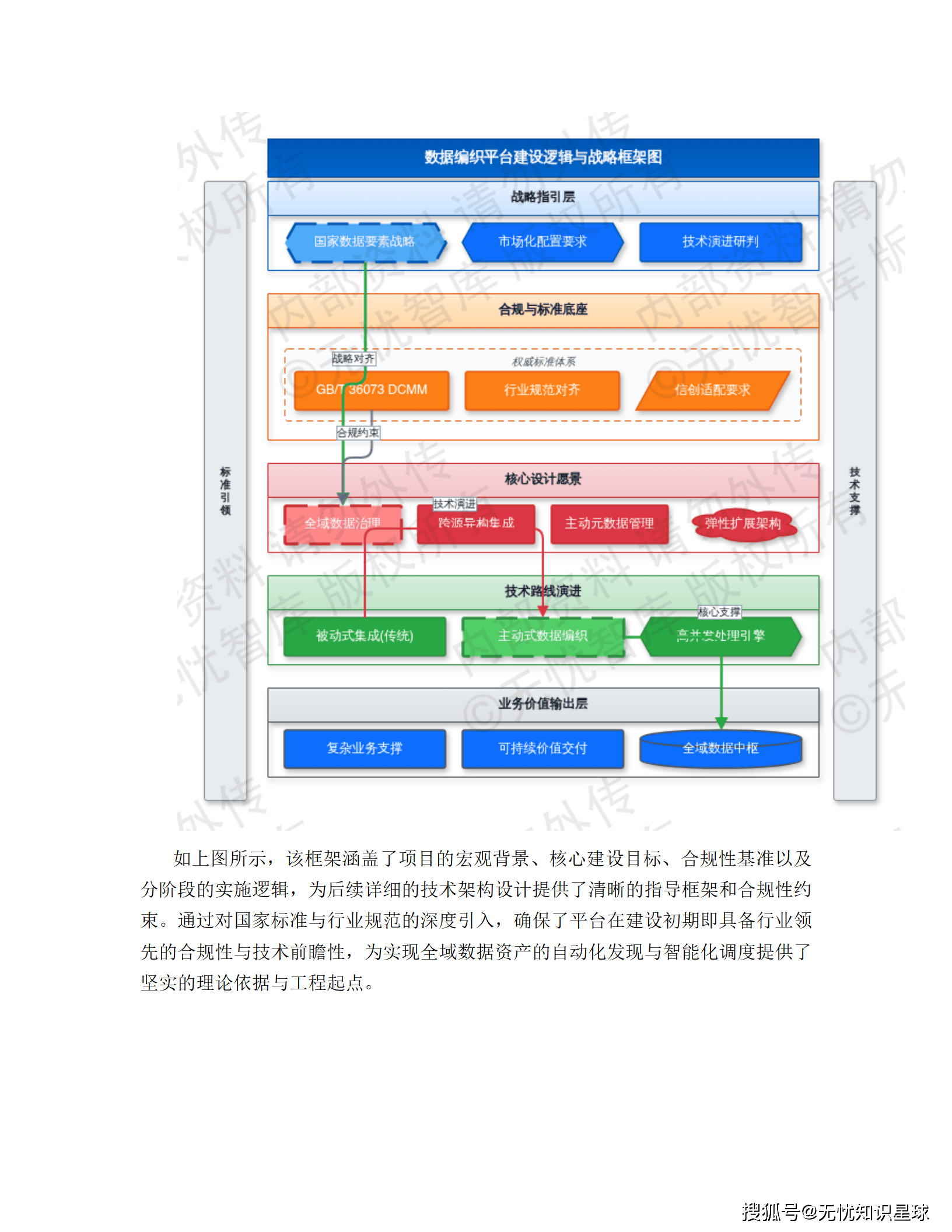
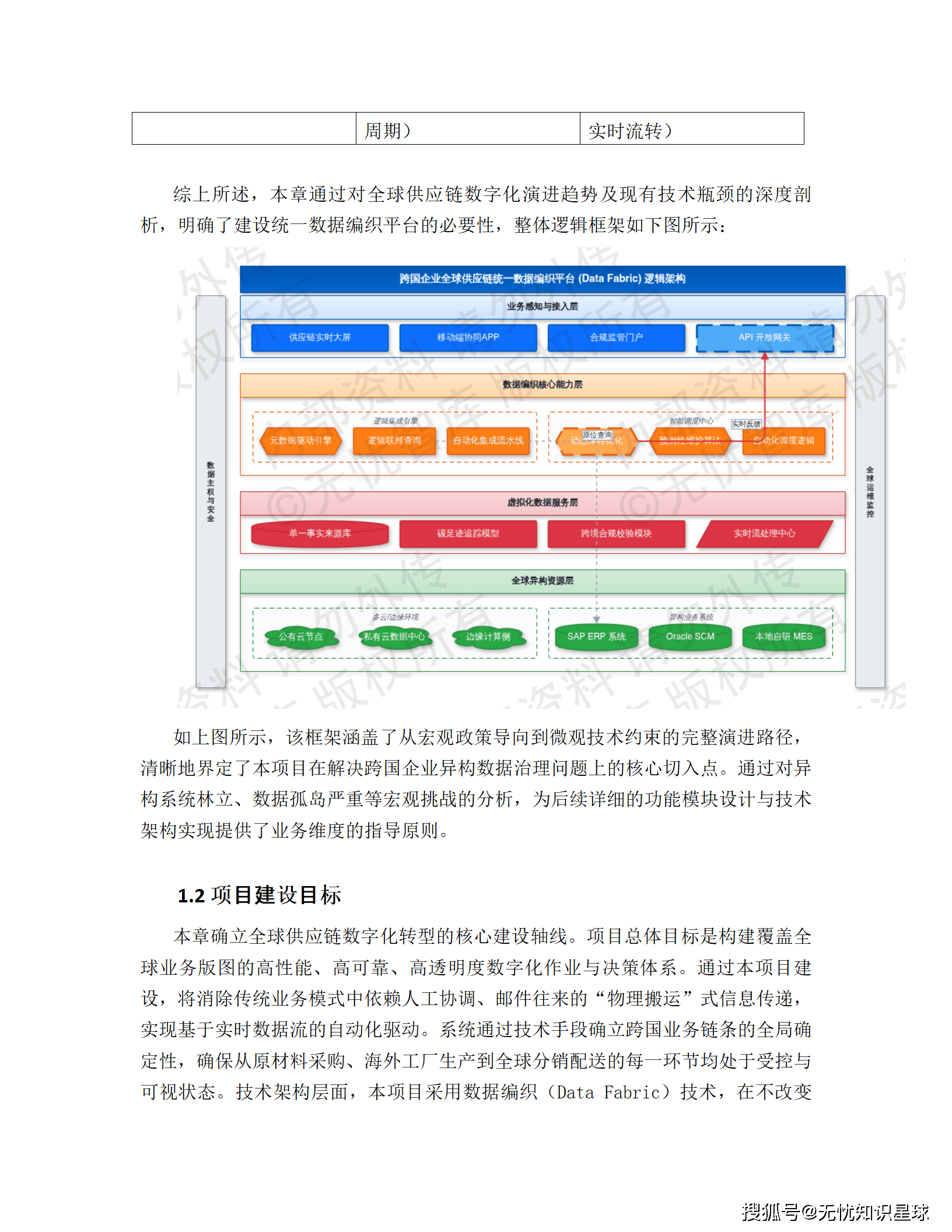
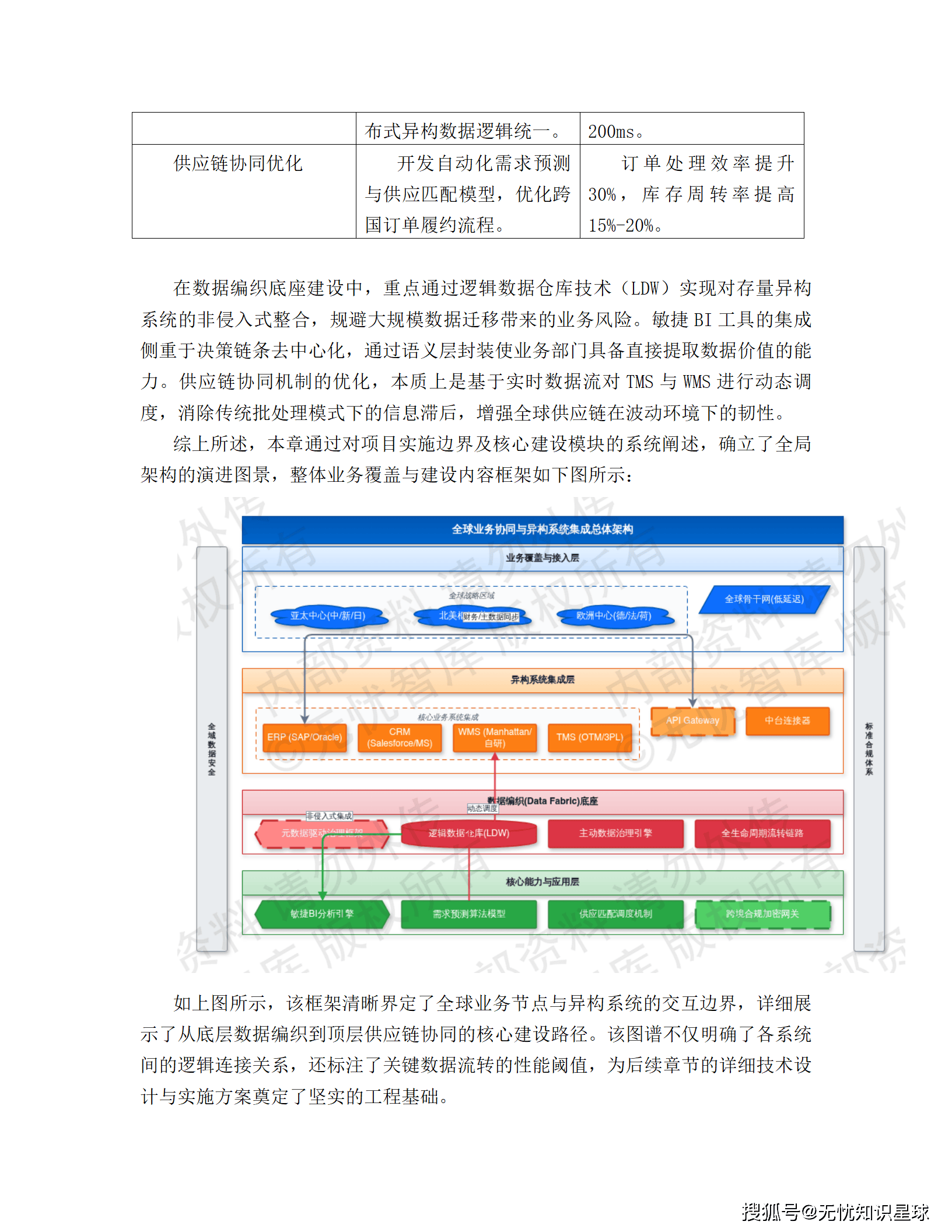
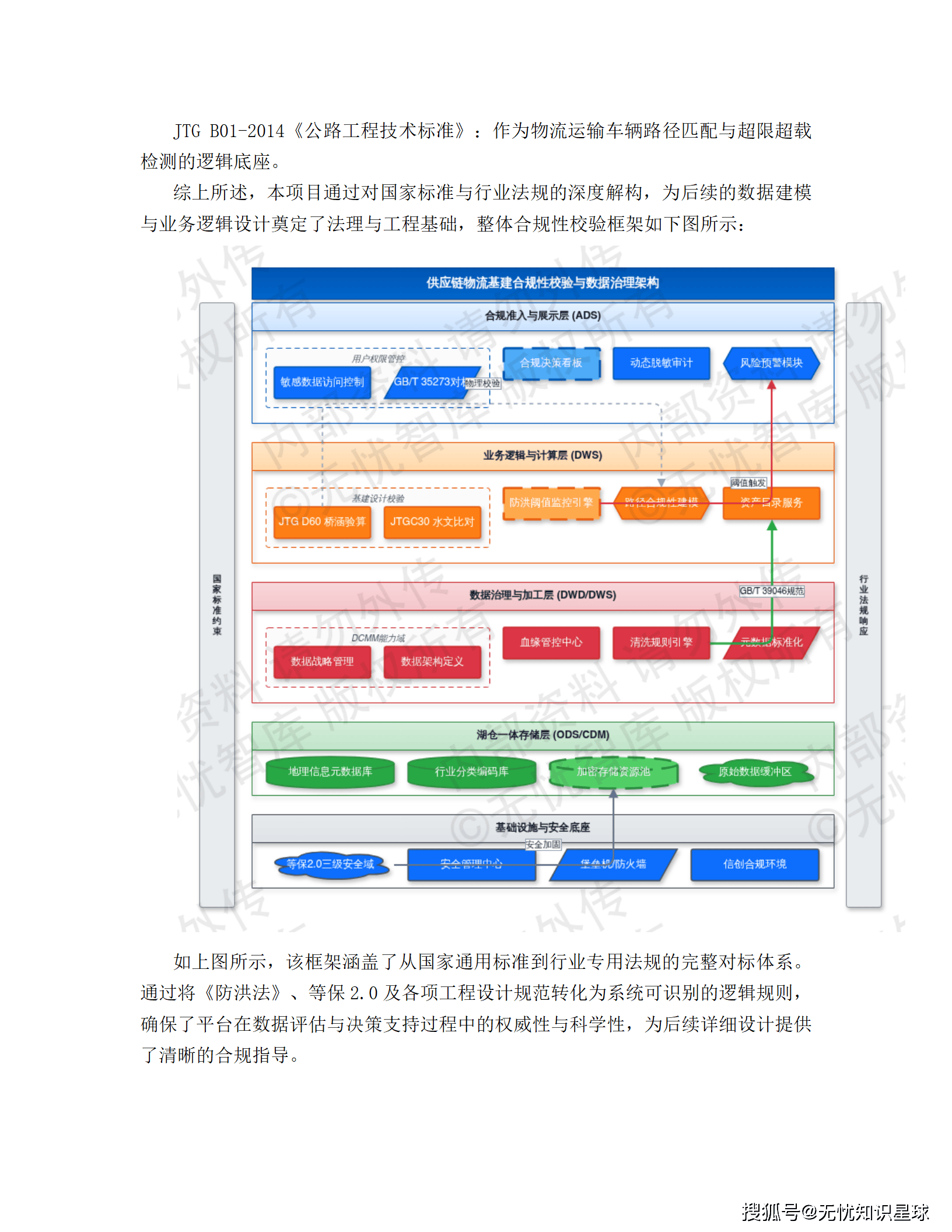
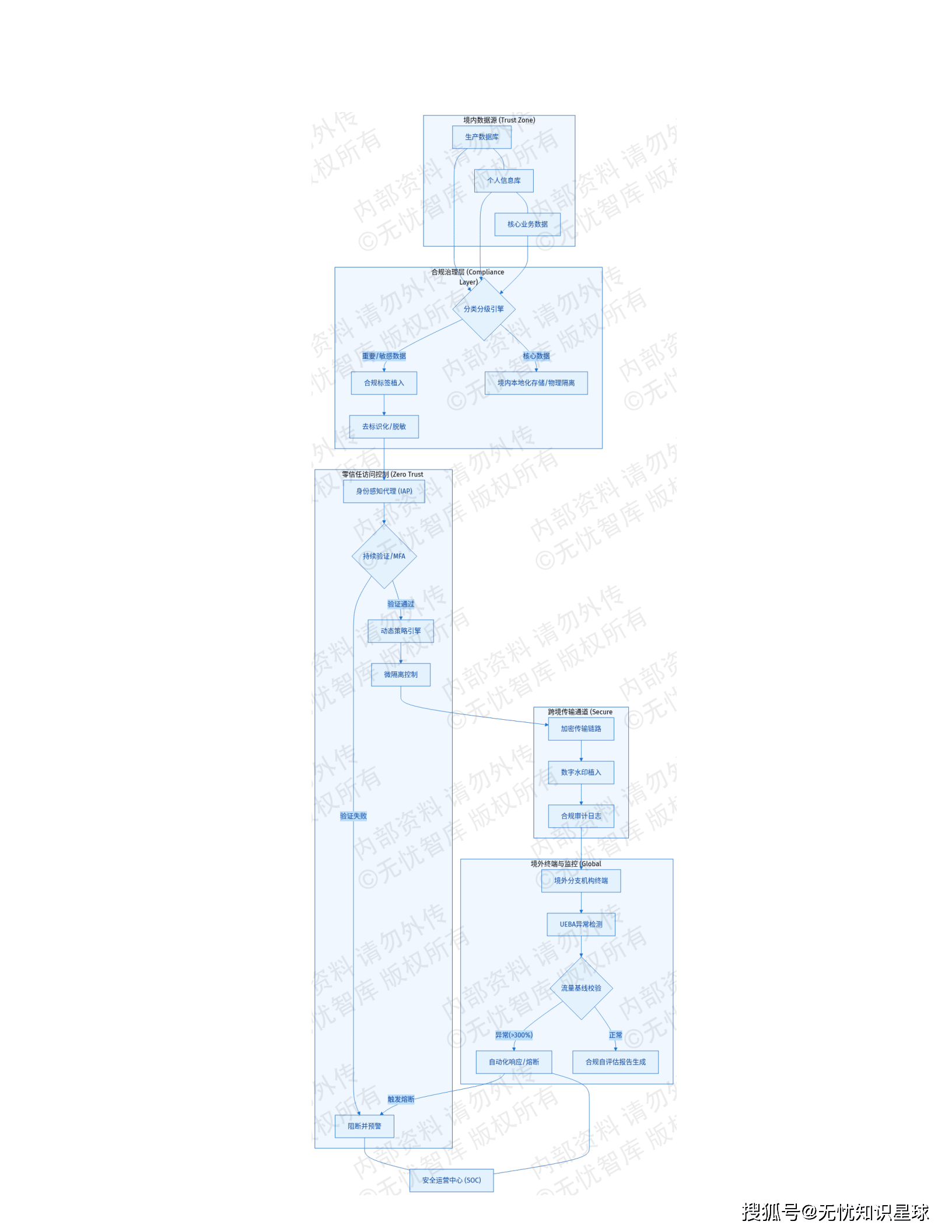
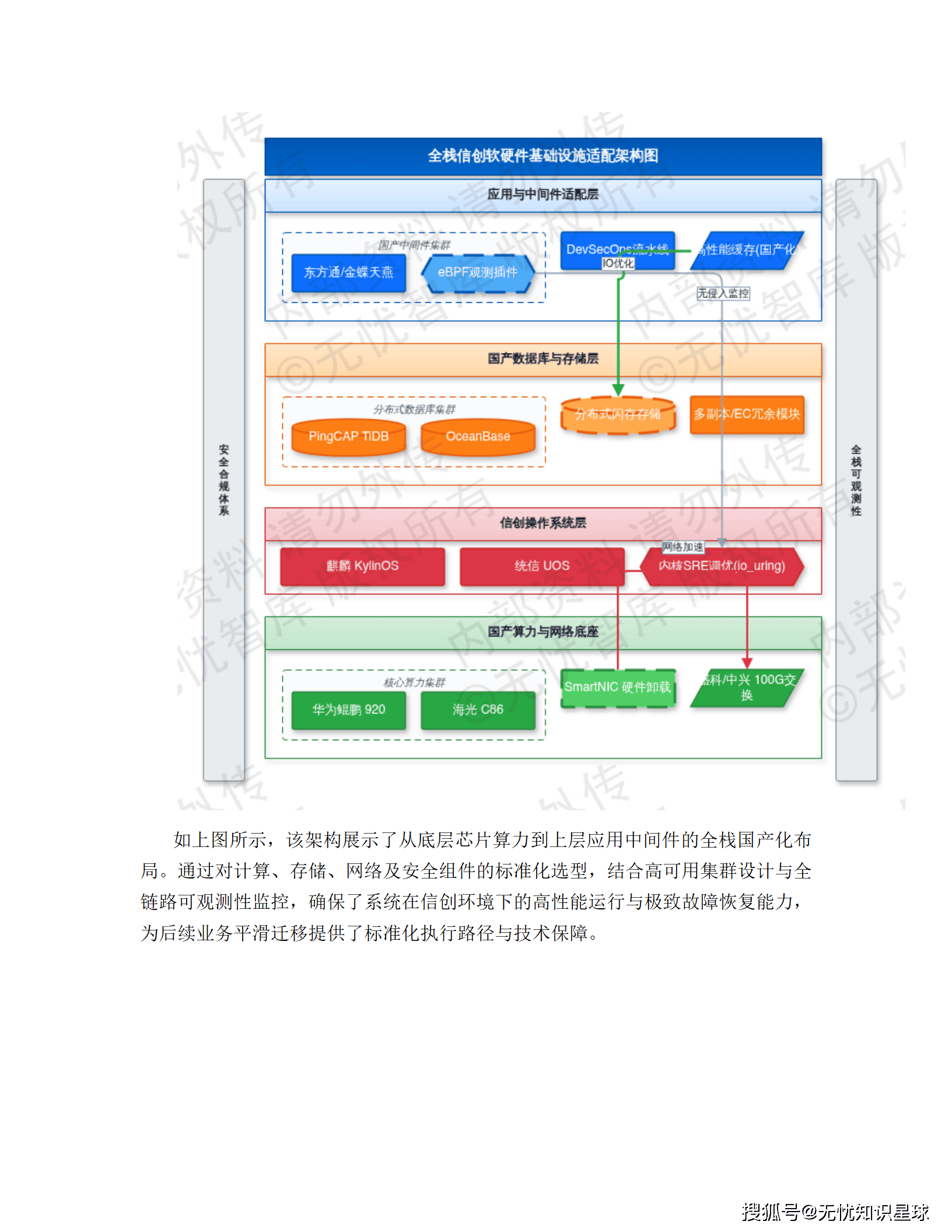
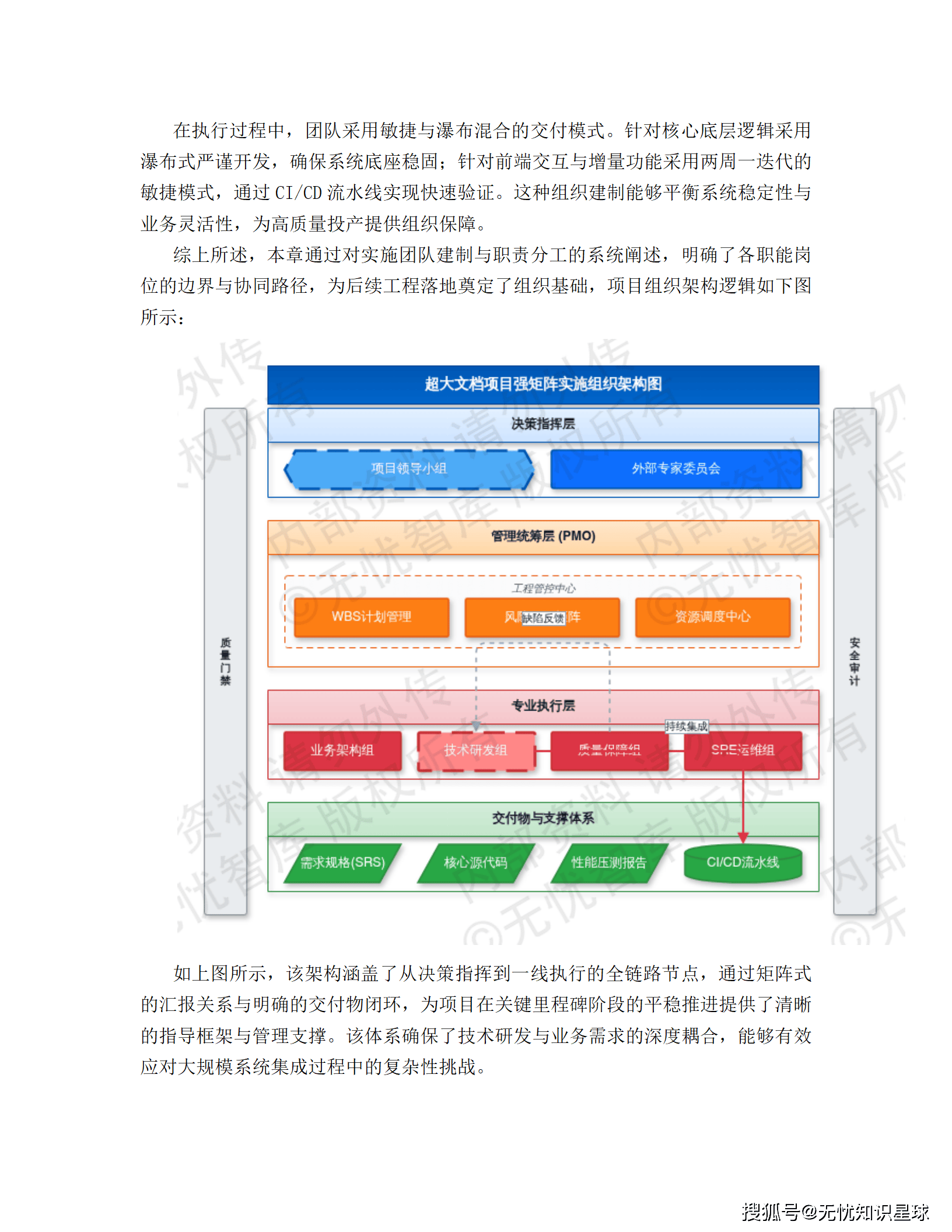
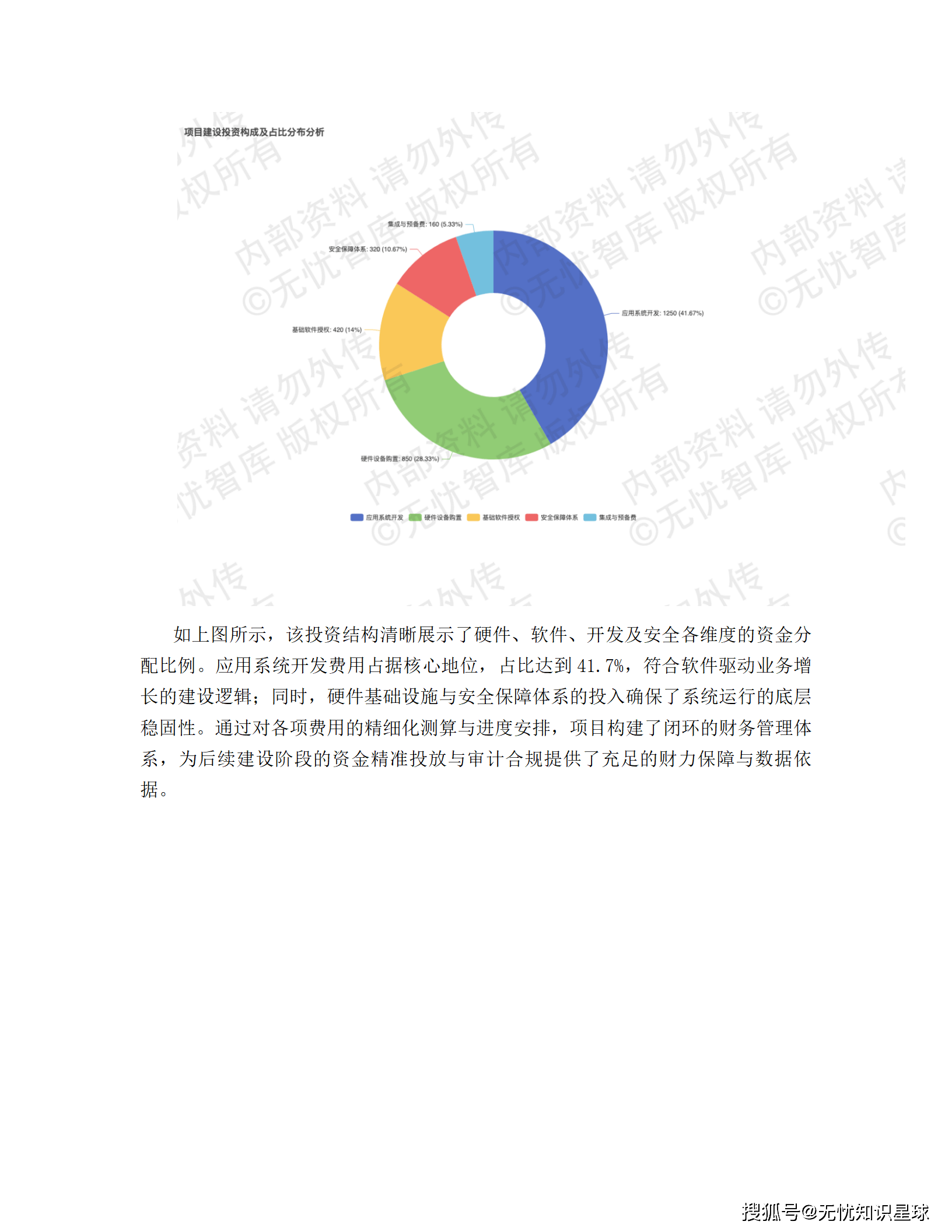
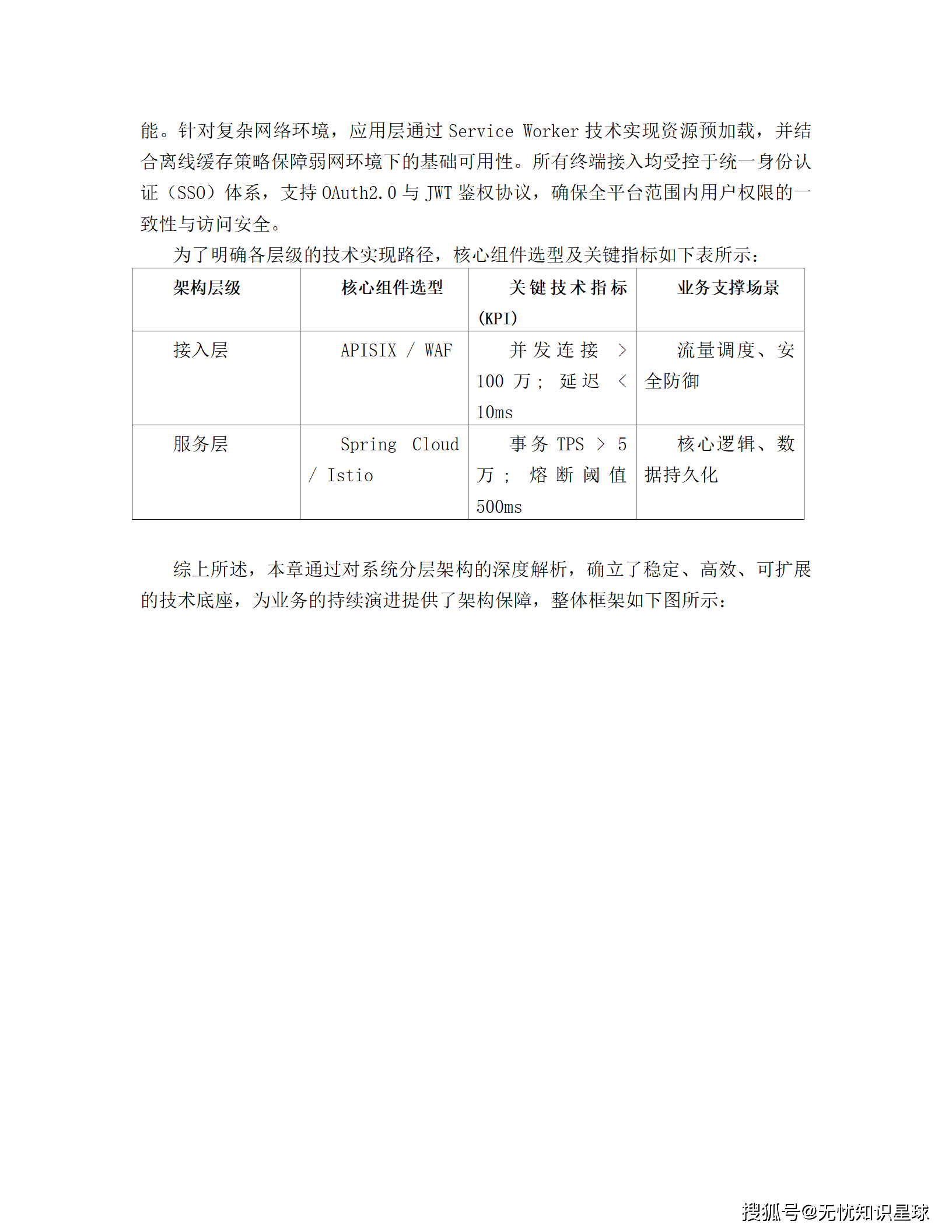导读:这是一份真实的企业级"十五五"数字化转型建设方案,覆盖从架构设计、技术选型到合规落地的全链路。如果你在做数据中台、供应链可视化,或者正在被异构数据集成折磨,这篇文章或许能给你一些具体的参考。
一、背景:为什么非建这个平台不可
1.1 供应链数字化到底卡在哪里
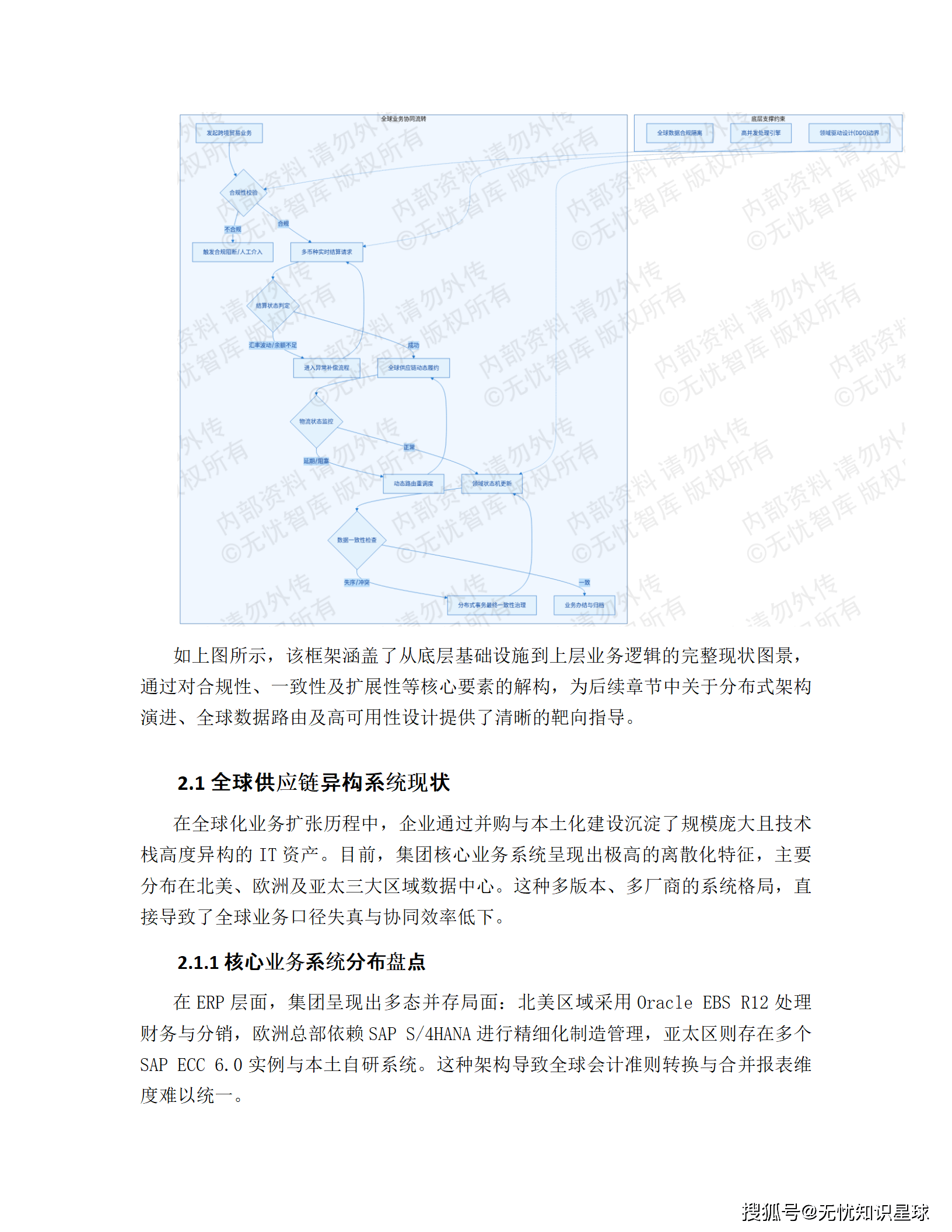
很多人以为跨国企业的供应链已经很"数字化"了------SAP、Oracle、自研WMS,一套一套的。但现实情况是,这些系统之间基本靠ETL批处理来传数据,T+1的延迟是家常便饭,遇到大促或紧急采购,等到数据同步过来,黄花菜都凉了。
更麻烦的是,这些系统在全球各地独立建设,北美是 Oracle EBS R12,欧洲是 SAP S/4HANA,亚太是一堆 SAP ECC 6.0 加各种本地自研套件。每个系统都有自己的字段定义、编码规则、业务语义,"订单交期"这个字段,三个地区可能存了三种格式、三种口径。
现存 P2P 接口超过 450 个,涉及 REST API、SOAP、SFTP 文件交换、数据库触发器,拓扑图画出来像蜘蛛网。某个 SFTP 服务器一挂,下游一片连锁瘫痪,还没有自动补偿机制,全靠人肉介入。
这就是这个项目诞生的直接原因。
1.2 传统 ETL 模式的死胡同
传统的数据集成思路,就是把数据"搬"到一个中心节点。听起来没问题,但实际执行起来有三个越来越难解决的矛盾:
第一,物理冗余的成本指数级增长。 数据要在 ODS→DWD→DWS 各层间流转,还要为不同业务部门输出不同口径,每增加一个下游应用,存储冗余度平均提升 1.2~1.5 倍。数据越来越多,但有价值的越来越难找,形成所谓的"数据淤泥"。
第二,Schema 变更带来的连锁爆炸。 源端系统一旦改个字段类型,下游所有依赖这条物理链路的作业全部报错。TB 级数据环境里,光是排查影响范围就要花几天,修复周期以周计算。
第三,跨境数据传输的合规红线。 全量数据跨境搬运,很容易踩到各国数据主权和隐私保护法规的雷区。欧盟、东南亚、中国的数据合规要求各不相同,"把数据都汇到一个地方"这个假设本身,在法律层面就站不住脚。
正是这三重矛盾,让这家跨国企业决定放弃物理搬运,转向数据编织(Data Fabric)架构。
二、核心理念:Data Fabric 到底解决什么问题
