OpenClaw Cron 模块深度分析 --- Part 2:服务层与定时器引擎
四、服务层架构
📊 服务层方法调用关系图
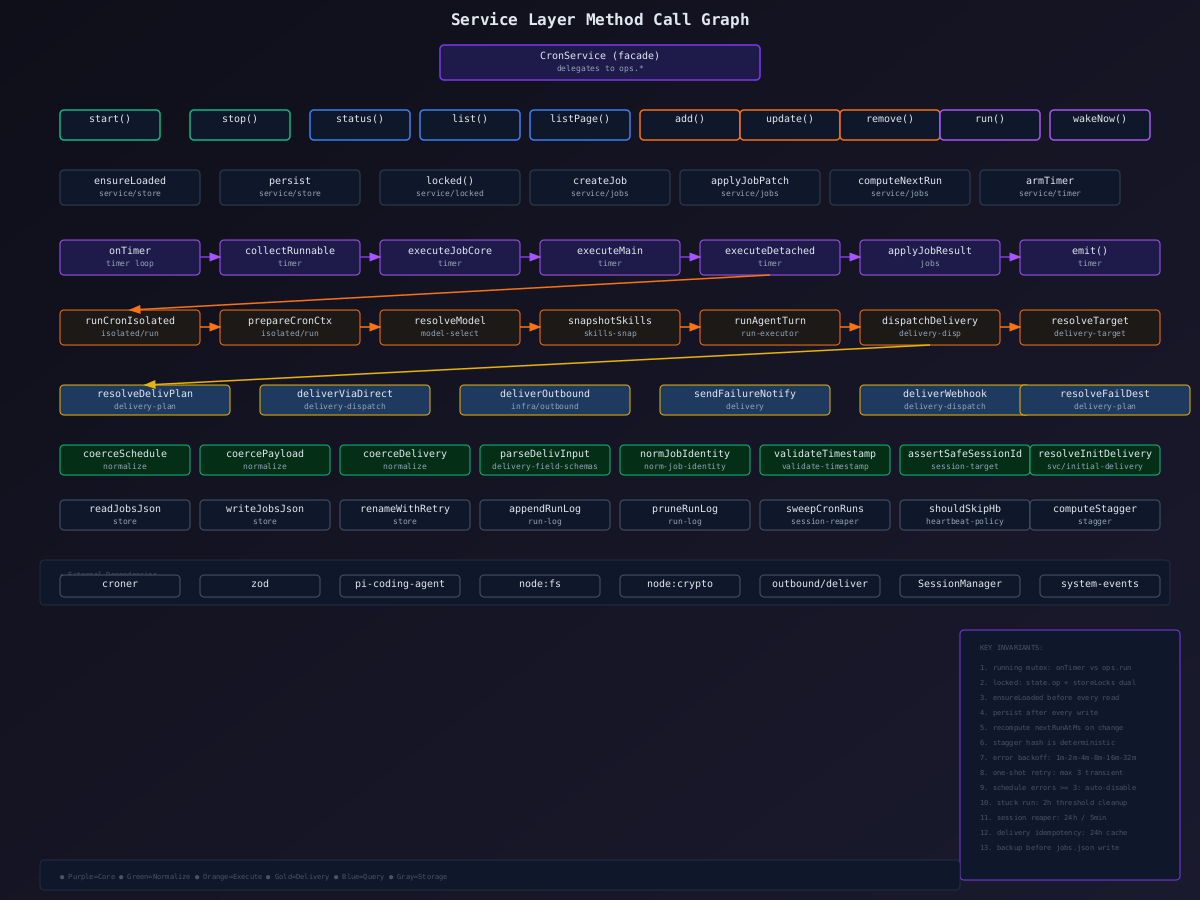
服务层(service/)是 Cron 模块的"大脑皮层"------它负责状态管理、并发控制、持久化读写、作业 CRUD,以及对外暴露的操作接口。整个服务层采用无类函数式 设计:所有函数都以 CronServiceState 作为第一参数显式传入,而非通过 this 隐式引用。这种设计使得测试可以自由构造 state 而无需实例化整个服务,也避免了类继承带来的隐式耦合。
4.1 CronServiceContract 接口设计
文件: service-contract.ts
typescript
export interface CronServiceContract {
start(): Promise<void>;
stop(): void;
list(opts?: { includeDisabled?: boolean }): Promise<CronListResult>;
listPage(opts?: CronListPageOptions): Promise<CronListPageResult>;
add(input: CronAddInput): Promise<CronAddResult>;
update(id: string, patch: CronUpdateInput): Promise<CronUpdateResult>;
remove(id: string): Promise<CronRemoveResult>;
run(id: string, mode?: CronRunMode): Promise<CronServiceRunResult>;
enqueueRun(id: string, mode?: CronRunMode): Promise<CronServiceRunResult>;
getJob(id: string): CronJob | undefined;
wake(opts: { mode: CronWakeMode; text: string }): CronWakeResult;
}接口分析方法:
-
生命周期类 :
start()/stop()--- 启动与停止调度器。start是异步的(需要加载存储、追赶错过作业、计算下次运行时间、启动定时器),stop是同步的(只需清除定时器)。 -
查询类 :
status()/list()/listPage()/getJob()--- 三个粒度的查询接口:status()返回轻量摘要(启用状态、作业数、下次唤醒时间)list()返回简单过滤+排序的作业数组listPage()提供完整的分页能力(query/limit/offset/sortBy/sortDir/enabled 过滤)getJob()直接按 ID 查找,不加锁,不触发 ensureLoaded
-
写操作类 :
add()/update()/remove()--- 标准 CRUD。 -
执行类 :
run()/enqueueRun()--- 两种手动触发方式:run()同步等待执行完成enqueueRun()投入命令队列异步执行,立即返回 enqueue 确认
-
唤醒类 :
wake()--- 向系统注入事件,可选择立即触发心跳或等待下次心跳。
设计亮点:
CronServiceRunResult是CronRunResult的扩展联合类型,增加了invalid-spec原因,专门处理存储中存在无效作业规格的情况listPage和list共存是因为 API 层面的不同需求------CLI/TUI 需要分页,内部监控需要简单列表getJob不走locked机制,是纯内存读取,意味着它可能返回过期数据(如果 store 未加载),但胜在零延迟
实现类 CronService (service.ts)是一个极简的门面:
typescript
export class CronService implements CronServiceContract {
private readonly state;
constructor(deps: CronServiceDeps) {
this.state = createCronServiceState(deps);
}
// 每个方法直接委托给 ops.*
}这种"胖函数、瘦类"模式让核心逻辑完全在纯函数中,类只做初始化和委托。enqueueRun 有一个防御性检查:如果 ops.enqueueRun 返回了未解决的 runnable disposition(理论上不应发生),直接抛异常而非静默返回错误状态。
配图建议:接口合约图
- 节点:
CronServiceContract(接口)、CronService(实现)、ops.*(函数集)、CronServiceState(状态)- 边:CronService → ops.(委托)、ops. → CronServiceState(操作)、CronService → createCronServiceState(构造)
- 标签:每个方法名、返回类型
4.2 CronServiceState 状态机
文件: service/state.ts
typescript
export type CronServiceState = {
deps: CronServiceDepsInternal;
store: CronStoreFile | null;
timer: NodeJS.Timeout | null;
running: boolean;
op: Promise<unknown>;
warnedDisabled: boolean;
storeLoadedAtMs: number | null;
storeFileMtimeMs: number | null;
};逐字段解析:
| 字段 | 类型 | 语义 | 状态转换 |
|---|---|---|---|
deps |
CronServiceDepsInternal |
不可变依赖,构造时确定 | 不变 |
store |
`CronStoreFile | null` | 内存中的作业存储镜像 |
timer |
`NodeJS.Timeout | null` | 当前定时时器句柄 |
running |
boolean |
onTimer 是否正在执行 | false → true(onTimer 入口)→ false(onTimer finally) |
op |
Promise<unknown> |
操作链尾端 Promise,用于 locked() 串行化 | 构造时 Promise.resolve() → 每次locked操作后更新 |
warnedDisabled |
boolean |
是否已发出"调度器已禁用"警告 | false → true(warnIfDisabled,仅一次) |
storeLoadedAtMs |
`number | null` | 上次加载存储的时间戳 |
storeFileMtimeMs |
`number | null` | 上次加载时文件的 mtime |
状态机关键不变量:
- store ↔ timer 一致性 :只要
store !== null且cronEnabled === true,就应有 timer 被 arm。如果 store 未加载,timer 不应运行。 - running 互斥 :
running === true时,新的 onTimer 触发会直接 re-arm 后返回,避免并发执行。 - op 链完整性 :
op始终是一个已 resolve 或 pending 的 Promise,代表最后一个已提交的 locked 操作。它确保了跨 storePath 的操作串行化。 - warnedDisabled 单次性:禁用警告只输出一次,避免每个操作都打日志。
createCronServiceState 工厂函数:
typescript
export function createCronServiceState(deps: CronServiceDeps): CronServiceState {
return {
deps: { ...deps, nowMs: deps.nowMs ?? (() => Date.now()) },
store: null,
timer: null,
running: false,
op: Promise.resolve(),
warnedDisabled: false,
storeLoadedAtMs: null,
storeFileMtimeMs: null,
};
}注意 deps 的展开:CronServiceDeps.nowMs 是可选的(nowMs?: () => number),而 CronServiceDepsInternal.nowMs 是必需的。工厂函数通过 ?? (() => Date.now()) 提供默认实现。这种模式让生产代码可以注入虚拟时钟(用于测试时间敏感逻辑),同时保证运行时总有可用的时钟。
辅助类型:
CronRunMode = "due" | "force"---due只运行到期作业,force无视到期判定CronWakeMode = "now" | "next-heartbeat"--- 唤醒模式CronStatusSummary--- 状态摘要结构CronRunResult--- 运行结果联合类型,区分 ran/enqueued/not-due/already-running/ok-falseCronRemoveResult--- 删除结果CronAddResult = CronJob/CronUpdateResult = CronJob--- 添加/更新直接返回完整作业
配图建议:状态机图
- 节点(状态组合):
IDLE(store=null, timer=null, running=false)、LOADED(store≠null, timer=null, running=false)、ARMED(store≠null, timer≠null, running=false)、RUNNING(store≠null, timer≠null, running=true)- 边(转换):ensureLoaded → IDLE→LOADED、armTimer → LOADED→ARMED、onTimer入口 → ARMED→RUNNING、onTimer.finally → RUNNING→ARMED、stopTimer → *→LOADED
- 标签:触发条件
4.3 CronServiceDeps 依赖注入体系
文件: service/state.ts
typescript
export type CronServiceDeps = {
nowMs?: () => number;
log: Logger;
storePath: string;
cronEnabled: boolean;
cronConfig?: CronConfig;
defaultAgentId?: string;
resolveSessionStorePath?: (agentId?: string) => string;
sessionStorePath?: string;
missedJobStaggerMs?: number;
maxMissedJobsPerRestart?: number;
enqueueSystemEvent: (text: string, opts?: { ... }) => void;
requestHeartbeatNow: (opts?: { ... }) => void;
