前言:协议设计的"第一性原理"
抛弃 Nginx 配置文件和 Chrome DevTools 的抓包面板,我们把视角拉到协议的最底层。
HTTP/1.1 是一个"人类易读、机器难解析"的协议,而 HTTP/2 的所有改动,都是在用二进制的思维重塑数据在管道里的流动方式。搞懂这背后的逻辑,比背熟任何配置参数都管用。
先看一张图,它概括了这次协议进化的核心脉络:
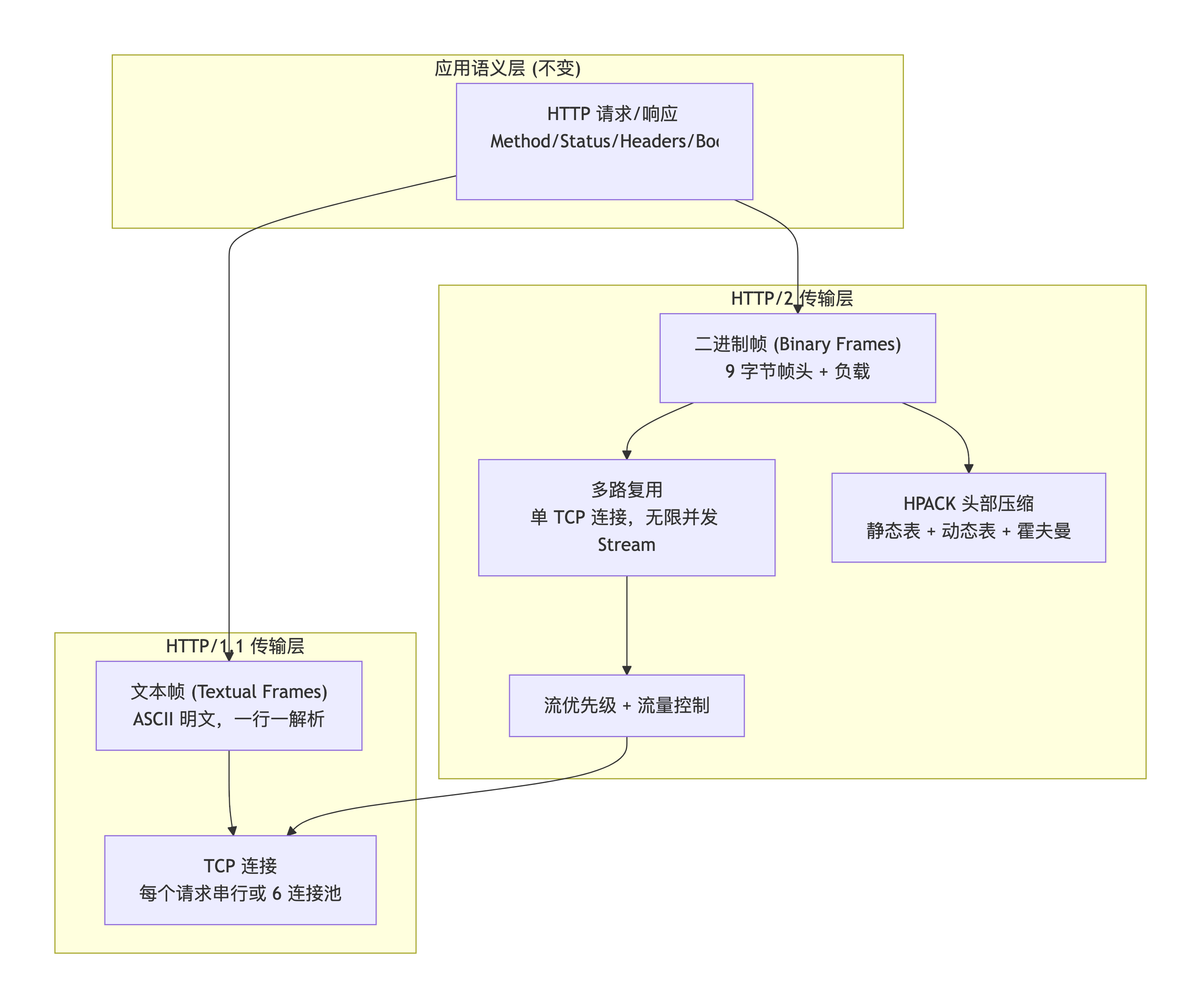
一句话总结这次进化的本质:HTTP 的语义(请求/响应、状态码)没变,变的是"怎么打包"和"怎么在 TCP 管道里调度"。
带着这个前提,我们往下看。
第一章:HTTP/1.1------优雅的文本迷宫
1.1 文本协议的"美丽"与代价
HTTP/1.1 是文本协议。它的请求长这样:
GET /api/users/123 HTTP/1.1\r\n
Host: api.example.com\r\n
User-Agent: Mozilla/5.0 ...\r\n
Accept: application/json\r\n
\r\n优雅、直观。你可以用 telnet 直接跟服务器"聊天"。
但这份优雅是有代价的------解析成本极高。试想一下,服务器读到这个字节流时,它面临的问题:
-
每个请求头之间用
\r\n分割,需要逐字节扫描。 -
值里可能还有空格、换行,需要做状态机处理。
-
头部名称大小写不敏感(RFC 2616 说 Host 和 host 等价),解析器要维护大小写转换表。
