MLOps 平台架构设计:从 0 到 1 构建企业级机器学习运维系统
摘要
随着人工智能技术的快速发展,越来越多的企业开始将机器学习模型应用于生产环境。然而,从模型开发到部署运维的整个生命周期管理却面临着巨大挑战。MLOps(Machine Learning Operations)作为 DevOps 在机器学习领域的延伸,提供了一套完整的方法论和工具链,帮助企业实现机器学习模型的自动化开发、部署、监控和迭代。
本文将从 MLOps 的核心概念出发,深入探讨企业级 MLOps 平台的架构设计原则、关键组件、技术选型以及实施路径。通过实际案例和代码示例,帮助读者理解如何从零开始构建一个可扩展、高可用的 MLOps 平台。文章涵盖数据流水线、模型训练、模型注册、自动化部署、监控告警等核心模块,并提供 Java 和 Python 双语言代码示例,适合后端工程师、数据科学家和 DevOps 工程师阅读参考。
关键词:MLOps、机器学习运维、平台架构、自动化部署、模型监控、Kubernetes、CI/CD
目录
- [MLOps 概述与核心价值](#MLOps 概述与核心价值)
- [MLOps 平台架构设计原则](#MLOps 平台架构设计原则)
- 核心组件详解
- 技术选型与工具链
- [实战:构建 MLOps 流水线](#实战:构建 MLOps 流水线)
- 模型监控与告警系统
- 安全与合规考虑
- 总结与展望
1. MLOps 概述与核心价值
1.1 什么是 MLOps?
MLOps(Machine Learning Operations)是机器学习(Machine Learning)与运维(Operations)的结合,旨在通过自动化和标准化流程,提高机器学习模型从开发到生产的效率和质量。MLOps 借鉴了 DevOps 的核心理念,但针对机器学习项目的特殊性进行了扩展和优化。
与传统软件开发不同,机器学习项目具有以下特点:
- 数据依赖性:模型质量高度依赖于训练数据的质量和数量
- 实验性:需要频繁进行超参数调优和模型迭代
- 可复现性挑战:相同的代码在不同数据或环境下可能产生不同结果
- 持续监控需求:模型在生产环境中可能出现性能衰减(Model Drift)
1.2 MLOps 的核心价值
构建 MLOps 平台可以为企业带来以下核心价值:
- 加速模型上线:自动化流水线将模型从开发到部署的时间从数周缩短到数小时
- 提高模型质量:标准化的测试和验证流程确保模型在生产环境的稳定性
- 降低运维成本:自动化监控和告警减少人工干预,提高运维效率
- 促进团队协作:统一的平台让数据科学家、工程师和运维人员高效协作
- 确保合规性:完整的审计日志和版本控制满足监管要求
1.3 MLOps 成熟度模型
根据企业 MLOps 实践的成熟度,可以分为三个级别:
- Level 0 - 手动流程:所有步骤手动执行,无自动化
- Level 1 - 自动化流水线:实现训练和部署的自动化
- Level 2 - CI/CD 集成:完整的持续集成和持续部署,支持自动化重新训练
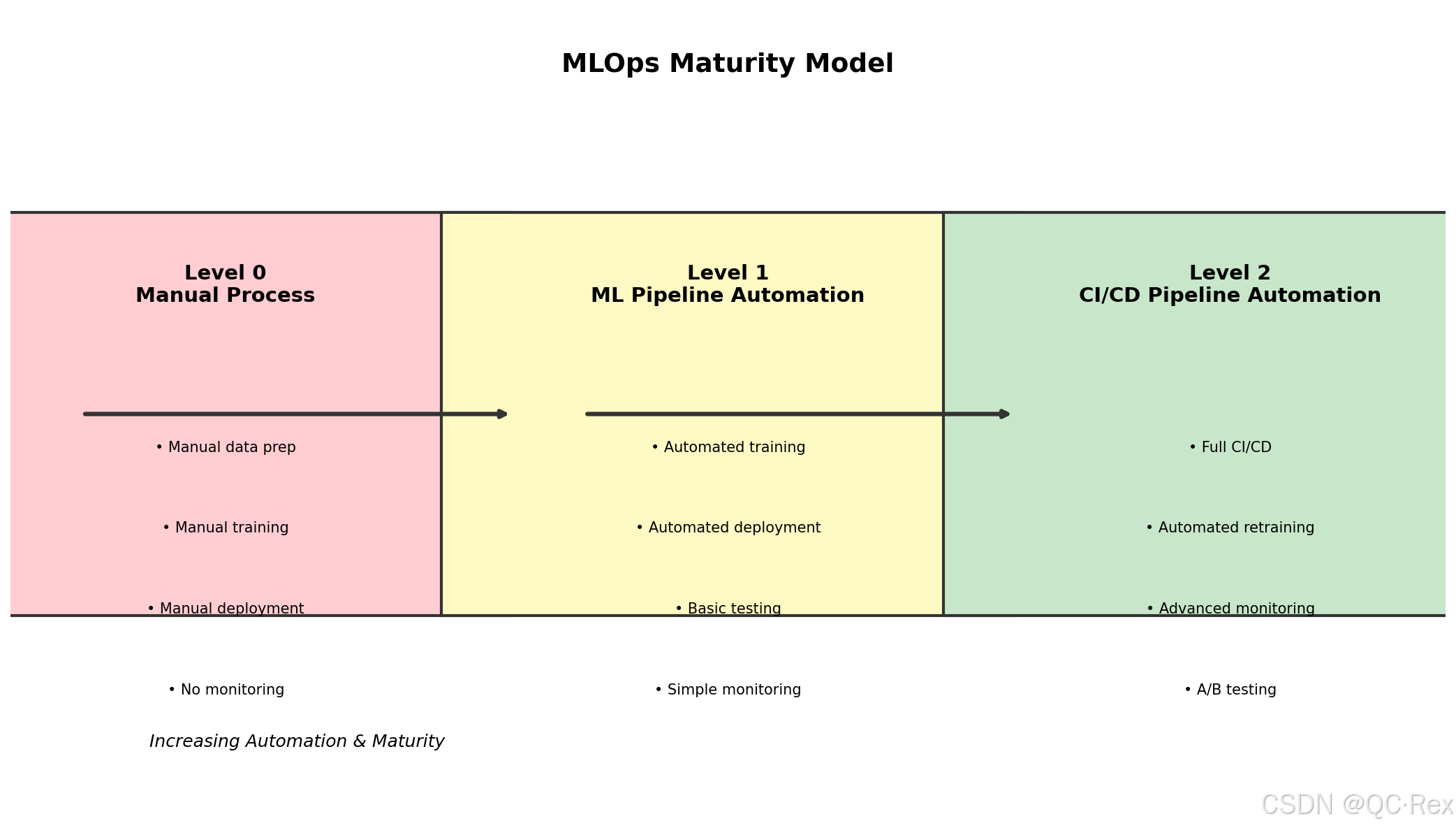
图 1: MLOps 成熟度模型 - 从手动流程到完整 CI/CD 的演进
本文重点讨论如何构建 Level 2 级别的企业级 MLOps 平台。
2. MLOps 平台架构设计原则
2.1 核心设计原则
在设计 MLOps 平台时,应遵循以下核心原则:
2.1.1 模块化与解耦
将平台拆分为独立的模块,每个模块负责单一职责。常见模块包括:
- 数据管理模块
- 特征工程模块
- 模型训练模块
- 模型注册模块
- 部署服务模块
- 监控告警模块
模块之间通过定义良好的 API 进行通信,便于独立扩展和替换。
2.1.2 可扩展性
平台应支持水平扩展,能够处理不断增长的数据量和模型数量。关键考虑点:
- 使用容器化技术(Docker/Kubernetes)实现弹性伸缩
- 采用分布式存储处理大规模数据
- 支持多租户和资源隔离
2.1.3 可复现性
确保每次实验和部署都可以复现:
- 版本控制代码、数据、模型和配置
- 记录完整的实验元数据
- 使用容器固定运行环境
2.1.4 安全性
保护敏感数据和模型资产:
- 实施细粒度的访问控制(RBAC)
- 加密存储和传输中的数据
- 审计所有关键操作
2.2 整体架构概览
以下是典型的企业级 MLOps 平台架构图:
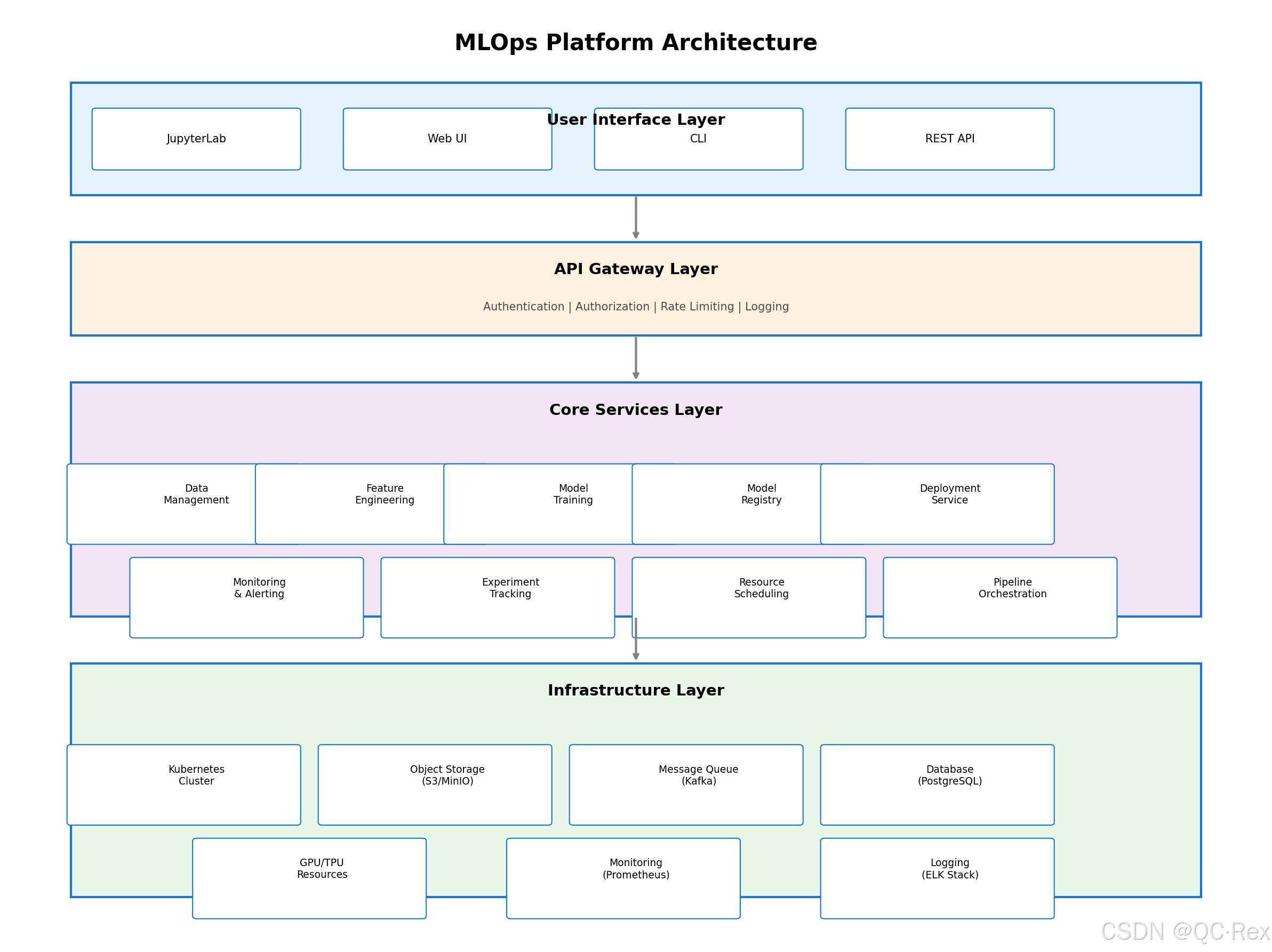
图 2: MLOps 平台整体架构图 - 展示四层架构设计
3. 核心组件详解
3.1 数据管理模块
数据管理模块负责数据的采集、存储、版本控制和质量管理。
核心功能:
- 数据接入:支持多种数据源(数据库、API、文件、流数据)
- 数据版本控制:使用 DVC(Data Version Control)等工具管理数据版本
- 数据质量检查:自动检测数据缺失、异常值、分布变化
- 数据血缘追踪:记录数据来源和转换历史
Java 代码示例 - 数据质量检查器:
java
package com.mlops.platform.data.quality;
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import java.util.*;
