短视频平台的内容消费速度已经远超人工生产速度。一个中等规模的影视解说账号,要维持日更节奏,单靠人工完成脚本、配音、剪辑、字幕、分发五个环节,人力成本会随账号数量线性增长。
这篇文章的目标是把影视解说的生产链路拆开来看:每个环节当前有哪些技术方案、各方案的能力边界在哪里、哪些环节已经可以被 AI 工具接管、哪些环节仍然需要人工介入。最后给出一套可落地的全链路方案参考。
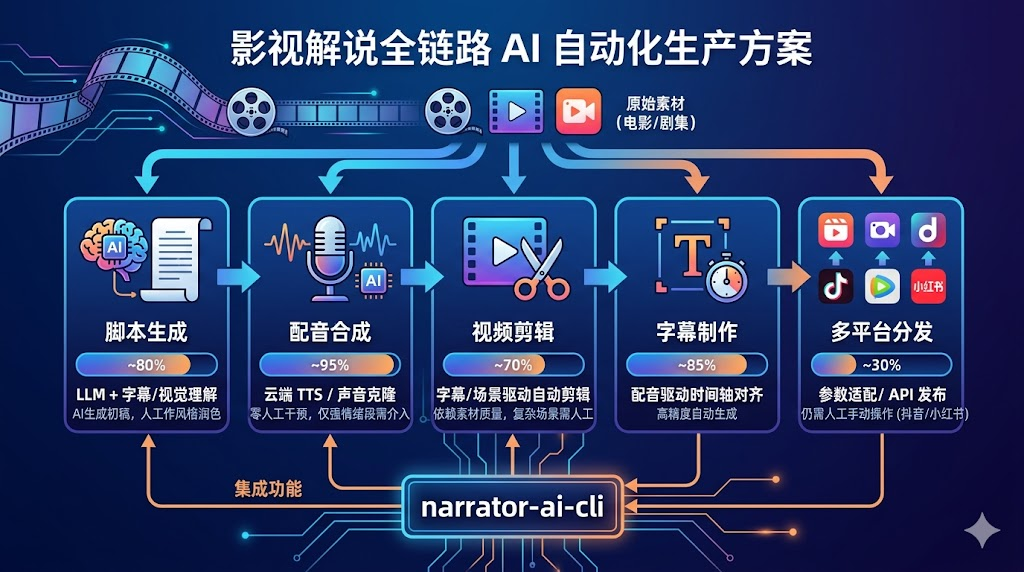
一、影视解说视频生产链路拆解:五个环节的技术架构与数据流转
一条完整的影视解说视频,从素材到发布,经过以下五个环节:
原始素材(电影/剧集)↓
环节1 脚本生成:理解剧情 → 提炼叙事结构 → 生成解说文案
环节2 配音合成:文案 → TTS 合成 → 音频后处理
环节3 视频剪辑:字幕时间轴 → 镜头匹配 → 视频合成
环节4 字幕制作:配音时间轴 → 字幕样式 → 字幕烧录
环节5 多平台分发:格式转码 → 平台参数适配 → 发布
五个环节的技术复杂度和自动化难度差异很大。
脚本生成和配音合成已经有成熟的 AI 方案;视频剪辑的自动化程度取决于素材质量;字幕制作高度依赖配音时间轴的精度;多平台分发是目前自动化程度最低、工具碎片化最严重的环节。
二、各环节 AI 技术方案现状:从 LLM 脚本生成到 TTS 配音合成的能力边界
2.1 脚本生成:从人工撰写到 LLM 驱动
传统方案: 人工观看素材 → 手写解说脚本,一部90分钟电影约需60到90分钟。
当前 AI 方案:
-
基于字幕文件(SRT)的文案生成:把字幕文本喂给 LLM,生成解说脚本。优点是速度快(3到5分钟),缺点是无法理解画面内容,对纯视觉叙事的场景(无对白的动作戏、纪录片图表)效果差。
-
基于视觉理解的文案生成:抽取关键帧,用多模态模型(GPT-4o、Gemini Vision)理解画面内容,再结合字幕生成脚本。准确率更高,但 API 调用成本也更高。

- 风格化模型:在基础文案生成之上叠加风格约束(喜剧、悬疑、情感),让文案有账号辨识度。
能力边界: 当前 AI 脚本生成在标准剧情类内容上已经可以达到"可用"水平,但在需要深度文化理解(方言梗、历史背景)和强创意表达的场景上,仍然需要人工润色。
2.2 配音合成:TTS 技术已基本成熟
传统方案: 人工录音或外包配音,成本高、周期长、风格难以标准化。
当前 AI 方案:
-
云端 TTS 服务(Azure TTS、阿里云 TTS、腾讯 TTS):音色自然度高,支持情感调节,按字符计费,适合规模化生产。
-
本地 TTS 模型(Coqui TTS、VITS):无调用成本,但需要 GPU,音色质量低于云端服务。
-
声音克隆:用少量样本克隆特定音色,适合需要固定人设声音的账号。
能力边界: 云端 TTS 在中文普通话场景下已经达到接近真人的自然度。主要局限在于:情绪表达的细腻程度仍不如真人,方言支持有限,长文本的语调连贯性偶有问题。

2.3 视频剪辑:自动化程度差异最大的环节
传统方案: 人工在剪辑软件(Premiere、达芬奇)里逐帧操作,一条5分钟解说视频约需30到60分钟。
当前 AI 方案:
-
字幕时间轴驱动剪辑:用 SRT 文件的时间戳信息驱动 FFmpeg 自动切割视频片段,再按解说脚本的叙事顺序重新拼接。这是目前自动化程度最高的方案,适合有完整字幕的剧情类内容。
-
场景检测驱动剪辑:用 FFmpeg 的场景变化检测(
