 最近我在用 Codex 做一个真实研发需求。
最近我在用 Codex 做一个真实研发需求。
需求本身不算特别大:阅读器里要做"高光场景插卡"和"高光段落气泡"。
但这次我真正想实验的,不是这两个功能最后怎么写,而是另一件事:
能不能把我平时处理 PRD、拆需求、写方案、改代码、做验证的过程,固定成一个稳定的 AI workflow?
不是每次都靠临场发挥跟 AI 聊。
而是把流程打包成一个 Skill,让 AI 知道:需求从哪里读,读完怎么拆,什么时候要停下来等我确认,什么时候才能真正改代码。
真实工程里,问题往往不在 AI 不会写代码。
问题在于它太愿意往前冲。
PRD 没读完整,它也敢猜。需求范围没确认,它也敢写。仓库有本地改动,它也敢继续。构建没跑通,它也可能轻描淡写地说"应该没问题"。
这就很危险。
所以这次我想复盘的,是一次从飞书 PRD 到代码实现的完整 AI 编程 workflow:
text
飞书 PRD -> CLI 读取 -> 本地快照 -> 需求拆解 -> Open Questions
-> 人工确认 -> 技术方案 -> 任务拆解 -> 代码实现 -> QA 与验证记录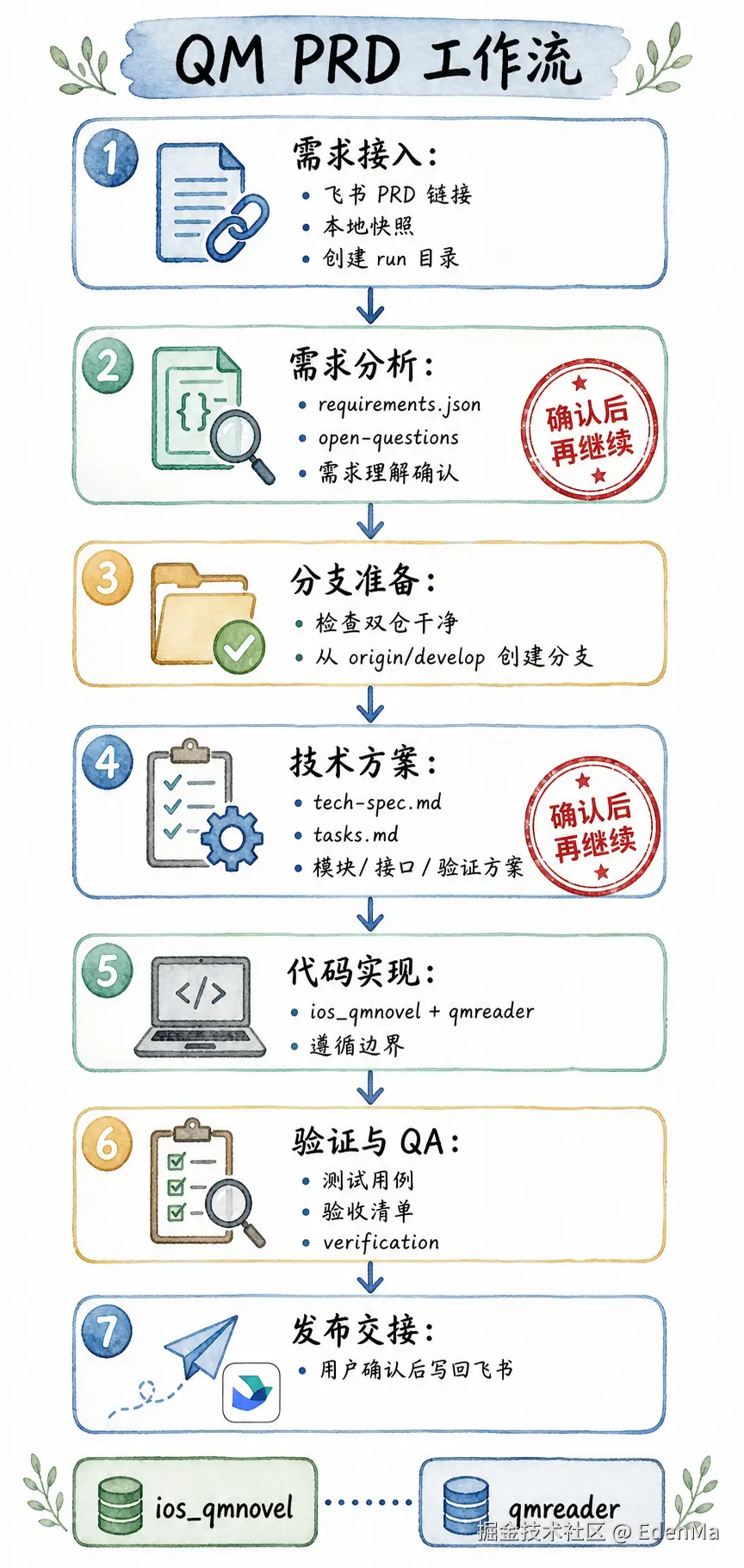 图片说明:从飞书 PRD 链接到本地快照、需求拆解、技术方案、代码实现和 QA 的完整流程。
图片说明:从飞书 PRD 链接到本地快照、需求拆解、技术方案、代码实现和 QA 的完整流程。
一、第一步不是写代码,而是读取真实需求源头
这次会话的第一句话其实很普通。
用户给了一个飞书 Wiki 链接,然后说:
我只研发其中的:阅读器高光场景插卡和高光段落气泡两部分,其他不用管。
如果是普通 AI 编程方式,下一步大概就是把 PRD 丢给 AI,说:
帮我实现一下。
然后 AI 开始搜代码、猜结构、改文件。
看起来很快,但这里有一个问题:AI 到底有没有读到真实需求源头?
