


目录
[2.1. 文档](#2.1. 文档)
[2.2. 倒排索引](#2.2. 倒排索引)
[2.3. 分词](#2.3. 分词)
[4.1. 标准执行流程](#4.1. 标准执行流程)
[4.2. 核心类设计](#4.2. 核心类设计)
[4.3. Parser 类](#4.3. Parser 类)
[1. 递归枚举文件](#1. 递归枚举文件)
[2. HTML 文档解析](#2. HTML 文档解析)
[4.4. Index 类](#4.4. Index 类)
[4.5. DocInfo 类](#4.5. DocInfo 类)
[4.6. Weight 类](#4.6. Weight 类)
一、项目简介
本项目是基于 Java+SpringBoot 开发的简易 Java API 文档搜索引擎,核心目标是实现对 JDK 17 官方 API 文档的高效检索,用户输入查询词即可获取包含标题、描述、链接的搜索结果,并可跳转至对应官方文档页面。项目摒弃了效率低下的暴力搜索方式,采用搜索引擎核心的倒排索引,搭配正排索引实现文档与关键词的双向映射;整体分为索引、搜索、Web三大核心模块,索引模块负责扫描本地 HTML 格式的 Java API 文档,通过 ansj 分词库完成英文分词,构建并持久化正排、倒排索引,还借助线程池优化索引构建速度,同时用正则清理 HTML 标签、剔除无效脚本内容;搜索模块加载索引后,对查询词分词、过滤停用词,通过多路归并合并多关键词权重并按权重排序,生成带关键词标红的摘要结果;Web 模块通过 SpringBoot 提供搜索接口,搭配简易前端页面实现可视化搜索交互,最终完成轻量化、可交互的Java API文档检索功能。
二、核心概念
2.1. 文档
JDK 8 官方 API 文档的本地 HTML 文件,存储路径:D:\doc_search_index\docs\api\java.base\java。本地每个.html文件,唯一对应 Oracle 官方 Java 8 API 在线文档页面,比如 java.util.ArrayList.html。每一个独立的.html文件,经预处理后即为一个独立文档。
2.2. 倒排索引
倒排索引是现代搜索引擎中最核心的数据结构。它的设计目的非常直接:实现从"词汇"到"文档"的极速映射,从而支持高效的全文本搜索。正向索引以文档为主键,就像是一本书的目录,记录了"哪个文档里包含了哪些内容",其映射关系为文档 ID -> 文档内容 -> 包含的词汇,缺点是如果用户想搜索某个特定的词汇,系统必须遍历所有文档的内容去进行匹配,这在海量数据下是不可接受的,时间复杂度极高;而倒排索引以词汇为主键,就像是一本书最后的索引附录页,记录了"这个词汇出现在了哪些页面上",其映射关系为词汇 -> 包含该词汇的文档 ID 列表,优点是搜索时只需查找词典,直接取出对应的文档 ID 列表,时间复杂度极低。
2.3. 分词
分词是将连续文本拆分为有意义的最小词汇单元(term)的过程,是搜索引擎的核心基础操作。核心作用是为后续的倒排索引构建、词频统计、权重计算、查询匹配提供基础。
使用 ansj_seg 分词库完成分词,英文分词会自动转为小写。并且会覆盖文档标题、文档正文、用户输入的查询词三类文本。
XML
<!--分词依赖-->
<dependency>
<groupId>org.ansj</groupId>
<artifactId>ansj_seg</artifactId>
<version>5.0.4</version>
<scope>compile</scope>
</dependency>代码示例:
java
package com.yang.java_doc_searcher.searcher;
import org.ansj.domain.Term;
import org.ansj.splitWord.analysis.ToAnalysis;
import java.util.List;
public class Parser {
public static void main(String[] args) {
String str = "The story of Google began in 1995 " +
"with the meeting of two Stanford University " +
"graduate students, Larry Page and Sergey Brin.";
List<Term> terms = ToAnalysis.parse(str).getTerms();
for (Term term : terms) {
System.out.print(term.getName() + "/");
}
}
}
三、核心流程
- 索引模块:扫描本地 Java API 文档→解析 HTML→构建正排 + 倒排索引→持久化到文件。
- 搜索模块:加载索引→查询词分词→查倒排索引→结果排序→返回搜索结果。
- Web 模块:提供搜索接口 + 前端页面,展示结果并跳转官方 API 文档。
四、索引模块
4.1. 标准执行流程
- 枚举文件 :递归扫描指定目录,收集所有
.html文档。 - 解析文档:提取每个 HTML 的标题、在线 URL、纯文本正文(去标签)。
- 构建索引:先建正排索引,再基于分词结果建倒排索引。
- 持久化存储:将索引写入磁盘文件,避免重复构建。
4.2. 核心类设计
- Parser:索引构建的入口执行类,负责文件枚举、HTML 解析、调用 Index 完成索引构建与保存。
- Index:索引核心管理类,维护正排 / 倒排索引,提供增、查、存、加载的核心方法。
- DocInfo:正排索引实体类,存储单篇文档的完整信息。
- Weight:倒排索引权重实体类,存储词对应的文档 ID 与权重值。
4.3. Parser 类
1. 递归枚举文件
