@TOC(192. 统计词频)
❤️ 原题 ❤️
写一个 bash 脚本以统计一个文本文件 words.txt 中每个单词出现的频率。
为了简单起见,你可以假设:
words.txt只包括小写字母和' '。- 每个单词只由小写字母组成。
- 单词间由一个或多个空格字符分隔。
示例:
假设 words.txt 内容如下:
csharp
the day is sunny the the
the sunny is is你的脚本应当输出(以词频降序排列):
csharp
the 4
is 3
sunny 2
day 1说明:
- 不要担心词频相同的单词的排序问题,每个单词出现的频率都是唯一的。
- 你可以使用一行
Unix pipes实现吗?
⭐️ 解题思路 ⭐️
注意几个关键词:词频降序排列、统计每个单词出现次数、使用一行命令实现。
① 使用 xargs 将所有行转为单列显示:
bash
cat words.txt | xargs -n1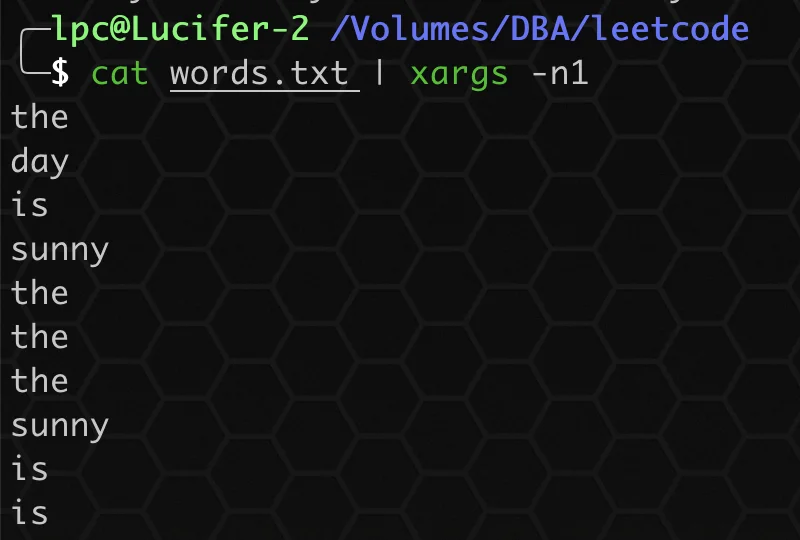 ② 使用
② 使用 sort + uniq 函数进行排列:
sort -nr表示依照数值的大小降序排序。uniq -c表示在每列旁边显示该行重复出现的次数。
bash
cat words.txt | xargs -n1 | sort | uniq -c | sort -nr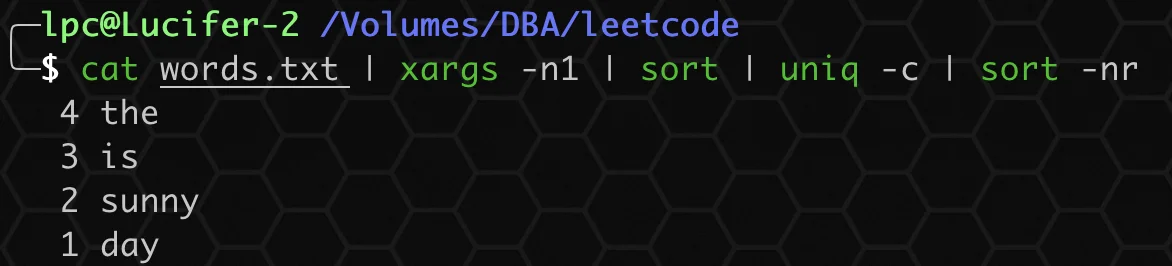 ③ 使用
③ 使用 awk + print 函数将 1、2 列位置互换:
bash
cat words.txt | xargs -n 1 | sort | uniq -c | sort -nr | awk '{print $2" "$1}' 至此,本题已解。
至此,本题已解。
去 LeetCode 执行一下看看结果吧: 
❄️ 写在最后 ❄️
本题依然是使用 Linux 的一些基础命令:xargs、sort、uniq、awk,基础很重要!
本次分享到此结束啦~
如果觉得文章对你有帮助,点赞、收藏、关注、评论,一键四连支持,你的支持就是我创作最大的动力。
📚 推荐阅读:DBA 学习之路
如果这篇文章对你有帮助,推荐访问我的 Oracle DBA 系统学习站点,涵盖 100 天完整学习路线:
- 🔧 Oracle 安装部署 · RMAN 备份恢复 · Data Pump 数据迁移
- 🏗️ RAC 高可用 · DataGuard 容灾 · 多租户架构
- 🔍 故障排查 · 升级迁移 · GoldenGate 数据同步