一、简介
1、介绍
Azkaban 是由Linkedin 公司推出的工作流任务调度器,主要用于在一个工作流内以一个特定的顺序运行一组工作和流程,它的配置是通过简单的key:value对的方式,通过配置中的Dependencies 来设置依赖关系。Azkaban使用job配置文件建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪创建的工作流。
官网地址![]() https://azkaban.github.io/
https://azkaban.github.io/
2、工作流调度系统
1)一个完整的数据分析系统通常都是由大量任务单元组成: Shell 脚本程序,Java程序,MapReduce程序、Hive脚本等
2)各任务单元之间存在时间先后及前后依赖关系
3)为了很好地组织起这样的复杂执行计划,需要一个工作流调度系统来调度执行;
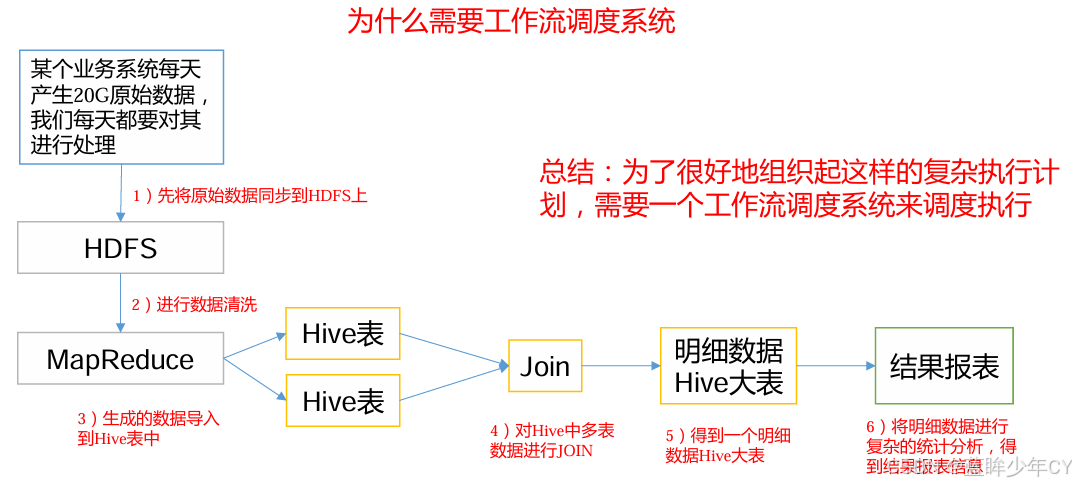
例如,有这样一个需求,某个业务系统每天产生 20G 原始数据,每天都要对其进行处理。
处理步骤如下所示:
通过Hadoop先将原始数据上传到HDFS上(HDFS的操作);
使用MapReduce对原始数据进行清洗(MapReduce的操作);
将清洗后的数据导入到hive表中(hive的导入操作);
对Hive中多个表的数据进行JOIN处理,得到一张hive的明细表(创建中间表);
通过对明细表的统计和分析,得到结果报表信息(hive的查询操作);
3、特点
-
- 兼容任何版本的hadoop
-
- 易于使用的Web用户界面
-
- 简单的工作流的上传
-
- 方便设置任务之间的关系
-
- 调度工作流
-
- 模块化和可插拔的插件机制
-
- 认证/授权(权限的工作)
-
- 能够杀死并重新启动工作流
-
- 有关失败和成功的电子邮件提醒
4、架构
-
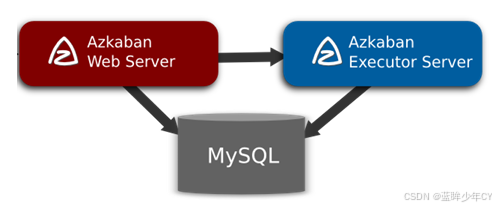
AzkabanWebServer:AzkabanWebServer是整个Azkaban工作流系统的主要管理者, 用户登录认证、负责project 管理、定时执行工作流、跟踪工作流执行进度等一 系列任务。
-
AzkabanExecutorServer:负责具体的工作流的提交、执行,通过mysql数据库来协调任务的执行。
-
关系型数据库(MySQL):存储大部分执行流状态,AzkabanWebServer 和 AzkabanExecutorServer 都需要访问数据库。
二、安装与启动
1、准备工作
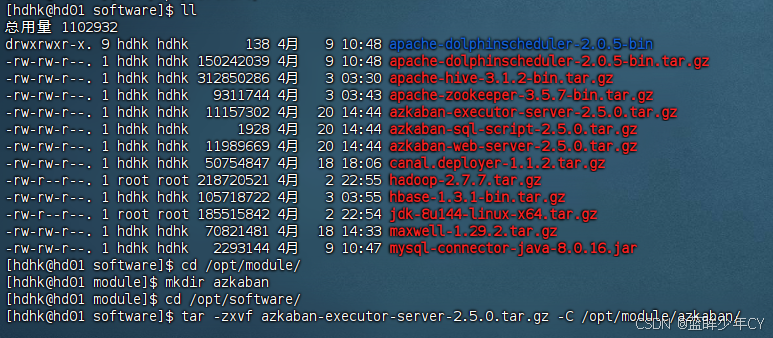
(1)上传并解压
下载地址![]() http://azkaban.github.io/downloads.html 将Azkaban Web 服务器、Azkaban 执行服务器、Azkaban 的sql执行脚本上传到/opt/software目录下,并解压
http://azkaban.github.io/downloads.html 将Azkaban Web 服务器、Azkaban 执行服务器、Azkaban 的sql执行脚本上传到/opt/software目录下,并解压
a) azkaban-web-server-2.5.0.tar.gz
b) azkaban-executor-server-2.5.0.tar.gz
c) azkaban-sql-script-2.5.0.tar.gz
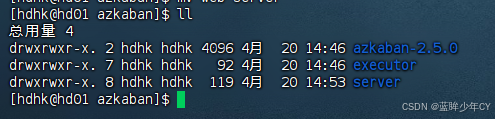
(2)执行sql脚本
