模型管理平台实战:Ollama本地部署与全流程指南
在大模型应用开发的浪潮中,本地部署大模型 已经成为开发者和企业的刚需。无论是出于数据隐私保护、降低API调用成本,还是离线环境使用的需求,拥有一个轻量、高效、易用的本地模型运行环境都至关重要。而Ollama正是目前最受欢迎的本地大模型管理平台之一,它让原本复杂的模型部署和管理变得像安装软件一样简单。
本文将带你从零开始,全面了解Ollama的核心优势、详细部署步骤、基础使用方法、高级配置技巧,以及如何与Dify等AI应用开发平台无缝集成,让你快速搭建起自己的本地大模型生态。
一、为什么选择Ollama?
在介绍具体部署步骤之前,我们先搞清楚一个问题:市面上有这么多本地大模型运行工具(如LM Studio、Text Generation WebUI、llama.cpp),为什么Ollama能够脱颖而出?
1.1 Ollama是什么
Ollama是一个开源的本地大语言模型运行和管理平台,它基于llama.cpp进行了深度优化和封装,提供了一套简洁的命令行工具和RESTful API,让用户可以在几秒钟内启动并运行各种主流的大语言模型。
Ollama的核心理念是**"一键运行"**,它自动处理了模型下载、量化、依赖安装、环境配置等所有繁琐的步骤,用户只需要一条命令就能运行最新的大模型。
1.2 Ollama的核心优势
| 特性 | 说明 |
|---|---|
| 极致简单 | 一条命令安装,一条命令运行模型,无需任何复杂配置 |
| 模型丰富 | 支持Llama 3、Qwen、Gemma、Mistral、Phi等几乎所有主流开源大模型 |
| 自动量化 | 自动提供4-bit、8-bit等不同量化级别的模型,平衡性能和精度 |
| 跨平台支持 | 完美支持Windows、macOS(含Apple Silicon)和Linux |
| 硬件加速 | 原生支持NVIDIA CUDA、Apple Metal和AMD ROCm加速 |
| API友好 | 提供与OpenAI兼容的RESTful API,方便与其他应用集成 |
| 轻量高效 | 资源占用低,即使在消费级显卡上也能流畅运行7B-13B模型 |
| 模型管理 | 内置模型仓库,支持模型的下载、删除、查看和版本管理 |
1.3 与其他工具的对比
- vs llama.cpp:llama.cpp是底层引擎,功能强大但使用复杂,需要手动编译和管理模型;Ollama是基于llama.cpp的上层封装,提供了更友好的用户体验。
- vs LM Studio:LM Studio有图形界面,适合非技术用户;Ollama更适合开发者和自动化场景,提供了强大的API和命令行工具。
- vs Text Generation WebUI:Text Generation WebUI功能最丰富,但配置复杂,资源占用高;Ollama轻量快速,专注于核心的模型运行和管理功能。
二、Ollama部署前准备
2.1 硬件要求
Ollama对硬件的要求相对较低,不同大小的模型需要不同的硬件配置:
| 模型大小 | 最低显存要求 | 推荐显存 | 推荐CPU | 内存 |
|---|---|---|---|---|
| 7B | 4GB(4-bit量化) | 8GB | 4核 | 16GB |
| 13B | 8GB(4-bit量化) | 16GB | 8核 | 32GB |
| 34B | 16GB(4-bit量化) | 32GB | 16核 | 64GB |
| 70B | 32GB(4-bit量化) | 64GB | 32核 | 128GB |
注意:
- 以上为4-bit量化模型的要求,8-bit量化模型需要翻倍的显存
- Apple Silicon芯片的统一内存架构表现优异,M1/M2/M3 Pro及以上芯片可以流畅运行7B-13B模型
- 如果没有独立显卡,Ollama也可以纯CPU运行,但速度会慢很多
2.2 软件要求
- Windows:Windows 10 1903及以上版本,需要开启WSL 2
- macOS:macOS 12 Monterey及以上版本
- Linux:内核版本4.15及以上,支持systemd
三、Ollama详细部署步骤
3.1 macOS部署
macOS是Ollama体验最好的平台,尤其是Apple Silicon芯片,得益于统一内存架构和Metal加速,运行速度非常快。
安装方法:
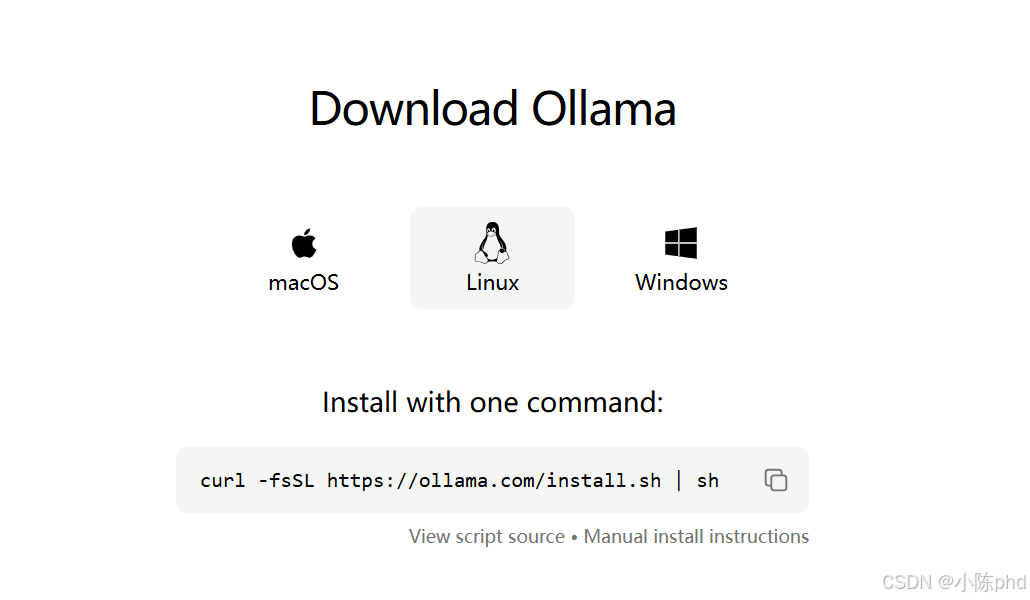
- 访问Ollama官网:https://ollama.com/
- 点击"Download for macOS"下载安装包
- 双击下载的
.dmg文件,将Ollama拖到应用程序文件夹 - 打开终端,输入以下命令验证安装:
bash
ollama --version或者使用Homebrew一键安装:
bash
brew install ollama3.2 Linux部署
Linux部署同样非常简单,官方提供了一键安装脚本。
安装方法:
bash
# 一键安装
curl -fsSL https://ollama.com/install.sh | sh
