 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
- 引言
-
- 一、Preliminaries:四层架构与"记忆"的定义
-
- [1.1 总体架构:四层同构](#1.1 总体架构:四层同构)
- [1.2 "记忆"的最小形式化](#1.2 "记忆"的最小形式化)
- 二、接口设计:三层同构
-
- [2.1 `MemoryBase` 抽象:五个最小动作](#2.1
MemoryBase抽象:五个最小动作) - [2.2 `Memory` 实类:核心八方法](#2.2
Memory实类:核心八方法) - [2.3 `filters` DSL:一种克制的查询语言](#2.3
filtersDSL:一种克制的查询语言) - [2.4 REST 接口(`server/main.py`)](#2.4 REST 接口(
server/main.py)) - [2.5 `VectorStoreBase`:写入/读出的通用抽象](#2.5
VectorStoreBase:写入/读出的通用抽象) -
- [2.6 Provider 可插拔层:`Factory.provider_to_class`](#2.6 Provider 可插拔层:
Factory.provider_to_class)
- [2.6 Provider 可插拔层:`Factory.provider_to_class`](#2.6 Provider 可插拔层:
- [2.1 `MemoryBase` 抽象:五个最小动作](#2.1
- [三、写入链路:`add()` 里的九个 Phase](#三、写入链路:
add()里的九个 Phase) -
- [3.1 `infer=False` 快速通道](#3.1
infer=False快速通道) - [3.2 更新 / 删除的图同步清理](#3.2 更新 / 删除的图同步清理)
- [3.1 `infer=False` 快速通道](#3.1
- [四、读取链路:`search()` 的三路融合](#四、读取链路:
search()的三路融合) - [五、实体--记忆二部图:Mem0 的"图"到底是什么](#五、实体–记忆二部图:Mem0 的"图"到底是什么)
-
-
- [5.1 数据模型:两个集合,一张二部图](#5.1 数据模型:两个集合,一张二部图)
- [5.2 实体抽取:四类模式 + 屏蔽词表](#5.2 实体抽取:四类模式 + 屏蔽词表)
- [5.3 写入链路上的图操作(Phase 7 展开)](#5.3 写入链路上的图操作(Phase 7 展开))
- [5.4 读取链路上的图操作(Step 6 展开)](#5.4 读取链路上的图操作(Step 6 展开))
- [5.5 为何不直接上 Neo4j?](#5.5 为何不直接上 Neo4j?)
-
- [六、历史与幂等:SQLite 两张表撑住一切](#六、历史与幂等:SQLite 两张表撑住一切)
- 七、收益归因:为什么四项指标可以同时变好
- 结语:几个核心判断
引言
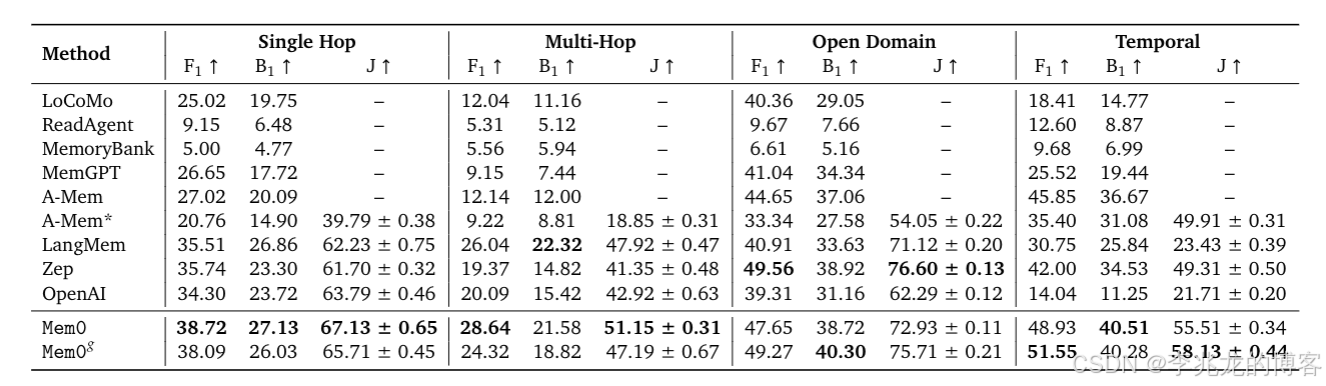
近一年 Agent Memory 相关工作扎堆出现,讨论常常卡在两种极端:要么"全上下文就是最好的记忆",要么"上个向量库检索最近 K 条就叫记忆"。
Mem0 给出的答案比较朴素------把记忆系统看作一条写入流水线和一条读取流水线,把决策权交还给 LLM,但把所有结构化动作留在代码里 。这套取舍让它在 LOCOMO 基准上对 full-context 方案 J 分数仅落后 ~6 点,却拿到 91% 的 p95 延迟下降和 90%+ 的 Token 节省 ,同时图记忆 Mem0g 的构建时间被压到分钟级。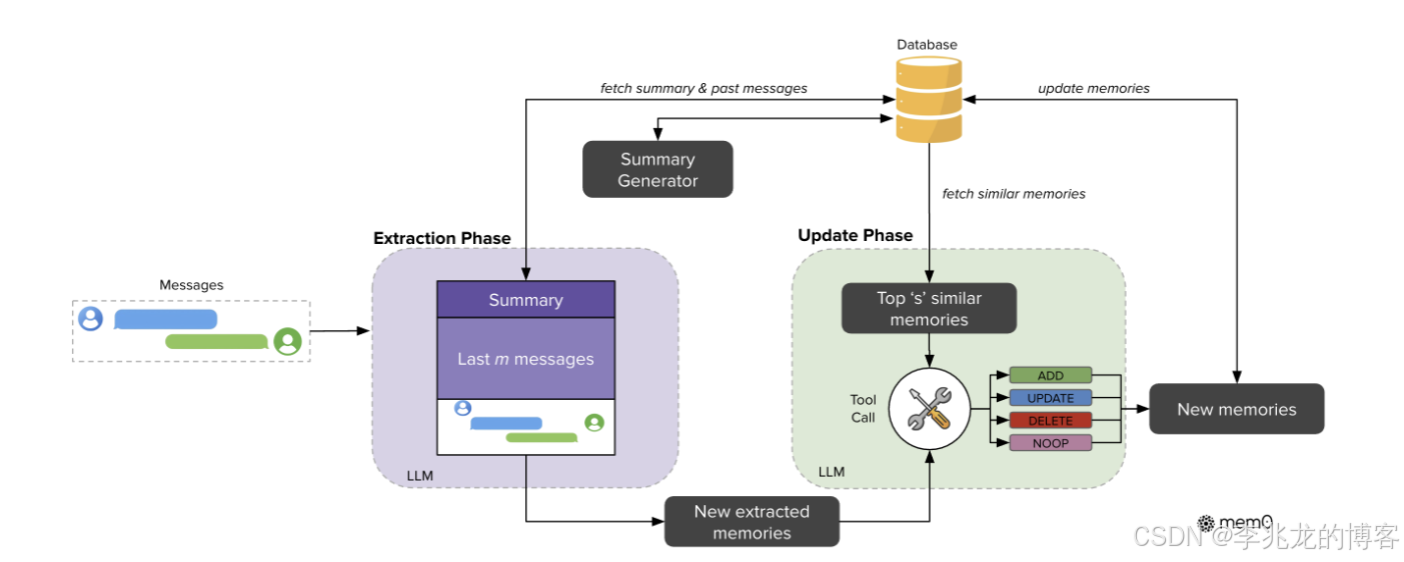
本文按"总体架构 / 接口 / 写入链路 / 读取链路 / 实体-记忆二部图 / 收益归因 / 生产部署"七块展开,每一节尝试回答三个问题:这层接口解决了什么、难点在哪里、它为什么会让指标同时变好。
一、Preliminaries:四层架构与"记忆"的定义
1.1 总体架构:四层同构
读懂 Mem0 首先得把它的四层结构画清楚。源码里虽然目录零碎,但整体可以切成"接入层 / 核心编排层 / Provider 可插拔层 / 底层存储"四层------上层的 30 个向量库、24 个 LLM、15 个 Embedding 的排列组合,全部在 Memory 这一层归一:
┌─────────────────────────────────────────────────────────────────┐
│ 接入层 Entry/Protocol │
│ REST : server/main.py (FastAPI + X-API-Key) │
│ MCP : openmemory/api/ , mem0-plugin/ , mcp.mem0.ai │
