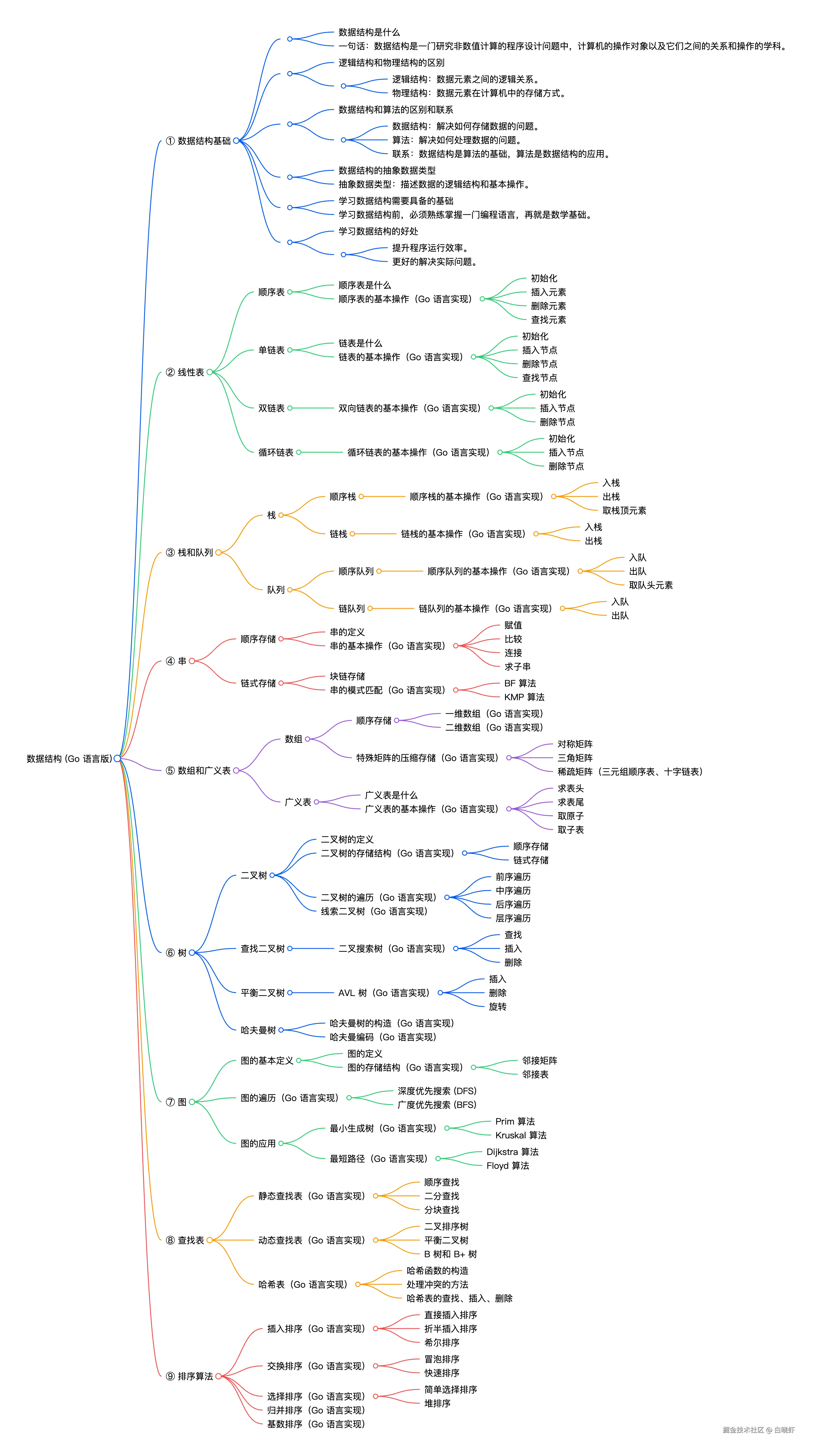
数据结构(Go语言版)完全指南
序章:数据结构是什么?------ 程序员的"收纳艺术"
想象你是一个图书管理员。面对成千上万本书,你怎么摆放才能让找书最快?
- 随便堆地上 → 找一本书要翻遍所有书 → O(n)
- 按类别放书架 → 先找类别再找书 → O(log n)
- 每本书编号,知道编号直接定位 → O(1)
数据结构就是研究"如何高效组织和存储数据"的学科。
第一章:数据结构基础 ------ 万丈高楼平地起
1.1 数据结构是什么?
