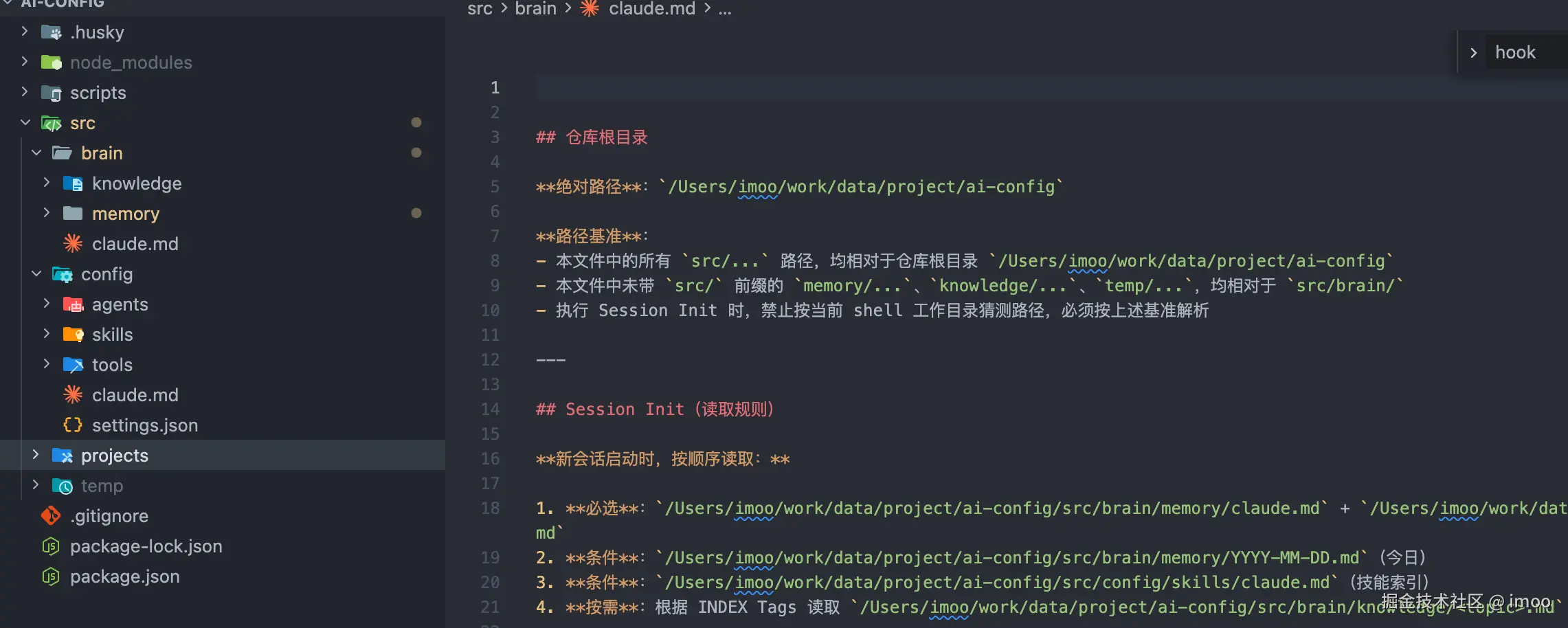
- src/brain 负责记忆层
- src/config 负责工具层
- src/projects 负责业务层
- src/temp 用于存储一些临时文件
外层的作用是引入各类工具文件,比如 node_modules、husky、.gitgnore 等,不引入这一层的话, 这些文件会和上述核心层同级,占据额外的上下文。
实现思路
记忆层
当前的 brain 层,主要是结合了分享会上的长期记忆方案以及 claude 的渐进加载机制。我们只需要在入口增加这样的说明,它就会自动进到 brain 层:
md
---
## Session Init(读取规则)
**新会话启动时,按顺序读取:**
1. **必选**:`/Users/imoo/work/data/project/ai-config/src/brain/claude.md`
2. **必选**:`/Users/imoo/work/data/project/ai-config/src/brain/memory/claude.md` + `/Users/imoo/work/data/project/ai-config/src/brain/knowledge/claude.md`
3. **条件**:`/Users/imoo/work/data/project/ai-config/src/brain/memory/YYYY-MM-DD.md`(今日)
4. **条件**:`/Users/imoo/work/data/project/ai-config/src/config/skills/claude.md`(技能索引)
5. **按需**:根据 Index Tags 读取 `/Users/imoo/work/data/project/ai-config/src/brain/knowledge/<topic>.md`
6. **写入前必读**:新增或改写 `knowledge/*.md` 前,先读取 `/Users/imoo/work/data/project/ai-config/src/brain/knowledge/knowledge-format.md`
