Hi,大家好,欢迎来到维元码簿。
本文属于 《Claude Code 源码 Deep Dive》 系列,专注于上下文工程中的 System Prompt 板块。如果你想了解整个系列,可以先看系列开篇 | Claude Code 源码架构概览:51万行代码的模块地图。
本文聚焦一件事:模型的"人设"是怎么被塑造出来的------System Prompt 的每一个零件怎么组装,又怎么被缓存策略保护。
读完全文,你将能回答这几个问题:
- Claude Code 专业沉稳的"人设"是谁写的? 没有一个人定义了它,那它是怎么被塑造出来的?
- System Prompt 为什么是一段数组而不是一个大字符串? 这个看似随意的决定,背后藏着什么工程考量?
- 为什么有些模块每次调用都重新计算,有些算一次就够了? "会话内一旦确定,不再变化"------这句话背后的缓存哲学是什么?
前情提要:模型收到了什么
本文的定位是上下文工程 ------拆解模型每次调用时 Claude Code 到底组装了什么。那最自然的起点,就是找到那个组装的终点:实际发给 Anthropic API 的请求参数。
paramsFromContext()(src/services/api/claude.ts)返回发给 API 的完整参数。拆开看,真正变成 token 喂给模型的有三个字段:
| 字段 | 作用 | 预估占比 |
|---|---|---|
system |
告诉模型"你是谁、怎么做事"的指令集 | ~30% |
messages |
对话历史:用户输入、模型回复、工具调用结果 | ~60% |
tools |
工具 Schema:告诉模型可以调用哪些工具 | ~10% |
把三个板块合在一起,模型看到的上下文全景如下:
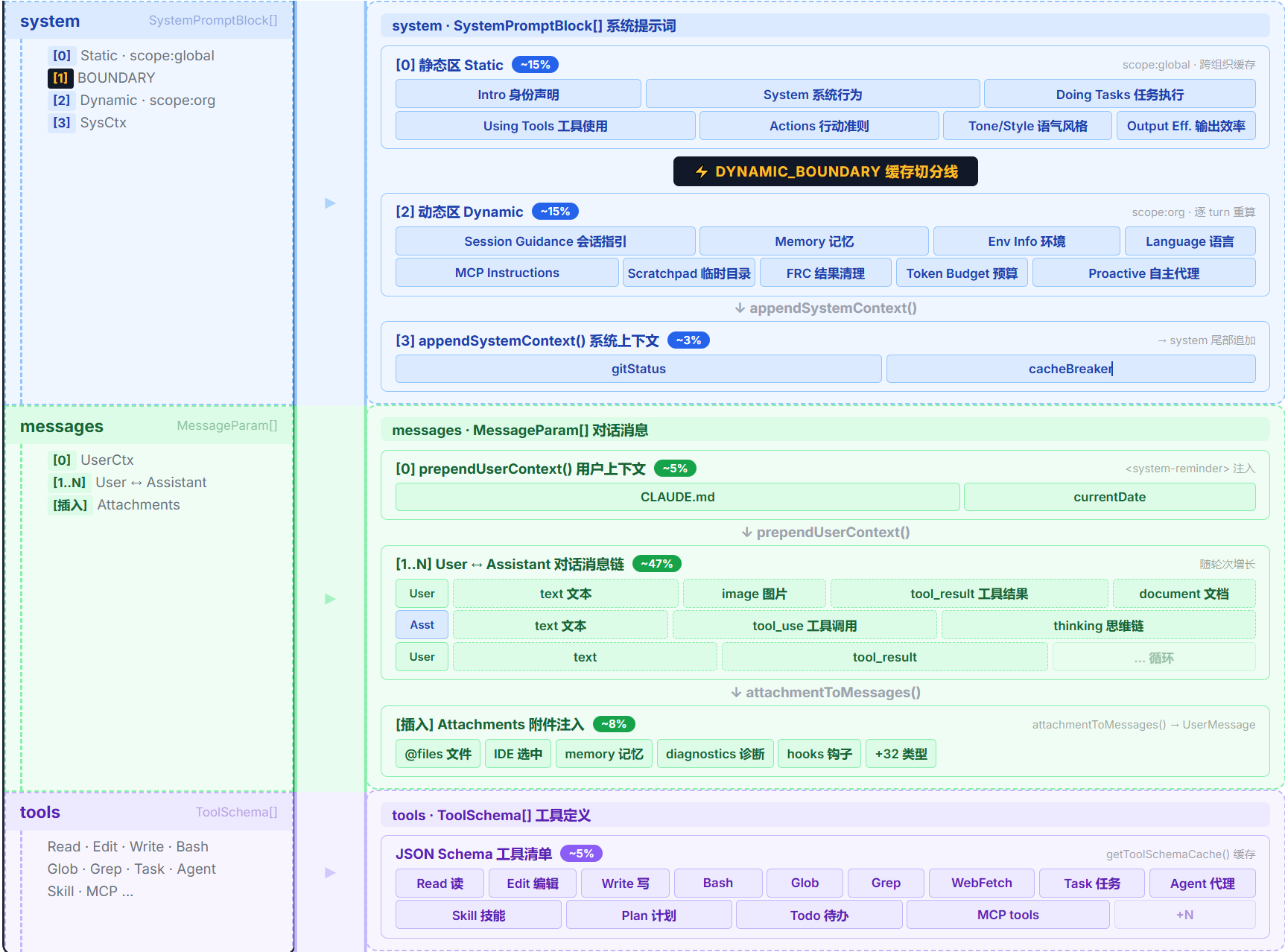
三个板块各是什么:
- System Prompt (
system,~30%):模型的"身份设定与环境感知",由 7 个静态模块 + 11+ 个动态模块组装成string[]。静态区所有用户共享,可命中全局缓存;动态区因会话变化。总入口getSystemPrompt(),但可能被优先级链替换。 - Messages (
messages,~60%):对话与隐藏注入,承载用户输入、工具结果、附件展开等全部对话信息。 - Tools (
tools,~10%):30+ 内置工具 + MCP 外部工具的 JSON Schema。
本文只拆解第一个板块------System Prompt。 Messages 和 Tools 分别在姊妹篇中展开。
System Prompt 的骨架------7 静态 + 11+ 动态