如果需求只是散落在聊天上下文里,后面每一步都会变得很飘。它可能记错,可能漏掉,也可能把自己猜出来的东西当成需求。
所以我的 workflow 第一件事不是进代码仓库,而是接入飞书 CLI,把需求文档先读下来:
bash
lark-cli docs +fetch --api-version v2 --doc <feishu_url> --format json这一步会把飞书里的 PRD 拉到本地,保存成快照和 metadata。
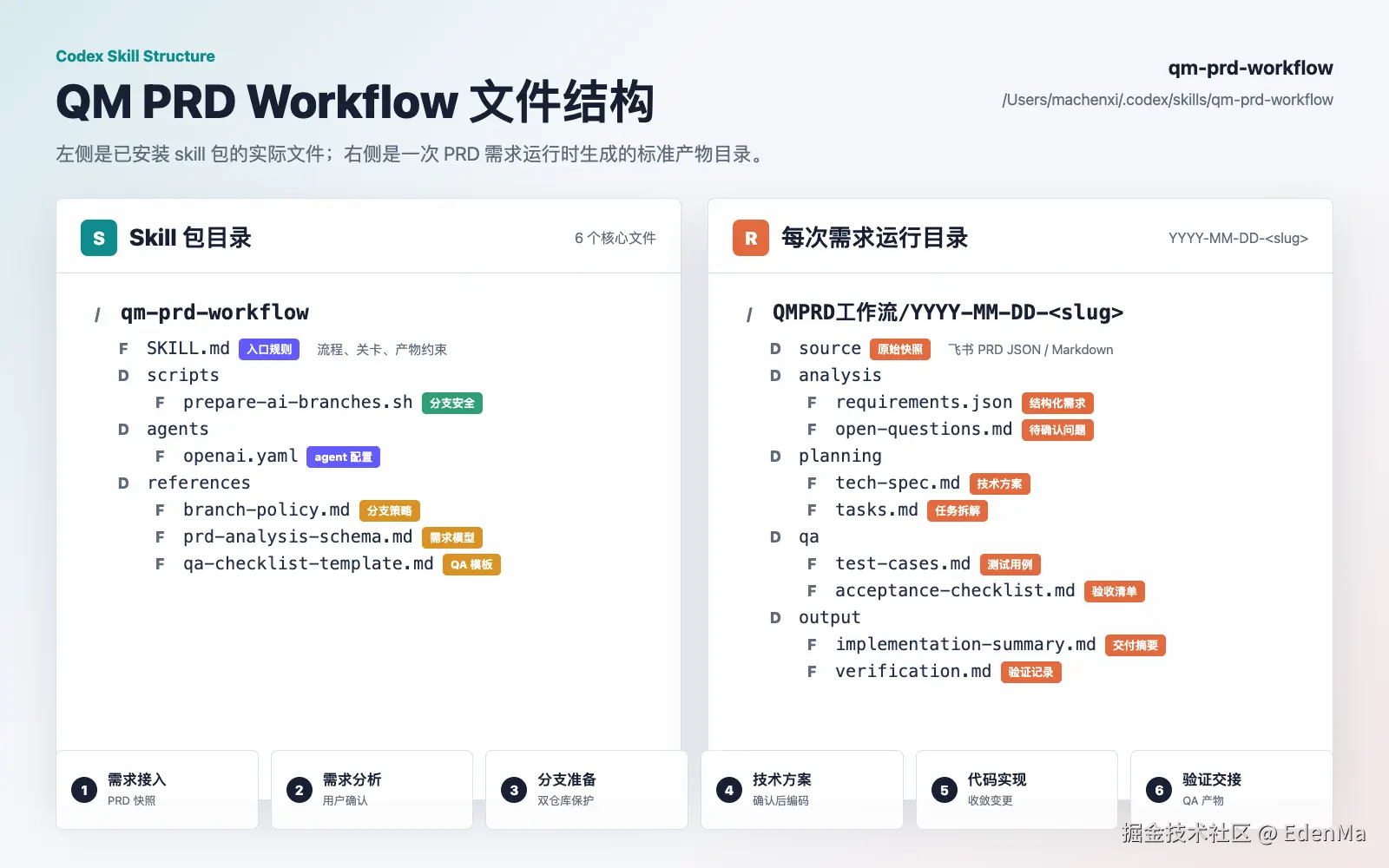
这次对应的工作流目录是:
text
/Users/Desktop/QMPRD工作流/2026-05-28-reader-highlight-scene/
source/
analysis/
planning/
qa/
output/source/ 保存 PRD 快照,analysis/ 保存需求拆解和待确认问题,planning/ 保存技术方案和任务拆解,qa/ 保存测试用例和验收清单,output/ 保存实现摘要和验证结果。
这里最重要的不是目录好不好看。
而是它把一次聊天,变成了一组可以回看、可以确认、可以交接的本地文件。
普通 prompt 依赖上下文记忆。
workflow 依赖阶段产物。
这个差别非常大。
 图片说明:需求入口来自飞书文档,workflow 会先读取和保存真实需求源头。
图片说明:需求入口来自飞书文档,workflow 会先读取和保存真实需求源头。
二、读完 PRD 之后,真正重要的是需求拆解