│ SDK : mem0(Py) / mem0-ts(TS) CLI: cli/python / cli/node │
│ 集成 : vercel-ai-sdk / openclaw / cookbooks │
└─────────────────────────────────────────────────────────────────┘
│ 所有接入最终落到 Memory
▼
┌─────────────────────────────────────────────────────────────────┐
│ 核心编排层 Memory (mem0/memory/main.py) │
│ Memory / AsyncMemory │
│ _add_to_vector_store --- V3 分阶段批处理写入流水线 │
│ _search_vector_store --- 三路混合检索 (semantic+BM25+图) │
│ storage.py SQLiteManager (history / messages) │
│ utils.py 消息解析 / 视觉消息 / JSON 提取 │
│ configs/prompts.py 事实抽取 / 记忆更新提示词 │
└─────────────────────────────────────────────────────────────────┘
│ Factory 装配具体 Provider
▼
┌─────────────────────────────────────────────────────────────────┐
│ Provider 可插拔层 (mem0/utils/factory.py) │
│ LlmFactory(24) / EmbedderFactory(15) │
│ VectorStoreFactory(30) / RerankerFactory(5) │
└─────────────────────────────────────────────────────────────────┘
│ 统一 base.py 抽象
▼
┌─────────────────────────────────────────────────────────────────┐
│ 底层存储 Storage │
│ Vector : pgvector / Qdrant / Pinecone / Milvus / Chroma / ... │
│ History: SQLite (~/.mem0/history.db) │
│ LLM API: OpenAI / Anthropic / Bedrock / Gemini / Ollama... │
└─────────────────────────────────────────────────────────────────┘关键观察 :这四层里,真正独特的代码 90% 在第二层(mem0/memory/*.py)。向量库、LLM、Embedding 只是把各家 SDK 包一层 base.py 的抽象 ------ Mem0 的价值几乎完全来自核心编排层里那两条流水线的设计。
1.2 "记忆"的最小形式化
论文里 Mem0 的形式化其实很克制:只要维护一个可以被 add / search / update / delete 的事实集合 Ω,每次新来一对消息 ( m t − 1 , m t ) (m_{t-1}, m_t) (mt−1,mt) 就跑一次 extraction → update 两阶段流水线。一条记忆长这样(见 mem0/configs/base.py::MemoryItem):
python
class MemoryItem(BaseModel):
id: str
memory: str # 抽取出的事实文本(自然语言)
hash: Optional[str] # md5(memory),用于幂等
metadata: Optional[Dict]
score: Optional[float]
created_at: Optional[str]
updated_at: Optional[str]核心配置 MemoryConfig 同样极简:
python
class MemoryConfig(BaseModel):
vector_store: VectorStoreConfig # 向量库
llm: LlmConfig # 事实抽取/决策用 LLM
embedder: EmbedderConfig # 向量化模型
history_db_path: str = "~/.mem0/history.db"
reranker: Optional[RerankerConfig] # 可选重排
version: str = "v1.1"
custom_instructions: Optional[str] # 自定义事实抽取指令三个设计选择要先挑出来讲,后面所有性能收益都是它们的副产物:
| 选择 | 工程含义 | 后续影响 |
|---|---|---|
| memory 是自然语言短事实 | 不存 embedding,不存片段,不存摘要树 | Token 低、语义紧、可被 LLM 直接消费 |
| hash = md5(memory) | 天然幂等 | 重复 add 不会重复写入,写入吞吐稳定 |
以 session scope 隔离 (user_id/agent_id/run_id) |
一条记忆属于一个会话主体 | filter 下推到向量库,搜索域天然缩小 |
对比 Zep 之类把全量摘要缓存在每个图节点上 的方案:Zep 的图构建出来大约要 60 万 Token 每会话 (原始对话才 26k),Mem0 只要 7k,Mem0g 也只要 14k。差距不是来自更好的压缩算法,而是来自"什么不该存"的判断。
二、接口设计:三层同构
Mem0 的接口被刻意做成三层同构 ------ Python SDK、REST、托管平台 MemoryClient 参数几乎一一对应。同构的好处是开发阶段用本地 Memory,上线切 REST,迁移到托管只改 base url,不动业务代码。
2.1 MemoryBase 抽象:五个最小动作
mem0/memory/base.py 把最小面暴露得极干净:
python
class MemoryBase(ABC):
@abstractmethod
def get(self, memory_id): ...
@abstractmethod
def get_all(self): ...
@abstractmethod
def update(self, memory_id, data): ...
@abstractmethod
def delete(self, memory_id): ...
@abstractmethod
def history(self, memory_id): ...注意抽象层没有 add 和 search ,这两个是实现类自行提供的------因为它们不是 CRUD,而是完整的两条流水线。这个划分和论文里 "extraction/update 是独立阶段" 的叙事完全一致。
2.2 Memory 实类:核心八方法
实际落地的 Memory / AsyncMemory 在 mem0/memory/main.py,核心八个方法全部带 keyword-only 参数,签名如下(省略 AsyncMemory):
| 方法 | 签名要点 | 作用 |
|---|---|---|
add |
add(messages, *, user_id, agent_id, run_id, metadata, infer=True, memory_type=None, prompt=None) |
写入入口;infer=True 走 LLM 抽取,False 走直写 |
search |
search(query, *, top_k=20, filters, threshold=0.1, rerank=False) |
混合检索(semantic + BM25 + entity boost) |
get |
get(memory_id) |
单条查询 |
get_all |
get_all(*, filters, top_k=20) |
按 filters 列出 |
update |
update(memory_id, data, metadata=None) |
重算 embedding,记录 history,刷新实体边 |
delete |
delete(memory_id) |
向量删除 + history 留痕 + 实体摘除 |
delete_all |
delete_all(user_id, agent_id, run_id) |
按会话维度批量删 |
history |
history(memory_id) |
返回该记忆的 ADD/UPDATE/DELETE 流水 |
两个约束要特别拎出来讲,因为它们直接决定了生产环境的健壮性:
user_id / agent_id / run_id至少提供一个 。源码里_build_filters_and_metadata校验。search / get_all必须通过filters={...}传入 ,顶层 kwargs 会被_reject_top_level_entity_params拒绝:
python
def _reject_top_level_entity_params(kwargs, method_name):
invalid_keys = ENTITY_PARAMS & set(kwargs.keys())
if invalid_keys:
raise ValueError(
f"Top-level entity parameters {invalid_keys} are not supported in {method_name}(). "
f"Use filters={{'user_id': '...'}} instead."
