短剧出海的视频翻译不是把台词翻成外语这么简单。真正的工程问题是:一部 80 集中文短剧要同时交付日语、英语、越南语三个版本,如何在可控成本内完成语音识别、翻译、配音、字幕、硬字幕处理、质量检测和多格式交付。
如果只处理一集,很多工具都能跑通;但当任务变成 80 集 × 3 个语种,系统要面对的是 240 个语言版本、上千条角色台词、不同画质和音频质量、硬字幕擦除、异常重跑、交付文件对齐等问题。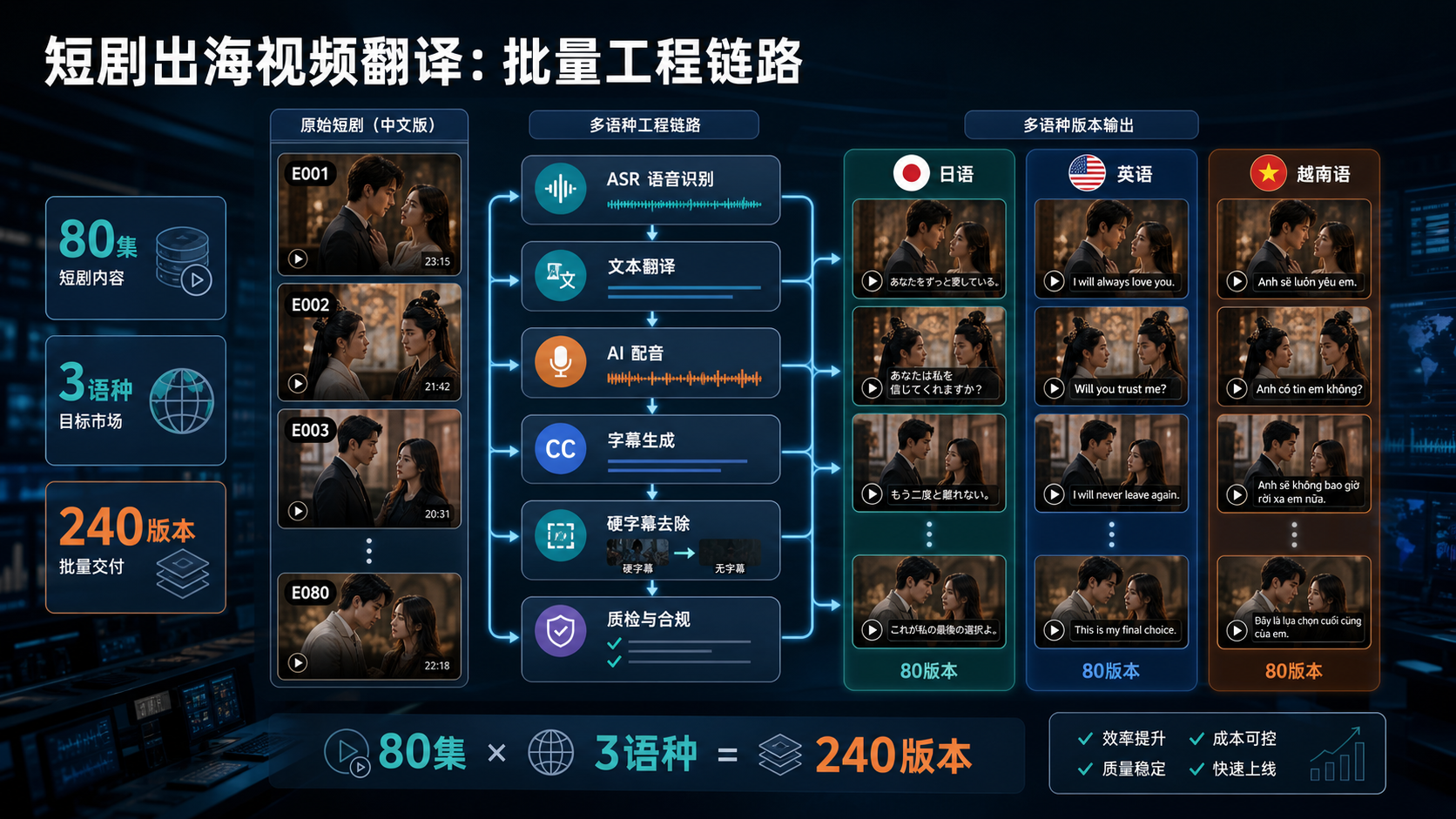
短剧出海的视频翻译技术方案,本质上是一个批量媒体处理工作流,而不是单点 AI 能力展示。
本文用一个真实工程场景拆解完整链路:一部 80 集中文短剧,需要翻译成日语、英语、越南语三个版本。目标交付物包括目标语言配音视频、硬字幕压制版视频、SRT 字幕文件和用于复剪的音频文件。
一、输入评估:先判断这部短剧能不能批量跑
批量生产之前,第一步不是直接提交全部视频,而是做输入评估。这个环节决定后面是走自动化流水线,还是必须先人工修复素材。
评估通常分四类。
-
画面层:是否有硬字幕,字幕位置是否固定,是否有多行字幕、花字、弹幕或贴纸遮挡。
-
音频层:人声是否清晰,背景音乐是否压过对白,是否存在多人重叠说话。
-
角色层:主要角色数量、男女声比例、旁白和对白是否混在同一音轨。
-
文件层:分辨率、帧率、音轨数量、编码格式、文件命名是否能稳定排序。
工程上可以先用 ffprobe 批量抽取媒体信息,建立输入清单:
ffprobe -v error \ -select_streams v:0 \ -show_entries stream=codec_name,width,height,r_frame_rate,duration \ -show_entries format=filename,duration,size \ -of json episode_001.mp4
对于 80 集短剧,建议在入库阶段生成一个 manifest.json,每集至少记录以下字段:
{ "episode_id": "E001", "source_file": "episode_001.mp4", "duration_sec": 92.4, "resolution": "1080x1920", "has_burned_subtitle": true, "subtitle_region": "bottom", "audio_quality": "medium", "speaker_count_estimated": 4, "target_languages": ["ja-JP", "en-US", "vi-VN"] }
这里有一个容易踩的坑:不要等 80 集全部跑完后才发现原视频带硬字幕。如果中文硬字幕已经烧录在画面里,后续再叠加日语或英语字幕,会出现双字幕干扰,海外用户观看体验会明显下降。
所以,前期评估阶段要先决定三件事:
-
是否需要硬字幕擦除。
-
是否需要目标语言字幕压制。
-
是否需要保留原始无字幕版本,供后续复剪或广告投放使用。
二、打样验证:先取第一集前 30 秒跑完整链路
批量任务最忌讳直接全量开跑。更稳的做法是从第一集截取前 30 秒,跑一遍完整链路。
为什么只取 30 秒?