Netty 的 HTTP 解析器实现 深刻展示了这一点:它使用了 ReplayingDecoder 状态机模式,逐字节检查 CRLF、冒号分隔符、LWS 行折叠等文本特性。本质上,Netty 是在用二进制状态机去解析一个纯文本协议------这种"高射炮打蚊子"的无奈,恰恰揭示了 HTTP/1.1 文本设计的根本缺陷。
这就像你写了一封英文信,却要求对方用正则表达式去理解你的意思。能看懂,但太累了。
1.2 持久连接与分块传输
HTTP/1.0 时代,每个请求都要新建 TCP 连接,用完就关。三次握手 + 四次挥手 + 慢启动,光"打招呼"就花掉了大部分时间。
HTTP/1.1 做了两个关键改进:
第一,持久连接(Persistent Connection) 。默认情况下,TCP 连接在响应后不关闭,可以复用。这意味着多个请求可以共享同一个 TCP 连接,省去了重复握手的开销。
第二,分块传输编码(Chunked Transfer Encoding) 。对于动态生成的内容,服务器在发送响应头时可能不知道总长度是多少。Chunked 编码允许服务器以"块"为单位逐步发送数据,每个块前面用十六进制标明长度,最后用一个长度为 0 的块表示结束。
HTTP/1.1 200 OK\r\n
Transfer-Encoding: chunked\r\n
\r\n
1a\r\n ← 十六进制长度,表示接下来 26 字节
{"users": [{"id": 1, "name": ← 第一块数据(部分)
10\r\n ← 长度 16 字节
"Alice"}, {"id": 2 ← 第二块数据(继续)
...\r\n
0\r\n\r\n ← 长度 0,表示结束1.3 管线化:一个"看似美好"的尝试
既然一个 TCP 连接可以复用,能不能连续发多个请求,不等上一个响应就发下一个?
