
🔥草莓熊Lotso: 个人主页
❄️个人专栏: 《C++知识分享》 《Linux 入门到实践:零基础也能懂》
✨生活是默默的坚持,毅力是永久的享受!
🎬 博主简介:

文章目录
- 前言:
- [一. HTTP 协议初识](#一. HTTP 协议初识)
-
- [1.1 什么是 HTTP 协议](#1.1 什么是 HTTP 协议)
- [1.2 CS 模式与 BS 模式](#1.2 CS 模式与 BS 模式)
- [二. 深入理解 URL 与 URI](#二. 深入理解 URL 与 URI)
-
- [2.1 URL 的完整格式解析](#2.1 URL 的完整格式解析)
- [2.2 域名与 DNS 解析](#2.2 域名与 DNS 解析)
- [2.3 URI 与 URL 的区别与联系](#2.3 URI 与 URL 的区别与联系)
- [三. URL 编码与解码:urlencode 与 urldecode](#三. URL 编码与解码:urlencode 与 urldecode)
-
- [3.1 为什么需要 URL 编码](#3.1 为什么需要 URL 编码)
- [3.2 URL 编码规则](#3.2 URL 编码规则)
- [3.3 URL 解码实现与源码解读](#3.3 URL 解码实现与源码解读)
- [四. 实战:最简单的 HTTP 服务器(看不看都可以,后面还会具体讲的,这里只是先简单看看)](#四. 实战:最简单的 HTTP 服务器(看不看都可以,后面还会具体讲的,这里只是先简单看看))
-
- [4.1 代码实现](#4.1 代码实现)
- [4.2 代码解读](#4.2 代码解读)
- 结尾:
前言:
当你打开浏览器访问百度、刷抖音、看视频的时候,背后默默支撑这一切的就是HTTP 协议。它是互联网世界的 "通用语言",定义了客户端与服务器之间如何通信、如何交换数据。虽然我们每天都在使用 HTTP,但很多人对它的底层原理一知半解。作为后端开发者,深入理解 HTTP 协议不仅是面试的必考点,更是写出高性能、高可靠网络程序的基础。本文将从最基础的概念讲起,带你一步步揭开 HTTP 协议的神秘面纱。
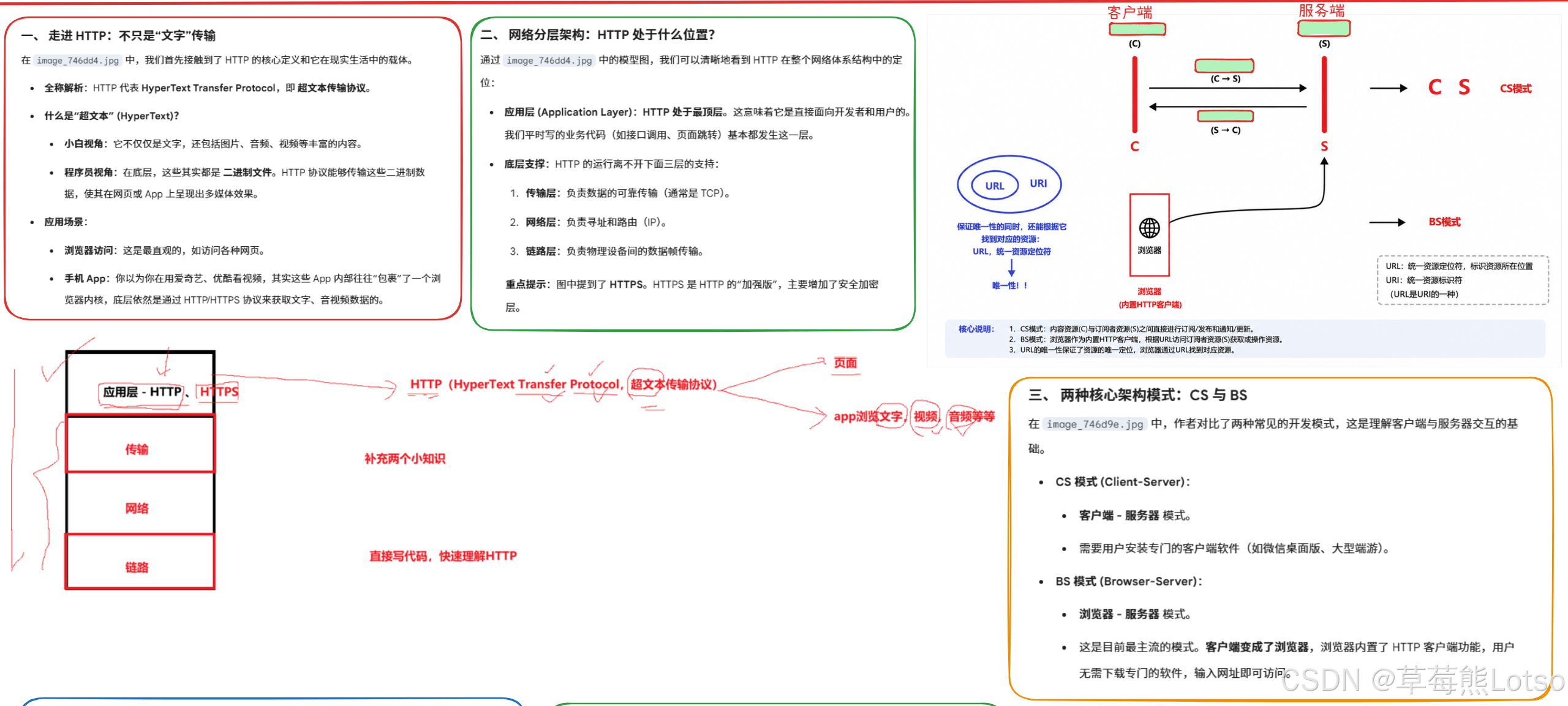
一. HTTP 协议初识
1.1 什么是 HTTP 协议
HTTP(HyperText Transfer Protocol,超文本传输协议)是应用层最广泛使用的协议之一。它定义了客户端(如浏览器)与服务器之间的通信规则,用于传输超文本(HTML 文档)、图片、视频、音频等各种资源。
这里的 "超文本" 是什么意思?
- 从用户视角看:超越了普通文本,可以包含图片、视频、音频、链接等多媒体内容
- 从程序员视角看:本质上就是二进制文件,Linux 下 "一切皆文件",所有网络资源最终都以文件形式存在于服务器上
HTTP 协议是一个无连接、无状态的协议:
- 无连接:每次请求都需要建立新的 TCP 连接,请求完成后立即关闭连接(HTTP/1.1 引入了持久连接优化)
- 无状态:服务器不会保存客户端的任何状态信息,每次请求都是独立的
1.2 CS 模式与 BS 模式
我们之前写的网络程序都是基于CS 模式(Client-Server,客户端 - 服务器模式),需要我们自己编写客户端和服务器程序。
而 HTTP 协议主要基于BS 模式(Browser-Server,浏览器 - 服务器模式):
- 客户端:不需要我们自己编写,直接使用浏览器(内置了 HTTP 客户端)
- 服务器:我们需要编写符合 HTTP 协议规范的服务器程序
这就是为什么我们只需要写一个 HTTP 服务器,就能让全世界的浏览器都能访问它的原因 ------ 所有浏览器都遵循相同的 HTTP 协议规范。

