一、 关系抽取概念
关系抽取就是从一段文本中抽取出 (主体,关系,客体) 这样的三元组,用英文表示就是(subject , relation,object)这样的三元组。
具体定义: 给定一个句子 S,其中包含实体 A 和实体 B,预测两个实体间的关系r ∈ R (R代表数据集中所有关系的集合) . 或者说,抽取实体之间的关系是将非结构化的文本信息转化为结构化的信息,最终以关系三元组〈S,P,O〉的形式来描述. 其中,S 和O为主、客实体,P为预测出的两个实体之间的关系。
- 关系抽取两大任务:
- 识别文本中的subject和object (实体识别任务)
- 判断这两个实体属于哪种关系 (关系分类)
- 关系抽取是一个文本分类问题(而之前学习的NER是序列标注问题 ) ,相比于情感分析、新闻分类等其他任务,关系抽取主要有3个特点:
- 领域众多,关系模型构建复杂. 针对一个或者多个限定领域的关系抽取的研究时间较长,研究者投入的精力相对开发领域多,因此方法众多,技术成熟.
- 数据来源广,主要有结构化、半结构化、无结构3类. 结构化数据针对表格文档、数据库等;半结构化数据针对如维基百科、百度百科等;无结构属于纯文本数据.
- 关系种类繁多且复杂,噪音数据无法避免,实体间的关系多样,有一种或者多种关系.
二、关系抽取的常用方法
2.1基于规则方式实现关系抽取