)这两条约束的工程意义是:所有入口都必须在编译期把作用域定死,搜索空间在进入向量库之前就已经被 filter 下推切掉------这是后面延迟能做到 p95 200ms 的主要原因。
2.3 filters DSL:一种克制的查询语言
search.filters 支持一套小型 DSL(_process_metadata_filters):
python
filters = {
"user_id": "u1",
"AND": [{"category": {"in": ["food", "music"]}},
{"score": {"gte": 0.7}}],
"OR": [{"status": "active"}, {"status": "pending"}],
"NOT": [{"archived": True}],
"tag": "*", # 通配
"amount": {"gt": 100, "lte": 500},
}操作符:eq / ne / gt / gte / lt / lte / in / nin / contains / icontains;逻辑:AND / OR / NOT。Mem0 负责把同一份 DSL 翻译成 pgvector / Qdrant / Pinecone 等各自的原生语法。这一层是"同构"的关键:同一段检索代码无论换哪个向量库都不用改。
2.4 REST 接口(server/main.py)
一共十条路由,和 SDK 几乎逐一对齐:
| 方法 | 路径 | 对应 SDK | Body / Query |
|---|---|---|---|
| POST | /configure |
热更新 MemoryConfig |
JSON |
| POST | /memories |
add |
messages, user_id/agent_id/run_id, metadata, infer, memory_type, prompt |
| GET | /memories |
get_all |
user_id / agent_id / run_id |
| GET | /memories/{id} |
get |
--- |
| POST | /search |
search |
query, user_id/agent_id/run_id, filters, top_k, threshold |
| PUT | /memories/{id} |
update |
{text, metadata?} |
| GET | /memories/{id}/history |
history |
--- |
| DELETE | /memories/{id} |
delete |
--- |
| DELETE | /memories |
delete_all |
user_id / agent_id / run_id |
| POST | /reset |
reset |
--- |
鉴权实现(verify_api_key):
- 未设置
ADMIN_API_KEY→ 所有接口开放(仅告警); - 设置后 → 请求必须携带
X-API-Key,服务器用secrets.compare_digest做恒定时间比较。
这种"只把 SDK 封成 HTTP"的做法,使得本地 Memory 和远端 Memory 在测试/压测里的行为曲线可以直接对比,对调优极其重要。
2.5 VectorStoreBase:写入/读出的通用抽象
Mem0 能支持 30 种向量库的真正原因在 mem0/vector_stores/base.py。每个 Provider 都统一实现:
| 方法 | 作用 |
|---|---|
insert(vectors, ids, payloads) |
批量写入 |
update(vector_id, vector, payload) |
更新单条 |
delete(vector_id) / delete_col() / reset() |
删除/重置集合 |
get(vector_id) |
按 ID 取回 |
list(filters, top_k) |
过滤列表 |
search(query, vectors, top_k, filters) |
语义检索 |
keyword_search(query, top_k, filters) |
关键词/BM25 检索(若不支持则返回 None) |
search_batch(queries, vectors_list, top_k, filters) |
批量向量检索 |
这 8 个方法是写入/读出链路得以通用的关键抽象------图层也是用这一套接口实现的(下文第五节会详细讲)。
2.6 Provider 可插拔层:Factory.provider_to_class
python
# mem0/utils/factory.py
class LlmFactory:
provider_to_class = {
"openai": ("mem0.llms.openai.OpenAILLM", OpenAIConfig),
"anthropic": ("mem0.llms.anthropic.AnthropicLLM", AnthropicConfig),
...