首先,递归遍历配置的文档根目录 JDK 8 API 的 api 目录,接着仅收集后缀为 .html 的文件,过滤非文档文件与目录。
java
package com.yang.java_doc_searcher.searcher;
import java.io.File;
import java.util.ArrayList;
/**
* @author gao
* @date 2026/4/20 15:15
*/
public class Parser {
// 要搜索的根目录路径
private static final String INPUT_PATH = "D:/doc_search_index/docs/api";
public void run() {
ArrayList<File> fileList = new ArrayList<>();
enumFile(INPUT_PATH, fileList);
System.out.println(fileList);
}
/**
* 递归枚举指定路径下的所有 HTML 路径
* @param inputPath 要搜索的目录路径
* @param fileList 将找到的 HTML 文件路径添加到里面
*/
private void enumFile(String inputPath, ArrayList<File> fileList) {
// 路径转为 File 对象
File rootPath = new File(inputPath);
// 获取目录下的所有文件和子目录
File[] files = rootPath.listFiles();
for (File f : files) {
// 如果是目录,继续递归
if (f.isDirectory()) {
enumFile(f.getAbsolutePath(), fileList);
} else {
// 如果是 .html 文件,则添加进顺序表中
if (f.getAbsolutePath().endsWith(".html")) {
fileList.add(f);
}
}
}
}
public static void main(String[] args) {
Parser parser = new Parser();
parser.run();
}
}2. HTML 文档解析
java
public void run() {
ArrayList<File> fileList = new ArrayList<>();
enumFile(INPUT_PATH, fileList);
for (File f : fileList) {
// 解析 HTML 文件
System.out.println("开始解析:" + f.getAbsolutePath());
parseHTML(f);
}
}
private void parseHTML(File f) {
// 1. 解析标题
String title = parseTitle(f);
// 2. 解析 URL
String url = parseURL(f);
// 3. 解析正文
String content = parseContent(f);
}- 解析标题
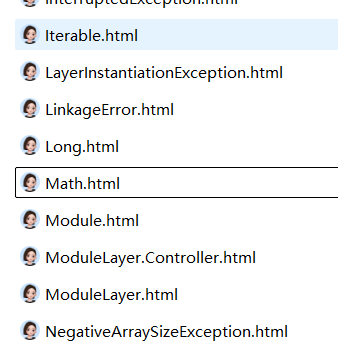
我们查看下几个文件里的内容,可以看出 .html 之前的内容就是我们想要获取的标题。我们使用 getName() 方法得到文件名,由于获取的文件都有 .html 后缀,再通过 subString() 去除即可。

java
/**
* 从文件名中解析出标题并去掉文件扩展名
* @param f 要解析的文件对象
* @return 返回去掉扩展名的文件名作为标题
*/
private String parseTitle(File f) {
String tmp = f.getName();
String title = tmp.substring(0, tmp.length() - 5);
return title;
}- 解析 URL
我们对比本地的文档路径与 Oracle 官网的 URL,可以发现,我们只需将本地文档路径前面的部分替换为 Oracle 官网再拼接即可。
java
/**
* 解析文件路径并构建完整URL链接
* 该方法将本地文件路径转换为Oracle Java文档API的URL格式
* @param f 要解析的文件对象
* @return 完整的URL字符串
*/
private String parseURL(File f) {
String part1 = "https://docs.oracle.com/javase/8/docs/api/";
String part2 = f.getAbsolutePath().substring(INPUT_PATH.length());
return part1 + part2;
}- 解析文本
java
/**
* 解析文件内容,跳过HTML标签内的内容
* @param f 要解析的文件对象
* @return 解析后的纯文本内容
*/
private String parseContent(File f) {
try (FileReader fileReader = new FileReader(f)) {
boolean isCopy = true;
StringBuilder content = new StringBuilder();
while (true) {
int ret = fileReader.read();
// 到达文件末尾,停止读取
if (ret == -1) {
break;
}
char ch = (char) ret;
if (isCopy) {
// 遇到开始符号
if (ch == '<') {
// 停止复制,跳过当前字符
isCopy = false;
continue;
