作者:来自 Elastic Chris Hegarty 及 Lorenzo Dematte
我们如何将 Elasticsearch 的原生 SIMD 评分引擎引入 serverless,以及为什么 serverless 将成为向量搜索创新的下一站。
从向量搜索到强大的 REST API,Elasticsearch 为开发者提供了最完整的搜索工具集。你可以浏览 Elasticsearch Labs 仓库中的示例 notebooks 来尝试新功能,也可以开启免费试用或在本地运行 Elasticsearch。
我们已经将 simdvec(Elasticsearch 原生的单指令多数据 SIMD 向量评分引擎)引入 serverless。在并发负载下,搜索吞吐量几乎提升了一倍,p99.9 尾延迟从 237 ms 降低到 30 ms。通过让 simdvec 直接访问 blob cache 的内存映射区域,serverless 现在能够运行与有状态架构一致的零拷贝 SIMD 内核,实现相同的召回率,并且完全没有 heap 开销。由于 serverless 让我们可以控制整个存储层,我们相信这将成为向量搜索性能的未来最优形态。下面是实现方式。
Elasticsearch Serverless 上的向量搜索
Elasticsearch Serverless 构建在 Stateless Elasticsearch 之上,这是一种完全解耦的计算与存储架构,其中索引数据存储在远端对象存储中,而搜索节点只保留本地缓存。为了让向量搜索在这种架构上保持高性能,评分引擎必须直接作用于本地缓存,而不是先复制到 heap 中。
Elasticsearch simdvec 是执行向量距离计算的核心引擎。它提供手工调优的 AVX-512 和 NEON 内核、带显式预取(prefetching)的批量评分,以及直接面向 CPU 寄存器的数据流式传输的 off-heap 内存访问能力。在有状态 Elasticsearch 中,simdvec 一直有一条"直接供给通道":memory-mapped 文件将原生指针直接送入 SIMD intrinsics。在 serverless 中,数据已经以完全正确的形式存在于 blob cache 的 memory-mapped 区域,但缺少一条通路将其连接到评分引擎。
我们现在已经建立了这条通路。simdvec 在 Serverless 上运行与有状态架构完全一致的 off-heap 原生 SIMD 评分路径。而由于 serverless 让我们可以控制整个存储层,这仅仅只是开始。
专用 "高辛烷值燃料":为什么 simdvec 需要 off-heap 内存来进行向量评分
simdvec 的速度来自于直接使用 off-heap 内存。它接收一个指向 memory-mapped 数据的原生指针,并将其直接传递给 C++ SIMD intrinsics。没有中间拷贝,没有 heap 分配。数据从存储直接流入 CPU 寄存器。这个点比听起来更关键:simdvec 的 kernel 处理向量的速度甚至快于数据复制速度,因此任何 copy 都会成为瓶颈,而不是评分本身。
在有状态 Elasticsearch 中,这一切是天然成立的。Lucene 会将索引文件 memory-mapped 到本地磁盘,而 scorer 可以直接从 mapped 区域获取原生指针。这条路径正是我们发布基准测试结果的基础,也是我们希望在 serverless 中复现的能力。要理解如何实现这一点,我们需要先看 serverless 是如何存储和访问数据的。
Serverless blob cache:Elasticsearch 如何存储向量数据
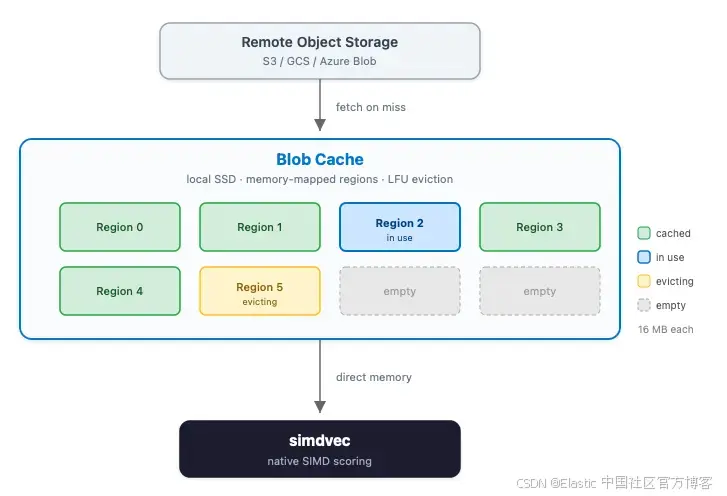
在无状态架构中,所有索引数据的主副本都存储在远端对象存储中,例如 S3。每个 search node 维护一个本地缓存(称为 blob cache),用于保存索引数据中最近或最常访问的部分,存放在本地 SSD 上。有状态 Elasticsearch 的 frozen tier 使用了类似架构:searchable snapshots 也依赖类似的 blob cache,将远端存储中的数据区域 memory-mapped 到本地磁盘。当查询命中缓存数据时,会直接从本地高速存储提供服务;当未命中时,blob cache 会从远端存储拉取数据并缓存,以供后续查询使用。