}同样的模式复制到 EmbedderFactory / VectorStoreFactory / RerankerFactory。新增一个 provider 的成本固定为"一个文件 + 一行注册",是 Mem0 能在工程上快速扩散的前提。
三、写入链路:add() 里的九个 Phase
这是 Mem0 性能收益最集中的地方。Memory._add_to_vector_store 在 V3 流水线里把一次 add 拆成了九个阶段,核心意图是"把所有串行依赖做成批处理":
Phase 0 上下文聚合
- session_scope = (user_id, agent_id, run_id)
- db.get_last_messages(session_scope, limit=10)
- parse_messages(messages)
Phase 1 已有记忆召回
- embed(parsed_messages, "search")
- vector_store.search(top_k=10, filters=session_filters)
- uuid_mapping = {"0":uuid_a, "1":uuid_b, ...} 防 LLM 幻觉 ID
Phase 2 LLM 事实抽取 (单次调用)
- system_prompt = ADDITIVE_EXTRACTION_PROMPT (+ AGENT_CONTEXT_SUFFIX)
- user_prompt = generate_additive_extraction_prompt(
existing_memories, new_messages,
last_k_messages, custom_instructions)
- response = llm.generate_response(response_format={"type":"json_object"})
Phase 3 批量向量化
- embed_batch(mem_texts, "add") 失败退化到单条
Phase 4+5 去重
- md5(text) vs 已有 hashes + batch 内 seen_hashes
- lemmatize_for_bm25(text) 存入 payload.text_lemmatized
Phase 6 批量落库
- vector_store.insert(all_vectors, all_ids, all_payloads)
- db.batch_add_history(event=ADD)
Phase 7 实体-记忆二部图建边(详见第五节)
Phase 8 db.save_messages(messages, session_scope)
返回 [{id, memory, event:"ADD"}, ...]四个刻意放进这条流水线的工程抉择:
- Phase 2 的"单次 LLM 调用" 。论文 Table 2 显示 Mem0 的 p95 搜索延迟是 200ms ,是所有 memory 系统里最低的;而 A-Mem、LangMem、Zep 的构建之所以慢,大多数是因为"抽取-比对-合并"被拆成了多次独立 LLM 调用。Mem0 把召回结果和新消息一起喂给 LLM,让它在一轮里完成
ADD/UPDATE/DELETE/NOOP四元决策。 - Phase 3 / Phase 6 / Phase 7 全部 batch。哪怕写 10 条记忆也只发一次 embedding 请求和一次向量库 insert。批处理吃 GPU,对接 OpenAI 这类计费的 embedding API 也能省下 30%+ 的往返。
- uuid_mapping 防幻觉 。喂给 LLM 的现存记忆 id 永远是
"0","1","2",LLM 拿不到真实 UUID,因此不可能"编造一条不存在的记忆来 UPDATE"------这条细节是 LLM 驱动记忆管理能在生产跑起来的前提。 memory_type=procedural_memory。带agent_id时把一整段对话压缩成"过程/步骤型"单条长记忆,用于 Agent 自我学习的复用。
3.1 infer=False 快速通道
有一种场景不适合让 LLM 决策 ------ 已经在上游做了结构化抽取,只想把事实塞进库。Mem0 暴露了 infer=False:
python
if not infer:
for msg in messages:
emb = self.embedding_model.embed(msg["content"], "add")
self._create_memory(msg["content"], {msg["content"]: emb}, per_msg_meta)跳过 Phase 1/2,直接进 Phase 6。离线批量导入历史对话、做迁移、做基准测试时极其有用。
3.2 更新 / 删除的图同步清理
任何对 memory 的变更都要保证图里 linked_memory_ids 与 memory 集合最终一致。
update(memory_id, data):- 重新 embed 新文本,
vector_store.update(memory_id, new_vector, new_payload) db.add_history(UPDATE, old_text, new_text)_remove_memory_from_entity_store(memory_id, session_filters):遍历所有会话下的实体;若memory_id存在于某实体的linked_memory_ids:remaining = linked - {memory_id}- 若
remaining == []:entity_store.delete(entity_id)(孤儿实体回收) - 否则:重新 embed 实体并
entity_store.update(entity_id, vec, payload)
_link_entities_for_memory(memory_id, new_data, session_filters):对新文本重新做实体抽取并挂接回去。
- 重新 embed 新文本,
delete(memory_id):vector_store.delete→db.add_history(DELETE)→_remove_memory_from_entity_store(同上),保证无悬垂边。delete_all(user_id=..., agent_id=..., run_id=...):按 scope 取出 memories 后逐条走_delete_memory。
四、读取链路:search() 的三路融合
读取端更有意思。Mem0 不是"语义检索 top-K"这种朴素做法,而是在 _search_vector_store 里做了一次三路融合:
Step 1 预处理
query_lemmatized = lemmatize_for_bm25(query)
query_entities = extract_entities(query) # 至多 8 个 (type, text)
Step 2 embed(query, "search")
Step 3 语义检索(过取)
internal_limit = max(top_k*4, 60)
semantic = vector_store.search(vectors=..., top_k=internal_limit, filters=...)
Step 4 关键词检索
keyword = vector_store.keyword_search(query=query_lemmatized, ...)
