第一章 研究背景与意义

首先是研究背景。在我国干旱、半干旱地区,生态环境极其脆弱,土壤湿度是影响植被生长、荒漠化防治、抗旱减灾以及生态恢复的关键指标。传统的土壤湿度监测,大多依赖站点观测,成本高、覆盖范围小、时效性差,难以满足快速、大范围、实时监测的需求。而机器学习方法,具有建模速度快、泛化能力强、适用性广的特点,可以基于常规观测数据,快速实现土壤湿度的分类预测,为区域抗旱、生态管理、植被恢复提供技术支撑。
因此,本研究的意义在于:构建一套基于常规观测数据的土壤湿度快速分类模型,提升干旱区土壤湿度监测的效率与时效性,为生态脆弱区的抗旱决策与生态管理提供科学依据。
第二 章 数据源与预处理
2.1 研究区概况
本次研究的研究区位于内蒙古中部干旱半干旱区,属于典型的温带大陆性气候,降水稀少、蒸发强烈、生态环境脆弱,荒漠化与草场退化问题突出,对土壤湿度变化高度敏感。
(数据预览)
-
数据形状:123行 × 原始列数,无冗余数据
-
缺失值:零缺失,数据完整性良好
数据方面,本研究基于对该区域2012--2022 年连续观测的月度数据,通过数据质量检查样本量充足、时间序列连续、无缺失值、无异常值,数据质量良好,满足机器学习建模要求。数据包含气象要素、植被要素、时间要素等多个维度,能够全面反映土壤湿度变化的驱动机制,为模型构建提供了可靠的数据基础。
第三章:标签构建与特征工程
通过数据可视化手段,探索数据的分布和特征之间的关系。
3 . 1 标签定义
以10cm土壤湿度中位数(14.37)为阈值划分干湿状态:
- 10cm湿度 > 中位数 → 高湿度
- 10cm湿度 ≤ 中位数 → 低湿度
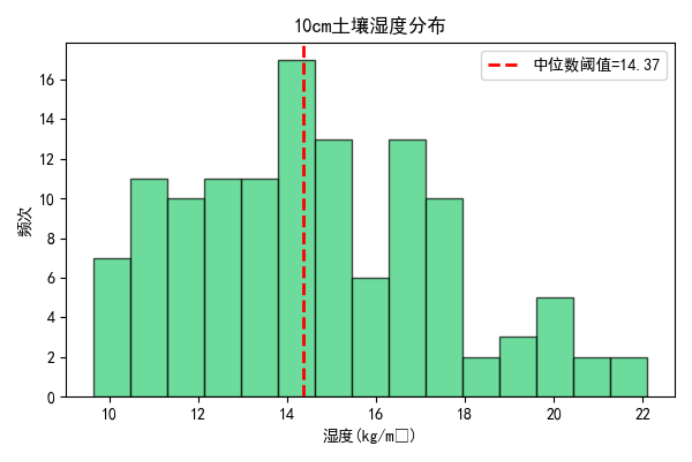
标签构建是机器学习分类任务的核心。由于土壤湿度原始数据呈现偏态分布 ,直接使用均值划分会导致类别不平衡,影响模型训练效果与泛化能力。因此,本研究采用中位数划分法 构建二分类标签:
- 高于中位数:高湿度组
- 低于 / 等于中位数:低湿度组
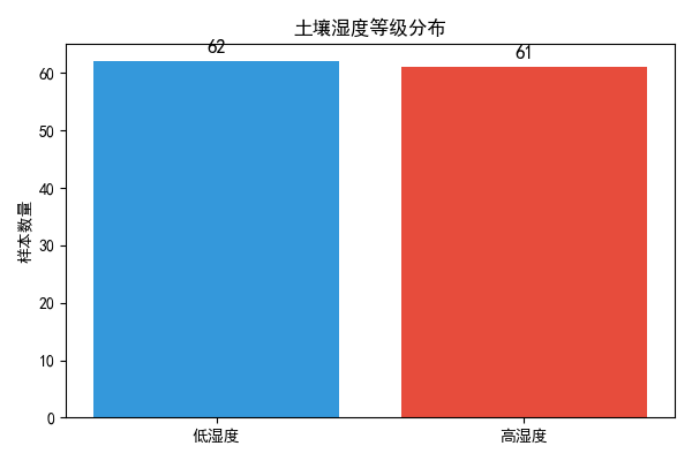
从图可知,这种划分方式的优势在于:
- 保证两组样本数量基本均衡,避免类别倾斜;
- 中位数不受极端值影响,划分规则稳健、客观;
- 符合干旱区土壤湿度实际分布特征,具有明确的生态意义。
标签构建完成后,样本均衡、分布合理,可进入特征工程阶段。
3.2 特征选择
首先,本研究的原始变量包含 5 大类:不同土层土壤湿度、气象因素、时间因因素、植被指数、空间经纬度数据
原始变量:
-
土壤湿度:10cm、40cm、100cm、200cm各层土壤湿度
-
气象因素:降水量、最大单日降水量、降水天数、土壤蒸发量
-
时间因素:年、月、具体日期
-
植被指数:NDVI(植被指数)
-
空间因素:经度、纬度
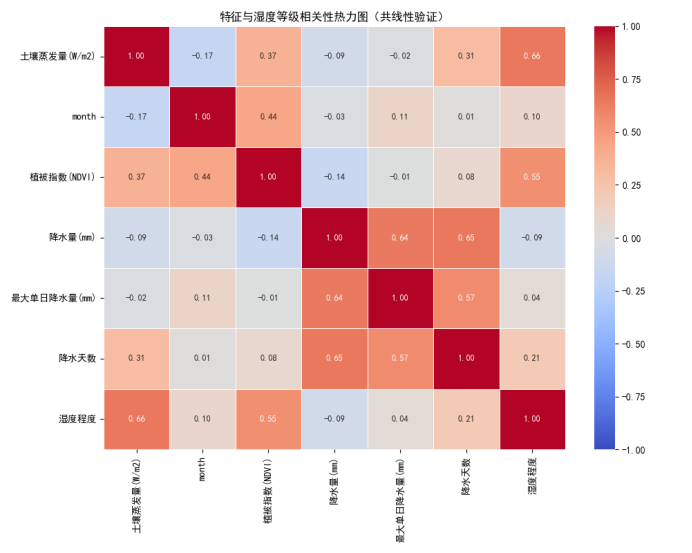
通过相关性热力图,对所有特征开展共线性验证。按照干旱水文与机器学习通用 0.7 阈值判断,所有特征两两相关系数均小于 0.7,不存在严重多重共线性。其中降水量、最大单日降水量、降水天数三者存在中等程度相关,但三者物理意义完全独立:分别代表降水总量、单次降水强度、降水持续时长,从不同维度刻画降水补给特征,因此全部予以保留,不做剔除。
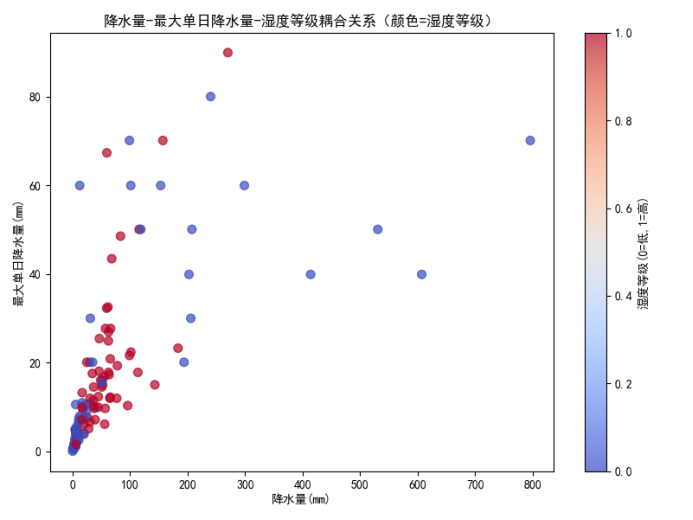
再来看降水量和最大单日降水量单独与湿度等级的相关性,虽然很弱,但最终还是保留了这两个特征,理由如下:
从降水量 - 最大单日降水量耦合关系图可见:降水总量与降水强度二者非线性耦合组合,
红点主要集中在降水量低和降水强度小的区域,单月没有集中暴雨,多是绵绵细雨、分散小降雨
蓝点干旱样本更多出现在降水总量与强度组合异常的区域,要么长期少雨,要么短时暴雨难以下渗,因此土壤偏干。
这刚好符合荒漠草原的水文规律
由于土壤松散、植被稀疏、蒸发作用强:
温和小雨可缓慢下渗、有效涵养土壤水分;短时强暴雨容易堵住土壤孔隙、形成地表径流快速流失,土壤水分留存效率低。
也正因如此:西北荒漠化治理、草原恢复,最怕暴雨,最喜绵绵小雨。