因为短剧前 30 秒通常包含人物出场、对白节奏、背景音乐、字幕样式和剪辑节奏。它足够暴露多数工程问题,又不会消耗太多处理资源。
截取样片可以用 FFmpeg 完成:
ffmpeg -y \ -i episode_001.mp4 \ -ss 00:00:00 \ -t 30 \ -c copy sample_e001_30s.mp4
打样链路建议完整覆盖以下步骤:
样片输入 ↓ 媒体信息检测 ↓ ASR 语音识别 ↓ 说话人/角色分离 ↓ 字幕提取或硬字幕检测 ↓ 中文台词清洗 ↓ 日语/英语/越南语翻译 ↓ 目标语言配音生成 ↓ 字幕时间轴对齐 ↓ 字幕压制或导出 SRT ↓ 人工抽检
如果使用 Whisper 这类 ASR 模型做打样,可以先验证转写稳定性:
whisper sample_e001_30s.mp4 \ --language Chinese \ --task transcribe \ --output_format srt \ --output_dir ./asr_out
打样阶段重点看三类结果。
第一类是识别结果。台词是否漏字,角色名、专有名词、语气词是否被误识别。
第二类是翻译结果。短剧台词不能只追求字面准确,还要适应目标市场的口语表达。中文里常见的"你给我等着""别装了""我不会放过你",直译到英语或日语里往往会显得生硬。
第三类是时间轴结果。配音生成后,目标语言句子长度可能变长。英语通常比中文长,日语可能在语气表达上更绕,越南语又有自己的节奏。如果不做时长控制,配音很容易压到下一句对白。
打样的目标不是证明系统能跑,而是确定后续 80 集批量生产时哪些环节必须自动化,哪些环节必须保留人工审核。
三、全链路流程图:从源视频到多语种成片
一个可批量交付的短剧视频翻译系统,建议拆成 7 个处理层。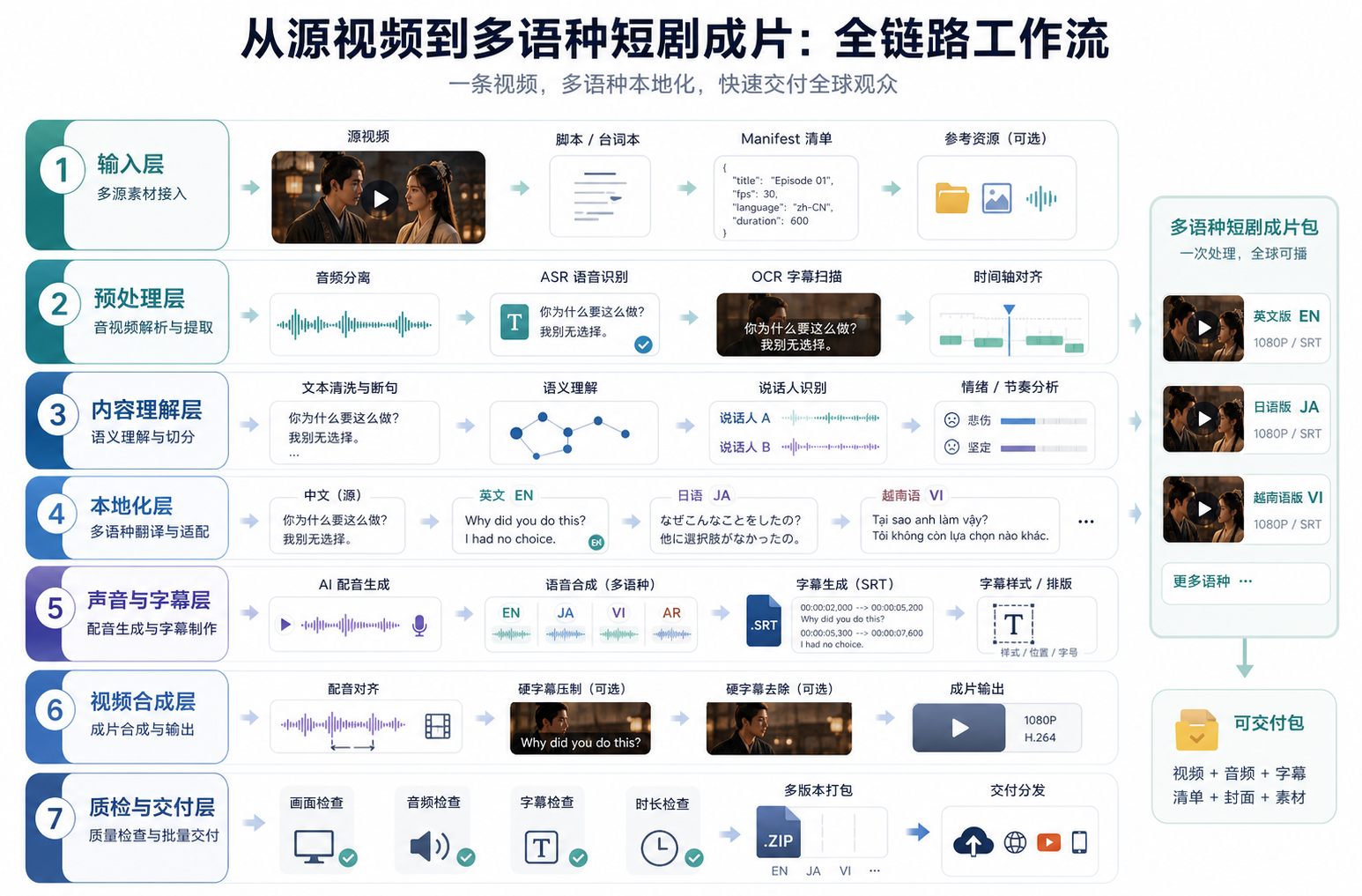
┌──────────────────────────────────────────────┐ │ 1. 输入层 │ │ 视频文件 / 云盘链接 / 剧集 manifest / 语种配置 │ └──────────────────────────────────────────────┘ ↓ ┌──────────────────────────────────────────────┐ │ 2. 预处理层 │ │ ffprobe 检测 / 分辨率校验 / 音轨抽取 / 样片截取 │ └──────────────────────────────────────────────┘ ↓ ┌──────────────────────────────────────────────┐ │ 3. 