Step 5 BM25 归一化
normalize_bm25(raw, midpoint, steepness) -> bm25_scores[id]
Step 6 实体加权(详见第五节)
Step 7/8 score_and_rank(semantic, bm25_scores, entity_boosts, threshold, top_k)
(可选) reranker.rerank(query, results, limit)三路的分工很清晰:
| 路线 | 擅长 | 不擅长 |
|---|---|---|
| 语义向量 | 概念泛化、跨语言同义 | 专有名词、时间、数字 |
| BM25 关键词 | 人名/地名/专有名词、精确匹配 | 换种说法就 miss |
| 实体加权 | 多跳问题、跨会话关联 | 一跳语义命中就够的问题反而拖慢 |
这也解释了为什么 Mem0 在 LOCOMO 的 temporal / multi-hop 两档比纯语义 RAG 高出 10 分以上------temporal 命中靠关键词 + 实体,multi-hop 靠实体图的跨记忆链接。论文 Table 1 的差距不是幻觉。
三个容易忽略的工程设计:
internal_limit = max(top_k*4, 60)过取。向量库先多拿一些候选交给融合打分,避免 BM25 或实体 boost 把高价值记忆"挤不进"初始 top-K。- 热门实体衰减(下节展开)。一个实体如果挂了 1000 条记忆,全部加同样的 boost 就等于没 boost;衰减保证"稀有关联"价值更高。
- Reranker 是可选的后置步骤 。默认
rerank=False,因为 rerank 几乎必然引入一次 LLM / cross-encoder 调用。把它做成可选开关是对"默认延迟最低"的尊重。
get(memory_id) 与 get_all(filters, top_k) 则直接走 vector_store.get / list,不做混合检索,按 filters 过滤并统一成 MemoryItem schema 返回。
五、实体--记忆二部图:Mem0 的"图"到底是什么
重要纠偏 :很多文档(包括 CLAUDE.md / README)说 "Graph Memory 需要 Neo4j / Memgraph / Kuzu / Apache AGE"。但翻当前 Python 源码 ------ 核心
Memory类根本不读MemoryConfig.graph字段,也没有任何独立的图库 Provider 实现 。docker-compose.yaml里起的 Neo4j 容器目前只是占位;grep -rn neo4j mem0/只命中exceptions.py里 Kuzu 的一个报错字符串。真正在跑的"图"只有一个 :entity_store ,由同一个向量库 Provider 的副集合
<collection>_entities承担。这是 Mem0 整个架构里最被低估但最优雅的一处设计。
5.1 数据模型:两个集合,一张二部图
┌─────────────────────┐ ┌─────────────────────────────────┐
│ memories │ │ memories_entities │
│ (主记忆集合) │ │ (实体节点集合) │
│ │ │ │
│ id = <mem_uuid> │◀───────┐ │ id = <entity_uuid> │
│ vec = emb(text) │ │ │ vec = emb(entity_text) │
│ payload { │ │ │ payload { │
│ data, hash, │ └────────│ data = "北京", │
│ user_id, │ │ entity_type = "PROPN", │
│ agent_id, │ │ linked_memory_ids = [ │
│ run_id, │ │ "<mem_uuid_1>", │
│ text_lemmatized, │ │ "<mem_uuid_2>", ... │
│ ... │ │ ], │
│ } │ │ user_id/agent_id/run_id │
└─────────────────────┘ │ } │
└─────────────────────────────────┘- 节点:每条 memory 是一个节点;每个实体(专名/复合名词/引号片段)也是一个节点。
- 边 :用
memories_entities.payload.linked_memory_ids: List[str]存 entity → memory 的邻接表。没有显式的"边表"。 - 图范围 :实体节点的
user_id/agent_id/run_id与 memory 一致,天然按会话作用域分片,跨用户不会串味。 - 实体等价判定 :在同一 scope 内,
embed(entity_text)余弦相似度 ≥ 0.95 即视为同一节点。
5.2 实体抽取:四类模式 + 屏蔽词表
mem0/utils/entity_extraction.py::extract_entities 产出 List[(entity_type, entity_text)]:
PROPN:连续首字母大写的专有名词(人名、地点、品牌)QUOTED:单/双引号包裹的字符串(标题、术语)NOUN_COMPOUND:特定修饰语 + 名词的复合词(machine learning)NOUN_FALLBACK:特定模式下退化为单名词
屏蔽通用词表:_GENERIC_HEADS / _CIRCUMSTANTIAL_MODS / _NON_SPECIFIC_ADJ / _GENERIC_ENDINGS / _GENERIC_CAPS,避免把 "thing / stuff / some" 之类词当实体。有 spaCy 则走 NLP 版(en_core_web_sm),否则走正则回退。
5.3 写入链路上的图操作(Phase 7 展开)
Phase 7 是五步批处理:
python
# Phase 7 伪代码 (mem0/memory/main.py:865-955)
all_entities = extract_entities_batch(all_texts) # 7a. 批量抽取
global_entities = {} # 7b. 跨记忆去重
for idx, (mem_id, text, vec, payload) in enumerate(records):
for etype, etext in all_entities[idx]:
key = etext.strip().lower()
if key in global_entities:
global_entities[key][2].add(mem_id) # 合并同实体的多条 memory 边
else:
global_entities[key] = [etype, etext, {mem_id}]
entity_embeddings = embed_batch([g[1] for g in ...]) # 7c. 批量 embed 实体文本
existing_matches = entity_store.search_batch( # 7d. 批量查图
queries=valid_texts, vectors_list=valid_vectors,
top_k=1, filters=session_filters)
for j, key in enumerate(valid_keys):
matches = existing_matches[j]
if matches and matches[0].score >= 0.95: # 7e-命中: 老节点合边
linked = set(matches[0].payload["linked_memory_ids"])
linked |= memory_ids_for_this_entity
entity_store.update(vector_id=matches[0].id, vector=None,
payload={..., "linked_memory_ids": sorted(linked)})
else: # 7e-未命中: 新节点
to_insert_vectors.append(...)