这就是 HTTP 管线化(Pipelining) 。
时间线(理想情况):
客户端 → 服务端: 请求1 → 请求2 → 请求3
客户端 ← 服务端: 响应1 ← 响应2 ← 响应3但是,现实很残酷。
服务器的响应 必须严格按照请求顺序返回 。如果请求 1 的响应处理时间特别长(比如查了一个慢 SQL),后面的请求 2 和 3 即使早就处理完了,也只能在队列里干等着。只要排在前面的请求卡住了,后面所有准备就绪的响应全得憋在缓冲区里等**------这就是典型的队头阻塞。**
这就像你在超市只有一个收银台,前面的大妈在翻找零钱,后面的所有人都得等着------无论你只买了一瓶水。
更致命的是,许多中间代理(Proxy)根本 不支持或默认禁用 管线化。于是,这个理论上很好的特性,在实践中几乎销声匿迹。
怎么办? 浏览器的实际做法是:对同一个域名开 6~8 个并行 TCP 连接。每个连接独立发送请求,各管各的。但这带来了新问题:
-
多个 TCP 连接意味着多次握手、多次慢启动。
-
HTTPS 下还要多次 TLS 握手,开销更大。
-
每个连接都要维护自己的拥塞控制状态。
HTTP/1.1 的底层数据结构,直接决定了 Web 性能优化的天花板。
第二章:SPDY------Google 的"实验室先行者"
在 HTTP/2 走进 IETF 成为国际标准前,Google 先在自家产品里跑通了一个叫 SPDY 的实验协议。
SPDY 的核心思想非常简单:
在保留 HTTP 语义不变的前提下,在应用层引入二进制分帧与多路复用机制,将并发的 HTTP 请求拆分成帧,在单一的 TCP 连接上交织传输,从而解决 HTTP/1.1 的队头阻塞和连接数冗余问题。
SPDY 的实验成果直接催生了 HTTP/2 的几乎所有核心特性:
-
二进制分帧:不再用文本,改用二进制帧。
-
多路复用:一个连接承载多个并发请求/响应。
-
头部压缩:减少重复头部传输。
-
服务器推送:主动推资源给客户端。
-
请求优先级:重要资源先发。
Google 在自家的 Chrome 和 Gmail 等服务上验证了 SPDY 的效果,发现页面加载时间可以缩短 20% 以上。有了这个数据背书,IETF 在 SPDY 的基础上开始了 HTTP/2 的标准化工作。
这套被实战验证过的机制,直接被 IETF 搬过去成了 HTTP/2 的骨架,SPDY 随之退役。
第三章:HTTP/2 核心------二进制分帧层
3.1 从"一行一行"到"一帧一帧"
HTTP/2 最大的革命,是 不再用文本传输 。它把所有的请求/响应数据都切分成更小的 二进制帧(Frame) ,每一帧都有一个固定的格式。
让我们先看看帧的通用结构:
HTTP/2 帧格式 (RFC 7540 §4.1):
+-----------------------------------------------+
| Length (24) |
+---------------+---------------+---------------+
| Type (8) | Flags (8) |
+-+-------------+---------------+---------------+
|R| Stream Identifier (31) |
+=+=============================================+
| Frame Payload (0...) |
+-----------------------------------------------+| 字段 | 长度 | 说明 |
|---|---|---|
| Length | 24 位 | 帧负载的长度,最大 2^24-1 (16,777,215) 字节 |
| Type | 8 位 | 帧类型,定义了 10 种(DATA、HEADERS、PRIORITY 等) |
| Flags | 8 位 | 帧的标志位,如 END_STREAM、END_HEADERS |
| R | 1 位 | 保留位,必须为 0 |
| Stream Identifier | 31 位 | 流 ID,标识此帧属于哪个流 |
为什么是二进制?
你用 ASCII 文本发送"Content-Length: 1024",服务端需要解析 20 个字符,还要转成整数。
用二进制帧,Length 字段直接就是 24 位的整数,一次
memcpy+ 字节序转换就搞定。
这就是"机器友好"的本质------字段位置是写死的,类型是明确的,拿来就能用,不需要任何词法分析。
3.2 流、消息、帧:三位一体
HTTP/2 的数据组织有三个层级:
-
帧(Frame) :HTTP/2 的最小通信单位,每个帧有类型和长度。
-
消息(Message) :一个完整的 HTTP 请求或响应,由一个或多个帧组成。
-
流(Stream) :一个 TCP 连接内的双向字节流,承载一对请求/响应消息。
流 ID 的奇偶规则 非常巧妙:客户端发起的流是奇数,服务端发起的流是偶数。这样一来,双方永远不会在 ID 分配上产生冲突,无需任何同步锁------这是一种"协议层无锁设计"。
为什么流 ID 只用了 31 位?因为第一位是保留位(R),RFC 7540 说它"必须为 0"。这给未来扩展留下了空间。
3.3 帧的交织:多路复用的本质
一个典型的 HTTP/2 连接上,帧是可以 交织(Interleave) 的:
时间线(一个 TCP 连接内):
HEADERS(Stream 13) →
HEADERS(Stream 15) →
DATA(Stream 15) →
DATA(Stream 13) →
DATA(Stream 13) →
DATA(Stream 15, END_STREAM) →每个帧的头部都带着 Stream Identifier,接收方根据它把帧重新组装成完整的消息。同一个流内的帧必须保持顺序,但不同流之间完全独立,可以乱序传输。
这就是多路复用的底层机制------它把 HTTP 层面的并发问题,变成了帧的组装问题。
3.4 那么,队头阻塞解决了吗?