→ 完成后回复:`记忆系统已加载`
---brain 层里有两部分是核心:
-
knowledge:存放关键规则,可以手动维护
-
memory:存放每次对话的一些关键记录,有点像日记本
knowledge 和 memory 层,会有对应的 claude.md 及每天的日期文件,通过 claude 的自动读取机制,能很方便的读到对当前层级设定的规则。如
md
# Memo Index
| Date | Summary | Tags |
|-------|---------|------|
---
**说明:**
- 每日 memory 存放在 `memory/YYYY-MM-DD.md`
- `checkpoint` 时若未更新当日 `memory`,视为 `checkpoint` 未完成
- memory 只记录今日完成的工作清单(Done),不含反思或经验
- 每条 Done 尽量写结果,不写流水账式命令记录
- 若某条结论未来可复用,应拆到 knowledge,并在 memory 中只保留简述
- Index 用于快速检索,不加载全部 memory
md
# Knowledge Index
| Usage | File | Summary | Tags |
|-------|------|---------|------|
---
**说明:**
- knowledge 存放可复用的稳定结论、方法论、用户偏好
- Agent 启动时只加载 `claude.md` 索引
- 新增或改写 knowledge 前,先读取 `knowledge-format.md`
- `Usage` 记录 knowledge 文件被读取和实际使用的次数,默认按次数降序排序
- 每次 checkpoint 时,基于本轮实际读取过的 knowledge 文件更新 `Usage`
- 只收录稳定规则、用户偏好、项目长期结论
- 避免记录仅对单次会话有价值的过程细节
- 需要某个主题时,按 Tags 匹配到对应文件再读取
---记忆层的设计其实相当简单,于我而言这两块即可应对大部分情况,可根据需要进行拓展。不过过于复杂的设计,很可能导致模型上下文庞大时更新知识流程出错。