一句话定义 :数据结构是一门研究非数值计算 的程序设计问题中,计算机的操作对象 以及它们之间的关系 和操作的学科。
通俗理解 :不是研究怎么算1+1,而是研究怎么放数据、怎么找数据、怎么处理数据之间的关系。
1.2 逻辑结构 vs 物理结构
| 维度 | 逻辑结构 | 物理结构 |
|---|---|---|
| 关注点 | 数据之间的逻辑关系 | 数据在内存中的实际存储方式 |
| 例子 | 线性表、树、图 | 顺序存储(数组)、链式存储(指针) |
| 独立性 | 独立于计算机 | 依赖于计算机 |
| 类比 | 建筑图纸 | 实际施工 |
1.3 数据结构与算法的关系
经典公式 :程序 = 数据结构 + 算法
| 角色 | 数据结构 | 算法 |
|---|---|---|
| 解决的问题 | 如何存储数据 | 如何处理数据 |
| 关系 | 算法的基础 | 数据结构的应用 |
| 类比 | 厨房的食材摆放 | 烹饪方法 |
1.4 抽象数据类型(ADT)
定义 :描述数据的逻辑结构 和基本操作,不涉及具体实现。
go
// 线性表的抽象数据类型
type List interface {
Init() // 初始化
Length() int // 求长度
Get(i int) any // 取元素
Insert(i int, e any) // 插入
Delete(i int) // 删除
// ... 不涉及具体是数组还是链表实现
}1.5 学习数据结构的基础
- 一门编程语言(本文用 Go)
- 数学基础(主要是逻辑思维和复杂度分析)
1.6 学习数据结构的好处
| 好处 | 说明 |
|---|---|
| 提升程序运行效率 | 选对结构,速度差100倍 |
| 更好解决实际问题 | 复杂系统的基础 |
第二章:线性表 ------ 排队的艺术
线性表 :n个数据元素的有限序列 ,元素之间一对一。
2.1 顺序表 ------ 数组的实现
特点 :用连续的内存空间存储数据。
go
package main
import "fmt"
// 顺序表结构
type SeqList struct {
data []int // 存储数据的数组
length int // 当前长度
capacity int // 容量
}
// 初始化
func NewSeqList(cap int) *SeqList {
return &SeqList{
data: make([]int, cap),
length: 0,
capacity: cap,
}
}
// 插入元素(位置i,元素e)
func (s *SeqList) Insert(i int, e int) bool {
// 边界检查
if i < 0 || i > s.length || s.length >= s.capacity {
return false
}
// 第i个位置后的元素后移
for j := s.length; j > i; j-- {
s.data[j] = s.data[j-1]
}
s.data[i] = e
s.length++
return true
}
// 删除元素(位置i)
func (s *SeqList) Delete(i int) (int, bool) {
if i < 0 || i >= s.length {
return 0, false
}
e := s.data[i]
// 第i个位置后的元素前移
for j := i; j < s.length-1; j++ {
s.data[j] = s.data[j+1]
}
s.length--
return e, true
}
// 查找元素
func (s *SeqList) Find(e int) int {
for i := 0; i < s.length; i++ {
if s.data[i] == e {
return i
}
}
return -1
}
func main() {
list := NewSeqList(10)
// 插入
list.Insert(0, 10) // [10]
list.Insert(1, 20) // [10, 20]
list.Insert(0, 5) // [5, 10, 20]
fmt.Printf("顺序表: %v, 长度: %d\n", list.data[:list.length], list.length)
// 输出: 顺序表: [5 10 20], 长度: 3
// 删除
val, _ := list.Delete(1)
fmt.Printf("删除位置1的元素: %d\n", val)
// 输出: 删除位置1的元素: 10
fmt.Printf("删除后: %v\n", list.data[:list.length])
// 输出: 删除后: [5 20]
// 查找
idx := list.Find(20)
fmt.Printf("20的位置: %d\n", idx)
// 输出: 20的位置: 1
}插入删除过程图:
时间复杂度分析:
| 操作 | 最好 | 最坏 | 平均 |
|---|---|---|---|
| 访问 | O(1) | O(1) | O(1) |
| 插入 | O(1)(尾部) | O(n)(头部) | O(n) |
| 删除 | O(1)(尾部) | O(n)(头部) | O(n) |
2.2 单链表 ------ 用指针串起来的"火车"
特点 :元素可以分散存储 ,通过指针连接。
go
package main
import "fmt"
// 节点结构
type ListNode struct {
data int // 数据域
next *ListNode // 指针域
}
// 单链表
type LinkedList struct {
head *ListNode // 头指针
length int
}
// 初始化
func NewLinkedList() *LinkedList {
// 带头结点(方便操作)
head := &ListNode{}
return &LinkedList{head: head, length: 0}
}
// 头插法(逆序建立)
func (l *LinkedList) InsertHead(e int) {
newNode := &ListNode{data: e}
newNode.next = l.head.next