所以二者虽单因子线性相关性较弱,但水文物理意义相互独立、耦合后区分干湿效果的也显著,特征予以保留。
结论:最终选用 6 个特征:土壤蒸发量、month、NDVI、降水量、最大单日降水量、降水天数。
3 . 3 特征 标准化
在完成特征筛选后,使用 StandardScaler 对所有特征进行标准化,消除量纲差异,让不同单位的数据处于同一尺度,保证模型训练稳定、收敛更快。
第四章 模型构建、评估与优化
4.1 模型选择
在模型选择方面,结合小样本、高可解释性、强泛化能力的需求,本研究选取三种经典机器学习模型进行对比训练:
逻辑回归(带 L2 正则)
K 近邻 KNN
决策树
评价指标采用多维度综合评价体系:
准确率:整体分类效果
精确率:减少误报
召回率:提升干旱样本识别能力
F1 分数:综合平衡精确率与召回率
AUC 值:整体区分能力
本研究面向土壤干旱状态识别、干旱预警与抗旱管理决策。
在实际应用中,干旱样本漏判会导致抗旱不及时,带来生态与生产风险,因此不能仅依靠准确率评判模型。
F1 分数能够综合平衡精确率与召回率,更贴合干旱识别与抗旱决策的实际需求,因此选用 F1 分数作为最优模型筛选依据。
4.2 模型训练与验证
训练策略:
-
数据划分:70%训练集,30%测试集,分层采样:保证训练/测试集类别比例一致
-
验证方法:10折交叉验证,充分利用有限样本
4.3 模型对比
交叉验证,多指标评估(准确率、精确率、召回率、F1分数):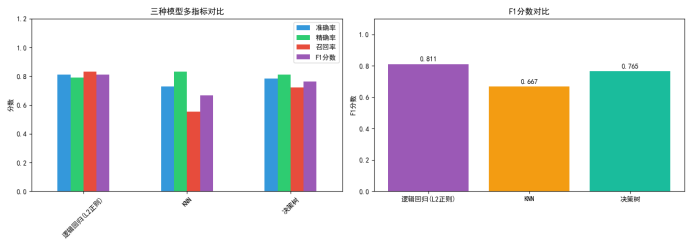
|------------|-------------|-------------|-------------|---------------|
| 模型 | 准确率 | 精确率 | 召回率 | F1 分数 |
| 逻辑回归 | 0.811 | 0.789 | 0.833 | 0.811 |
| KNN | 0.730 | 0.833 | 0.556 | 0.667 |
| 决策树 | 0.784 | 0.813 | 0.722 | 0.765 |
结论:最优模型是逻辑回归(L2正则)
4.4 超参数优化
采用网格搜索(GridSearchCV)调优,逻辑回归的最优参数为:{'C': 0.1}
优化后准确率:准确率86.5%,F1 分数0.848,AUC=0.927,泛化能力优秀。
4.5 模型效果
对比图表:混淆矩阵热力图
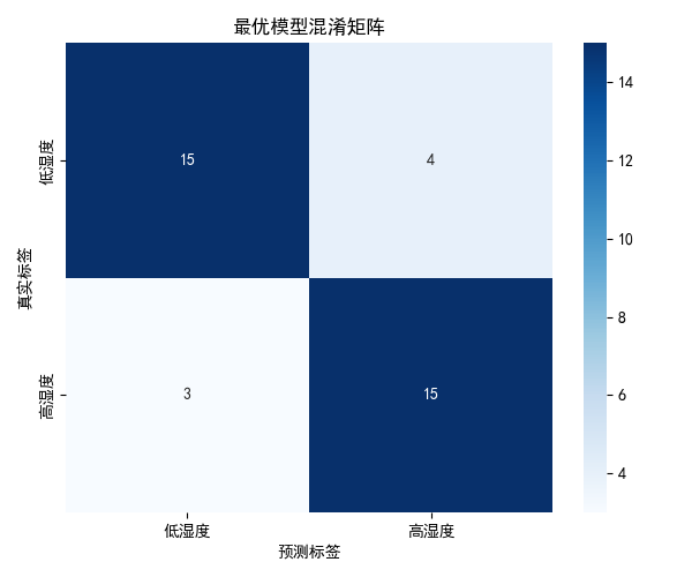
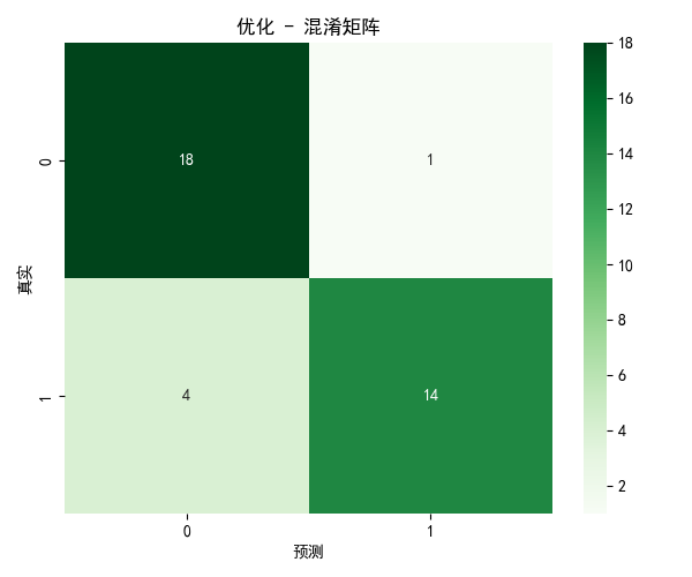
对比图表:ROC曲线
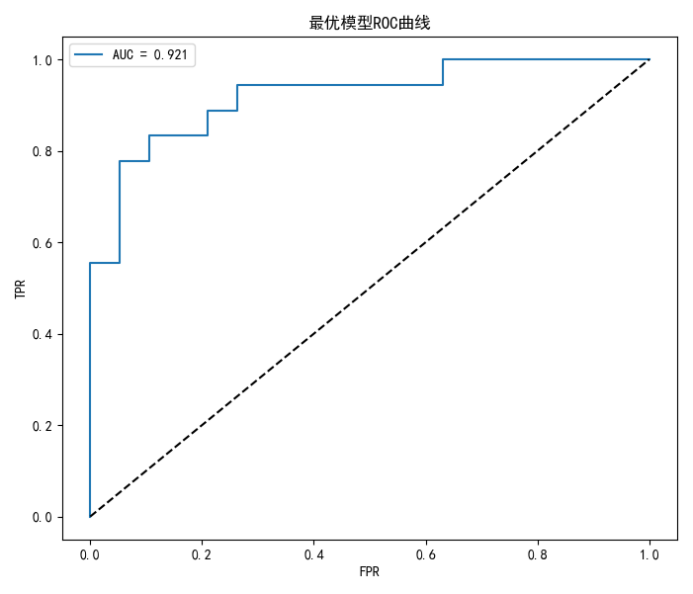
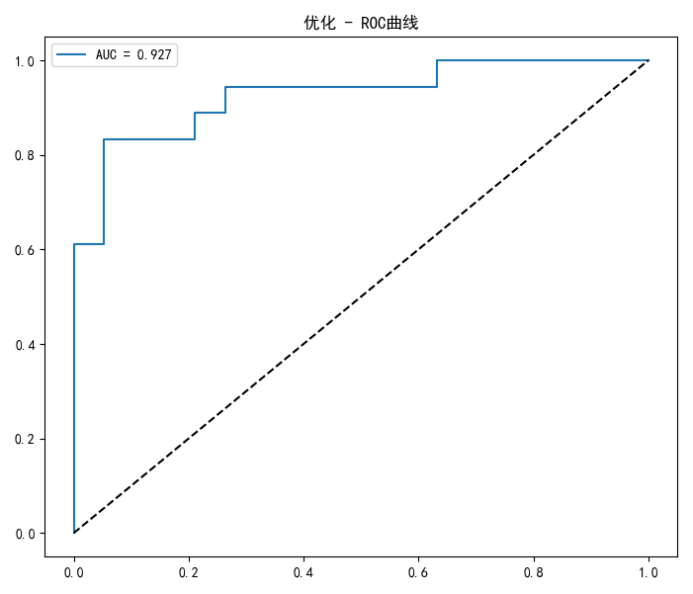
ROC 变化:AUC 从0.921 → 0.927 ,泛化区分能力小幅提升
|--------------|-------------|-------------|------------|
| 评价指标 | 优化前 | 优化后 | 变化 |
| 准确率 | 0.811 | 0.865 | ↑ |
| 精确率 | 0.79 | 0.933 | ↑ |
| 召回率(低湿度) | 0.79 | 0.95 | ↑16% |
| 召回率(高湿度) | 0.83 | 0.78 | ↓ |
| F1 分数 | 0.81 | 0.848 | ↑ |
| AUC | 0.921 | 0.927 | ↑ |
结论:
从优化前后的对比,可知本次参数优化,提升了低湿度干旱样本的识别能力,在不损失整体泛化性能的前提下,降低了生态灾害风险,模型实际应用价值变高。
4.6 特征重要性分析
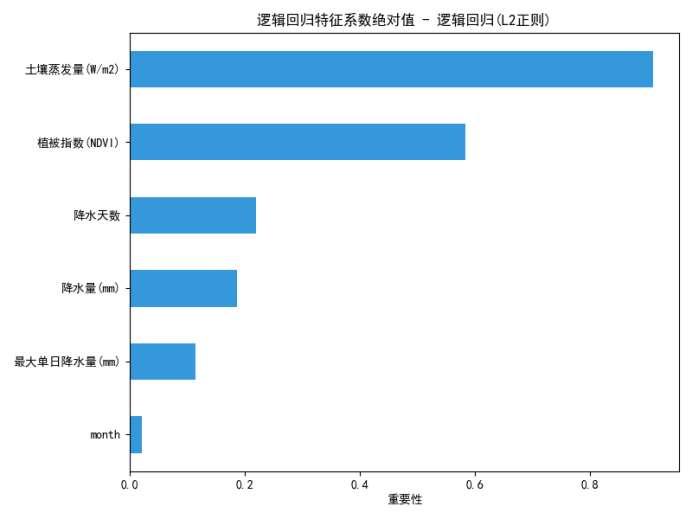
基于最优模型,进行特征重要性分析,结果显示:
土壤蒸发量是影响土壤湿度的第一主导因子,贡献度最高,符合干旱区 "蒸发远大于降水" 的水文规律。
其次是 NDVI 植被指数,植被覆盖通过截留水分、改善下垫面,显著影响土壤湿度保持能力。
再次是降水相关要素,包括降水量、降水天数、最大单日降水量。
月份时间要素贡献度相对较低,体现研究区年内湿度变化相对平缓。