import java.util.stream.Collectors;
/**
* 数据质量检查器
* 用于验证训练数据的质量,确保数据符合预期标准
*/
@Component
@Slf4j
public class DataQualityChecker {
/**
* 数据质量报告
*/
@Data
public static class QualityReport {
private int totalRecords;
private int missingValues;
private int duplicateRecords;
private Map<String, Double> columnStats;
private List<String> issues;
private boolean passed;
private double qualityScore;
}
/**
* 检查数据集质量
* @param data 输入数据
* @param config 质量检查配置
* @return 质量报告
*/
public QualityReport checkQuality(List<Map<String, Object>> data,
QualityConfig config) {
QualityReport report = new QualityReport();
report.setTotalRecords(data.size());
report.setIssues(new ArrayList<>());
report.setColumnStats(new HashMap<>());
if (data.isEmpty()) {
report.getIssues().add("数据集为空");
report.setPassed(false);
report.setQualityScore(0.0);
return report;
}
// 检查缺失值
report.setMissingValues(countMissingValues(data, config.getRequiredColumns()));
double missingRate = (double) report.getMissingValues() /
(data.size() * config.getRequiredColumns().size());
if (missingRate > config.getMaxMissingRate()) {
report.getIssues().add(String.format(
"缺失值比例过高:%.2f%% (阈值:%.2f%%)",
missingRate * 100, config.getMaxMissingRate() * 100));
}
// 检查重复记录
report.setDuplicateRecords(countDuplicates(data));
if (report.getDuplicateRecords() > config.getMaxDuplicates()) {
report.getIssues().add(String.format(
"重复记录过多:%d (阈值:%d)",
report.getDuplicateRecords(), config.getMaxDuplicates()));
}
// 计算质量分数
report.setQualityScore(calculateQualityScore(report, config));
report.setPassed(report.getQualityScore() >= config.getMinQualityScore());
log.info("数据质量检查完成 - 得分:{}/100, 是否通过:{}",
report.getQualityScore(), report.isPassed());
return report;
}
private int countMissingValues(List<Map<String, Object>> data,
List<String> columns) {
int count = 0;
for (Map<String, Object> row : data) {
for (String column : columns) {
if (row.get(column) == null ||
(row.get(column) instanceof String &&
((String) row.get(column)).trim().isEmpty())) {
count++;
}
}
}
return count;
}
private int countDuplicates(List<Map<String, Object>> data) {
Set<String> seen = new HashSet<>();
int duplicates = 0;
for (Map<String, Object> row : data) {
String key = row.toString();
if (!seen.add(key)) {
duplicates++;
}
}
