Claude 4.7来了,但中国用户可能再也用不到了
Anthropic在同一周干了两件事:发布了可能是目前最强的编程模型Claude Opus 4.7,同时启动了对中国用户的"精准清场"。作为一名每天深度依赖Claude工作的从业者,我想聊聊这一周的心情。

@toc
01 冰火两重天的一周
4月16日深夜,Anthropic发布了Claude Opus 4.7。
两天前的4月14日,Anthropic悄悄上线了KYC实名认证机制。
这两个动作同时发生,让中国AI社区经历了一场情绪过山车:前脚还在讨论"新模型编程能力炸了",后脚就发现"自己的账号可能用不了了"。
我身边一个做独立开发的朋友,4.7发布那天兴奋地跟我说"SWE-bench直接跳了11个百分点",第二天早上打开电脑就收到了验证弹窗,要求他手持护照拍照。他没有外国护照,当天下午账号就被封了。
这大概就是2026年中国AI从业者最真实的写照:你追着世界前沿跑,但世界一直在给你关上大门。
02 Opus 4.7:确实是最强的编程模型
先说模型本身。
Claude Opus 4.7在编程领域的提升是实打实的,这一点几乎所有评测者都认可。SWE-bench Pro从53.4%跳涨到64.3%,碾压GPT-5.4的57.7%和Gemini 3.1 Pro的54.2%。在Cursor实战基准CursorBench上,从58%跳到70%。 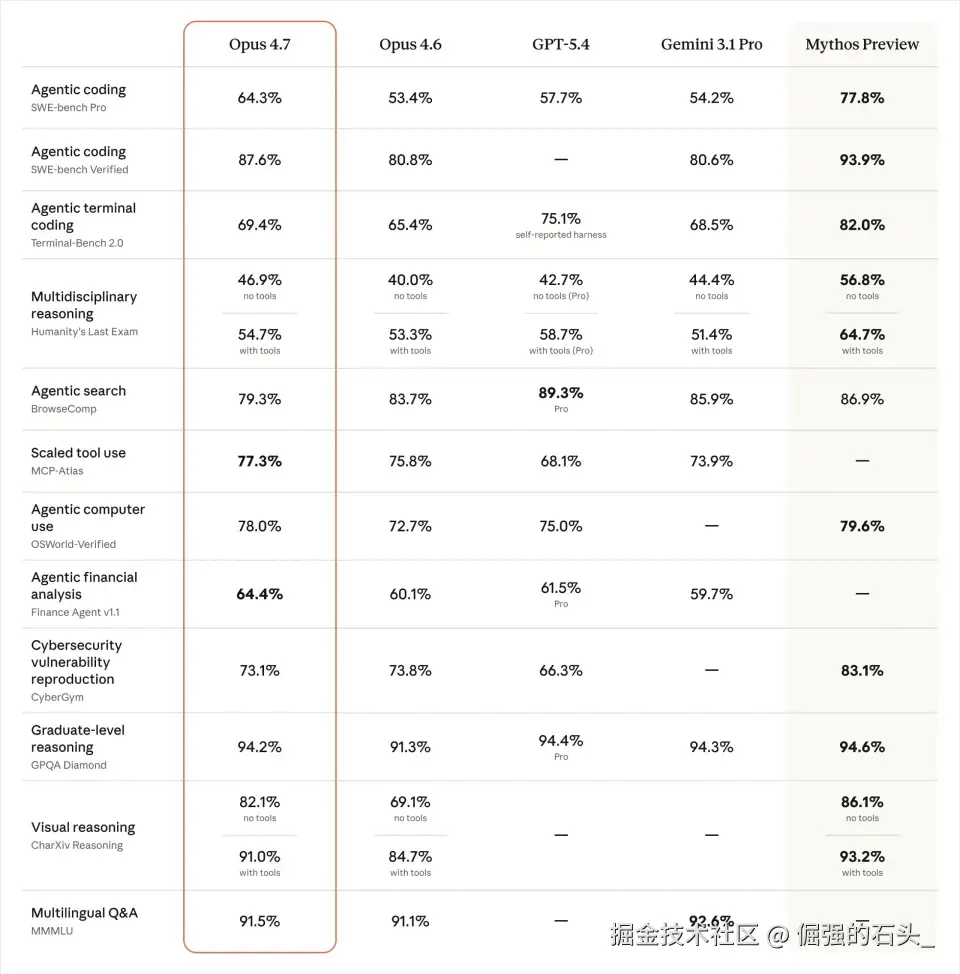
真实用户反馈更有说服力:
Rakuten(乐天)说Opus 4.7解决的生产任务数量是4.6的3倍;Devin背后的Cognition公司说它可以"连续工作数小时而不掉线";代码审查工具CodeRabbit说召回率提升超过10%,"比GPT-5.4的xhigh模式还快"。
Anthropic自己的93任务编码基准测试里,Opus 4.7比4.6多解决了13%的任务------其中包括4个4.6和Sonnet 4.6都搞不定的"地狱级"任务。Hex的CTO说:"低effort档的Opus 4.7,大约等于中effort档的Opus 4.6。"
视觉能力也是断崖式提升。精准度从54.5%跳到98.5%,支持的图像分辨率从115万像素提升到375万像素,是前代的3倍多。以前截个屏让Claude看bug经常把字读错,现在基本不犯了。
作为编程工具,Opus 4.7确实是目前综合最强的。这一点没得黑。
03 但"最强"的代价你承受得起吗?
然而,"最强"两个字背后,是沉重的代价。
第一,隐性涨价35%。