创建azkaban数据库,并将解压的脚本导入到azkaban数据库。
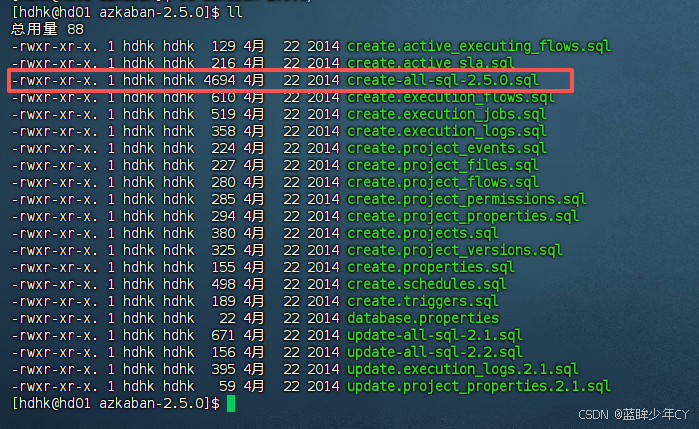
(3)生成密钥对和证书
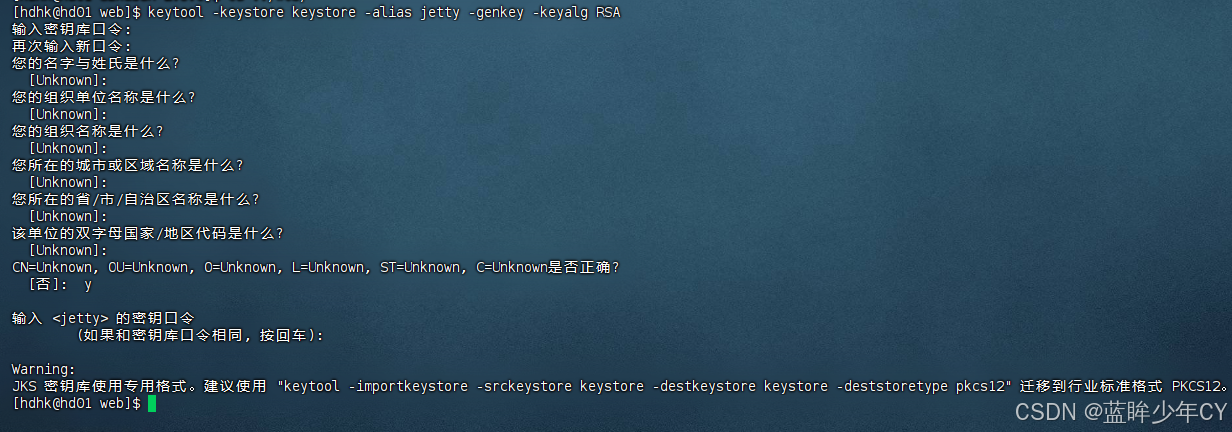
Keytool是java数据证书的管理工具,使用户能够管理自己的公/私钥对及相关证书。
keytool -keystore keystore -alias jetty -genkey -keyalg RSA
-keystore 指定密钥库的名称及位置(产生的各类信息将存在.keystore文件中)
-genkey(或者-genkeypair) 生成密钥对
-alias 为生成的密钥对指定别名,如果没有默认是mykey
-keyalg 指定密钥的算法 RSA/DSA 默认是DSA
在web目录下进行创建
2、修改配置文件
(1)修改web服务器配置
1)在server/conf目录,修改azkaban.properties文件
......
#默认web server存放web文件的目录
web.resource.dir=/opt/module/azkaban/server/web/
#默认时区,已改为亚洲/上海 默认为美国
default.timezone.id=Asia/Shanghai
#Azkaban UserManager class
user.manager.class=azkaban.user.XmlUserManager
#用户权限管理默认类(绝对路径) user.manager.xml.file=/opt/module/azkaban/server/conf/azkaban-users.xml
#Loader for projects #global配置文件所在位置(绝对路径)
executor.global.properties=/opt/module/azkaban/executor/conf/global.pro perties azkaban.project.dir=projects
#数据库类型
database.type=mysql
#端口号
mysql.port=3306
#数据库连接IP
mysql.host=hd01
#数据库实例名
mysql.database=azkaban
#数据库用户名
mysql.user=root
#数据库密码
mysql.password=root
#最大连接数
mysql.numconnections=100
Velocity dev mode
velocity.dev.mode=false
Azkaban Jetty server properties.
Jetty服务器属性.
#最大线程数
jetty.maxThreads=25
#Jetty SSL端口
jetty.ssl.port=8443
#Jetty端口
jetty.port=8081
#SSL文件名(绝对路径)
jetty.keystore=/opt/module/azkaban/server/keystore
#SSL文件密码
jetty.password=123456
#Jetty主密码与keystore文件相同
jetty.keypassword=123456
#SSL文件名(绝对路径)
jetty.truststore=/opt/module/azkaban/server/keystore
#SSL文件密码
jetty.trustpassword=123456
Azkaban Executor settings
executor.port=12321
........