2.1 一句话讲清楚 Data Fabric
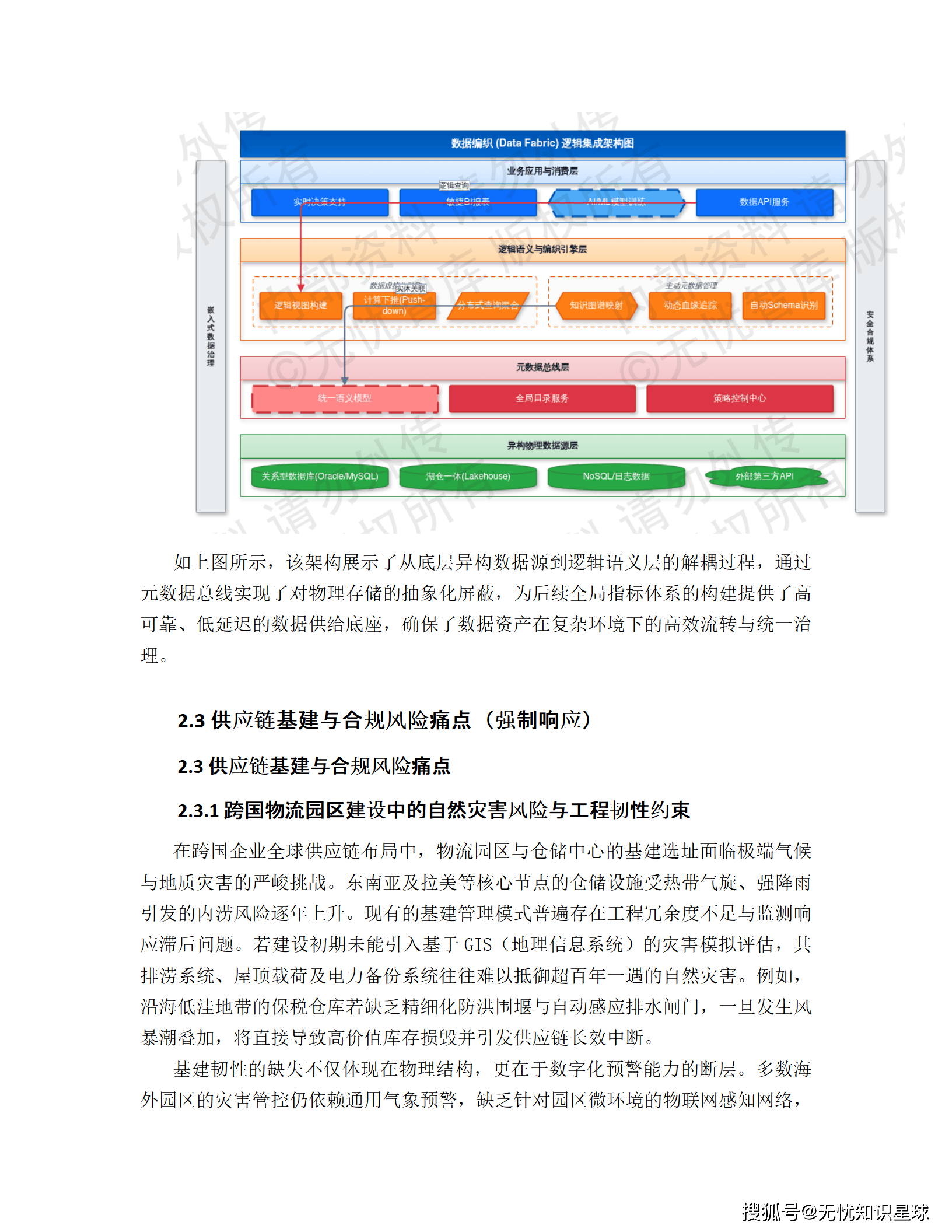
Data Fabric 的核心思路,是不搬数据,只建逻辑连接。
数据仍然在它原来的地方------Oracle 里的还在 Oracle,MongoDB 里的还在 MongoDB,边缘物联网设备产生的数据还在边缘侧。但通过统一的元数据管理、虚拟化数据层和联邦查询引擎,上层应用可以像访问"一个数据库"一样,访问散布在全球各地的数据。
物理上是分布式的,逻辑上是统一的。查询时按需执行,没有预先的全量搬运,没有多副本冗余。
用一个不那么学术的比喻:传统 ETL 是快递仓储模式------把货物从各地物流中心集中搬到一个大仓库,再统一发货;Data Fabric 是实时调货模式------你下单的时候,系统直接查各地库存,就近配货,主仓根本不需要存那么多货。
2.2 与传统架构的核心差异

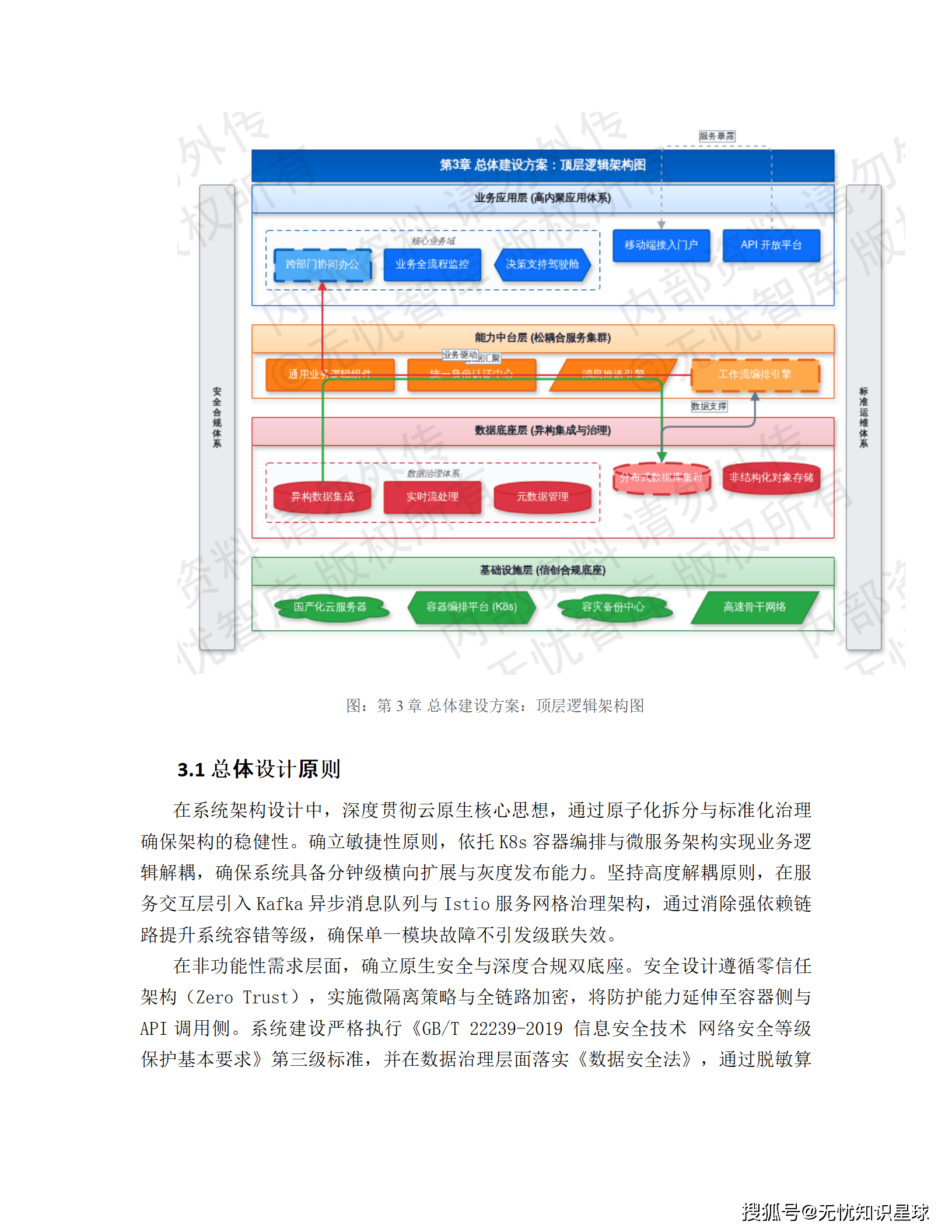
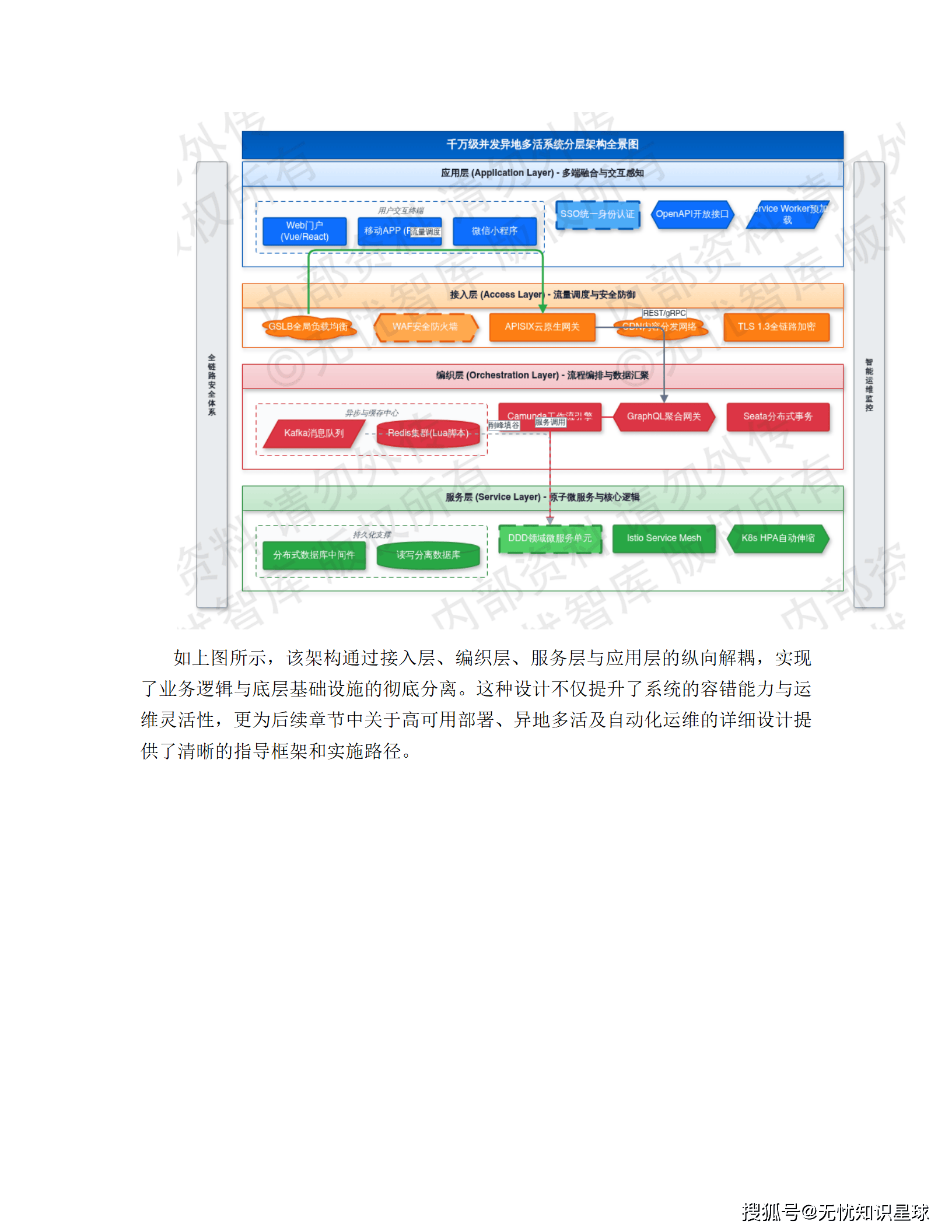
三、总体架构:分层设计的工程逻辑
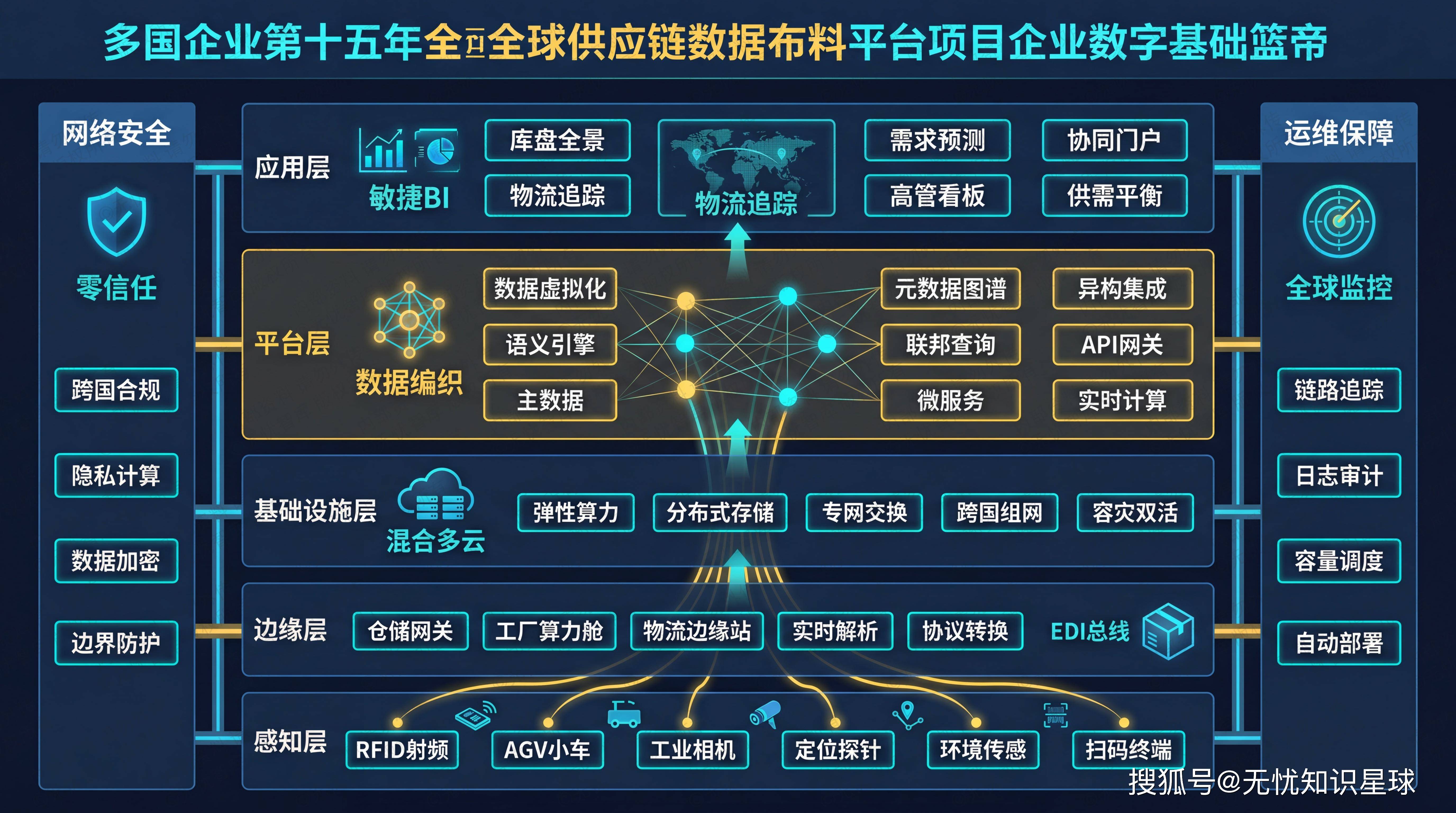
3.1 四层架构,各司其职
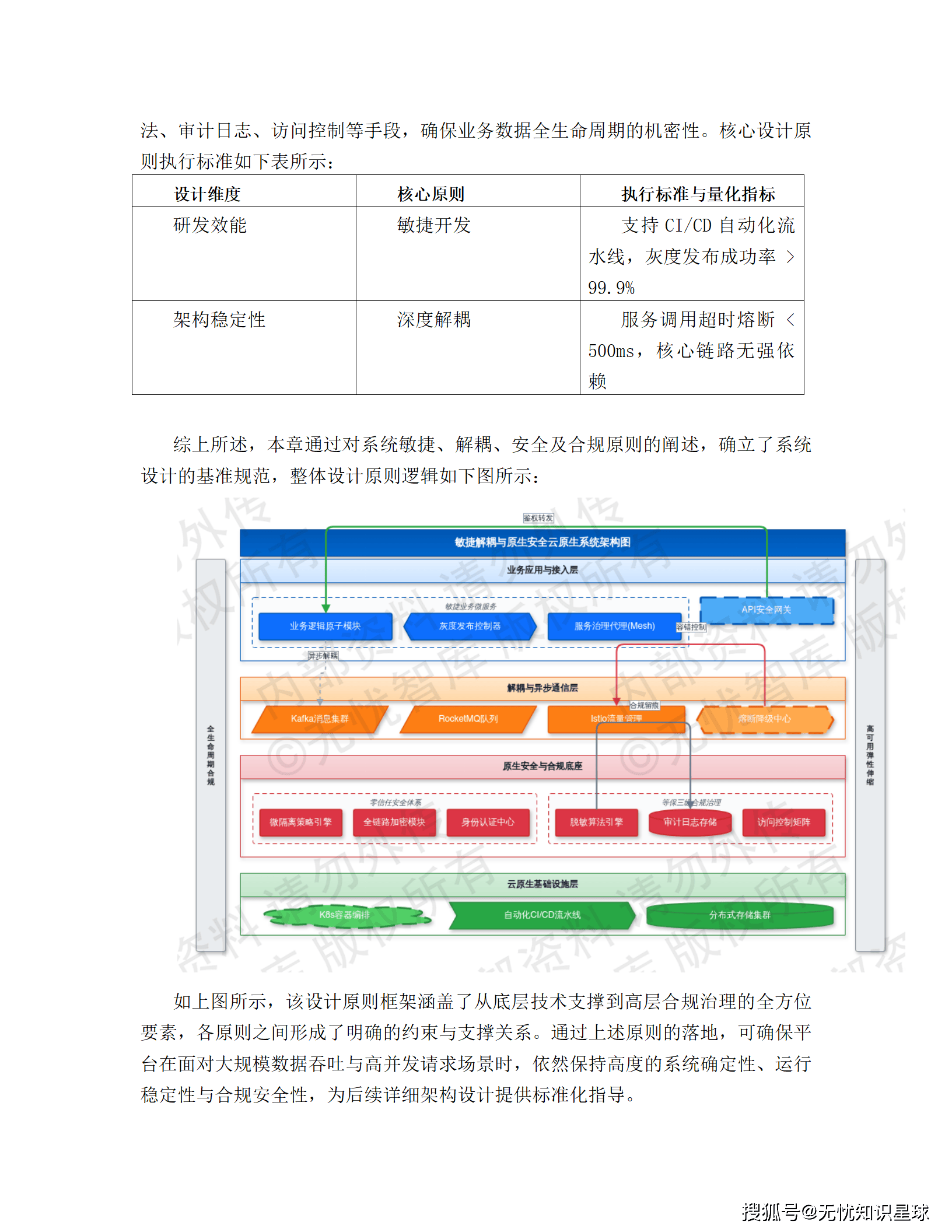
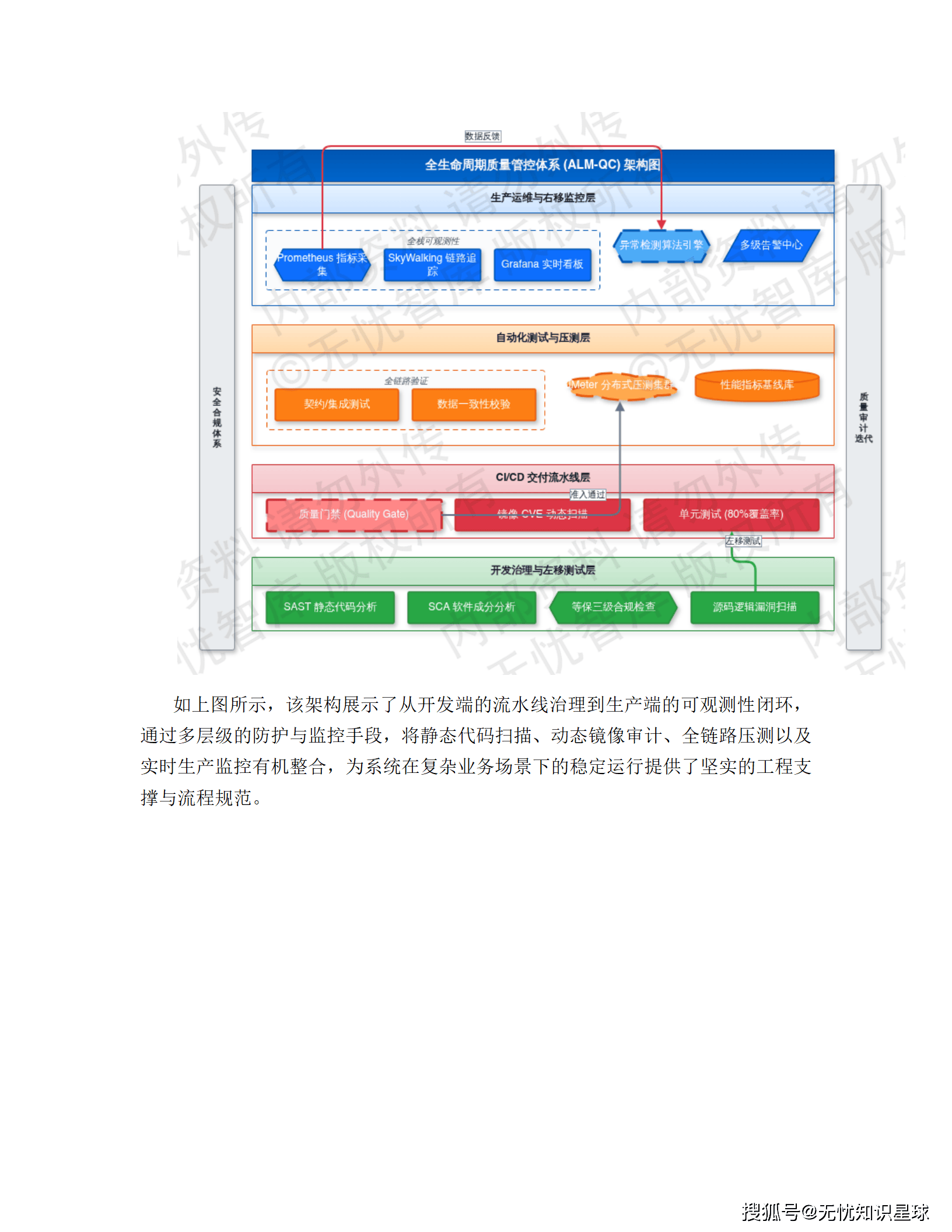
整体系统采用纵向分层架构,由下至上分为四层,层间通过标准化协议通信,并依托 Service Mesh 实现全链路流量治理。
接入层(流量调度与安全防御)
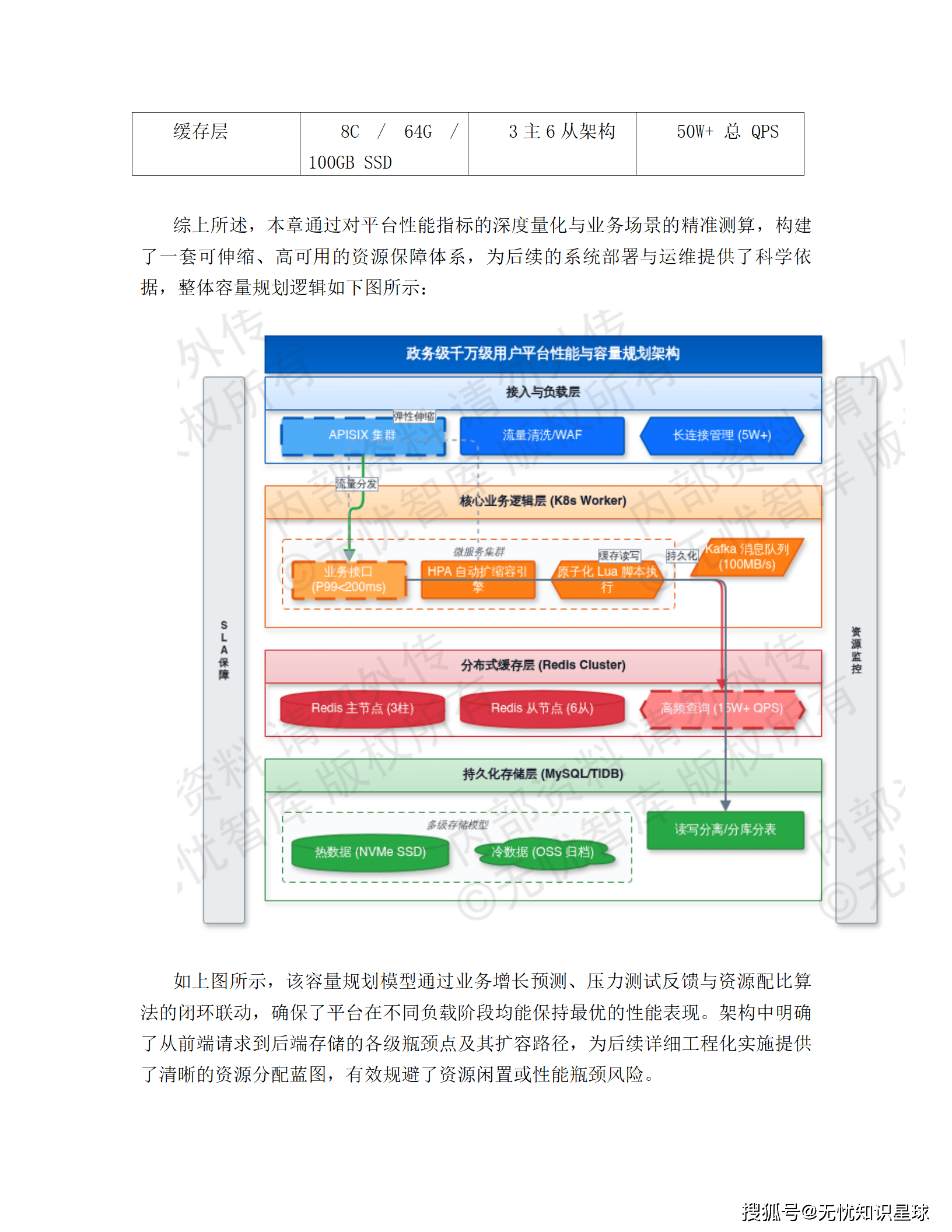
接入层是整个系统的流量入口,核心职责是流量清洗、协议转换和安全防护。技术上用云原生网关 APISIX 做多维度限流,令牌桶算法精确控流;WAF 实时拦截 SQL 注入和 XSS 攻击;全局负载均衡(GSLB)结合 CDN 动静分离,把用户请求调到最近的边缘节点。压测指标:网络接入延迟控制在 50ms 以内,并发连接支持超过 100 万。
编织层(业务流程动态编排)
编织层是逻辑调度中枢,负责跨服务的数据聚合和复杂业务流转。这里引入了分布式事务协调器 Seata,用于处理跨服务的原子性事务;BFF(Backend For Frontend)模式针对前端需求做数据实体规整;Redis 集群配合 Lua 脚本保证操作原子性;Kafka 承担异步解耦和流量削峰。
服务层(原子化微服务)
服务层基于 DDD(领域驱动设计)原则拆分,所有节点无状态化,支持 K8s HPA 动态扩缩容。深度集成 Istio,通过 Sidecar 模式做熔断、降级和链路追踪,SLA 目标 99.99%。读写分离和分库分表保证单表数据量在千万级阈值内,性能可控。
应用层(多端融合展现)
应用层提供 Web 门户、移动端、小程序及 OpenAPI 多种接口。前后端分离架构,Vue/React 组件化开发;Service Worker 资源预加载,弱网环境保基础可用;统一 SSO 身份认证,OAuth2.0 + JWT 鉴权,全平台权限一致。