Blob cache 由固定大小的 memory-mapped region 组成,默认是 16MB。它自行管理生命周期:追踪哪些 region 正在使用,在缓存满时采用 least-frequently-used(LFU)策略进行淘汰,并通过引用计数确保正在读取的 region 不会被回收。这些 region 虽然仍然通过操作系统进行 memory-mapped,但 blob cache 控制哪些 region 存在、哪些被填充以及何时回收。在有状态架构中,这些决策完全由操作系统负责。
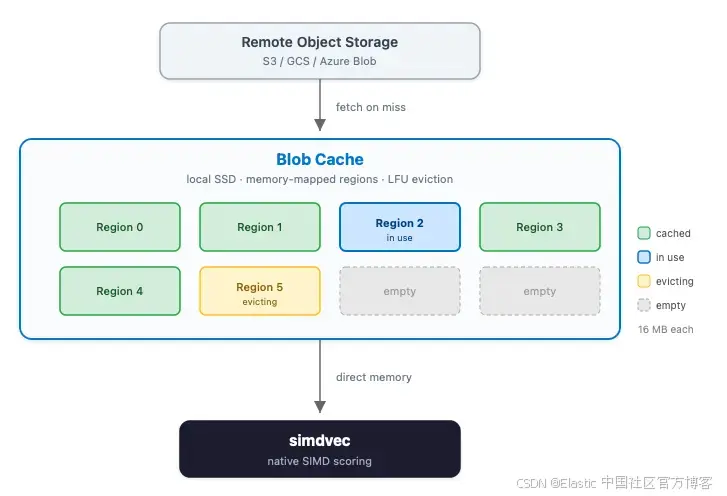
关键的是,由于每个 region 都是 memory-mapped,blob cache 中的向量数据本身已经以 simdvec 所需要的精确形式存在。但在我们建立这条连接之前,这些数据是无法直接访问的。每一次向量比较都会被复制到 heap 数组中,然后交给一个更慢的 scorer 处理。没有直接内存指针,没有 SIMD,每一次调用都会带来垃圾回收压力。
统一评分:所有存储层共享一条 SIMD 路径
我们引入了一个新的抽象层,使 scorer 可以在运行 SIMD 计算所需的极短时间内,从底层任意存储层安全地借用直接内存。如果数据可以以 direct memory 形式访问,simdvec 的原生 kernel 就会直接运行;如果不行(例如数据尚未缓存或跨越 region 边界),scorer 会退回到 heap copy。在实际运行中,这种 fallback 是非常少见的。
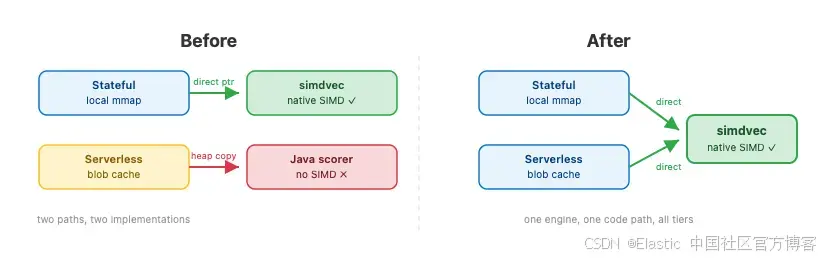
这就给了我们一个跨所有 tier 的统一评分入口:
- 有状态(本地磁盘):scorer 从操作系统的 memory map 中提取 native pointer。
- Blob cache(serverless / frozen tier):scorer 从 cache region 中借用一段 direct memory slice。
- Fallback:scorer 将字节复制到 heap。这种情况在实践中非常少见。
scorer 本身不需要知道自己运行在哪个 tier 上,这也意味着我们不再需要维护多套 scoring 实现;在此之前,有状态系统有一条快速 native path,而其他情况则走较慢路径。现在对 simdvec 的任何优化都会自动惠及所有 tier,包括它最强大的能力:bulk scoring。
跨 blob cache regions 的向量批量评分
一次查询可能需要对成千上万个候选向量进行评分。simdvec 的 bulk scoring 通过多 accumulator 的内循环、query amortization 以及 cache-line prefetching 来处理这些批量数据,当数据规模超过 CPU cache 时,相比单向量方案可提升最高 4 倍性能。
基于 inverted file(IVF)索引的搜索是 bulk scoring 发挥最大作用的场景。查询会选取一组 candidate posting lists,并在量化向量上进行扫描,在大批量数据上与 query vector 进行评分。在有状态架构中,这些向量位于连续的 memory-mapped 文件中,因此 bulk scoring 可以通过简单的 pointer arithmetic 完成,并在一次 native call 中完成整批评分。
在 serverless 中,对 posting list 的扫描可能跨越 blob cache region 边界。我们扩展了 direct memory 抽象,引入 bulk access 方法,可以在一次调用中解析多个 vector offsets 对应的 cache regions。如果批量中的所有向量都已缓存且不跨 region boundary,scorer 会获得一段 direct memory slice,并将整个 batch 交给 simdvec 的 native bulk kernel,享受与有状态系统相同的 prefetching 和 pipelining。如果发生跨 boundary 的情况,系统会退化为 per-vector scoring:仍然是 zero-copy,只是失去了 batching 的收益。在 16MB region 和 1024-byte vector 的条件下,这种情况大约每 16,000 个向量才会发生一次。
simdvec 的 bulk scoring 架构 ------ 也是 simdvec benchmarks 中强调的关键优势 ------ 现在已经可以在 serverless 上运行,并保留了与有状态系统一致的性能特征。那么它在实际中的表现如何?
