本地大模型的部署与使用
随着大语言模型(LLM)的快速发展,越来越多开发者开始关注"本地化部署"。 相比云端API,本地部署在隐私、安全、成本控制等方面具有明显优势。 本文将从三种常见使用方式出发:本地部署、网页应用、远端API接口调用,对其优劣进行分析,并给出基于 llama.cpp 的本地部署实战教程。
(提示:本文由ChatGPT编写,编者校对和调整)
三种使用方式对比
在实际使用中,大模型主要有三种接入方式:
1. 本地部署
特点:模型运行在本地设备(PC/服务器)
优点:
- 数据隐私性强(不出本地)
- 无需持续付费(一次性部署成本)
- 可深度定制(模型、推理参数、工具链)
缺点:
- 对硬件要求较高(尤其显存/内存)
- 部署复杂度较高
- 推理速度可能不如云端(受到本地硬件影响)
适用人群:开发者、对隐私敏感的用户、需要定制化能力的场景。
2. 网页应用(Web UI)
特点:通过浏览器访问模型(本地或远端)
常见形态:
- 本地 WebUI(如开源前端)
- 云端网页服务
优点:
- 使用门槛低(无需写代码)
- 交互体验好(聊天界面)
- 可集成插件(知识库、工具调用等)
缺点:
- 功能受限(相比API)
- 自动化能力较弱
- 本地部署时仍需处理环境问题
适用人群:普通用户、测试模型效果、轻量应用。
3. 远端 API 接口调用
特点:通过HTTP请求调用模型服务
优点:
- 易于集成(适合开发)
- 可扩展性强(微服务架构)
- 支持自动化和批处理
缺点:
- 依赖网络
- 存在隐私风险(若使用第三方API)
- 长期成本较高(按调用计费)
适用人群:开发者、企业应用、系统集成。
小结对比
| 方式 | 隐私 | 成本 | 灵活性 | 上手难度 |
|---|---|---|---|---|
| 本地部署 | 高 | 低 | 高 | 高 |
| 网页应用 | 中 | 中 | 中 | 低 |
| API调用 | 低 | 高 | 高 | 中 |
如果你目标是长期使用 + 可控 + 可扩展,本地部署是最值得投入的路径。
使用 llama.cpp 部署本地大模型
llama.cpp 是当前最轻量、最流行的本地推理框架之一,支持 CPU / GPU / Metal / Vulkan 等多种后端,特别适合中低配置设备运行量化模型。
当然,我们还有更多的方式来部署,例如最简单的Ollama,或是更热门的vLLM。 之所以选择llama.cpp,是因为其在性能、调参和部署难度上都比较均衡,适合更多的开发者或个人用户。
环境准备
系统要求:
- Windows / Linux / macOS
- 推荐内存:16GB+
- GPU(可选,但建议有)
依赖工具:
- Git(可选,能直接访问GitHub网页也可以)
- CMake(可选,可以直接下载release版本,不需要手动编译)
