@TOC(185. 部门工资前三高的所有员工)
❤️ 原题 ❤️
Employee 表包含所有员工信息,每个员工有其对应的工号 Id,姓名 Name,工资 Salary 和部门编号DepartmentId 。
diff
+----+-------+--------+--------------+
| Id | Name | Salary | DepartmentId |
+----+-------+--------+--------------+
| 1 | Joe | 85000 | 1 |
| 2 | Henry | 80000 | 2 |
| 3 | Sam | 60000 | 2 |
| 4 | Max | 90000 | 1 |
| 5 | Janet | 69000 | 1 |
| 6 | Randy | 85000 | 1 |
| 7 | Will | 70000 | 1 |
+----+-------+--------+--------------+Department 表包含公司所有部门的信息。
diff
+----+----------+
| Id | Name |
+----+----------+
| 1 | IT |
| 2 | Sales |
+----+----------+编写一个 SQL 查询,找出每个部门获得前三高工资的所有员工。例如,根据上述给定的表,查询结果应返回:
diff
+------------+----------+--------+
| Department | Employee | Salary |
+------------+----------+--------+
| IT | Max | 90000 |
| IT | Randy | 85000 |
| IT | Joe | 85000 |
| IT | Will | 70000 |
| Sales | Henry | 80000 |
| Sales | Sam | 60000 |
+------------+----------+--------+解释:
IT 部门中,Max 获得了最高的工资,Randy 和 Joe 都拿到了第二高的工资,Will 的工资排第三。销售部门(Sales)只有两名员工,Henry 的工资最高,Sam 的工资排第二。
⭐️ 解题思路 ⭐️
为了更清晰的表达,我在本地测试环境构建测试环境数据。
构建测试数据
sql
--create table
CREATE TABLE employee (ID NUMBER,NAME VARCHAR2(20),salary NUMBER,departmentid NUMBER);
CREATE TABLE department (ID NUMBER,NAME VARCHAR2(20));
--insert data
INSERT INTO employee VALUES (1,'Joe',85000,1);
INSERT INTO employee VALUES (2,'Henry',80000,2);
INSERT INTO employee VALUES (3,'Sam',60000,2);
INSERT INTO employee VALUES (4,'Max',90000,1);
INSERT INTO employee VALUES (5,'Janet',69000,1);
INSERT INTO employee VALUES (6,'Randy',85000,1);
INSERT INTO employee VALUES (7,'Will',70000,1);
INSERT INTO department VALUES (1,'IT');
INSERT INTO department VALUES (2,'Sales');
commit;❤️ 开始解题
又是排名问题,还是同分数同排名,不免又想到了 dense_rank() 函数,不过这次的使用方式与之前两篇有所不同,因为需要对结果集进行分区,因此还需用到该函数的 <partition_by_clause>。
关于该函数用法可参考:dense_rank()函数
sql
DENSE_RANK ( ) OVER ( [ <partition_by_clause> ] < order_by_clause > )首先,我们需要将两张表关联起来:
sql
SELECT d.name dname,
e.name AS ename,
e.salary
FROM employee e,
department d
WHERE e.departmentid = d.id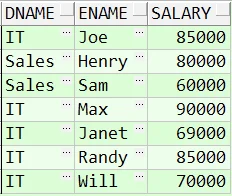 接下来,需要使用
接下来,需要使用 dense_rank() 函数进行排序,并且将结果集进行分组:
sql
SELECT d.name dname,
e.name AS ename,
e.salary,
dense_rank() over(PARTITION BY e.departmentid ORDER BY e.salary DESC) dr
FROM employee e,
department d
WHERE e.departmentid = d.id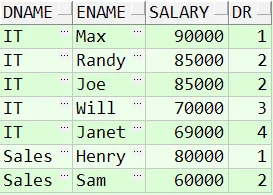 得到以上结果基本该题已经解出来了,最后只需要将结果取前三即可:
得到以上结果基本该题已经解出来了,最后只需要将结果取前三即可:
完整代码如下:
sql
SELECT t.dname AS "Department",
t.ename AS "Employee",
t.salary AS "Salary"
FROM (SELECT d.name dname,
e.name AS ename,
e.salary,
dense_rank() over(PARTITION BY e.departmentid ORDER BY e.salary DESC) dr
FROM employee e,
department d
WHERE e.departmentid = d.id) t
WHERE t.dr < 4;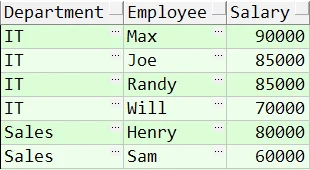 去 LeetCode 执行一下看看结果吧:
去 LeetCode 执行一下看看结果吧: 
❄️ 写在最后 ❄️
已经写了三篇关于排名的题解了,看来 LeetCode 很喜欢出关于排名的题啊,大家应该对 dense_rank() 函数很了解了吧。
本次分享到此结束啦~
如果觉得文章对你有帮助,点赞、收藏、关注、评论,一键四连支持,你的支持就是我创作最大的动力。
📚 推荐阅读:DBA 学习之路
如果这篇文章对你有帮助,推荐访问我的 Oracle DBA 系统学习站点,涵盖 100 天完整学习路线:
- 🔧 Oracle 安装部署 · RMAN 备份恢复 · Data Pump 数据迁移
- 🏗️ RAC 高可用 · DataGuard 容灾 · 多租户架构
- 🔍 故障排查 · 升级迁移 · GoldenGate 数据同步