runHeartbeatOnce?: (opts?: { ... }) => Promise<HeartbeatRunResult>;
wakeNowHeartbeatBusyMaxWaitMs?: number;
wakeNowHeartbeatBusyRetryDelayMs?: number;
runIsolatedAgentJob: (params: { ... }) => Promise<{ ... }>;
sendCronFailureAlert?: (params: { ... }) => Promise<void>;
onEvent?: (evt: CronEvent) => void;
};依赖分类:
基础设施工具(必需):
log: Logger--- 结构化日志器,支持 debug/info/warn/error 四级storePath: string--- 持久化文件路径(jobs.json)cronEnabled: boolean--- 全局开关,影响 armTimer 和 warnIfDisabled
时间控制(可选):
nowMs?: () => number--- 可注入的时钟,测试中用虚拟时钟,生产默认Date.nowmissedJobStaggerMs?: number--- 启动追赶时错开执行的间隔(默认 5000ms)maxMissedJobsPerRestart?: number--- 最多立即执行的错过作业数(默认 5)
会话与代理路由(可选):
defaultAgentId?: string--- 默认代理 ID,用于 main session 作业的 agentId 校验resolveSessionStorePath?: (agentId?) => string--- 根据代理 ID 解析会话存储路径sessionStorePath?: string--- 会话存储路径的直接指定
核心执行通道(必需):
enqueueSystemEvent--- 向主会话注入系统事件requestHeartbeatNow--- 请求立即触发心跳runIsolatedAgentJob--- 核心执行函数:在隔离会话中运行代理轮次
心跳控制(可选):
runHeartbeatOnce?--- 直接执行一次心跳(wakeMode="now" 时使用)wakeNowHeartbeatBusyMaxWaitMs?--- 等待心跳就绪的最大时间(默认 120000ms)wakeNowHeartbeatBusyRetryDelayMs?--- 心跳忙时重试间隔(默认 250ms)
告警与事件(可选):
sendCronFailureAlert?--- 自定义失败告警发送器onEvent?--- 事件回调(added/updated/removed/started/finished)
设计哲学:
- 最小必需原则:只有真正必需的依赖才标记为必需(log, storePath, cronEnabled, enqueueSystemEvent, requestHeartbeatNow, runIsolatedAgentJob),其余都是可选的
- 可测试性 :
nowMs和runIsolatedAgentJob的可注入性使得整个调度循环可以在测试中完全控制 - 渐进增强 :可选依赖缺失时系统仍能运行,只是功能降级(例如没有
runHeartbeatOnce则 wakeMode="now" 会回退到requestHeartbeatNow) - 关注点分离 :deps 不包含任何"如何存储"的知识------存储细节封装在
store.ts和外部的loadCronStore/saveCronStore中
配图建议:依赖关系图
- 中心节点:CronServiceDeps
- 分组节点:基础设施(log, storePath, cronEnabled)、时间控制(nowMs, missedJobStaggerMs)、执行通道(enqueueSystemEvent, runIsolatedAgentJob, runHeartbeatOnce)、告警(sendCronFailureAlert, onEvent)
- 边:标注必需/可选、默认值
- 用不同颜色区分必需依赖与可选依赖
4.4 locked() 并发控制机制
文件: service/locked.ts
这是整个服务层并发控制的核心------一个基于 Promise 链的协作式互斥锁。
typescript
const storeLocks = new Map<string, Promise<void>>();
const resolveChain = (promise: Promise<unknown>) =>
promise.then(
() => undefined,
() => undefined,
);
export async function locked<T>(state: CronServiceState, fn: () => Promise<T>): Promise<T> {
const storePath = state.deps.storePath;
const storeOp = storeLocks.get(storePath) ?? Promise.resolve();
const next = Promise.all([resolveChain(state.op), resolveChain(storeOp)]).then(fn);
const keepAlive = resolveChain(next);
state.op = keepAlive;
storeLocks.set(storePath, keepAlive);
return (await next) as T;
}逐行深度解析:
-
storeLocks:一个全局 Map,键是 storePath,值是该路径上最后一个操作的 Promise。这意味着同一 storePath 下的所有 locked 操作串行执行,但不同 storePath 的操作可以并行------这在多租户场景下至关重要。 -
resolveChain(promise):将任意 Promise 规约为一个Promise<void>,吞掉 rejection。这是一个关键的容错设计:- 前一个操作如果抛异常,不应该阻止后续操作执行
resolveChain确保链不会因前序失败而断裂
-
const storeOp = storeLocks.get(storePath) ?? Promise.resolve():获取当前 storePath 上的链尾 Promise。如果不存在(第一次操作),用已解决的 Promise 作为起点。 -
const next = Promise.all([resolveChain(state.op), resolveChain(storeOp)]).then(fn):- 这是双链等待的核心:同时等待
state.op(进程内操作链)和storeOp(同路径操作链)都完成 state.op防止同一 CronServiceState 实例上的操作并发(例如 timer tick 和手动 run)storeOp防止同一存储文件上的操作并发(例如多个 CronService 实例共享同一文件)Promise.all+resolveChain= 两条链都完成(无论成功失败)后才执行 fn
- 这是双链等待的核心:同时等待
-
const keepAlive = resolveChain(next):将本次操作结果也吞掉 rejection,用于保持链的延续性。 -
state.op = keepAlive; storeLocks.set(storePath, keepAlive):更新两条链的尾部引用,让后续操作等待本次完成。 -
return (await next) as T:返回实际结果。注意next和keepAlive是两个不同的 Promise 引用------next保留了 fn 的实际返回值和可能的 rejection,而keepAlive只用于链的延续。
并发场景分析:
-
场景 A:timer tick 和手动 add 并发
- timer tick 触发 onTimer,在 locked 内执行 ensureLoaded + collectRunnableJobs
- 同时 add() 也进入 locked
- add() 会等待 onTimer 的 locked 块完成后才执行
- 反之亦然
-
场景 B:两个不同的 storePath
storeLocks按 storePath 隔离- 不同路径的操作可以真正并行
- 但
state.op是进程内的,同一 state 上的操作仍然串行
-
场景 C:连续快速操作
- op1 → op2 → op3 依次排队
- 每个操作都会等待前一个完成
- 形成一个链式 Promise 序列
与 fs 锁的比较 :
这种设计没有使用文件锁(flock),因为:
- Cron 服务通常是单进程运行
- 文件锁在异常退出时可能残留
- Promise 链在进程内更高效、更可控
- 跨进程的互斥依赖
forceReload+ 文件系统的原子性来保证
配图建议:并发控制流程图
- 节点:Op1、Op2、Op3(操作)、state.op 链、storeLockspath 链
- 边:Op2 等待 Op1(resolveChain)、Op3 等待 Op2
- 标注:resolveChain 吞错、Promise.all 双链等待
- 并行示例:不同 storePath 的操作可以并行
4.5 ensureLoaded/persist 持久化策略
文件: service/store.ts
ensureLoaded
typescript
export async function ensureLoaded(
state: CronServiceState,
opts?: {
forceReload?: boolean;
skipRecompute?: boolean;
},
) {
// 快速路径:store 已在内存且不强制重载
if (state.store && !opts?.forceReload) {
return;
}
const fileMtimeMs = await getFileMtimeMs(state.deps.storePath);
const loaded = await loadCronStore(state.deps.storePath);
const jobs = (loaded.jobs ?? []) as unknown as CronJob[];
// 逐作业归一化与修复
for (const [index, job] of jobs.entries()) {
// 1. 身份字段归一化(legacy jobId → id)
// 2. 输入归一化(normalizeCronJobInput)
// 3. 无效 sessionTarget 警告
// 4. enabled 字段向后兼容(无 enabled 视为 true)
}
state.store = { version: 1, jobs };
state.storeLoadedAtMs = state.deps.nowMs();
state.storeFileMtimeMs = fileMtimeMs;
if (!opts?.skipRecompute) {
recomputeNextRuns(state);
}
}深度解析:
-
快速路径优化 :
if (state.store && !opts?.forceReload) return--- 一旦 store 加载到内存,后续读操作不再读文件。这在高频操作(list, status)中避免了不必要的 I/O。 -
forceReload 的使用场景:
onTimer的 locked 块内:每次 timer tick 都 forceReload,确保跨进程/外部编辑的变更不会丢失finishPreparedManualRun:执行完作业后 forceReload,因为 isolated agent 可能直接写入磁盘applyStartupCatchupOutcomes:启动追赶后 reload(注释说明可以复用内存,但用了 ensureLoaded)
-
skipRecompute 的使用场景:
onTimer中首次 ensureLoaded:先 skipRecompute,让 collectRunnableJobs 基于持久化的 nextRunAtMs 判断到期作业,避免在未执行到期作业的情况下提前推进 nextRunAtMs(#13992 的核心修复)start()中首次 ensureLoaded:先不重计算,等 runMissedJobs 完成后再重计算update()中:先 skip,因为后续会精确计算单个作业的 nextRunAtMs
-
作业归一化管线:加载时逐作业执行:
normalizeCronJobIdentityFields:将 legacyjobId字段转换为idnormalizeCronJobInput:全面的输入归一化(schedule、payload、delivery 等)isInvalidCronSessionTargetIdError处理:无效的 sessionTarget 不阻断加载,只打警告enabled字段回填:旧作业可能没有enabled字段,默认为true
-
storeFileMtimeMs :记录文件修改时间,当前实现中主要用于文档化目的(代码中未基于 mtime 做增量判断)。但
persist后会更新此字段,防止自己写入后立即触发不必要的重载。
persist
typescript
export async function persist(state: CronServiceState, opts?: { skipBackup?: boolean }) {
if (!state.store) {
return;
}
await saveCronStore(state.deps.storePath, state.store, opts);
state.storeFileMtimeMs = await getFileMtimeMs(state.deps.storePath);
}核心委托 :persist 本身很简单------调用 saveCronStore 然后更新 mtime。复杂性在 saveCronStore(store.ts)中:
- 序列化缓存 :
serializedStoreCache存储上一次写入的 JSON 字符串,如果新写入内容完全相同则跳过 I/O - 运行时字段剥离 :
stripRuntimeOnlyCronFields在备份比较时去掉state和updatedAtMs,因为运行时心跳会频繁更新这些字段,但不需要每次都创建备份 - 原子写入 :先写临时文件(
.pid.random.tmp),再 rename,防止写一半断电导致数据损坏 - 安全文件模式 :
chmod 0o600/ 目录0o700,确保只有当前用户可读写 - 备份策略 :写入前将旧文件复制为
.bak,但仅在内容有实质变化时才备份 - 跨平台兼容:rename 失败时(Windows EPERM/EEXIST)回退到 copyFile + unlink
warnIfDisabled
typescript
export function warnIfDisabled(state: CronServiceState, action: string) {
if (state.deps.cronEnabled) return;
if (state.warnedDisabled) return;
state.warnedDisabled = true;
state.deps.log.warn({ enabled: false, action, storePath }, "cron: scheduler disabled; ...");
}单次警告模式:只在首次操作时警告,避免日志洪水。
ensureLoadedForRead
typescript
async function ensureLoadedForRead(state: CronServiceState) {
await ensureLoaded(state, { skipRecompute: true });
if (!state.store) return;
const changed = recomputeNextRunsForMaintenance(state);
if (changed) await persist(state);
}关键设计 :读操作使用 recomputeNextRunsForMaintenance(而非 recomputeNextRuns),确保不会推进到期的 nextRunAtMs。这是 #16156 和 #13992 修复的核心------读操作不应该默默地跳过到期作业。
配图建议:持久化流程图
- 节点:ensureLoaded、loadCronStore、归一化管线、recomputeNextRuns、persist、saveCronStore
- 边:快速路径跳过、forceReload 路径、skipRecompute 路径
- 标注:每个 opts 选项的影响
五、定时器引擎
📊 定时器引擎流程图
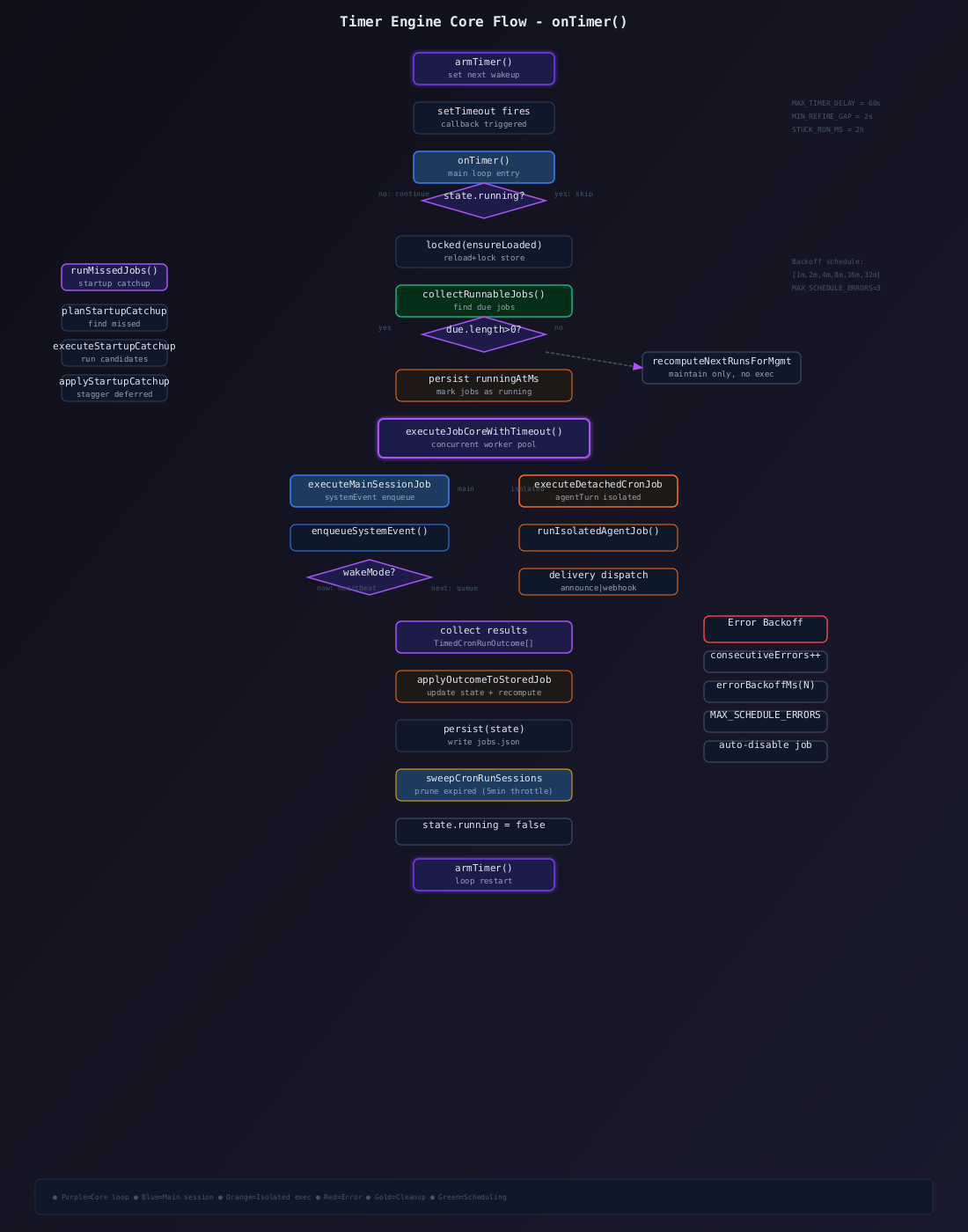
定时器引擎是 Cron 模块的"心脏"------它驱动作业的调度、执行和状态更新。整个引擎基于 setTimeout 实现,配合 onTimer 回调形成事件驱动循环。
5.1 armTimer 定时器调度算法
文件: service/timer.ts
typescript
const MAX_TIMER_DELAY_MS = 60_000; // 60秒
const MIN_REFIRE_GAP_MS = 2_000; // 2秒
export function armTimer(state: CronServiceState) {
// 1. 清除旧定时器
if (state.timer) clearTimeout(state.timer);
state.timer = null;
// 2. 如果调度器禁用,跳过
if (!state.deps.cronEnabled) return;
// 3. 查找最近的下次运行时间
const nextAt = nextWakeAtMs(state);
// 4. 无到期作业的情况
if (!nextAt) {
const enabledCount = ...;
if (enabledCount > 0) {
// 有启用的作业但没有 nextRunAtMs → 用维护重检定时器
armRunningRecheckTimer(state);
return;
}
// 没有任何启用作业 → 不设定时器
return;
}
// 5. 计算延迟
const now = state.deps.nowMs();
const delay = Math.max(nextAt - now, 0);
const flooredDelay = delay === 0 ? MIN_REFIRE_GAP_MS : delay;
const clampedDelay = Math.min(flooredDelay, MAX_TIMER_DELAY_MS);
// 6. 设置定时器
state.timer = setTimeout(() => {
void onTimer(state).catch(...);
}, clampedDelay);
}算法关键点:
-
nextWakeAtMs :遍历所有启用作业,取
nextRunAtMs的最小值。这是 O(n) 操作但 n 通常很小。 -
延迟计算三层保护:
delay = Math.max(nextAt - now, 0):确保非负flooredDelay = delay === 0 ? 2000 : delay:防热循环 。当 nextAt 已经过去但作业因runningAtMs被跳过时,delay 为 0,如果不加 floor,会形成 setTimeout(0) 无限循环(#17821 的修复)clampedDelay = Math.min(flooredDelay, 60000):防漂移。即使下次运行在 1 小时后,也最多 60 秒后唤醒一次,处理时钟跳变、系统休眠恢复等情况
-
维护重检定时器 :
armRunningRecheckTimer设置固定 60 秒的定时器。用于:- 有启用的作业但 nextRunAtMs 为 undefined(可能是计算错误)
- onTimer 执行期间保持调度器心跳(#12025 修复)
-
定时器回调非 async :注释说明回调故意不用
async,因为 Vitest 的假定时器工具会 await 异步回调,可能阻塞测试。
5.2 onTimer 主循环完整流程
typescript
export async function onTimer(state: CronServiceState) {
// 0. 防重入
if (state.running) {
armRunningRecheckTimer(state); // #12025: 保持心跳
return;
}
state.running = true;
armRunningRecheckTimer(state); // 执行期间保持心跳
try {
// Phase 1: 锁内查找到期作业
const dueJobs = await locked(state, async () => {
await ensureLoaded(state, { forceReload: true, skipRecompute: true });
const dueCheckNow = state.deps.nowMs();
const due = collectRunnableJobs(state, dueCheckNow);
if (due.length === 0) {
// 无到期作业 → 维护性重计算
const changed = recomputeNextRunsForMaintenance(state, {
recomputeExpired: true,
nowMs: dueCheckNow,
});
if (changed) await persist(state);
return [];
}
// 标记所有到期作业为正在运行
const now = state.deps.nowMs();
for (const job of due) {
job.state.runningAtMs = now;
job.state.lastError = undefined;
}
await persist(state);
return due.map(j => ({ id: j.id, job: j }));
});
// Phase 2: 锁外并发执行
const concurrency = Math.min(
resolveRunConcurrency(state),
Math.max(1, dueJobs.length)
);
const results = Array.from({ length: dueJobs.length });
let cursor = 0;
const workers = Array.from({ length: concurrency }, async () => {
for (;;) {
const index = cursor++;