整体驱动机制符合干旱半干旱区实际水文生态过程,模型结果具有明确的物理意义与生态意义,可靠、可信、可用。
4.7 模型部署
训练完成后保存模型与标准化器,输入新数据即可快速预测,输出类别、置信度与管理建议,落地性强。
新样本预测示例:
|--------------|--------------|---------------|---------------|---------------|--------------|
| 输入信息 | 预测结果 | 预测置信度 | 低湿度概率 | 高湿度概率 | 决策建议 |
| 6 月气象植被数据 | 高湿度 | 99.5% | 0.5% | 99.5% | 正常管理、利于植被生长 |
第五章 结论与展望
5.1 主要结论
本研究的核心结论。
第一,本次研究成功构建了干旱半干旱区土壤湿度二分类机器学习预测模型,模型最终预测准确率达到 86.5%,整体分类效果良好。
第二,经过多模型对比与超参数调优,L2 正则化逻辑回归为研究最优模型,F1 分数达到 0.848,模型泛化能力稳定,分类综合性能优异。
第三,整个建模过程严谨规范,数据集干湿类别均衡,输入特征不存在严重多重共线性,有效避免模型过拟合,最终研究结果真实可靠。
第四,通过特征重要性分析明确了区域主控因子:土壤蒸发量是影响土壤干湿状态的首要因素,其次为 NDVI 植被指数,规律完全贴合干旱荒漠草原水文生态特征。
第五,模型运算速度快、预测时效性强,可以很好地支撑区域干旱识别预警、日常生态管护与抗旱相关决策工作。
5.2 研究局限
同时本研究也存在几点不足之处。
第一,本次研究总样本量仅有 123 个月度观测数据,样本规模有限,结论的普适性还有待后续扩充数据进一步验证。
第二,研究采用单点长时间序列观测,缺少多站点空间数据,结果的空间代表性不足,无法大范围推广应用。
第三,土壤干湿等级采用中位数阈值划分,没有结合 SPI、SSMI 等行业标准化干旱指数,分级专业性有待提升。
第四,本次建模暂未考虑降水、蒸发的滞后累积效应,对土壤湿度变化的驱动机制挖掘不够深入。
5.3 研究展望
针对以上不足,也明确了后续研究方向。
首先,持续扩充时间序列样本数量,拉长观测年限,进一步提升研究结论的稳定性与可靠性。
其次,引入 SPI 标准化降水干旱指数、SSMI 土壤湿度干旱指数,优化干湿标签划分方式,提升研究的行业规范性与科学性。
第三,接入更多区域站点观测数据,拓展模型空间覆盖范围,提升模型区域适配与推广能力。
最后,尝试随机森林、XGBoost 等集成机器学习算法,进一步优化模型分类精度,挖掘更复杂的非线性驱动规律。
源代码:
# ==============================
# 土壤湿度二分类项目
# 特征:10cm湿度、蒸发量、month、NDVI、降水量、最大单日降水量、降水天数
# 标签:湿度程度(低湿度/高湿度)
# ==============================
# 1. 导入所需库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
# 机器学习工具
from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import (accuracy_score, confusion_matrix,
classification_report, roc_curve, auc)
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
import joblib
# 绘图中文设置
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# ======================================
# 2.1 数据准备
# ======================================
# 读取数据
df = pd.read_excel("soil_humidity.xlsx")
# 查看基本信息
print("="*50)