return duplicates;
}
private double calculateQualityScore(QualityReport report, QualityConfig config) {
double score = 100.0;
// 缺失值扣分
double missingPenalty = (double) report.getMissingValues() /
(report.getTotalRecords() * config.getRequiredColumns().size())
* 50;
score -= Math.min(missingPenalty, 30);
// 重复记录扣分
double duplicatePenalty = (double) report.getDuplicateRecords() /
report.getTotalRecords() * 30;
score -= Math.min(duplicatePenalty, 20);
// 问题数量扣分
score -= report.getIssues().size() * 5;
return Math.max(0, Math.round(score * 10) / 10.0);
}
}
/**
* 质量检查配置
*/
@Data
class QualityConfig {
private List<String> requiredColumns;
private double maxMissingRate = 0.05; // 最大缺失率 5%
private int maxDuplicates = 100; // 最大重复记录数
private double minQualityScore = 80.0; // 最低质量分数
}3.2 特征工程模块
特征工程模块负责特征的提取、转换、选择和版本管理。
核心功能:
- 特征提取:从原始数据中提取有意义的特征
- 特征转换:标准化、归一化、编码等
- 特征选择:选择对模型预测最有价值的特征
- 特征存储:使用 Feature Store 统一管理特征
3.3 模型训练模块
模型训练模块负责模型的训练、评估和超参数调优。
核心功能:
- 分布式训练:支持多 GPU、多节点训练
- 超参数调优:自动化搜索最优超参数组合
- 模型评估:多维度评估模型性能
- 实验追踪:记录所有实验配置和结果
Python 代码示例 - 模型训练流水线:
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
MLOps 模型训练流水线
支持分布式训练、超参数调优和实验追踪
"""
import os
import json
import logging
from datetime import datetime
from typing import Dict, Any, Optional
from dataclasses import dataclass, asdict
import mlflow
import numpy as np
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import joblib
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
@dataclass
class TrainingConfig:
"""训练配置"""
model_name: str
train_data_path: str
test_data_path: str
output_path: str
n_estimators: int = 100
max_depth: Optional[int] = None
random_state: int = 42
cv_folds: int = 5
@dataclass
class TrainingResult:
"""训练结果"""
model_name: str
train_timestamp: str
metrics: Dict[str, float]
hyperparameters: Dict[str, Any]
model_path: str
mlflow_run_id: str
status: str
class ModelTrainer:
"""模型训练器"""
def __init__(self, config: TrainingConfig):
self.config = config
self.mlflow_tracking_uri = os.getenv(
'MLFLOW_TRACKING_URI',
'http://localhost:5000'
)
def run(self) -> TrainingResult:
"""执行训练流程"""
logger.info(f"开始训练模型:{self.config.model_name}")
# 设置 MLflow 追踪
mlflow.set_tracking_uri(self.mlflow_tracking_uri)
mlflow.set_experiment(self.config.model_name)
with mlflow.start_run() as run:
try:
# 加载数据
X_train, y_train = self._load_data(self.config.train_data_path)
X_test, y_test = self._load_data(self.config.test_data_path)
# 记录超参数
hyperparams = {
'n_estimators': self.config.n_estimators,
'max_depth': self.config.max_depth,
'random_state': self.config.random_state
}
mlflow.log_params(hyperparams)
# 训练模型
model = RandomForestClassifier(
n_estimators=self.config.n_estimators,
max_depth=self.config.max_depth,
random_state=self.config.random_state
)
model.fit(X_train, y_train)
# 交叉验证
cv_scores = cross_val_score(
model, X_train, y_train,
cv=self.config.cv_folds,
scoring='accuracy'
)
mlflow.log_metric('cv_mean_accuracy', cv_scores.mean())
mlflow.log_metric('cv_std_accuracy', cv_scores.std())
# 测试集评估
y_pred = model.predict(X_test)
accuracy = np.mean(y_pred == y_test)
mlflow.log_metric('test_accuracy', accuracy)
# 记录其他指标
from sklearn.metrics import precision_score, recall_score, f1_score
mlflow.log_metric('precision', precision_score(y_test, y_pred, average='weighted'))
mlflow.log_metric('recall', recall_score(y_test, y_pred, average='weighted'))
mlflow.log_metric('f1_score', f1_score(y_test, y_pred, average='weighted'))
# 保存模型
model_path = os.path.join(
self.config.output_path,
f"{self.config.model_name}_{datetime.now().strftime('%Y%m%d_%H%M%S')}.pkl"
)
os.makedirs(os.path.dirname(model_path), exist_ok=True)
joblib.dump(model, model_path)
# 记录模型 artifact
mlflow.sklearn.log_model(model, "model")
result = TrainingResult(
model_name=self.config.model_name,
train_timestamp=datetime.now().isoformat(),
metrics={
'accuracy': accuracy,
'cv_mean': cv_scores.mean(),
'cv_std': cv_scores.std()
},
hyperparameters=hyperparams,
model_path=model_path,
mlflow_run_id=run.info.run_id,
status='success'
)
logger.info(f"训练完成 - 准确率:{accuracy:.4f}")
return result
except Exception as e:
logger.error(f"训练失败:{str(e)}")
mlflow.set_tag('status', 'failed')
return TrainingResult(
model_name=self.config.model_name,
train_timestamp=datetime.now().isoformat(),
metrics={},
hyperparameters={},
model_path='',
mlflow_run_id=run.info.run_id,
status='failed'
)
def _load_data(self, data_path: str):
"""加载数据(简化示例)"""
# 实际项目中应从文件或数据库加载
X = np.random.rand(1000, 20)
y = np.random.randint(0, 2, 1000)
return X, y
if __name__ == '__main__':
# 示例用法
config = TrainingConfig(