2)修改用户配置
在server/conf目录,修改azkaban-users.xml文件
<azkaban-users>
<user username="azkaban" password="azkaban" roles="admin" groups="azkaban" />
<user username="metrics" password="metrics" roles="metrics"/>
<user username="admin" password="admin" roles="admin,metrics"/>
<role name="admin" permissions="ADMIN" />
<role name="metrics" permissions="METRICS"/>
</azkaban-users>
(2)执行服务器配置
修改executor/conf目录下的azkaban.properties
#Azkaban
#时区
default.timezone.id=Asia/Shanghai
Azkaban JobTypes Plugins
#jobtype 插件所在位置
azkaban.jobtype.plugin.dir=plugins/jobtypes
#Loader for projects executor.global.properties=/opt/module/azkaban/executor/conf/global.properties azkaban.project.dir=projects
database.type=mysql
mysql.port=3306
mysql.host=192.168.10.139
mysql.database=azkaban
mysql.user=root
mysql.password=root
mysql.numconnections=100
Azkaban Executor settings
#最大线程数
executor.maxThreads=50
#端口号(如修改,请与web服务中一致)
executor.port=12321
#线程数
executor.flow.threads=30
3、启动服务
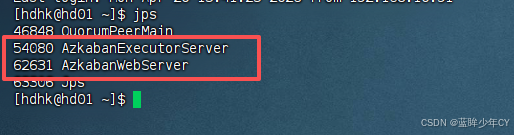
注意: 先执行executor,再执行web,避免Web Server会因为找不到执行器启动失败。
启动Executor服务器
/opt/module/azkaban/executor/bin/azkaban-executor-start.sh
启动Web服务器
/opt/module/azkaban/server/bin/azkaban-web-start.sh
4、访问
https://服务器IP地址:8443,即可访问 azkaban 服务了。
三、实战案例
1、入门案例
输出:HelloWord
(1)创建 .job文件
第一个入门案例
type=command
command= echo 'hello word azkaban'

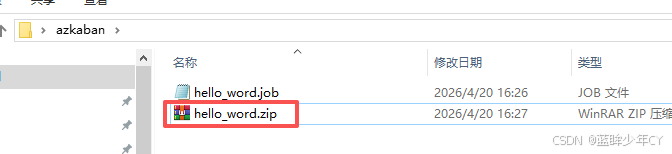
(2)打包成zip文件
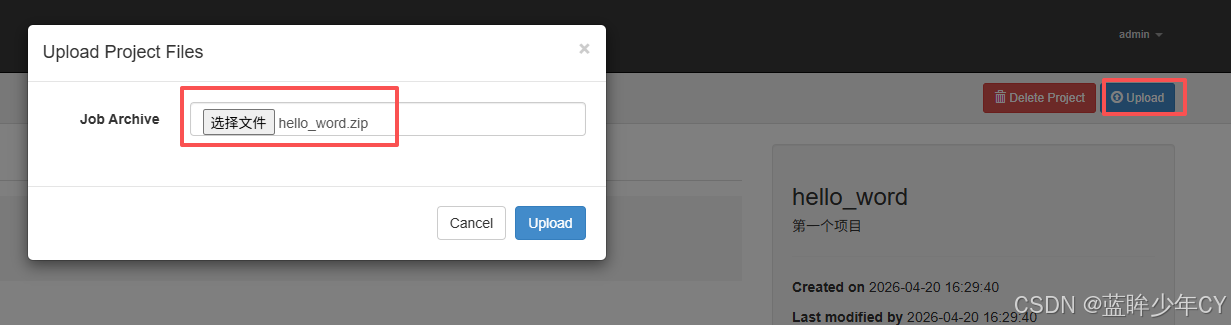
(3)上传文件
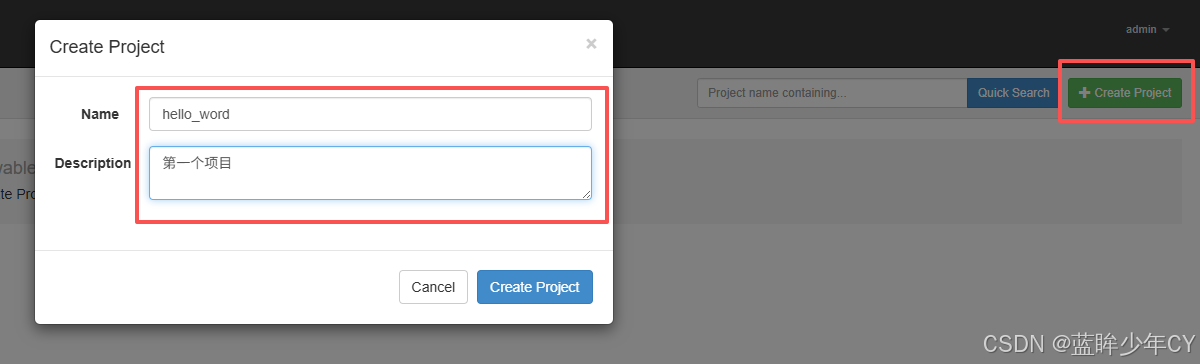
创建项目
上传文件
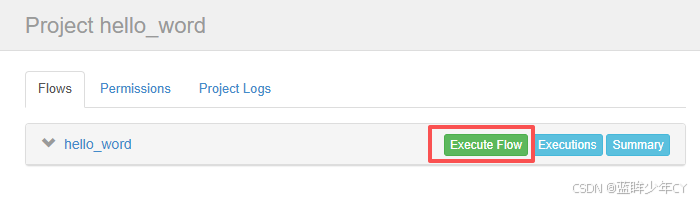
(4)执行任务
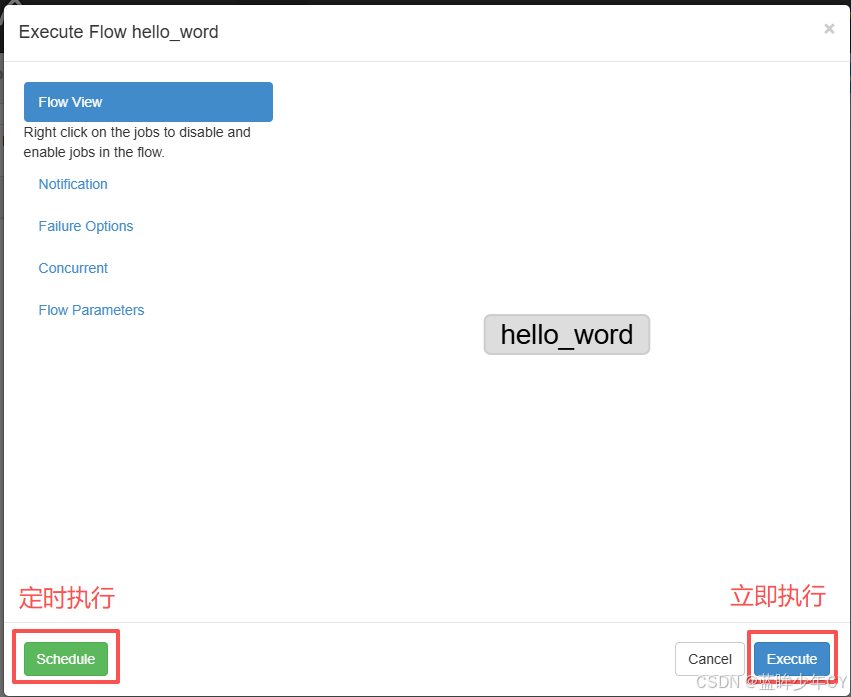
绿色表示执行成功

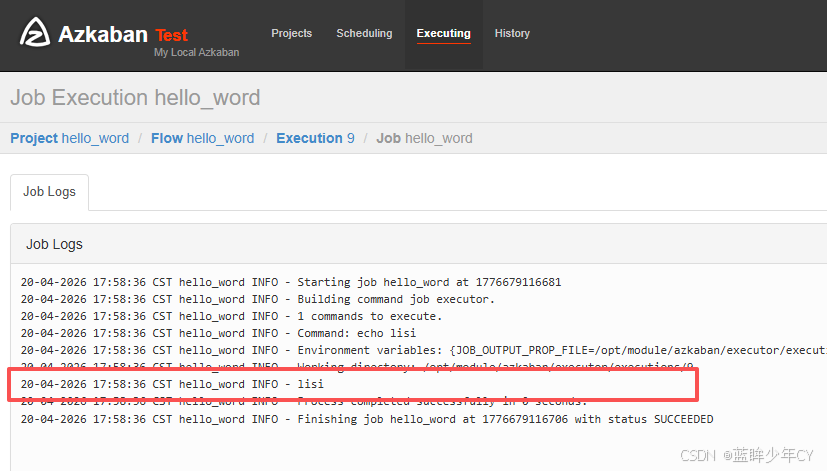
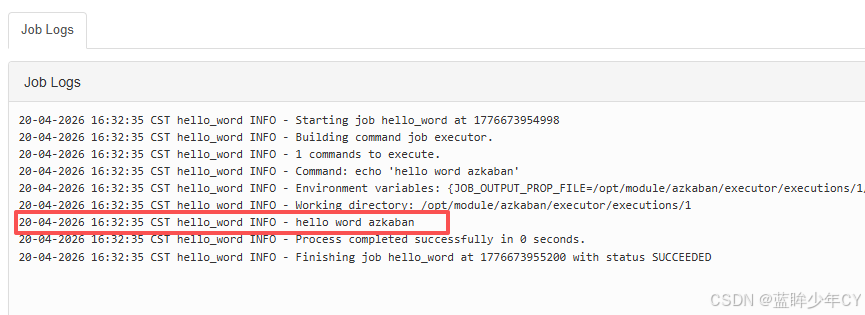
(5)查看日志
点击details
2、相对文件案例
(1)编写一个shell文件
echo 'Hello Word Lisi'
(2)编写job文件
type=command
command=sh hello.sh
(3)打包
将shell文件和job文件打包成一个zip文件
(4)上传执行

(5)查看日志
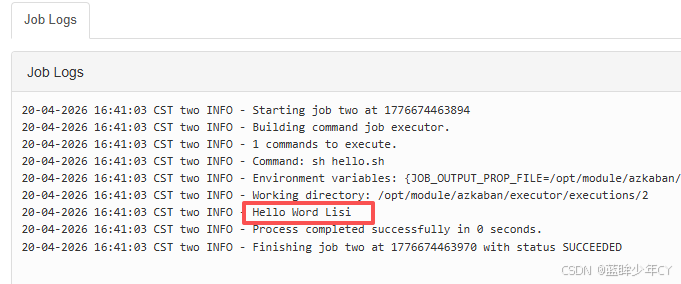
3、邮件通知
(1)修改配置文件
修改server/conf目录下的azkaban.properties 文件
......
