介绍:
本论文作者主要是解决了在Q-Learning方法中对于q-value的过高估计的问题。
q-value高估问题:
首先我们看Q-Learning的更新公式:
其中:
这里用来近似下一个状态
的Q值,算法的迭代结果就是将估计的Q值,不断朝着
方向去逼近。
从直观上来理解Q值的高估:
根据Q值的定义
显然,的,这就造成了迭代结果会对Q值进行高估。
为了解决这个问题,作者提出了Double Q-Learning,通过用两个价值函数网络和
,将动作选择网络
和动作评估网络
分开,避免过高估计问题。
原始的Q-Leaning的目标是:
改进的后的Double Q-Learning的目标表示:
++从公式可以看出,在新的目标中,选择动作,还是根据计算的结果,求argmax,但是用
来估计目标Q-value。++
论文中,给出了一个定理和对应的实验,讲明,这个高估的误差是随着动作空间的增大而增大的。

这个定理之处,当动作空间,且Q-value的方差有
,则有:
- Double Q-Learning的下界绝对误差为0
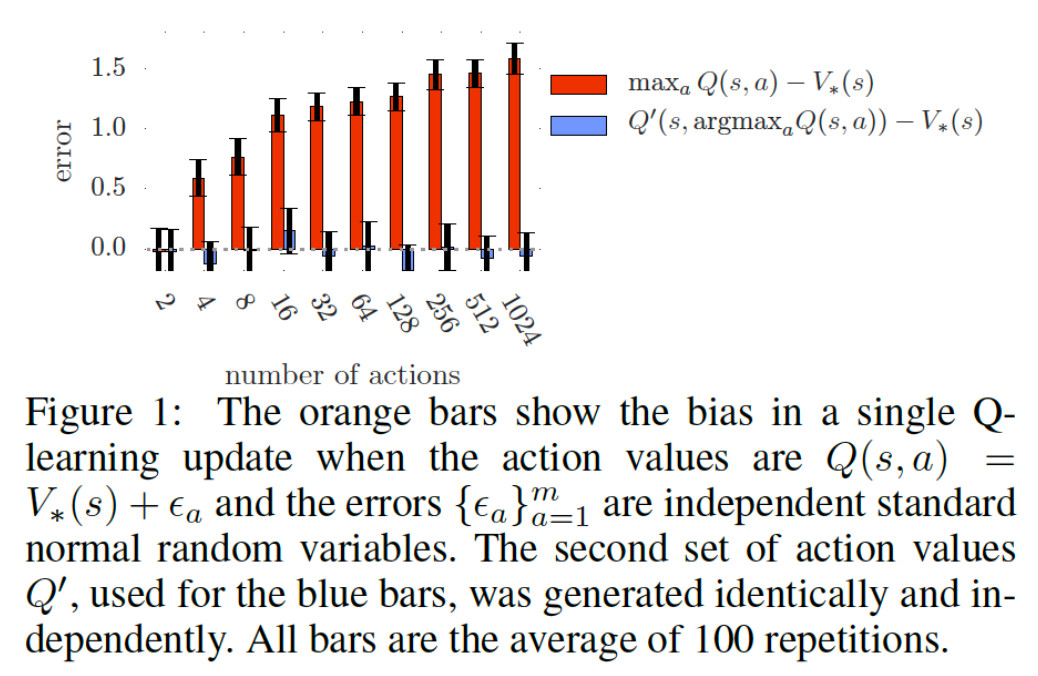
从实验结果可以看出,Double Q-Learning是无偏估计,并没有随着m的增大而过度变化,基本在0附近。
Double DQN
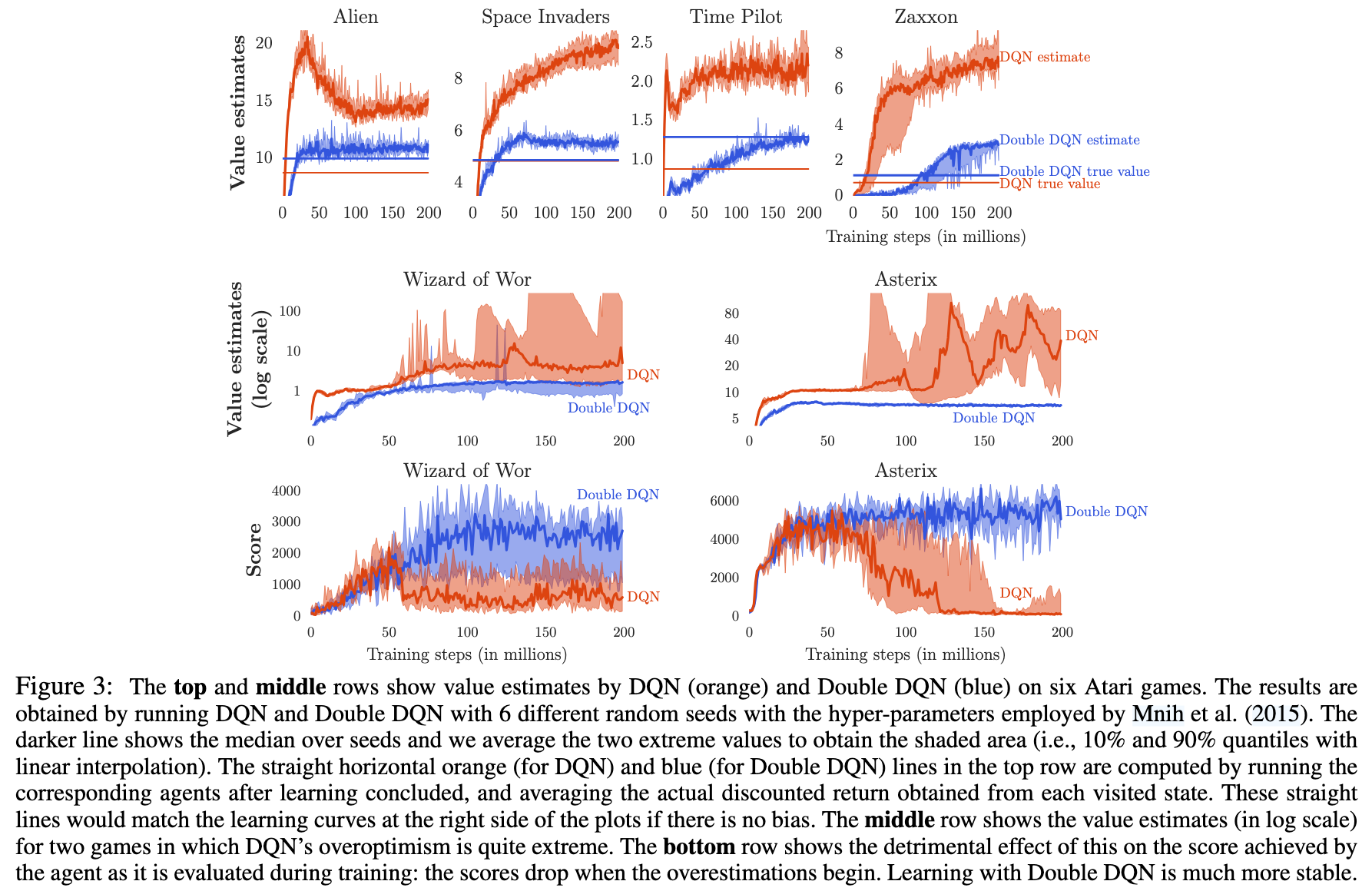
从实验结果第一排图像可以看出Double DQN对Q value的估计明显更接近于真实值,传统DQN明显高估很多
从第二排图像可以看出,DQN训练也更不稳定,说明高估问题会明显影响训练的稳定性。
原文中没有给出伪代码,这里我自己写一个:
python
Algorithm: Double Deep Q-Network (DDQN)
Initialize:
当前网络 Q,参数 θ 随机初始化