内容理解层 │ │ ASR 转写 / 说话人识别 / 硬字幕检测 / OCR 提取 │ └──────────────────────────────────────────────┘ ↓ ┌──────────────────────────────────────────────┐ │ 4. 本地化层 │ │ 台词清洗 / 术语表 / 多语种翻译 / 语气改写 │ └──────────────────────────────────────────────┘ ↓ ┌──────────────────────────────────────────────┐ │ 5. 声音与字幕层 │ │ 声音克隆 / AI 配音 / SRT 生成 / 时间轴对齐 │ └──────────────────────────────────────────────┘ ↓ ┌──────────────────────────────────────────────┐ │ 6. 视频合成层 │ │ 硬字幕擦除 / 新字幕压制 / 音视频合成 / 导出 │ └──────────────────────────────────────────────┘ ↓ ┌──────────────────────────────────────────────┐ │ 7. 质检与交付层 │ │ 自动检测 / 异常回退 / 人工抽检 / 多格式交付 │ └──────────────────────────────────────────────┘
这个拆法的好处是,每一层都有明确输入和输出。即使某一集翻译失败,也不需要从头重跑所有步骤。
例如,ASR 已经通过,只有越南语配音失败,那么任务可以从"越南语配音生成"节点回退;如果硬字幕擦除效果不达标,则只重跑视频修复和字幕压制,不影响日语、英语、越南语的翻译文本。
四、批量调度架构:不要把 240 个版本当成一个大任务
80 集 × 3 语种,看起来是 240 个输出任务。但工程上不能把它当成一个大任务提交。更稳的做法是拆成"剧集任务"和"语种子任务"两层。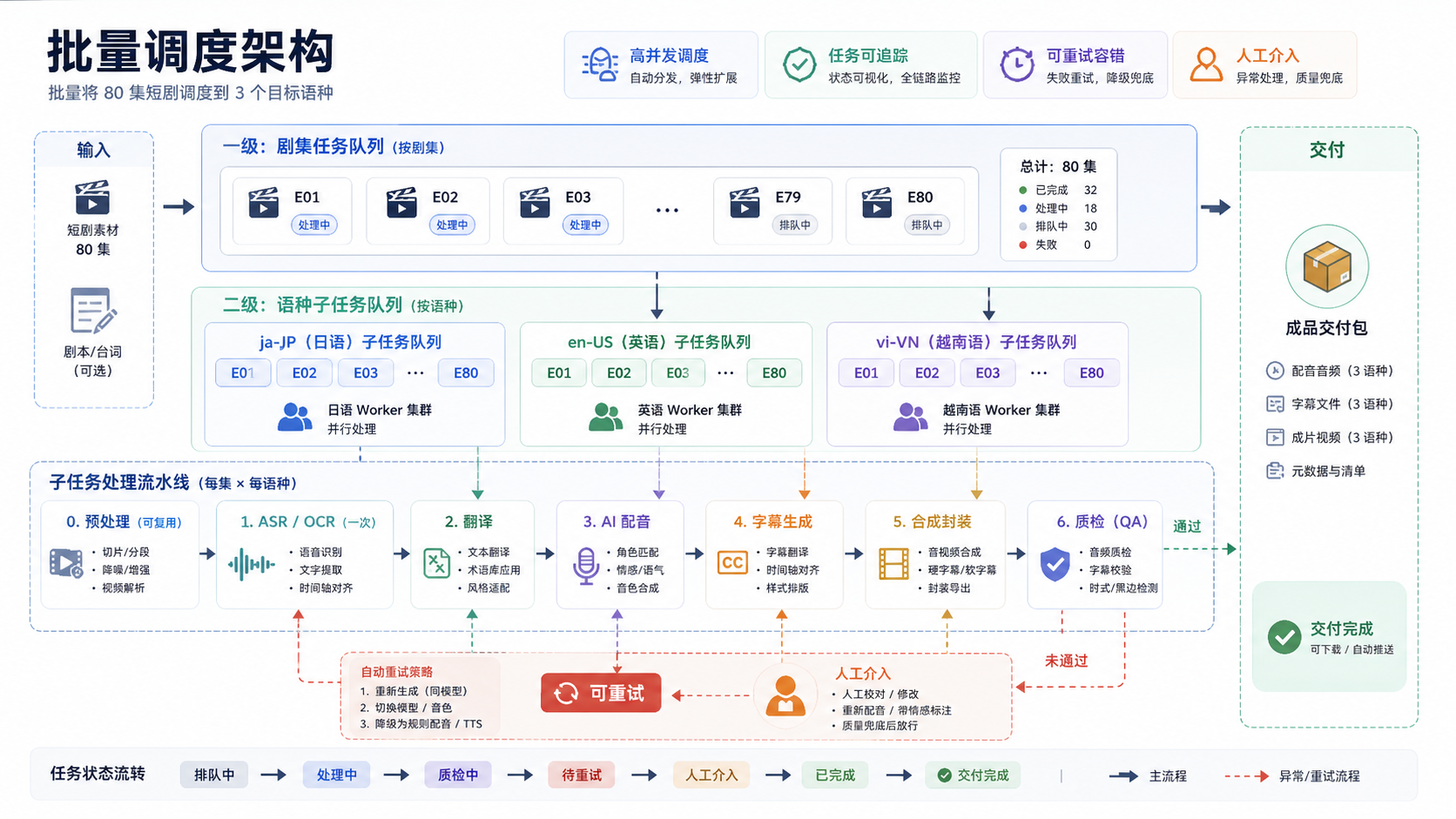