Anthropic这次换了一个新的tokenizer(分词器)。新的tokenizer号称"改进了文本处理效率",但副作用是------同样的文字,会被切成更多的token,大约是原来的1.0到1.35倍。定价没变(输入 5/百万token,输出25/百万token),但你的账单会涨。 
叠加默认推理深度从high提升到新增的xhigh档位------token消耗进一步推高。一个Reddit用户的原话:"4.7的消耗速度像核反应堆一样。"
第二,长上下文崩了。
Anthropic自己的数据:百万token长上下文记忆测试(MRCR v2),Opus 4.6得分78.3%,Opus 4.7得分32.2% 。暴跌46个百分点。联网搜索BrowseComp评分也从83.7%掉到79.3%,被GPT-5.4的89.3%甩开一截。 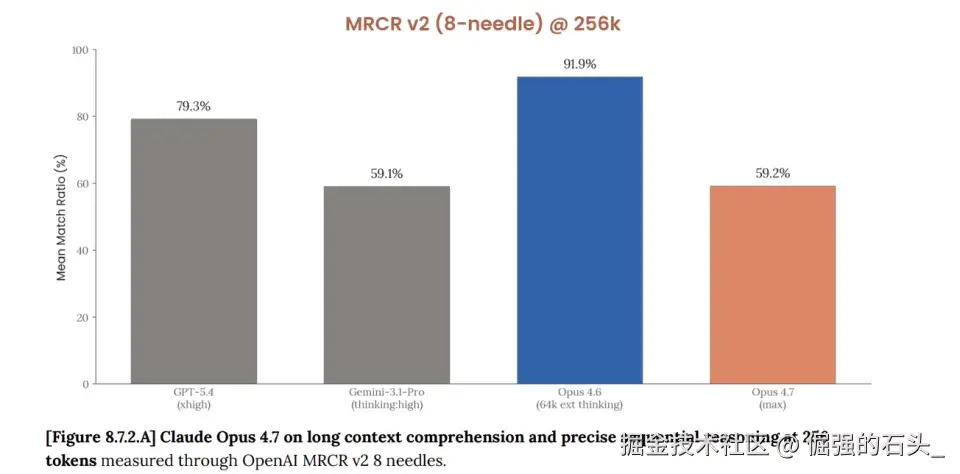
第三,文风变了。
大量写作者反映,Opus 4.7开始出现"大厂味"------满嘴"稳稳接住""压实闭环"这种互联网黑话,破折号乱用,续写内容干巴巴。一位AI博主形容:"好好的Claude,也开始不说人话了。"
第四,Claude自己都说它不是最强的。
Anthropic在官方公告里亲口写道:Opus 4.7的能力"不如Claude Mythos Preview"。Mythos是一周前发布的"真王",能自主发现藏了27年的Linux内核零日漏洞,但只对Apple、Google、Microsoft等少数合作伙伴开放。
Anthropic主动说"这个不是我们最强的",这在AI行业几乎是破天荒的。这意味着Anthropic开始做取舍了------不是每个版本都必须全面领先,而是在编程、视觉、成本之间做trade-off。
04 然后,KYC来了
如果说Opus 4.7的技术取舍还属于"可以讨论的范围",那接下来这件事,就直接触到了中国用户的生存底线。
4月14日,Anthropic在帮助中心悄悄上线了身份验证页面。4月15日起,大量用户开始收到弹窗:必须手持政府签发的实体证件(护照/驾照/身份证)原件进行实时拍照验证,否则无法继续使用。
验证规则堪称严苛:只接受护照、驾照或身份证原件,复印件、扫描件、数字证件、临时身份证统统不行。流程由第三方公司Persona Identities执行。
但最让用户头皮发麻的,是官方FAQ里的这段话:**账户即便完成验证,照样可能被禁用。**理由包括从不支持的位置创建账户、违反服务条款、未满18岁使用。
这不是通行证,是"精准清场"的预检。 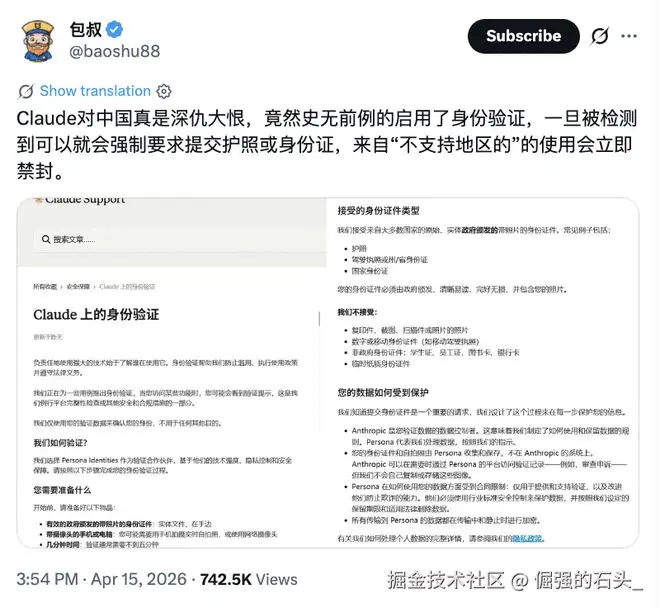