select='gt(scene,threshold)')自动识别镜头切换点,按切换点切割素材。适合无字幕或字幕质量差的素材。 -
多模态理解驱动剪辑:用视觉模型理解每个镜头的内容和情绪,按解说脚本的情绪节奏匹配镜头。技术最复杂,效果最好,但计算成本也最高。
能力边界: 字幕时间轴驱动方案在字幕质量好的素材上已经可以全自动完成,但在字幕缺失、多人对话交叉、快速剪辑的素材上仍然需要人工介入。
2.4 字幕制作:依赖配音时间轴精度
字幕制作的核心技术问题是时间轴对齐:字幕的显示时间需要和配音的播放时间精确匹配,误差超过200毫秒就会有明显的不同步感。
当前方案:
-
配音驱动字幕:先合成配音,用 Whisper 对配音做语音识别,生成精确的字幕时间轴,再用 FFmpeg 烧录字幕。这是目前精度最高的方案。
-
脚本时间轴估算:根据文案字数和 TTS 语速估算每段字幕的时长,误差约在 100 到 300 毫秒之间。
能力边界: 配音驱动字幕方案在标准语速下精度可以控制在 50 毫秒以内,基本达到广播级标准。主要局限在于需要两次 TTS 调用(合成配音 + 识别配音),链路更长,成本略高。
2.5 多平台分发:自动化程度最低的环节
当前痛点: 抖音、B站、小红书、YouTube 对视频格式、分辨率、码率、字幕格式的要求各不相同。人工适配四个平台,每条视频需要额外30到45分钟。
当前方案:
-
参数预设方案:为每个平台维护一套 FFmpeg 转码参数预设,批量转码。
-
平台 API 自动发布:部分平台(B站、YouTube)提供开放 API,支持程序化上传。抖音和小红书目前没有开放上传 API,仍需手动操作。
能力边界: 转码和格式适配已经可以完全自动化,但发布操作在抖音和小红书上仍然是人工瓶颈。
三、五环节自动化程度横评:工具选型与人工介入边界
把五个环节的技术方案、自动化程度、主流工具、适用场景整合成一张能力矩阵表,方便团队做工具选型决策。
|-------|-------|----------------------|--------------------------------------|---------------|
| 生产环节 | 自动化程度 | 主流技术方案 | 代表工具 | 人工介入点 |
| 脚本生成 | ★★★★☆ | LLM + 字幕驱动 / 多模态视觉理解 | GPT-4o、Gemini Vision、narrator-ai-cli | 风格润色、文化梗处理 |
| 配音合成 | ★★★★★ | 云端 TTS / 声音克隆 | Azure TTS、阿里云 TTS、narrator-ai-cli | 情绪异常段人工替换 |
| 视频剪辑 | ★★★☆☆ | 字幕时间轴驱动 / 场景检测驱动 | FFmpeg、narrator-ai-cli | 字幕缺失素材、快速剪辑场景 |
| 字幕制作 | ★★★★☆ | 配音驱动时间轴 / 脚本估算时间轴 | Whisper、FFmpeg | 时间轴异常段校正 |
| 多平台分发 | ★★☆☆☆ | 参数预设转码 / 平台 API 上传 | FFmpeg、B站API | 抖音/小红书手动发布 |
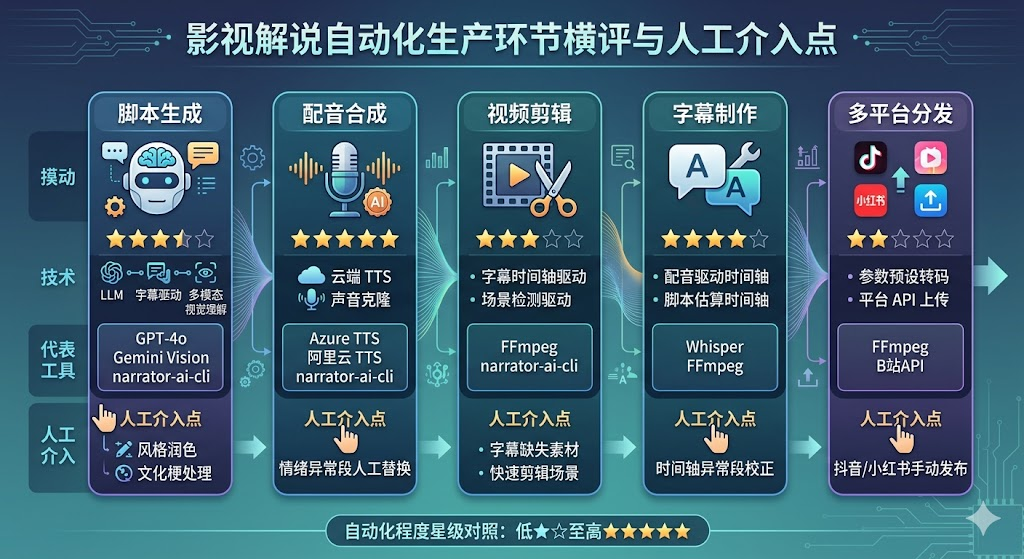
矩阵解读:
-
配音合成是自动化程度最高的环节,云端 TTS 已经可以做到零人工干预。
-
视频剪辑是自动化程度最低的生产环节,素材质量直接决定自动化上限。
-
多平台分发是整条链路的最后一个人工瓶颈,短期内难以完全消除。
-
