这个网络部分的内容,也是内容多且面试常考、工作常用的,因此,还是对此日更,学习这些,潜移默化的加深了我对互联网这一行业的了解。接下来我们继续。
认识请求"报头"(header)
我们都知道,报头header,是键值对结构,他分成了很多行,每一行是一个键值对,键还值之间用空格分割。这个键和值都是在RFC标准文档中标准规定的。
报头的种类很多,给大家列举几个常见的:
Host
表示服务器主机的地址和端口。

host冒号后面的是端口号,而host是IP地址(域名)。

在绝大多数情况下。这两个属性是一致的,但有一些特殊场景下是不一致的,比如,使用了代理(不过,即使使用了代理,也可以通过host来获取到最原始的目标是啥)。
HTTP协议中,传输的时候可能会涉及到"加密"(HTTPS),URL部分是不会被加密的,被加密的是header和body。
加密后,此时,服务器收到请求之后也就可以做一个最终校验。
这里依赖https这种操作,只能保证传输过程中是安全的,但是如果密码就明文保存在服务器上,服务器可能会被黑客攻击,严重触发拖库,也会造成密码泄露。
Content-length
表示body中的数据长度,单位是字节(前提是请求中要有body)。
在HTTP协议中,传输层这里是基于TCP实现的,所谓的HTTP协议,就是把字符串构造成HTTP约定的格式。

在这一结构中,没有body的HTTP请求,读到空行,就可以认为是结束了。
有body的HTTP请求呢?
先读取首行和header,读到空行,解析header中的content-length,根据这里的值,接下来再读取固定字节的长度。
前面写TCP代码,next来读取的(隐含了一个约束,使用空白符作为结束标记)
而UDP是这个情况:

Content-Type
表示请求的body中的数据格式。
这个提示了接收方向如何解析body中的数据。在HTTP这里面能够携带的数据种类是比较多的。

他们的作用:

其中,HTML、CSS与js会在前端基础上学到,教大家如何做一个页面,这个以后再谈。
这是Content-Type的格式:

用记事本打开后,看到的这些都是合法的js的语句,只是看起来与js不太一样,本质语法是同一套的。

请求和响应,都会用到上两个header,如果有body,并且没有这两个属性(哪怕只有一个)都认为是非法的/错误的HTTP报文。
User-Agent(简称UA)
结构如下(x64是CPU的位数):

User-Agent里面表示了用户使用的设备的浏览器和操作系统的情况。
同一个时间段内,有些用户的浏览器,版本是比较旧的,支持的功能少;有些用户浏览器版本更新,支持的功能多。
如果支持的功能少,可能就比不过竞争对手,如果支持的功能多,旧版本浏览器设备的用户,可能就展示不了。就像Linux系统的64x一样,所有的32x的应用程序就无法打开了。
那么就根据用户使用的设备进行区分,通过UA中的浏览器版本/操作系统的版本,区分出当前用户的设备,最多都支持哪些特性:
老的浏览器,返回功能少的网页,正确显示;新的浏览器,返回功能多的网页,体验丰富。这样,程序员就需要维护多套代码。
除此之外,UA还有另外一个用途:可以用来区分用户的设备。

Referer
描述了当前页面的来源,就是说,这个页面是从哪个页面跳转来的。
这里如果直接输入URL或点击收藏栏打开的页面是没有referer的

他经常用到的场景,比如:广告系统。

就像这个带"广告"字样的搜索栏,他是按照点击量计费的,由广告主给搜狗等搜索软件的企业。那么双方(搜狗与广告主都统计)在一定时间内,某个广告的点击量,在搜狗,统计方式很好办,点击广告跳转的时候,先访问搜狗的"计费服务器"(记录日志),再从计费服务器跳转到广告页面;广告主服务器也有日志,统计广告主服务器日志中访问的次数就可以了。广告主可能会同时在多个平台投放广告,此时就需要做出区分------referer这样的方式。
运营商劫持
但是否存在可能,有人把referer改了,本来是搜狗的referer改成了别人的?
这个就叫来自运营商的"运营商劫持",这个行为是有能力的,在用户上网的时候,HTTP请求都是经由运营商的路由器或交换机,通过软件,分析数据流量,把一些广告的HTTP数据进行修改就行了。并且是有动机的,运营商也有自己的广告平台,与百度/搜狗等是竞争关系。
针对这个问题,百度、搜狗等一起在技术上反制,比如用https,https协议能够有效的对HTTP数据进行加密传输,与此同时,referer也被加密了。
Cookie
浏览器展示页面的过程中,页面里虽然可以通过js来实现一些逻辑,但是js代码无法访问你的硬盘(文件系统)。这是浏览器给js戴上的"紧箍咒",怕js能操作用户文件系统瞎搞的,实际开发中,有时候还是希望把某些数据能够保存到本地硬盘的,因此浏览器引入了cookie机制。
cookie就是浏览器允许网页在本地硬盘存储数据的一种机制,不是让网页代码直接访问文件系统,而是做了一层抽象,浏览器的cookie提供了键值对存储机制。