if (index >= dueJobs.length) return;
results[index] = await runDueJob(dueJobs[index]);
}
});
await Promise.all(workers);
// Phase 3: 锁内应用结果
if (completedResults.length > 0) {
await locked(state, async () => {
await ensureLoaded(state, { forceReload: true, skipRecompute: true });
for (const result of completedResults) {
applyOutcomeToStoredJob(state, result);
}
recomputeNextRunsForMaintenance(state);
await persist(state);
});
}
} finally {
// Phase 4: 清理与重 arm
// 4a. Session 清理(reaper)
sweepCronRunSessions(...);
state.running = false;
armTimer(state);
}
}流程四阶段深度解析:
Phase 1 --- 锁内查找(快速,只读+标记):
forceReload: true:每次 tick 都从磁盘重读,确保外部变更不丢失skipRecompute: true:关键!先不重计算,让 collectRunnableJobs 基于持久化的 nextRunAtMs 判断。如果先重计算,可能把到期的 nextRunAtMs 推进到未来,导致作业被跳过(#13992)- 标记
runningAtMs并持久化:在释放锁之前记录"正在运行"标记,防止 timer tick 或手动 run 重复触发同一作业 - 如果无到期作业,使用
recomputeNextRunsForMaintenance做保守维护
Phase 2 --- 锁外并发执行:
- 释放锁后执行,避免长时间运行阻塞其他操作(list, status 等)
- 使用 worker 池模式实现并发控制:
resolveRunConcurrency()从cronConfig.maxConcurrentRuns读取,默认 1 cursor++是原子操作(JS 单线程),无需额外同步- 每个作业执行包括:标记 active、发射 started 事件、创建 task ledger 记录、executeJobCoreWithTimeout
Phase 3 --- 锁内应用结果:
- 再次 forceReload:因为 isolated agent 可能在执行期间直接修改了磁盘文件
applyOutcomeToStoredJob:应用每个作业的执行结果到最新的内存镜像- 使用
recomputeNextRunsForMaintenance而非recomputeNextRuns:避免推进在 Phase 1 和 Phase 3 之间新到期的作业(#17852 的修复------日常 cron 不应跳 48 小时)
Phase 4 --- 清理:
- Session reaper:自节流(每 5 分钟一次),清理 cron 运行创建的过期会话
state.running = false+armTimer:无论成功失败都重新启动调度循环
finally 的设计意图 :reaper 放在 finally 而不是 try 块内,因为即使作业执行异常,reaper 仍然需要运行。注释还指出,当长时间运行的作业让 state.running 在多个 tick 周期内保持 true 时,onTimer 的早期返回会跳过 reaper------将 reaper 放在 finally 是为了确保它至少在当前 tick 执行。
5.3 collectRunnableJobs 调度决策逻辑
typescript
function collectRunnableJobs(
state: CronServiceState,
nowMs: number,
opts?: {
skipJobIds?: ReadonlySet<string>;
skipAtIfAlreadyRan?: boolean;
allowCronMissedRunByLastRun?: boolean;
},
): CronJob[]委托给 isRunnableJob 逐作业判定:
typescript
function isRunnableJob(params: {
job: CronJob;
nowMs: number;
skipJobIds?: ReadonlySet<string>;
skipAtIfAlreadyRun?: boolean;
allowCronMissedRunByLastRun?: boolean;
}): boolean {
// 1. 禁用检查
if (!isJobEnabled(job)) return false;
// 2. 跳过集合检查(启动追赶时排除中断的一次性作业)
if (params.skipJobIds?.has(job.id)) return false;
// 3. 运行中检查
if (typeof job.state.runningAtMs === "number") return false;
// 4. 一次性作业已完成检查
if (params.skipAtIfAlreadyRan && job.schedule.kind === "at" && job.state.lastStatus) {
// 特例:瞬态错误重试中,nextRunAtMs > lastRunAtMs
if (job.state.lastStatus === "error" && ... && nextRun > lastRun) {
return nowMs >= nextRun;
}
return false;
}
// 5. 常规到期判定
if (hasScheduledNextRunAtMs(next) && nowMs >= next) return true;
// 6. 退避窗口检查(错误重试中,backoff 未到期)
if (hasScheduledNextRunAtMs(next) && next > nowMs && isErrorBackoffPending(job, nowMs)) {
return false;
}
// 7. 错过运行检测(启动追赶专用)
if (!params.allowCronMissedRunByLastRun || job.schedule.kind !== "cron") return false;
// 计算 previousRunAtMs,如果 > lastRunAtMs 则说明错过了
return previousRunAtMs > lastRunAtMs;
}决策优先级(从高到低):
- 禁用 → 跳过
- 在跳过集合中 → 跳过
- 正在运行 → 跳过
- 一次性作业已完成 → 跳过(除非瞬态重试)
- nextRunAtMs 已到期 → 可运行
- nextRunAtMs 在未来但退避中 → 跳过
- 启动追赶模式:错过检测 → 可运行
opts 参数的调用场景:
skipJobIds:start()中传入中断的一次性作业 ID(它们不应被追赶)skipAtIfAlreadyRan:planStartupCatchup中为 true,避免重新运行已完成的一次性作业allowCronMissedRunByLastRun:planStartupCatchup中为 true,检测在停机期间错过的 cron 作业
5.4 executeJobCore 双路径执行(main vs isolated)
typescript
export async function executeJobCore(
state: CronServiceState,
job: CronJob,
abortSignal?: AbortSignal,
): Promise<CronRunOutcome & CronRunTelemetry & { delivered?; deliveryAttempted? }>路径分发:
sessionTarget === "main" → executeMainSessionCronJob
sessionTarget !== "main" → executeDetachedCronJob路径 A:executeMainSessionCronJob
主会话路径的核心是"注入系统事件 + 唤醒心跳":
typescript
async function executeMainSessionCronJob(...) {
// 1. 提取 systemEvent 文本
const text = resolveJobPayloadTextForMain(job);
if (!text) return { status: "skipped", error: "..." };
// 2. 注入系统事件
state.deps.enqueueSystemEvent(text, { agentId, sessionKey, contextKey });
// 3. 根据 wakeMode 选择唤醒策略
if (job.wakeMode === "now" && state.deps.runHeartbeatOnce) {
// 3a. 立即唤醒:循环等待心跳执行
for (;;) {
heartbeatResult = await state.deps.runHeartbeatOnce(...);
if (heartbeatResult.status !== "skipped" ||
heartbeatResult.reason !== "requests-in-flight") break;
// 周期作业不等待忙心跳(#58833:避免队列等待反映到 cron 持续时间)
if (isRecurringJob) {
state.deps.requestHeartbeatNow(...);
return { status: "ok", summary: text };
}
// 超时回退
if (nowMs - waitStartedAt > maxWaitMs) {
state.deps.requestHeartbeatNow(...);
return { status: "ok", summary: text };
}
await waitWithAbort(retryDelayMs);
}
}
// 3b. 常规唤醒
state.deps.requestHeartbeatNow(...);
return { status: "ok", summary: text };
}设计精髓:
-
事件注入 + 心跳唤醒 = 延迟执行:main session 作业不直接执行,而是将事件注入队列,然后请求心跳来处理。这意味着 cron 作业的实际执行发生在心跳循环中,而非 cron 线程中。
-
wakeMode="now" 的忙等待策略:
- 使用
runHeartbeatOnce直接触发心跳,而非requestHeartbeatNow(后者只是调度) - 如果主车道忙(requests-in-flight),会循环重试
- 有超时保护(
wakeNowHeartbeatBusyMaxWaitMs,默认 2 分钟) - 周期作业特殊处理 (#58833):检测到忙时直接退回到
requestHeartbeatNow,避免 cron 作业的执行时间反映的是队列等待而非实际执行
- 使用
-
abort 信号支持 :
waitWithAbort函数在等待期间监听 abort 信号,超时时立即返回错误状态。