3.2 核心设计原则
这套架构在设计之初就确立了几条硬约束:
- 敏捷性:K8s 容器编排 + 微服务解耦,支持分钟级横向扩展,灰度发布成功率目标 > 99.9%
- 深度解耦:Kafka 异步消息 + Istio 服务网格,服务调用超时熔断 < 500ms,单模块故障不引发级联失效
- 零信任安全:微隔离策略,全链路加密,防护延伸到容器侧和 API 调用侧
- 信创合规:严格执行等保 2.0 三级标准,数据全生命周期的脱敏、审计、访问控制全部到位
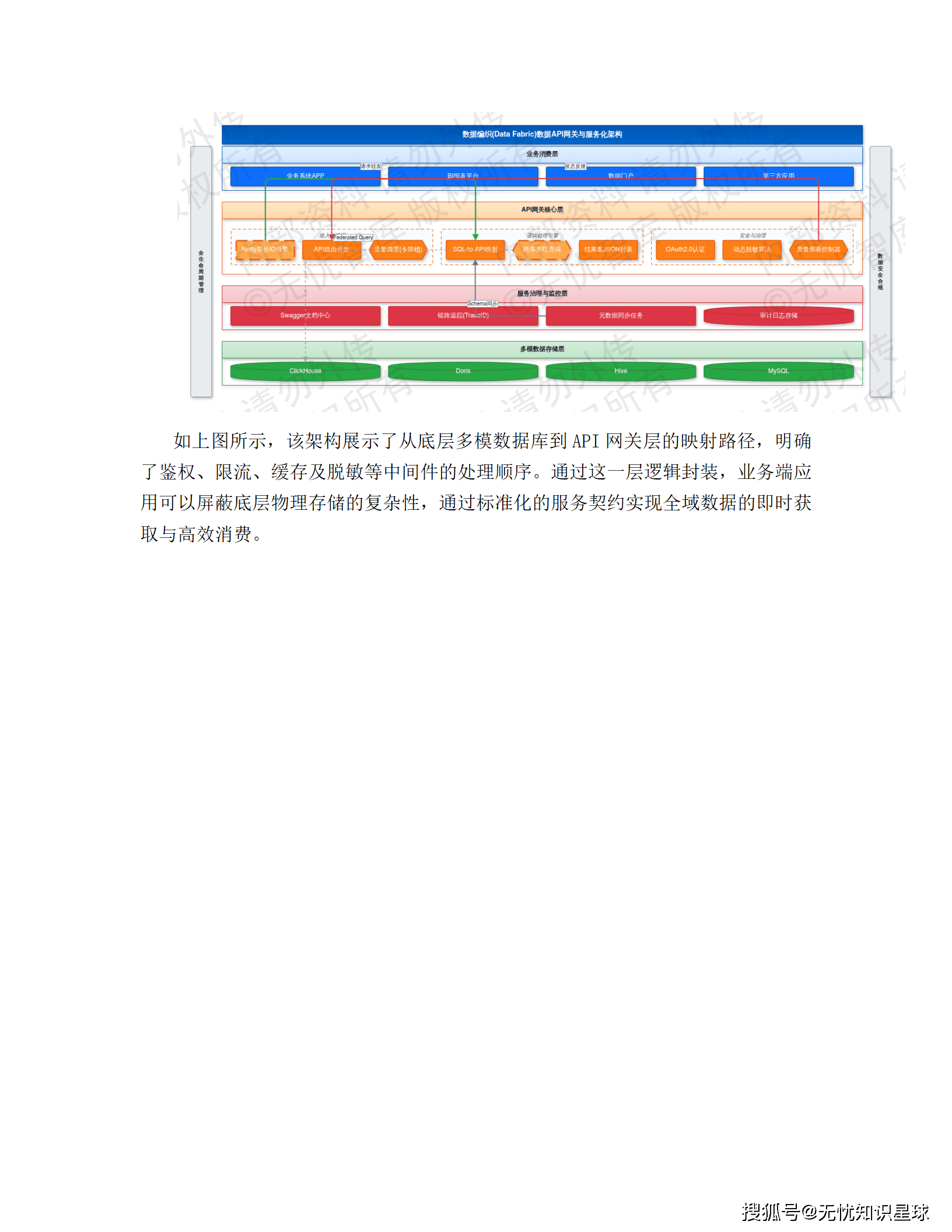
四、数据编织底座:技术实现的四个关键模块
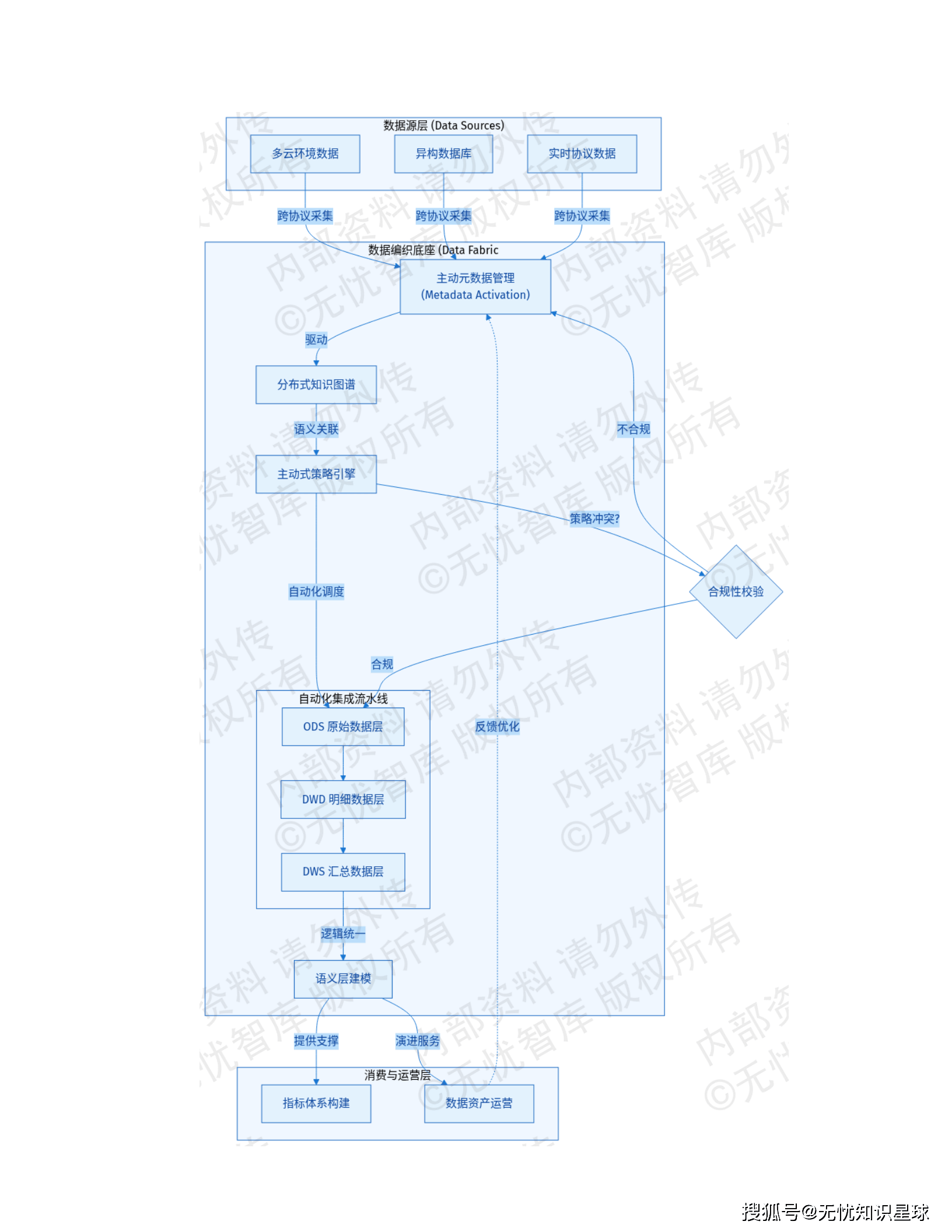
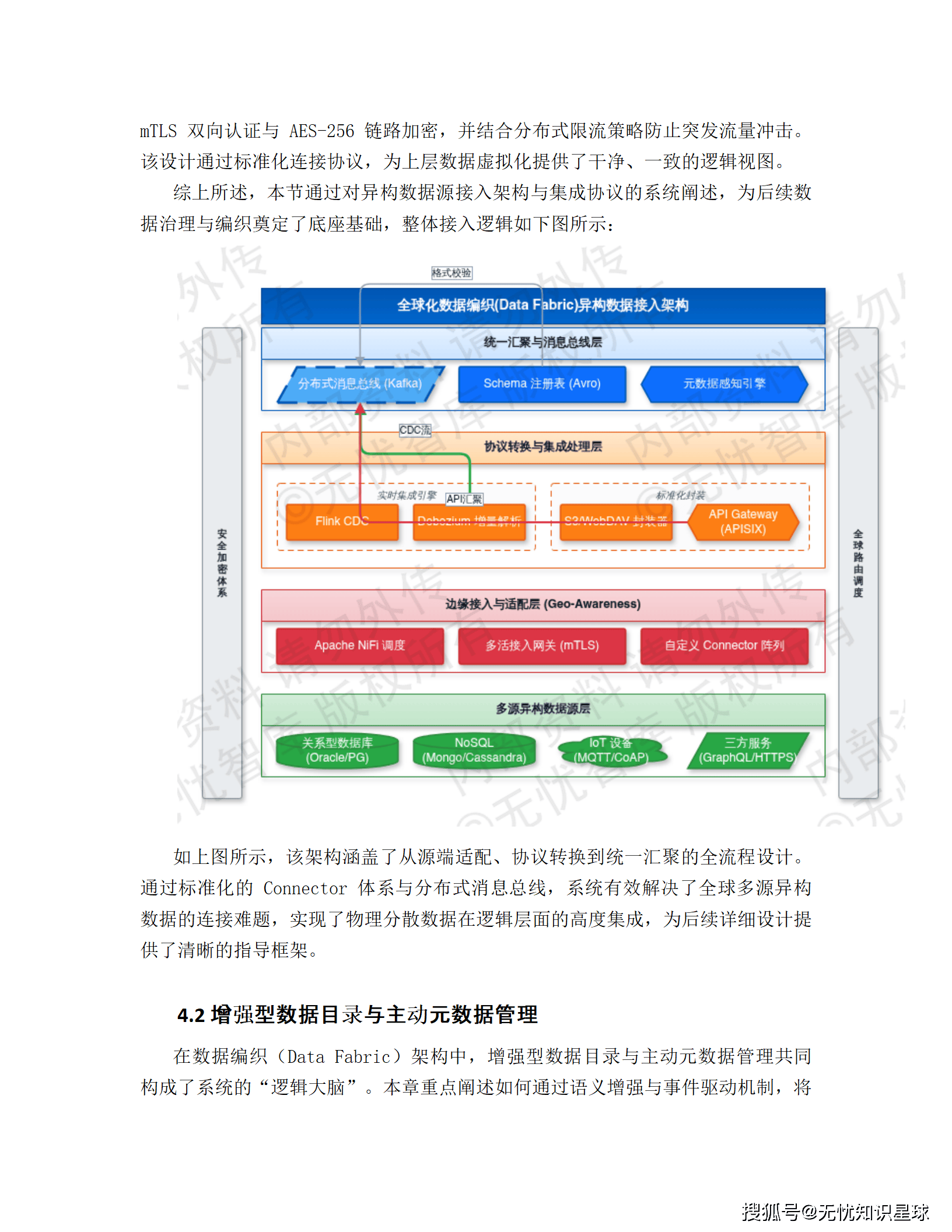
4.1 异构数据源接入层:50 种协议的统一入口
全球的数据源太杂了:Oracle、PostgreSQL、MongoDB、Cassandra、InfluxDB、MQTT 物联网协议......放弃了传统的点对点硬编码集成方式,转而构建"协议适配器 + 分布式消息总线 + 元数据感知"的标准化框架。
底层适配器集成 Apache NiFi 和自定义 Connector,支持 50+ 主流协议。关系型数据库走 CDC(变更数据捕获)技术,用 Debezium + Kafka Connect 解析源端 binlog,秒级捕获数据变更,不侵入业务逻辑。非结构化数据通过 S3 或 WebDAV 标准化封装。物联网边缘数据走 EMQX + Flink CDC,实时采集传感器信号。
为解决跨地域的高延迟问题,集成层在全球部署了多活接入节点,用 Geo-Awareness 地理位置感知路由,边缘数据优先汇聚到物理距离最近的网关。数据用 Avro 格式序列化以保证元数据传输一致性,金融级场景强制开启 mTLS 双向认证和 AES-256 链路加密。
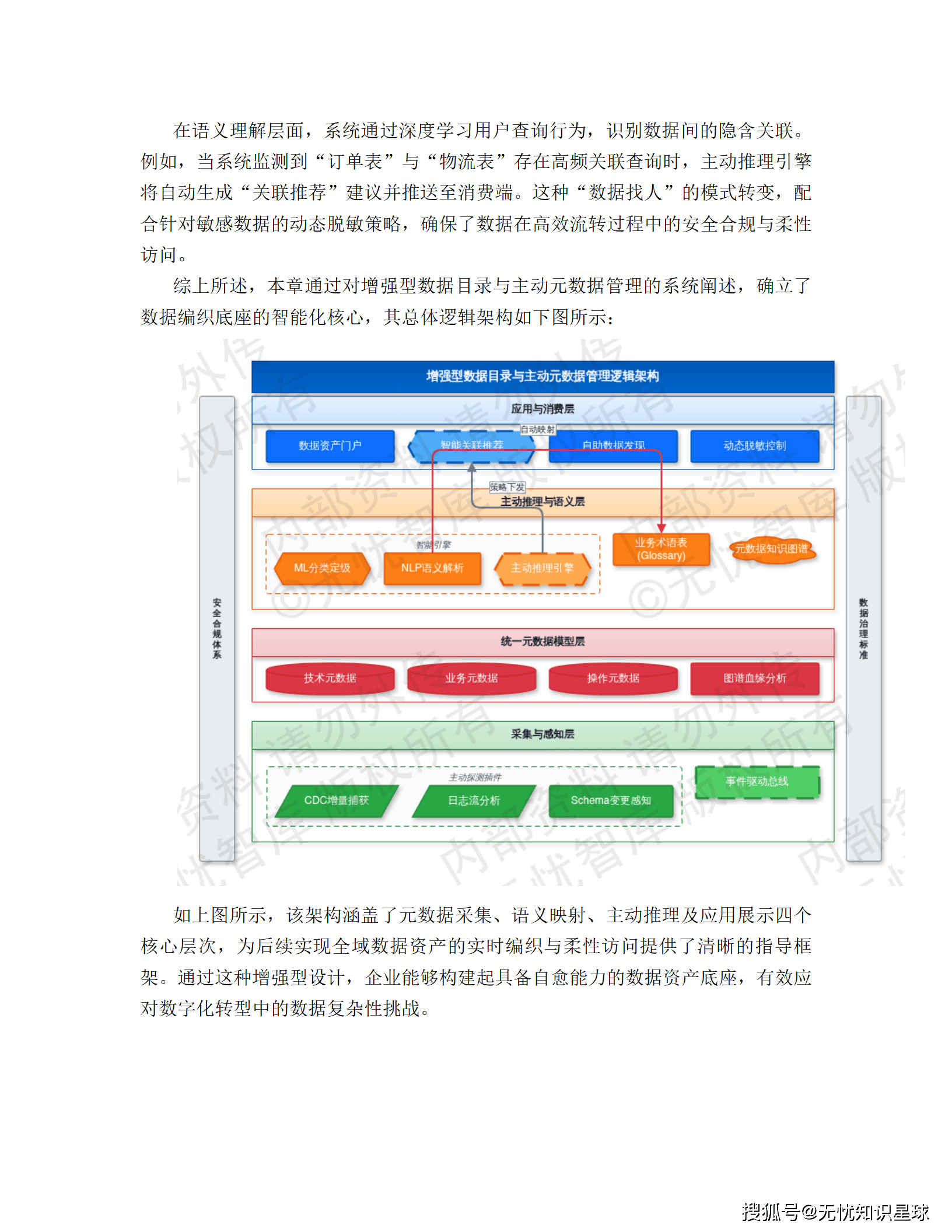
4.2 增强型数据目录与主动元数据管理:数据的"自我意识"
这是整个 Data Fabric 的大脑,也是区别于传统数据治理最核心的创新点。
传统数据目录是被动的------你得手动录入资产信息,维护字段说明,标注血缘关系。一旦源端变更,目录就过时了,运维人员天天在追这个差值。
**主动元数据管理(Active Metadata Management)**的做法完全相反:
系统在集成层和计算层部署轻量探测插件,实时捕获 Schema 变更、访问频次、数据质量波动等信号。主动推理引擎根据这些信号实时调整管理策略,元数据和物理数据始终保持强一致。
语义理解这块用了 NLP 技术,对物理层 Schema 做深度解析,把底层存储的原始字段(比如"CUST_UID")自动关联到企业标准业务术语表("客户唯一标识"),消除跨系统语义歧义。整个数据目录用图数据库实现,支撑全域资产知识图谱,万亿级节点快速检索。