在fiddler中看到的cookie部分:
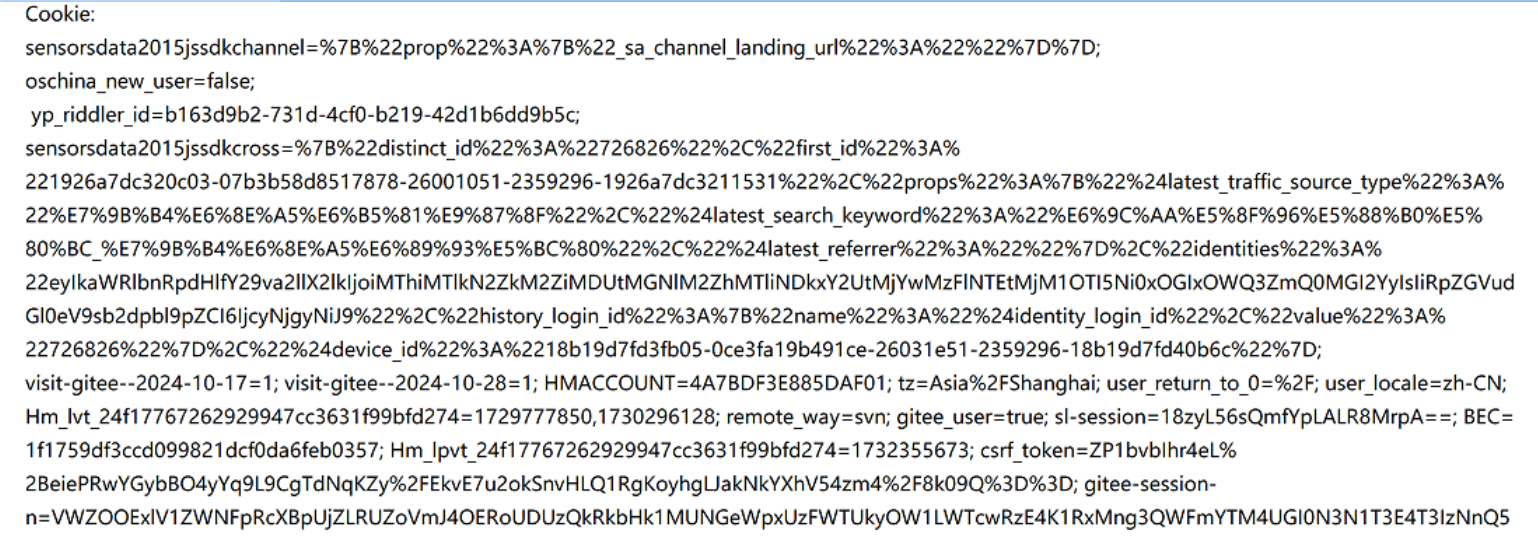
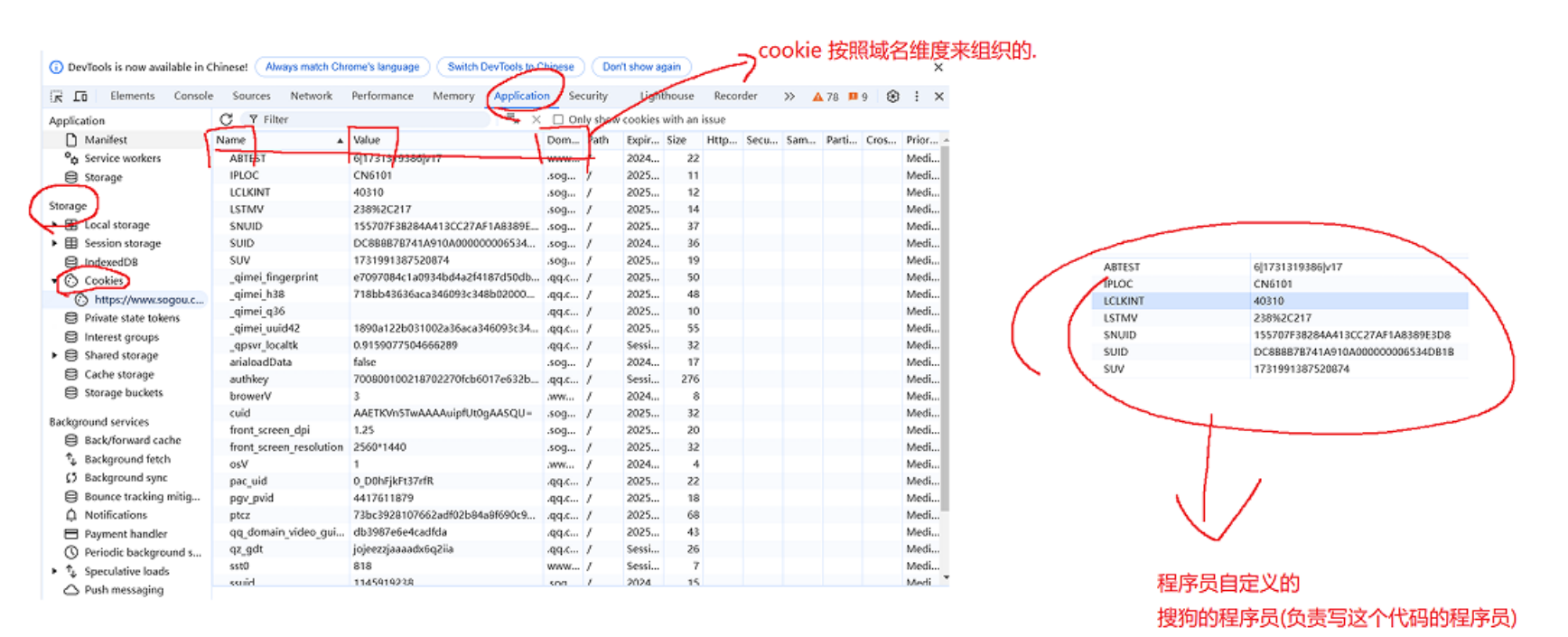
浏览器中可以直接看到当前页面保存的cookie有哪些的,打开浏览器(百度、搜狗等),右键再点击"检查",点击Application再点击cookie就可以看到。
浏览器保存了这些cookie之后,就会在后续给服务器发送请求的时候,把这些cookie键值对放到请求cookie header中传输给服务器。