┌────────────────────┐ │ 任务入口 │ │ manifest + 配置 │ └─────────┬──────────┘ ↓ ┌────────────────────┐ │ 调度器 │ │ episode queue │ └─────────┬──────────┘ ↓ ┌──────────────────────────┼──────────────────────────┐ ↓ ↓ ↓ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │ E001 预处理 │ │ E002 预处理 │ │ E003 预处理 │ └──────┬───────┘ └──────┬───────┘ └──────┬───────┘ ↓ ↓ ↓ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │ ASR / OCR │ │ ASR / OCR │ │ ASR / OCR │ └──────┬───────┘ └──────┬───────┘ └──────┬───────┘ ↓ ↓ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 语种子任务队列:ja-JP / en-US / vi-VN │ └──────────────┬──────────────────┬──────────────────┬────────┘ ↓ ↓ ↓ ┌────────────┐ ┌────────────┐ ┌────────────┐ │ 翻译任务 │ │ 配音任务 │ │ 字幕任务 │ └─────┬──────┘ └─────┬──────┘ └─────┬──────┘ ↓ ↓ ↓ ┌────────────────────────────────────────────┐ │ 合成 / 质检 / 异常回退 / 交付 │ └────────────────────────────────────────────┘
调度时有几个工程决策。
第一,预处理、ASR、OCR 应该按剧集复用。同一集的视频转写和硬字幕识别只需要做一次,不应该因为有 3 个语种就重复做三遍。
第二,翻译、配音、字幕压制按语种拆分。日语、英语、越南语的文本长度、配音时长、字幕换行规则不同,应该分开调度和质检。
第三,任务状态要落库。至少需要记录:
{ "episode_id": "E001", "stage": "dubbing", "language": "ja-JP", "status": "running", "retry_count": 1, "upstream_artifacts": { "asr_srt": "E001.zh.srt", "translated_srt": "E001.ja-JP.srt", "speaker_map": "E001.speakers.json" } }