路径 B:executeDetachedCronJob
隔离会话路径是真正的"执行":
typescript
async function executeDetachedCronJob(...) {
if (job.payload.kind !== "agentTurn") {
return { status: "skipped", error: "isolated job requires payload.kind=agentTurn" };
}
if (abortSignal?.aborted) return resolveAbortError();
const res = await state.deps.runIsolatedAgentJob({
job,
message: job.payload.message,
abortSignal,
});
if (abortSignal?.aborted) return { status: "error", error: timeoutErrorMessage() };
return {
status: res.status,
error: res.error,
summary: res.summary,
delivered: res.delivered,
deliveryAttempted: res.deliveryAttempted,
sessionId: res.sessionId,
sessionKey: res.sessionKey,
model: res.model,
provider: res.provider,
usage: res.usage,
};
}关键特征:
- 直接委托给
deps.runIsolatedAgentJob,执行在独立会话中 - 执行后再次检查 abort 信号(双重检查模式)
- 返回丰富的遥测数据(model, provider, usage)------这些来自代理的实际执行
超时包装:executeJobCoreWithTimeout
typescript
export async function executeJobCoreWithTimeout(state, job) {
const jobTimeoutMs = resolveCronJobTimeoutMs(job);
if (typeof jobTimeoutMs !== "number") return await executeJobCore(state, job);
const runAbortController = new AbortController();
return await Promise.race([
executeJobCore(state, job, runAbortController.signal),
new Promise<never>((_, reject) => {
timeoutId = setTimeout(() => {
runAbortController.abort(timeoutErrorMessage());
reject(new Error(timeoutErrorMessage()));
}, jobTimeoutMs);
}),
]);
}超时策略:
resolveCronJobTimeoutMs根据 payload 类型选择不同的默认超时agentTurn有 60 分钟安全上限,其他类型 10 分钟- 使用
Promise.race+AbortController实现 - 超时时 abort 信号传递给 executeJobCore,让内部的
waitWithAbort和runIsolatedAgentJob可以提前退出
5.5 applyJobResult 结果处理与状态更新
这是整个状态更新逻辑的核心函数,决定作业执行后的所有状态变化:
typescript
export function applyJobResult(
state: CronServiceState,
job: CronJob,
result: {
status: CronRunStatus;
error?: string;
delivered?: boolean;
startedAt: number;
endedAt: number;
},
opts?: { preserveSchedule?: boolean },
): boolean // 返回是否应删除作业完整流程:
1. 记录基础状态
- runningAtMs = undefined (清除运行标记)
- lastRunAtMs = startedAt
- lastRunStatus = status
- lastStatus = status
- lastDurationMs = endedAt - startedAt
- lastError = error
- lastErrorReason = failover 原因解析
- lastDelivered = delivered
- lastDeliveryStatus = resolveDeliveryStatus(...)
- updatedAtMs = endedAt
2. 错误追踪
if (status === "error"):
consecutiveErrors += 1
检查是否需要失败告警:
- 解析告警配置 (job级 → 全局级)
- 超过 after 阈值 && 不在冷却期 && 非 bestEffort → 发送告警
else:
consecutiveErrors = 0
lastFailureAlertAtMs = undefined
3. 一次性作业删除判定
shouldDelete = (schedule.kind === "at" && deleteAfterRun && status === "ok")
4. 下次运行计算 (分支处理)
if shouldDelete:
→ 返回 true (不计算下次运行)
elif schedule.kind === "at": (一次性作业)
if status === "ok" || "skipped": disable + nextRunAtMs = undefined
if status === "error":
if 瞬态错误 && consecutiveErrors <= maxAttempts:
→ nextRunAtMs = endedAt + backoff (瞬态重试)
else:
→ disable + nextRunAtMs = undefined
elif status === "error" && enabled: (周期作业错误)
backoff = errorBackoffMs(consecutiveErrors)
normalNext = computeJobNextRunAtMs(job, endedAt)
nextRunAtMs = max(normalNext, endedAt + backoff)
elif enabled: (周期作业成功)
nextRunAtMs = computeJobNextRunAtMs(job, endedAt)
if schedule.kind === "cron":
→ 确保 nextRunAtMs >= endedAt + MIN_REFIRE_GAP_MS (防热循环)
else:
nextRunAtMs = undefined
5. 返回 shouldDelete关键设计决策:
-
preserveSchedule 选项:用于手动 force 运行。当 force 运行 every 类型的作业时,不应让此次运行影响"每 N 毫秒"的锚点计算。实现方式是临时恢复
lastRunAtMs为执行前的值来计算 nextRun,然后恢复。 -
一次性作业的错误重试 (#24355):瞬态错误(限流、过载、网络)允许重试,使用指数退避。非瞬态错误或超过最大重试次数后禁用。
deleteAfterRun:true只在status === "ok"时触发删除,所以耗尽重试的一次性作业保留在 store 中供检查。 -
cron 作业的 MIN_REFIRE_GAP_MS(#17821):cron 表达式计算可能在同一秒内返回"下一个"时间点,导致无限触发循环。2 秒的最小间隔是安全网。
-
resolveCronNextRunWithLowerBound:专门为 cron 类型作业设计的下限解析函数。如果自然下次运行时间无法解析(undefined),会发出警告并清除 schedule 以避免触发循环。
-
失败告警机制:
- 支持 job 级和全局级配置
- 有冷却期(默认 1 小时),避免频繁告警
- bestEffort 模式的作业不发送告警
- 支持 announce 和 webhook 两种模式
5.6 错误退避与瞬态重试机制
退避调度:
typescript
export const DEFAULT_ERROR_BACKOFF_SCHEDULE_MS = [
30_000, // 30秒
60_000, // 1分钟
5 * 60_000, // 5分钟
15 * 60_000, // 15分钟
60 * 60_000, // 1小时
];
export function errorBackoffMs(
consecutiveErrors: number,
scheduleMs = DEFAULT_ERROR_BACKOFF_SCHEDULE_MS,
): number {
const idx = Math.min(consecutiveErrors - 1, scheduleMs.length - 1);
return scheduleMs[Math.max(0, idx)] ?? scheduleMs[0];
}设计:
- 5 级递增退避,从 30 秒到 1 小时
- 超过 5 次错误后封顶在 1 小时
- 可通过
cronConfig.retry.backoffMs自定义
瞬态错误识别:
typescript
const TRANSIENT_PATTERNS: Record<string, RegExp> = {
rate_limit: /(rate[_ ]limit|too many requests|429|...)/i,
overloaded: /\b529\b|\boverloaded(?:_error)?\b|.../i,
network: /(network|econnreset|econnrefused|fetch failed|socket)/i,
timeout: /(timeout|etimedout)/i,
server_error: /\b5\d{2}\b/,
};5 类瞬态错误模式:
- 限流(rate limit/429)
- 过载(529/overloaded)
- 网络(ECONNRESET/ECONNREFUSED)
- 超时(timeout/ETIMEDOUT)
- 服务器错误(5xx)
重试配置:
typescript
function resolveRetryConfig(cronConfig?: CronConfig) {
const retry = cronConfig?.retry;
return {
maxAttempts: retry?.maxAttempts ?? 3,
backoffMs: retry?.backoffMs ?? [30_000, 60_000, 5 * 60_000],
retryOn: retry?.retryOn ?? undefined,
};
}- 默认最多 3 次重试
- 默认使用前 3 级退避
retryOn可以自定义哪些瞬态类别触发重试
重试决策流程:
错误发生 → 错误文本匹配瞬态模式?