全景图告诉我们 System Prompt 大约占模型上下文的 30%。但 30% 背后的工程量,远比数字显示的更精密。System Prompt 不是一段写死的文本,而是一个动态组装的指令集------根据用户类型、运行模式、工具配置、MCP 连接状态实时拼装。
总入口是 getSystemPrompt()(src/constants/prompts.ts),返回 string[]------数组而非大字符串,目的是让后续缓存切分逻辑按元素粒度标记边界。
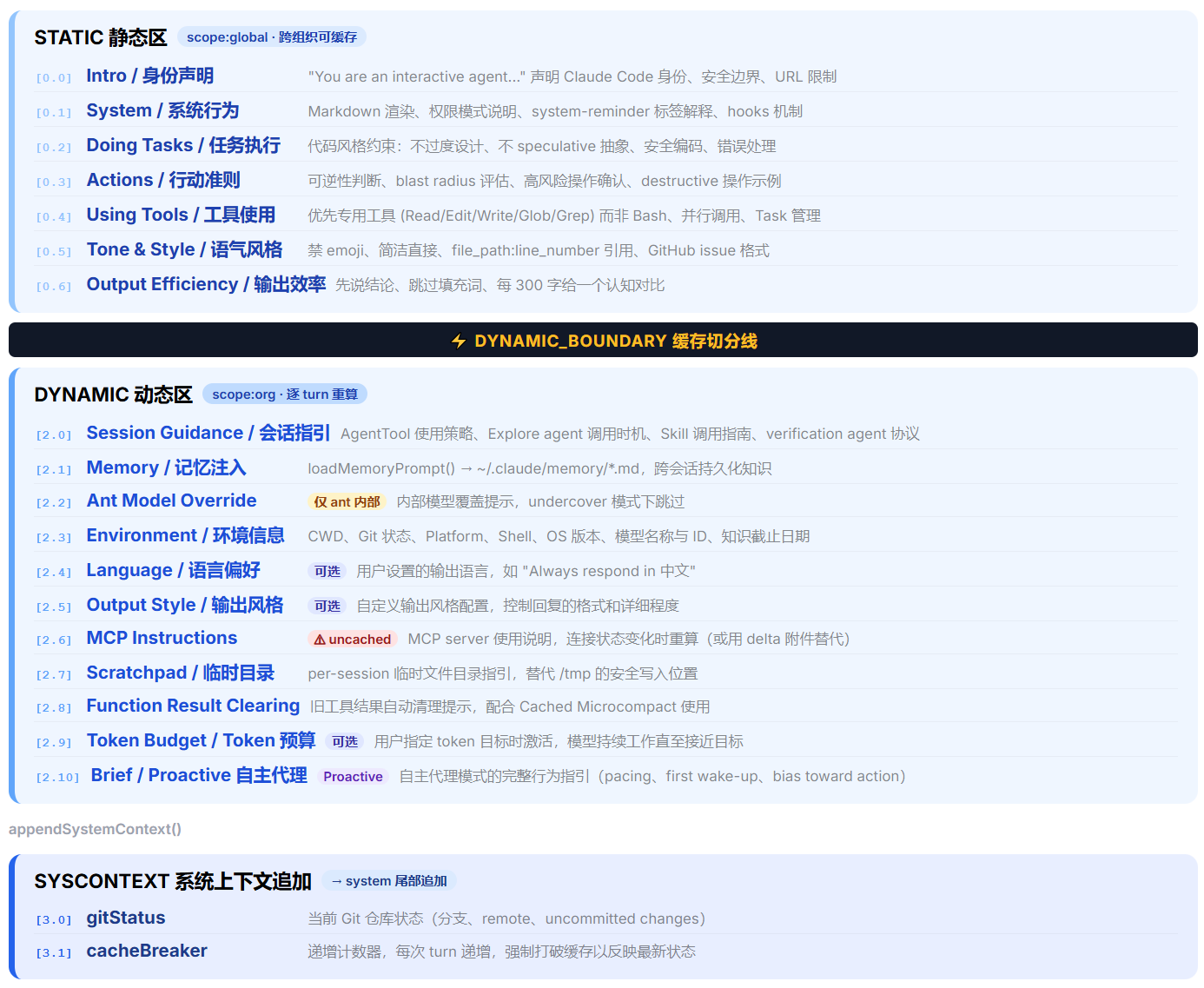
如上图所示,中间的 SYSTEM_PROMPT_DYNAMIC_BOUNDARY 把 prompt 分为静态区和动态区。静态区对所有用户完全相同,可用 scope: 'global' 跨组织缓存;动态区因会话而异,只能用 scope: 'org' 或逐 turn 重算。团队在设计 prompt 时就把缓存作为一等公民:每个新 section 都必须回答"放在边界之前还是之后?"。
静态区------7 个不变的模块
静态区的内容对所有用户完全相同------你可以和地球另一端的用户共享同一份 KV cache,只要字节一致。这 7 个模块构成了 Claude Code 的"人格基础"。

| 模块 | 核心原文 | 工程洞察 |
|---|---|---|
| Intro / 身份声明 | You must NEVER generate or guess URLs |
"安全壳"设计------编程场景中模型编造 URL 可导致访问恶意网站 |
| System / 系统行为 | Your conversation is not limited by the context window |
告诉模型有自动压缩兜底,不会因"怕用完 token"而拒绝复杂任务 |
| Doing Tasks / 任务执行 | Don't speculate. Three lines of similar code are fine |
最长的静态模块。"不过度设计"贯穿始终 |
| Actions / 行动准则 | Consider the reversibility and blast radius of actions |
如果只读一个模块就读这个。可逆操作自由执行,不可逆必须确认 |
| Using Tools / 工具使用 | Prefer dedicated tools over Bash |
Bash 最不透明,用户难以审查 |
| Tone & Style / 语气 | 不用 emoji、代码引用用 file:line |
解决了真实 UX 问题 |