- 基于规则的知识抽取主要还是通过人工定义一些抽取规则,从文本中抽取出三元组信息 (实体-关系-实体) . 重点即是定义规则. 虽然定义规则这种抽取方式看起来有点 low,但却简单实用,很多时候,效果比很多高深的算法还要好一些 (非绝对,具体领域具体分析) .
- 基于规则方法的实现在后续章节介绍
2.2 基于Pipeline流水线方法实现关系抽取(先做NER再做关系抽取)
- Pipeline方法是指在实体识别已经完成的基础上再进行实体之间关系的抽取.
- 基于Pipline流水线方法的实现在后续章节介绍
2.3 基于Joint联合抽取方法实现关系抽取
- Joint联合抽取方法通过修改标注方法和模型结构直接输出文本中包含的(ei ,rk, ej)三元组. Joint联合抽取方法又分为: "参数共享的联合模型" 和 "联合解码的联合模型":
- 基于joint联合抽取方法的实现在后续章节介绍.
2.2和2.3都是使用深度学习的方式
三、 关系抽取任务常见问题
3.1正常关系抽取
- 正常关系 (Normal) 问题:
- 即三元组之间没有重叠, 数据中只有一个实体对及关系
- 如: "《人间》是王菲演唱歌曲"中存在1种关系: (王菲-歌手-人间)

3.2单一实体关系重叠(SEO)
- 单一实体关系重叠问题 (Single Entity Overlap (SEO) )
- 数据中一个实体参与到了多个关系中
- 如: "叶春叙出生于浙江,毕业于黄埔军校"中存在两种关系: (叶春叙-毕业院校-黄埔军校) 、 (叶春叙-出生地-浙江)