更有意思的是行为分析功能:当系统监测到"订单表"和"物流表"存在高频关联查询时,主动推理引擎会自动生成"关联推荐"并推送给消费端。这种从"人找数据"到"数据找人"的转变,在大型组织里能实实在在减少大量重复建设。
主动元数据核心指标:
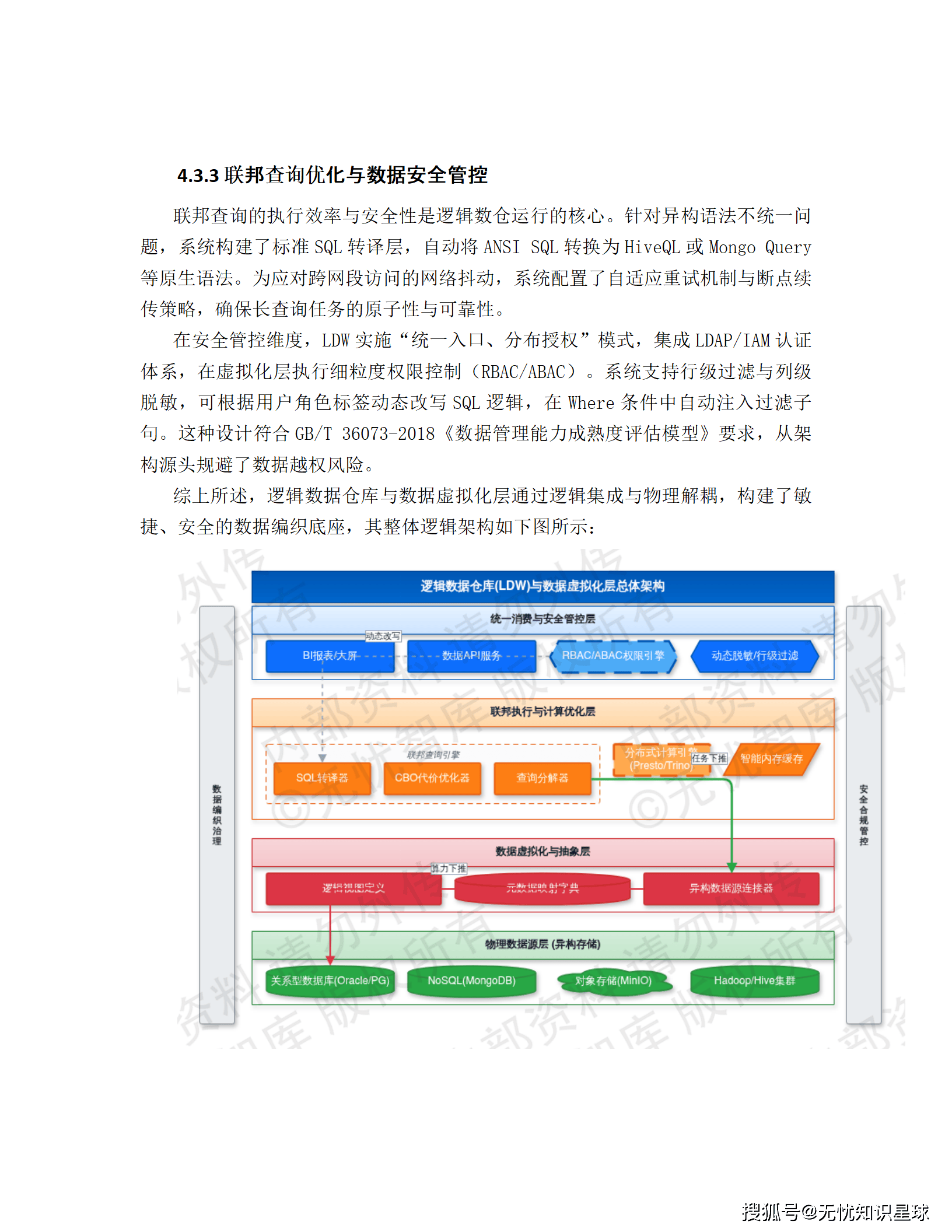
4.3 逻辑数据仓库(LDW)与数据虚拟化层:联邦查询的工程实现
LDW(Logical Data Warehouse)是 Data Fabric 架构中消除物理存储依赖的核心组件。架构上分四层:
- 物理数据源层:Oracle、PostgreSQL、MongoDB、MinIO、Hadoop 集群等,数据原地不动
- 数据抽象层:定义规范化逻辑视图,屏蔽底层物理表结构差异
- 联邦执行引擎层:查询重写和下推优化,驱动查询指令在靠近数据源的端侧执行
- 统一消费层:对上层应用提供标准的数据访问接口
虚拟化层基于 Trino/Denodo 构建,通过连接器实时同步远程数据源的元数据字典,生成逻辑表(Logical Tables)。当业务发起 SQL 查询时,查询分解技术把总任务拆成多个子任务,分发到各异构源系统并行执行,只把结果集汇聚回来。完全避免了全量数据的预先拉取。
性能优化上用了两个关键技术:**基于代价的优化器(CBO)**评估各源库算力资源,决定哪部分计算下推、哪部分在网关聚合;**动态过滤(Dynamic Filtering)**在运行时动态决定过滤条件,减少无效的跨库扫描。高频访问场景用内存计算缓存热数据,减少对源系统的主动扫描压力。
安全方面,LDW 实施"统一入口、分布授权"模式,LDAP/IAM 认证,细粒度 RBAC/ABAC 权限控制,支持行级过滤和列级脱敏。根据用户角色标签动态改写 SQL 逻辑,在 Where 条件里自动注入过滤子句,数据越权风险从架构层面规避。
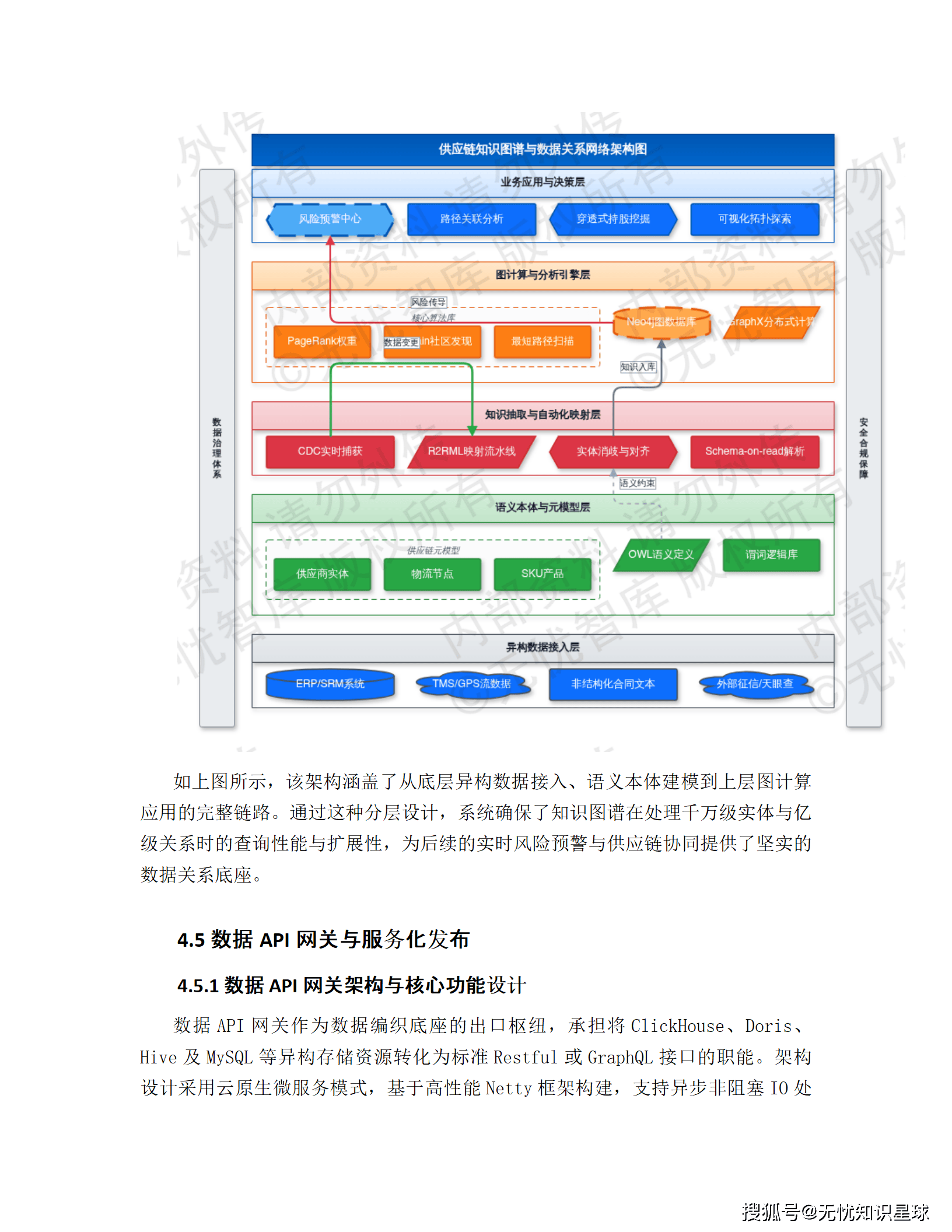
4.4 知识图谱与数据关系网络:供应链的"神经系统"
知识图谱解决的是一个很具体的问题:当某个底层供应商突然停供,谁能在 5 分钟内知道这件事影响了哪些一级供应商、哪些在制订单、哪些客户交期有风险?
传统方式是人工排查,打电话发邮件,可能要好几天。知识图谱方案是:把供应商、产品、工厂、物流节点之间的所有关系,用图结构存储下来,支持毫秒级的多跳关联查询。
实体识别阶段,集成 NLP 和 NER(命名实体识别)算法,从非结构化的合同、采购协议、日志文件里抽取关键实体。全局唯一标识符(GUID)机制,确保同一个供应商在 ERP、CRM、外部征信系统里的多个记录,被逻辑合并为一个唯一节点。
知识抽取用声明式映射语言(R2RML)构建自动化流水线,CDC 信号驱动,把关系型数据实时转换为 RDF 三元组。"同名异物"和"异名同物"的问题,用机器学习实体消歧技术解决------计算语义相似度 + 拓扑结构特征,自动对齐实体。
图计算层用 PageRank 和 Louvain 社区发现算法做深度扫描,识别供应链中的"关键单点故障"节点。还支持穿透式持股分析,整合工商数据识别供应商间的共同控股方,防范合规和串标风险。
五、业务应用层:数据编织能力如何变成业务价值
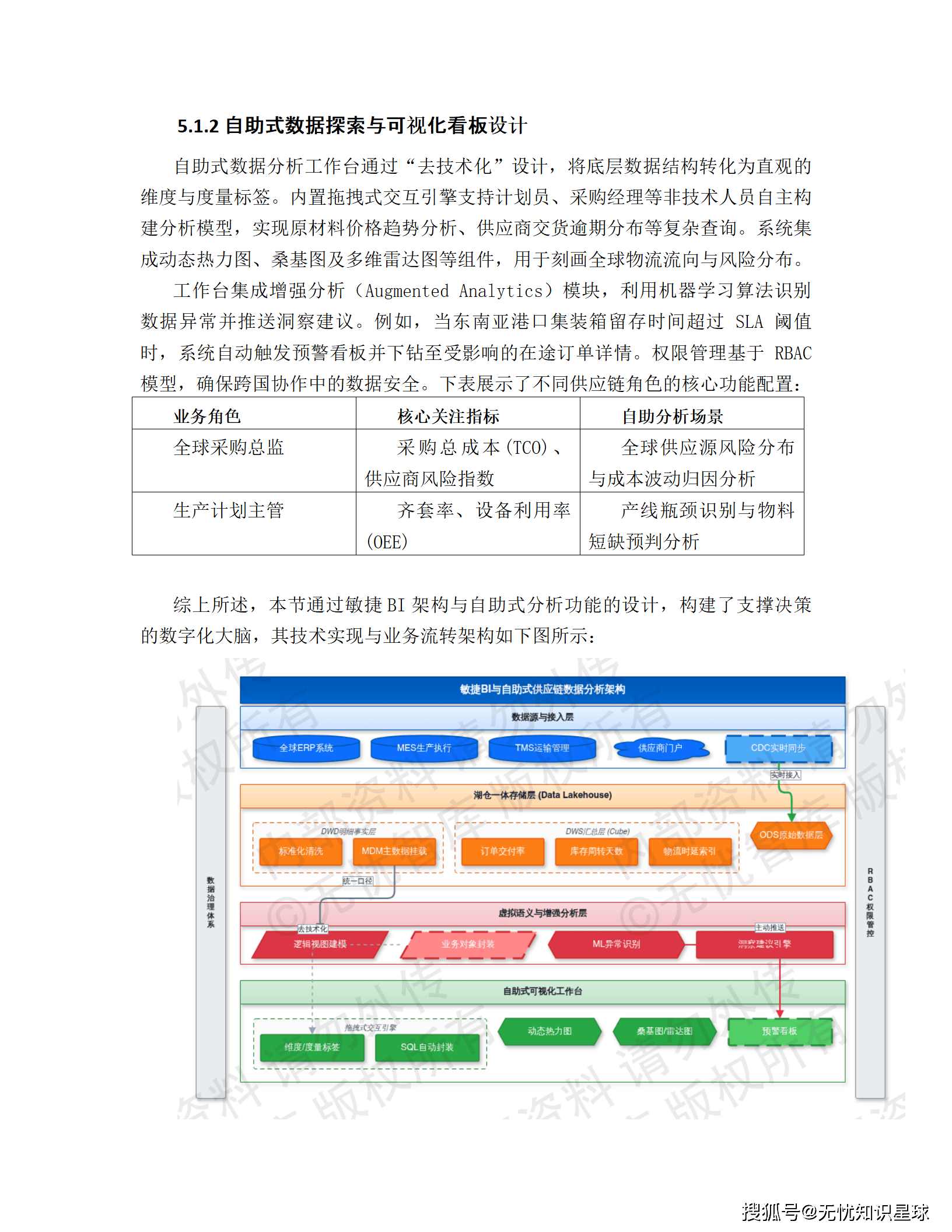