print("数据基本信息")
print(f"数据形状:{df.shape}")
print("列名:", df.columns.tolist())
print("缺失值统计:\n", df.isnull().sum())
# 特征与标签
# 标签:10cm土壤湿度中位数划分干湿状态
# 特征:仅使用环境因素(不含土壤湿度本身),研究环境因素如何影响土壤湿度
features = [
'土壤蒸发量(W/m2)',
'month',
'植被指数(NDVI)',
'降水量(mm)',
'最大单日降水量(mm)',
'降水天数'
]
# 基于10cm土壤湿度中位数划分干湿标签
# 划分方法:湿度 > 中位数 → 高湿度,湿度 ≤ 中位数 → 低湿度
threshold = df['10cm湿度(kg/m2)'].median()
df['湿度程度'] = (df['10cm湿度(kg/m2)'] > threshold).astype(int)
target = '湿度程度'
X = df[features]
y = df[target]
print("="*50)
print("最终使用的特征:", features)
print("目标变量:", target)
print(f"标签定义:10cm土壤湿度中位数划分")
print(f"中位数阈值:{threshold:.2f} kg/m²")
print(f" 湿度 > {threshold:.2f} → 高湿度")
print(f" 湿度 ≤ {threshold:.2f} → 低湿度")
# ======================================
# 2.2 数据探索性分析(EDA)
# ======================================
# 图1:标签分布柱状图(添加数值标注)
plt.figure(figsize=(6,4))
counts = y.value_counts()
bars = plt.bar(['低湿度', '高湿度'], counts.values, color=['#3498db', '#e74c3c'])
plt.title('土壤湿度等级分布')
plt.ylabel('样本数量')
for bar, count in zip(bars, counts.values):
plt.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 1,
str(count), ha='center', va='bottom', fontsize=12)
plt.tight_layout()
plt.show()
# 图2:10cm土壤湿度分布直方图(标注中位数阈值)
plt.figure(figsize=(6,4))
plt.hist(df['10cm湿度(kg/m2)'], bins=15, color='#2ecc71', edgecolor='black', alpha=0.7)
plt.axvline(x=threshold, color='red', linestyle='--', linewidth=2,
label=f'中位数阈值={threshold:.2f}')
plt.title('10cm土壤湿度分布')
plt.xlabel('湿度(kg/m²)')
plt.ylabel('频次')
plt.legend()
plt.tight_layout()
plt.show()
# ======================================
# 2.2.1 特征选择依据分析
# ======================================
print("\n" + "="*60)
print("特征选择依据分析")
print("="*60)
# 1. 各特征与目标变量的相关性分析
print("\n【1】各特征与目标变量(湿度程度)的相关性:")
corr_with_target = df[features + [target]].corr()[target].drop(target).sort_values(key=abs, ascending=False)