应用层解决了,传输层还没有。
HTTP/2 确实消除了 HTTP 层面的队头阻塞------不同流的帧可以任意交织,谁也不等谁。但是,TCP 的队头阻塞依然存在。
打个比方:你有多条不同颜色的水流(HTTP/2 Stream),但最终都要流进同一根水管(TCP 连接)。如果水管某处堵了(丢包重传),所有水流都得暂停,无论颜色是什么。
TCP 保证数据 按序可靠到达。如果某个 TCP 数据包在网络中丢失,后续的所有数据包(哪怕已经到了接收方)都必须等待那个丢失的包被重传,才能向上层交付。这个问题,要等到 HTTP/3 基于 UDP 的 QUIC 协议才能彻底解决。
第四章:HPACK------头部压缩的"三板斧"
4.1 头部膨胀有多严重?
现在打开 Chrome DevTools 的 Network 面板,随便看一个请求的 Header:
cookie: session_id=abc... (几百字节)
user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 ... (上百字节)
accept-encoding: gzip, deflate, br
accept-language: zh-CN,zh;q=0.9,en;q=0.8很多头部在每个请求中 完全一样,却每次都要原样发送。在移动网络下,这就是在烧用户的流量。
HTTP/2 引入的 HPACK (RFC 7541)专门解决这个问题,核心是 "索引 + 霍夫曼编码" 的双重压缩策略。
4.2 静态表:天生就有的 61 条索引
HPACK 首先定义了一个 静态表(Static Table) ,包含了 61 个最常见的 HTTP 头部字段:
| 索引 | 字段名 | 字段值 |
|---|---|---|
| 1 | :authority | --- |
| 2 | :method | GET |
| 3 | :method | POST |
| 4 | :path | / |
| 5 | :path | /index.html |
| 8 | :status | 200 |
| 15 | accept-encoding | gzip, deflate |
| ... | ... | ... |
静态表是硬编码的 ,每个 HTTP/2 实现都内置这份表格。也就是说,当你发送 :method: GET 时,只需要传输 一个字节的索引号(2),而不是 12 个字符。
这就像你和新朋友第一次见面要自我介绍:"我叫张三,来自北京,做软件开发"。
而和老朋友见面,只需要说一句"老规矩",对方就全懂了。
4.3 动态表:连接级别的"短期记忆"
如果静态表里没有你需要的头部怎么办?HPACK 给了你一个 动态表(Dynamic Table) 。
它的工作原理很简单:
-
首次发送一个未在表中的头部时,用 字面量 发送完整内容,并添加到动态表中。
-
后续再发送相同头部时,直接发送动态表的索引号。
-
动态表是 FIFO 队列,满了就踢出最老的条目。
关键点:动态表是双向维护的。 编码器和解码器各自维护一份完全一致的动态表,这样发送方只需要发索引,接收方就能在自己的表里查到完整内容。
这里有一个微妙的设计:动态表的更新是 即时生效的 。发送方在编码头部时,如果决定将某个字面量添加到动态表,它必须 假定接收方也会同步更新------不需要任何确认信号。这是一种"乐观更新"的设计哲学,极大地减少了协议开销。
但这也带来了攻击面。 如果恶意客户端故意发送大量不同的头部来"撑爆"动态表,服务端内存会迅速耗尽。因此,每个 HTTP/2 实现都严格限制了最大并发流数量 (http2_max_concurrent_streams),避免动态表被恶意填充。
4.4 霍夫曼编码:最后一道压缩
即使要用字面量发送,HTTP/2 也不放过压缩的机会。HPACK 使用了一种 预定义的霍夫曼编码表 对字符串进行压缩。
原理很简单:高频字符用短编码,低频字符用长编码。比如空格在 HTTP 头部中极为常见,HPACK 给它的编码只有 1 位,而低频的 'z' 可能需要 13 位。
为什么用预定义表而不是动态生成? 因为 HPACK 需要 低延迟 。如果每次连接都要先统计字符频率再生成霍夫曼树,首字节时间会显著增加。预定义表虽然在压缩率上不如动态生成,但换来了 零启动成本------这是一个典型的"速度换极致压缩"的工程权衡。
4.5 为什么不直接用 GZIP?