mail settings
发送者
smtp地址
邮箱用户名(邮箱)
邮箱密码(一般为授权码)
mail.password=eqewq22312
job.failure.email=
job.success.email=
lockdown.create.projects=false
cache.directory=cache
(2)在执行任务时配置邮箱通知
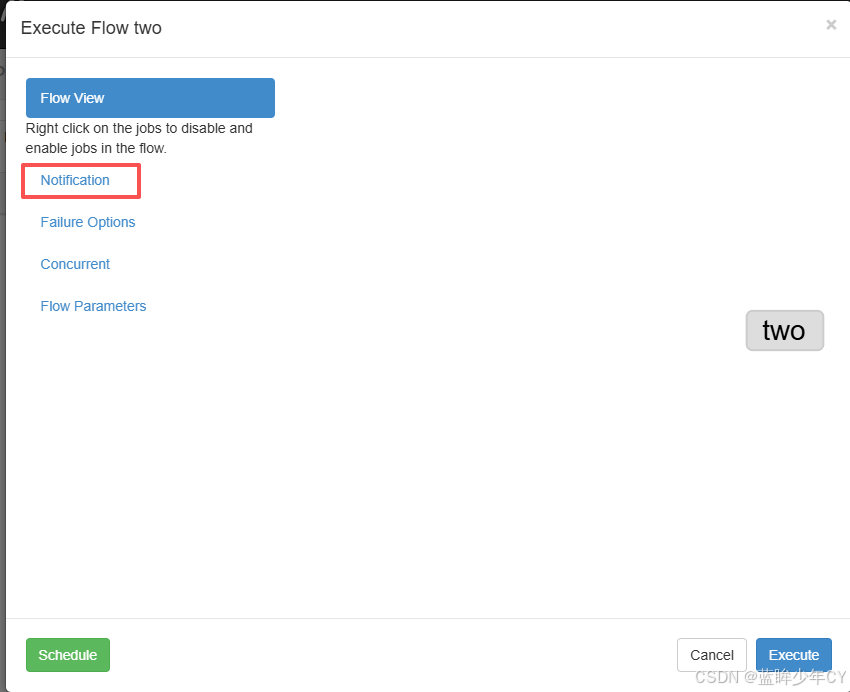
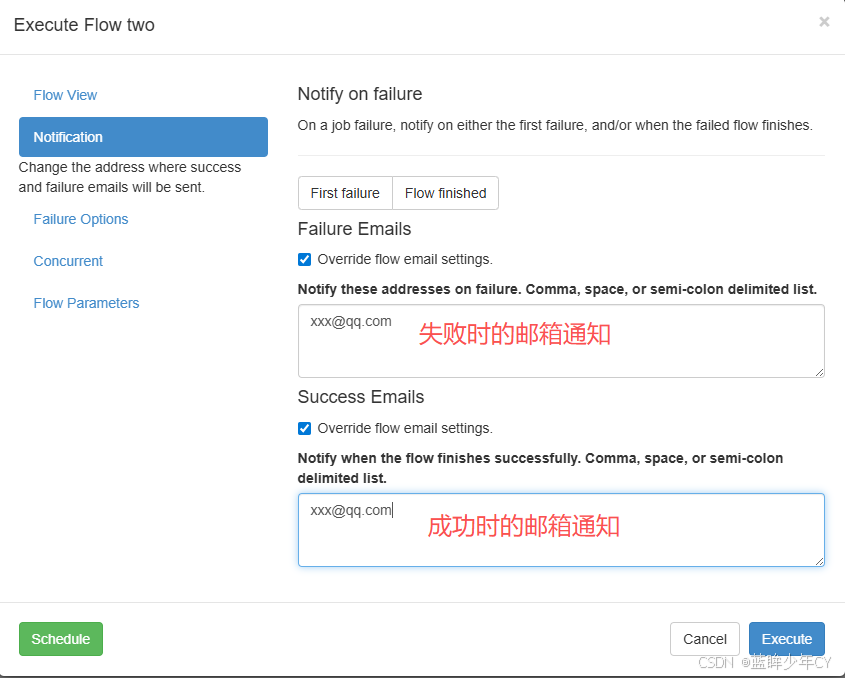
4、多工作流案例
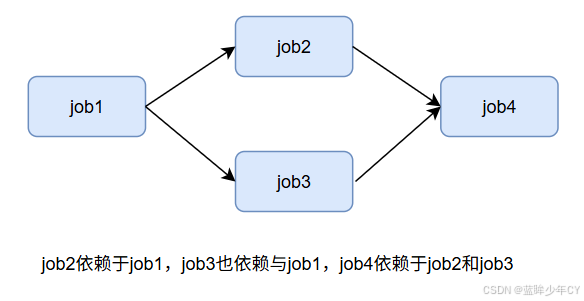
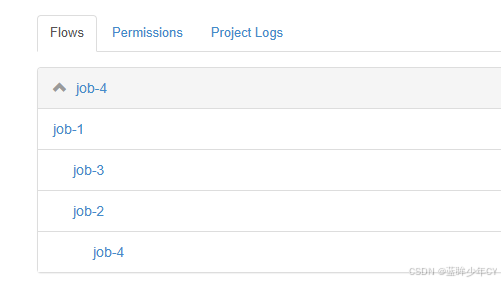
例如:实现如图案例
(1)创建job文件
dependencies:需要依赖的job
job-1
type=command
command= echo '我是 job-1'
job-2
type=command
dependencies=job-1
command=echo '我是 job-2'
job-3
type=command
dependencies=job-1
command=echo '我是 job-3'
job-4
type=command
dependencies=job-2,job-3
command=echo '我是 job-4'
(2)打包zip文件并上传
(3)执行查看结果