├─ 否 → 非瞬态错误 → 禁用作业
└─ 是 → consecutiveErrors <= maxAttempts?
├─ 是 → 安排退避重试 (nextRunAtMs = endedAt + backoff)
└─ 否 → 禁用作业 (max retries exhausted)注意 :瞬态重试只对一次性作业(schedule.kind === "at")生效。周期作业的错误统一使用 errorBackoffMs 退避,但不区分瞬态/非瞬态------它们不会被禁用(除非 schedule 计算连续出错 3 次)。
5.7 启动追赶(runMissedJobs)策略
typescript
export async function runMissedJobs(
state: CronServiceState,
opts?: { skipJobIds?: ReadonlySet<string> },
) {
const plan = await planStartupCatchup(state, opts);
if (plan.candidates.length === 0 && plan.deferredJobIds.length === 0) return;
const outcomes = await executeStartupCatchupPlan(state, plan);
await applyStartupCatchupOutcomes(state, plan, outcomes);
}三阶段设计:
Phase 1: planStartupCatchup(计划阶段)
typescript
async function planStartupCatchup(state, opts?) {
const maxImmediate = state.deps.maxMissedJobsPerRestart ?? 5;
return locked(state, async () => {
await ensureLoaded(state, { skipRecompute: true });
const now = state.deps.nowMs();
const missed = collectRunnableJobs(state, now, {
skipJobIds: opts?.skipJobIds,
skipAtIfAlreadyRan: true, // 不重跑已完成的一次性作业
allowCronMissedRunByLastRun: true, // 启用错过检测
});
const sorted = missed.toSorted((a, b) =>
(a.state.nextRunAtMs ?? 0) - (b.state.nextRunAtMs ?? 0)
);
const startupCandidates = sorted.slice(0, maxImmediate); // 立即执行
const deferred = sorted.slice(maxImmediate); // 延迟执行
// 标记立即执行的作业为 running
for (const job of startupCandidates) {
job.state.runningAtMs = now;
job.state.lastError = undefined;
}
await persist(state);
return { candidates, deferredJobIds };
});
}关键设计:
skipAtIfAlreadyRan: true:已完成的一次性作业不参与追赶allowCronMissedRunByLastRun: true:通过previousRunAtMs > lastRunAtMs检测停机期间错过的 cron 作业- 最多
maxMissedJobsPerRestart(默认 5)个作业立即执行,超出的延迟 - 按 nextRunAtMs 排序,优先执行"最过期"的
Phase 2: executeStartupCatchupPlan(执行阶段)
typescript
async function executeStartupCatchupPlan(state, plan) {
const outcomes: TimedCronRunOutcome[] = [];
for (const candidate of plan.candidates) {
outcomes.push(await runStartupCatchupCandidate(state, candidate));
}
return outcomes;
}注意 :启动追赶到执行是串行的(for...of await),不是并行的。这避免了在启动阶段对网关造成突发负载。与 onTimer 中的 worker 池并发不同。
Phase 3: applyStartupCatchupOutcomes(应用阶段)
typescript
async function applyStartupCatchupOutcomes(state, plan, outcomes) {
const staggerMs = state.deps.missedJobStaggerMs ?? 5_000;
await locked(state, async () => {
await ensureLoaded(state, { skipRecompute: true });
for (const result of outcomes) {
applyOutcomeToStoredJob(state, result);
}
// 延迟作业:按阶梯安排下次运行
if (plan.deferredJobIds.length > 0) {
const baseNow = state.deps.nowMs();
let offset = staggerMs;
for (const jobId of plan.deferredJobIds) {
const job = state.store.jobs.find(entry => entry.id === jobId);
if (!job || !isJobEnabled(job)) continue;
job.state.nextRunAtMs = baseNow + offset;
offset += staggerMs;
}
}
recomputeNextRunsForMaintenance(state);
await persist(state);
});
}延迟作业的阶梯调度 :每个被推迟的作业的 nextRunAtMs 设为 baseNow + offset,offset 每次递增 staggerMs(默认 5 秒)。例如 10 个被推迟的作业会在接下来 50 秒内依次执行。
start() 的完整流程:
1. 清除所有 stale runningAtMs 标记
- 一次性作业的中断 ID 收集到 interruptedOneShotIds
2. runMissedJobs(state, { skipJobIds: interruptedOneShotIds })
- 不追赶上次运行中被中断的一次性作业
3. ensureLoaded + recomputeNextRuns
- 追赶完成后再做全量重计算
4. armTimer
- 开始正常调度循环5.8 stagger 防惊群机制
文件: service/jobs.ts + stagger.ts
问题 :多个 cron 作业配置了相同的整点表达式(如 0 * * * *),如果同时触发,会对下游服务造成突发负载。
解决方案:基于作业 ID 的确定性偏移。
typescript
function resolveStableCronOffsetMs(jobId: string, staggerMs: number) {
if (staggerMs <= 1) return 0;
const cacheKey = `${staggerMs}:${jobId}`;
const cached = staggerOffsetCache.get(cacheKey);
if (cached !== undefined) return cached;
const digest = crypto.createHash("sha256").update(jobId).digest();
const offset = digest.readUInt32BE(0) % staggerMs;
// LRU 缓存(最大 4096 条)
staggerOffsetCache.set(cacheKey, offset);
return offset;
}机制解析:
-
确定性:对 jobId 做 SHA256 哈希,取前 4 字节转为 uint32,对 staggerMs 取模。同一个 jobId 在任何时刻、任何进程上都得到相同的偏移量。
-
均匀分布 :SHA256 的输出均匀分布,取模后偏移量在
[0, staggerMs)范围内均匀分布。 -
缓存 :
staggerOffsetCache避免重复哈希计算,最大 4096 条(LRU 驱逐)。 -
staggerMs 的确定:
- 显式指定:
schedule.staggerMs - 隐式推断:
isRecurringTopOfHourCronExpr检测整点 cron 表达式(0 * * * *),自动分配 5 分钟的 stagger - 默认:0(无偏移)
- 显式指定:
computeStaggeredCronNextRunAtMs 算法:
typescript
function computeStaggeredCronNextRunAtMs(job: CronJob, nowMs: number) {
if (job.schedule.kind !== "cron") return computeNextRunAtMs(job.schedule, nowMs);
const staggerMs = resolveCronStaggerMs(job.schedule);
const offsetMs = resolveStableCronOffsetMs(job.id, staggerMs);