第四,要给重试设置上限。媒体任务常见失败不是代码异常,而是某一段音频过短、字幕时间轴冲突、视频编码不兼容或字幕擦除质量不达标。无限重试只会浪费资源。
建议把任务分成三类:
-
可自动重试:网络超时、临时队列失败、单段配音生成失败。
-
可降级处理:高级擦除失败后改用标准擦除,或只交付 SRT 文件。
-
必须人工介入:音频严重失真、角色串台、硬字幕覆盖人物主体。
五、质量自动检测:指标要比"看起来还行"更具体
批量交付不能只靠人工逐集观看。质量检测至少要覆盖文本、音频、字幕和视频四层。
下面是一套可落地的阈值配置示例:
quality_gate: asr: min_confidence: 0.82 max_empty_segment_ratio: 0.03 max_repeated_text_ratio: 0.05 translation: max_length_expansion: en-US: 1.55 ja-JP: 1.35 vi-VN: 1.45 required_terms_hit_rate: 0.95 max_untranslated_chinese_chars: 0 dubbing: max_duration_drift_ms: 650 max_segment_overlap_ms: 120 min_voice_consistency_score: 0.78 subtitle: max_chars_per_line: en-US: 42 ja-JP: 28 vi-VN: 38 max_lines_per_caption: 2 max_timeline_gap_ms: 500 video: min_output_resolution_ratio: 0.98 max_audio_peak_db: -1.0 min_audio_loudness_lufs: -20 max_audio_loudness_lufs: -12
这些阈值不是一成不变的标准,而是工程上的第一道闸门。真正落地时,要根据剧集类型调整。
例如,爽剧对白节奏快,max_duration_drift_ms 可以稍微放宽;情感戏台词慢,声音一致性和停顿节奏更重要;越南语字幕如果换行过密,移动端观看会很累,就要提高字幕规则的权重。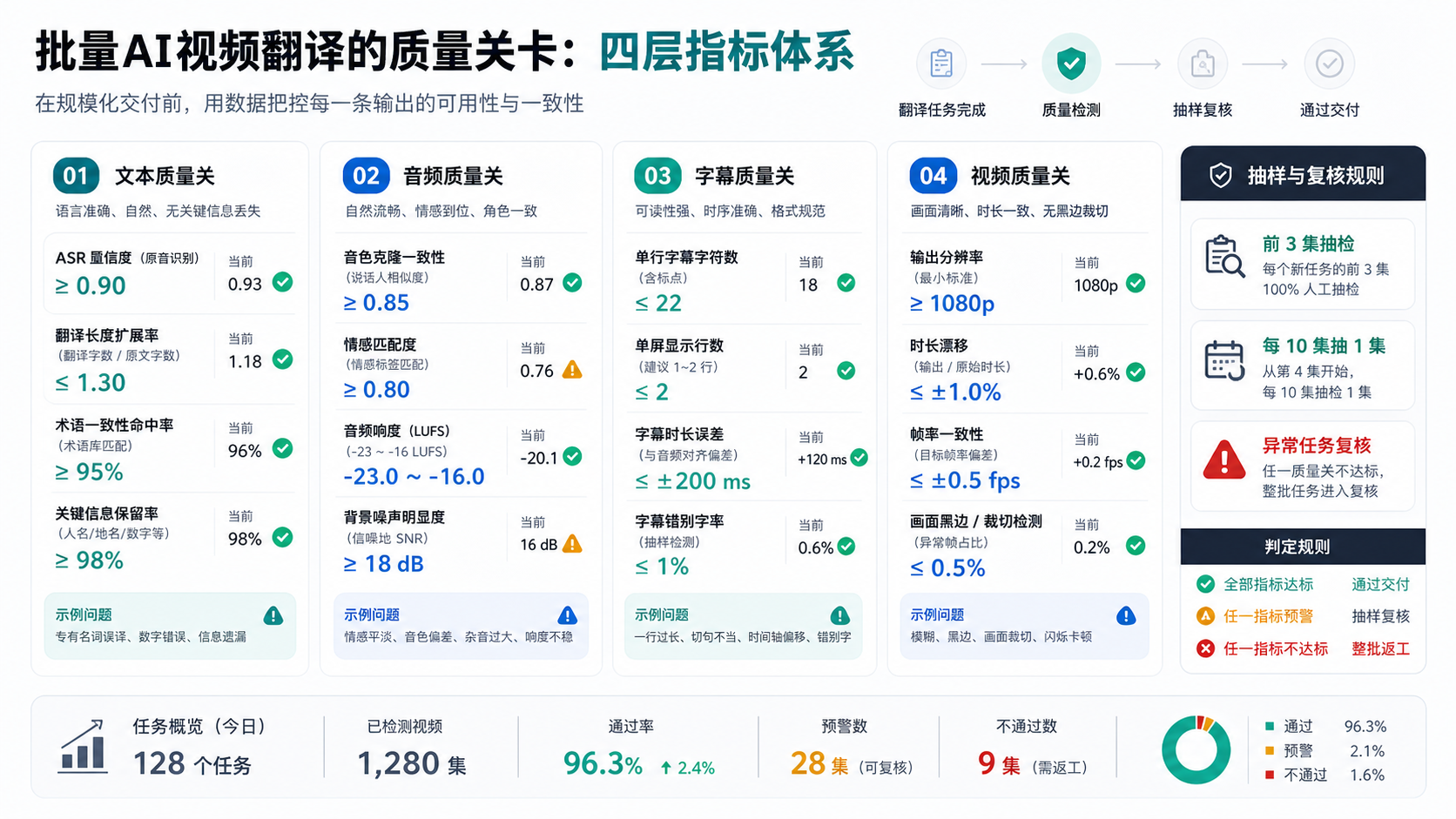