有同学可能发现了,这里只介绍了如何让 agent 读取记忆,写入记忆单独放在了后文,先介绍大致层级。
工具层
- skill 和 agents 层其实就是做个迁移。
- tools 层则是各种封装好的工具
这里介绍几个例子:
bb-browser:也就是 ai 操控浏览器的一个浏览器插件 + cli。
这个工具可以让 agent 直接操纵你现在浏览器,从而跳过鉴权等操作,我将使用说明置入到了 skill 中。这里会有一个很好的开发体验,在当前架构下, ai 可以同时读取插件内容、cli 内容、skill 内容,一旦出现变更,可以同步处理这三端的代码与上下文
飞书中转能力:也就是龙虾的将飞书消息与 claude 打通的能力。
这里实际上需要本地起一个 ws 服务,用于持续让 bot 的接收飞书发来的消息,并起一个 claude 进行处理。这一步需要你提前去建好飞书应用,并且开通以下权限才能正常。
json
{
"scopes": {
"tenant": [
"contact:user.employee_id:readonly",
"docs:doc",
"docs:permission.member:create",
"docs:permission.member:delete",
"docs:permission.member:retrieve",
"docx:document",
"im:chat",
"im:chat:read",
"im:chat:update",
"im:message",
"im:message.group_at_msg:readonly",
"im:message.group_msg",
"im:message.p2p_msg:readonly",
"im:resource"
],
"user": []
}
}projects 层
负责链接你的各种业务项目,能让模型获得充分的上下文
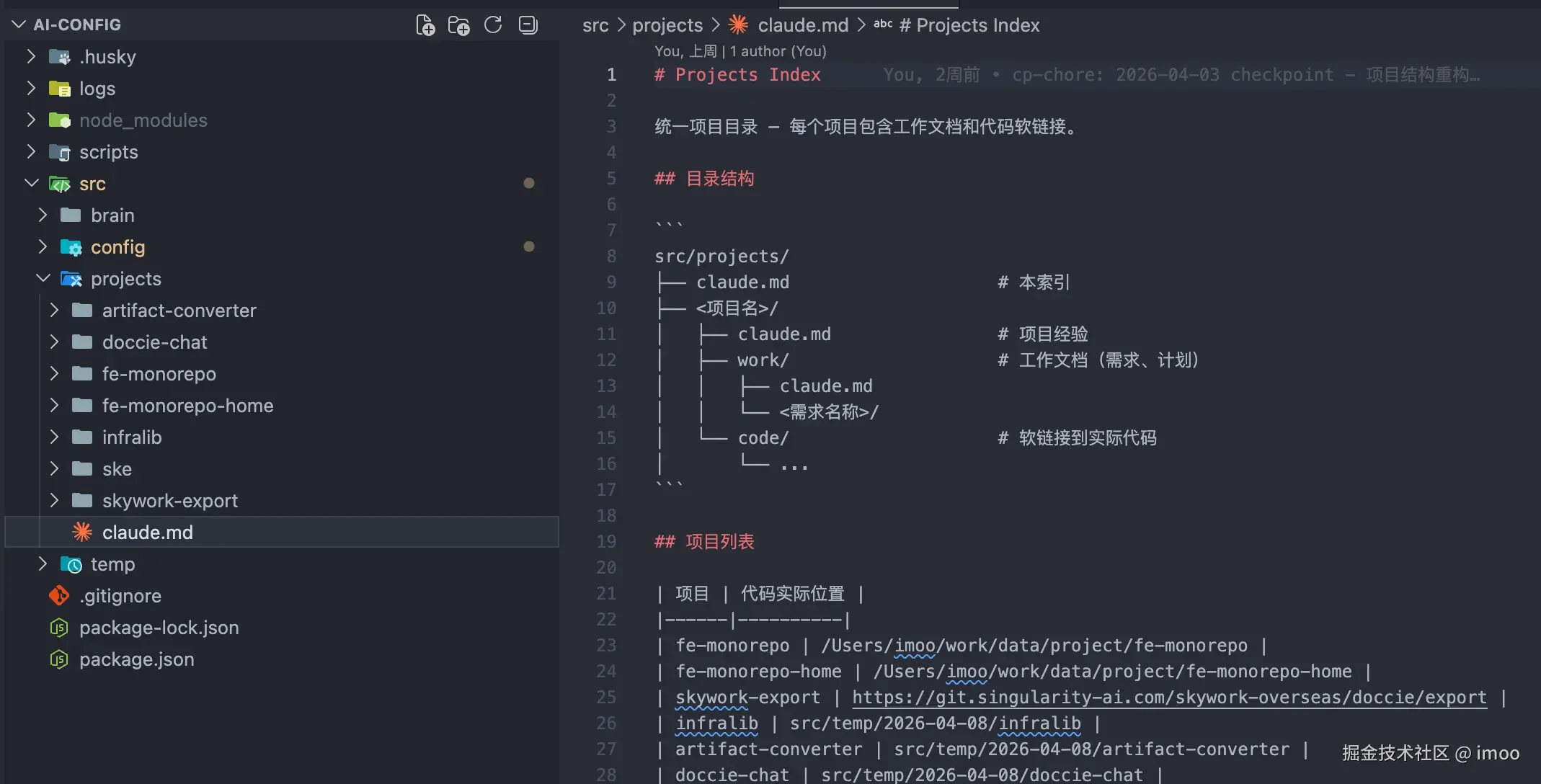
每个项目我切了两层,work 放需求级别的文件夹,code 则是放项目源码。这里我的 code 基本是软链过来的,因为我的工作目录划分了不同的文件夹,不太好直接扔到这里来。