if (offsetMs <= 0) return computeNextRunAtMs(job.schedule, nowMs);
// 核心:将时间光标前移 offsetMs,计算基础下次运行时间,再加回 offsetMs
let cursorMs = Math.max(0, nowMs - offsetMs);
for (let attempt = 0; attempt < 4; attempt++) {
const baseNext = computeNextRunAtMs(job.schedule, cursorMs);
if (baseNext === undefined) return undefined;
const shifted = baseNext + offsetMs;
if (shifted > nowMs) return shifted; // 找到未来的偏移时间点
cursorMs = Math.max(cursorMs + 1, baseNext + 1_000);
}
return undefined; // 4 次尝试未找到,放弃
}算法核心思想 :将时间轴"虚拟前移" offsetMs,在虚拟时间线上计算 cron 下次触发时间,然后"移回" offsetMs。这样每个作业的触发时间就被确定性偏移了。
示例:
- 作业 A 和作业 B 都配置了
0 * * * *(每小时整点) - staggerMs = 5 分钟
- 作业 A 的 SHA256 offset = 120000(2 分钟)
- 作业 B 的 SHA256 offset = 240000(4 分钟)
- 实际触发时间:作业 A 在每小时的 :02,作业 B 在每小时的 :04
4 次尝试上限:处理边界情况------如果偏移后的时间点恰好已经过去(例如 offset 很大,整点 + offset 已过),需要继续寻找下一个时间窗口。4 次足以覆盖至少一个完整的 cron 周期。
配图建议:时间轴图
- 横轴:时间
- 纵轴:多个作业(Job A, Job B, Job C)
- 标注:原始触发点(整点)、偏移量、实际触发点
- 展示 SHA256 确定性偏移如何分散触发
六、作业生命周期
📊 作业生命周期状态机
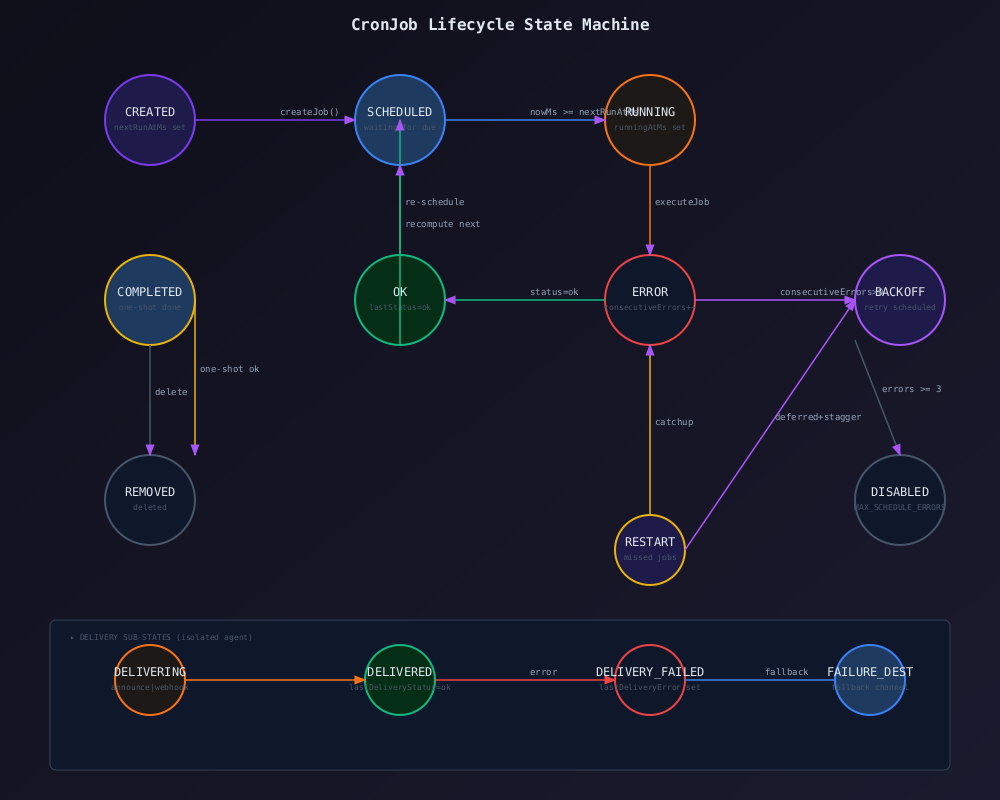
6.1 作业创建(createJob)
文件: service/jobs.ts
typescript
export function createJob(state: CronServiceState, input: CronJobCreate): CronJob {
const now = state.deps.nowMs();
const id = crypto.randomUUID();
// 1. Schedule 归一化
const schedule = input.schedule.kind === "every"
? { ...input.schedule, anchorMs: resolveEveryAnchorMs({ schedule: input.schedule, fallbackAnchorMs: now }) }
: input.schedule.kind === "cron"
? (() => {
const explicitStaggerMs = normalizeCronStaggerMs(input.schedule.staggerMs);
if (explicitStaggerMs !== undefined) return { ...input.schedule, staggerMs: explicitStaggerMs };
const defaultStaggerMs = resolveDefaultCronStaggerMs(input.schedule.expr);
return defaultStaggerMs !== undefined
? { ...input.schedule, staggerMs: defaultStaggerMs }
: input.schedule;
})()
: input.schedule;
// 2. deleteAfterRun 推断
const deleteAfterRun = typeof input.deleteAfterRun === "boolean"
? input.deleteAfterRun
: schedule.kind === "at" ? true : undefined;
// 3. 构造作业对象
const job: CronJob = {
id,
agentId: normalizeOptionalAgentId(input.agentId),
sessionKey: normalizeOptionalString(input.sessionKey),
name: normalizeRequiredName(input.name),
description: normalizeOptionalString(input.description),
enabled: typeof input.enabled === "boolean" ? input.enabled : true,
deleteAfterRun,
createdAtMs: now,
updatedAtMs: now,
schedule,
sessionTarget: input.sessionTarget,
wakeMode: input.wakeMode,
payload: input.payload,
delivery: resolveInitialCronDelivery(input),
failureAlert: input.failureAlert,
state: { ...input.state },
};
// 4. 规格验证
assertSupportedJobSpec(job);
assertMainSessionAgentId(job, state.deps.defaultAgentId);
assertDeliverySupport(job);
assertFailureDestinationSupport(job);
// 5. 计算首次运行时间
job.state.nextRunAtMs = computeJobNextRunAtMs(job, now);
return job;
}创建流程五步:
Step 1 --- Schedule 归一化:
every类型:补全anchorMs,默认为当前时间cron类型:计算 staggerMs------显式指定 > 整点表达式推断 > 无 staggerat类型:原样使用
Step 2 --- deleteAfterRun 推断:
- 如果未指定且 schedule.kind === "at",默认为 true(一次性作业执行后删除)
- 其他类型默认为 undefined(不删除)
Step 3 --- 字段归一化:
name:必需,trim 后非空agentId:可选,通过normalizeAgentId归一化sessionKey:可选字符串enabled:默认 truedelivery:委托给resolveInitialCronDelivery
Step 4 --- 四重断言验证:
assertSupportedJobSpec:main 作业必须 systemEvent,isolated 作业必须 agentTurnassertMainSessionAgentId:main 作业的 agentId 必须与 defaultAgentId 匹配assertDeliverySupport:channel delivery 只支持 isolated 作业,webhook 需要有效 URLassertFailureDestinationSupport:failureDestination 只支持 isolated 作业或 webhook 模式
Step 5 --- 计算首次 nextRunAtMs:这是创建的最后一步,确保新作业立即可调度。
6.2 作业更新(applyJobPatch)
typescript
export function applyJobPatch(
job: CronJob,
patch: CronJobPatch,
opts?: { defaultAgentId?: string },
)合并策略:
applyJobPatch 使用选择性合并而非全量替换------只修改 patch 中明确指定的字段:
| 字段 | 合并策略 |
|---|---|
| name | 直接替换(必需,normalizeRequiredName) |
| description | 直接替换 |
| enabled | 直接替换 |
| deleteAfterRun | 直接替换 |
| schedule | 智能合并:cron 类型保留旧 staggerMs;其他类型直接替换 |
| sessionTarget | 直接替换 |
| wakeMode | 直接替换 |
| payload | 深度合并(mergeCronPayload) |
| delivery | 深度合并(mergeCronDelivery) |
| failureAlert | 深度合并(mergeCronFailureAlert) |
| state | 浅合并({ ...job.state, ...patch.state }) |
| agentId | 归一化后替换 |
| sessionKey | 归一化后替换 |
Schedule 智能合并:
typescript
if (patch.schedule.kind === "cron") {
const explicitStaggerMs = normalizeCronStaggerMs(patch.schedule.staggerMs);
if (explicitStaggerMs !== undefined) {
job.schedule = { ...patch.schedule, staggerMs: explicitStaggerMs };
} else if (job.schedule.kind === "cron") {
// 保留旧 staggerMs!