model_name='fraud_detection_v1',
train_data_path='./data/train.csv',
test_data_path='./data/test.csv',
output_path='./models',
n_estimators=100,
max_depth=10
)
trainer = ModelTrainer(config)
result = trainer.run()
print(json.dumps(asdict(result), indent=2))3.4 模型注册模块
模型注册模块提供模型的版本管理、审批流程和生命周期管理。
核心功能:
- 模型版本控制:每个模型有多个版本
- 模型审批流程:支持多阶段审批(开发→测试→生产)
- 模型元数据:记录模型来源、训练数据、性能指标
- 模型检索:支持按名称、版本、标签检索模型
3.5 部署服务模块
部署服务模块负责将模型部署到生产环境,支持多种部署模式。
部署模式:
- 实时推理:REST API 或 gRPC 接口
- 批量推理:定时处理批量数据
- 边缘部署:部署到边缘设备
- A/B 测试 :支持多版本模型同时运行
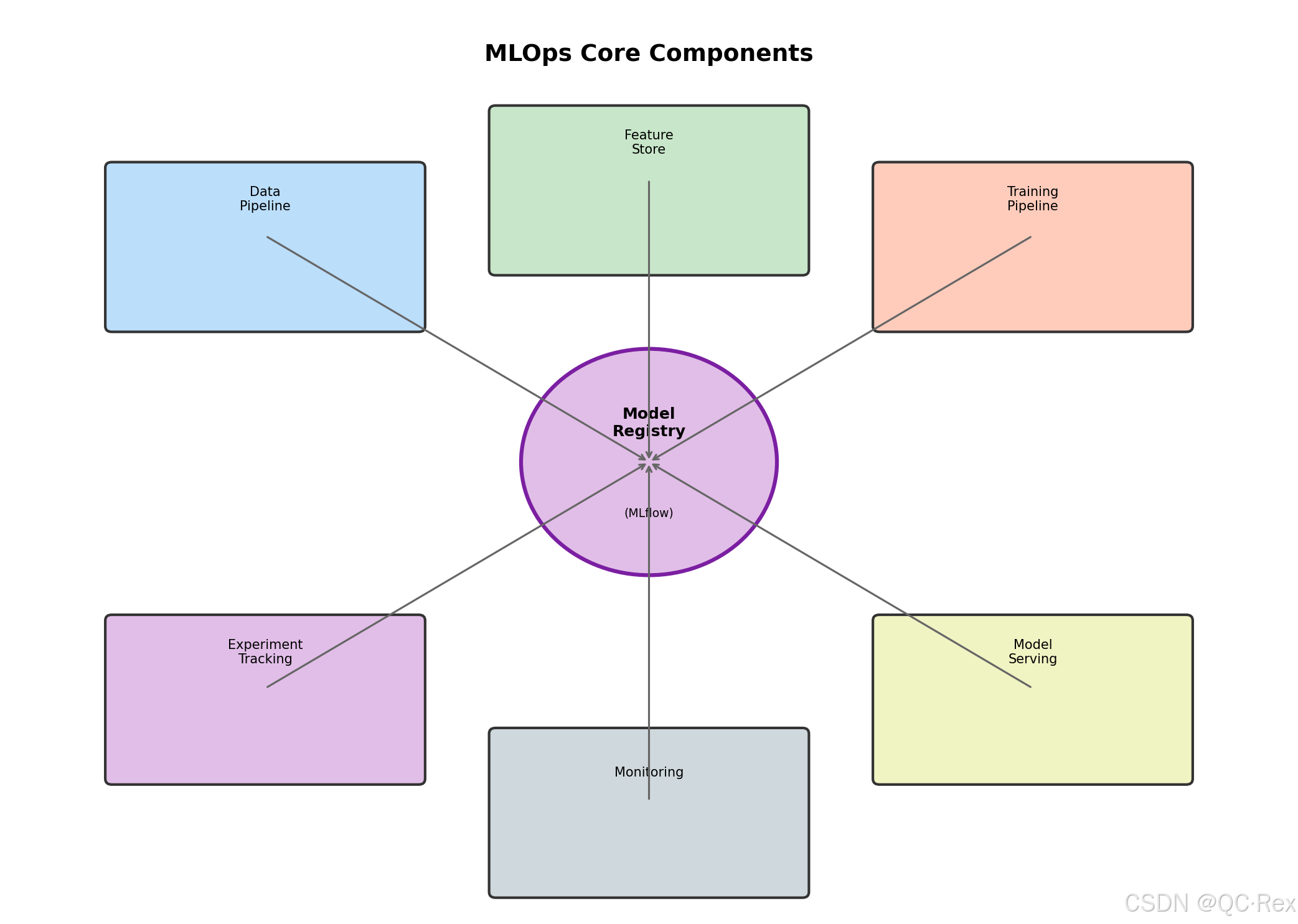
图 3: MLOps 核心组件关系图 - 以模型注册表为中心的组件交互
4. 技术选型与工具链
4.1 推荐技术栈
以下是构建企业级 MLOps 平台的推荐技术栈:
| 组件类别 | 推荐工具 | 说明 |
|---|---|---|
| 容器编排 | Kubernetes | 容器编排和自动化部署 |
| 工作流引擎 | Apache Airflow / Argo Workflows | 编排数据流水线和训练任务 |
| 实验追踪 | MLflow / Weights & Biases | 记录实验配置和结果 |
| 模型注册 | MLflow Model Registry | 模型版本管理 |
| 特征存储 | Feast / Tecton | 统一特征管理 |
| 数据版本 | DVC (Data Version Control) | 数据和模型版本控制 |
| 监控告警 | Prometheus + Grafana | 指标监控和可视化 |
| 日志管理 | ELK Stack (Elasticsearch, Logstash, Kibana) | 日志收集和分析 |
| CI/CD | Jenkins / GitLab CI / GitHub Actions | 持续集成和部署 |
4.2 Kubernetes 部署配置示例
以下是模型服务的 Kubernetes 部署配置:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: model-serving-deployment
namespace: mlops
labels:
app: model-serving
version: v1.0.0
spec:
replicas: 3
selector:
matchLabels:
app: model-serving
template:
metadata:
labels:
app: model-serving
version: v1.0.0
spec:
containers:
- name: model-server
image: registry.example.com/mlops/model-server:v1.0.0
ports:
- containerPort: 8080
resources:
requests:
memory: "512Mi"
cpu: "250m"
limits:
memory: "1Gi"
cpu: "500m"
env:
- name: MODEL_NAME
value: "fraud_detection_v1"
- name: MODEL_VERSION
value: "1.0.0"
- name: MLFLOW_TRACKING_URI
value: "http://mlflow.mlops.svc.cluster.local:5000"
livenessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
readinessProbe:
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
---
apiVersion: v1
kind: Service
metadata:
name: model-serving-service
namespace: mlops
spec:
selector:
app: model-serving
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: ClusterIP
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: model-serving-hpa
namespace: mlops
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: model-serving-deployment