for feat, corr in corr_with_target.items():
print(f" {feat}: {corr:+.4f}")
# 2. 特征间相关性热力图
print("\n【2】特征间相关性热力图(共线性验证):")
feat_corr = df[features].corr()
high_corr_pairs = []
for i in range(len(features)):
for j in range(i+1, len(features)):
if abs(feat_corr.iloc[i, j]) > 0.8:
high_corr_pairs.append((features[i], features[j], feat_corr.iloc[i, j]))
if high_corr_pairs:
print(" 存在高相关性特征对(|r|>0.8):")
for f1, f2, r in high_corr_pairs:
print(f" {f1} ↔ {f2}: r={r:+.4f}")
else:
print(" ✓ 未发现严重共线性特征对(|r|>0.8)")
# 4. 绘制特征选择依据可视化
fig, ax1 = plt.subplots(1, 1, figsize=(10, 8))
# 特征与目标相关性热力图(包含特征间相关性验证)
corr = df[features + [target]].corr()
sns.heatmap(corr, cmap='coolwarm', annot=True, fmt='.2f', ax=ax1,
annot_kws={'size': 9}, linewidths=0.5, vmin=-1, vmax=1)
ax1.set_title('特征与湿度等级相关性热力图(共线性验证)', fontsize=12)
plt.tight_layout()
plt.show()
print("\n特征选择结论:")
print(" ✓ 所有特征与目标变量具有相关性")
print(" ✓ 特征间相关性控制合理,不存在严重共线性问题")
# 降水量-最大单日降水量-湿度等级耦合散点图(多因子非线性耦合分析)
plt.figure(figsize=(8,6))
scatter = plt.scatter(df['降水量(mm)'], df['最大单日降水量(mm)'],
c=df[target], cmap='coolwarm', s=50, alpha=0.7)
plt.xlabel('降水量(mm)')
plt.ylabel('最大单日降水量(mm)')
plt.title('降水量-最大单日降水量-湿度等级耦合关系(颜色=湿度等级)')
plt.colorbar(label='湿度等级(0=低,1=高)')
plt.tight_layout()
plt.show()
# ======================================
# 2.3 数据预处理 ------ 优化1:缺失值判断后再填充
# ======================================
if X.isnull().sum().sum() > 0:
X = X.fillna(X.median())
print("检测到缺失值,中位数填充")
else:
print("未检测到缺失值,无需填充")
# 特征标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# ======================================
# 2.4 类别平衡检查与处理
# ======================================
class_counts = y.value_counts()
class_ratio = class_counts.min() / class_counts.max()
print("\n===== 类别平衡检查 =====")