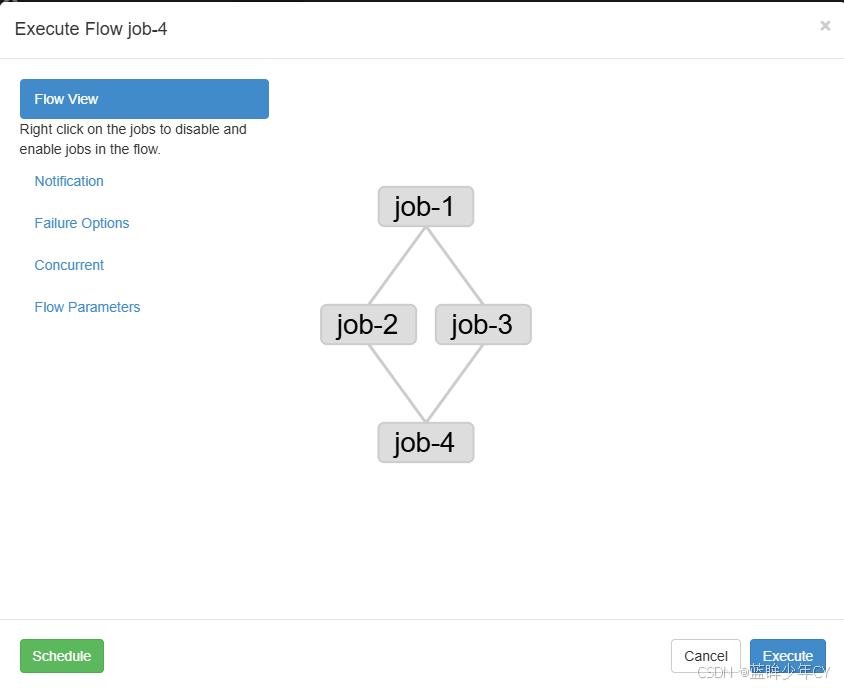
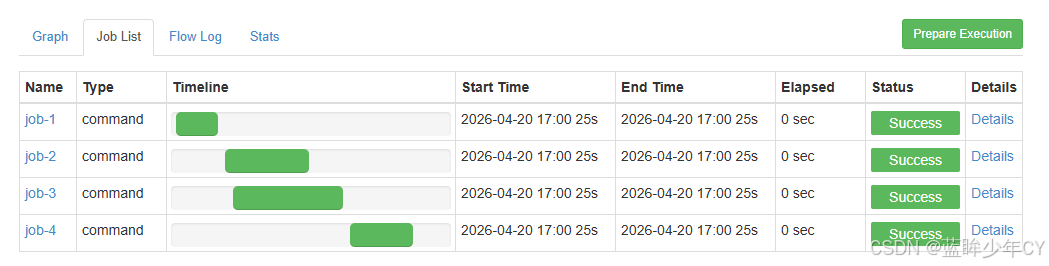
发现job2和job3是同时执行的
5、执行Java任务
(1)编写Java代码
java
public class Main {
public static void main(String[] args) {
FileOutputStream fos = null;
try {
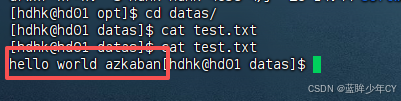
fos = new FileOutputStream("/opt/datas/test.txt");
fos.write("hello world azkaban".getBytes());
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
fos.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
}(2)编译
(3)编写job文件
type=javaprocess
java.class=com.hk.Main
#classpath=./*
classpath=AzKaban-demo-1.0-SNAPSHOT.jar
(4)打包
将jar包和job文件一起打包
(5)执行查看结果

6、HDFS任务
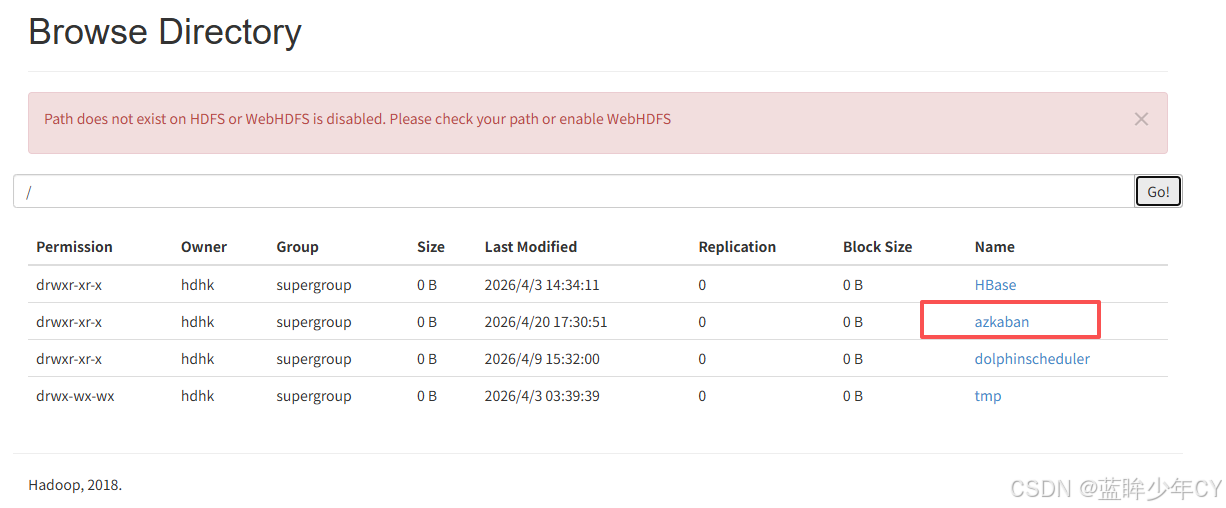