二. 深入理解 URL 与 URI
2.1 URL 的完整格式解析
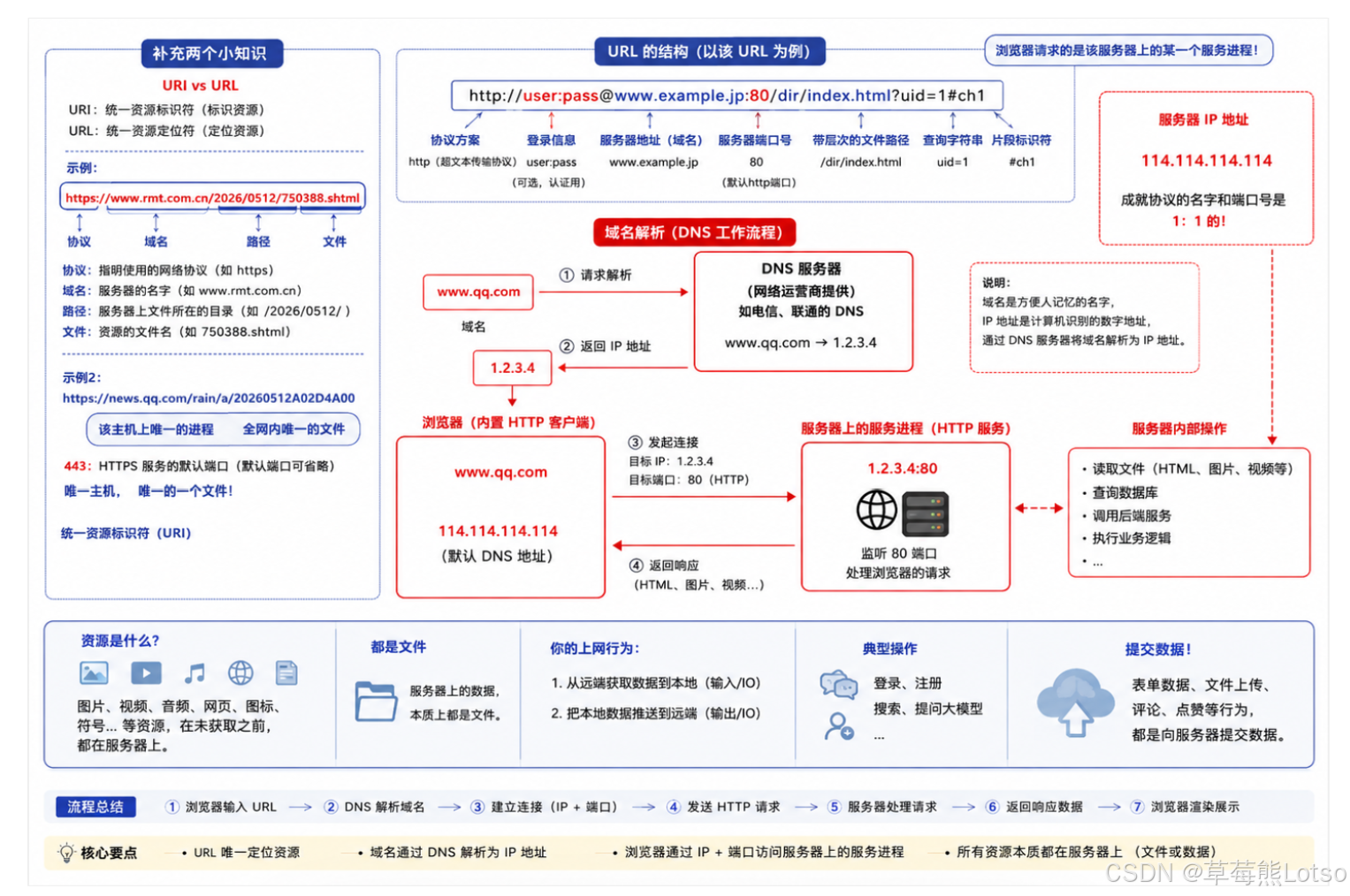
我们平时说的 "网址" 其实就是 URL(Uniform Resource Locator,统一资源定位符)。一个完整的 URL 格式如下:
bash
http://user:pass@www.example.jp:80/dir/index.htm?uid=1#ch1
我们来拆解每一部分的含义:
| 部分 | 说明 | 示例 |
|---|---|---|
| 方案名(协议) | 表示使用的协议类型 | http |
| 认证信息 | 可选,用于登录认证 | user:pass |
| 服务器地址 | 服务器的域名或 IP 地址 | www.example.jp |
| 服务器端口号 | 服务器监听的端口号 | 80 |
| 带层次的文件路径 | 资源在服务器上的路径 | /dir/index.htm |
| 查询字符串 | 可选,传递给服务器的参数 | ?uid=1 |
| 片段标识符 | 可选,定位页面内的锚点 | #ch1 |
注意几个关键点:
- 端口号通常可以省略,因为协议与端口号是强绑定 的:
- HTTP 默认端口:80
- HTTPS 默认端口:443
- 文件路径具有唯一性,它标识了服务器上的一个具体资源
- 一个完整的 URL 可以在全网范围内唯一标识一个资源
2.2 域名与 DNS 解析
我们平时访问网站使用的是域名(如www.baidu.com),但网络通信底层只能识别 IP 地址。这就需要 DNS(域名系统) 来完成域名到 IP 地址的转换。
DNS 解析的基本流程:
- 你在浏览器输入
www.baidu.com - 浏览器向 DNS 服务器发送查询请求:"www.baidu.com对应的 IP 地址是什么?"