把 PRD 拉下来以后,也不能直接写代码。
因为"读到了文档"和"理解了需求",中间还隔着一大段距离。
这次 workflow 的下一步,是产出两个文件:
text
analysis/requirements.json
analysis/open-questions.mdrequirements.json 不是简单总结,而是把需求拆成工程可以处理的对象。比如:
json
{
"scope": ["阅读器高光场景插卡", "高光段落气泡"],
"non_goals": ["PRD 中其他模块本期不处理"],
"api": ["/api/v1/paragraph/bubbles", "chapters.highlight", "icon_type = 7"],
"ui_rules": ["插卡展示在段落末尾", "只压同一段落的神段评 / 作家插图"],
"tracking": ["插卡曝光埋点", "插卡点击埋点"]
}这不是为了让文档显得正式。
而是为了让 AI 先把自己的理解暴露出来。
AI 最麻烦的地方之一,是它看起来很自信。它经常会把"我猜是这样"写得像"需求就是这样"。
所以需求拆解的价值,就是把这个黑盒打开,让人先看一眼:范围对不对?非目标有没有写清楚?接口字段有没有猜错?UI 规则和埋点有没有漏?
open-questions.md 则负责把不确定项沉淀下来。
比如这次就涉及:
text
- 高光插卡是否跟随书籍插图开关?
- icon_type = 7 是否完全以后端返回为准?
- 点击跳转本期是否要完整实现?