脚本生成和字幕制作是当前 AI 工具投入产出比最高的两个环节,优先自动化这两个环节可以释放最多人力。
四、narrator-ai-cli 接入全链路:脚本生成与配音合成环节的三种集成方式
在上述五个环节中,narrator-ai-cli 主要覆盖脚本生成和配音合成两个环节,通过 CLI 接口把这两个环节的 API 调用封装成可脚本化的命令。
接入方式一:替换脚本生成环节
如果团队当前的工作流是"人工撰写脚本 → 人工配音",可以先只替换脚本生成环节,保留人工配音。
只生成解说脚本,输出 JSON 供人工审阅和修改 narrator-ai-cli commentary create-script \ --movie-file input.mp4 \ --scene-type movie_commentary \ --learning-model-id narrator-comedy-001 \ --output-script scripts/output_script.json
生成的 JSON 文件包含每个片段的时间戳、解说文案、对应关键帧路径,人工在 JSON 里直接修改 narration 字段,改完后再进入配音环节。
接入方式二:同时替换脚本生成和配音合成
一条命令完成脚本生成 + 配音合成 + 视频合成 narrator-ai-cli commentary create-movie \ --movie-file input.mp4 \ --scene-type movie_commentary \ --learning-model-id narrator-comedy-001 \ --platform "抖音" \ --output output/movie_解说.mp4
执行前会显示预估调用额度,确认后才开始扣费,不会有意外消耗。
接入方式三:通过 AI Agent 驱动(Skill 接入)
如果团队在用 AI Agent 工作流(WorkBuddy、小龙虾 OpenClaw 等),可以加载官方 SKILL.md 文件,让 Agent 直接驱动 CLI:
用户:帮我把 input.mp4 做成爆笑喜剧风格的解说,发抖音用
Agent:正在提取字幕...文案生成中...配音合成中...✅ 成片已输出:output/movie_解说.mp4
三种接入方式的选择逻辑:团队刚开始引入 AI 工具,建议从方式一开始,保留人工审阅环节,逐步建立对 AI 输出质量的信任;批量生产场景用方式二;已经在用 AI Agent 工作流的团队用方式三。

五、全链路方案落地:个人创作者到中型团队的 AI 工具配置策略
不同规模的内容团队,全链路自动化的优先级和配置方式不同。
个人创作者(日产1到2条)
优先自动化脚本生成和配音合成,视频剪辑和字幕制作用 narrator-ai-cli 的一次性出片模式,多平台分发手动操作。全链路人工介入点只保留发布前的质量审核。
工具配置:narrator-ai-cli(脚本+配音+剪辑+字幕)+ FFmpeg(格式转码)+ 手动发布
小团队(日产5到10条)
在个人创作者配置基础上,增加批量处理脚本和定时任务,实现素材入库后自动出片。分步模式保留文案审阅环节,确保账号调性一致。
工具配置:批量 Shell 脚本 + narrator-ai-cli + FFmpeg 参数预设 + B站/YouTube API 自动上传
中型内容团队(日产20条以上)