你可能会问:为什么不直接用 GZIP 压缩整个 HTTP 头部?
答案:安全问题。
2012 年,一种叫 CRIME(Compression Ratio Info-leak Made Easy) 的攻击横空出世。攻击者通过观察压缩后数据长度的变化,可以逐字符推断出加密内容(如 Cookie)。这利用了压缩算法"相似内容压得更小"的特性。
HPACK 的设计刻意 避免了跨请求的压缩相关性,并且对敏感信息(如 Cookie 值)不与其他头部混合压缩,从而从根本上免疫了 CRIME 类攻击。
安全与性能之间的博弈,从来都不是非黑即白的选择题,而是在钢丝上寻找平衡点的艺术。
第五章:流量控制与优先级------HTTP/2 的"调度系统"
5.1 为什么需要 HTTP 层面的流量控制?
你可能会问:TCP 不是已经有流量控制了吗?为什么 HTTP/2 还要自己搞一套?
答案在于"颗粒度"。
TCP 的流量控制是针对整个连接的。它只管"对方还能接收多少字节",不管"这些字节属于哪个流"。
在 HTTP/2 中,一个连接上可能有几十个流在并发传输。如果一个流的数据处理慢(比如写入磁盘),它不应该阻塞其他流。TCP 层面的流控做不到这一点------只要连接窗口没满,发送方就会继续推数据,结果慢的流占满了接收缓冲区,快的流反而被拖累。
HTTP/2 的流控是双层的:
-
连接级窗口:控制整个 TCP 连接上的未处理数据量。
-
流级窗口:控制每个流的未处理数据量。
发送数据前,必须 同时检查 连接级和流级两个窗口------两者都通过才能发送,发送后两个窗口 同时扣减。
5.2 WINDOW_UPDATE:流控的"令牌"
流控的运转依赖于一种特殊的帧:WINDOW_UPDATE。
当接收方消费了数据(比如把 DATA 帧的内容写入了磁盘缓冲区),它就可以发送 WINDOW_UPDATE 帧,告诉发送方:"我的窗口增加了 N 字节,你可以继续发送了。"
有趣的是,WINDOW_UPDATE 不是每消费一点数据就发送一次,而是等到窗口增加到某个阈值才批量发送。这种"批量更新"机制减少了控制帧的数量,提升了整体吞吐量。
这就像你给快递员付费,不是每次收到一件就付一次,而是攒到一定金额一起结算。效率更高,但不会影响送货。
5.3 优先级:谁先走?
当多个流都想发送数据,但带宽有限时,谁优先?
HTTP/2 引入了一套 基于依赖关系的优先级系统:
-
依赖关系:流可以声明依赖于另一个流(形成树),表示"希望被依赖的父流比子流优先得到资源"的偏好;规范并不要求"子流必须等父流完成才能发送",且同父的兄弟流之间没有强制顺序。
-
权重:同一父节点下的子流按权重比例分配可用资源(通常体现在发送配额/速率上)。
-
独占标记:当前流成为父流的唯一直接子节点,父流原有的子节点变为当前流的子节点。
Netty 的 WeightedFairQueueByteDistributor 正是这一算法的经典实现,它借鉴了 Linux 内核的 CFS(完全公平调度器) 思想,模拟"理想的多任务 CPU"来分配字节。
5.4 优先级树的操作复杂度
RFC 7540 设计的优先级依赖树在理论上可以任意重排,但每次 PRIORITY 帧都可能触发 O(n) 的树结构调整。在流数量极多的高并发场景下,这可能成为性能瓶颈。
工业界的应对策略? 许多 HTTP/2 实现会 限制优先级树的深度和重排频率 ,甚至在服务器端 忽略客户端的优先级声明。毕竟,RFC 7540 明确说优先级只是"建议",服务端可以选择忽略。
这再次印证了一个道理:协议标准是理想,工程实现是妥协。二者之间的张力,恰是技术有趣之处。
第六章:服务器推送------把"外卖"变成"自助餐"
6.1 推送是什么?为什么需要它?