}
content.append(ch);
} else {
// 遇到结束符号恢复复制
if (ch == '>') {
isCopy = true;
}
}
}
return content.toString();
} catch (IOException e) {
throw new RuntimeException(e);
}
}4.4. Index 类
Parser 把解析好的文档交给 Index,Index 负责把文档变成可检索的索引;搜索模块需要查数据时,直接调用 Index 的查询方法即可。
我们需要利用正排索引,通过文档索引来获取文档的信息,这里我们可以使用 ArrayList 来进行存储文档,并通过 get() 方法快速通过下标访问。当对输入的查询词进行分词之后,再通过 HashMap 进行快速映射,瞬间找到所有包含这个词的文档。
java
package com.yang.java_doc_searcher.searcher;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
public class Index {
// 下标 = docId,支持通过文档 ID 快速查文档信息
private ArrayList<DocInfo> forward = new ArrayList<>();
// Key 为分词后的词(英文自动小写),Value 为该词对应的文档权重列表
private HashMap<String, ArrayList<Weight>> forwardIndex = new HashMap<>();
// 1. 根据 docId 查询正排索引,返回文档详情
public DocInfo getDocInfo(int docId) {
}
// 2. 根据分词查询倒排索引,返回对应文档权重列表
public List<Weight> getInverted(String term) {
}
// 3. 新增文档,触发正排 + 倒排索引构建
public void addDoc(String title, String url, String content) {
}
// 4. 将索引序列化为 JSON,写入磁盘文件
public void save() {
}
// 5. 从磁盘加载索引文件到内存
public void load() {
}
}
java
/**
* 根据文档 ID 获取文档信息
* @param docId 文档索引
* @return 包含文档的信息
*/
public DocInfo getDocInfo(int docId) {
return forwardIndex.get(docId);
}
/**
* 根据给定的词条获取倒排索引列表
* 从倒排索引中检索与指定词条关联的所有权重信息
* @param term 给定的词条
* @return 返回与该词条关联的权重列表
*/
public List<Weight> getInverted(String term) {
return invertedIndex.get(term);
}Parser 解析完文档后,调用 addDoc() 方法,把「标题、URL、正文」交给 Index 构建索引。
java
/**
* 新增文档,自动构建正排+倒排索引
* @param title 标题
* @param url 在线 URL
* @param content 纯文本内容
*/
public void addDoc(String title, String url, String content) {
DocInfo doc = buildForward(title, url, content);
buildInverted(doc);
}buildForward() 把文档的标题、URL、正文封装成 DocInfo 对象,加入正排索引,自动分配文档 ID(docId)。
java
private DocInfo buildForward(String title, String url, String content) {
DocInfo doc = new DocInfo();
doc.setDocId(forwardIndex.size());
doc.setTitle(title);
doc.setUrl(url);
doc.setContent(content);
forwardIndex.add(doc);
return doc;
}buildInverted() 对文档的标题、正文分词 → 统计词频 → 计算权重 → 把「词→文档」写入倒排索引。
java
private void buildInverted(DocInfo doc) {
class WordCount {
// 词条在标题中出现的次数
public int titleCount;
// 词条在文本内容中出现的次数
public int contentCount;
}
HashMap<String, WordCount> wordCountHashMap = new HashMap<>();
// 对文档标题进行分词处理
List<Term> terms = ToAnalysis.parse(doc.getTitle()).getTerms();
for (Term term : terms) {
String word = term.getName();
WordCount wordCount = wordCountHashMap.get(word);
// 如果词不存在,则创建新的 WordCount 对象
if (wordCount == null) {
WordCount newWordCount = new WordCount();
newWordCount.titleCount = 0;
newWordCount.contentCount = 1;