minReplicas: 3
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 705. 实战:构建 MLOps 流水线
5.1 流水线设计
一个完整的 MLOps 流水线包含以下阶段:
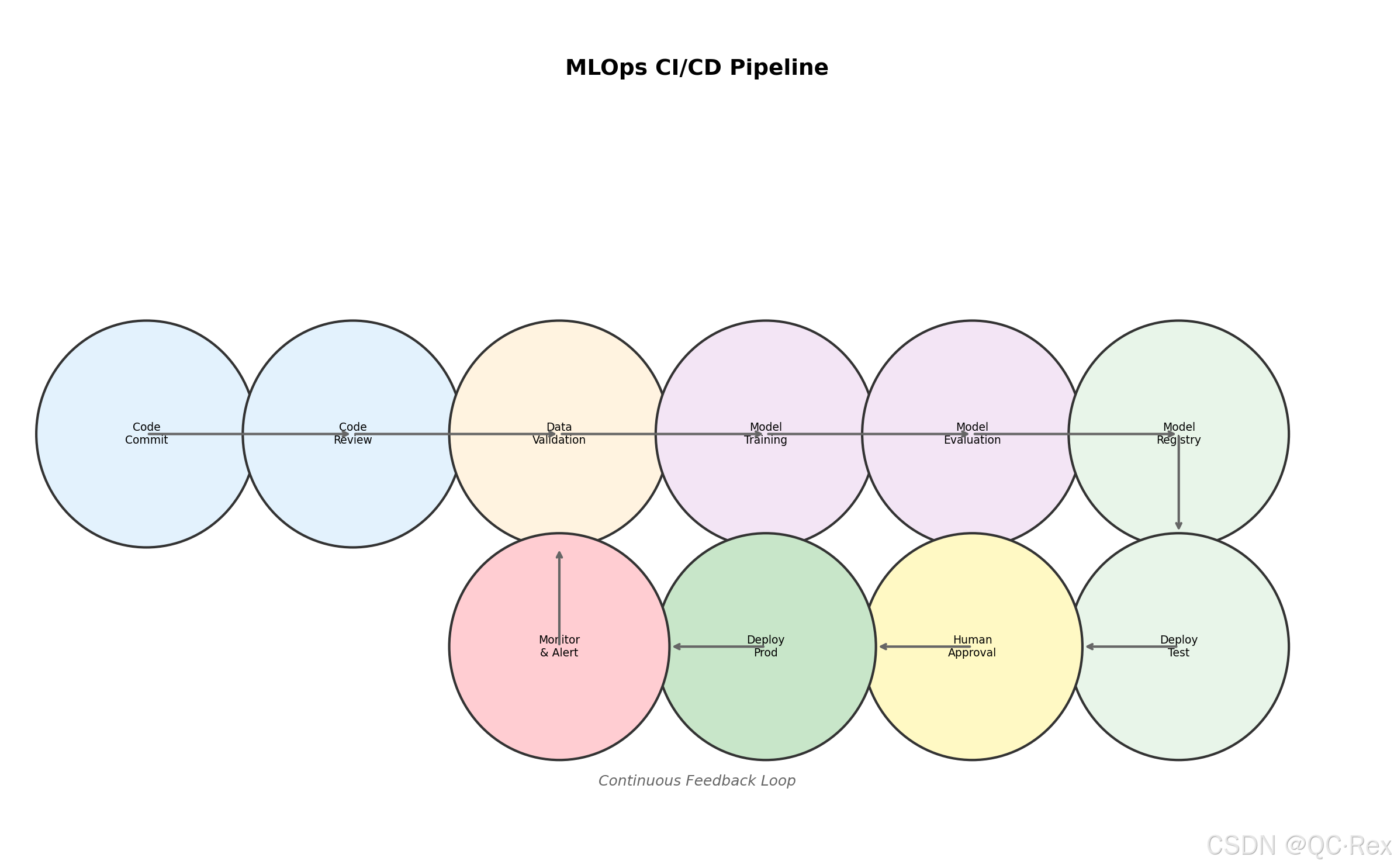
图 4: MLOps CI/CD 流水线 - 从代码提交到生产部署的完整流程
- 代码提交:开发者提交代码到 Git 仓库
- 代码审查:自动触发代码质量检查和审查
- 数据验证:验证训练数据的质量和完整性
- 模型训练:在隔离环境中训练模型
- 模型评估:评估模型性能,与基准比较
- 模型注册:将合格模型注册到模型仓库
- 自动化测试:运行集成测试和端到端测试
- 部署到测试环境:部署模型到测试环境验证
- 人工审批:相关负责人审批上线
- 部署到生产:灰度发布或全量发布
- 监控告警:持续监控模型性能
5.2 GitLab CI/CD 配置示例
yaml
# .gitlab-ci.yml
stages:
- validate
- train
- evaluate
- register
- deploy-test
- deploy-prod
variables:
MLFLOW_TRACKING_URI: "http://mlflow.example.com:5000"
MODEL_REGISTRY: "model-registry.example.com"
# 代码和数据验证
validate:
stage: validate
image: python:3.10
script:
- pip install -r requirements.txt
- python scripts/validate_code.py
- python scripts/validate_data.py
artifacts:
paths:
- validation_report.json
# 模型训练
train:
stage: train
image: python:3.10
needs: [validate]
script:
- pip install -r requirements.txt
- python scripts/train.py --config config/train_config.yaml
artifacts:
paths:
- models/
- training_metrics.json
# 模型评估
evaluate:
stage: evaluate
image: python:3.10
needs: [train]
script:
- pip install -r requirements.txt
- python scripts/evaluate.py --model models/ --threshold 0.85
rules:
- if: $CI_COMMIT_BRANCH == "main"
# 模型注册
register:
stage: register
image: python:3.10
needs: [evaluate]
script:
- pip install mlflow
- python scripts/register_model.py --name $MODEL_NAME --version $CI_COMMIT_SHA
rules:
- if: $CI_COMMIT_BRANCH == "main"
# 部署到测试环境
deploy-test:
stage: deploy-test
image: bitnami/kubectl:latest
needs: [register]
script:
- kubectl apply -f k8s/test/
- kubectl rollout status deployment/model-serving-test -n mlops-test
environment:
name: test
url: https://test-api.example.com/health
rules:
- if: $CI_COMMIT_BRANCH == "main"
# 部署到生产环境(需要人工审批)
deploy-prod:
stage: deploy-prod
image: bitnami/kubectl:latest
needs: [deploy-test]
script:
- kubectl apply -f k8s/prod/
- kubectl rollout status deployment/model-serving-prod -n mlops-prod
environment:
name: production
url: https://api.example.com/health
when: manual
rules:
- if: $CI_COMMIT_BRANCH == "main"6. 模型监控与告警系统
6.1 监控指标
模型监控应覆盖以下关键指标:
系统指标:
- 服务可用性:API 响应成功率
- 延迟:P50、P95、P99 响应时间
- 吞吐量:每秒请求数(QPS)
- 资源使用:CPU、内存、GPU 使用率