另外我也不希望子项目的改动直接带到我的记忆系统的改动中,最多留个需求文档供复盘,所以这里的 git 我是直接忽略了 code 层。
这里涉及到了比较多的规则,还有频繁使用的软链接、需求写法等,所以我直接封装了一个 project-work 的 skill 来处理这件事,也避免给 agent 带来噪音,所有需求通用类的要求会被收敛到一起

这一层值得一提的是,由于记忆系统的存在,就算你只开了某个子项目,你也能直接在子项目的 ai 终端中读取到其他项目的上下文。
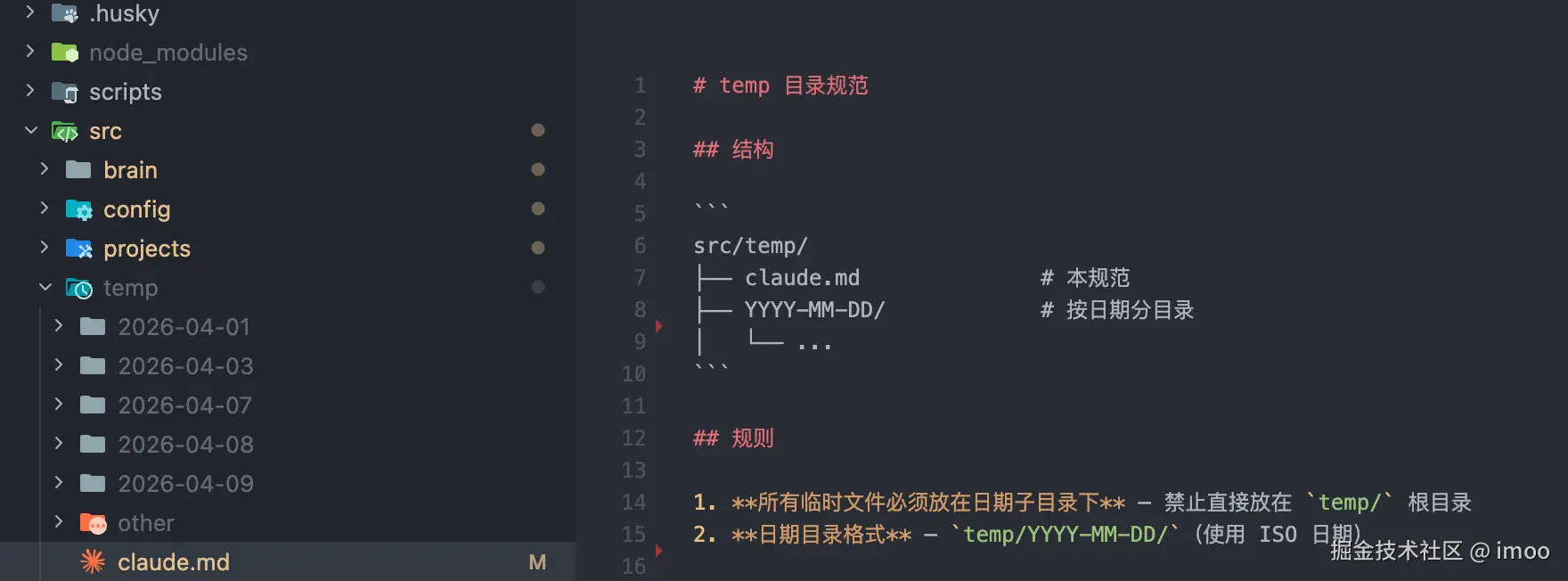
temp 层
这层就放各类的临时文件了,比如我的计划、报告、临时 git 仓库等,没有说明放置位置的文件都会被收到这里,用日期进行划分,这里只临时存放,所以也同样会被 git 忽略。
关于知识增长
上文中谈到了记忆层的读取,这里则着重于记忆层的写入。
理想情况下,我们需要大模型每次被纠错 / 了解了我们的新习惯时,都自动写入记忆到知识层。
但随着上下文的增长,自动处理会逐渐跑偏甚至失效,所以我们要两手准备,即自动和手动。
手动记录
我增加了一个 checkpoint skill,当我完成当前任务,并且觉得此次对话有价值时,会发送 checkpoint 给 ai,由于在 claude.md 中约定了这个规范,ai 会自动执行该 skill
md
---
## Checkpoint
用户输入 "checkpoint" 时,使用 `checkpoint` skill 执行。
---该 skill 就是一个工作流:
md
---
name: checkpoint workflow
description: checkpoint 总流程 - 先沉淀 memory 与 knowledge,再更新索引,最后执行 add/commit/push
---
# Checkpoint Workflow
## 结论
- `checkpoint` 只在用户明确输入 `checkpoint` 时触发,不能按"收尾""结束 session"等语义自动推断。