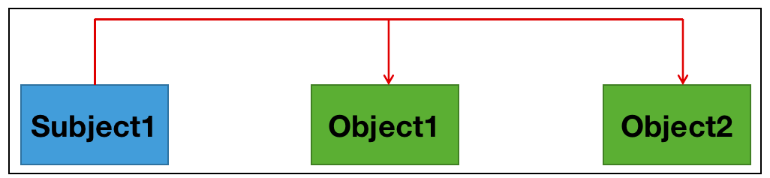
3.3实体对重叠(EPO)
-
实体对重叠(Entity Pair Overlap (EPO)):
- 数据中一个实体对有两种不同的关系类型
- 如: "周星驰导演了《功夫》,并担任男主角"中存在2种关系: (周星驰-演员-《功夫》) 、 (周星驰-导演-《功夫》)
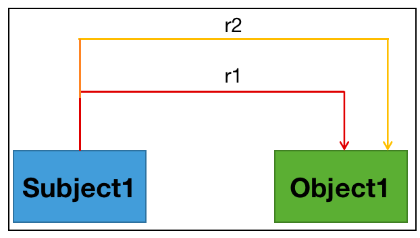
3.4小结
-
正常关系 (Normal) 问题:数据中只有一个实体对及关系
-
单一实体关系重叠问题 (Single Entity Overlap (SEO) ):数据中一个实体参与到了多个关系中