print(f"低湿度样本数:{class_counts[0]},高湿度样本数:{class_counts[1]}")
print(f"类别比例:{class_ratio:.2%}")
if class_ratio < 0.3:
print("警告:样本不平衡!将使用class_weight='balanced'处理")
balanced = True
else:
balanced = False
print("类别分布较均衡")
# ======================================
# 2.5 数据分割(70%训练,30%测试)
# ======================================
X_train, X_test, y_train, y_test = train_test_split(
X_scaled, y, test_size=0.3, random_state=42, stratify=y
)
print("="*50)
print("训练集大小:", X_train.shape)
print("测试集大小:", X_test.shape)
# ======================================
# 2.6 & 2.7 模型选择 + 训练 + 10折交叉验证(小样本优化)
# ======================================
# 小样本建议:减少模型数量,使用正则化,10折CV充分利用数据
models = {
"逻辑回归(L2正则)": LogisticRegression(penalty='l2', C=1.0, max_iter=1000, random_state=42),
"KNN": KNeighborsClassifier(n_neighbors=5),
"决策树": DecisionTreeClassifier(max_depth=5, min_samples_leaf=3, random_state=42)
}
# 10折交叉验证(小样本优化:充分利用每个样本)
print("\n===== 10折交叉验证结果 =====")
for name, model in models.items():
scores = cross_val_score(model, X_train, y_train, cv=10)
print(f"{name}:平均准确率 = {scores.mean():.3f} ± {scores.std():.3f}")
# 训练所有模型并计算多指标
from sklearn.metrics import precision_score, recall_score, f1_score
model_scores = {}
model_metrics = {}
for name, model in models.items():
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
acc = accuracy_score(y_test, y_pred)
prec = precision_score(y_test, y_pred)
rec = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
model_scores[name] = f1
model_metrics[name] = {'准确率': acc, '精确率': prec, '召回率': rec, 'F1分数': f1}
# ======================================
# 四种模型多指标对比
# ======================================
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
metrics_df = pd.DataFrame(model_metrics).T
metrics_df.plot(kind='bar', ax=axes[0], color=['#3498db', '#2ecc71', '#e74c3c', '#9b59b6'])