l.head.next = newNode
l.length++
}
// 尾插法(顺序建立)
func (l *LinkedList) InsertTail(e int) {
newNode := &ListNode{data: e}
// 找到最后一个节点
p := l.head
for p.next != nil {
p = p.next
}
p.next = newNode
l.length++
}
// 按位置插入
func (l *LinkedList) Insert(i int, e int) bool {
if i < 0 || i > l.length {
return false
}
p := l.head
// 找到第i-1个节点
for j := 0; j < i; j++ {
p = p.next
}
newNode := &ListNode{data: e}
newNode.next = p.next
p.next = newNode
l.length++
return true
}
// 删除
func (l *LinkedList) Delete(i int) (int, bool) {
if i < 0 || i >= l.length {
return 0, false
}
p := l.head
for j := 0; j < i; j++ {
p = p.next
}
e := p.next.data
p.next = p.next.next // 跳过被删节点
l.length--
return e, true
}
// 打印
func (l *LinkedList) Print() {
p := l.head.next
for p != nil {
fmt.Printf("%d -> ", p.data)
p = p.next
}
fmt.Println("nil")
}
func main() {
list := NewLinkedList()
// 尾插建立 [10, 20, 30]
list.InsertTail(10)
list.InsertTail(20)
list.InsertTail(30)
list.Print()
// 输出: 10 -> 20 -> 30 -> nil
// 头插 5
list.InsertHead(5)
list.Print()
// 输出: 5 -> 10 -> 20 -> 30 -> nil
// 位置2插入15
list.Insert(2, 15)
list.Print()
// 输出: 5 -> 10 -> 15 -> 20 -> 30 -> nil
// 删除位置2
val, _ := list.Delete(2)
fmt.Printf("删除: %d\n", val)
// 输出: 删除: 15
list.Print()
// 输出: 5 -> 10 -> 20 -> 30 -> nil
}链表插入过程:
顺序表 vs 链表对比:
| 特性 | 顺序表 | 链表 |
|---|---|---|
| 存储空间 | 预先分配,可能浪费 | 动态分配,不浪费 |
| 访问速度 | O(1) 随机访问 | O(n) 必须顺序访问 |
| 插入删除 | 需要移动元素,O(n) | 只需改指针,O(1) |
| 适用场景 | 查询多、修改少 | 频繁插入删除 |
2.3 双链表 ------ 可以倒着走的"双向通道"
go
type DListNode struct {
data int
prior *DListNode // 前驱
next *DListNode // 后继
}
// 双链表插入(在p之后插入s)
func InsertAfter(p, s *DListNode) {
s.next = p.next
s.prior = p
p.next.prior = s // 如果p不是最后一个
p.next = s
}2.4 循环链表 ------ 首尾相接的"环形跑道"
第三章:栈和队列 ------ 特殊的线性表
3.1 栈(Stack)--- 后进先出(LIFO)
生活类比:叠盘子、弹夹、浏览器后退。
go
package main
import "fmt"
// 顺序栈
type SeqStack struct {
data []int
top int // -1表示空栈
}
func NewSeqStack(cap int) *SeqStack {
return &SeqStack{
data: make([]int, cap),
top: -1,
}
}
func (s *SeqStack) Push(e int) bool {
if s.top >= len(s.data)-1 {
return false // 栈满
}
s.top++
s.data[s.top] = e
return true
}
func (s *SeqStack) Pop() (int, bool) {
if s.top == -1 {
return 0, false // 栈空
}
e := s.data[s.top]
s.top--
return e, true
}
func (s *SeqStack) Peek() (int, bool) {
if s.top == -1 {
return 0, false
}
return s.data[s.top], true
}
func main() {
stack := NewSeqStack(10)
stack.Push(10)
stack.Push(20)
stack.Push(30)
top, _ := stack.Peek()
fmt.Printf("栈顶: %d\n", top)
// 输出: 栈顶: 30
val, _ := stack.Pop()
fmt.Printf("弹出: %d\n", val)
// 输出: 弹出: 30
val, _ = stack.Pop()
fmt.Printf("弹出: %d\n", val)
// 输出: 弹出: 20
}经典应用:括号匹配
go
func isValid(s string) bool {
stack := make([]rune, 0)
pairs := map[rune]rune{')': '(', ']': '[', '}': '{'}
for _, ch := range s {