案例:在hdfs上创建一个azkaban文件夹
(1)编写job文件
type=command
command=hadoop fs -mkdir /azkaban
(2)创建项目并上传文件
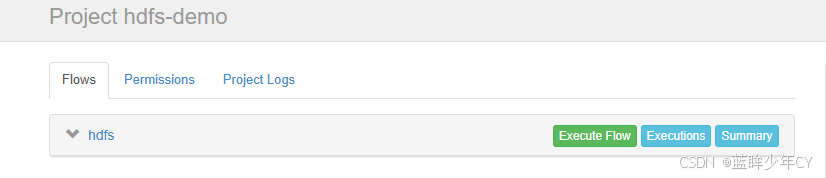
(3)启动hadoop
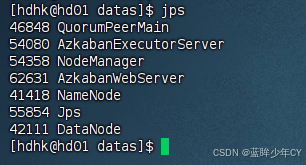
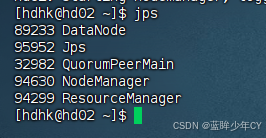
(4)执行任务查看结果


7、MapReduce任务
(1)编写job
type=command
command=hadoop jar /opt/module/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /azkaban/input /azkaban/output
(2)创建项目并上传文件

(3)上传文件到hdfs的/azkaban/input目录下
hdfs dfs -put hello.txt /azkaban/input
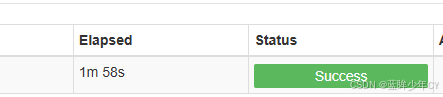
(4)执行并查看结果

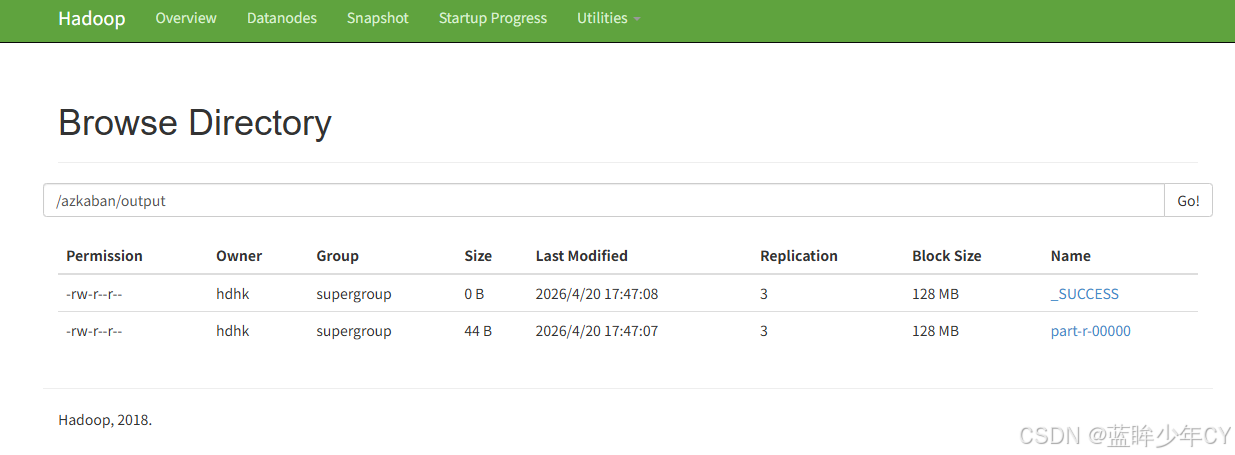
8、Hive 任务
(1)创建hive的sql脚本
vim student.sql
use default;
drop table student;
create table student(id int, name string)