- checkpoint 的顺序固定为:回顾本轮内容 -> 写 memory -> 写 knowledge -> 更新索引 -> 自检 -> `git add` -> `git commit` -> `git push`。
- 不写 memory,checkpoint 不完整;没有完成知识沉淀,checkpoint 也不完整;未完成 `push`,checkpoint 也不完整。
- 用户明确输入 `checkpoint` 后,先运行 `git status`,识别已有脏改动和本轮工作范围。
- `git add` / `git commit` / `git push` 必须放在沉淀完成之后统一执行,提交前再运行一次 `git status`,确认没有遗漏文件。
## 适用规则
- 执行前先读取:
- `src/brain/memory/claude.md`
- `src/brain/knowledge/claude.md`
- `src/brain/knowledge/knowledge-format.md`
- `src/brain/knowledge/reinforced-rules.md`
- 如需补充用户偏好或错误模式,再按索引读取相关 `prefer-*.md` / `error-*.md` 文件。
- 如本轮涉及 `temp/` 写入,再读取 `src/temp/claude.md`。
- 写入 `memory/YYYY-MM-DD.md` 时只写 Done,不混入偏好、规则、反思。
- 写入 knowledge 时区分三类目标:
- `knowledge/<topic>.md`:稳定结论、方法论、排查结论
- `prefer-*.md`:稳定协作偏好
- `reinforced-rules.md`:反复犯错且需要强制检查的规则
- 更新完内容后同步更新对应索引:
- 新增或改写 knowledge 时,更新 `src/brain/knowledge/claude.md`
- 更新当日 memory 时,更新 `src/brain/memory/claude.md`