if ch == '(' || ch == '[' || ch == '{' {
stack = append(stack, ch)
} else {
if len(stack) == 0 || stack[len(stack)-1] != pairs[ch] {
return false
}
stack = stack[:len(stack)-1]
}
}
return len(stack) == 0
}
func main() {
fmt.Println(isValid("({[]})")) // true
fmt.Println(isValid("({[})")) // false
}3.2 队列(Queue)--- 先进先出(FIFO)
生活类比:排队买票、打印机任务队列。
go
package main
import "fmt"
// 循环队列(解决假溢出)
type CircleQueue struct {
data []int
front int // 队头
rear int // 队尾(下一个插入位置)
capacity int
}
func NewCircleQueue(cap int) *CircleQueue {
return &CircleQueue{
data: make([]int, cap),
front: 0,
rear: 0,
capacity: cap,
}
}
func (q *CircleQueue) Enqueue(e int) bool {
if (q.rear+1)%q.capacity == q.front {
return false // 队满(牺牲一个空间区分空和满)
}
q.data[q.rear] = e
q.rear = (q.rear + 1) % q.capacity
return true
}
func (q *CircleQueue) Dequeue() (int, bool) {
if q.front == q.rear {
return 0, false // 队空
}
e := q.data[q.front]
q.front = (q.front + 1) % q.capacity
return e, true
}
func main() {
queue := NewCircleQueue(5) // 实际存4个元素
queue.Enqueue(10)
queue.Enqueue(20)
queue.Enqueue(30)
val, _ := queue.Dequeue()
fmt.Printf("出队: %d\n", val) // 10
queue.Enqueue(40)
queue.Enqueue(50)
// 此时队列: [20, 30, 40, 50]
for !isEmpty(queue) {
v, _ := queue.Dequeue()
fmt.Printf("%d ", v)
}
// 输出: 20 30 40 50
}
func isEmpty(q *CircleQueue) bool {
return q.front == q.rear
}循环队列原理: 
第四章:串(String)--- 字符的序列
4.1 串的定义与操作
串 :零个或多个字符组成的有限序列。
go
// Go 中字符串是不可变的字节序列
s := "Hello, 世界"
fmt.Println(len(s)) // 13(中文3字节)
fmt.Println(len([]rune(s))) // 9(字符数)
// 串的基本操作
fmt.Println(s[0:5]) // "Hello"(子串)
fmt.Println(s + "!") // "Hello, 世界!"(连接)
fmt.Println(s == "Hello, 世界") // true(比较)4.2 模式匹配 ------ 找子串的位置
BF算法(暴力匹配):逐个比较,最坏 O(m×n)
 KMP算法:利用已匹配信息,避免回溯,O(m+n)
KMP算法:利用已匹配信息,避免回溯,O(m+n)
go
// KMP 核心:next数组(部分匹配表)
func getNext(pattern string) []int {
next := make([]int, len(pattern))
next[0] = -1
i, j := 0, -1
for i < len(pattern)-1 {
if j == -1 || pattern[i] == pattern[j] {
i++
j++
next[i] = j
} else {
j = next[j]
}
}
return next
}第五章:数组和广义表 ------ 多维世界的扩展
5.1 数组 ------ 线性表的推广
go
// 一维数组(向量)
arr1 := [5]int{1, 2, 3, 4, 5}
// 二维数组(矩阵)
arr2 := [3][4]int{
{1, 2, 3, 4},
{5, 6, 7, 8},
{9, 10, 11, 12},
}
// 存储方式:行优先(C/Go)或列优先(Fortran)
// 行优先:a[0][0], a[0][1]...a[0][3], a[1][0]...特殊矩阵压缩存储:
| 矩阵类型 | 特点 | 压缩方法 |
|---|---|---|
| 对称矩阵 | aij = aji | 只存上/下三角 |
| 三角矩阵 | 上/下三角为常数 | 只存三角+一个常数 |
| 稀疏矩阵 | 大量零元素 | 三元组表 (i, j, value) |
go
// 稀疏矩阵三元组
type Triple struct {
row, col int
value int
}
// 十字链表(更高效的稀疏矩阵存储)
type OLNode struct {
row, col int
value int
right *OLNode // 行链表
down *OLNode // 列链表
}5.2 广义表 ------ 递归的线性表
广义表 :元素可以是原子 ,也可以是子表。
第六章:树 ------ 分层管理的艺术
树 :n个节点的有限集合,有且仅有一个根 ,其余节点分为互不相交的子树。
6.1 二叉树 ------ 最多两个孩子的树
go
// 二叉树节点
type BiTreeNode struct {
data int
lchild *BiTreeNode
rchild *BiTreeNode
}
// 遍历(核心!)
