一、数据库核心概念深度解析
1. 数据
定义:数据是描述事物的符号记录,是数据库的核心存储单元,可涵盖数字、文本、图像、音频、视频等多种形式,能被计算机系统识别、存储并通过程序进行加工处理。
分类:
- 结构化数据:具有固定格式和长度,如表格中的数值、字符串(例:学生表中的学号、成绩)。
- 半结构化数据:具备一定结构但不严格,如 JSON、XML 文件。
- 非结构化数据:无固定结构,如图片、视频、音频文件。
2. 数据库(Database)
定义 :长期存储在计算机存储介质(硬盘、固态硬盘、U 盘等)上,由数据库管理系统(DBMS)统一管理的结构化、可共享的数据集集合。
核心特征:
- 数据结构化:数据不再孤立存储,而是按特定模型组织(如关系模型)。
- 数据共享性:多个用户 / 程序可同时访问数据,且能保证数据一致性。
- 低冗余度:避免数据重复存储,节省存储空间。
- 数据独立性:数据的存储结构和逻辑结构分离,修改存储结构不影响应用程序。
- 可控性:通过权限管理、备份恢复机制保障数据安全。
3. 数据库管理系统(DBMS)
定义:位于用户应用程序与操作系统之间的系统软件,负责对数据库进行统一管理与控制,是数据库系统的核心。
核心功能:
- 数据定义:支持用户通过 SQL 语句创建、修改、删除数据库及表结构(
CREATE/ALTER/DROP)。 - 数据操作:实现数据的增删改查(
INSERT/DELETE/UPDATE/SELECT)。 - 数据控制:管理用户权限、保障数据安全(授权、回收权限)。
- 数据维护:提供数据备份、恢复、索引优化、日志管理等功能。常见 DBMS 类型:
- 关系型 DBMS:基于关系模型(二维表),如 Oracle、DB2、SQL Server、MySQL、SQLite。
- 非关系型 DBMS:基于键值、文档、列族等模型,如 Redis、MongoDB、Cassandra(适用于嵌入式场景的多为轻量级关系型)。
二、数据库体系分类与选型
1. 按应用规模分类
| 类型 | 代表产品 | 核心特点 | 适用场景 |
|---|---|---|---|
| 大型数据库 | Oracle、IBM DB2 | 支持海量数据(TB/PB 级)、高并发、复杂事务处理、跨平台、企业级架构 | 银行、金融、大型企业核心系统 |
| 中型数据库 | MySQL、Microsoft SQL Server | 兼顾性能与易用性,支持中小型企业业务,开源 / 商业版可选,适配多操作系统 | 电商、政务、中小企业管理系统 |
| 小型数据库 | SQLite、Berkeley DB | 体积极小、无需独立服务、嵌入式集成度高、资源占用低 | 嵌入式设备、移动应用、单机程序 |
2. 嵌入式数据库核心选型对比
嵌入式场景需兼顾资源占用、响应速度、集成难度,以下为主流选型深度对比:
| 数据库名称 | 开发 / 归属方 | 核心特性 | 嵌入式适配性 | 适用场景 |
|---|---|---|---|---|
| SQLite | D. Richard Hipp | 开源 C 语言实现,零配置、单文件存储、支持 ACID 事务、兼容 SQL92 标准,体积仅 250KB | 极高(轻量级、无依赖) | 移动 APP、嵌入式设备、单机程序 |
| Firebird | 开源社区 | 关系型、支持存储过程 / 触发器、多版本并发控制(MVCC),体积稍大 | 中(需一定资源) | 功能复杂的嵌入式系统、小型服务器 |
| Berkeley DB | Sleepycat Software(Oracle) | 键值存储模型、无服务器架构、直接链接应用程序,支持高并发读写 | 极高(极简架构) | 缓存系统、配置存储、轻量数据存取 |
| eXtremeDB | McObject | 内存数据库、运行效率极高、支持实时事务,可定制化部署 | 高(高性能需求) | 工业控制、实时嵌入式系统、车载设备 |
三、SQLite 核心基础
1. SQLite 核心特性详解
SQLite 是嵌入式关系型数据库的标杆,其特性远超基础认知,具体如下:
- 零配置部署:无需安装服务、无需启动后台进程,直接调用 API 即可使用,彻底解决嵌入式设备 "部署复杂" 痛点。
- 单文件存储:整个数据库(表、索引、视图、触发器)封装为单个磁盘文件,便于迁移、备份(直接复制文件即可完成备份)。
- 跨平台共享:数据库文件支持大端 / 小端字节序机器间自由共享,适配嵌入式设备多架构(ARM、x86、RISC-V)部署。
- 轻量高效 :
- 源码约 3 万行 C 代码,编译后仅 250KB~500KB,内存占用极低。
- 数据操作速度优于多数同类数据库,单表查询、增删改响应时间达微秒级。
- 完整事务支持:严格遵循 ACID(原子性、一致性、隔离性、持久性)原则,支持事务回滚、崩溃恢复,保障数据安全。
- 全 SQL 兼容:支持绝大多数 SQL92 标准,包括索引、触发器、视图、存储过程(简化版),降低开发迁移成本。
- 容量上限 :单数据库文件最大支持2TB存储,满足绝大多数嵌入式场景数据需求。
2. SQLite 与传统数据库的核心差异
| 对比维度 | SQLite | 传统数据库(MySQL/Oracle) |
|---|---|---|
| 架构模式 | 嵌入式库(直接链接应用程序) | 客户端 - 服务器模式(独立服务进程) |
