我们详细拆解了 RAG(检索增强生成)的完整工作流程,并探讨了如何应对大模型的"幻觉"痛点 ,我们频繁提及了一个核心组件------**向量数据库(Vector Database)。**这时候,很多同学一定会产生一个疑问:
"MySQL 作为经久不衰的'数据库之王',几乎包揽了企业核心业务的各类增删改查。既然 RAG 的底层也是'检索',那我能不能直接在 MySQL 里建个表,把文档的向量存进去,用传统的 SQL 语句去做 AI 检索呢?"
答案是:在小规模、玩具级的 Demo 项目中可以尝试;但在真正的企业级、商业化 AI 项目中,MySQL 根本无法胜任。
今天这篇博客,我们就从底层数据结构、数学计算特征以及系统架构等多个维度,深度剖析为什么 MySQL 不适合做 AI 检索,以及为什么 AI 时代必须引入专用的向量数据库。
1. 维度灾难:高维特征与标量数据的底层冲突
要理解这个问题,首先要看二者处理的数据对象有什么本质区别。
-
MySQL 处理的是"标量数据"(Scalar Data): 如年龄(Int)、名字(Varchar)、订单时间(Datetime)等。这些数据是一维的,在数轴上可以通过简单的"大于、小于、等于"来进行绝对的顺序排列。
AI 检索处理的是"高维特征向量"(High-Dimensional Vectors): 无论是文本、图片还是语音,经过 Embedding 模型转化后,都会变成一串稠密的浮点数 。这些向量的维度通常高达 768 维甚至 1536 维 。
在高维空间中,传统的"大小"概念失效了。AI 检索不再寻找"完全相等"的值,而是寻找在数学空间中"距离最近、语义最相似"的邻居。这种高维连续空间的数学特性,导致了关系型数据库在底层逻辑上难以兼容。
2. 索引机制的决裂:B+ 树面对高维空间的彻底瘫痪
MySQL 之所以能够实现百万、千万级数据的毫秒级精确查询,核心功臣是其聚簇索引所采用的 B+ 树(B+ Tree) 数据结构。
B+ 树的一维局限性
B+ 树是一种多路平衡查找树。它要求索引的关键码必须是可以排序的一维标量。在查询时,它通过对一维数值进行二分式的分支判断,将时间复杂度降低到 O(\\log N)。
然而,当面对 1536 维的向量时,B+ 树根本不知道该如何建树。你无法定义向量 A 是否"大于"向量 B。哪怕你强行对向量的某一个维度建树,它也完全无法体现多维空间下的整体语义相似度。
MySQL 面对向量检索的代价:O(N) 全表扫描
在没有有效索引的情况下,如果你在 MySQL 中存储了 100 万条向量,并试图找出与用户问题最相似的 Top-K 个结果,MySQL 唯一的办法就是进行全表扫描(Full Table Scan)。
它需要把这 100 万条记录逐一从磁盘加载到内存中,用 CPU 将用户问题的向量与这 100 万个向量挨个做一遍高维数学计算,最后进行全局排序。在长文中我们提到,向量检索要求低延迟 ;而 MySQL 面对 100 万条数据的全表暴力检索,延迟通常会飙升到数秒甚至数十秒,这在实时交互的 AI 项目中是完全不可接受的。
专用向量数据库的解法:ANN 近似最近邻索引
专用的向量数据库不采用 B+ 树,而是采用专门针对高维空间设计的 ANN(Approximate Nearest Neighbor,近似最近邻) 索引算法 。 例如最常用的 HNSW(分层导航小世界图) ,它把向量作为图的节点,通过构建多层复杂网络图,让检索像在社交网络里找人一样,通过"朋友的朋友"快速跳跃,在几毫秒内就能从数亿向量中捞出最相似的结果,时间复杂度接近 O(\\log N)。
3. 算力消耗的鸿沟:复杂的距离度量计算
传统 MySQL 的检索操作,在 CPU 层面主要是简单的数值比较 或字符串匹配(即便是全文索引,底层也是基于倒排索引的词素比对)。这类计算对 CPU 的消耗极低。
而在 AI 检索中,计算两点之间的"语义相似度",需要频繁调用复杂的数学公式 。以最常用的余弦相似度(Cosine Similarity)为例,其计算公式为 :
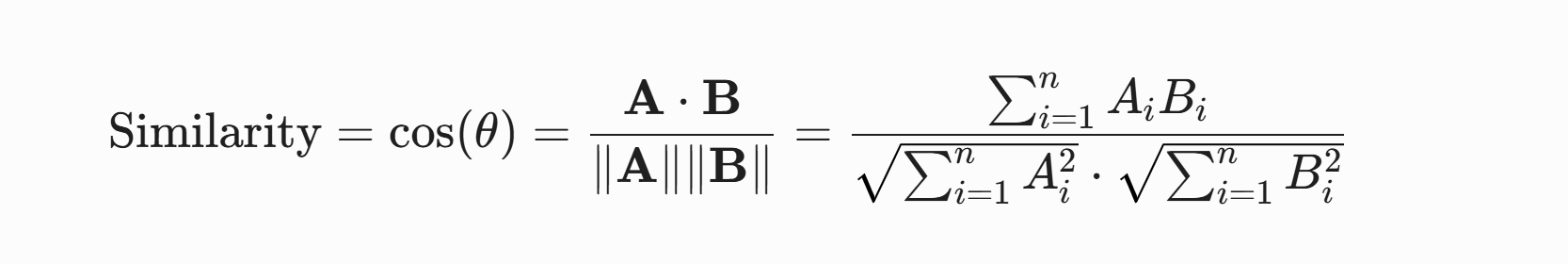
试想一下,如果每次查询都要对海量 1536 维的浮点数数组进行上述的乘法、平方和开方运算:
-
MySQL 的计算方式: MySQL 缺乏针对大规模向量并行计算的优化,依靠单核或有限的线程池去硬抗这种密集型浮点运算,CPU 会瞬间被拉满,导致整个数据库实例瘫痪。
-
专用向量数据库的优化: 现代向量数据库(如 Milvus)在底层大量采用了 SIMD(单指令流多数据流) 技术,利用 CPU 的高级指令集(如 AVX-512)甚至 GPU 加速,能够在一个时钟周期内并行处理几十个浮点数计算,这使得它们的算力效率与 MySQL 相比有质的飞跃。
4. 语义理解短板:LIKE 与全文索引无法触及的灵魂
有些后端工程师可能会反驳:"我不用向量,我用 MySQL 自带的 LIKE '%关键词%' 或者 FULLTEXT 全文索引,不也能做搜索吗?"