func PreOrder(root *BiTreeNode) {
if root == nil { return }
fmt.Print(root.data, " ") // 访问根
PreOrder(root.lchild) // 遍历左子树
PreOrder(root.rchild) // 遍历右子树
}
func InOrder(root *BiTreeNode) {
if root == nil { return }
InOrder(root.lchild)
fmt.Print(root.data, " ") // 中序:左-根-右
InOrder(root.rchild)
}
func PostOrder(root *BiTreeNode) {
if root == nil { return }
PostOrder(root.lchild)
PostOrder(root.rchild)
fmt.Print(root.data, " ") // 后序:左-右-根
}
// 层序遍历(用队列)
func LevelOrder(root *BiTreeNode) {
if root == nil { return }
queue := []*BiTreeNode{root}
for len(queue) > 0 {
node := queue[0]
queue = queue[1:]
fmt.Print(node.data, " ")
if node.lchild != nil {
queue = append(queue, node.lchild)
}
if node.rchild != nil {
queue = append(queue, node.rchild)
}
}
}遍历过程可视化:
6.2 线索二叉树 ------ 利用空指针
问题:n个节点的二叉树有 n+1 个空指针,浪费!
解决 :利用空指针存储前驱/后继(线索),方便遍历。
6.3 二叉搜索树(BST)--- 高效的查找结构
性质:左子树 < 根 < 右子树
go
// 查找
func BSTSearch(root *BiTreeNode, key int) *BiTreeNode {
for root != nil {
if key == root.data {
return root
} else if key < root.data {
root = root.lchild
} else {
root = root.rchild
}
}
return nil
}
// 插入
func BSTInsert(root **BiTreeNode, key int) bool {
if *root == nil {
*root = &BiTreeNode{data: key}
return true
}
if key == (*root).data {
return false // 已存在
} else if key < (*root).data {
return BSTInsert(&(*root).lchild, key)
} else {
return BSTInsert(&(*root).rchild, key)
}
}BST 查找过程:
6.4 AVL树 ------ 平衡的二叉搜索树
问题:BST 可能退化成链表(最坏 O(n))
解决 :AVL树要求左右子树高度差 ≤ 1 ,不平衡时旋转。
6.5 哈夫曼树 ------ 带权路径最短的树
应用:数据压缩(哈夫曼编码)