需要引入任务队列和状态管理,避免并发任务互相干扰。建议用 AI Agent 工作流(WorkBuddy 或小龙虾)驱动 narrator-ai-cli,多个 Agent 并行处理不同素材,任务状态统一管理。
工具配置:AI Agent(任务编排)+ narrator-ai-cli Skill(执行层)+ FFmpeg(合成层)+ 平台 API(分发层)
【截图位置2】: 三种团队规模的全链路配置对比图,标注各环节工具选型和人工介入点
六、AI 影视解说自动化的当前局限:哪些场景仍然需要人工介入
自动化方案不是银弹,有几个场景目前仍然需要人工介入,需要在方案设计时提前规划。
脚本生成的局限
AI 生成的解说脚本在以下场景质量明显下降:素材字幕缺失或质量差(OCR 识别错误多);内容涉及大量文化背景知识(历史片、地域性强的喜剧);需要强创意表达(爆款标题、金句设计)。这三类场景建议保留人工撰写或人工深度润色,不要完全依赖 AI 输出。
配音合成的局限
云端 TTS 在以下场景表现不稳定:超长句子(超过50字)的语调连贯性;强情绪段落(大哭、大笑、愤怒)的情感表达;方言内容的发音准确性。建议在质量审核环节专门检查这三类片段,异常段用人工录音替换。
视频剪辑的局限
字幕时间轴驱动剪辑在以下素材上效果差:无字幕的纯动作场景;多人快速对话交叉剪辑;帧率不标准的老片素材。这类素材需要人工在剪辑软件里处理,不要强行走自动化流程。
七、影视解说全链路自动化可行边界:五环节自动化程度与落地优先级总结
脚本生成可以达到约80%的自动化程度。narrator-ai-cli 的分步模式(先生成文案 JSON,人工审阅后再合成视频)是目前最稳妥的接入方式------AI 负责生成初稿,人工只做最后的风格校准。文化背景复杂的内容和需要强创意表达的场景,建议保留人工撰写。
配音合成是五个环节里最接近全自动的一个,可以达到约95%的自动化程度。唯一需要人工介入的是强情绪段落和方言内容,建议在质量审核环节专门检查这两类片段,异常段用人工录音替换。
视频剪辑的自动化上限约70%,强依赖素材质量。字幕完整、帧率标准的素材可以全自动完成;字幕缺失或快速剪辑的素材需要人工处理。不要试图用自动化方案强行处理低质量素材,人工处理反而更快。
字幕制作可以达到约85%的自动化程度。配音驱动时间轴方案精度最高,适合对字幕质量有要求的账号;脚本估算时间轴方案成本更低,适合对精度要求不高的批量生产场景。
全链路自动化的核心价值不是把人工降到零,而是把人工介入点从"每个环节都要操作"压缩到"只在质量异常时介入"。按上表的方案配置,一个人可以管理原来需要3到5人才能维持的日更产能。
参考资料
-
narrator-ai-cli 项目:
git clone https://github.com/jieshuo-ai/narrator-ai-cli -
narrator-ai-cli Skill 仓库:
git clone https://github.com/jieshuo-ai/narrator-ai-cli-skill -
FFmpeg 场景检测文档:https://ffmpeg.org/ffmpeg-filters.html#select_002c-aselect
-
Whisper 多语言识别:https://github.com/openai/whisper
-
Radford et al., "Robust Speech Recognition via Large-Scale Weak Supervision", arXiv:2212.04356