| Output Efficiency | Go straight to the point. Don't be unnecessarily terse |
外部版偏简洁,内部版偏可理解 |
几个值得展开的设计亮点:
Doing Tasks 的"不过度设计"。四条规则每条背后都有模型曾犯过的真实错误:加了一个没人要求的特性、为三行相似代码抽了个 helper、在系统边界外加了不必要的 validation。团队选择在 prompt 层面显式禁止这些行为,而不是靠模型"自觉"------这是 prompt 工程的务实态度。
Actions 的"可逆性分级"。Claude Code 对 AI 安全的理解不是限制能力,而是让 AI 在高风险场景下主动慢下来。更有意思的是"授权范围匹配":用户批准一次 git push 不等于在所有上下文都批准,这防止了模型把单次授权泛化为永久权限。
Output Efficiency 的"简洁 vs 可理解"博弈 。原文 What's most important is the reader understanding your output without mental overhead or follow-ups, not how terse you are------外部版偏简洁,内部版偏可理解,因为内部用户更频繁使用,追问成本更高。
一个更深的问题:这些行为约束为什么不写进代码,而是写在 prompt 里? 答案是灵活性和可迭代性。代码约束是刚性的------一旦写死 禁止删除未跟踪文件,在所有场景下都生效。但 prompt 约束是软性的,模型可以根据上下文灵活判断。比如"可逆操作自由执行"------什么是可逆的,需要模型根据场景判断(创建文件可逆,push 到 shared branch 不可逆)。这种判断力用代码实现极其困难,但在 prompt 里只需一句话。
更重要的是,prompt 可以快速迭代。Claude Code 团队发现模型在某个场景下行为不理想时,最快的修复方式往往是在 prompt 里加一条规则------比改代码、发布、等用户更新快得多。7 个静态模块中的很多规则,就是这样在真实用户反馈中逐步积累的。
动态区------11+ 个条件模块
如果说静态区是"所有员工共享的基本守则",那动态区就是"针对每个岗位的个性化指引"。

| 模块 | 重要级 | 核心职责 |
|---|---|---|
| session_guidance | P0 | 基于工具集生成使用策略(Agent / Explore / Skill / Verification) |
| memory | P0 | 加载 ~/.claude/memory/*.md,跨会话持久知识 |
