Transformer实战(40)------Transformer时间序列数据建模
0. 前言
Transformer 因其在自然语言处理 (Natural Language Processing, NLP) 任务中的优异表现而被广泛应用,其主要优势在于能够有效建模时间序列数据。这些数据可以是文本,也可以是非文本。本节将介绍如何使用 Transformer 进行时间序列数据建模和预测,将学习时间序列的基本概念,并在此基础上使用一个简单的模型,用以初步了解时间序列数据,并为各种预测任务奠定基础。同时,还将学习 Transformer 与传统方法的不同之处,以及如何将 Transformer 模型应用于时间序列数据建模。
1. 时间序列概念
时间序列数据通常是一组按特定方法测量的观测值,这些观测值在测量间隔上有内在的关联,此类数据可以来自物理或非物理的测量。例如,房间温度可以通过物理设备在特定时间间隔内进行测量。
根据任务的不同,可以对从特定来源测量的数据应用不同的机器学习任务。例如,给定一个特定的时间范围,可以使用回归分析预测未来的值;而对于给定的时间序列,也可以使用分类任务。
时间序列预测是时间序列领域中最重要的任务之一。在这一任务中,给定一个时间段模型预测未来的值。例如,使用预测分析来预测特定商品的价格,如电视或橘子价格预测。从时间序列数据中预测未来数据的过程也称为时间序列回归,通过时间序列数据学习统计模型。这个统计模型用于根据给定的历史数据预测未来。
该领域的另一个重要任务是时间序列分类。给定一个信号,分类器会根据历史数据,并将其分类为给定的类别集。例如,当给定汽车发动机噪音在特定时间内的传感器测量值,模型可以预测引擎是否存在问题。测量也会影响数据的质量,时间序列数据通常来自物理或非物理现象的测量,这些数据可能会受到噪音的影响。噪音是测量中的常见问题,可能是传感器故障或其他因素所导致的。对于分类器或回归模型来说,克服这一问题至关重要。
对于时间序列数据,最简单的是移动平均模型,但这类模型无法反映时间序列数据中传递的信息,其改进方法,如自回归积分移动平均模型 (AutoRegressive Integrated Moving Average, ARIMA),表现更好,但与 Transformer 相比,同样具有不足之处。
在时间序列数据领域中,针对不同类型的数据建模,也提出了多种创新性的方法。例如,为了预测股票的未来价格,可以将其视为一个环境,将模型视为一个智能体。在这种范式下,可以应用强化学习方法。智能体可以进行买入、卖出或持有股票,并且在每个时间戳下,它都需要决定采取什么动作。训练将从智能体对环境的探索开始,以了解采取不同动作的后果,通过学习,智能体会形成一个策略,帮助其理解应采取的最佳行动。接下来,智能体利用所学的知识来最大化奖励。尽管这种方法可能不适用于所有类型的时间序列问题,但了解不同的建模类型非常重要。
Transformer 是理解序列数据的最佳工具之一,它们已经在 NLP 中展示了其优越性。已经提出了多种使用 Transformer 进行时间序列预测的方法,包括 Transformer、Informer、LogFormer、Reformer 和 AutoFormer,每种方法都有其优缺点。
在下一节中,将进一步学习如何使用 Transformer 进行时间序列数据建模,包括分类和回归预测,还将了解这一应用背后的基本思想及其实现方式。
2. Transformer 时间序列建模
在深入学习 Transformer 用于时间序列建模之前,首先了解移动平均等基本方法。移动平均方法通过一个历史数据窗口并计算平均值来预测未来值,它会不断迭代数据以预测下一个值。
2.1 数据加载
(1) 首先,下载时间序列(股票价格)数据。
(2) 通过打印变量查看数据样本:
python
import numpy as np
import pandas as pd
data = pd.read_csv('stock_data.csv')
data.head(5)输出结果如下所示:

(3) 绘制折线图可视化数据:
python
from matplotlib import pyplot as plt
plt.plot(data['Close'])
plt.show()结果如下所示:
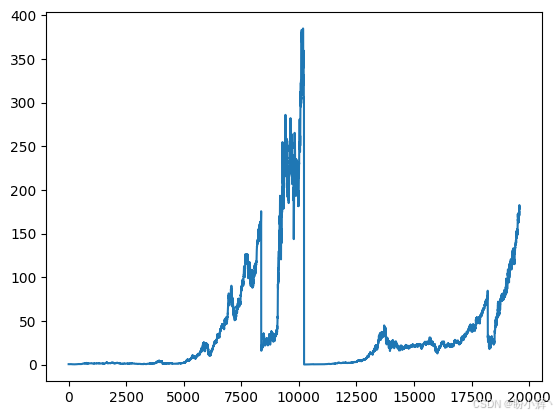
2.2 移动平均方法
(1) 对数据应用移动平均:
python
data["moving_average"] = data["Close"].rolling(10).mean()(2) 可视化移动平均结果:
python
data[['Close','moving_average']].plot()结果如下所示:
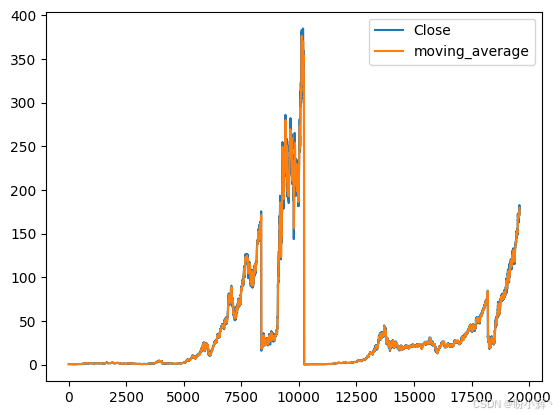
从可视化结果中可以看出,移动平均方法能够在一定程度上预测未来值。为了了解其预测值与实际值之间的差距,可以使用均方误差 (Mean Squared Error, MSE) 等误差指标来衡量差异。差距较大是因为它仅关注过去窗口的值,在本节中,窗口大小为 10。这意味着它仅根据过去 10 个时间步的值计算平均值,然后将该值视为未来值。然而,时间序列问题并不像看起来那么简单。在股票预测问题中,有许多外部和内部市场参数都会影响结果,像移动平均这样简单的模型无法捕捉数据中的特定模式,也无法预测太远的未来,因为如果过去引入任何误差,它将会被传播到未来。
(6) 假设我们的目标是仅预测下一个值;通过预测值和实际值,计算 MSE:
python
from sklearn.metrics import mean_squared_error
mean_squared_error(data["Close"][9:], data["moving_average"][9:])结果如下所示,可以看到误差非常大:
shell
24.8909653868925此外,移动平均这类方法还有一个缺点,即当存在缺失值时无法处理。针对这个问题,引入了一些解决方法,例如用前一个值、窗口的均值,甚至是零来替换缺失值,但这些方法也存在不同的问题。
2.3 Transformer 模型
Transformer 能够像BERT处理掩码词元 (mask token) 一样处理缺失值。我们从一个简单的示例开始,目标是预测比特币第二天的价格是高于还是低于前一天,可以将其视为一个分类问题。在本节中,我们将实现一个基于 Transformer 的时间序列分类模型,并观察其表现。
首先,我们需要将数据集转换为所需的格式。股票的初始价格是以每日收盘价表示的,对于每个样本,我们获取过去30天的数据,并且预测该周期之后的第二天的价格是上涨还是下降。
对整个数据集应用一个 31 天的滑动窗口。创建一系列窗口,每个窗口包含三十个值,滑动窗口获取预测的真实值------如果前 30 天的均值低于第 31 天的值,模型应该预测为 0;否则,应预测为 1。同时,对整个窗口的值执行归一化,以便模型训练更加稳定。
(1) 将数据集转换为 NumPy 格式:
python
dataset_x = []
dataset_y = []
for i in range(0, data.shape[0]-31):
# if data[i : i + 31].Close.shape[0] == 31:
dataset_y.append(
1
if data[i : i + 30].Close.mean() < data.iloc[i + 30].Close
else 0
)
mean_ = data[i : i + 30].Close.mean()
std_ = data[i : i + 30].Close.std()
dataset_x.append(list((data[i : i + 30].Close - mean_) / std_))
import numpy as np
dataset_x = np.array(dataset_x)
dataset_y = np.array(dataset_y)
dataset_x = dataset_x.reshape(dataset_x.shape[0],dataset_x.shape[1],1)
train_x, test_x = dataset_x[:3000], dataset_x[3000:]
train_y, test_y = dataset_y[:3000], dataset_y[3000:]
print(train_x.shape)
print(train_y.shape)(2) 构建基于 Transformer 的模型,首先实现 Transformer 编码器:
python
from tensorflow.keras import layers
def encoder(inputs, head_size, num_heads, feed_forward_dimension, dropout=0):
# 确保输入是 3D 张量
if len(inputs.shape) == 2:
inputs = layers.Reshape((1, inputs.shape[-1]))(inputs)
# Attention layer
x = layers.MultiHeadAttention(
key_dim=head_size, num_heads=num_heads, dropout=dropout
)(inputs, inputs)
x = layers.Dropout(dropout)(x)
x = layers.LayerNormalization(epsilon=1e-6)(x)
attention_result = x + inputs
# Convlution as feedforward
x = layers.Conv1D(filters=feed_forward_dimension, kernel_size=1, activation="relu")(
attention_result
)
x = layers.Dropout(dropout)(x)
x = layers.Conv1D(filters=inputs.shape[-1], kernel_size=1)(x)
x = layers.LayerNormalization(epsilon=1e-6)(x)
return x + attention_result(3) 接下来,使用 encoder 模块创建实际模型:
python
def build_model(input_shape, head_size, num_heads, ff_dim, dropout, num_transformer_blocks, dense_units, dense_dropout):
inputs = keras.Input(shape=input_shape)
x = inputs
for _ in range(num_transformer_blocks):
x = encoder(x, head_size, num_heads, ff_dim, dropout)
x = layers.GlobalAveragePooling1D(data_format="channels_first")(x)
for d in dense_units:
x = layers.Dense(d, activation="relu")(x)
x = layers.Dropout(dense_dropout)(x)
outputs = layers.Dense(2, activation="softmax")(x)
return keras.Model(inputs, outputs)(4) 然后,编译模型并查看模型架构:
python
import tensorflow as tf
model = build_model(
input_shape=train_x.shape[1:],
head_size=256,
num_heads=4,
ff_dim=4,
dropout=0.25,
num_transformer_blocks=4,
dense_units=[128],
dense_dropout=0.4,
)
model.summary()输出结果如下所示:
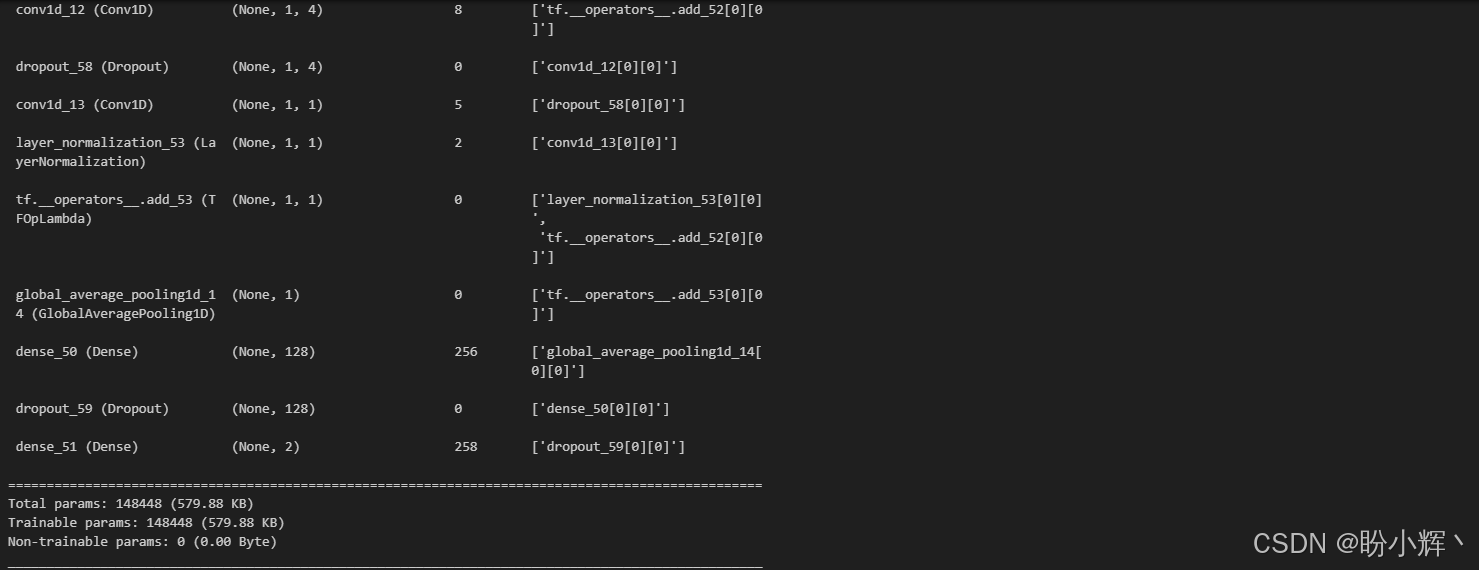
(5) 模型和数据准备完毕后,开始训练模型:
python
model.compile(
loss="sparse_categorical_crossentropy",
optimizer=keras.optimizers.Adam(learning_rate=1e-4),
metrics=["sparse_categorical_accuracy"],
)(6) 可以在模型训练过程中使用回调函数,例如,使用提前停止 (early stopping),它会在模型性能无法继续改进时提前停止模型训练:
python
callbacks = [keras.callbacks.EarlyStopping(patience=5, restore_best_weights=True)](7) 训练并评估模型:
python
model.fit(
train_x,
train_y,
epochs=5,
batch_size=32,
callbacks=callbacks,
)
model.evaluate(test_x, test_y, verbose=1)可以看到,仅经过几个 epoch 并使用少量数据样本,就可以取得不错的结果:

除了分类之外,还可以通过简单的修改将相同的模型改为预测下一个值,即回归任务。可以使用 sigmoid 激活函数后输出值而不进行分类。此外,还需要将损失函数改为 MSE。同时,还要对需要预测的真实值进行一些小的调整。
小结
在本节中,我们学习了时间序列数据的基础知识以及如何将 Transformer 应用于时间序列数据。Transformer 可以应用于时间序列数据,因为它们能够处理时间序列中的未知值,而大多数模型无法做到这一点。
系列链接
Transformer实战(1)------词嵌入技术详解
Transformer实战(2)------循环神经网络详解
Transformer实战(3)------从词袋模型到Transformer:NLP技术演进
Transformer实战(4)------从零开始构建Transformer
Transformer实战(5)------Hugging Face环境配置与应用详解
Transformer实战(6)------Transformer模型性能评估
Transformer实战(7)------datasets库核心功能解析
Transformer实战(8)------BERT模型详解与实现
Transformer实战(9)------Transformer分词算法详解
Transformer实战(10)------生成式语言模型 (Generative Language Model, GLM)
Transformer实战(11)------从零开始构建GPT模型
Transformer实战(12)------基于Transformer的文本到文本模型
Transformer实战(13)------从零开始训练GPT-2语言模型
Transformer实战(14)------微调Transformer语言模型用于文本分类
Transformer实战(15)------使用PyTorch微调Transformer语言模型
Transformer实战(16)------微调Transformer语言模型用于多类别文本分类
Transformer实战(17)------微调Transformer语言模型进行多标签文本分类
Transformer实战(18)------微调Transformer语言模型进行回归分析
Transformer实战(19)------微调Transformer语言模型进行词元分类
Transformer实战(20)------微调Transformer语言模型进行问答任务
Transformer实战(21)------文本表示(Text Representation)
Transformer实战(22)------使用FLAIR进行语义相似性评估
Transformer实战(23)------使用SBERT进行文本聚类与语义搜索
Transformer实战(24)------通过数据增强提升Transformer模型性能
Transformer实战(25)------自动超参数优化提升Transformer模型性能
Transformer实战(26)------通过领域适应提升Transformer模型性能
Transformer实战(27)------参数高效微调(Parameter Efficient Fine-Tuning,PEFT)
Transformer实战(28)------使用 LoRA 高效微调 FLAN-T5
Transformer实战(29)------大语言模型(Large Language Model,LLM)
Transformer实战(30)------Transformer注意力机制可视化
Transformer实战(31)------解释Transformer模型决策
Transformer实战(32)------Transformer模型压缩
Transformer实战(33)------高效自注意力机制
Transformer实战(34)------多语言和跨语言Transformer模型
Transformer实战(35)------跨语言相似性任务
Transformer实战(36)------Transformer模型部署
Transformer实战(37)------Transformer模型训练追踪与监测
Transformer实战(38)------视觉Transformer
Transformer实战(39)------多模态生成式Transformer