| 部署复杂度 | 零配置,无依赖 | 需安装、配置、启动服务 |
| 资源占用 | 极低(内存 / CPU / 磁盘) | 较高(适配高并发、海量数据) |
| 并发能力 | 单写多读(写操作独占锁) | 多读写并发(MVCC / 锁机制) |
| 适用场景 | 单机 / 嵌入式 / 移动应用 | 企业级、高并发、分布式系统 |
3. SQLite 安装与环境配置(全平台)
(1)Linux 系统安装
-
在线安装(Ubuntu/Debian) :
# 更新软件源 sudo apt update # 安装sqlite3及开发库(含头文件,用于C语言编程) sudo apt-get install sqlite3 libsqlite3-dev -
在线安装(CentOS/RHEL) :
sudo yum install sqlite3 sqlite3-devel -
本地安装 :
-
从 SQLite 官网(https://www.sqlite.org/download.html)下载对应架构的源码包(如
sqlite-autoconf-3450100.tar.gz)。 -
解压并编译安装:
tar -zxvf sqlite-autoconf-3450100.tar.gz cd sqlite-autoconf-3450100 ./configure --prefix=/usr/local/sqlite make && sudo make install -
配置环境变量(永久生效):
echo "export PATH=/usr/local/sqlite/bin:$PATH" >> /etc/profile source /etc/profile
-
(2)Windows 系统安装
- 官网下载预编译包(
sqlite-dll-win32-x86-3450100.zip/sqlite-dll-win64-x64-3450100.zip)。 - 解压后将
sqlite3.exe添加到系统环境变量(Path),即可在命令行直接使用。 - 开发集成:将
sqlite3.lib添加到项目库目录,sqlite3.h添加到头文件目录。
(3)嵌入式设备(ARM / 嵌入式 Linux)
- 交叉编译源码:指定交叉编译器(如
arm-linux-gnueabihf-gcc)编译生成适配设备架构的sqlite3可执行文件和库文件。 - 移植到设备:通过 NFS/SCP 将可执行文件拷贝到设备
/usr/bin目录,库文件拷贝到/lib目录。
4. SQLite3 核心命令
(1)系统命令(.开头)
| 命令 | 功能描述 |
|---|---|
.help |
查看所有系统命令帮助文档 |
.quit / .exit |
退出 SQLite3 命令行模式 |
.schema [表名] |
查看指定表的创建语句(含字段类型、约束);无参数则查看全库表结构 |
.databases |
查看当前打开的所有数据库(显示数据库名、存储路径) |
.table |
列出当前数据库下所有数据表 |
.mode [模式] |
设置数据输出模式(column列模式、list列表模式、jsonJSON 模式) |
.header on/off |
开启 / 关闭查询结果的表头显示(默认关闭) |
.nullvalue [字符] |
设置 NULL 值的显示字符(默认空,例:.nullvalue NULL) |
.backup [库名] [文件] |
备份整个数据库到指定文件 |
.restore [库名] [文件] |
从指定文件恢复数据库 |
(2)SQL 核心命令(标准 SQL)
基本的 sql 命令,不以 . 开头,但是都要 ; 结尾
创建一张数据库的表 stu
create table stu(id Integer,name char,score Integer);
插入一条记录
insert into stu values(1001,'zhangsan',80);
插入部分字段记录
insert into stu(name,score) values(1002,'lisi');
查询所有记录
select *from stu;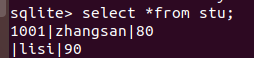
查询数据库部分内容字段
select name,score from stu;
根据属性查询
select * from stu where score=80;
删除一条记录
delete from stu where id=1001;
更新一条记录
update stu set name='wangwu' where score=90;
添加一列
alter table stu add column address char;
删除一列
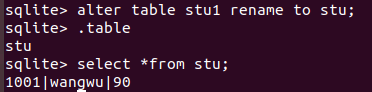
1.创建一张表(提取字段)
create table stu1 as select id,name,score from stu;
2.删除原有表
drop table stu;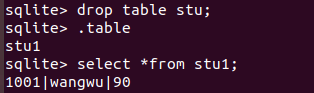
3.将新的表的名字改成原有的表名字
alter table stu1 rename to stu;