自动检测通过后,还需要抽样人工复核。建议按以下策略抽检:
-
每个语种至少抽检前 3 集。
-
每 10 集抽检 1 集完整成片。
-
所有异常重跑任务必须人工看 30 秒以上。
-
主角首次出场、情绪爆发、多人对话片段优先抽检。
这里有一个经验:质量检测不要只看最终视频,也要保存中间产物。 ASR、翻译字幕、配音音频、角色映射、硬字幕擦除后视频都应该可回溯。否则一旦客户反馈"第 37 集日语版第三分钟声音不对",团队很难定位到底是识别错、翻译错、配音错,还是合成错。
六、交付设计:输出文件要服务审核和复用
短剧出海项目的交付物不应该只有一个 .mp4。对于 80 集 × 3 语种的任务,推荐按以下目录组织:
deliverables/ ja-JP/ mp4_dubbed/ E001.ja-JP.dubbed.mp4 mp4_subtitled/ E001.ja-JP.subtitled.mp4 srt/ E001.ja-JP.srt audio/ E001.ja-JP.mp3 en-US/ mp4_dubbed/ mp4_subtitled/ srt/ audio/ vi-VN/ mp4_dubbed/ mp4_subtitled/ srt/ audio/ reports/ quality_report.csv failed_tasks.json manifest.final.json
命名规范非常关键。不要用"第一集英文版最终最终.mp4"这种人工命名方式。建议固定格式:
{episode_id}.{language}.{artifact_type}.{ext} 示例: E001.en-US.dubbed.mp4 E001.en-US.subtitle.srt E001.en-US.voice.mp3
字幕文件要和视频保持同一套 episode_id 和 language code。这样后续无论进入广告投放、海外平台上传、二次剪辑,还是人工审核,都能快速匹配。
如果需要把字幕烧录到视频里,可以用 FFmpeg 做最终压制:
ffmpeg -y \ -i E001.clean.mp4 \ -vf "subtitles=E001.en-US.srt:force_style='FontName=Arial,FontSize=18'" \ -c:a copy \ E001.en-US.subtitled.mp4
注意,字幕压制前要先确认字体、字号、描边、底部安全区和移动端可读性。短剧经常是竖屏视频,底部同时有字幕、平台 UI 和互动按钮,字幕位置不能只按传统横屏视频习惯处理。