5.1 敏捷 BI 与自助式数据分析工作台
传统 BI 有个死穴:业务人员有分析需求,得找数据开发写报表,中间可能要走一两周的需求对齐、开发、测试流程。等数据出来,时机窗口说不定已经过了。
本方案的自助式工作台解决的核心问题是去技术化:把底层数据结构转化为直观的维度和度量标签,内置拖拽式交互引擎,计划员、采购经理这类非技术人员可以自主构建分析模型,做原材料价格趋势分析、供应商交货逾期分布这类复杂查询。
建模策略用"逻辑视图 + 物理聚合"双模:高频核心指标(订单交付率、库存周转天数)在 DWS 层预建多维数据立方体(Cube),亿级数据毫秒级响应;临时性探索需求走虚拟语义层实时查询,复杂 SQL Join 被封装成业务对象,业务侧完全感知不到底层复杂度。
增强分析(Augmented Analytics)模块用机器学习识别数据异常,主动推送洞察建议。比如东南亚港口集装箱留存时间超过 SLA 阈值,系统自动触发预警,并下钻到受影响的在途订单详情,责任人收到的不是一条告警,而是一份带上下文的分析报告。
不同角色的分析场景:
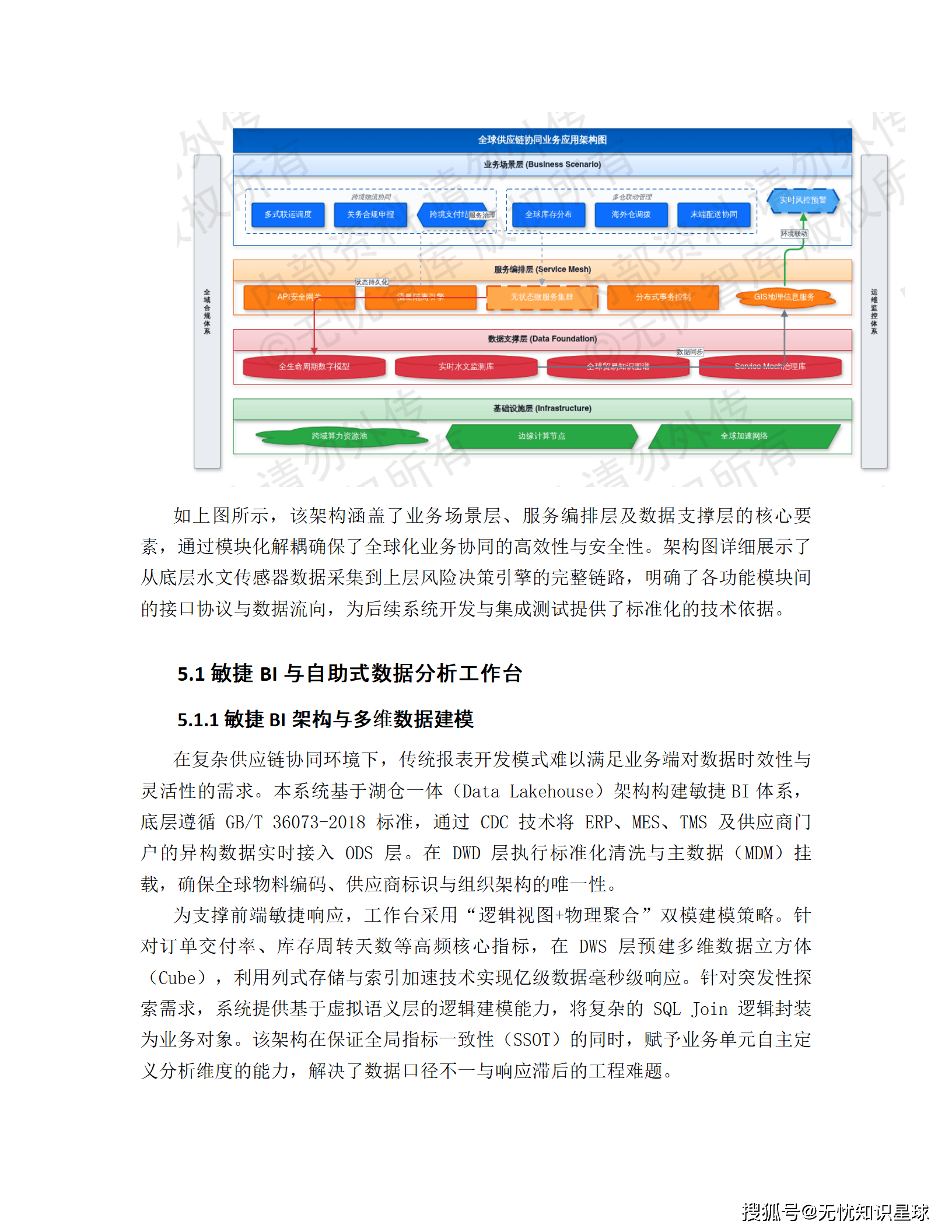
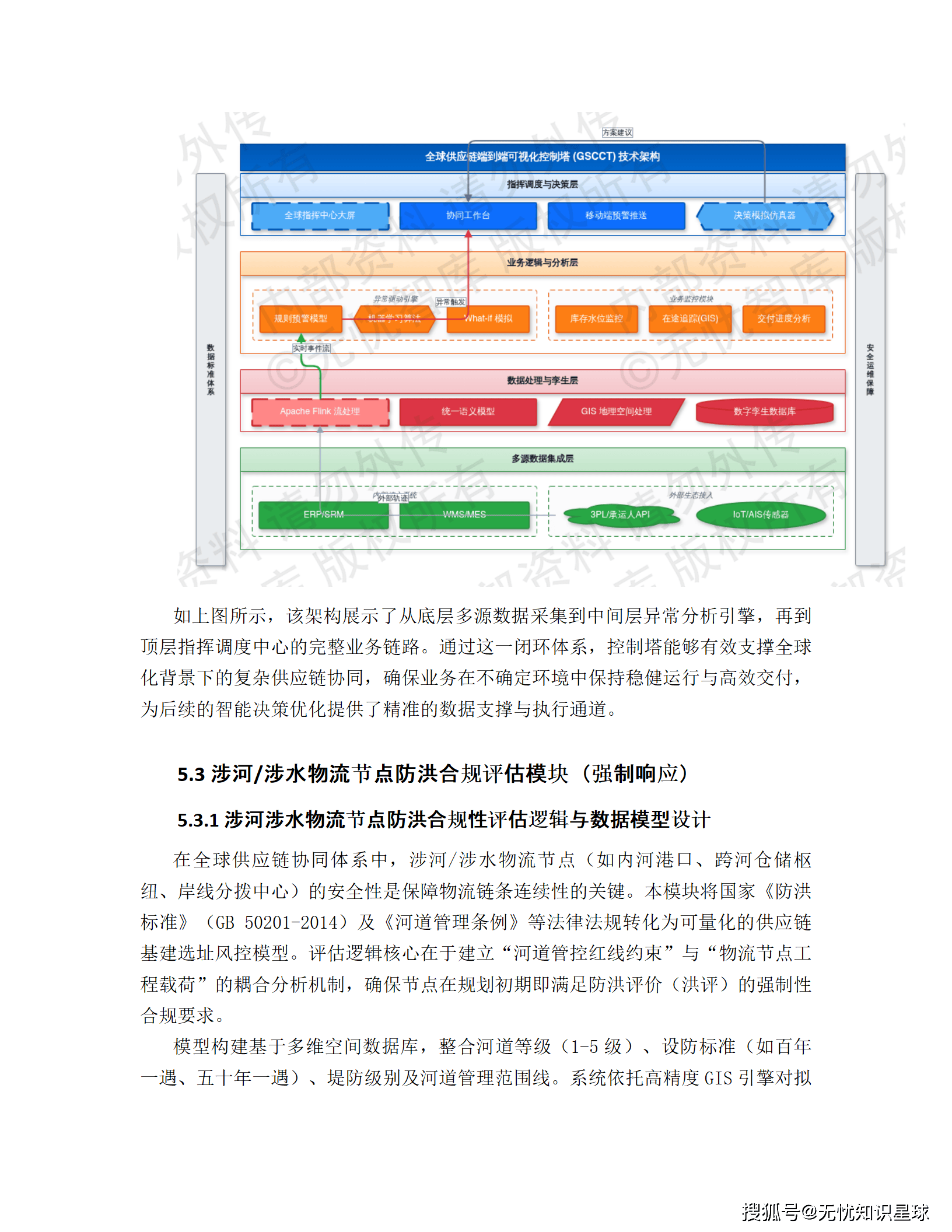
5.2 全球供应链端到端可视化控制塔
控制塔是整套方案最直接的业务价值出口,定位是企业的"全局指挥中心"。
技术上,控制塔用微服务架构结合 Apache Flink 流处理,支持全球海量业务事件毫秒级同步。数据来源覆盖 ERP、WMS、TMS、第三方物流 API、AIS 船舶追踪、IoT 传感器,通过 API、EDI 和物联网接入,高精度 GIS 地图上以热力图和路径图形式呈现全球物流网络实时状态。
控制塔的核心不是"看",而是异常驱动的闭环响应:
当业务数据偏离预设阈值(比如库存跌破安全水位,或运输时效偏差超 15%),系统自动启动异常处理工作流,通过协同工作台把预警推送到责任人,责任人直接在线反馈处置方案,替代传统的邮件电话沟通。
更高阶的功能是 What-if 仿真分析:检测到供应地区发生自然灾害等风险时,系统立即模拟切换备选供应商、空运补货、调整生产优先级等多种方案,对比各方案的成本、交付延迟和利润影响,辅助指挥中心在极短时间内做出最优决策。这不是 PPT 上的功能,背后是知识图谱的关联推理 + 供应链 MILP 优化模型在支撑。
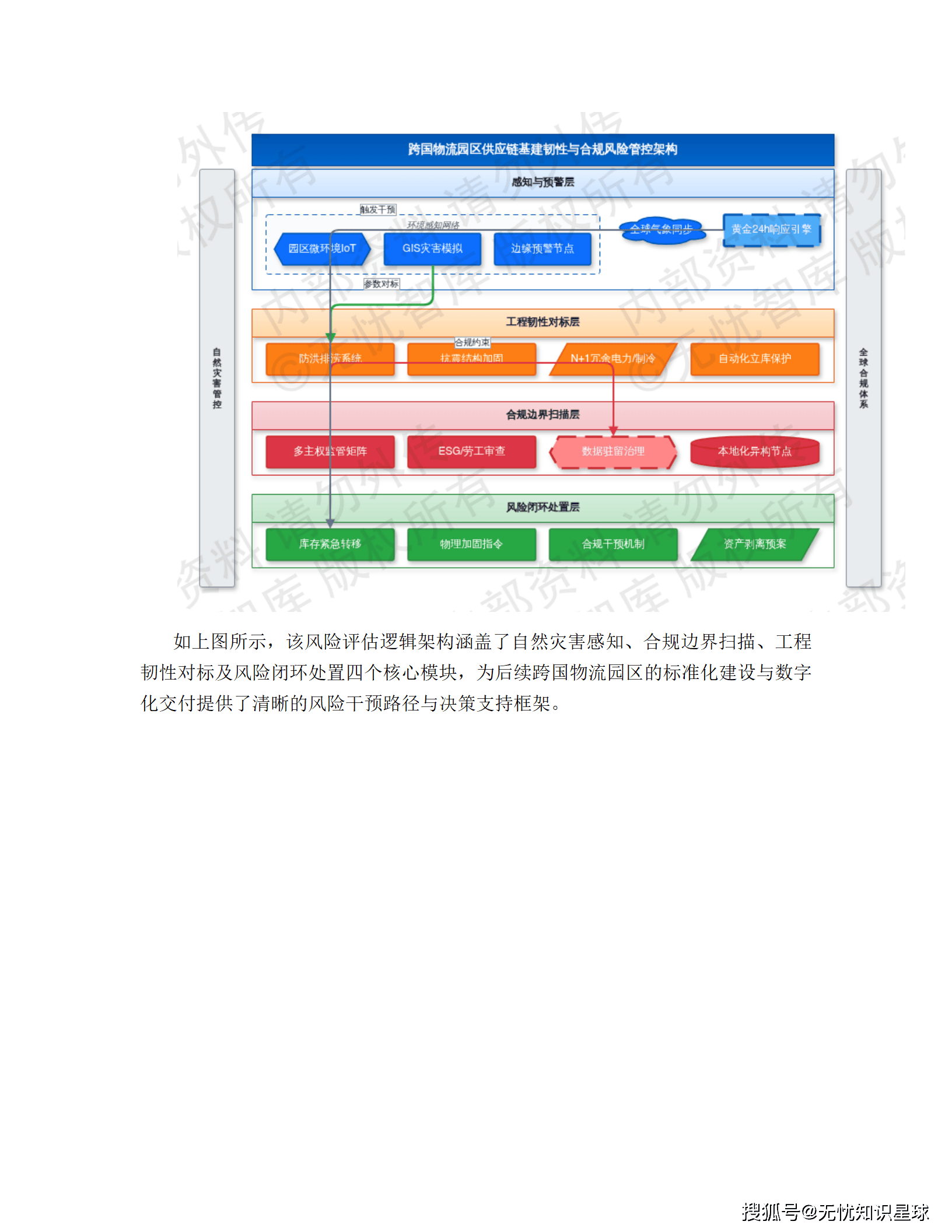
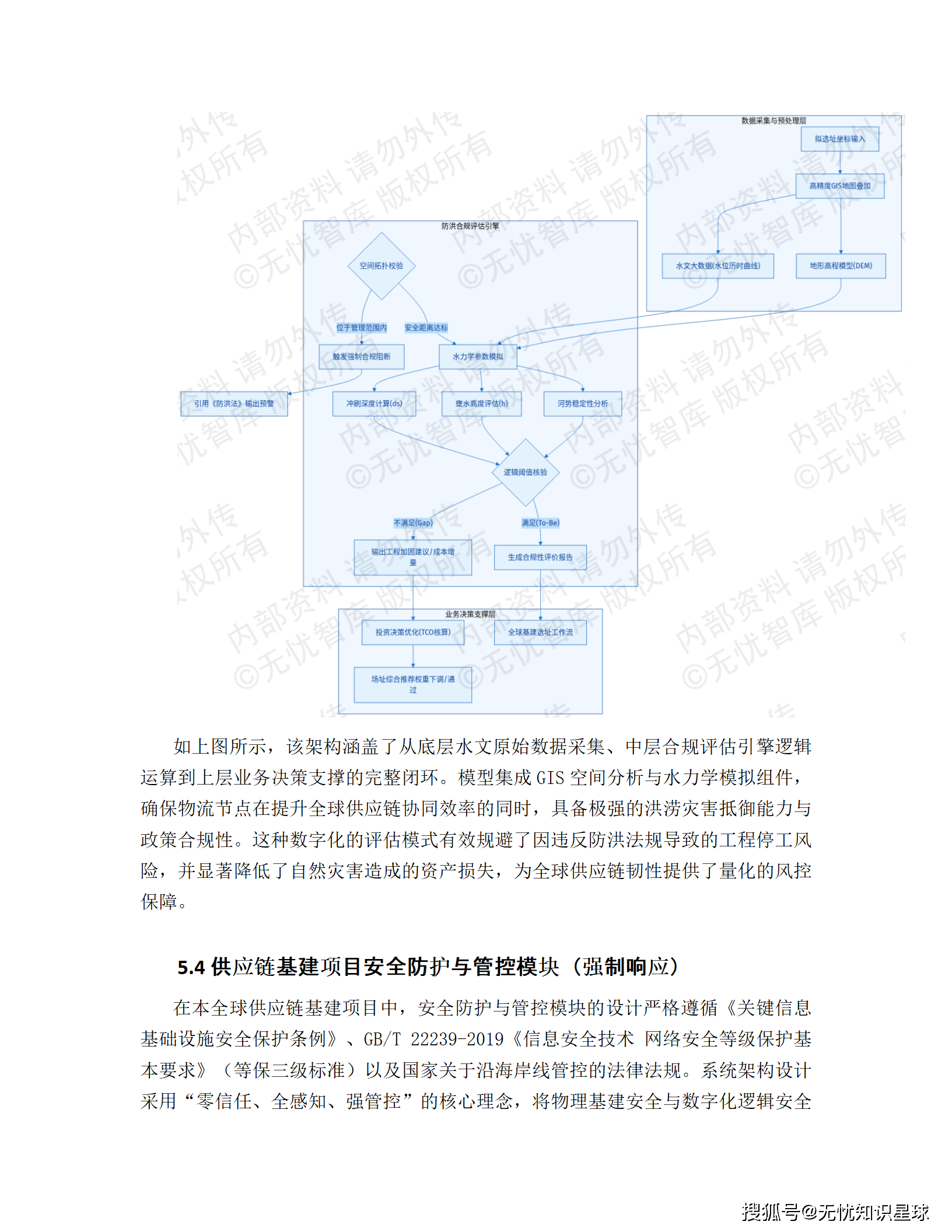
5.3 涉河涉水物流节点防洪合规评估模块
这个模块听起来偏门,但在方案里是作为"强制响应"来设计的,背后有明确的法律依据。
跨国企业的仓储中心、港口、物流园区,很多选址在河道沿线或沿海低洼地带。《中华人民共和国防洪法》第二十二条明确规定:在河道管理范围内建设桥梁、码头、道路、仓库等工程设施,必须符合防洪标准。
现实问题是:企业在全球建了几十个物流节点,每个节点的防洪合规状态分散在各地档案里,根本无法统一管理,更别说实时监测了。
这个模块做的事情:
一,静态合规评估。 把 JTGC30---2015《公路工程水文勘测设计规范》、GB 50201-2014《防洪标准》等行业标准转化为系统可识别的逻辑规则,自动比对物流节点的防洪等级、排水泵站流量、设计洪水频率等参数,输出合规性评估报告。
二,动态实时监控。 接入各节点周边的水位计、流量计、雨量计等物联网传感器数据,当监测数据触发防洪警戒阈值时,系统自动启动应急预案,动态调整涉河区域的仓储调度和物流路径。
三,灾害风险建模。 基于 GIS 地理信息系统做灾害模拟评估,沿海低洼节点的风暴潮叠加风险、地震带节点的结构振动敏感性,都被量化为风险评分,纳入供应链路由规划的约束条件。
六、数据治理:没有这些,架构再好也白搭
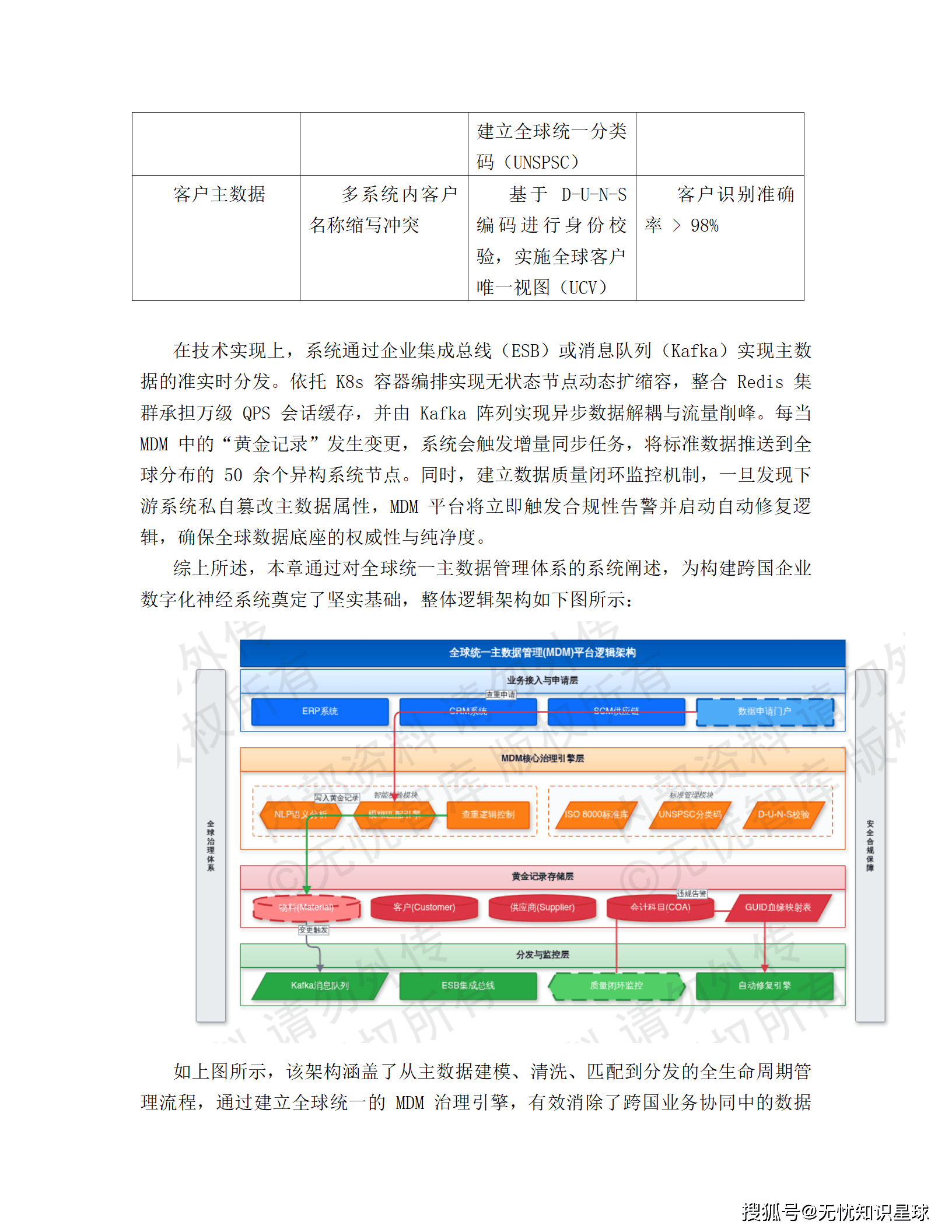
6.1 全球统一主数据管理(MDM)
跨国企业数据治理的痼疾是"同物不同名、同名不同义"。同一个物料,北美叫"Part #US001234",欧洲叫"Artikel-EU-5678",亚太又是另一套编码,合并报表的时候财务团队每次都在手工对照。
MDM 平台用的是"黄金记录(Golden Record)"机制------对物料、客户、供应商、会计科目等核心实体,在全球范围内建立唯一标识,所有业务系统都以此为准,不允许在本地维护"私版本"。
去重查重引擎集成了 NLP 和模糊匹配算法。当任何系统发起新主数据申请,系统自动检索全球现存数据库,识别相似度超过 85% 的既有记录,强制要求申请人核对,从源头遏制冗余数据产生。
治理模式用"集中式 + 联邦式"混合:全球通用基础信息由集团总部集中下发;有地域特性的属性(本地税号、特定物流参数),允许各大区在遵循全局标准前提下联邦扩展。黄金记录一旦变更,Kafka 驱动增量同步任务,推送到全球分布的 50+ 异构系统节点,准实时完成。
主数据治理效果指标:
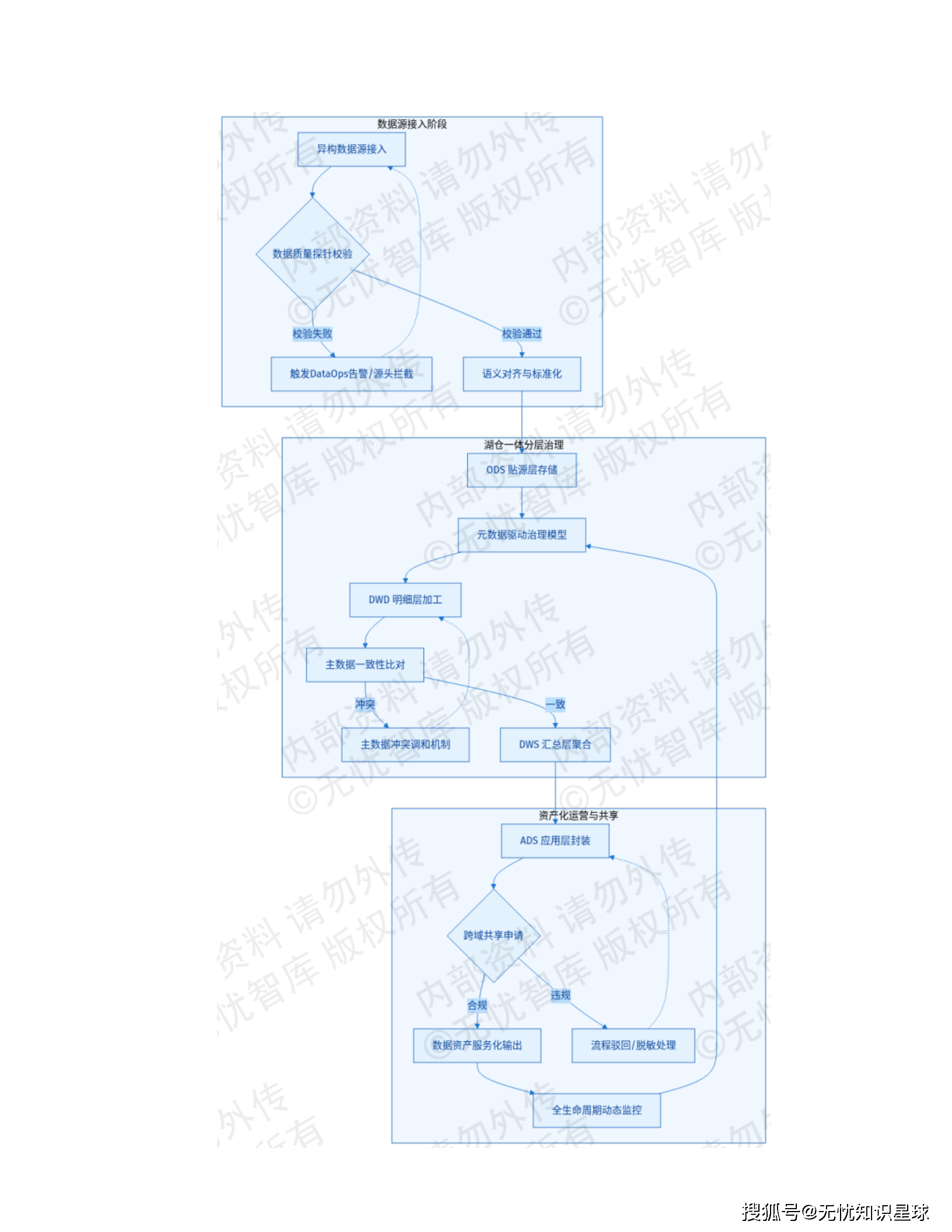
6.2 数据质量闭环:事前、事中、事后三道防线
数据质量治理有一个反直觉的道理:越晚发现问题,修复成本越高。一条脏数据进了 ODS,可能会污染 DWD 的三十个下游表,最终影响几十份报表。
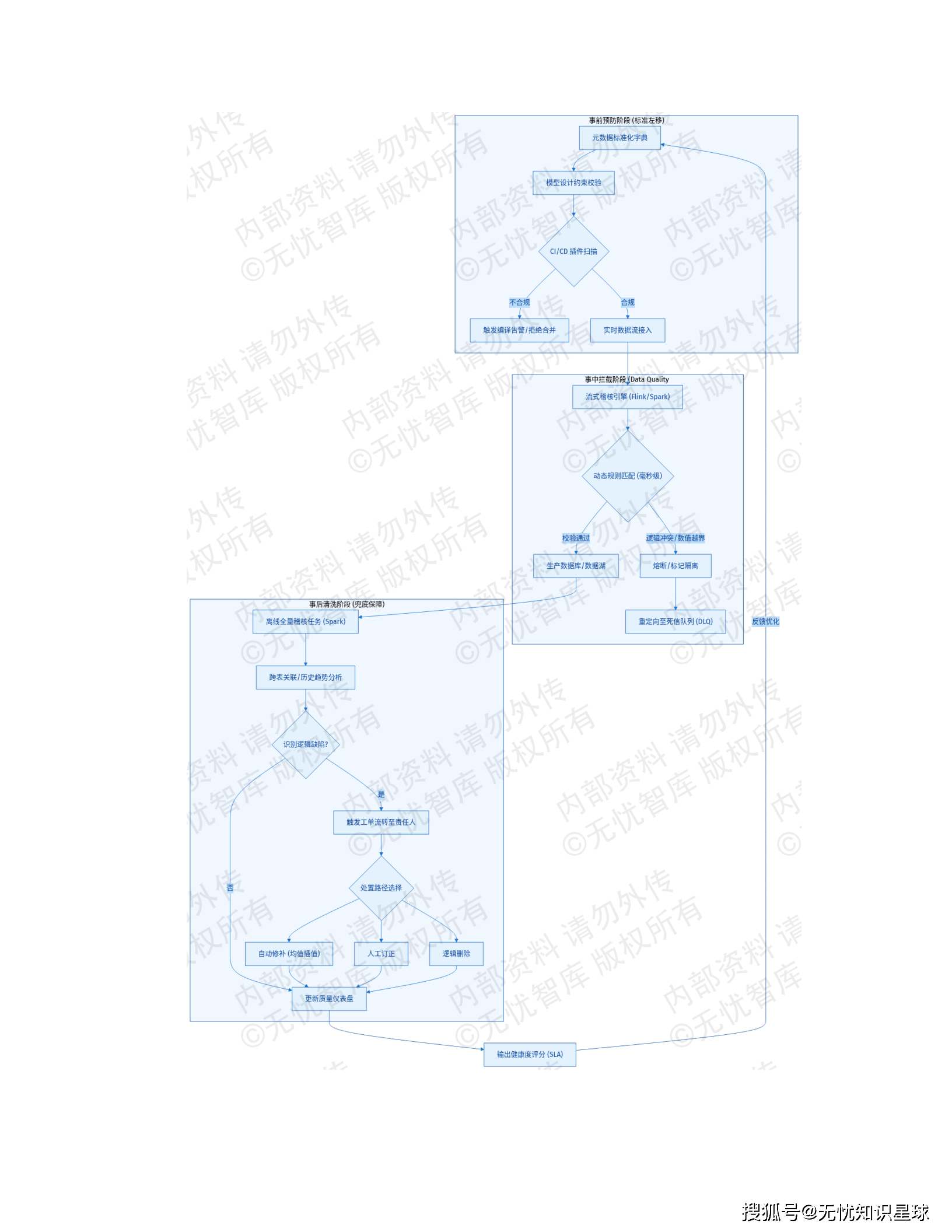
这套方案建立了事前预防、事中拦截、事后清洗的三位一体质量闭环:
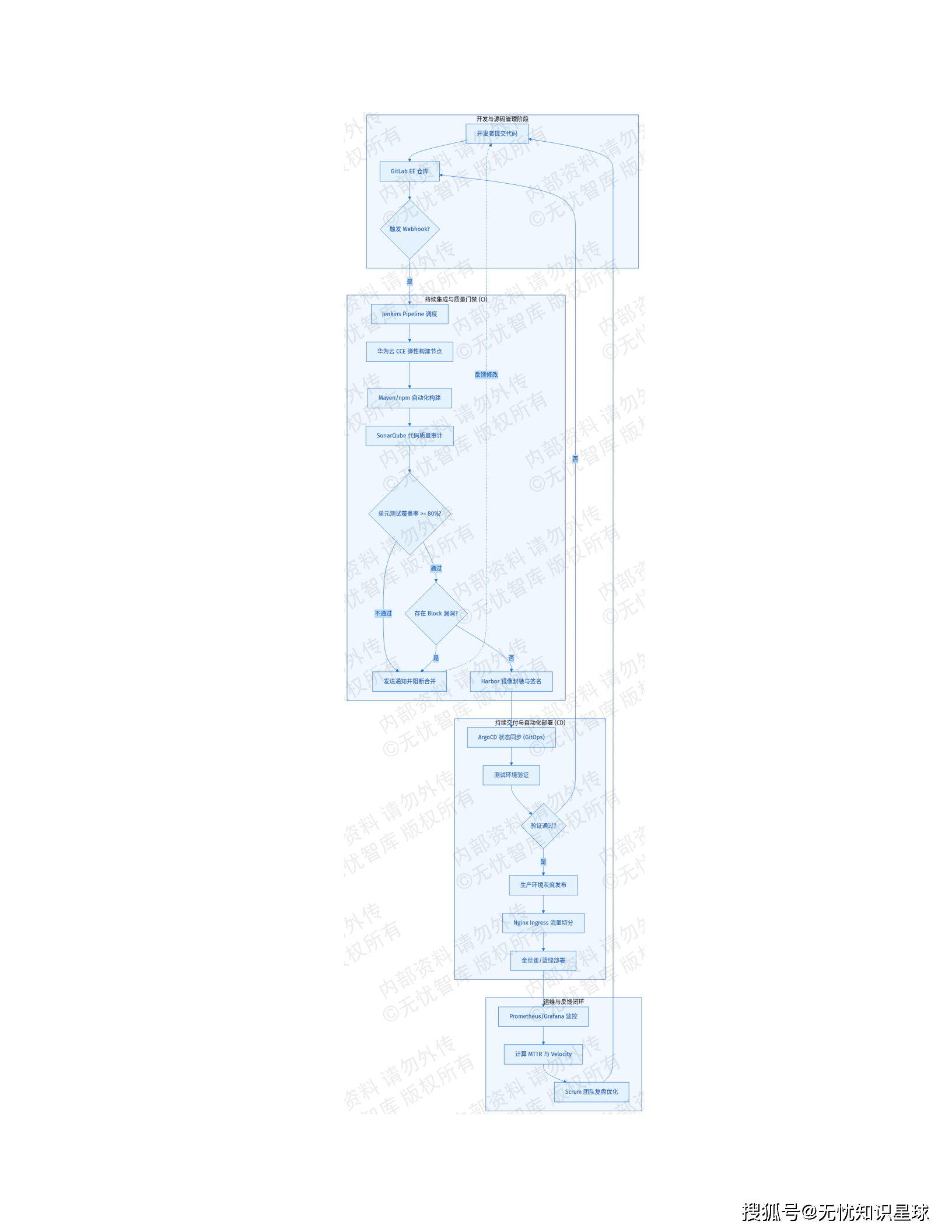
事前预防:在数据模型设计阶段就强制引入元数据标准化约束。CI/CD 流水线里部署静态代码校验插件,针对 SQL 脚本和 ETL 逻辑执行字段命名、类型精度、非空约束的自动扫描。脚本违反预设规则,直接阻断合并,不让进生产分支。
事中拦截:部署基于 Flink/Spark Streaming 的流式稽核引擎(Data Quality Firewall),在数据入湖入仓的实时链路上做毫秒级比对。金融交易金额偏离历史均值超过 3 个标准差且未通过风控校验的记录,直接重定向到死信队列(Dead Letter Queue),不允许进生产库。拦截延迟 < 200ms,误拦截率 < 0.01%。