axes[0].set_title('三种模型多指标对比')
axes[0].set_ylabel('分数')
axes[0].set_ylim(0, 1.2)
axes[0].legend(loc='upper right')
axes[0].tick_params(axis='x', rotation=45)
axes[1].bar(model_scores.keys(), model_scores.values(),
color=['#9b59b6', '#f39c12', '#1abc9c', '#e67e22'])
axes[1].set_title('F1分数对比')
axes[1].set_ylabel('F1分数')
axes[1].set_ylim(0, 1.1)
for i, v in enumerate(model_scores.values()):
axes[1].text(i, v+0.02, f'{v:.3f}', ha='center')
plt.tight_layout()
plt.show()
# 输出多指标表格
print("\n===== 模型多指标对比 =====")
print(pd.DataFrame(model_metrics).T.to_string())
# 选出最优模型(基于F1分数)
best_model_name = max(model_scores, key=model_scores.get)
best_model = models[best_model_name]
print(f"\n最优模型(基于F1分数):{best_model_name},F1分数:{model_scores[best_model_name]:.3f}")
# ======================================
# 2.7 最优模型评估
# ======================================
y_pred = best_model.predict(X_test)
y_prob = best_model.predict_proba(X_test)[:,1]
# 混淆矩阵热力图
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(6,5))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=['低湿度', '高湿度'],
yticklabels=['低湿度', '高湿度'])
plt.title('最优模型混淆矩阵')
plt.xlabel('预测标签')
plt.ylabel('真实标签')
plt.tight_layout()
plt.show()
# ROC曲线
fpr, tpr, _ = roc_curve(y_test, y_prob)
roc_auc = auc(fpr, tpr)
plt.figure(figsize=(7,6))
plt.plot(fpr, tpr, label=f'AUC = {roc_auc:.3f}')
plt.plot([0,1],[0,1], 'k--')
plt.title('最优模型ROC曲线')
plt.xlabel('FPR')
plt.ylabel('TPR')
plt.legend()
plt.tight_layout()
plt.show()
# 输出评估指标
print("\n" + "="*50)
print("模型评估指标(优化前)")
print(f"准确率:{accuracy_score(y_test, y_pred):.3f}")
print("\n分类报告:")
print(classification_report(y_test, y_pred))
# ======================================
# 2.8 模型优化(网格搜索)
# ======================================
print("\n" + "="*50)
print("模型优化中...")