- DNS 服务器返回对应的 IP 地址(如
180.101.50.242) - 浏览器使用这个 IP 地址与服务器建立 TCP 连接
DNS 服务器分为两大类:
| 服务类型 | 主要作用 | 常见代表 |
|---|---|---|
| 权威 DNS 服务器 | 管理域名的 DNS 记录,回答 "这个域名对应哪个 IP" | 腾讯云 DNS、阿里云 DNS、Cloudflare |
| 递归 DNS 服务器 | 帮你 "跑腿" 去全球 DNS 系统查询域名对应的 IP | 运营商 DNS、Google 8.8.8.8、阿里云 223.5.5.5 |
2.3 URI 与 URL 的区别与联系
很多人会混淆 URI 和 URL,其实它们是包含与被包含的关系:
- URI(Uniform Resource Identifier,统一资源标识符):用于唯一标识一个资源的字符串
- URL(Uniform Resource Locator,统一资源定位符):不仅标识资源,还告诉我们如何找到这个资源
简单来说:URL 是 URI 的一种特殊形式。所有的 URL 都是 URI,但不是所有的 URI 都是 URL。
举个生活中的例子:
- 身份证号:是 URI,它唯一标识一个人,但不能告诉你这个人在哪里
- 家庭住址:是 URL,它不仅标识一个人,还告诉你如何找到这个人

三. URL 编码与解码:urlencode 与 urldecode
3.1 为什么需要 URL 编码
我们先来看一个例子:当你在百度搜索 "aa/?#&bb" 时,浏览器会自动将 URL 转换为:
bash
https://www.baidu.com/s?wd=aa%2F%3F%23%26bb可以看到,原来的特殊字符/?#&都被转换成了%2F%3F%23%26这样的格式。这就是URL 编码。
为什么需要编码?
- URL 中有些字符具有特殊含义(如
/表示路径分隔符,?表示查询字符串开始) - 如果参数中包含这些特殊字符,会导致 URL 格式解析错误
- 汉字、空格等非 ASCII 字符也不能直接出现在 URL 中
3.2 URL 编码规则
URL 编码的规则非常简单:
- 将需要转码的字符转换为对应的十六进制值
- 从右到左取 4 位(不足 4 位直接处理),每 2 位为一组
- 在每组前面加上%,编码成%XY的格式
举几个例子:
+的 ASCII 码是 43,十六进制是2B,编码后为%2B/的 ASCII 码是 47,十六进制是2F,编码后为%2F?的 ASCII 码是 63,十六进制是3F,编码后为%3F- 汉字 "北" 的 UTF-8 编码是
E6 B5 8B,编码后为%E6%B5%8B

3.3 URL 解码实现与源码解读
URL 解码是编码的逆过程,服务器收到编码后的 URL 后,需要将其还原为原始字符。
下面是一个 C++ 实现的 URL 解码函数:
cpp
#include <string>
#include <cassert>
// 将十六进制字符转换为对应的数值
unsigned char FromHex(unsigned char c)
{
if (c >= '0' && c <= '9') return c - '0';
if (c >= 'a' && c <= 'f') return c - 'a' + 10;
if (c >= 'A' && c <= 'F') return c - 'A' + 10;
return 0;
}
std::string UrlDecode(const std::string& str)
{
std::string strTemp = "";
size_t length = str.length();
for (size_t i = 0; i < length; i++)
{
// '+' 解码为空格
if (str[i] == '+')
strTemp += ' ';
// 遇到 '%' 表示后面跟着两个十六进制字符
else if (str[i] == '%')
{
// 确保后面有两个字符
assert(i + 2 < length);
// 分别取高4位和低4位
unsigned char high = FromHex((unsigned char)str[++i]);
unsigned char low = FromHex((unsigned char)str[++i]);
// 组合成原始字符
strTemp += high * 16 + low;
}
// 普通字符直接保留
else
strTemp += str[i];
}
return strTemp;
}代码解读:
FromHex函数:将十六进制字符(0-9, a-f, A-F)转换为对应的数值- 遍历输入字符串:
- 遇到
+:解码为空格 - 遇到
%:读取后面两个字符,分别作为高 4 位和低 4 位,组合成原始字符 - 普通字符:直接添加到结果中
- 遇到
四. 实战:最简单的 HTTP 服务器(看不看都可以,后面还会具体讲的,这里只是先简单看看)
理论讲了这么多,我们来动手写一个最简单的 HTTP 服务器,加深对 HTTP 协议的理解。这个服务器只需要在网页上输出 "hello world"。
4.1 代码实现
cpp
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
void Usage()
{
printf("usage: ./server [ip] [port]\n");
}
int main(int argc, char* argv[])
{