- 更新 `src/brain/knowledge/claude.md` 时,同步把本轮实际读取过的 knowledge 文件 `Usage` 加一,并按 `Usage` 降序重排。
- 如果 checkpoint 开始时已存在与本轮无关的改动,先识别边界,不把无关文件误纳入提交。
- 若改动包含 `src/projects/`,不能直接提交,必须先展示 `git diff` 并等待用户确认。
- `git push` 默认属于 checkpoint 标准流程,除非用户明确说这次只提交不推送,或远端/网络阻塞导致无法完成。
- 完成后报告:
- memory 写入位置
- 更新过的 knowledge 文件
- 更新过的索引
- 执行的 git 流程
- 若未提交,说明阻塞原因其中,根据本轮对话更新 knowledge 与 memory 是核心,也是 agent 能持续成长的关键。
利用 checkpoint 新增的 commit,前缀我规定为了 cp-,这是为了防止跟自己手动更新的部分产生混淆,另外后续也需要根据这个标识,进行一些特殊的处理
这里 checkpoint 用其他的词也行,不过如果太常见可能容易令模型歧义
自动记录
自动记录是高频触发项,需要记录的点主要是 knowledge,此类约束需要在每次对话中都用到,所以需要加到我们的入口文件 claude.md 里
md
## 记忆系统(Memory Protocol)
**核心原则**:所有工作过程必须沉淀到记忆系统,不写 memory 或者知识没正确积累都视为任务未完成
| 类型 | 位置 | 要求 |
|------|------|------|
| **memory** | `memory/YYYY-MM-DD.md` | 今日完成的工作清单(Done) |
| **knowledge** | `knowledge/<topic>.md` | 可复用的稳定结论、用户偏好、方法论 |
**即时沉淀:**
- 如果在对话过程中被用户纠正,或已经确认形成了可复用的稳定结论,必须先更新对应 knowledge,再继续当前工作
- 不要等到 checkpoint 才补记这类内容,避免遗漏或表述失真
- 写入时只记录稳定结论本身,不把一次性上下文和命令过程塞进 knowledge合理性评估