事后清洗:离线计算引擎每日全量稽核,跨表关联和历史趋势分析,识别实时链路抓不到的逻辑缺陷。异常数据自动触发工单流转,提供均值插值自动修补、人工订正、逻辑删除三种处置路径,质量仪表盘实时输出 SLA 健康度评分。
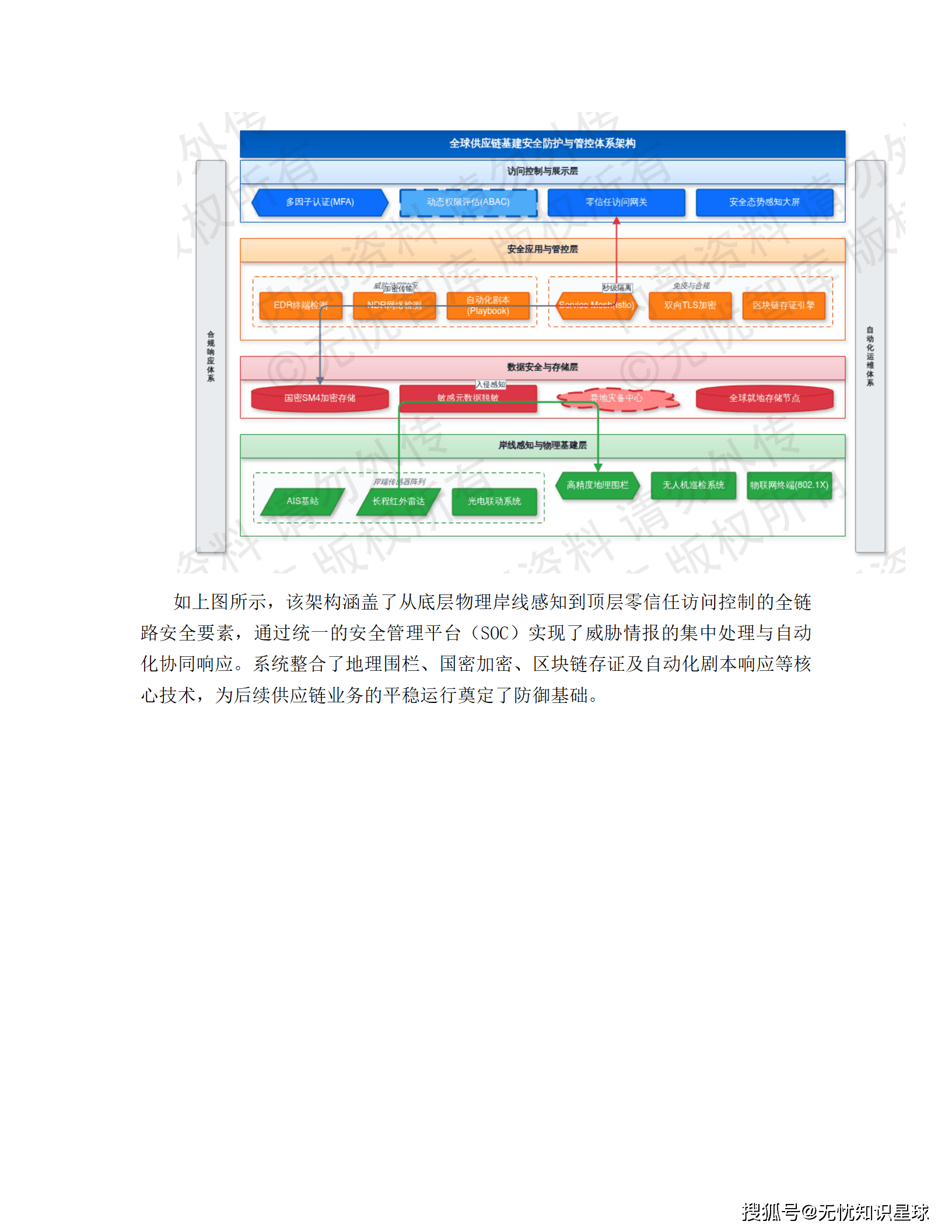
七、平台非功能性设计:稳定性和安全性怎么做
7.1 高可用与容灾设计
核心业务系统目标 SLA 99.99%,折算下来全年允许停机时间不超过 52 分钟,这对架构的容灾能力有极高要求。
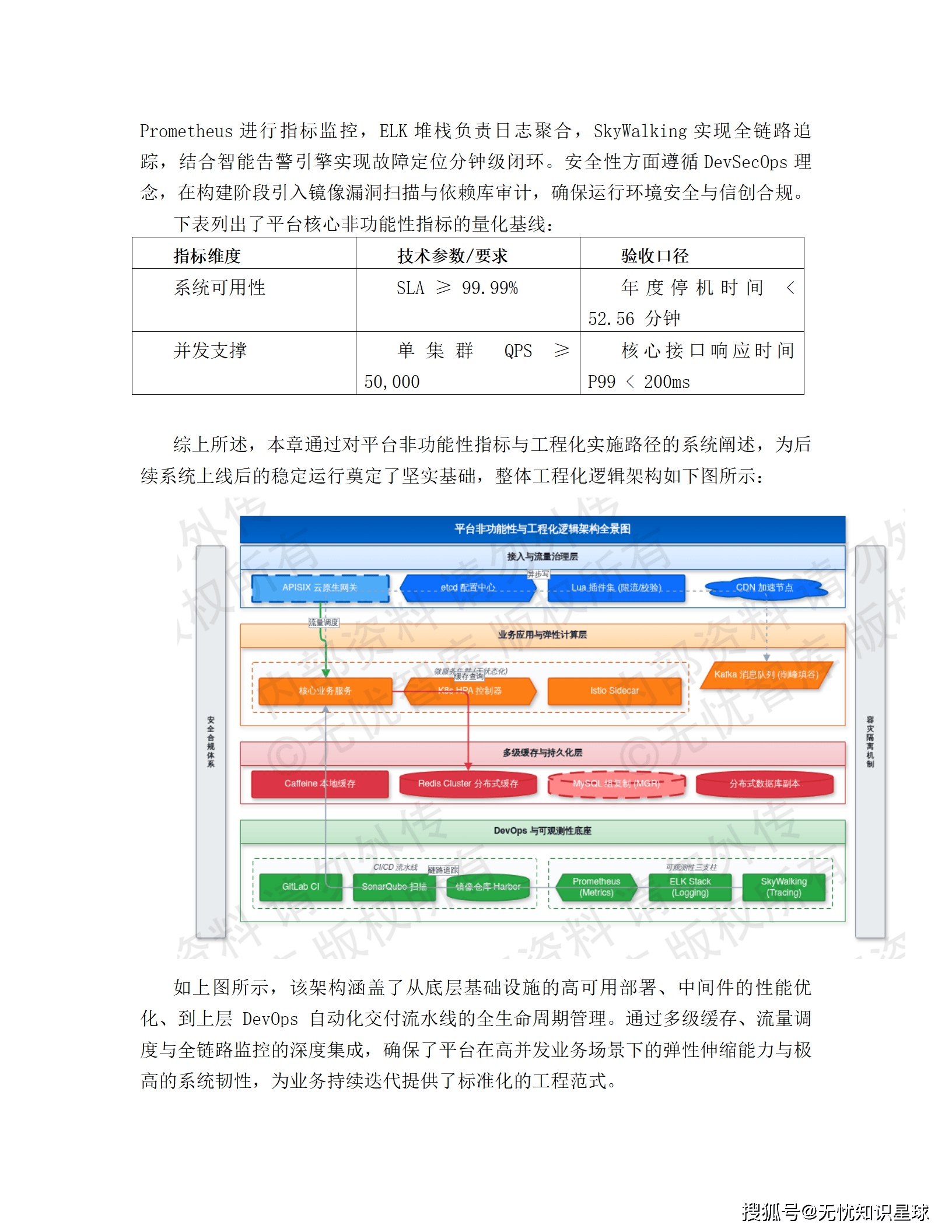
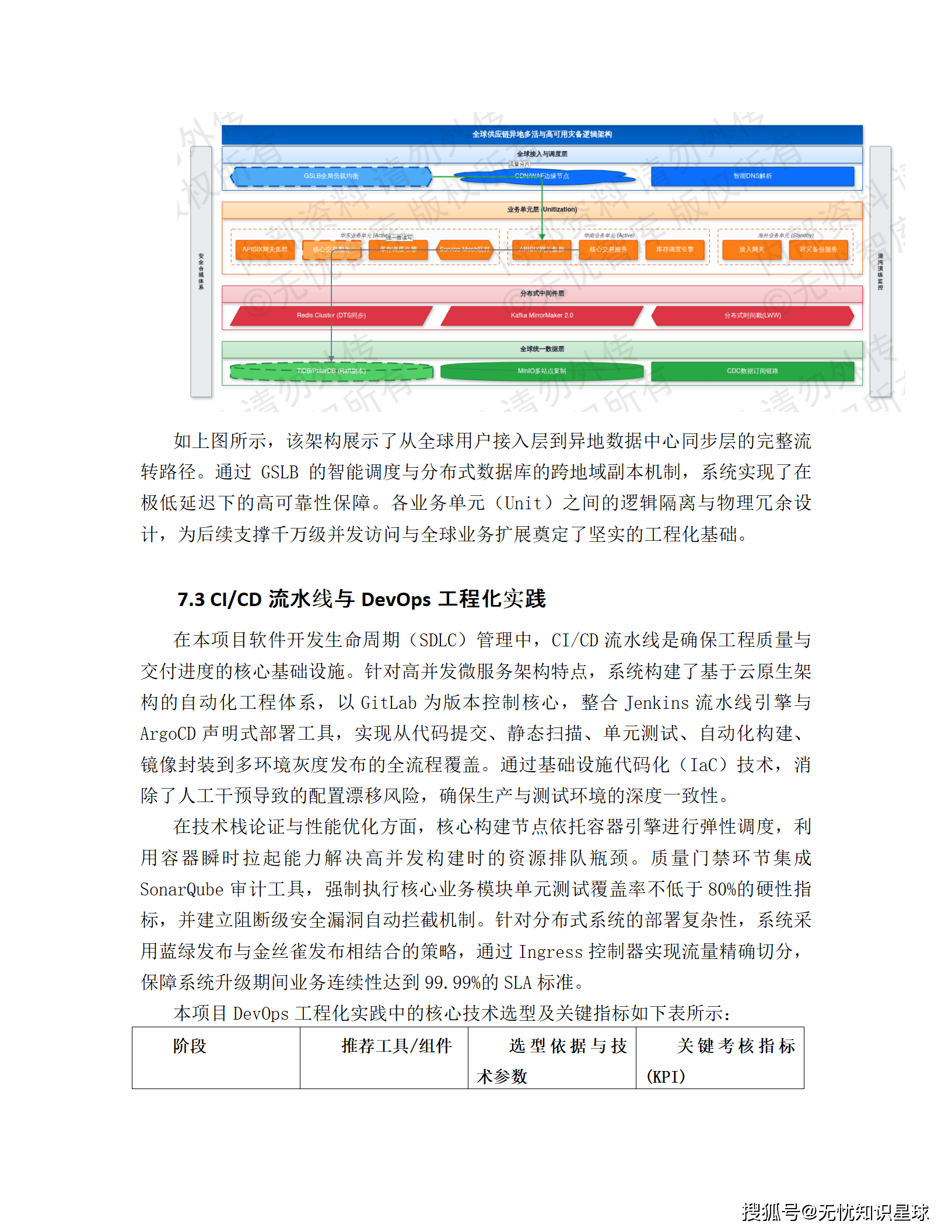
方案采用多活部署模式,三大区域(亚太、北美、欧洲)各建独立的数据节点,任一节点故障不影响其他区域正常服务。关键业务走 RPO < 5 分钟、RTO < 30 分钟的容灾指标,数据库层用 MGR(MySQL Group Replication)或 RAC 集群实现高可用。K8s 集群结合 HPA 策略做弹性伸缩,峰值流量自动拉起新实例,业务低谷自动缩容控成本。
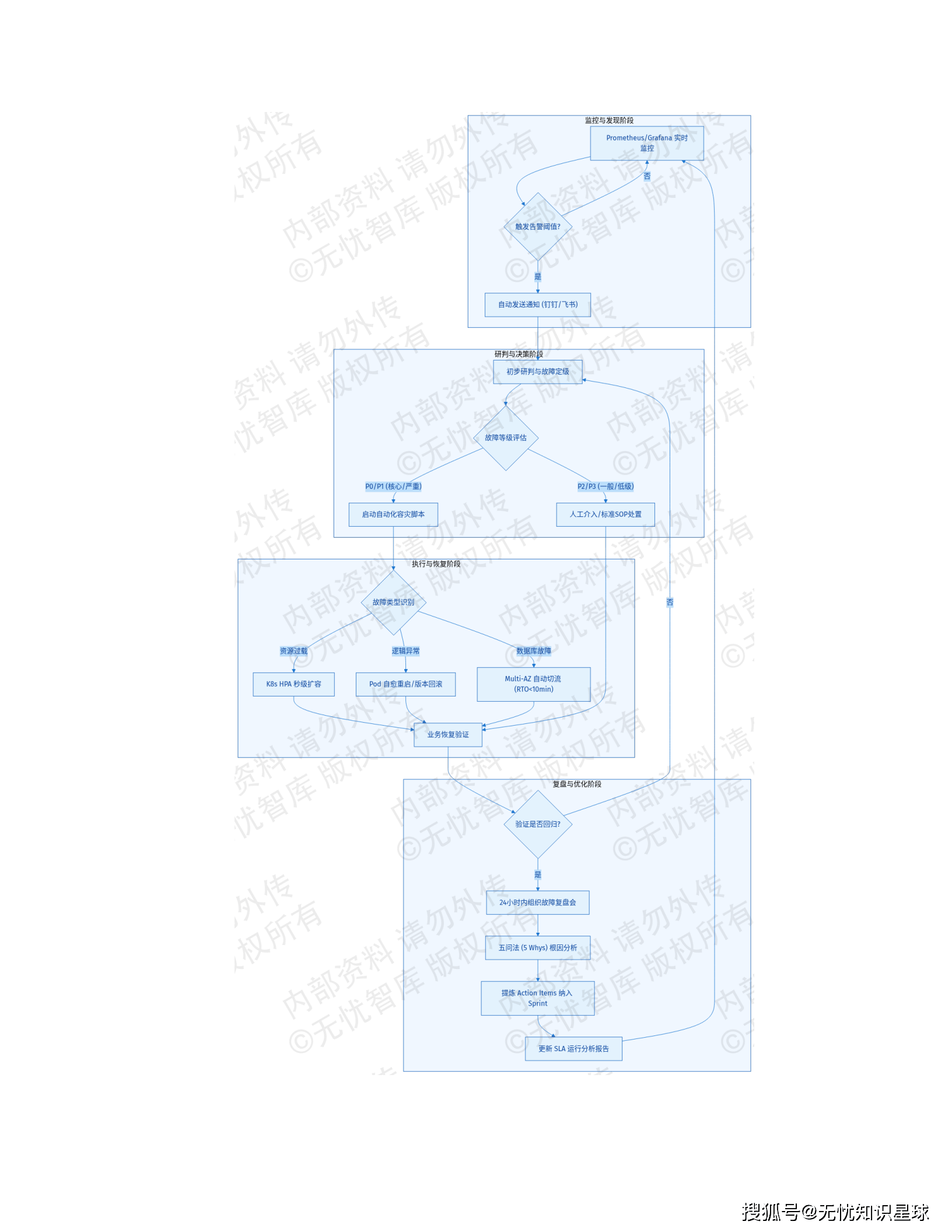
故障响应机制分三级:一级故障(核心业务中断)10 分钟内响应、2 小时内恢复;二级故障(部分功能受损)4 小时内解决;三级故障(一般性优化)24 小时内反馈。Prometheus + Grafana 做全栈监控,异常检测算法主动识别流量突增、延迟漂移等亚健康状态,在故障发生前触发多级告警。
7.2 安全架构:零信任落地
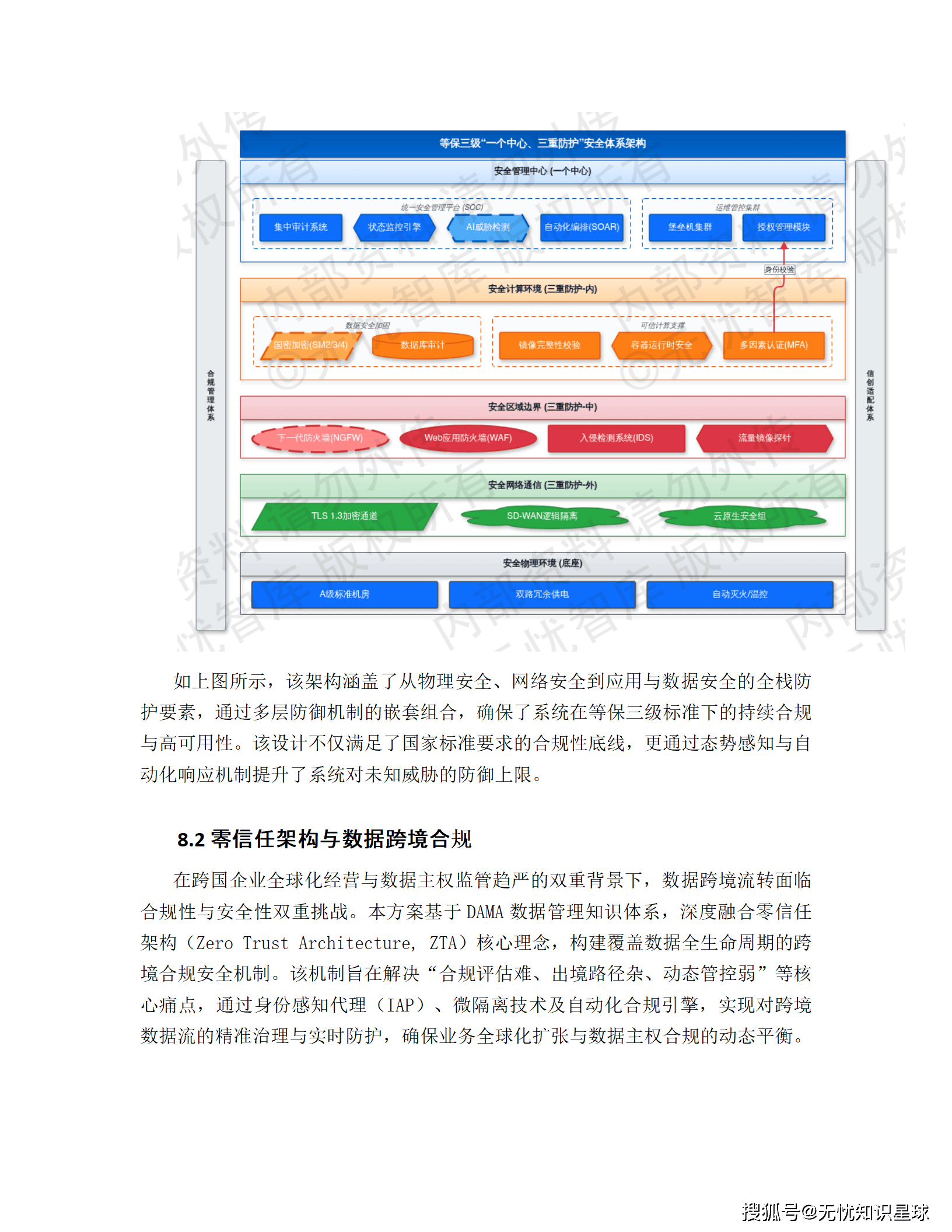
整套安全架构的核心思路是零信任(Zero Trust)------不信任任何默认的内部网络,每次访问都要做身份验证和授权校验。
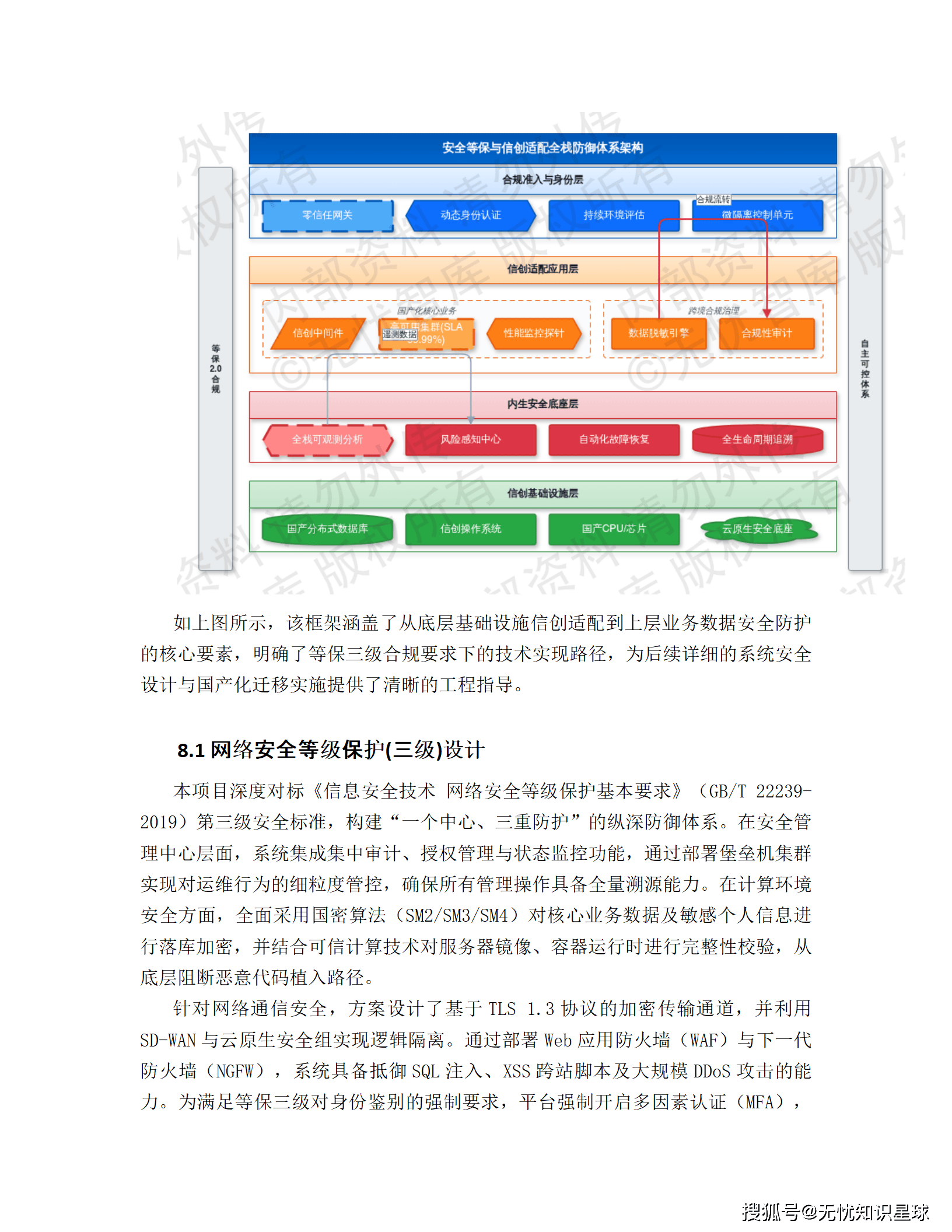
具体落地:所有运维操作经过堡垒机审计,变更操作强制执行双人复核和灰度发布;数据访问层 RBAC/ABAC 双模授权,支持行级过滤和列级脱敏;API 层全部开启 OAuth 2.0 鉴权,敏感字段 AES-256 加密传输;等保 2.0 三级建设标准,涵盖安全物理环境、安全通信网络、安全区域边界、安全计算环境和安全管理中心五个维度。
跨境数据流转这块,不同司法管辖区部署本地化节点,实现数据驻留合规。敏感数据(车辆轨迹、生物识别信息)的采集和存储,严格遵守所在地隐私保护法规,不走全球统一云架构,合规边界在设计阶段就确定了。
7.3 性能指标基准
这些是方案里明确承诺的量化指标,不是定性描述:
八、实施路径:分阶段建设的工程逻辑
方案采用分阶段交付策略,规避大爆炸式上线的风险:
第一阶段(基础底座):完成 Data Fabric 底座建设,核心异构数据源接入,增强型数据目录和主动元数据管理上线,实现全域元数据覆盖率达到 100%。同步完成全球统一主数据管理平台建设,清洗存量脏数据。
第二阶段(业务应用):在底座稳定运行后,叠加敏捷 BI 工作台和供应链控制塔,数据消费层上线。接入全球各区域的 ERP、WMS、TMS,供应链端到端可见性从 65% 提升到 99%。