simdvec 在 Elasticsearch Serverless 上:向量搜索"圈速"表现
我们使用 1800 万向量的 MSMARCO 数据集进行基准测试,维度为 1024,并采用 IVF 结合 Better Binary Quantization(BBQ,1-bit 量化)。所有结果均在 warm blob cache 上测得,完整数据集已驻留在本地 cache region 中,因此我们测量的是 scoring 路径本身,而不是远端拉取延迟。
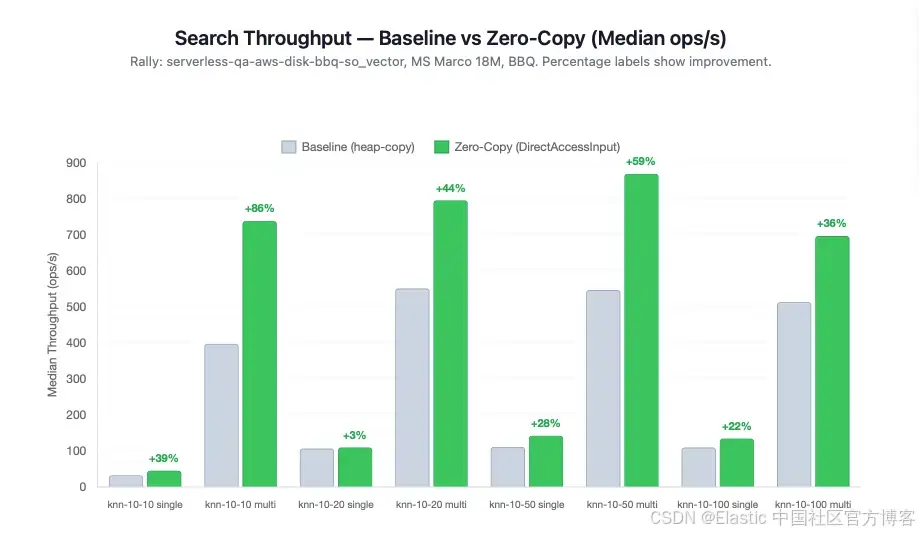
吞吐量(Throughput)
在并发负载下,搜索吞吐量几乎翻倍,从 398 ops/s 提升到 739 ops/s。单客户端的提升幅度为 23--39%,但真正的差异体现在并发场景中:整体提升达到了 2--3 倍,因为消除 heap copy 后,GC 压力和内存分配竞争被移除,而这些正是此前限制并发 scoring 的主要瓶颈。
尾部延迟(Tail latency)
直接内存路径彻底改变了高负载下的尾部延迟表现:
- p99.9 从 237 ms 降低到 30 ms(下降 87%)。
- p99.99 从 9.1 秒降低到 55 ms(下降 99.4%)。
p100 从 11.4 秒降低到 100 ms 以下。
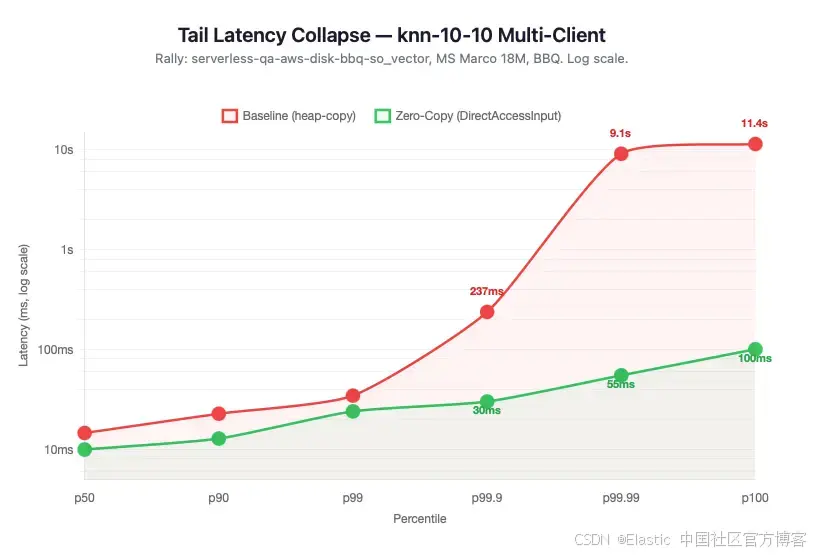
最坏情况的离群延迟(outliers)------以前需要数秒完成的请求,现在只需几十毫秒就能完成。由 heap copy 引起的排队(queueing)和由此带来的延迟尖峰已经消失。
召回率(recall)完全一致。相同的向量被评分,产生相同的结果。而我们才刚刚开始。
超越一致性:Elasticsearch Serverless 能为向量搜索带来哪些有状态系统无法实现的能力
达到与有状态系统一致的性能只是目标之一,但更有意思的发现是:无状态架构让我们能够做一些有状态系统无法做到的事情。
在有状态系统中,操作系统控制 memory-mapped 文件的行为:哪些 page 保持常驻、何时进行 eviction、以及预读(read ahead)的激进程度。应用层可以提供 hint,但这些 hint 作用于整个文件映射,而且内核可能会忽略它们。更重要的是,search 和 indexing 在同一节点上并发执行,因此一个对某种访问模式有利的 hint,可能会损害另一种访问模式。实际情况下,为了平衡不同需求,必须保持保守。
在 serverless 中,有两个根本性差异。首先,blob cache 以完全的应用层控制方式管理自己的 memory-mapped regions。其次,serverless 将 indexing 和 search 分离到不同的 tier:search 节点不执行 merge,indexing 节点不提供查询服务。没有冲突的访问模式意味着我们可以对内存策略更加激进。我们正在推进以下方向:
- 按 region 的内存策略(Per-region memory advice)