七、一个平台实践:把单点能力合成工程链路
在一个短剧出海项目中,我们验证过一个匿名化的视频翻译平台。它的工程价值不在于单独做 ASR、翻译或 TTS,而是把源视频提交、多角色识别、AI 视频翻译、AI 配音、字幕生成、字幕压制、硬字幕擦除和多格式导出连接成一条链路。
这个链路对 80 集短剧尤其关键。因为短剧不是单条广告片,角色会跨集出现,语气和称呼需要保持一致,字幕样式也要统一。如果每一集都靠不同工具手动拼接,最终最容易出问题的不是 AI 能力,而是文件版本、时间轴和返工管理。
这类平台更适合以下场景:
-
已经有一批中文短剧素材,需要持续翻译成多语种版本。
-
视频里存在中文硬字幕,需要先擦除再重新压制目标语言字幕。
-
剧集中有多角色对白,需要尽量保持角色声音和情绪一致。
-
团队需要同时交付视频、音频、SRT 和质检报告。
上面提到的平台实践,对应的是 VividDub 的一站式视频本地化工作流。它适合的不是一次性手工剪辑,而是把视频翻译、配音、字幕和交付做成可复用的工程流程。
对于开发者或技术团队,可以从公开仓库了解它的产品和工作流入口:
VividDub GitHub: https://github.com/VividDub-io/VividDub VividDub Website: https://vividdub.com/
八、总结:批量视频翻译要先设计工程系统,再选择模型
短剧出海的视频翻译技术方案,不能只按"识别模型 + 翻译模型 + 配音模型"来理解。模型只是其中一部分,真正决定交付稳定性的,是前期评估、打样验证、批量调度、质量检测、异常回退和多格式交付。
如果要把一部 80 集中文短剧翻译成日语、英语、越南语三个版本,建议按以下顺序推进:
-
先做输入评估,确认硬字幕、角色、音频和文件规范。
-
再用第一集前 30 秒跑通全链路,明确需要人工审核的节点。
-
批量生产时按"剧集任务 + 语种子任务"拆分,不把 240 个版本当成一个大任务。
-
用质量阈值自动拦截明显异常,再用人工抽检处理主观体验问题。
-
交付时保留视频、音频、SRT 和质量报告,让后续复剪和返工可追溯。
AI 视频翻译的工程价值,不是让人完全不参与,而是把重复、易错、难追踪的环节系统化。 对短剧出海团队来说,这比单次翻译效果更重要。
参考资料: FFmpeg Documentation OpenAI Whisper GitHub Repository Introducing Whisper VividDub GitHub Repository