| mcp_instructions | P0 | MCP Server 使用说明 |
| env_info_simple | P1 | 环境信息(CWD / 平台 / Shell / 模型名 / 知识截止日期) |
| output_style | P1 | 自定义输出风格 |
| frc | P1 | 告知模型旧工具结果可能被清除 |
| summarize_tool_results | P1 | 提醒模型处理工具结果时记录重要信息 |
| language | P2 | 用户语言偏好 |
| scratchpad | P2 | per-session 临时文件目录指引 |
| token_budget | P2 | 用户指定 token 目标时激活 |
| ant_model_override | P2 | 内部 ant 用户额外指令覆盖 |
session_guidance 是动态区最复杂的模块。内容取决于"这个会话有哪些工具可用"------AgentTool 使用策略、Explore agent 调用时机、Skill 调用指南。因为涉及具体工具列表,不能放静态区,但 memoized 后会话内只算一次。
mcp_instructions 最为特殊------它是目前唯一可能每 turn 重算的模块(MCP Server 可能随时连接/断开)。但后来引入 mcp_instructions_delta 后,MCP 状态稳定时不注入任何内容,缓存完全命中。这是从"破坏缓存"到"保护缓存"的典型演进。
Section 缓存框架:memoized vs uncached
动态区的每个模块都用统一的缓存框架包装。来自 src/constants/systemPromptSections.ts(仅 69 行):
| 方法 | 缓存策略 | 何时重算 | 对缓存的影响 |
|---|---|---|---|
systemPromptSection() |
计算一次,缓存到 /clear 或 /compact |
会话重置时 | 不影响缓存 |
DANGEROUS_uncachedSystemPromptSection() |
每 turn 重算 | 每次 API 调用前 | 可能破坏 prompt cache |

绝大多数模块走 systemPromptSection() 路径------通过 session 级闭包缓存结果,整个会话只计算一次。只有 MCP 指令等少数场景走 DANGEROUS_uncached 路径。
缓存策略的演进也有故事:token_budget 曾是 DANGEROUS_uncached(每次 budget 翻转触发重算),后来改为 memoized------因为措辞用了条件句,没有 budget 激活时就是 no-op。这一改节省了约 20K tokens/次的缓存断裂。