05 中国用户:最尴尬的存在
在这场KYC风暴中,中国用户是最受伤的群体。
中国护照不被支持。 根据多方反馈,Persona的验证系统不接受中国护照作为有效证件。这意味着,通过各种方式使用Claude的中国极客和开发者,连"验证"的资格都没有。
封号逻辑从IP过滤升级到身份过滤。 Anthropic同期更新了"unsupported regions"销售限制说明,明确点名中国是不支持的区域。大规模封号已经从检测你的IP地址,升级为检测你的身份信息------即便你用了美国IP、买了虚拟信用卡,只要身份核验过不了关,账号就面临封禁。
完成认证也可能被封。 不少用户反映,即便完成了KYC验证,账号还是被封了。Reddit上的情绪可以用一条高赞评论概括:"Claude做KYC,不是反蒸馏,真正要清洗的是薅羊毛的中国人。"
一位在X平台上的中国开发者写道:"Claude不是不能用,而是越来越不稳定,国内厂商目前没有一个能完全接住它,且可用性正被风控手段一点点蚕食。"
中文互联网上甚至出现了一个黑色幽默段子:大家都在问"李彦宏到底对达里奥做了什么"。Anthropic CEO达里奥·阿莫代伊曾在百度工作过一年,网友们苦中作乐地调侃,他在百度的经历让他"对中国的执念比OpenAI还要深"。
调侃背后是深深的无奈。
06 Persona:一个不让人放心的第三方
KYC争议的另一个焦点是Anthropic选择的合作伙伴------Persona Identities。 
Persona是一家美国头部身份验证服务商,也为OpenAI和Discord等公司提供服务。但它在隐私领域的名声并不好。
今年初,安全研究人员在一个与联邦风险授权管理计划(FedRAMP)关联的Google Cloud服务器上,发现了近2500个Persona的前端文件,无需任何漏洞利用即可访问。这些文件揭示Persona的验证能力远超年龄确认:它可执行多达269种不同的验证检查,包括将用户面部与监控名单比对、筛查政治敏感人物、在恐怖主义和间谍活动等14个类别中进行负面媒体扫描,并为用户信息分配风险评分。
而且Persona的隐私条款显示,其拥有17个子处理器可能接触用户数据,且允许将数据用于"改善反欺诈能力"------这意味着你的身份证照片可能被用来训练Persona的AI模型。
更讽刺的是,这已经不是第一次出事了。2025年10月,Discord的另一家验证供应商5CA遭到黑客入侵,超过7万名用户的政府身份证件照片泄露。Discord随后引入Persona作为替代,但不到一个月双方合作即告终止。
如今Anthropic选择了这家同样争议缠身的公司。 