to_insert_ids.append(uuid.uuid4())
to_insert_payloads.append({
"data": etext, "entity_type": etype,
"linked_memory_ids": sorted(memory_ids_for_this_entity),
**session_filters,
})
entity_store.insert(vectors=to_insert_vectors, # 批量写新节点
ids=to_insert_ids, payloads=to_insert_payloads)写路径的图一致性保证:
- memory 先于 entity 写入(Phase 6 先落 memory,Phase 7 再建边),即便 Phase 7 失败也只是少几条边,主 memory 仍可检索;
_upsert_entity的"update 命中 vs. insert 新建"分支保证不会出现重复节点,同实体 ≥ 0.95 相似度就合并;update会先撤销旧边再建新边,避免幻影引用;- 实体层的错误一律被 catch 为
WARNING/DEBUG,不会让主写入路径失败------这是把图层做成"增强而非依赖"的关键。
5.4 读取链路上的图操作(Step 6 展开)
这是"图辅助检索"------ query 抽实体 → 查图 → 为命中的邻居 memory 注入加权:
python
# _compute_entity_boosts (mem0/memory/main.py:1440)
query_entities = extract_entities(query)[:8] # 最多 8 个
deduped = ... # 去重
memory_boosts = {}
for _, entity_text in deduped:
entity_embedding = embedding_model.embed(entity_text, "search")
# 一跳邻接查询: 在图的实体节点里找相似节点
matches = entity_store.search(
query=entity_text, vectors=entity_embedding,
top_k=500, filters=session_filters,
)
for match in matches:
if match.score < 0.5: # 弱匹配丢弃
continue
linked_memory_ids = match.payload["linked_memory_ids"] # 图的边
num_linked = max(len(linked_memory_ids), 1)
# 热门实体衰减: 一个实体被越多 memory 共享, 单次加权就越小
# 例: 连 1 条 → 1.0; 连 10 条 → 0.919; 连 100 条 → 0.090
weight = 1.0 / (1.0 + 0.001 * ((num_linked - 1) ** 2))
boost = match.score * ENTITY_BOOST_WEIGHT * weight
for mid in linked_memory_ids:
memory_boosts[mid] = max(memory_boosts.get(mid, 0.0), boost)
return memory_boosts # 喂给 score_and_rankmemory_boosts 最终与语义分数、BM25 分数在 score_and_rank 里做加权融合,再按 threshold 过滤、截断至 top_k。衰减公式 1/(1+0.001*(n-1)²) 不是玄学:它的工程意图是"稀有共现实体的语义贡献被放大,像 'user' / 'system' 这种每条都挂的烂大街实体自动被压低"。
5.5 为何不直接上 Neo4j?
- 绝大多数记忆检索只需要一跳(entity → memories),向量库 + JSON 数组就能 O(1) 解决;
- 多跳推理需要 Cypher 这类图查询语言,但 mem0 的目标场景是"RAG 前的精排",时延敏感;
- 少一个外部依赖,Provider 数量从 30+4 变成 30(复用向量库);所有 provider 的
list/search/search_batch就够用; - Neo4j/Memgraph 在
docker-compose.yaml/mem0ai[graph]extra 里存在,但都是未实现的占位。
这一小节大概是全文最值得划重点的地方:不是所有图都要用图数据库。当访问模式只有一跳时,二部图 + 邻接表 payload 在向量库里几乎零成本就能实现,运维和一致性都不比 Neo4j 方案复杂。
六、历史与幂等:SQLite 两张表撑住一切
mem0/memory/storage.py::SQLiteManager 维护两张表(默认位于 ~/.mem0/history.db):
-
history: 每条记忆的变更流水id TEXT PK | memory_id | old_memory | new_memory | event (ADD|UPDATE|DELETE) | created_at | updated_at | is_deleted | actor_id | role支持从老 schema 自动迁移(
_migrate_history_table)。 -
messages: 会话原始消息(session_scope = user_id=...&agent_id=...&run_id=...),供下次add时作为 last-K 上下文。