整个 Section 缓存框架的核心思想只有一句话:尽量不重算,万不得已才重算。
优先级链:System Prompt 的完整决策树
前面看到的 getSystemPrompt() 返回的是"默认"System Prompt。但实际运行中,它只是决策树的一个叶子节点。外层的 buildEffectiveSystemPrompt() 决定了最终使用哪个 prompt:
| 分支 | 行为 | 频率 |
|---|---|---|
| Override | 直接返回 overrideSystemPrompt,跳过所有默认逻辑 |
极低,内部测试用 |
| Coordinator | 用协调者 prompt 替换默认,用于多 Agent 编排 | 极低,实验功能 |
| Agent + Proactive | Default 追加 Agent prompt,保留基础行为指引 | 低 |
| Agent / Custom | Agent/Custom 替换 Default,完全接管 | 低 |
| Default(标准模式) | 使用 7+11 模块 | 绝大多数用户 |
两个关键设计点:
- Proactive 是追加,标准 Agent 是替换:Proactive 模式下 Agent prompt 追加到 Default 之后,因为自主代理仍需要基础行为指引。标准模式下 Agent 完全接管,用自己的指令体系替代默认的。
- appendSystemPrompt 总是追加(Override 除外),确保额外内容不遗漏。
这对用户意味着什么? 绝大多数用户(Default 模式)看到的 Claude Code 是标准版------专业、简洁、不主动加戏。但如果你配置了自定义 Agent prompt,Claude Code 会完全变成你定义的样子------一个代码审查 Agent、一个测试编写 Agent、一个 DevOps Agent。同一个产品,不同的灵魂。
更有趣的是 Proactive 模式。在这个模式下,Agent prompt 追加到 Default 之后而不是替换------这意味着 Agent 保留了 Claude Code 的基础行为(不乱删文件、不用 Bash 能用 Read 就用 Read),同时叠加了领域特定的指令。就像一个有良好职业素养的员工,在基础守则之上接收了项目组的具体指引。这种"追加而非替换"的设计,是工程务实主义的体现。
缓存切分:能共享就共享,不能共享就降级
System Prompt 的缓存切分由 splitSysPromptPrefix()(src/utils/api.ts)处理。它的设计目标很明确:尽可能让静态区命中最高级别的缓存共享,同时避免不同用户的动态内容互相干扰。