- 编译器(如 MSVC / gcc / clang,同上可选)
个人用户可以零工具使用,以下内容不介绍手动编译方式,仅采用已编译版本。
下载llama.cpp
进入llama.cpp的GitHub页面,点击Releases进入发布列表。
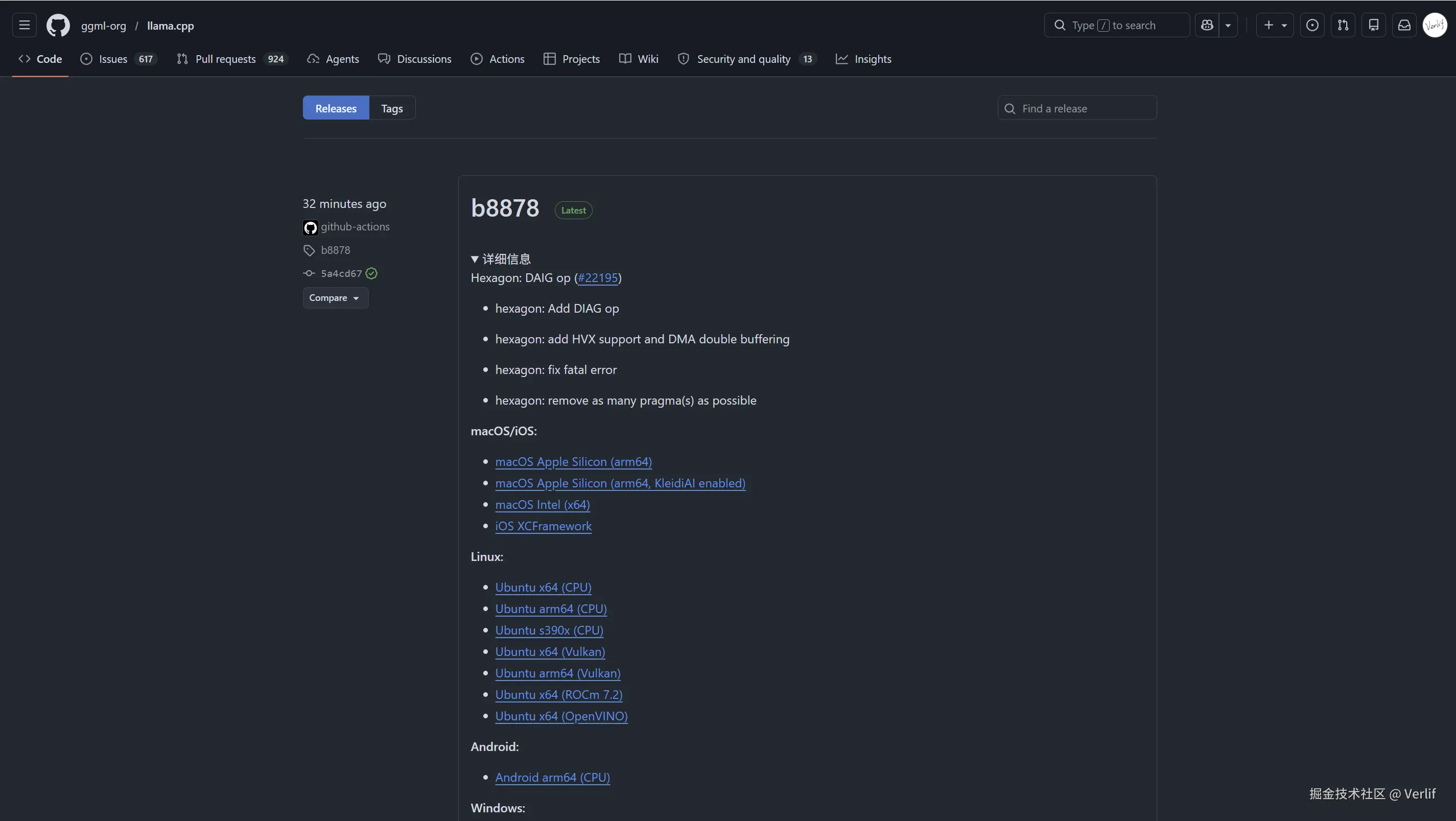
通常来说选择最新版本就可以了,找到自己要部署的系统,比如我是Windows,用的是AMD的显卡,就选Windows x64 (Vulkan)
下载下来是一个压缩包,解压到一个新的目录,比如D://llama.cpp就可以了,llama.cpp就算是下载好了。
下载模型
你需要下载 GGUF 格式模型(量化模型)。
通常你可以到huggingface下去下载开源模型,怎么找模型这里就不做详述了,不会的可以到网上找教程。
(注意,huggingface 上的都是开源模型,无需付费和会员,不要被骗了)
这里我下载了两个小模型,分别是 qwen3.5:4b 和 bge-m3:8b ,然后放在某个文件夹下面方便管理。
我是放在了之前创建的llama.cpp目录下的新建的models目录中,例如:
启动 API 服务
我直接给一个可以用的启动api服务的指令,这里以 qwen3.5:4b 举例:
cmd
D:\llama.cpp\llama-server.exe -m D:\llama.cpp\models\Qwen3.5-4B-Q4_K_M.gguf --port 9101 -ngl 999 --reasoning-budget 0 -ctk q8_0 -ctv q8_0常用参数说明:
-m:模型路径-port:api端口-ngl:当编译支持 GPU 时,该选项允许将某些层卸载到 GPU 上进行计算,数值表示权重,999表示几乎全分配到 GPU 上--reasoning-budget:限制模型最多能花多少 token 去写推理过程(thinking),-1表示无限制,0表示无,大于0表示具体数值-ctk:控制 Key cache 的数据精度(量化方式),这里用q8_0可以在牺牲极小精度的情况下降低内存消耗-ctv:控制 Value cache 的数据精度(量化方式),这里用q8_0可以在牺牲极小精度的情况下降低内存消耗
其他参数可以通过D:\llama.cpp\llama-server.exe --help方式得到。
调用实例
启动了模型自带的API服务后可通过接口调用:
shell
curl http://localhost:9101/v1/chat/completions
-H "Content-Type: application/json"
-d "{"model":"local","messages":[{"role":"user","content":"你好,简单介绍一下你自己"}],"max_tokens":128}"使用OpenAI方式接入到应用上
现在我们已经有了模型服务了,就可以将其使用在我们的其他应用上了,比如思源笔记、CherryStudio、各类游戏等等。
接入参数:
text
提供商类型:OpenAI
API密钥:(随便填,比如`123`)
API地址:http://localhost:9101/v1/chat/completions
模型名称:(随便填,因为llama.cpp对于每个模型都是单独的api服务,无法通过模型名称切换)然后就可以使用了。
多模型运行与随系统启动
多模型运行
通常来说,本地部署一般都是几个模型同时跑,各干各的事情,比如4b模型用来日常交流,2b模型用作翻译,嵌入用来做知识库,因此我们可以用脚本的方式一键启动。
我直接给一个我用的bat脚本:
bat
@echo off
start "qwen3.5:4b" D:\llama.cpp\llama-server.exe -m D:\llama.cpp\models\Qwen3.5-4B-Q4_K_M.gguf --port 9101 -ngl 999 --reasoning-budget 0 -ctk q8_0 -ctv q8_0
start "bge-m3:8b" D:\llama.cpp\llama-server.exe -m D:\llama.cpp\models\bge-m3-567M-F16.gguf --port 9102 --embedding --ctx-size 2048 --batch-size 256 -ngl 999 --no-mmap --ubatch-size 64这里我就跑了两个模型,qwen3.5:4b 和 bge-m3:8b,一个语言模型,一个嵌入模型。
随系统启动
当然,有了这个bat脚本文件,要随系统启动就更简单了:
win+R打开运行输入窗口- 输入
shell:startup打开启动目录 - 将启动脚本或启动脚本的快捷方式放在里面
然后每次系统启动时,模型就会同步运行了。
(注意,最好先手动运行一下脚本,看是否符合预期,即几个模型就有几个运行窗口)
其他
- 建议在调试模型时,打开任务控制台,实时监控系统资源与占用情况,按需调整参数。
- 不要盲目追求大,参数越多的模型,占用的系统资源也就越多,推荐在本地运行时至少10 token/s 的模型,个人感觉20 token/s是舒服的下限。
- 模型上下文越大,占用的内存越多,适当减少上下文最大长度。
总结
本地大模型的核心价值在于:可控性 + 成本优势 + 数据安全。
- 如果你只是"用",网页应用最方便
- 如果你要"做东西",API是必选
- 如果你要"掌控",本地部署才是终点
而 llama.cpp 提供了一条极其轻量但强大的路径,让普通设备也能真正运行大模型。