模型指标:
- 预测分布:预测结果的统计分布
- 数据漂移:输入数据分布与训练数据的差异
- 概念漂移:模型预测准确率随时间的变化
- 异常检测 :检测异常输入和预测
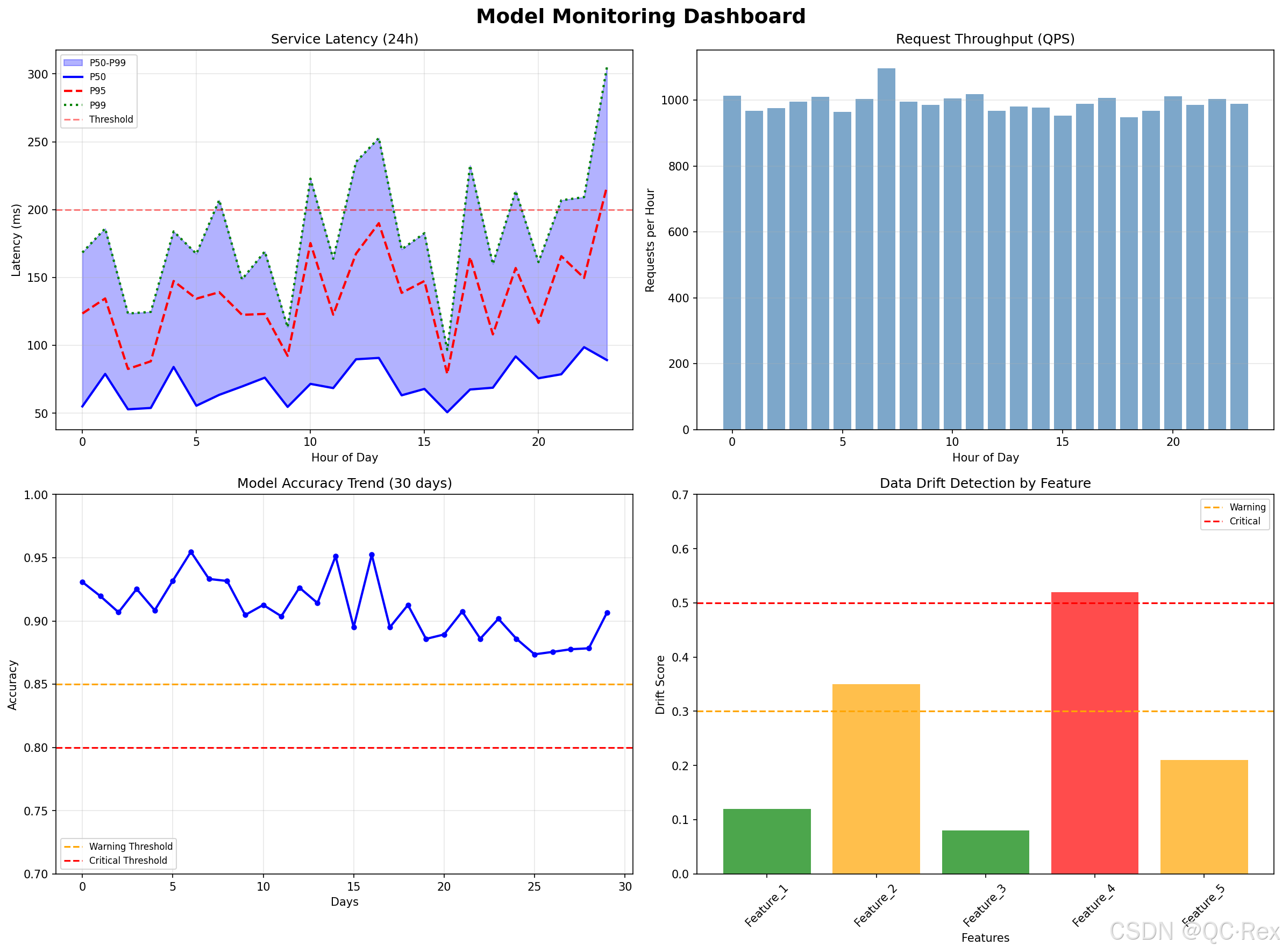
图 5: 模型监控仪表板 - 展示延迟、吞吐量、准确率和数据漂移
6.2 Prometheus 监控配置
yaml
# prometheus-rules.yml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: mlops-alerts
namespace: mlops
spec:
groups:
- name: mlops.rules
rules:
# 服务可用性告警
- alert: ModelServiceDown
expr: up{job="model-serving"} == 0
for: 5m
labels:
severity: critical
annotations:
summary: "模型服务不可用"
description: "模型服务 {{ $labels.instance }} 已宕机超过 5 分钟"
# 高延迟告警
- alert: HighLatency
expr: histogram_quantile(0.95, rate(http_request_duration_seconds_bucket{job="model-serving"}[5m])) > 1
for: 10m
labels:
severity: warning
annotations:
summary: "模型服务延迟过高"
description: "P95 延迟超过 1 秒,当前值:{{ $value }}s"
# 错误率告警
- alert: HighErrorRate
expr: rate(http_requests_total{job="model-serving",status=~"5.."}[5m]) / rate(http_requests_total{job="model-serving"}[5m]) > 0.05
for: 5m
labels:
severity: critical
annotations:
summary: "模型服务错误率过高"
description: "错误率超过 5%,当前值:{{ $value | humanizePercentage }}"
# 数据漂移告警
- alert: DataDriftDetected
expr: data_drift_score > 0.3
for: 1h
labels:
severity: warning
annotations:
summary: "检测到数据漂移"
description: "数据漂移分数超过阈值,当前值:{{ $value }}"
# 模型性能下降告警
- alert: ModelPerformanceDegradation
expr: model_accuracy < 0.80
for: 24h
labels:
severity: warning
annotations:
summary: "模型性能下降"
description: "模型准确率低于 80%,当前值:{{ $value | humanizePercentage }}"6.3 模型重新训练触发
当检测到以下情况时,应触发模型重新训练:
- 数据漂移:输入数据分布发生显著变化
- 性能下降:模型准确率低于阈值
- 定期更新:按计划定期重新训练(如每周/每月)
- 新数据可用:积累了足够多的新标注数据
7. 安全与合规考虑
7.1 安全最佳实践
访问控制:
- 实施基于角色的访问控制(RBAC)
- 最小权限原则,只授予必要的权限
- 使用服务账户进行服务间认证
数据安全:
- 传输层加密(TLS/SSL)
- 存储加密(静态数据加密)
- 敏感数据脱敏处理
- 数据访问审计日志
模型安全:
- 模型签名和验证
- 防止模型窃取和对抗攻击
- 模型输出内容过滤
7.2 合规要求
根据不同行业和地区,可能需要满足以下合规要求:
- GDPR(欧盟通用数据保护条例):数据主体权利、数据最小化
- HIPAA(美国健康保险流通与责任法案):医疗数据保护
- SOC 2:服务组织控制审计
- ISO 27001:信息安全管理体系
7.3 审计日志
记录所有关键操作以便审计:
java
package com.mlops.platform.audit;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import org.springframework.transaction.annotation.Transactional;
import java.time.Instant;
import java.util.Map;
/**
* 审计日志记录器
* 记录所有关键操作以满足合规要求
*/
@Component
@Slf4j
public class AuditLogger {
/**
* 记录模型部署操作
*/
@Transactional
public void logModelDeployment(String modelName, String version,