SYSTEM_PROMPT_DYNAMIC_BOUNDARY 是一个特殊字符串,不在模型的"人格指令"中------模型看到的是一个被替换后的分隔。它的真正作用是在 splitSysPromptPrefix() 中作为缓存切分锚点:
- 边界标记之前的所有元素(静态区)合并为一个 TextBlock,scope 为
global - 边界标记之后的所有元素(动态区)合并为另一个 TextBlock,scope 为
org - 两个 TextBlock 分开发送,API 的 KV cache 就能按不同 scope 缓存
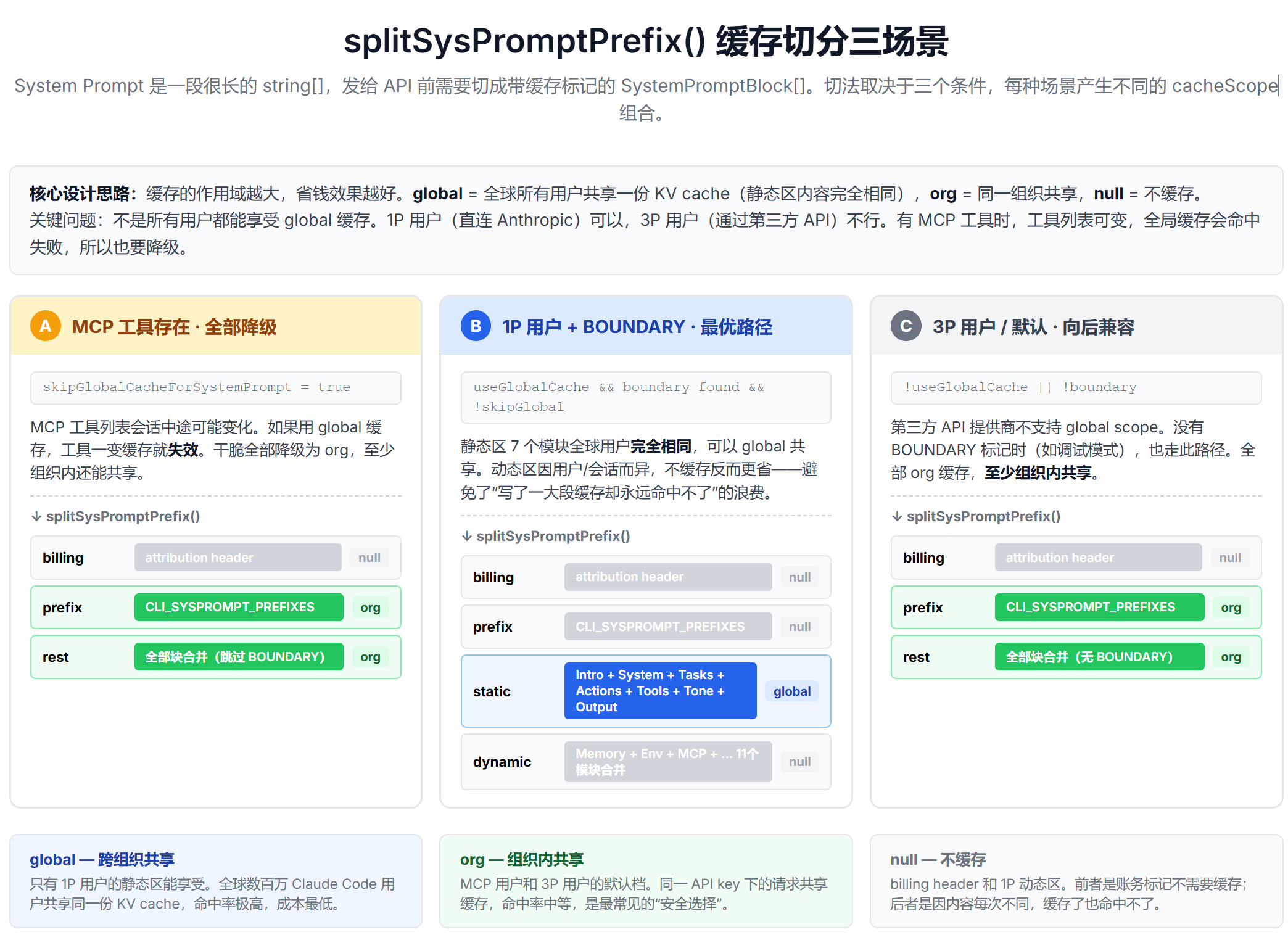
三种场景的设计思路:能共享就共享,不能共享就降级。
场景 1:有 MCP 工具时------全部降级为 org。 不同用户配置的 MCP 工具不同,工具 Schema 会影响 System Prompt 的内容。此时全局缓存不可用,所有内容降级为组织级缓存。
场景 2:无 MCP 工具 + 有 boundary marker------静态区命中 global。 这是最优场景。7 个静态模块对所有用户完全相同,可以跨组织、跨用户共享缓存。
场景 3:第三方 API 提供商------回退到 org。 Bedrock、Vertex 等平台可能不支持全局缓存,统一用组织级。
这三种场景体现了"缓存策略应该是条件性的,而不是一刀切的"工程原则。
用户感知不到缓存的存在------直到它断裂。 缓存断裂的直接后果是:这一轮的响应变慢(因为要重新处理整个前缀),API 费用突增(重新处理意味着更多的 input tokens)。Claude Code 内置了"缓存断裂检测"(promptCacheBreakDetection.ts,651 行),它在每次 API 调用前后对比状态:调用前追踪 12 个维度的变更(system prompt 变了?工具 Schema 变了?模型换了?),调用后检查 cache_read_input_tokens 是否骤降。如果断裂了,系统会自动记录事件并归因到具体原因------"MCP 工具新增了 3 个"或"Beta header 从 5min TTL 切到了 1h TTL"。这个检测系统本身也是一个工程细节:不是出了问题才排查,而是主动监控、自动归因。
SystemContext:追加在 System Prompt 尾部
System Prompt 的主体是模块化组装的指令集,但还有一类信息不适合放在指令里------环境状态。当前 Git 分支、是否有未提交变更、工作目录结构......这些信息每轮都可能变化,但语义上更像是"身份背景"而非"对话内容"。