脚本侧约束
众所周知,模型的幻觉是相当严重的,在知识增长的时候很容易写错文件,比如我们已经指定了 src/brain 为记忆层的情况,它仍然可能写到外层的 /brain。
这种情况其实在项目开发中是挺常见的,比如【git 分支命名规范不对的时候,直接拦截,不允许提交】,和这个其实是类似的情况,所以理所当然的请出了我们的 husky
husky 主要负责在 git 提交过程中加入钩子,在这里的应用就是拦截不合规范的提交
我在外层的 /script 中增加了一个脚本,并配有白名单机制,只允许设置好的文件类型、目录等被提交
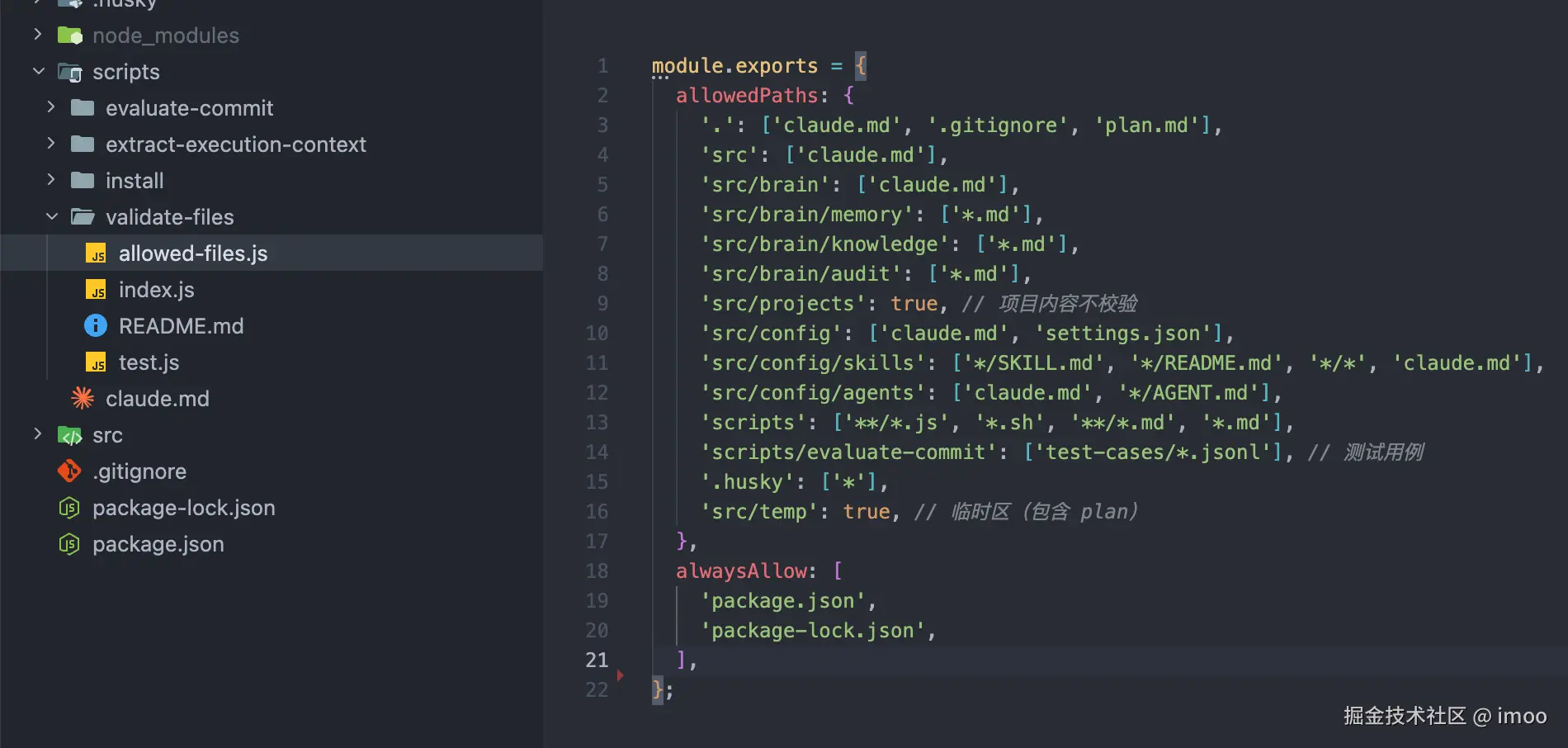
如此一来,模型即使出了幻觉,也会在 checkpoint 提交时被卡住,返回的错误会让 ai 重新去读取当前设置的文件规则,从而在大体架构上约束住模型。
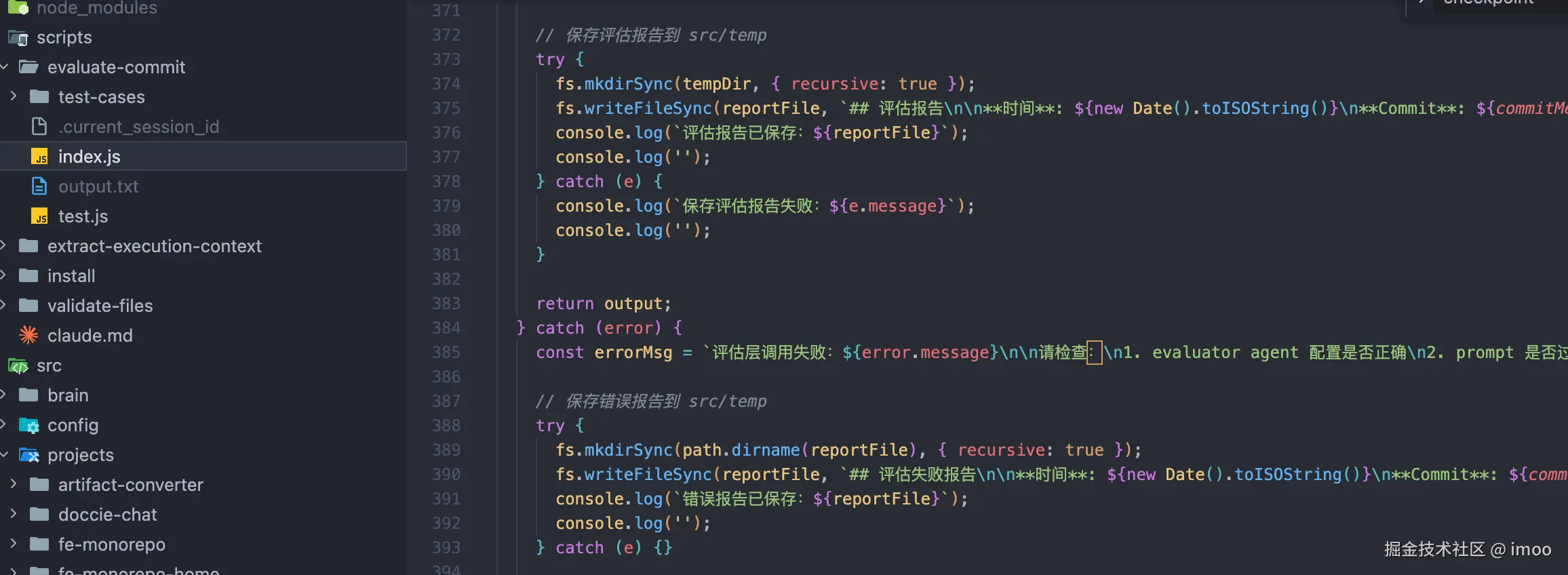
模型侧评估
根据上面的 husky 拦截原理,我们还可以再加入一个评估 agent,用于整体评估该 checkpoint 是否符合预期。它会按照以下步骤执行:
- 新开一个空白的 agent,避免给自己生成的结果开后门
- 收集当前对话的完整流程,git diff 作为上下文
- 根据设定好的评估规则进行评估
评估若拒绝,则 commit 会被打断,并且将错误抛回给主流程继续处理
关于飞书豪华加强版
不得不吹的一点,当你舍弃了龙虾这些封装的好的库,你将得到无穷的灵活度。
case1: 当到饭点的时候,你的 claude code 只跑了一半,这时候就可以用手机接过该对话,放心去吃饭,原理是使用 session id 进行对话同步。
此处应该有图片,但是飞书有水印,遂放弃,看下文字版本吧。首先是 /list 指令
md
(我发送)/list
(agent 开始回复)最近 5 条本地会话:
1. ai-config | 04-20 11:13
提问:好像如果 /load 回复太多的时候, 会弹出来一大串消息, 有点影响正常使用, 将这一串消息合成一条吧, 不过注意飞书消息一次最多18000...