传统 HTTP 模式下,浏览器先请求 HTML,解析后再请求 CSS 和 JS,然后再请求图片。这个过程是 串行发现、并行请求 的------等 HTML 解析完才知道还需要什么,已经晚了。
HTTP/2 的 服务器推送(Server Push) 改变了这个模式:服务器可以在客户端请求之前,主动把可能需要的资源"推"给客户端。
6.2 PUSH_PROMISE:推送的"预告片"
服务器推送不是直接扔数据,而是先发送一个 PUSH_PROMISE 帧,告诉客户端:"我准备推一个资源给你,它在 Stream N 上"。
客户端收到 PUSH_PROMISE 后,可以选择:
-
接受:正常接收 Stream N 的数据。
-
拒绝 :发送一个
RST_STREAM帧,取消这个推送。
这种设计给客户端保留了最终决定权------毕竟客户端可能已经缓存了这个资源。
6.3 推送的尴尬:为什么你很少见到它?
理论上很美好,但实践中服务器推送 用得很少。为什么?
-
缓存判断困难:服务器不知道客户端是否已缓存了某个资源。推了可能浪费带宽。
-
过度推送:如果配置不当,可能把不需要的资源也推过去。
-
浏览器支持不一致:不同浏览器的推送策略和缓存行为有差异。
-
难以调试:推送发生在协议层,DevTools 中的呈现不够直观。
目前,Push 更多被用作"预加载"的替代方案。但在 HTTP/2 生态中,它远没有多路复用和头部压缩那样普及。
终章:HTTP/2 的边界与 HTTP/3 的黎明
让我们回到文章开头的核心论点:HTTP/2 的所有改动,都是在用二进制的思维重塑数据在管道里的流动方式。
它成功了,但并非完美。
HTTP/2 解决了 HTTP 层面的队头阻塞,但 TCP 层面的队头阻塞依然存在。一个丢包就能让整个连接暂停,所有流都受到影响。此外,TCP 的三次握手和 TLS 握手仍然是启动时延的重要组成部分。
这就是 HTTP/3 要解决的问题。HTTP/3 基于 QUIC(UDP 之上的可靠传输协议),把流控和可靠性从 TCP 中抽离出来,在 UDP 之上重新实现:
-
0-RTT 连接建立:缓存过的连接可以立即发送数据。
-
无队头阻塞:丢包只影响单个流,不影响其他流。
-
连接迁移:切换网络(Wi-Fi 到 4G)连接不中断。
下面是三种协议的对比总结:
| 维度 | HTTP/1.1 | HTTP/2 | HTTP/3 |
|---|---|---|---|
| 协议格式 | 文本 | 二进制帧 | 二进制帧 |
| 多路复用 | 管线化(几乎不用) | 单 TCP 多 Stream | 单 UDP 多 Stream |
| 头部压缩 | 无 | HPACK | QPACK(改进版 HPACK) |
| 队头阻塞 | 严重(HTTP 层 + TCP 层) | TCP 层仍存在 | 完全消除 |
| 传输层 | TCP | TCP | UDP (QUIC) |
| 连接迁移 | 不支持 | 不支持 | 支持 |
| 启动时延 | 1-RTT(TCP) | 2-RTT(TCP+TLS) | 0-RTT / 1-RTT |
回头看 HTTP/2 的改动:把文本换成二进制,把长文本换成索引表,在 TCP 之上再加一层流控。这些看似把协议搞复杂的设计,其实都是在为过去的"想当然"买单。
计算机没有语感,也不懂上下文,它只认固定长度的字节和确定的内存地址。HTTP/2 的全部意义,就是停止用人类的习惯去刁难机器。
(全文完)