- 高光插卡和神段评、作家插图的优先级怎么处理?用户补完以后,AI 再读取这个文件,把方案收敛。
这一步看起来慢,但它解决的是一个真实问题:
如果需求理解错了,在这个阶段纠正很便宜;等代码写完再纠正就很贵。

图片说明:需求拆解、Open Questions、技术方案和验证结果都沉淀为本地文件。
三、Skill 不是提示词,是一份工作说明书
这次真正起作用的,是一个叫 qm-prd-workflow 的 Skill。
我以前也容易把 Skill 理解成"更长、更详细的提示词"。
但这次跑完之后,我的感觉变了。
Skill 更像一份给 AI 的员工手册。
它不是告诉 AI "你要聪明一点",而是在规定:你在哪些目录工作,先读什么,每一步产出什么文件,什么时候必须停下来问人,哪些动作绝对不能自己决定。
比如这个 workflow 会写清楚项目边界:
text
主 App 仓库:/Users/Desktop/ios_qmnovel
阅读器组件仓库:/Users/Desktop/qmreader
工作流产物根目录:/Users/Desktop/QMPRD工作流它也会写清楚流程关卡:
text
飞书 PRD intake
本地快照
需求分析
Open Questions
技术方案
任务拆解
代码实现
QA 和 verification还会写清楚禁止动作:用户确认需求理解和技术方案之前,不改项目代码;仓库有未提交改动时停止;不要自动 stash、commit、reset、clean;不要把分析文档散落到业务仓库。
这些规则听起来都不性感。
但它们恰恰是工程协作里最值钱的部分。
普通 prompt 像临时交代一句"帮我看看这个需求"。
Skill 更像给新同事的一份岗位操作指南。
AI 不缺执行力。
它缺的是一套稳定的工作边界。
图片说明:SKILL.md、scripts、references 和 assets 共同组成一套可复用的工作说明书。
四、Human in the Loop 不是每一步盯着 AI
Human in the Loop 很容易被说空。
好像只要流程里有人点一下确认,就叫人在环。
但我这次的体感是,它真正有价值的地方,不是让人每一步都盯着 AI,而是把人的判断力放到最该出现的位置。
这次 workflow 里有几个明确的停顿点。
需求理解后停下来:人确认范围和非目标。
Open Questions 后停下来:人补充接口、UI、埋点、开关逻辑。
技术方案后停下来:人确认实现方向。
进入实现前停下来:如果仓库有本地改动,AI 不自作主张处理,而是等人决定。
这次 ios_qmnovel 有本地改动时,workflow 没有自动 stash 或 reset。最后用户明确说"无须管 ios_qmnovel 本地改动,进入代码实现",AI 才继续,只改 qmreader。
这个细节很小,但很重要。
因为 AI 最容易让人不放心的地方,就是它会替你处理你没授权它处理的东西。
好的 workflow 应该反过来:
AI 负责推进、记录、执行和提醒风险。
人负责确认方向、补充上下文、收敛方案和承担关键决策。
好的 workflow 不是把人从流程里拿掉,而是把人放在最有判断价值的位置。
五、具体代码实现只是 workflow 的验证样例
最后,这个需求确实进入了代码实现。
但我不想把这篇文章写成高光插卡的 Swift 技术方案。
具体业务实现不是主角,它只是这条 workflow 的一个验证样例。
简单说,最后代码层面做了这些事:
- 新增
YYHighlightParaView - 解析
chapters.highlight字段 - 支持
icon_type = 7映射reader_a_remark_bubble_default - 把高光插卡接入段末插件管理
- 补上插卡曝光和点击埋点
这些实现证明了一件事:workflow 不是只会写文档,它可以从飞书 PRD 一路走到真实代码改动。
但更重要的是,它会让交付结果更可靠,又可复用的产物,增加自己对代码实现,尤其是第一版代码实现的掌控,以及后续还可以根据需要引用分享产物。
六、如果你也想写一个 Skill,先写边界,再写能力
这次跑完以后,我对 Skill 的理解变得更具体了。
如果你也想把自己的重复工作固化成一个 Skill,我会建议先别急着写一大段提示词。
先写边界。
你可以从这些问题开始:
- 入口是什么?是飞书链接、PRD 文档、截图,还是接口说明?
- 真实需求怎么读取?能不能优先接入飞书 CLI、GitHub issue等,而不是只靠聊天上下文?
- 每一步产物放哪里?比如
source/analysis/planning/qa/output。 - 需求要拆成什么结构?范围、非目标、接口、UI、埋点、风险、Open Questions。
- 哪些节点必须等人确认?需求理解、技术方案、进入实现、验证阻塞。
- 哪些动作禁止自动做?比如 reset、stash、commit,或者在没确认前改业务代码。
这些限制不是束缚 AI。
恰恰相反,它们是在帮 AI 变得可信。
一个好 Skill 不是让 AI 看起来更聪明。
一个好 Skill 是让 AI 在重复工作里更稳定、更可控、更可交付。
写在最后
这次高光插卡需求本身,其实不是重点。
重点是我终于更清楚地看到:AI 编程要稳定下来,不能只靠"更会提问"。
它需要 workflow。
接入飞书 CLI,是为了让 AI 读取真实需求源头。
需求拆解,是为了让 AI 先暴露理解。
Human in the Loop,是为了让人在关键节点做判断。
本地 artifacts,是为了让过程可追溯、可交接、可复盘。
我现在越来越觉得,AI 协作最重要的变化不是"人被拿掉"。
而是人终于可以从重复推进里抽身出来,把注意力放到更重要的判断上。
后续想法:不断的完善自己的workflow skill,引入多agent协作、代码性能检测、产物归档到云端形成知识库等等。