回答:已经改了。 `/load` 现在会优先把"已加载对话 + 最后一个提问 + 回放内容"合成一条消息发送;只有合并后超过飞书单条 18000 字...
2. fe-monorepo | 04-20 10:57
提问:先改一下我看看
回答:我先给你落了一版最小改动...
3. fe-monorepo | 04-17 20:50
提问:是说 website 模式下
回答:对,website 模式下这两个接口分工是这样的...
4. ai-config | 04-17 16:32
提问:你得写全, 可以自己运行看看有哪些, 并且给我补上中文介绍
回答:已经补完,README 现在是基于我本地实际运行 `gws --help`、`gws --help`、`gws schem...
5. ai-config | 04-17 16:28
提问:apps.googleusercontent.co...
回答:已经写进项目了: - 新增 [`.env`](/Users/imoo/work/data/project/ai-config/src/temp...
使用 `/load <序号>` 加载指定对话。接着是 /load 加载
bash
(我发送)/load 2
(agent 开始回复)已加载对话 fe-monorepo | 04-20 10:57
最后一个提问: 先改一下我看看
后续在这个话题里的普通消息会基于这条上下文继续。
我先按最小改动做一版,只碰... (这里是完整的,不过不占用篇幅了)还有的同学会说,会不会像龙虾一样停不下来,所以我这里还提供了一个 /abort 功能,供你写错或者它理解错的时候直接终止。
case2: 当群里某个话题下讨论的热火朝天,需要用 agent 排查时,能直接 @ 介入并自动读取上下文,原理是话题 id 可以拉到完整消息
perl
消息1:你好,现在几点
消息2:我忘了 @你
消息3:@claude200
claude200:我先按仓库规则完成会话初始化,读取必需的记忆与目录说明文件,再基于线程上下文继续回复用户。
claude200:记忆系统已加载,我补一下线程里漏掉的回复,先取当前时间,然后按飞书对话语气续上。
claude200:现在是 2026-04-20 11:34:47(CST,上海时区)。你刚才忘了 `@` 我也没事,这里补上回复。case3:通过 mcp 直接读取飞书文档
这个倒是挺常见的,让 agent 直接读业务文档。
新增的好处则是让他记录了一下,当 mcp 授权过期时,它会直接提醒你去哪个链接再点一下,省去了查路径的问题。
case4:当你遇到新功能还需要加新特性时
比如说最近在改造对话功能时,想让他读取到对话,就先贴一个小表情。
这个功能能让我知道它正在正常工作,我直接一句话发给了它,它库库改造完成后,自动进行了服务重启。这样一来我想要什么新功能,只需要直接告诉它即可,灵活度极高,而且处理成本极低。
总之用起来一个字,爽!

总结
本文有两个关键点:
- 用一个简单的方式搭建记忆管理系统,并将记忆这部分做成不依赖平台、可迁移的方式
- 手搓一个链接飞书的方式,体验绝对远高于龙虾的飞书
就是这些,感谢阅读~