幂等与去重的所有魔法都在这两张表 + vector payload 的 hash 字段里 :_add_to_vector_store 把"已有 hashes + batch 内 seen_hashes"并起来去重,保证同一事实不会重复入库;session 作用域保证不同用户/agent 互不污染。
一个小细节值得注意:messages 表在 Phase 0 被用作"last-K 历史消息"的来源,这让 Mem0 的 add 天然具备"隔夜还能继续抽事实"的能力------conversation summary 不是存在 LLM 的缓存里的,而是落在 SQLite 里的。这比 langgraph 一类把对话丢在内存 dict 里的方案鲁棒得多。
七、收益归因:为什么四项指标可以同时变好
这是全文想回答的核心问题。论文给了数字,但没讲清楚数字从哪来。把写入/读取两条链路拆开之后,映射关系其实非常干净:
| 指标 | 对应机制 | 直观量级 |
|---|---|---|
| LLM-as-Judge J 提升 | 存的是"结构化短事实"而不是 raw chunk,噪声少;+BM25/实体 boost 在 temporal/multi-hop 上补向量检索的短板 | LOCOMO 上 J 比 OpenAI memory 相对 +26%,比最强 RAG 相对 +10% |
| p95 延迟下降 91% | 只把"事实集合"灌给生成 LLM(均值 7k Token),而不是 26k raw;search 阶段只跑向量+BM25+图邻接 而非 LLM;单次 LLM 抽取代替多轮 | full-context p95 17s → Mem0 p95 1.44s |
| Token 消耗 -90% | 事实化 → 7k Token;向量 payload 里只存文本+lemma+hash;不缓存摘要到每个节点 | Mem0 7k vs full-context 26k vs Zep 600k |
| 构建时间缩短 | Phase 2 单次抽取、Phase 3/6/7 全 batch、二部图替代 Neo4j 异步回填、hash 幂等 | Zep 需小时级异步回填,Mem0g 最坏场景 < 1 分钟 |
这里最反直觉的一点是:准确率和延迟居然是同一个机制的两个方向。
- 论文里 "full-context + 26k 裸对话"的 J 只有 72.9,而 Mem0 靠 7k 精炼事实拿到 66.9;但 full-context 要多付 20k Token 和 15 秒延迟来换那 6 分。在 P99 SLA 1 秒的交互式 Agent 场景里,这不是一个可接受的 tradeoff。
- 过去几个 memory 系统(LangMem、Zep、A-Mem)更倾向于"多存一点可能有用的":存全量摘要、存图的完整上下文、存多级重述。结果它们的每一次搜索都要扫过更长的 payload,LLM 上下文填得更满,生成端反而要读进去更多噪声。准确率和延迟的负相关不是必然规律,而是"存得太多"的代价。
- Mem0 的赌注是:让 LLM 在写入时做决策,在读取时不做决策 。写入时的每一次
ADD/UPDATE/DELETE决策都会让 Ω 变小、变准;读取时则完全靠"向量 + BM25 + 实体 boost"的近似算法,完全不让生成前链路出现 LLM。这个分工是 Mem0 在 Table 2 里同时拿到 p50 search 148ms、p95 search 200ms 的根本原因。
一句话总结:Mem0 的性能不是来自某个算法的胜利,而是来自接口边界的克制。
结语:几个核心判断
把架构、接口层、写入流水线、读取融合、二部图、收益归因、生产部署串起来看,关于 Mem0 我愿意留下这几条判断:
- 接口层面 :Mem0 的抽象刻意在"CRUD 五方法 + 两条流水线(add/search)"这个粒度停住,这是它能跨 30+ 向量库、24 LLM 落地的前提;过度抽象或过度泛化都会破坏这种工程稳定性。
- 写入层面 :V3 的九阶段流水线是个典型的 "把串行 LLM 调用压成单次、其余全部 batch" 的设计,可以直接迁移到任何需要 LLM 做判断的管线里。LLM 只在第 2 个 phase 出现一次------这是性能账的根源。
- 读取层面:语义 + BM25 + 实体 boost 三路融合比"单纯上 reranker"更值得抄。Reranker 是一次 LLM 调用的成本,BM25+实体在代码里几乎免费。
- 图层面 :Mem0 的"图"不是 Neo4j,而是复用向量库的二部图 + 邻接表 payload 。访问模式只要一跳,就不要为了看起来正统而引入 Cypher 依赖。"用向量库当图数据库"这套思路值得直接抄到其他 Agent Memory 项目里去。
- 收益归因 :准确率和延迟在"存得太多"的系统里是对立的,在"存精炼事实"的系统里是同向的。Mem0 与 full-context / Zep 的差距不是优化差距,而是边界差距。
参考
- Prateek Chhikara et al. Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory. arXiv:2504.19413, 2025.
- mem0ai/mem0 源码:
mem0/memory/main.py、mem0/memory/base.py、mem0/memory/storage.py、mem0/configs/base.py、mem0/configs/prompts.py、mem0/utils/factory.py、mem0/utils/entity_extraction.py、mem0/vector_stores/base.py、server/main.py。 - LOCOMO benchmark:Maharana et al. ACL 2024。