Claude Code 的做法是把这类信息作为 SystemContext 追加在 System Prompt 尾部。放 System Prompt 而非 Messages,是因为它的语义是"你当前所处的环境",不是用户说的话。
与之对应的是 UserContext,它注入到 Messages0 的位置。两者都叫"Context",但设计意图完全不同:SystemContext 是环境状态(身份层面),UserContext 是项目知识(对话层面)------详见姊妹篇消息管道与隐藏注入(./02-Claude Code深度拆解-上下文里有什么-消息上下文管理.md)。
本章小结
System Prompt 看起来只是一段文本,但背后的工程体系非常精密:
- 静态区 7 模块:对所有用户相同,共享 global KV cache------你今天调用的缓存,可能复用了另一个用户 10 分钟前计算的结果
- 动态区 11+ 模块:通过 Section 缓存框架管理,会话内只算一次
- 优先级链:Override > Coordinator > Agent(proactive追加) > Custom > Default------同一个 Claude Code,在不同场景下展现的是不同面貌
- 缓存边界 :静态区和动态区用
DYNAMIC_BOUNDARY分隔,三层 scope(global/org/ephemeral)按条件降级 - SystemContext:环境状态追加在尾部,与 UserContext(注入 Messages)形成互补
没有一个人定义了 Claude Code 的人设。 18 个模块按优先级链拼装,你在不同场景下看到的 Claude Code,其实是同一套骨架在不同模块组合下的不同面貌。
系列导航:
本文属于 《Claude Code 源码 Deep Dive》 系列中「上下文组成与缓存」命题的子篇章,专注于 System Prompt 的组装与缓存。
本文是完整版《Claude Code 源码深度解析:拆解上下文的组成与缓存》的子命题之一。如果你想了解上下文编排的全景(System Prompt + Messages + Tools + 缓存工程),推荐阅读完整版。
姊妹篇(可独立阅读):
- Claude Code 深度拆解:上下文里有什么------消息上下文管理
- Claude Code 深度拆解:上下文里有什么------工具能力声明
- Claude Code 源码深度解析:拆解上下文的组成与缓存
如果这篇文章对你有帮助,欢迎点赞收藏 支持一下。有任何想法或疑问,欢迎评论区留言讨论 👋