你以为"安全"是Anthropic的品牌核心?用户发现,所谓的"安全"只关乎模型本身,而不关乎使用模型的人。
07 一个15岁少年被封号的故事
KYC还暴露了一个容易被忽视的问题:年龄限制。
Claude的最低使用年龄是18岁。而OpenAI和Gemini的最低使用年龄仅13岁。
一位网名为llm_nerd的用户在Reddit上分享了他的经历:他15岁的儿子是一名游戏程序员,订阅了Claude Max服务,通过AI编程接单开发,收入甚至超过了父亲。但账号因被系统检测为未成年人使用而遭封禁。Anthropic发邮件明确告知:"检测到你的账户被儿童使用,违反了我们的规定。"
最终Anthropic退了一整月的订阅费,未按已使用天数扣除------但一个少年开发者的职业生涯被打断了。
有网友讽刺道:OpenAI和Gemini 13岁就能用,Anthropic非要18岁,这是"自绝于年轻开发者"。
当一个15岁的少年靠AI编程月入过万,你却告诉他"你还不够格使用这个工具"------这件事本身就足够荒诞了。
08 我们面对的到底是什么
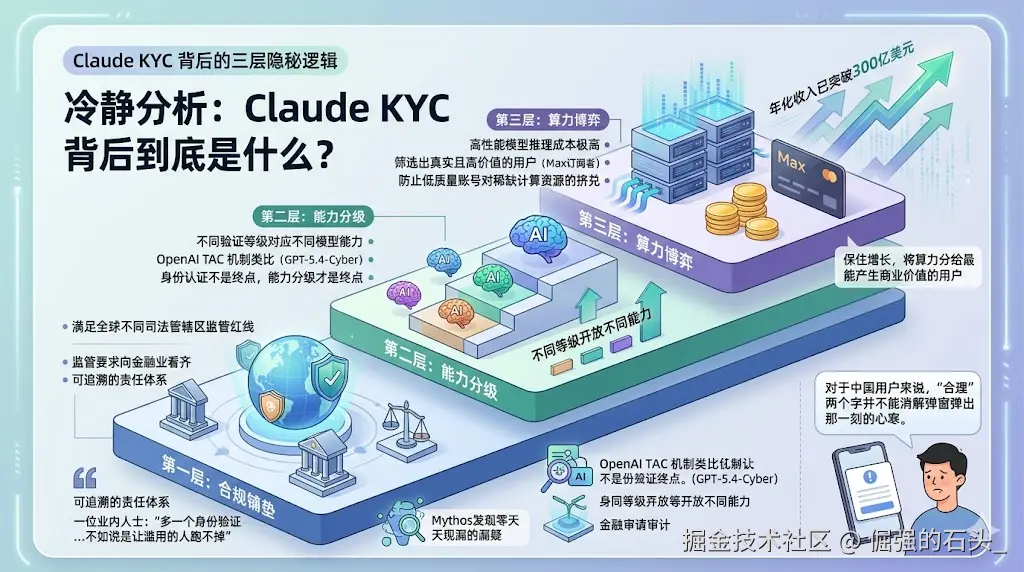
冷静下来想一想,Claude的KYC背后其实有三层逻辑。
第一层:合规铺垫。 随着AI能力越来越强------Claude Mythos能自主发现系统零日漏洞,金融机构用Claude处理交易核算------监管机构的要求正在向金融业看齐。Anthropic需要一套可追溯的责任体系,以满足全球不同司法管辖区的监管红线。一位业内人士说:"多一个身份验证,与其说是为了'防滥用',不如说是为了'让滥用的人跑不掉'。"
第二层:能力分级。 OpenAI推出GPT-5.4-Cyber时已经搞了TAC机制------不同验证等级对应不同模型能力。Anthropic的KYC很可能走同一条路。今天让你验证身份,明天就能根据验证等级开放不同能力。身份认证不是终点,能力分级才是终点。
第三层:算力博弈。 高性能模型的推理成本极高。通过身份验证筛选出真实且高价值的用户(Max订阅者),可以有效防止低质量账号对稀缺计算资源的挤兑。Anthropic年化收入已突破300亿美元,首超OpenAI------但它要保住这个增长,就必须把算力分给最能产生商业价值的用户。
这三层逻辑每一条都站得住脚。但对于中国用户来说,"合理"两个字并不能消解弹窗弹出那一刻的心寒。
09 中国用户的突围之路
Claude的围墙越高,中国开发者越需要找到替代方案。目前社区里主要有三条路:
第一条:API聚合平台。 一些平台聚合了Gemini、GPT、Claude等顶级模型,国内网络即可访问。开发者不需要直接面对Anthropic的KYC,一行代码都不用改。这是目前最平滑的过渡方案。
第二条:国产大模型组合拳。 目前的业界共识是,国内没有任何一家大模型能单挑Claude,但可以通过模型组合实现降维替代:
- 纯代码编写 → 智谱GLM(推理逻辑和代码风格最接近Claude)
- 内容创作 → 通义千问(稳定性极高,API性价比高)
- 长文本处理 → Kimi(学术论文和长资料分析有战力)
- 自动化工程 → MiniMax(并发处理能力强)
第三条:开源本地部署。 当闭源大厂纷纷走向合规、实名和严控,追求隐私和灵活度的用户必然会拥抱本地化部署。这条路技术门槛最高,但也最不受制约。
数据显示,3月份豆包月活达3.31亿,千问月活2.23亿,DeepSeek月活1.37亿------中国大模型的使用基数已经不小了。Claude越是收紧限制,中国AI产品在海外市场的反向渗透就越猛烈。
"Claude无法使用后,这些用户大概率会流回国产大模型。"一位已经转向国产模型的从业者说。
10 我的一点私人感受
写这篇文章的时候,我的Claude Max账号还能用。
但我已经把所有重要的工作流都做了备份------prompt文档、CLAUDE.md配置、常用的技能脚本,全部导出存到了本地。不是因为我觉得Claude不好用了,而是因为我已经学会了一个教训:在2026年,任何海外AI工具都可能在某一天突然对你关上门。
前几天看到一个帖子,标题是" Claude不是不能用而是越来越不稳定"。底下一条评论说:"能用一天是一天,谁叫Claude模型真的牛逼呢。"
这句话看得人鼻子发酸。
三年前我们用GPT-3.5的时候,觉得AI是全人类的礼物。三年后的今天,AI变得越来越强,但能用到最强AI的人却越来越少。你要有合适的国籍、合适的年龄、合适的支付方式、合适的网络环境------然后还要祈祷某天不会突然弹出一个KYC窗口,告诉你"请证明你有资格使用这个工具"。
Opus 4.7确实很强。编程能力碾压GPT-5.4,视觉精准度接近满分,自验证机制让复杂任务真正可以放手。
但一个你用不了的"最强模型",跟你有什么关系呢?
AI正在全面告别想用就用的玩具阶段,正式跨入重器监管的深水区。 未来高能力的AI可能会像高级金融账户一样,需要极为复杂的信用背书和身份背书。
对于每一个中国AI从业者来说,尽快告别对单一海外巨头的路径依赖,在手里多备几把国产化模型作为防身武器------这不是选择,是生存策略。
Claude Opus 4.7很好。但我已经不确定,下个月我还能不能打开它了。