-
实体对重叠(Entity Pair Overlap (EPO)):数据中一个实体对有两种不同的关系类型
四、doccano关系标注
(1)启动doccano
首先,在终端中运行下面的代码来启动WebServer
conda activate docc
# 启动webserver(端口号可以随意设置)
doccano webserver --port 8888然后,打开另一个终端,运行下面的代码启动---任务队列:
conda activate docc
# 启动任务队列
doccano task(2)创建任务
选择Sequence Labeling
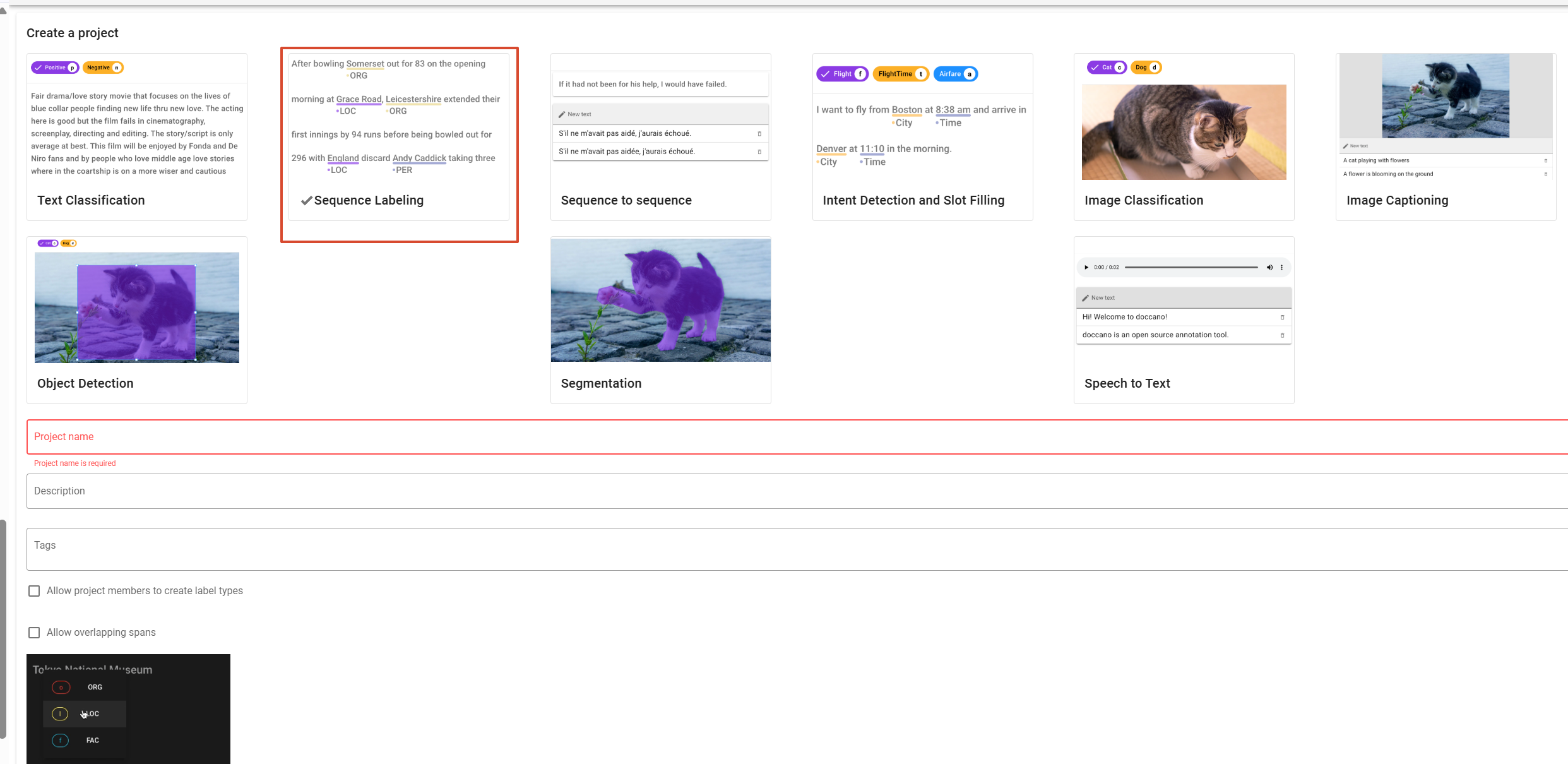
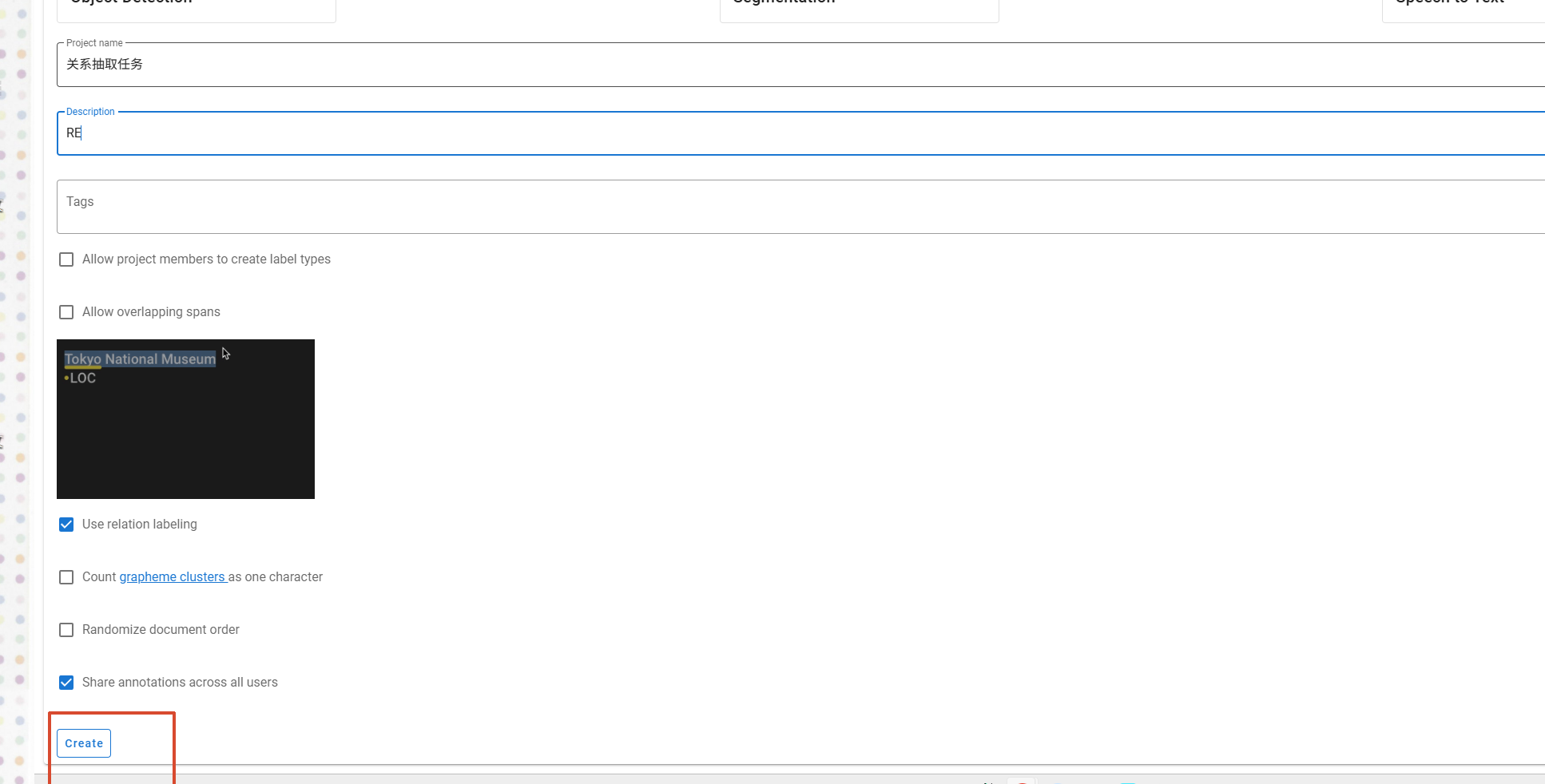
数据导入:
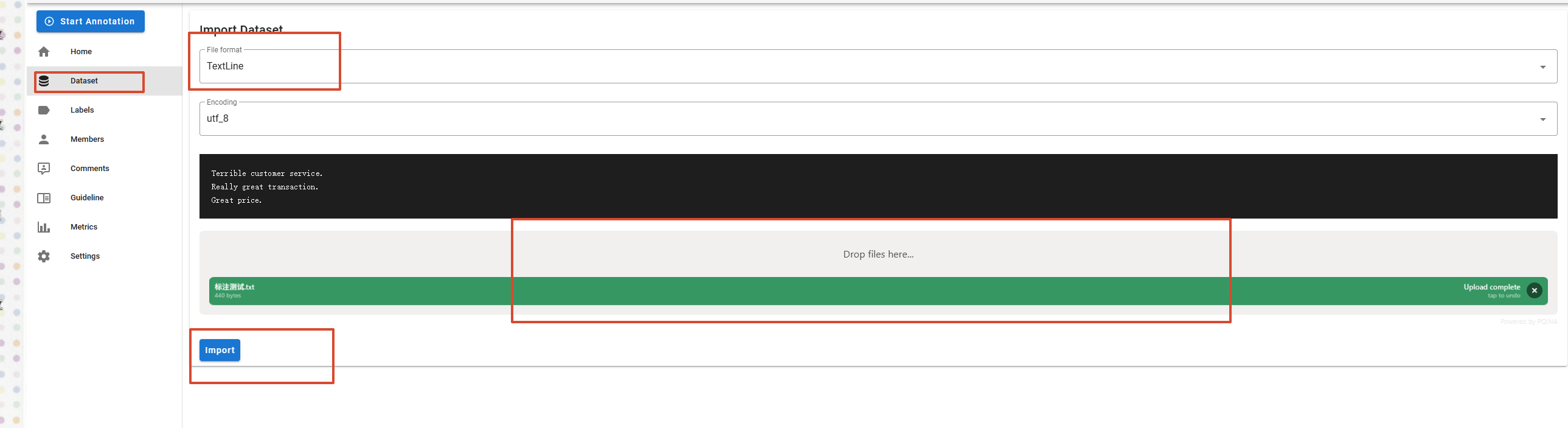
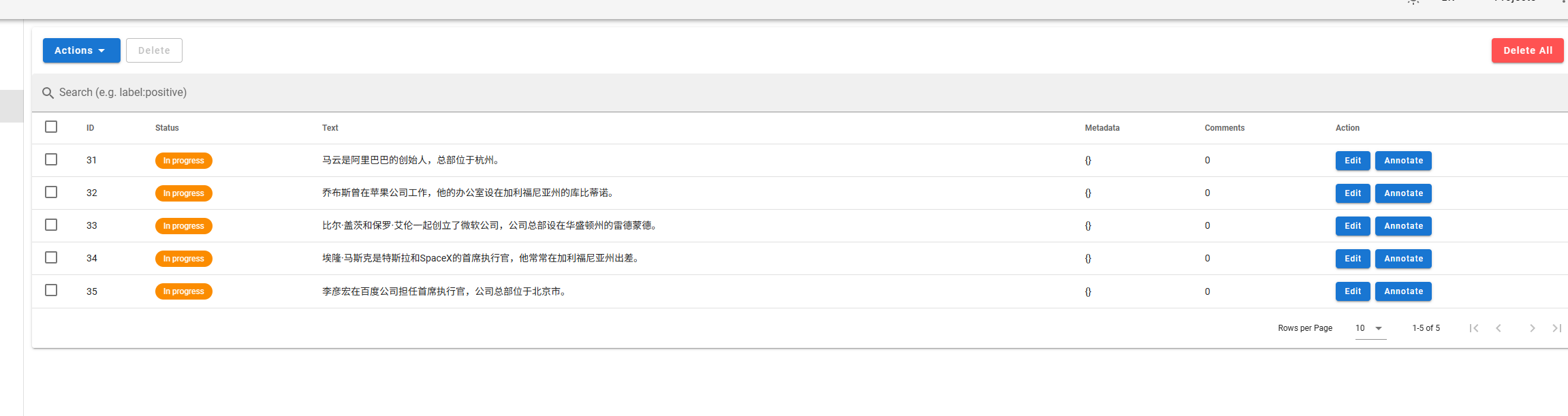
导入成功:
创建标签:
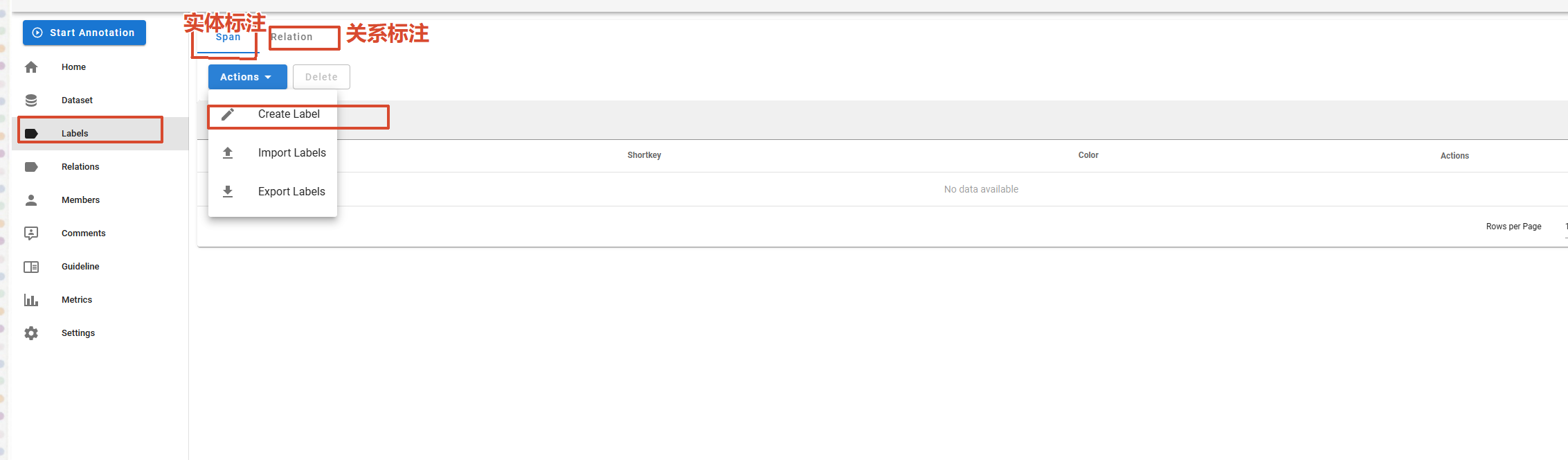
标签创建完成


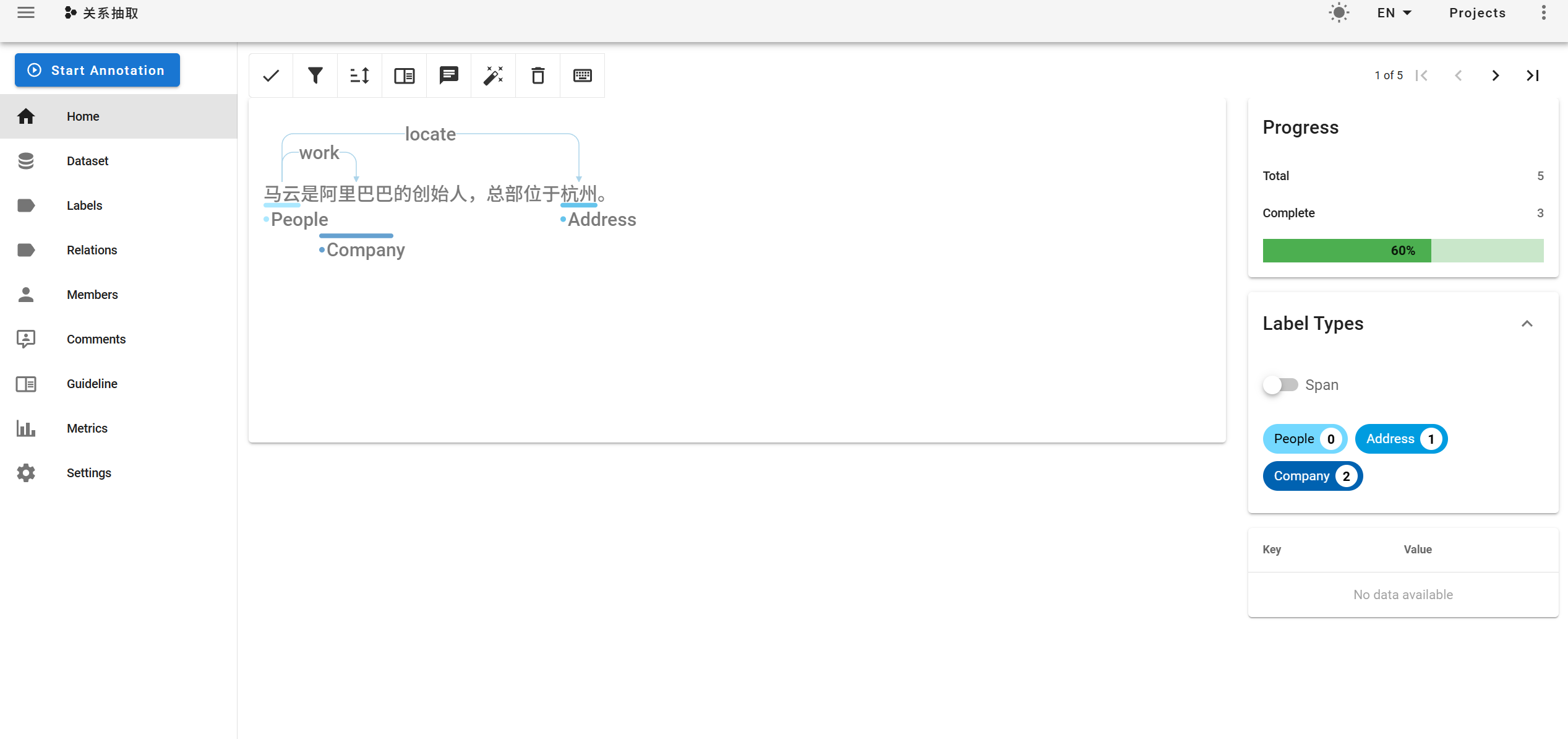
开始打标签:
结果导出:
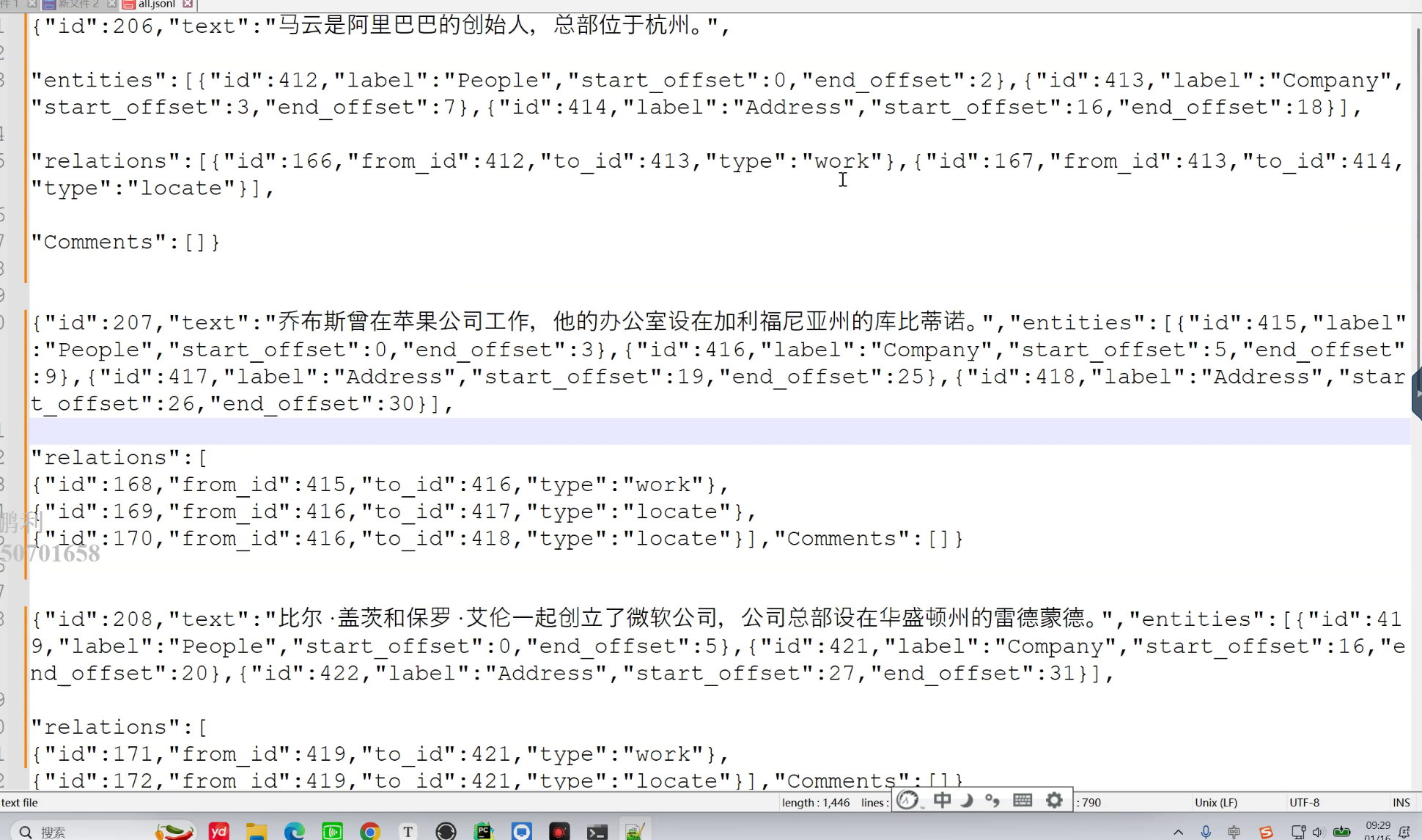
结果分析:
