🤡当牛马的那些事
上一个项目领导让我爬亚马逊iPhone销售信息。第一版爬虫脚本跑了一会,IP被ban。第二版爬虫脚本使用了代理池代理和定时延迟,运行了1天,代理池被标记,直接爬取失败。再之后的版本,添加了多个代理池,跑了两天,最后结果数据格式全变了------标题字段突然没了,价格里掺了广告。
后来我才懂:维护一套爬虫就像在打移动靶。封IP、封号、改页面结构......几百行Python?改一次结构就得重写一半。根本跑不长久。
我发现 Bright Data 把他们的企业级数据采集基础设施封装成了一个 MCP 服务器,换句话说,你不再需要自己维护代理池、浏览器集群、反爬策略,可以像 USB 外设一样直接插进任何 MCP 兼容的 AI 工作流里。没有夸张的成分------就这一步,彻底改变了我做数据采集的方式。这篇博客记录我从踩坑到解脱的全过程,如果你想边看边实践,可以注册BrightData获得 $20 试用额度(附专属折扣码:yinlei20)。
❓为什么多平台采集这么难
和同行聊天最常听到的吐槽就是:"爬虫难的不是写代码,而是持续对抗反爬机制。"这不是矫情,是真实的数据灾难。每多采集一个平台,就多一套维护成本,而且每个平台的反爬手段各不相同,像专门给你挖的坑。
下面是几个主流平台的反爬难点对比:
| 平台 | 主要反爬机制 | DIY 失败率 |
|---|---|---|
| Amazon | 动态渲染、验证码、速率限制 | 极高 |
| TikTok | 签名加密、设备指纹 | 极高 |
| 登录墙、行为检测 | 极高 | |
| eBay / Temu | 地区限制、JS 渲染 | 高 |
| Google SERP | 反爬算法频繁更新 | 高 |
Amazon 会限制同一 IP 的访问频率,超出阈值直接封禁;TikTok 的签名加密让普通 HTTP 请求根本过不去;LinkedIn 更是连看个公开资料都可能被行为检测算法盯上。你写了一个爬虫,上线后提心吊胆,三天两头改 User-Agent、换 IP、加延迟------然后下周网站一更新,一切重来。核心矛盾很简单:每加一个平台 = 多一套维护成本,而工程师的时间是有限的。
🧵架构介绍 --- Bright Data MCP + OpenCode
先解释一下 MCP 是什么。Model Context Protocol 是 Anthropic 推出的开源标准,核心概念极简------就像 USB 是电脑连接外设的标准接口,MCP 是让 AI 模型以统一且安全的方式连接外部资源与工具的"万能转接头"。在我们这个场景里,插上的就是 Bright Data 背后那整套企业级数据采集基础设施。
整个架构流程非常直观:
arduino
用户输入(平台 + 关键词 + URL)
↓
Bright Data MCP Server
↓
┌───────────┼──────────┐
Amazon eBay LinkedIn
↓
结构化 JSON 输出
↓
报表 / 数据库 / LLM为什么这个组合特别有效?OpenCode 的 Skills 机制让你可以把爬取任务封装成可复用的"技能包",一次写好、到处调用。而 Bright Data MCP 服务器提供了超过 60 个专业 Web 工具,涵盖电商、社媒、浏览器自动化等类别,自动处理 IP 轮换、验证码绕过、JavaScript 渲染这些最让人头疼的部分。两者结合,等于用自然语言驱动一条企业级的 AI 数据采集流水线------你只需要描述想爬什么,剩下的全自动。
🎫前置准备
动手之前,准备好这几样东西:
- Bright Data 账号 :免费试用有20美元额度,足够跑大量测试。注册链接: 注册 Bright Data,免费获得 $20 试用额度
- OpenCode :支持 MCP 的 AI 编码助手,我用的是桌面版,在这下载
- Bright Data MCP Server API Token:登录控制台后在账户设置里获取
- 基本的命令行操作经验:会复制粘贴配置就行
整个过程不需要写一行爬虫代码,也完全不用操心代理、验证码、JS 渲染这些破事。
🔨实战教程 --- 手把手操作
Step 1:配置 Bright Data MCP Server
-
登录 Bright Data 控制台,进入账户设置页面
-
找到 API Token 区域,复制你的 token,格式类似
2dceb1-aa0123456-789a-bcdef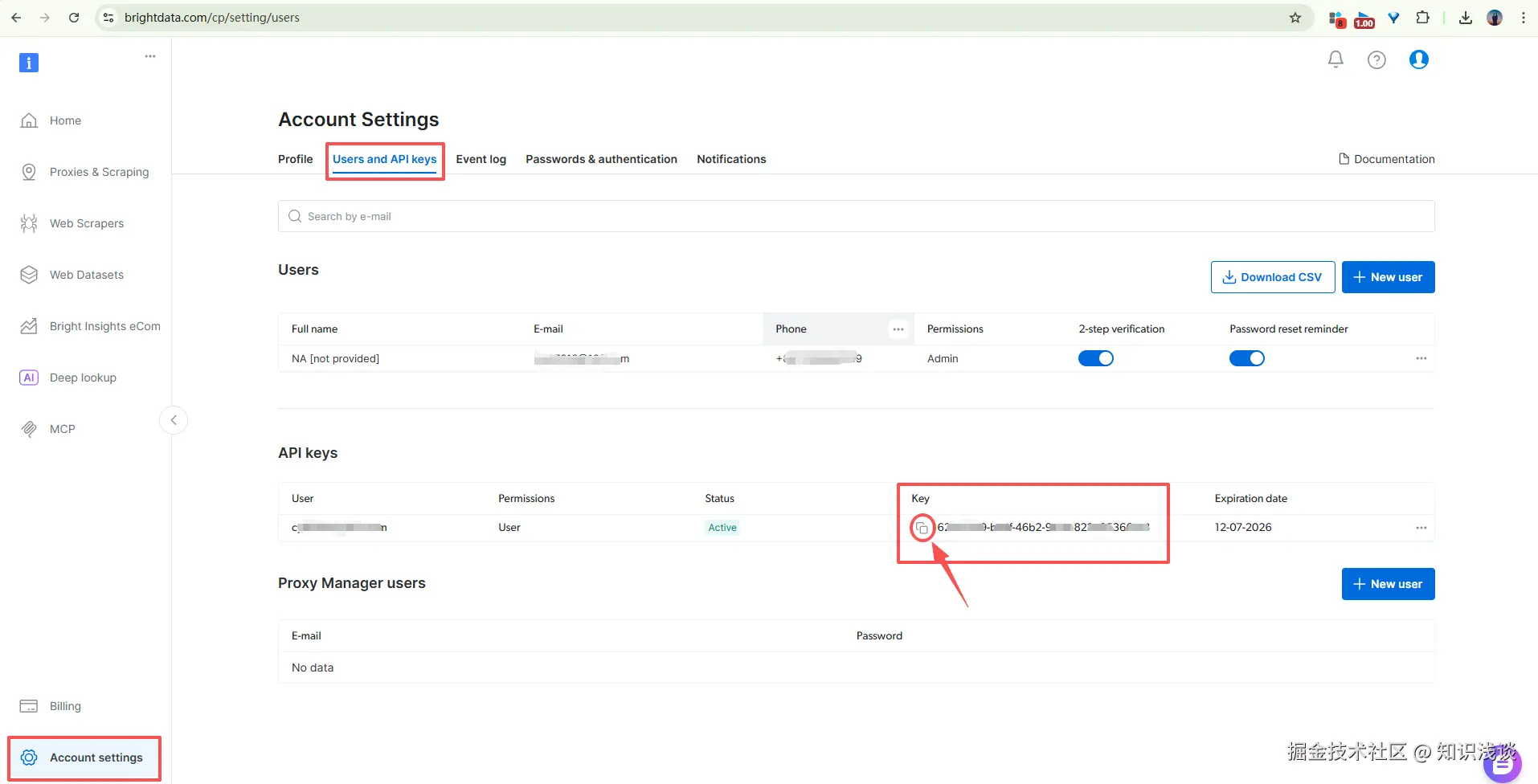
-
记下 MCP 服务器端点:
https://mcp.brightdata.com/sse?token=YOUR_API_TOKEN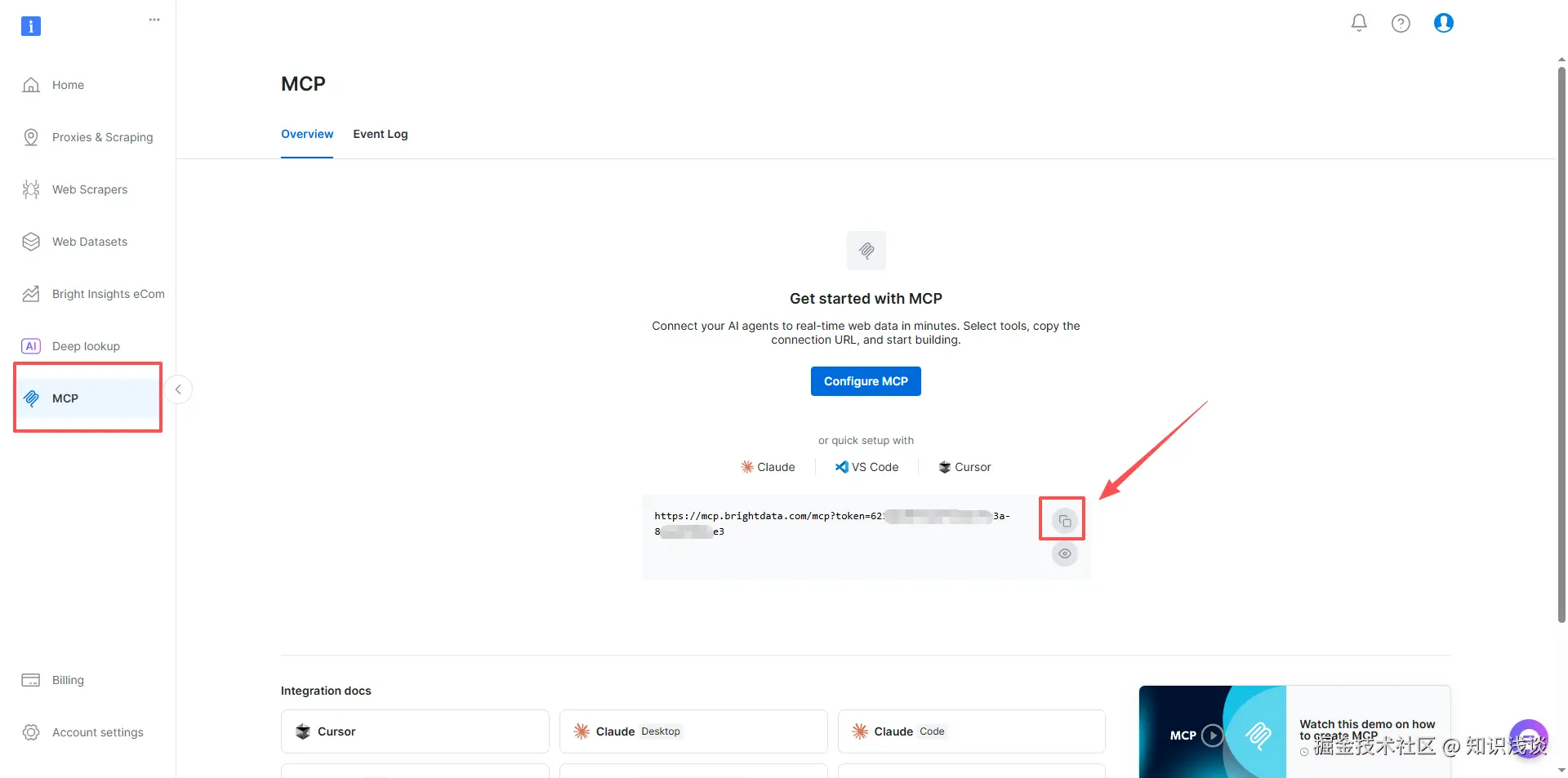
在 OpenCode 中配置 MCP 服务器,Windows电脑只需要在 C:\Users\Administrator\.config\opencode\opencode.json 中添加: 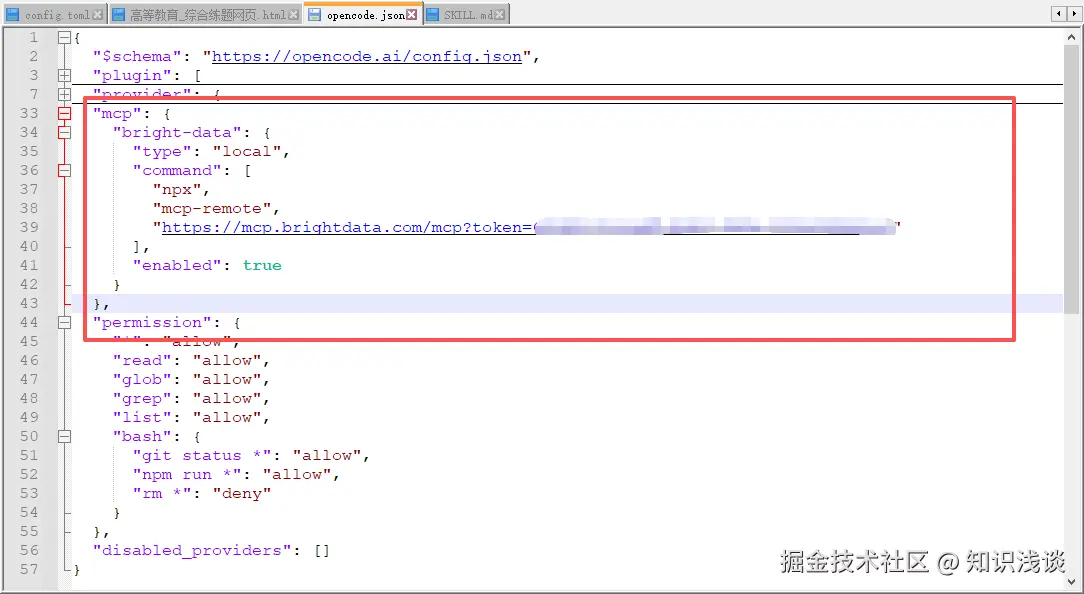
json
"mcp": {
"bright-data": {
"type": "local",
"command": [
"npx",
"mcp-remote",
"https://mcp.brightdata.com/mcp?token=YOUR_BRIGHTDATA_API_TOKEN"
],
"enabled": true
}
}把 YOUR_BRIGHTDATA_API_TOKEN 替换成你刚才复制的真实 token,保存文件即可。
Step 2:在 OpenCode 中验证连接
重启 OpenCode 桌面应用,点击右上角 状态→ MCP,你应该能看到 bright-data 服务器显示为"已连接"状态。 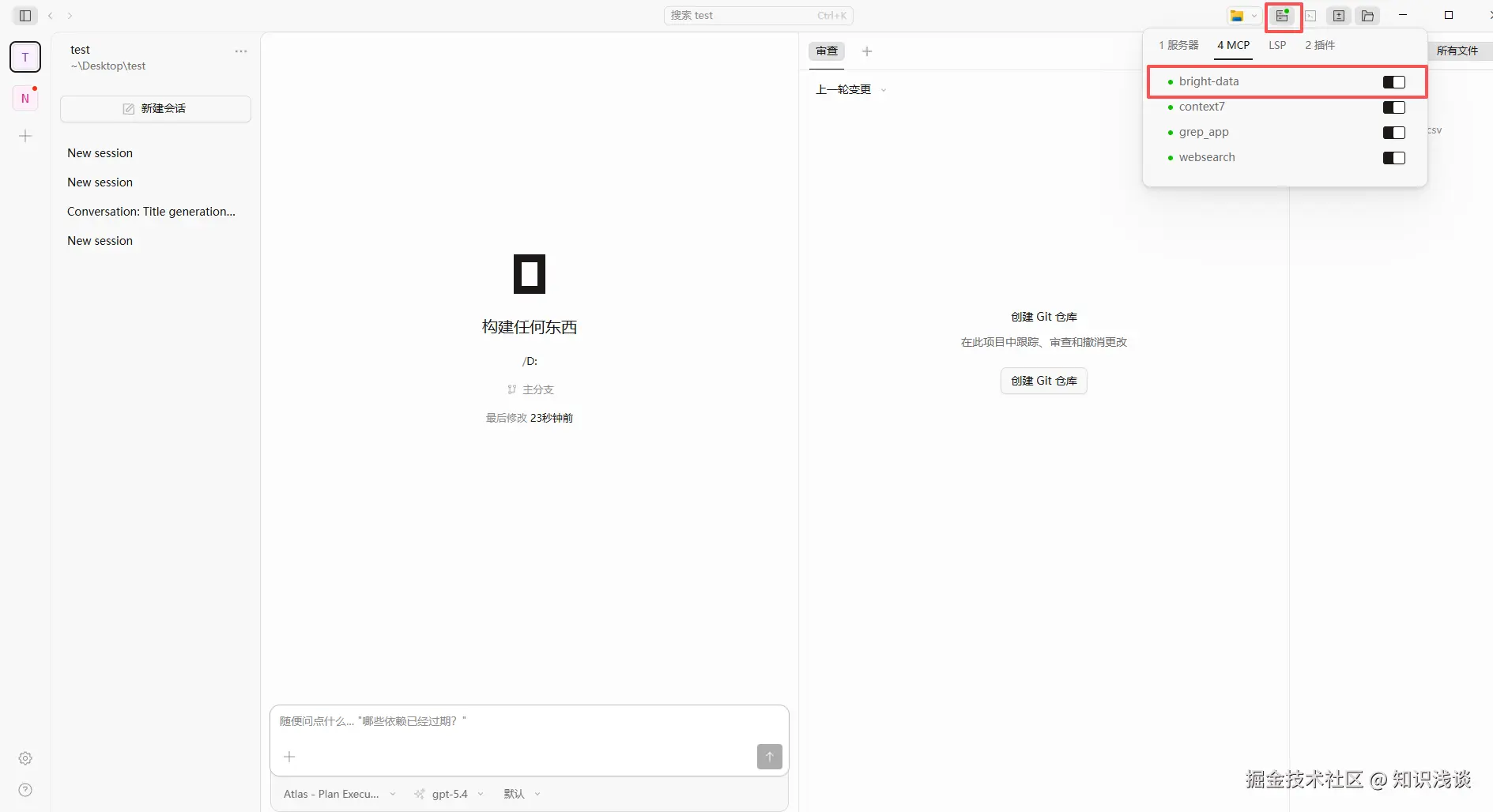 更直接的方式:在 OpenCode 的对话窗口输入"帮我列出 Bright Data MCP 可用的工具",如果返回一个长长的工具列表------恭喜,连接成功。Bright Data MCP 暴露了 65+ 个工具,涵盖搜索、电商数据提取、社交媒体爬取、浏览器自动化等场景。
更直接的方式:在 OpenCode 的对话窗口输入"帮我列出 Bright Data MCP 可用的工具",如果返回一个长长的工具列表------恭喜,连接成功。Bright Data MCP 暴露了 65+ 个工具,涵盖搜索、电商数据提取、社交媒体爬取、浏览器自动化等场景。
Step 3:写一个的Bright Data采集 Skill
我已经写好了,下滑就能下载直接用
Skill 本质上是一个 Markdown 文件,定义了一项任务的名称、描述以及具体执行步骤。我们创建一个价格监控 Skill,命名为 SKILL.md,内容框架如下:SKILL.md文件放到 你的项目根目录/.opencode/skills/bright-data-price-monitor 目录下,OpenCode 重启会自动发现并加载它。 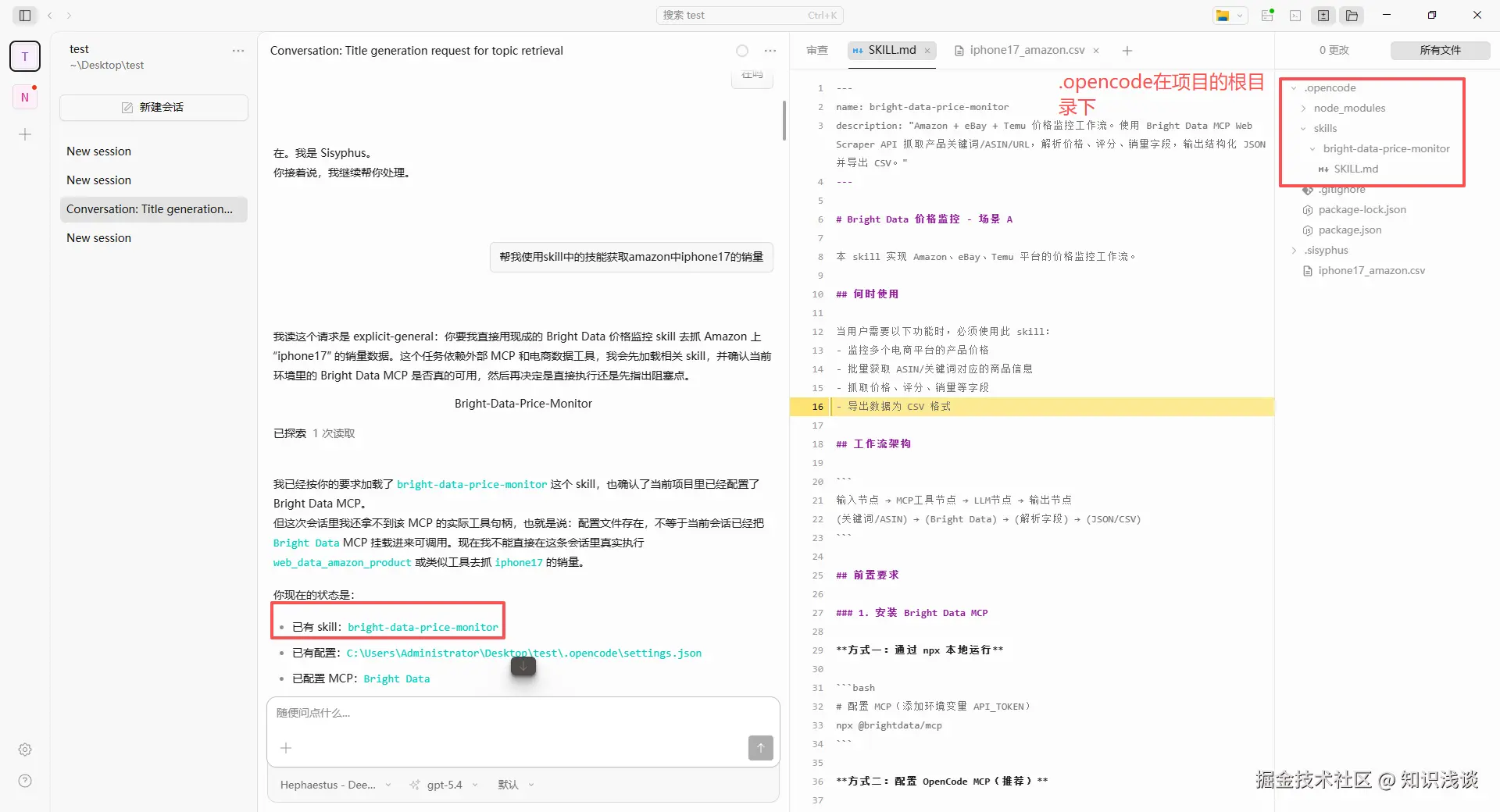 之后你只需要在对话中说"帮我使用skill中的技能获取amazon中iphone17的相关信息",AI 就会按这个流程执行。
之后你只需要在对话中说"帮我使用skill中的技能获取amazon中iphone17的相关信息",AI 就会按这个流程执行。
Step 4:测试与基准测试
这是实测对比数据:
| 指标 | DIY 方案 | Bright Data MCP + OpenCode |
|---|---|---|
| 封锁率 | 超过 60% | 低于 1% |
| 数据成功率 | 约 40% | 超过 99% |
| 新平台接入时间 | 1 至 2 周 | 低于 30 分钟 |
| 月均维护时间 | 超过 20 小时 | 低于 2 小时 |
| 成本(1万条数据) | 工程时间成本极高 | 按成功付费,成本可控 |
Bright Data 的 Web Scraper API 覆盖 44 个热门领域,包括 Amazon、Walmart、eBay、LinkedIn、Instagram、TikTok 等,一次集成就能搞定所有平台。SERP API 则支持 Google、Bing、DuckDuckGo、Yandex 等搜索引擎,带地理定位和高级自定义选项。最让我安心的是,Bright Data 在独立基准测试中取得了 98.44% 的平均成功率,为所有受测服务商中最高。
🎉免费分享我写的SKILL-拿走就能用
我把这套配置打包好了,你可以直接下载使用。
OpenCode Skill 文件
- bright-data-price-monitor/SKILL.md ------ 价格监控 Skill 文件
使用方式:
- 安装BrightData MCP并替换文件中的
YOUR_API_TOKEN为你自己的 Bright Data API Token - 将下载的
SKILL.md复制到你的项目根目录/.opencode/skills/bright-data-price-monitor目录 - 根据需要修改目标 URL 或关键词
- 在 OpenCode 对话中直接调用这个 Skill
对话示例
配置好之后,在 OpenCode 中输入:
"帮我使用skill中的技能获取amazon中iphone17的相关信息"
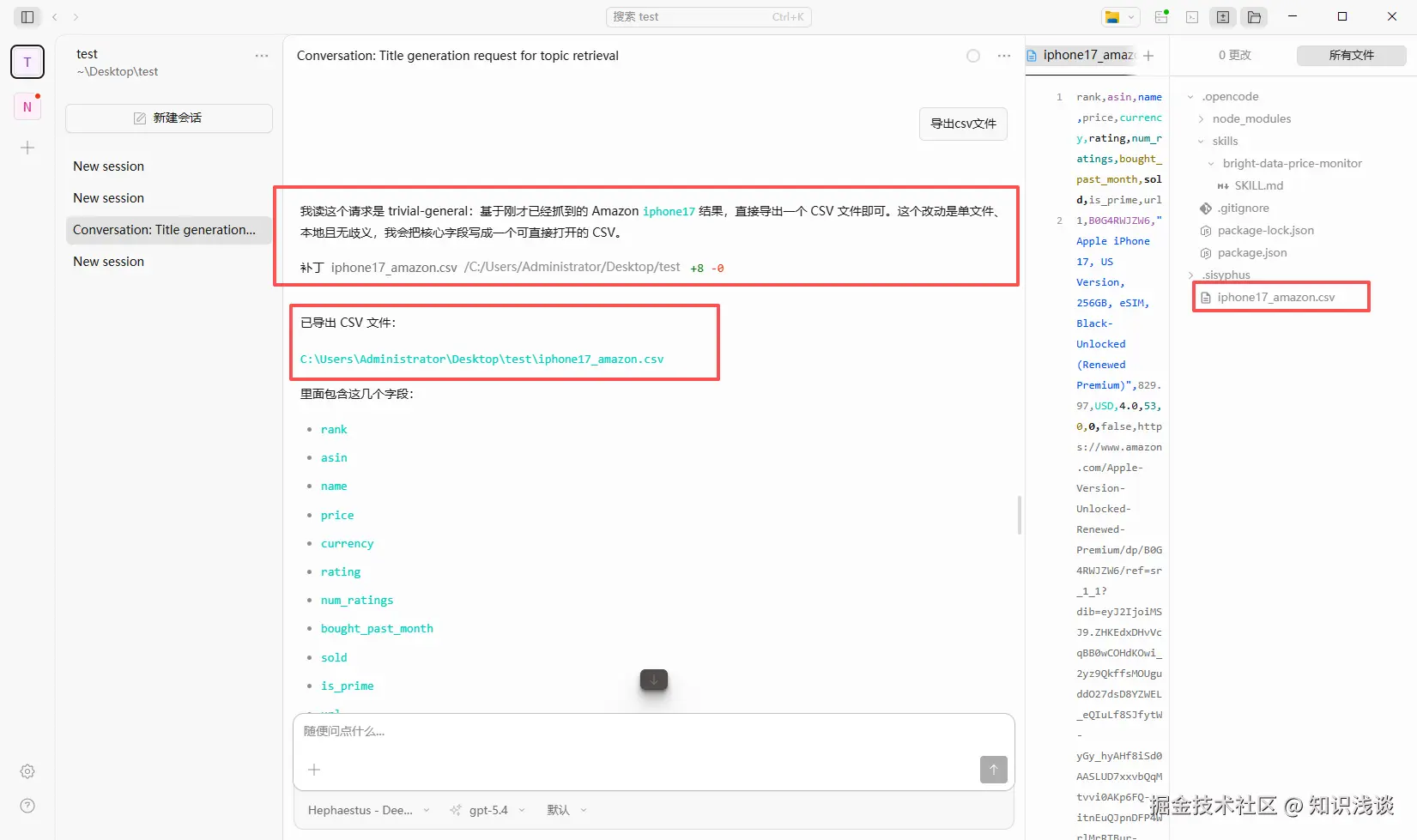
OpenCode 会自动调用 Bright Data MCP 的电商工具,返回结构化的价格对比数据。整个过程从输入到拿到结果不超过 30 秒。 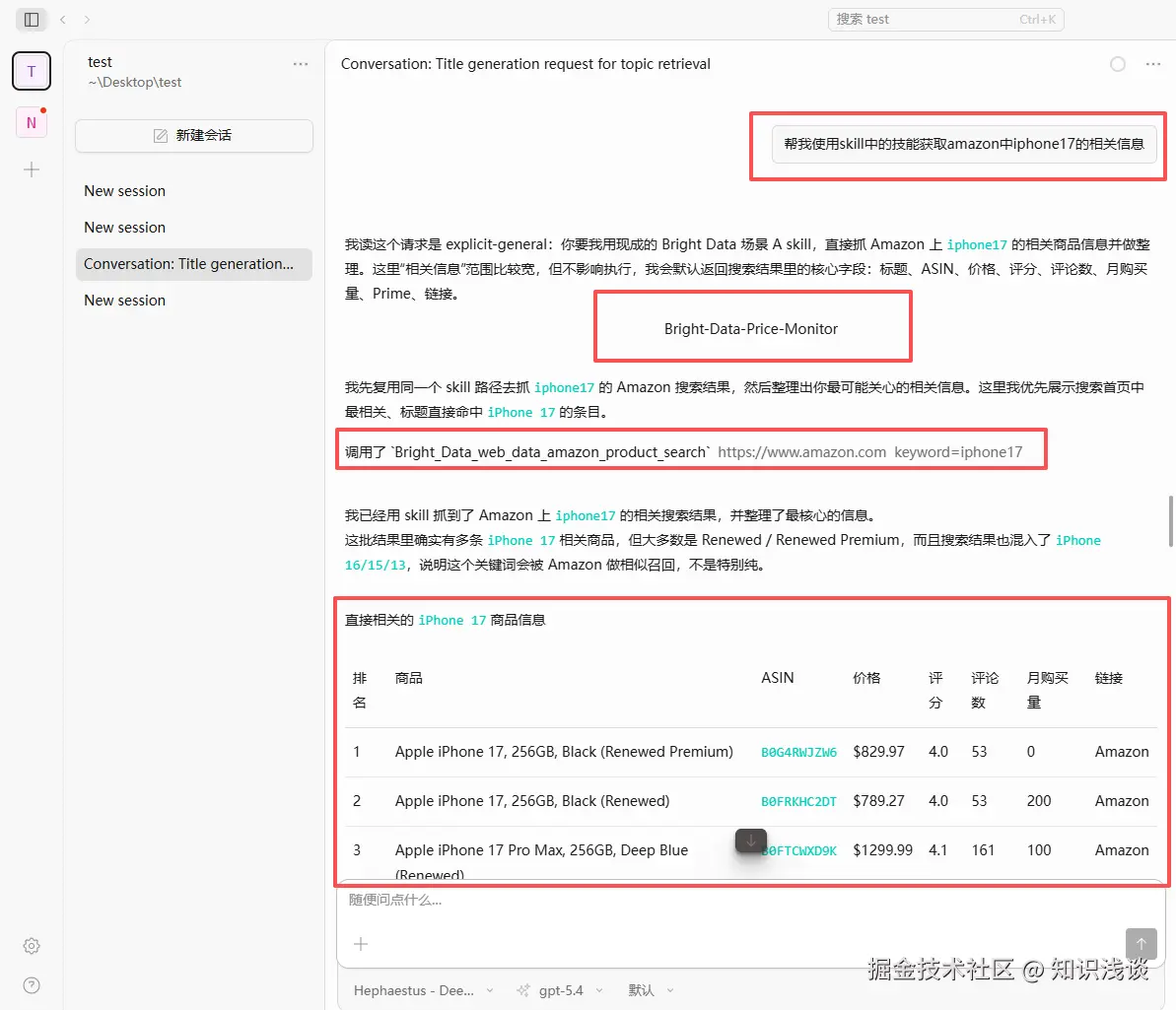
🎲成本分析
很多朋友问我:"用第三方服务是不是比自己写爬虫贵?"咱们算一笔实账。
| 方案 | 前期投入 | 月均维护 | 10 万条数据成本 |
|---|---|---|---|
| 自建爬虫 | 2 至 4 周工程时间 | 超过 20 小时/月 | 工程成本难以量化 |
| Bright Data MCP + OpenCode | 不到 1 天配置 | 低于 2 小时/月 | 按成功采集付费, 0.001−0.05/页 |
Bright Data 的定价核心逻辑是"按成功采集付费",封了不收费、验证码不收费、失败不收费。免费版每月 5,000 次请求,足够个人开发者和日常 AI 工作流使用。最大的隐性成本其实不是服务费,而是工程师的宝贵时间------花两周搭代理轮换、每天被报警吵醒修爬虫,这些时间成本远比服务费高得多。
总结
回顾这一路从踩坑到解脱的经历,三个核心收获:
- 一套 OpenCode Skill 替代 7 套独立爬虫 ------ 不用再为每个平台单独写代码和维护
- Bright Data MCP 处理所有封锁问题 ------ 代理、验证码、JS 渲染、设备指纹,全部自动搞定
- 模板和 Skill 直接拿走用 ------ 不用从零开始,复制粘贴就能跑起来
如果你也在被爬虫封锁折磨,不妨试试这套方案。通过 注册 Bright Data,免费获得 $20 试用额度 ,下载本文的 Skill 模板,5 分钟内搭建你的多平台数据采集流水线。只为成功采集的数据付费------不成功不花钱,这条规则对开发者来说足够公平。
如果你也在被爬虫封锁折磨,不妨试试这套方案。通过 专属链接(粉丝福利折扣码:yinlei20) 免费注册 Bright Data,获得 $20 试用额度。下载本文的 Skill 模板,5 分钟内搭建你的多平台数据采集流水线。只为成功采集的数据付费------不成功不花钱,这条规则对开发者来说足够公平。