wordCountHashMap.put(word, newWordCount);
} else {
wordCount.contentCount++;
}
}
// 遍历哈希表中的每个词条
for (Map.Entry<String, WordCount> entry : wordCountHashMap.entrySet()) {
List<Weight> invertedList = invertedIndex.get(entry.getKey());
if (invertedList == null) {
ArrayList<Weight> newInvertedList = new ArrayList<>();
Weight weight = new Weight();
weight.setDocId(doc.getDocId());
weight.setWeight(entry.getValue().titleCount * 10 + entry.getValue().contentCount);
newInvertedList.add(weight);
invertedIndex.put(entry.getKey(), newInvertedList);
} else {
Weight weight = new Weight();
weight.setDocId(doc.getDocId());
weight.setWeight(entry.getValue().titleCount * 10 + entry.getValue().contentCount);
invertedList.add(weight);
}
}分词后统一小写:搜索 String 和 string 能查到相同结果。权重倾斜:标题权重远高于正文,保证标题匹配的文档排前面。
save() 把内存中的正排 / 倒排索引,序列化成 JSON 写入磁盘,下次启动直接加载,不用重新解析文档。
java
/**
* 保存索引信息到文件
* 将正排索引和倒排索引分别保存到指定路径的文本文件中
*/
public void save() {
System.out.println("保存索引开始");
File indexPathFile = new File(INDEX_PATH);
if (!indexPathFile.exists()) {
indexPathFile.mkdirs();
}
// 正排索引文件对象
File forwardIndexFile = new File(INDEX_PATH + "forward.txt");
// 倒排索引文件对象
File invertedIndexFile = new File(INDEX_PATH + "inverted.txt");
try {
// 将 Java 对象(ArrayList 和 HashMap)转换为 JSON 格式的字符串,并写入到指定的文件中
objectMapper.writeValue(forwardIndexFile, forwardIndex);
objectMapper.writeValue(invertedIndexFile, invertedIndex);
} catch (IOException e) {
throw new RuntimeException(e);
}
}load() 在程序启动时,从磁盘读取 JSON 文件,反序列化成内存索引,秒级加载。
java
/**
* 加载索引,从文件中读取正排索引和倒排索引数据
*/
public void load() {
System.out.println("加载索引开始!");
// 正排索引文件对象
File forwardIndexFile = new File(INDEX_PATH + "forward.txt");
// 倒排索引文件对象
File invertedIndexFile = new File(INDEX_PATH + "inverted.txt");
try {
// 将 JSON 格式的字符串转换为 Java 对象(ArrayList 和 HashMap),并加载到内存中
forwardIndex = objectMapper.readValue(forwardIndexFile, new TypeReference<ArrayList<DocInfo>>() {});
invertedIndex = objectMapper.readValue(invertedIndexFile, new TypeReference<HashMap<String, ArrayList<Weight>>>() {});
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("加载索引结束!");
}4.5. DocInfo 类
java
package com.yang.java_doc_searcher.searcher;
import lombok.Getter;
import lombok.Setter;
@Getter
@Setter
public class DocInfo {
private int docId;
private String title;
private String url;
private String content;
}4.6. Weight 类
java
package com.yang.java_doc_searcher.searcher;
import lombok.Getter;
import lombok.Setter;
@Getter
@Setter
public class Weight {
private int docId;
// 表示文档和词之间的关联性
// 值越大,相关性越强
private int weight;
}