# 验证安装
ollama --version手动安装(适用于无法访问外网的环境):
- 从GitHub Releases页面下载对应架构的安装包:https://github.com/ollama/ollama/releases
- 解压并安装:
bash
# 以amd64架构为例
tar -xzf ollama-linux-amd64.tgz
sudo mv ollama /usr/local/bin/
sudo mv ollama.service /etc/systemd/system/
# 启动服务
sudo systemctl daemon-reload
sudo systemctl enable ollama
sudo systemctl start ollama3.3 Windows部署
Windows部署需要WSL 2支持,这是因为Ollama在Windows上是通过WSL 2运行的。
安装步骤:
-
开启WSL 2:
- 以管理员身份打开PowerShell
- 运行命令:
wsl --install - 重启电脑
-
安装Ollama:
- 访问Ollama官网:https://ollama.com/
- 点击"Download for Windows"下载安装包
- 双击安装包,按照提示完成安装
- 打开PowerShell或命令提示符,输入以下命令验证安装:
powershell
ollama --version四、Ollama基础使用
安装完成后,我们就可以开始使用Ollama来管理和运行大模型了。
4.1 运行第一个模型
Ollama最强大的地方就是可以一键运行模型。以运行最新的Llama 3 8B模型为例:
bash
ollama run llama3这条命令会自动:
- 从Ollama模型仓库下载Llama 3 8B的4-bit量化模型
- 加载模型到内存/显存
- 启动交互式对话界面
下载完成后,你就可以直接在终端中与模型对话了:
>>> 你好,介绍一下你自己
我是Llama 3,由Meta开发的大型语言模型。我可以帮助你回答问题、撰写文章、编写代码、进行翻译等各种任务。
要退出对话,输入/bye或按Ctrl+D。
4.2 常用命令
Ollama提供了丰富的命令来管理模型:
bash
# 查看所有可用命令
ollama help
# 查看本地已安装的模型
ollama list
# 下载模型(不运行)
ollama pull qwen:7b
# 删除本地模型
ollama rm qwen:7b
# 查看模型信息
ollama show llama3
# 复制模型
ollama cp llama3 my-llama3
# 创建自定义模型
ollama create my-model -f Modelfile
# 启动Ollama服务
ollama serve4.3 模型标签说明
Ollama的模型名称后面可以跟标签,用于指定不同的版本和量化级别:
llama3:默认标签,通常是最新版本的4-bit量化模型llama3:8b:指定8B参数版本llama3:70b:指定70B参数版本llama3:8b-instruct-q8_0:指定8B指令微调版本的8-bit量化模型llama3:latest:总是使用最新版本
你可以在Ollama模型库(https://ollama.com/library)查看所有可用的模型和标签。
五、Ollama高级配置
5.1 自定义模型(Modelfile)
Ollama支持通过Modelfile来自定义模型,你可以修改模型的系统提示词、温度、上下文窗口大小等参数。
示例Modelfile:
dockerfile
# 基础模型
FROM llama3:8b
# 系统提示词
SYSTEM "你是一个专业的技术助手,擅长回答编程和计算机相关的问题。回答要简洁、准确、有条理。"
# 温度参数(0-1,越低越确定,越高越有创造性)
PARAMETER temperature 0.3
# 上下文窗口大小
PARAMETER num_ctx 4096
# 最大生成token数
PARAMETER num_predict 2048
# 停止词
PARAMETER stop "<|end_of_text|>"创建自定义模型:
bash
ollama create tech-assistant -f Modelfile
# 运行自定义模型
ollama run tech-assistant5.2 API调用
Ollama提供了与OpenAI兼容的RESTful API,默认运行在http://localhost:11434。
生成补全:
bash
curl http://localhost:11434/api/generate -d '{
"model": "llama3",
"prompt": "为什么天空是蓝色的?",
"stream": false
}'聊天补全:
bash
curl http://localhost:11434/api/chat -d '{
"model": "llama3",
"messages": [
{
"role": "user",
"content": "为什么天空是蓝色的?"