目标网络 Q_target,参数 θ_target ← θ
经验回放池 D,容量为 N
目标网络更新步数 C
训练轮数 M
每轮最大步数 T
折扣因子 γ
探索率 ε(ε-greedy策略)
学习率 α
小批量大小 batch_size
for episode = 1 to M do:
初始化状态 s
for t = 1 to T do:
// 动作选择(ε-greedy策略)
with probability ε:
a = 随机动作
else:
a = argmax_a Q(s, a; θ) // 使用当前网络选择动作
// 执行动作,观察奖励和下一状态
执行动作 a,得到奖励 r 和下一状态 s'
// 存储经验
将经验 (s, a, r, s') 存入 D
// 更新状态
s = s'
// 经验回放和网络更新
if 可以开始采样(如 D 中经验足够多):
从 D 中随机采样一个小批量,大小为 batch_size
// 计算小批量中每个样本的目标值 y_j
for each 样本 j in mini-batch:
if s' 是终止状态:
y_j = r_j
else:
// Double DQN 核心:动作选择与评估分离
// 1. 用当前网络选择下一个状态的最优动作
a_max = argmax_a Q(s'_j, a; θ)
// 2. 用目标网络评估该动作的价值
y_j = r_j + γ * Q_target(s'_j, a_max; θ_target)
// 计算损失(均方误差)
Loss = (1/batch_size) * Σ_j (y_j - Q(s_j, a_j; θ))^2
// 梯度下降更新当前网络参数
θ = θ - α * ∇_θ Loss
// 定期更新目标网络(硬更新)
if global_step % C == 0:
θ_target = θ
end for
end for