String environment, String operator) {
AuditEvent event = AuditEvent.builder()
.eventType("MODEL_DEPLOYMENT")
.timestamp(Instant.now())
.operator(operator)
.resourceType("MODEL")
.resourceId(modelName + ":" + version)
.details(Map.of(
"modelName", modelName,
"version", version,
"environment", environment
))
.build();
saveAuditEvent(event);
log.info("审计日志 - 模型部署:{} v{} -> {}", modelName, version, environment);
}
/**
* 记录数据访问操作
*/
@Transactional
public void logDataAccess(String datasetId, String operation,
String operator, String purpose) {
AuditEvent event = AuditEvent.builder()
.eventType("DATA_ACCESS")
.timestamp(Instant.now())
.operator(operator)
.resourceType("DATASET")
.resourceId(datasetId)
.details(Map.of(
"operation", operation,
"purpose", purpose
))
.build();
saveAuditEvent(event);
}
private void saveAuditEvent(AuditEvent event) {
// 保存到审计日志数据库
// 实际实现中应写入不可篡改的存储
}
}8. 总结与展望
8.1 关键要点总结
本文详细介绍了企业级 MLOps 平台的架构设计和实施方法,关键要点包括:
- MLOps 核心价值:加速模型上线、提高质量、降低成本、促进协作
- 架构设计原则:模块化、可扩展、可复现、安全
- 核心组件:数据管理、特征工程、模型训练、模型注册、部署服务、监控告警
- 技术选型:Kubernetes、MLflow、Airflow、Prometheus 等开源工具
- 实施路径:从自动化流水线到完整 CI/CD 集成
- 监控告警:系统指标 + 模型指标双重监控
- 安全合规:访问控制、数据加密、审计日志
8.2 实施建议
对于计划构建 MLOps 平台的企业,建议按以下步骤实施:
- 评估现状:了解当前的机器学习开发流程和痛点
- 制定路线图:从 Level 0 到 Level 2 的渐进式演进
- 选择工具:根据团队技术栈和业务需求选择合适的工具
- 试点项目:选择一个典型项目作为试点
- 迭代优化:根据反馈持续改进平台和流程
- 推广普及:将成功经验推广到其他团队和项目
8.3 未来趋势
MLOps 领域的发展趋势包括:
- 自动化程度提升:AutoML 与 MLOps 的深度融合
- 边缘 MLOps:模型在边缘设备的部署和管理
- 大模型运维:针对 LLM 的 specialized MLOps 工具链
- 绿色 MLOps:关注模型训练的能源效率和碳排放
- 治理与合规:更严格的模型治理和监管要求
附录:快速开始指南
A.1 环境准备
bash
# 安装 Docker 和 Kubernetes
curl -fsSL https://get.docker.com | sh
kubectl version --client
# 安装 MLflow
pip install mlflow
# 安装 Apache Airflow
pip install apache-airflow
# 克隆示例项目
git clone https://github.com/example/mlops-platform-template.git
cd mlops-platform-templateA.2 启动本地 MLOps 环境
bash
# 使用 Docker Compose 启动所有服务
docker-compose up -d
# 访问 MLflow UI
open http://localhost:5000
# 访问 Airflow UI
open http://localhost:8080
# 访问 Prometheus
open http://localhost:9090
# 访问 Grafana
open http://localhost:3000A.3 运行示例流水线
bash
# 提交训练任务
python scripts/submit_training_job.py --config examples/fraud_detection.yaml
# 查看训练状态
mlflow runs list --experiment-id 1
# 部署模型
kubectl apply -f deployments/fraud_detection_v1.yaml