job.schedule = { ...patch.schedule, staggerMs: job.schedule.staggerMs };
} else {
// 旧 schedule 不是 cron,推断默认 staggerMs
const defaultStaggerMs = resolveDefaultCronStaggerMs(patch.schedule.expr);
job.schedule = defaultStaggerMs !== undefined
? { ...patch.schedule, staggerMs: defaultStaggerMs }
: patch.schedule;
}
}Payload 深度合并(mergeCronPayload):
- 如果 kind 不同:整体替换(buildPayloadFromPatch)
- 如果 kind 相同且是 systemEvent:合并 text 字段
- 如果 kind 相同且是 agentTurn:逐字段合并(message, model, fallbacks, toolsAllow, thinking, timeoutSeconds, lightContext, allowUnsafeExternalContent)
toolsAllow: null表示清除(删除字段),toolsAllow: Array表示设置,未提供则保留原值
Delivery 深度合并(mergeCronDelivery):
- 从 existing 构建基础结构,逐字段覆盖
- 特殊处理:
patch.mode === "deliver"会被归一化为"announce"(向后兼容) failureDestination的嵌套合并:每个子字段(channel, to, accountId, mode)独立覆盖failureDestination === undefined表示清除
patch.schedule 变更的后续处理(在 ops.update 中):
typescript
if (scheduleChanged || enabledChanged) {
if (isJobEnabled(job)) {
job.state.nextRunAtMs = computeJobNextRunAtMs(job, now);
} else {
job.state.nextRunAtMs = undefined;
job.state.runningAtMs = undefined;
}
} else if (isJobEnabled(job) && !hasScheduledNextRunAtMs(job.state.nextRunAtMs)) {
job.state.nextRunAtMs = computeJobNextRunAtMs(job, now);
}设计意图:只在 schedule 或 enabled 实际变更时重计算 nextRunAtMs。其他字段的更新不触发重计算,避免不必要的调度扰动。
6.3 作业到期判定(isJobDue)
typescript
export function isJobDue(job: CronJob, nowMs: number, opts: { forced: boolean }) {
if (!job.state) job.state = {};
if (typeof job.state.runningAtMs === "number") return false; // 正在运行
if (opts.forced) return true; // 强制模式
return (
isJobEnabled(job) && // 已启用
hasScheduledNextRunAtMs(job.state.nextRunAtMs) && // 有有效下次运行时间
nowMs >= job.state.nextRunAtMs // 时间已到
);
}三层检查:
- 运行中 → 不可运行(任何模式)
- 强制模式 → 可运行(跳过 enabled 和时间检查)
- 正常模式 → enabled + 有效 nextRunAtMs + 时间已到
与 isRunnableJob 的关系 :isJobDue 是简化版的 isRunnableJob,用于手动 run 命令的预检。isRunnableJob 是完整版,用于定时器引擎和启动追赶,包含更多选项(skipJobIds, skipAtIfAlreadyRan, allowCronMissedRunByLastRun)。
6.4 一次性作业特殊处理
一次性作业(schedule.kind === "at")在多个环节有特殊逻辑:
创建时:
deleteAfterRun默认为true(其他类型默认 undefined)- 计算 nextRunAtMs 直接使用 atMs(绝对时间戳)
到期判定时:
- 启动追赶中
skipAtIfAlreadyRan: true:已完成的一次性作业不参与追赶 - 但瞬态错误重试中的例外:如果
nextRunAtMs > lastRunAtMs,说明是重试而非新触发
执行后状态更新:
- 成功 :
deleteAfterRun === true→ 从 store 中删除deleteAfterRun !== true→ 禁用作业,nextRunAtMs = undefined
- 跳过 :
- 禁用作业(#11452:防止跳过后热循环)
- 错误 :
- 瞬态错误 → 安排退避重试(最多 maxAttempts 次)
- 非瞬态错误 → 禁用作业
- 重试耗尽 → 禁用作业(保留在 store 中供检查,不删除)
关键设计决策:
- 成功后不删除 vs 删除 :由
deleteAfterRun控制。默认删除,但显式设为 false 可以保留作业记录。 - 错误后保留 :即使
deleteAfterRun: true,错误时也不删除------保留错误状态供用户检查是更安全的选择。 - 瞬态重试(#24355):限流、过载等暂时性错误允许自动重试,使用退避调度。这是后来添加的功能,之前一次性作业错误就直接禁用。
computeJobNextRunAtMs 中的一次性作业逻辑:
typescript
if (job.schedule.kind === "at") {
// 解析 atMs(支持 string 和 legacy number 格式)
const atMs = ...;
// 如果已成功完成且未更新 schedule → 不再到期
if (job.state.lastStatus === "ok" && job.state.lastRunAtMs) {
if (atMs !== null && atMs > job.state.lastRunAtMs) return atMs; // schedule 更新了
return undefined; // 真正完成
}
return atMs; // 未完成或从未运行
}6.5 作业删除策略
显式删除(remove):
typescript
export async function remove(state: CronServiceState, id: string) {
return await locked(state, async () => {
await ensureLoaded(state);
const before = state.store?.jobs.length ?? 0;
state.store.jobs = state.store?.jobs.filter((j) => j.id !== id) ?? [];
const removed = (state.store?.jobs.length ?? 0) !== before;
await persist(state);
armTimer(state);
if (removed) emit(state, { jobId: id, action: "removed" });
return { ok: true, removed } as const;
});
}简单过滤 + 持久化 + 重 arm 定时器。注意即使作业不存在也返回 ok: true, removed: false------删除不存在的作业不算错误。
隐式删除(执行后):
在 applyJobResult 返回 shouldDelete === true 时触发,发生在:
applyOutcomeToStoredJob中(timer tick 路径)finishPreparedManualRun中(手动 run 路径)
隐式删除后:
- 发射
removed事件 - 从 store.jobs 中过滤掉
- 如果是手动 run,还会 forceReload 并合并快照(防止 isolated agent 的磁盘写入被覆盖)
Stuck 运行标记清理:
typescript
const STUCK_RUN_MS = 2 * 60 * 60 * 1000; // 2小时
if (typeof runningAt === "number" && nowMs - runningAt > STUCK_RUN_MS) {
state.deps.log.warn({ jobId: job.id, runningAtMs: runningAt }, "cron: clearing stuck running marker");
job.state.runningAtMs = undefined;
changed = true;
}2 小时阈值:如果作业的 runningAtMs 超过 2 小时未清除,视为卡住(进程崩溃后恢复的残留标记),自动清除。
启动时的标记清理:
typescript
// start() 中
for (const job of jobs) {
if (typeof job.state.runningAtMs === "number") {
job.state.runningAtMs = undefined;
if (job.schedule.kind === "at") {
interruptedOneShotIds.add(job.id); // 中断的一次性作业不追赶
}
}
}设计理由 :进程重启时所有 runningAtMs 都是过时的(上次进程已死),全部清除。但一次性作业的中断需要特殊标记------它们不应该在启动追赶中重新执行,因为一次性作业通常是时间敏感的(如"在下午3点发送通知"),错过了就不应该补发。
配图建议:作业生命周期状态图
- 节点:Created → Scheduled (enabled, nextRunAtMs set) → Running (runningAtMs set) → Completed/Errored/Disabled/Deleted
- 边:add → Created、armTimer → Scheduled、onTimer → Running、applyJobResult → Completed/Errored/Disabled、deleteAfterRun → Deleted
- 特殊路径:瞬态重试循环(at 类型)、退避重试循环(周期类型错误)、卡住标记清理
- 标签:每个转换的触发条件和状态变化
附录:关键常量与配置速查
| 常量/配置 | 默认值 | 位置 | 作用 |
|---|---|---|---|
MAX_TIMER_DELAY_MS |
60,000 (60s) | timer.ts | 定时器最大间隔,防止漂移 |
MIN_REFIRE_GAP_MS |
2,000 (2s) | timer.ts | 最小重触发间隔,防热循环 |
STUCK_RUN_MS |
7,200,000 (2h) | jobs.ts | 运行标记过期阈值 |
DEFAULT_JOB_TIMEOUT_MS |
600,000 (10min) | timeout-policy.ts | 通用作业超时 |
AGENT_TURN_SAFETY_TIMEOUT_MS |
3,600,000 (60min) | timeout-policy.ts | AgentTurn 作业超时 |
DEFAULT_MISSED_JOB_STAGGER_MS |
5,000 (5s) | timer.ts | 启动追赶错开间隔 |
DEFAULT_MAX_MISSED_JOBS_PER_RESTART |
5 | timer.ts | 最大立即追赶作业数 |
DEFAULT_ERROR_BACKOFF_SCHEDULE_MS |
30s, 1m, 5m, 15m, 1h | jobs.ts | 错误退避梯度 |
DEFAULT_MAX_TRANSIENT_RETRIES |
3 | timer.ts | 一次性作业瞬态重试上限 |
DEFAULT_FAILURE_ALERT_AFTER |
2 | timer.ts | 连续错误 N 次后告警 |
DEFAULT_FAILURE_ALERT_COOLDOWN_MS |
3,600,000 (1h) | timer.ts | 告警冷却期 |
DEFAULT_TOP_OF_HOUR_STAGGER_MS |
300,000 (5min) | stagger.ts | 整点 cron 表达式默认 stagger |
MAX_SCHEDULE_ERRORS |
3 | jobs.ts | 调度计算连续错误后自动禁用 |
STAGGER_OFFSET_CACHE_MAX |
4,096 | jobs.ts | Stagger 偏移缓存上限 |