看一下fiddler的cookie内容,左边划了红线(右边那个划了红线的是有效期到什么时间)的是在浏览器中看到的键值对;右边那些就是有效期到什么时候。比如你去取钱,那个程序的有效期就很短,为了安全起见。
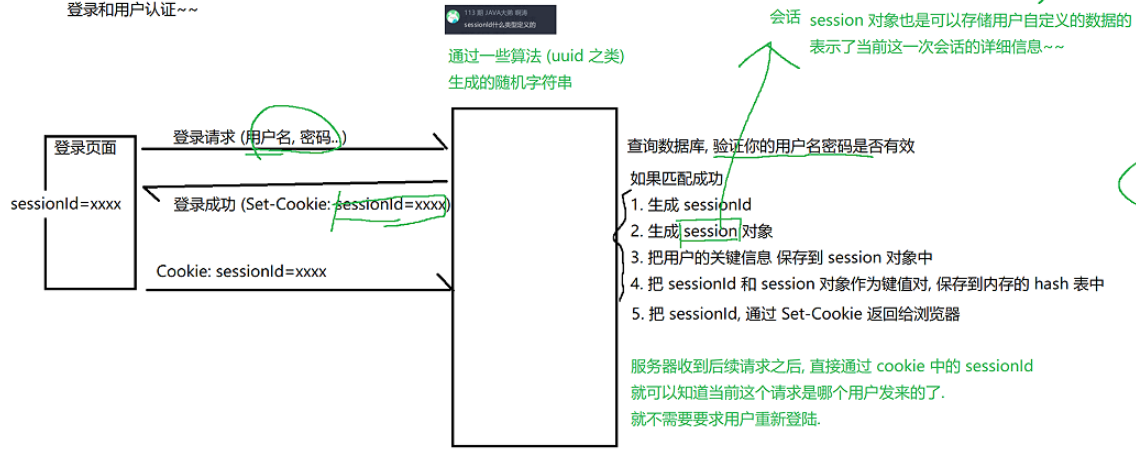
cookie里的数据都是程序员自定义内容,但是有一个典型的场景属于通用业务(登录和用户认证)。
下面是登录的流程:

今天的内容到此为止,明天我们继续。