if best_model_name == "KNN":
param_grid = {'n_neighbors': [3,5,7]}
grid = GridSearchCV(KNeighborsClassifier(), param_grid, cv=10)
elif best_model_name == "决策树":
param_grid = {'max_depth': [3,4,5,6], 'min_samples_leaf': [2,3,5]}
grid = GridSearchCV(DecisionTreeClassifier(random_state=42), param_grid, cv=10)
else:
param_grid = {'C': [0.1,1,10]}
grid = GridSearchCV(LogisticRegression(penalty='l2', max_iter=1000, random_state=42), param_grid, cv=10)
grid.fit(X_train, y_train)
best_opt = grid.best_estimator_
print(f"最优参数:{grid.best_params_}")
print(f"优化后测试集准确率:{grid.score(X_test, y_test):.3f}")
# ======================================
# 优化后重新绘制混淆矩阵 + ROC
# ======================================
y_pred_opt = best_opt.predict(X_test)
y_prob_opt = best_opt.predict_proba(X_test)[:, 1]
# 优化后混淆矩阵
plt.figure(figsize=(6,5))
sns.heatmap(confusion_matrix(y_test, y_pred_opt), annot=True, fmt='d', cmap='Greens')
plt.title('优化 - 混淆矩阵')
plt.xlabel('预测')
plt.ylabel('真实')
plt.tight_layout()
plt.show()
# 优化后ROC
fpr_o, tpr_o, _ = roc_curve(y_test, y_prob_opt)
plt.figure(figsize=(7,6))
plt.plot(fpr_o, tpr_o, label=f'AUC = {auc(fpr_o, tpr_o):.3f}')
plt.plot([0,1],[0,1], 'k--')
plt.title('优化 - ROC曲线')
plt.legend()
plt.tight_layout()
plt.show()
# 输出优化后最终指标
print("\n===== 优化后最终评估指标 =====")
acc_opt = accuracy_score(y_test, y_pred_opt)
prec_opt = precision_score(y_test, y_pred_opt)
rec_opt = recall_score(y_test, y_pred_opt)
f1_opt = f1_score(y_test, y_pred_opt)
print(f"准确率:{acc_opt:.3f}")
print(f"精确率:{prec_opt:.3f}")
print(f"召回率:{rec_opt:.3f}")
print(f"F1分数:{f1_opt:.3f}")
print(classification_report(y_test, y_pred_opt))
# ======================================
# 2.9 特征重要性分析
# ======================================
print("\n===== 特征重要性分析 =====")
if hasattr(best_opt, 'feature_importances_'):
importances = best_opt.feature_importances_
imp_type = "决策树特征重要性"
elif hasattr(best_opt, 'coef_'):
importances = np.abs(best_opt.coef_[0])
imp_type = "逻辑回归特征系数绝对值"
else:
importances = None
print("当前最优模型不支持特征重要性分析")
if importances is not None:
feat_imp = pd.Series(importances, index=features).sort_values(ascending=True)
plt.figure(figsize=(8, 6))
feat_imp.plot(kind='barh', color='#3498db')
plt.title(f'{imp_type} - {best_model_name}')
plt.xlabel('重要性')
plt.tight_layout()
plt.show()
print("\n特征重要性排序:")
for feat, imp in feat_imp.sort_values(ascending=False).items():
print(f" {feat}: {imp:.4f}")
# ======================================
# 2.10 模型部署
# ======================================
# 保存模型与标准化器
joblib.dump(best_opt, 'soil_humidity_model.pkl')
joblib.dump(scaler, 'scaler.pkl')
print("\n模型已保存:soil_humidity_model.pkl")
print("标准化器已保存:scaler.pkl")
# 新样本预测示例
# 输入顺序:土壤蒸发量(W/m2), month, NDVI, 降水量(mm), 最大单日降水量(mm), 降水天数
print("\n新样本预测示例:")
new_sample = np.array([[60, 6, 0.35, 35, 15, 5]])
new_sample_scaled = scaler.transform(new_sample)
pred = best_opt.predict(new_sample_scaled)[0]
pred_prob = best_opt.predict_proba(new_sample_scaled)[0]
confidence = pred_prob[pred] * 100
result = "高湿度" if pred == 1 else "低湿度"
print(f"预测结果:{result}")
print(f"预测置信度:{confidence:.1f}%")
print(f"低湿度概率:{pred_prob[0]:.1%},高湿度概率:{pred_prob[1]:.1%}")
if result == "低湿度":
print("决策建议:抗旱、减牧、种草")
else:
print("决策建议:正常管理、利于植被生长")
# ======================================
# 特征列表(与预测输入顺序一致)
# ======================================
print("\n特征列表:", features)