row format delimited fields terminated by ',';
load data local inpath '/opt/module/datas/student.txt' into table student;
insert overwrite local directory '/opt/module/datas/student'
row format delimited fields terminated by ','
select * from student;
(2)创建job文件
type=command
command=hive -f /opt/module/azkaban/jobs/student.sql
(3)上传后运行查看结果
cat /opt/module/datas/student/000000_0
1001,lisi
1002,wangwu
9、job传参
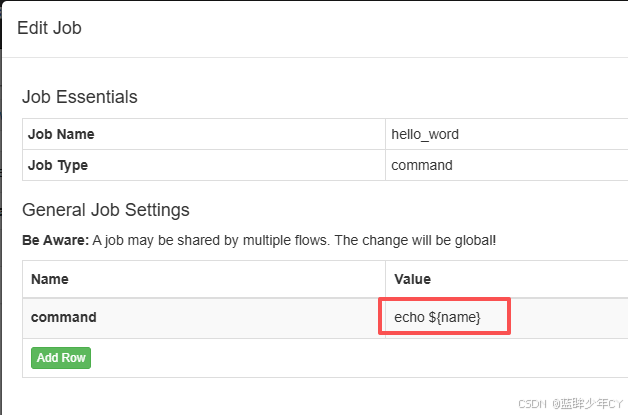
(1)修改hello_word案例
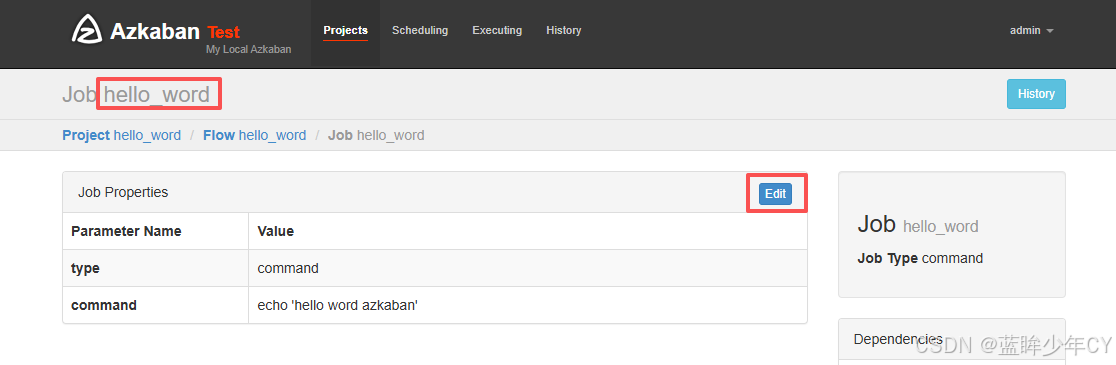
(2)修改为接收外部参数
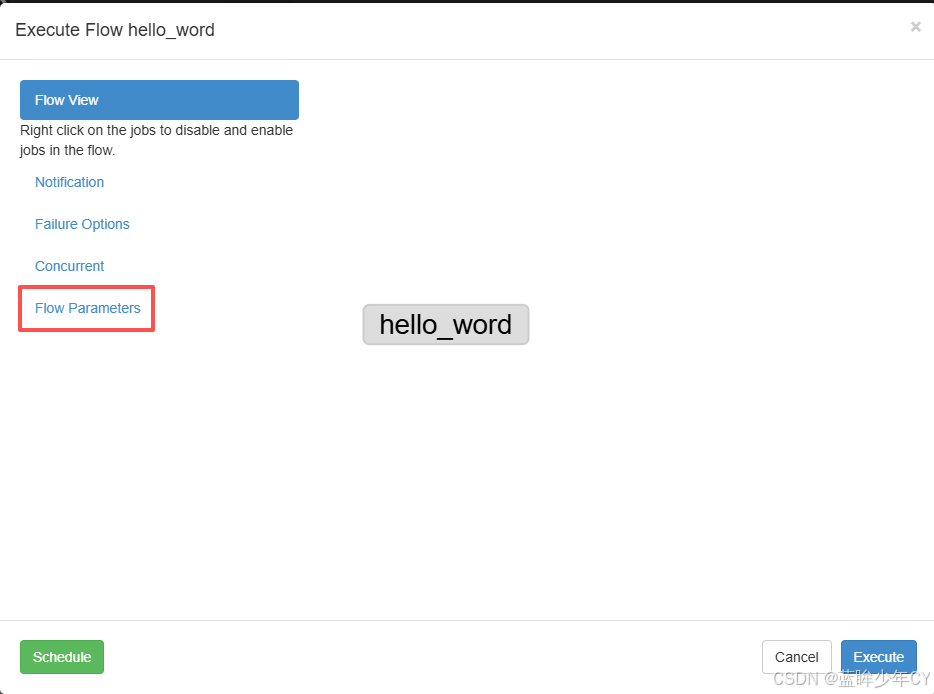
(3)执行的时候点击 Flow Parameters
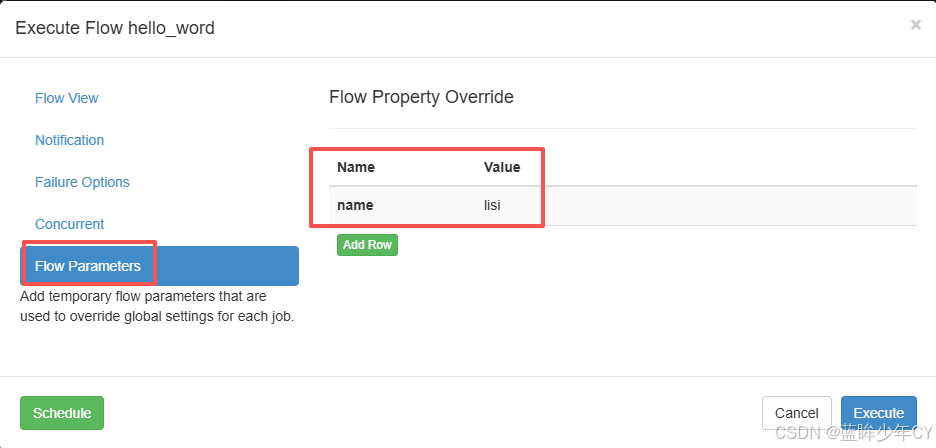
(4)给参数赋值
(5)执行查看输出结果