这正是传统文本检索 与大模型 AI 检索最根本的代差:
用户提问 ──> "苹果手机多少钱?"-
MySQL 的检索逻辑(基于字面): 无论是关键词索引还是
LIKE,MySQL 都在进行硬性的"字面匹配"。如果你的企业知识库里写的是"iPhone 15 零售价为 5999 元",由于没有出现"苹果"和"手机"这两个字,MySQL 就会直接返回"未找到相关结果"。 -
AI 检索的逻辑(基于语义): 经过 Embedding 模型转化后,"苹果手机"与"iPhone"在高维空间中的向量距离极近 。即使字面上没有一个字相同,向量数据库也能凭借"语义关联"把正确的答案检索出来 。
虽然现在高级 RAG 系统提倡"混合检索"(向量检索 + 传统关键词检索 BM25) ,但这里的关键词检索通常也是交给 Elasticsearch 或专用向量数据库的内嵌引擎来完成,而不是交给关系型的 MySQL 。
5. 架构与内存管理的冲突
MySQL 的架构设计初衷是高并发、高频、小数据量的 ACID 事务处理。为了保证数据不丢失,它设计了复杂的 Buffer Pool(缓冲池)、Redo Log(重做日志)和 Undo Log。它的数据主要是放在磁盘上的,内存只作为热点缓存。
然而,向量检索(尤其是 HNSW 索引)是一种极度依赖内存(RAM-Heavy)的计算 。为了保证图导航的流畅与毫秒级响应,HNSW 索引通常需要全部加载进物理内存中。
如果强行在 MySQL 中运行这种高维图索引,会产生严重的后果:
-
内存挤占: 巨大的向量索引会把 MySQL 的 Buffer Pool 吃光,导致正常的业务 SQL 无法缓存,引发大量的磁盘 IO,拖垮整个核心业务数据库。
-
垃圾回收与锁竞争: MySQL 在面对高密度的向量并发写入和更新时,由于其行锁、表锁以及 MVCC 机制,会导致严重的锁冲突,无法满足 AI 实时高并发的吞吐需求。
总结:MySQL vs 专用向量数据库
为了让大家有更直观的对比,我们把 MySQL 与专用向量数据库在 AI 检索场景下的表现整理成下表:
| 对比维度 | MySQL(关系型数据库) | 专用向量数据库(如 Milvus / Qdrant) |
|---|---|---|
| 支持的数据维度 | 低维(通常是一维标量值) | 高维(768 维 ~ 1536 维+ 稠密向量) |
| 底层索引结构 | B+ 树 / 倒排索引 | HNSW / IVF / 图索引 |
| 检索核心逻辑 | 精确匹配、范围查询、字面匹配 | 近似最近邻(ANN)语义相似度匹配 |
| 海量数据查询性能 | 极差(全表扫描 O(N),延迟高达秒级) | 极好(图导航检索,毫秒级响应) |
| 算力资源优化 | 无(CPU 单核/简单多线程硬抗) | 高优化(支持 SIMD 指令集、GPU 硬件加速) |
| 适用业务场景 | 订单、用户管理、事务处理、关系型存储 | RAG 知识库、大模型记忆体、图片/音视频相似度检索 |
补充探讨:MySQL 的向量扩展(如 HeatWave / pgvector)能用吗?
不可否认,随着 AI 浪潮的爆发,传统数据库阵营也在积极自救。例如 PostgreSQL 推出了 pgvector 插件,MySQL 的商业版(HeatWave)也加入了向量支持。
那么这些扩展能用吗?
-
适用场景: 如果你的知识库非常小(比如只有几千条、上万条数据),且你不想在架构中额外引入和维护一个新的组件,使用这些原生数据库的向量扩展是完全 OK 的。
-
不适用场景: 一旦文档量达到十万、百万级别,或者并发查询量(QPS)较高,这些"外挂"了向量功能的传统数据库就会露出底子在架构、内存和算力上的短板。
行业共识: 生产环境的商业 AI 项目,依然坚持"架构解耦"原则------由 MySQL 负责存储用户的对话历史、业务订单、元数据等结构化标量数据;而将切块后的文档向量,单独交由专业的向量数据库去进行毫秒级的语义检索 。所谓术业有专攻嘛。