}
],
"stream": false
}'列出本地模型:
bash
curl http://localhost:11434/api/tags5.3 远程访问配置
默认情况下,Ollama只允许本地访问。如果你想让其他设备也能访问你的Ollama服务,需要修改配置:
Linux/macOS:
bash
# 设置环境变量
export OLLAMA_HOST=0.0.0.0
# 重启Ollama服务
sudo systemctl restart ollamaWindows:
- 按下
Win+R,输入sysdm.cpl - 点击"高级"选项卡,然后点击"环境变量"
- 在"系统变量"中点击"新建"
- 变量名:
OLLAMA_HOST,变量值:0.0.0.0 - 点击确定,重启电脑
现在,其他设备就可以通过你的IP地址访问Ollama服务了:http://你的IP:11434
六、Ollama与Dify集成
这是本文最重要的部分,因为Ollama与Dify的结合可以让你快速搭建起完全本地化的AI应用开发平台。
6.1 集成步骤
- 确保Ollama服务正在运行:
bash
ollama serve-
打开Dify控制台,进入"系统设置" -> "模型供应商"
-
点击"添加模型供应商",选择"Ollama"
-
填写配置信息:
- 模型名称:自定义名称,如"Ollama-Llama3"
- 基础URL:
http://localhost:11434/v1(如果Dify和Ollama在同一台机器上) - API密钥:任意填写,Ollama默认不需要API密钥
- 模型类型:选择"文本生成"
- 支持的模型:填写你在Ollama中已安装的模型名称,如
llama3, qwen:7b
-
点击"保存",然后点击"测试连接",如果显示连接成功,就说明集成完成了。
6.2 使用本地模型创建应用
集成完成后,你就可以在Dify中使用Ollama提供的本地模型来创建各种AI应用了:
- 进入Dify控制台,点击"创建应用"
- 选择应用类型(如对话型应用、知识库问答应用)
- 在"模型设置"中,选择你刚才添加的Ollama模型
- 配置提示词和其他参数
- 发布应用,开始使用
这样,你就拥有了一个完全本地化的AI应用,所有数据都不会离开你的服务器,完美解决了数据隐私问题。
七、常见问题与解决方案
7.1 模型下载速度慢
解决方案:
- 使用国内镜像源:
bash
# Linux/macOS
export OLLAMA_MODELS=https://ollama.fly.dev
# Windows
set OLLAMA_MODELS=https://ollama.fly.dev- 手动下载模型文件,然后导入到Ollama
7.2 显存不足
解决方案:
- 使用更小参数的模型(如7B代替13B)
- 使用更低量化级别的模型(如4-bit代替8-bit)
- 关闭其他占用显存的程序
- 增加虚拟内存(效果有限)
7.3 无法远程访问
解决方案:
- 检查防火墙设置,确保11434端口已开放
- 确认
OLLAMA_HOST环境变量已设置为0.0.0.0 - 检查网络连接是否正常
7.4 模型运行缓慢
解决方案:
- 确保硬件加速已启用(NVIDIA CUDA、Apple Metal)
- 使用更快的存储设备(SSD)
- 减少上下文窗口大小
- 降低模型量化级别
八、总结与展望
Ollama的出现极大地降低了本地大模型部署和使用的门槛,让每个开发者都能轻松拥有自己的大模型运行环境。通过与Dify等AI应用开发平台的集成,我们可以快速构建出各种生产级的生成式AI应用,同时保证数据的安全性和隐私性。
未来,Ollama还会继续完善其功能,支持更多的模型和硬件加速,提供更强大的API和工具链。相信在不久的将来,本地大模型会成为每个开发者和企业的标配,推动AI技术的普及和应用。
如果你还没有尝试过Ollama,现在就动手安装一个吧!只需几分钟,你就能体验到本地大模型的魅力。