第三阶段(智能化增强):知识图谱完整上线,AI 驱动的异常检测和 What-if 仿真分析能力投产。防洪合规评估模块接入物联网传感器网络,实现物流节点实时风险监控。
核心量化建设目标:
九、运维体系:上线不是终点
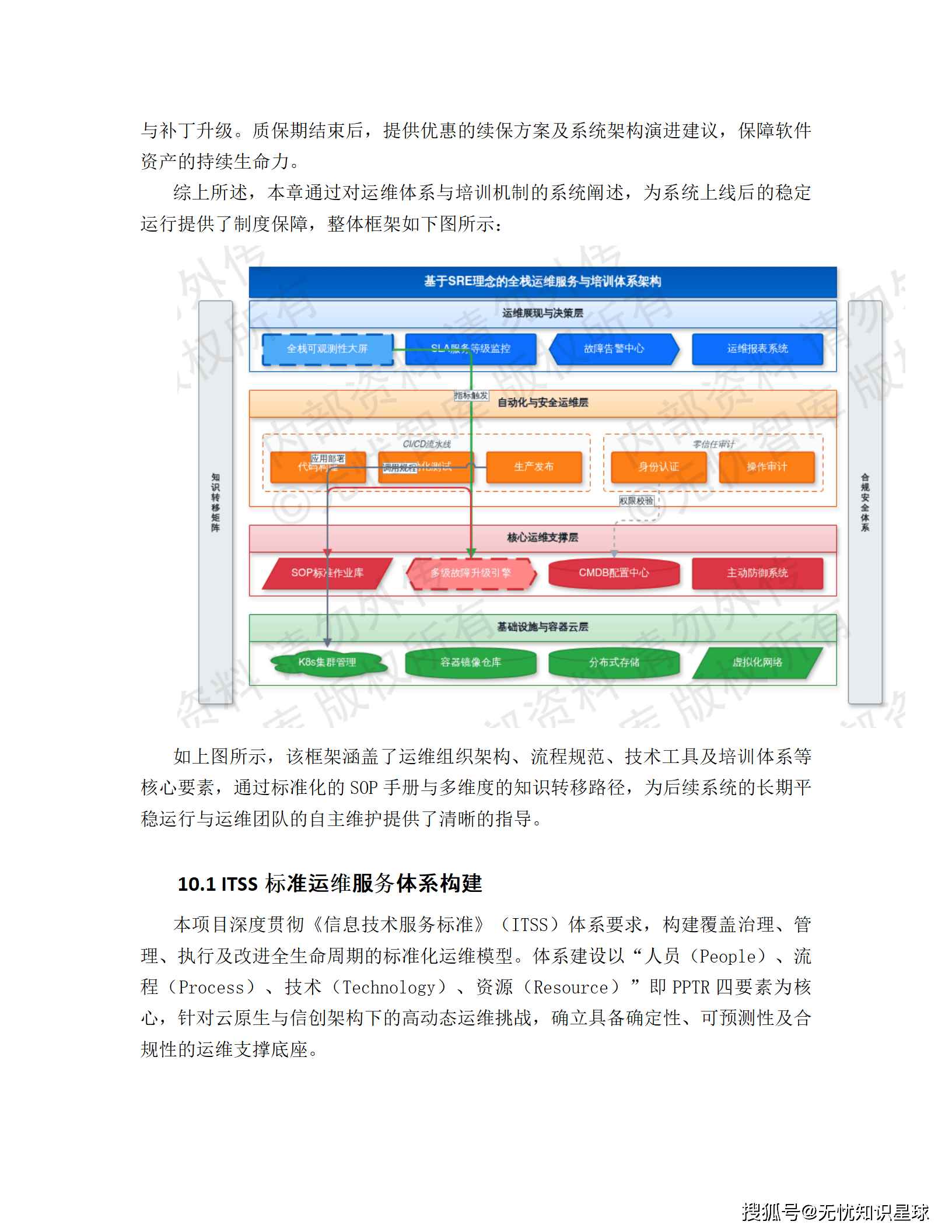
系统上线后的稳定运行依赖一套完整的运维支撑体系,方案按 ITSS(信息技术服务标准)来建设,核心是"PPTR 四要素":人员(People)、流程(Process)、技术(Technology)、资源(Resource)。
运维角色分为服务管理、系统架构、SRE 安全运维、业务保障四个层级,明确技能矩阵和安全红线。流程上覆盖服务台、事件管理、问题管理、CMDB 配置管理、变更管理的数字化集成。Prometheus + Grafana 做全栈可观测性,分布式链路追踪(Trace ID)记录完整请求生命周期。
培训方案分三个维度:管理层侧重系统价值和安全合规审计;技术运维层聚焦 K8s 集群维护、数据库调优、日志分析;业务操作层针对功能模块做实操演练,配套操作手册、视频教程和考核试卷。
质保期内承诺 7×24 小时远程技术支持,P1 级故障响应时长目标 ≤ 15 分钟,系统服务可用率年度保证 ≥ 99.99%。
十、一些工程师视角的思考
读完这份方案,有几点值得单独拿出来说:
关于 Data Fabric 的适用场景
Data Fabric 不是银弹,也不便宜。它最适合的场景是:数据源高度异构、物理搬运合规成本高、业务需要实时响应、组织对"统一数据集中"这件事本身就有阻力。如果你的公司数据源简单、规模小,老老实实做个数仓就够了,不需要搞这么复杂。
关于"去物理搬运"的边界
方案里强调"不搬数据",但这不是绝对的。高频访问的聚合指标还是会物化在 DWS 层,只是边界更清晰了------哪些数据值得物化、哪些适合实时联邦,是个需要权衡的工程决策,不是一刀切。
关于合规模块的优先级
防洪合规评估模块在很多人看来是"锦上添花",但从风险管理的角度,一次物流节点因自然灾害导致的停摆,损失可能远超整个平台的建设成本。把法律条文转化为可执行的数字化规则,这件事值得做。
关于元数据驱动的实际挑战
主动元数据管理理论上很美好,实际落地的最大障碍是业务人员的参与度。算法自动发现和分类只是第一步,业务语义的最终确认还是需要人来做。元数据治理不是纯技术问题,是组织问题。
结语
这份方案展示的不只是一个技术架构,而是一家跨国企业试图在"十五五"数字化转型窗口期,把散落在全球各地的数据资产,从"孤立的静态记录"变成"流动的生产力"的完整工程思路。
Data Fabric 作为一种架构范式,它的价值不在于某个具体的技术组件,而在于那个核心判断:数据的价值不在于它被搬到哪里,而在于它能在被需要的时候,以正确的语义、可信的质量、合规的方式,到达需要它的人手里。
这件事技术上有解,难的是组织、流程、标准三者的对齐------这也是大多数数字化转型项目最后卡住的地方。
本文涉及方案来源于某跨国企业"十五五"全球供应链数据编织平台建设方案,技术细节均基于原始方案内容整理,数据指标均为方案中明确定义的建设目标。