第七章:图 ------ 多对多的复杂关系
图:G = (V, E),V是顶点集,E是边集。
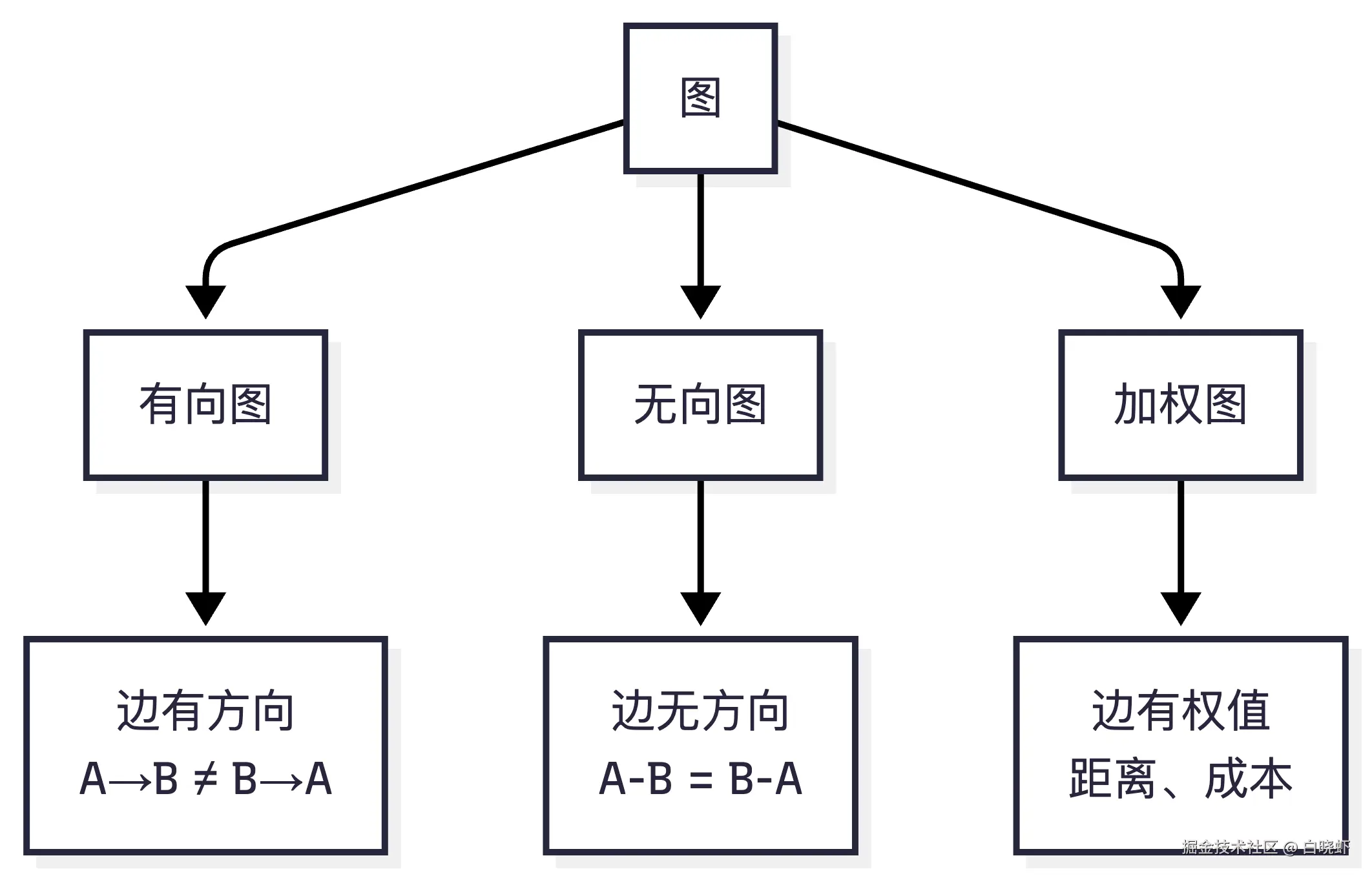
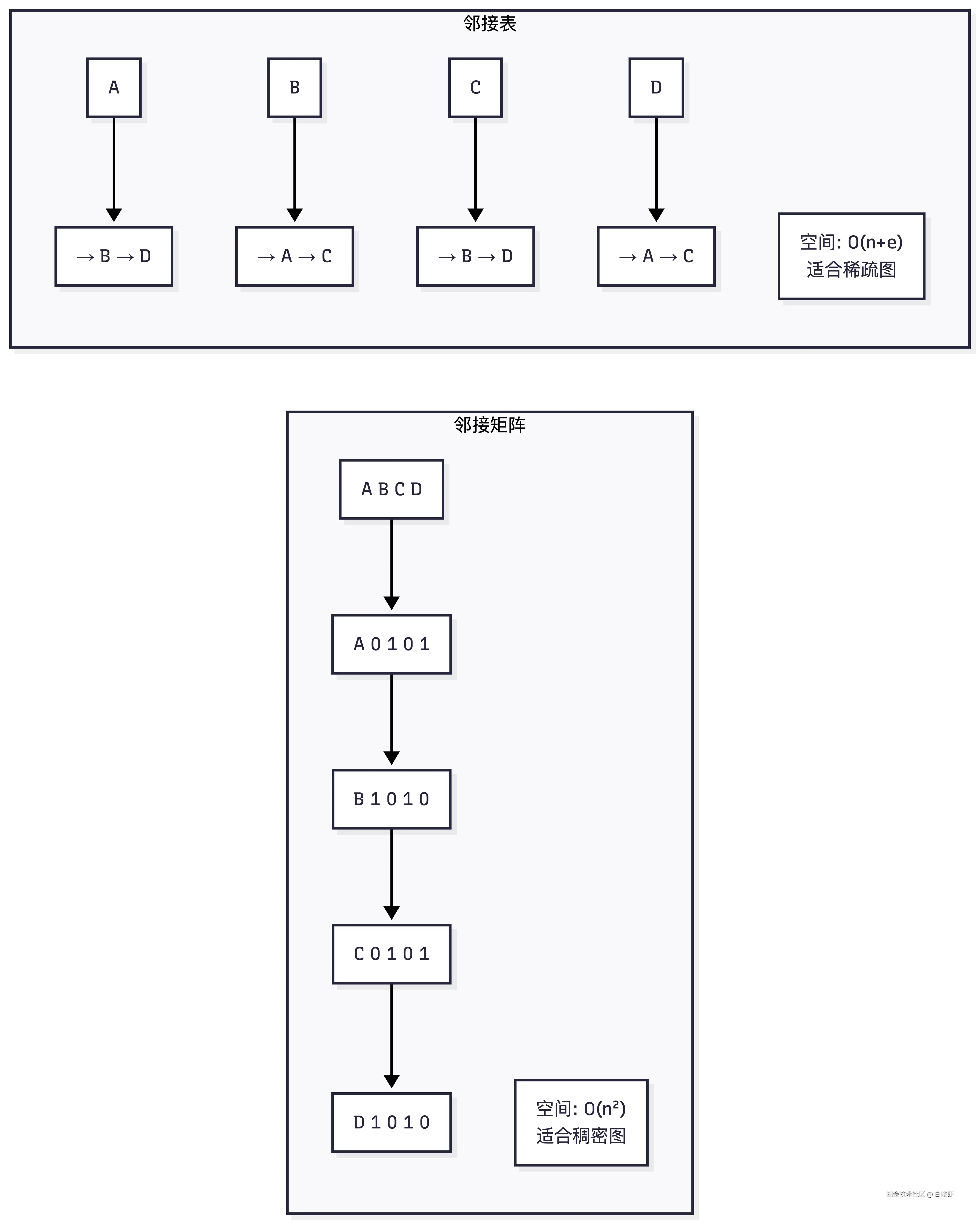
7.1 存储结构
go
// 邻接矩阵(适合稠密图)
type MGraph struct {
vexs []string // 顶点
arcs [][]int // 边矩阵
vexNum, arcNum int
}
// 邻接表(适合稀疏图)
type ArcNode struct {
adjVex int // 邻接点
weight int // 权值
nextArc *ArcNode // 下一条边
}
type VNode struct {
data string
firstArc *ArcNode
}
type ALGraph struct {
vertices []VNode
vexNum, arcNum int
}存储对比:
7.2 遍历
go
// 深度优先搜索(DFS)--- 类似树的前序
func DFS(g *ALGraph, v int, visited []bool) {
visited[v] = true
fmt.Print(g.vertices[v].data, " ")
for p := g.vertices[v].firstArc; p != nil; p = p.nextArc {
if !visited[p.adjVex] {
DFS(g, p.adjVex, visited)
}
}
}
// 广度优先搜索(BFS)--- 类似树的层序
func BFS(g *ALGraph, v int) {
visited := make([]bool, g.vexNum)
queue := []int{v}
visited[v] = true
for len(queue) > 0 {
v = queue[0]
queue = queue[1:]
fmt.Print(g.vertices[v].data, " ")
for p := g.vertices[v].firstArc; p != nil; p = p.nextArc {
if !visited[p.adjVex] {
visited[p.adjVex] = true
queue = append(queue, p.adjVex)
}
}
}
}DFS vs BFS 可视化:
7.3 最小生成树 ------ 连接所有顶点的最小代价
Prim算法 :从一个顶点开始,每次选最小边连接新顶点。
Kruskal算法 :按边权排序,每次选最小边,不形成环。
7.4 最短路径
Dijkstra算法 :单源最短路径,贪心策略,不能有负权边。
Floyd算法:所有顶点对最短路径,动态规划。
go
// Floyd 核心代码
for k := 0; k < n; k++ {
for i := 0; i < n; i++ {
for j := 0; j < n; j++ {
if dist[i][k] + dist[k][j] < dist[i][j] {
dist[i][j] = dist[i][k] + dist[k][j]
path[i][j] = k // 记录中间点
}
}
}
}
// 原理:如果经过k点更短,就更新第八章:查找表 ------ 快速定位的艺术
8.1 静态查找表
| 方法 | 条件 | 时间复杂度 |
|---|---|---|