- blob cache 知道每个 region 中数据的类型。它可以对 rescoring region 施加 random-access hint,因为原始 float32 向量是以不可预测顺序读取的,默认 readahead 会浪费内存(预读的 page 很可能永远不会被使用)。对于扫描 quantized vectors 的场景,则可以使用 sequential readahead。在 indexing tier 上,merge 是顺序读取,因此可以使用更激进的 readahead,在数据被需要之前提前加载 page,同时不会影响任何并发随机读取,因为该节点上根本不存在这种访问模式。
- cache-aware prefetching
- simdvec 已经在 CPU cache-line 层面执行 prefetch。在 serverless 中,我们可以将这一能力与 blob cache 的 region 驻留信息协同,实现多层级 prefetch:从 remote store 到 cache,从 OS pages 到 RAM,再到 CPU cache lines。blob cache 可以在 scoring 开始前告诉 scorer 哪些 region 已经驻留,从而避免对尚未缓存的数据发起 remote fetch。
- workload-aware eviction
- blob cache 可以优先保留向量搜索依赖的数据,例如每次查询都会访问的 IVF centroid indexes,或者在 bulk scoring 中频繁使用的 quantized vectors,而不是那些访问频率较低的数据。相比之下,OS page cache 依赖通用 heuristics 进行 eviction,并不理解数据语义。在 serverless 中,eviction policy 可以根据 workload 进行调优。
blob cache 提供了 OS page cache 无法实现的内存层级控制能力。这也是我们认为 serverless 是下一代向量搜索性能最有前景平台的原因:不仅是达到与有状态系统一致的性能,而是超越它。而 vectors 只是开始。
Elasticsearch Serverless 上的向量搜索:我们已经交付的内容与未来方向
simdvec 现在已经可以在 Elasticsearch 运行的所有环境中使用(有状态、serverless 以及 frozen tier),并提供一致的原生 SIMD 评分能力、相同的 bulk scoring,以及相同的 off-heap 效率。我们构建的这一抽象是通用的,并且已经贯穿整个存储链路的每一层,因此未来同样的方法也可能扩展到 term lookup、aggregations、sorting 以及 stored field retrieval。
Elasticsearch Serverless 是我们在向量搜索性能方面投入最集中的方向。每一次对 simdvec 的改进、每一次 blob cache 的优化,以及每一项新的存储层优化,都会首先在这里落地。如果你正在选择运行向量工作负载的平台,serverless 是一个持续变快的选择。你可以通过免费的 Elastic Cloud 试用开始体验。
原文:https://www.elastic.co/search-labs/blog/vector-search-serverless-simdvec-throughput