if (argc != 3)
{
Usage();
return 1;
}
// 1. 创建套接字
int fd = socket(AF_INET, SOCK_STREAM, 0);
if (fd < 0)
{
perror("socket");
return 1;
}
// 2. 绑定地址和端口
struct sockaddr_in addr;
addr.sin_family = AF_INET;
addr.sin_addr.s_addr = inet_addr(argv[1]);
addr.sin_port = htons(atoi(argv[2]));
int ret = bind(fd, (struct sockaddr*)&addr, sizeof(addr));
if (ret < 0)
{
perror("bind");
return 1;
}
// 3. 开始监听
ret = listen(fd, 10);
if (ret < 0)
{
perror("listen");
return 1;
}
printf("HTTP server running on %s:%s\n", argv[1], argv[2]);
// 4. 循环接受连接
for (;;)
{
struct sockaddr_in client_addr;
socklen_t len = sizeof(client_addr);
int client_fd = accept(fd, (struct sockaddr*)&client_addr, &len);
if (client_fd < 0)
{
perror("accept");
continue;
}
// 5. 读取客户端请求
char input_buf[1024 * 10] = {0};
ssize_t read_size = read(client_fd, input_buf, sizeof(input_buf) - 1);
if (read_size < 0)
{
close(client_fd);
continue;
}
// 打印请求内容
printf("[Request from %s:%d]\n%s\n",
inet_ntoa(client_addr.sin_addr),
ntohs(client_addr.sin_port),
input_buf);
// 6. 构造HTTP响应
char buf[1024] = {0};
const char* body = "<h1>hello world</h1>";
sprintf(buf, "HTTP/1.0 200 OK\r\nContent-Length:%lu\r\n\r\n%s",
strlen(body), body);
// 7. 发送响应
write(client_fd, buf, strlen(buf));
// 8. 关闭连接
close(client_fd);
}
close(fd);
return 0;
}4.2 代码解读
这个简单的 HTTP 服务器遵循了 HTTP 协议的基本规范:
- 接受客户端的 TCP 连接
- 读取客户端发送的 HTTP 请求
- 构造符合 HTTP 协议格式的响应:
- 响应行:
HTTP/1.0 200 OK(版本号 + 状态码 + 状态描述) - 响应头:
Content-Length:%lu(指定响应体的长度) - 空行:分隔响应头和响应体
- 响应体:
<h1>hello world</h1>(实际返回的内容)
- 响应行:
- 发送响应并关闭连接
编译运行:
bash
g++ -o http_server http_server.cpp
./http_server 0.0.0.0 9090然后在浏览器中输入http://你的服务器IP:9090,就能看到 "hello world" 了。同时,服务器终端会打印出浏览器发送的完整 HTTP 请求内容。
结尾:
html
🍓 我是草莓熊 Lotso!若这篇技术干货帮你打通了学习中的卡点:
👀 【关注】跟我一起深耕技术领域,从基础到进阶,见证每一次成长
❤️ 【点赞】让优质内容被更多人看见,让知识传递更有力量
⭐ 【收藏】把核心知识点、实战技巧存好,需要时直接查、随时用
💬 【评论】分享你的经验或疑问(比如曾踩过的技术坑?),一起交流避坑
🗳️ 【投票】用你的选择助力社区内容方向,告诉大家哪个技术点最该重点拆解
技术之路难免有困惑,但同行的人会让前进更有方向~愿我们都能在自己专注的领域里,一步步靠近心中的技术目标!结语:本文我们学习了 HTTP 协议的基础概念、URL 与 URI 的区别、URL 编码解码的原理,并实现了一个最简单的 HTTP 服务器。以下是面试中最常考的核心知识点:HTTP 协议的核心特点:无连接、无状态,URL 的完整格式:协议:// 认证信息 @服务器地址:端口 / 路径?查询字符串 #片段,协议与端口的绑定关系:HTTP=80,HTTPS=443,URI 与 URL 的区别:URL 是 URI 的子集,不仅标识资源还能定位资源,URL 编码的原因和规则:解决特殊字符和非 ASCII 字符的传输问题,编码为 % XY 格式,HTTP 响应的基本格式:响应行 + 响应头 + 空行 + 响应体,HTTP 协议的内容远不止这些,下一篇我们将深入学习 HTTP 请求和响应的详细格式、常见的请求方法和状态码,带你全面掌握 HTTP 协议的核心内容。如果你觉得本文对你有帮助,欢迎点赞、收藏、关注!有任何问题也可以在评论区留言交流。
✨把这些内容吃透超牛的!放松下吧✨ ʕ˘ᴥ˘ʔ づきらど