| 顺序查找 | 无序 | O(n) |
| 二分查找 | 有序 | O(log n) |
| 分块查找 | 分块有序 | O(√n) |
go
// 二分查找(非递归)
func BinarySearch(arr []int, key int) int {
low, high := 0, len(arr)-1
for low <= high {
mid := (low + high) / 2
if arr[mid] == key {
return mid
} else if arr[mid] < key {
low = mid + 1
} else {
high = mid - 1
}
}
return -1
}二分查找过程:
8.2 动态查找表
- 二叉排序树:插入删除方便,但可能不平衡
- 平衡二叉树(AVL):自动平衡,查找稳定 O(log n)
- B树/B+树 :多路平衡树,数据库索引的核心
8.3 哈希表 ------ O(1) 的查找神话
核心思想 :通过哈希函数直接计算存储位置。
go
package main
import "fmt"
// 简单哈希表(拉链法解决冲突)
type HashTable struct {
buckets []*HashNode // 桶数组
size int
}
type HashNode struct {
key string
value int
next *HashNode // 冲突时用链表
}
func NewHashTable(size int) *HashTable {
return &HashTable{
buckets: make([]*HashNode, size),
size: size,
}
}
// 哈希函数(简单取模)
func (h *HashTable) hash(key string) int {
sum := 0
for _, ch := range key {
sum += int(ch)
}
return sum % h.size
}
// 插入
func (h *HashTable) Put(key string, value int) {
index := h.hash(key)
newNode := &HashNode{key: key, value: value}
// 头插法
newNode.next = h.buckets[index]
h.buckets[index] = newNode
}
// 查找
func (h *HashTable) Get(key string) (int, bool) {
index := h.hash(key)
p := h.buckets[index]
for p != nil {
if p.key == key {
return p.value, true
}
p = p.next
}
return 0, false
}
func main() {
ht := NewHashTable(10)
ht.Put("apple", 5)
ht.Put("banana", 3)
ht.Put("cherry", 8)
val, _ := ht.Get("banana")
fmt.Printf("banana: %d\n", val) // 3
// 查看哈希分布
for i, bucket := range ht.buckets {
count := 0
for p := bucket; p != nil; p = p.next {
count++
}
if count > 0 {
