环境
bash
系统:CentOS-7
CPU : E5-2680V4 14核28线程
内存:DDR4 2133 32G * 2
显卡:Tesla V100-32G【PG503】 (水冷)
驱动: 535
CUDA: 12.2下载
https://modelscope.cn/models/Jackrong/Qwopus3.5-27B-v3-GGUF
Ollama配置MF
clike
FROM /models/Qwopus3.5-27B/Qwopus3.5-27B-v3-Q4_K_M.gguf
# --------------------------------------------------------------------------
# 🎯 CHAT TEMPLATE (Qwen3.5 Compatible)
# --------------------------------------------------------------------------
TEMPLATE """{{- if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}{{- range .Messages }}
{{- if eq .Role "user" }}<|im_start|>user
{{ .Content }}<|im_end|>
{{- else if eq .Role "assistant" }}<|im_start|>assistant
{{ .Content }}<|im_end|>
{{- end }}
{{- end }}<|im_start|>assistant
"""
SYSTEM """You are Qwopus3.5-27B-v3, an advanced AI assistant optimized for NVIDIA V100 32GB.
- Provide accurate, concise, and well-structured responses
- Use chain-of-thought reasoning for complex tasks
- Support multilingual input but default to user's language
- Decline harmful requests politely but firmly"""
# --------------------------------------------------------------------------
# ⚙️ HARDWARE OPTIMIZATION (V100-32GB CRITICAL)
# --------------------------------------------------------------------------
# ✓ 修正: Context 设为 4096 (平衡速度与显存),可按需调整
PARAMETER num_ctx 64096
# ✓ 批处理大小: 提升推理吞吐量 (显存允许下尽量大)
PARAMETER num_batch 512
# ✓ GPU 层数: 99 层全卸载,若 OOM 则降至 85-90
PARAMETER num_gpu 99
# ✓ CPU 线程: 匹配物理核心数,避免超线程开销
PARAMETER num_thread 8
# ✓ 内存映射: 加速加载,允许 swap 缓冲
PARAMETER use_mmap true
# ✓ (可选) 低显存模式: 若频繁 OOM 可启用
# PARAMETER low_vram true
# --------------------------------------------------------------------------
# 🎲 SAMPLING PARAMETERS (Balanced Quality/Speed)
# --------------------------------------------------------------------------
PARAMETER temperature 0.7
PARAMETER top_p 0.9
PARAMETER top_k 40
PARAMETER min_p 0.05
PARAMETER repeat_penalty 1.1
PARAMETER typical_p 0.9
PARAMETER presence_penalty 0.0
PARAMETER frequency_penalty 0.0
# --------------------------------------------------------------------------
# 🛑 OUTPUT CONTROL & STOP SEQUENCES
# --------------------------------------------------------------------------
# 标准 Qwen3.5 stop tokens
PARAMETER stop "<|im_end|>"
PARAMETER stop "<|im_start|>"
PARAMETER stop "<|user|>"
PARAMETER stop "<|assistant|>"
PARAMETER stop "<|system|>"
PARAMETER stop "</s>"
# 对话连贯性控制
PARAMETER num_keep 512运行
clike
ollama create Qwopus3.5-27B-V3 -f Modelfile验证模型
clike
http://192.168.1.222:11434/v1/models下载Easyclaw
clike
https://easyclaw.cn/安装
clike
windows下正常下一步安装启动
配置Ollama本地模型
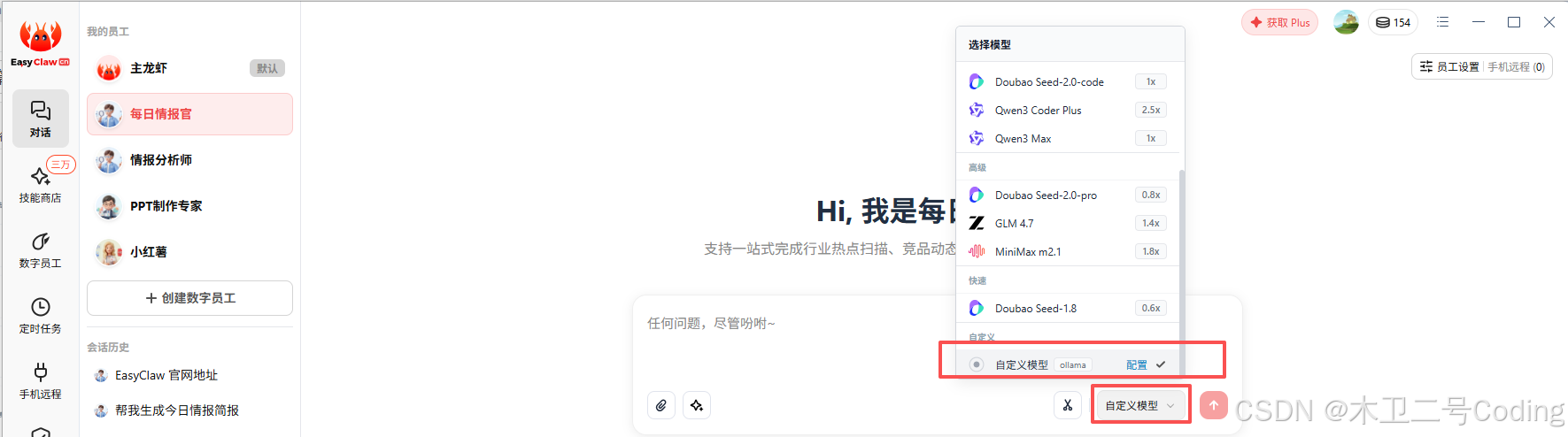
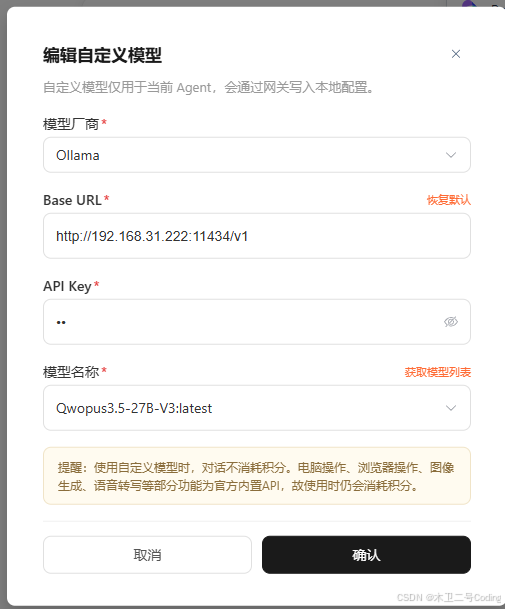
开始使用
可以正常使用了,速度还可以