fmt.Printf("桶%d: %d个元素\n", i, count)
}
}
}哈希冲突解决:
第九章:排序算法 ------ 让数据井然有序
9.1 排序算法分类与对比
、
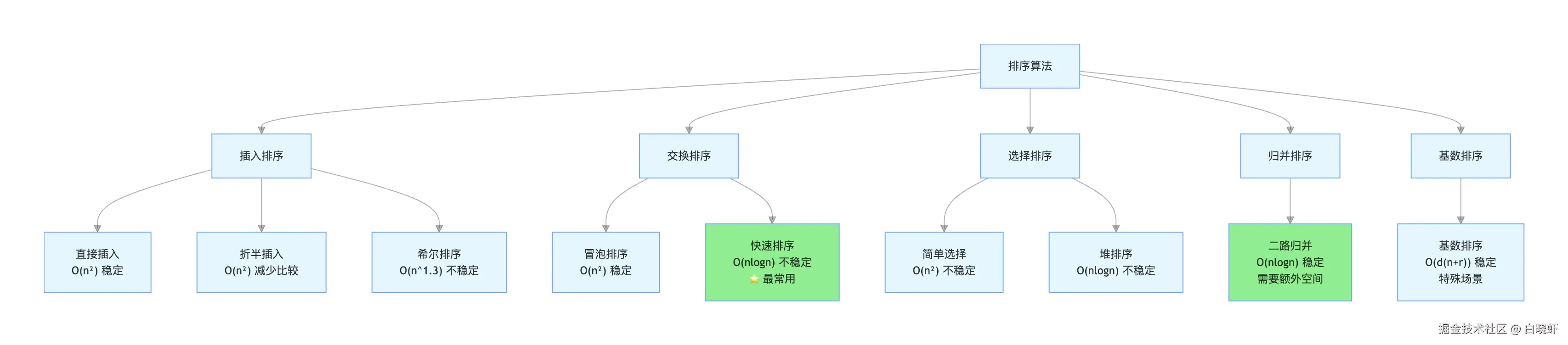
9.2 快速排序 ------ 分治的经典
go
package main
import "fmt"
func QuickSort(arr []int, low, high int) {
if low < high {
// 划分:pivot左边小,右边大
pivot := Partition(arr, low, high)
// 递归排序左右两部分
QuickSort(arr, low, pivot-1)
QuickSort(arr, pivot+1, high)
}
}
func Partition(arr []int, low, high int) int {
pivot := arr[low] // 选第一个为基准
for low < high {
// 从右找小的
for low < high && arr[high] >= pivot {
high--
}
arr[low] = arr[high]
// 从左找大的
for low < high && arr[low] <= pivot {
low++
}
arr[high] = arr[low]
}
arr[low] = pivot
return low
}
func main() {
arr := []int{49, 38, 65, 97, 76, 13, 27, 49}
fmt.Printf("排序前: %v\n", arr)
QuickSort(arr, 0, len(arr)-1)
fmt.Printf("排序后: %v\n", arr)
// 输出: 排序后: [13 27 38 49 49 65 76 97]
}快排过程可视化:
9.3 堆排序 ------ 选择排序的优化
go
// 建大顶堆,然后每次把堆顶(最大)放到末尾
func HeapSort(arr []int) {
n := len(arr)
// 从最后一个非叶子节点开始建堆
for i := n/2 - 1; i >= 0; i-- {
heapify(arr, n, i)
}
// 逐个取出最大值
for i := n - 1; i > 0; i-- {
arr[0], arr[i] = arr[i], arr[0] // 堆顶放到末尾
heapify(arr, i, 0) // 重新调整堆
}
}
func heapify(arr []int, n, i int) {
largest := i
left := 2*i + 1
right := 2*i + 2
if left < n && arr[left] > arr[largest] {
largest = left
}
if right < n && arr[right] > arr[largest] {
largest = right
}
if largest != i {
arr[i], arr[largest] = arr[largest], arr[i]
heapify(arr, n, largest) // 递归调整
}
}堆排序过程:
知识总串联:从线性到非线性,从简单到复杂
核心 :数据结构不是背出来的,是画出来的、写出来的、调出来的。每学一个结构,一定要亲手用 Go 实现一遍,才能真正掌握!