还记得之前那个特别火的 GStack 吗?
我前几天也发过文章介绍过。

就是 Y Combinator 现任总裁兼 CEO Garry Tan 开源的那套专门给 AI 写代码用的 Skill 工作流,目前 7 万+ Star。
每天有 3 万开发者在用,在 Claude Code 圈子里基本算是贼火模板了。
就在前几天,他又甩出来一个新项目,叫 GBrain。
这次解决的是另一个老大难:AI Agent 的金鱼脑问题。
解决每次开聊都从零开始的问题,昨天告诉它的事今天就当没发生过。
GBrain 干的事就一句话:给你的 AI Agent 装一个能持续变聪明的长期记忆。
这个项目 4 月初开源,十几天就拿了 9K+ Star。
作者本人就用它跑自己日常的真实 Agent:目前里面已经有 17888 个页面、4383 个人物、723 家公司、21 个定时任务全自动运转。
整套东西他只用了 12 天就搭出来了。
01、开源项目简介
GBrain 是给 AI Agent 用的长期记忆系统。
你的 Agent 接入它之后,会在你睡觉的时候自己变聪明。
自动消化你的会议记录、邮件、推特、语音通话和你随手记下的想法,顺手帮你补全每个出现过的人和公司的资料,还会自己修复坏掉的引用、整理凌乱的记忆。
第二天你起床,这个脑子已经比你昨晚睡前更聪明了。

bash
开源地址:github.com/garrytan/gbrain和之前的 GStack 什么关系?
GStack 教 Agent 怎么写代码,GBrain 教 Agent 怎么记事和思考。
两个项目可以独立用,也能合体。
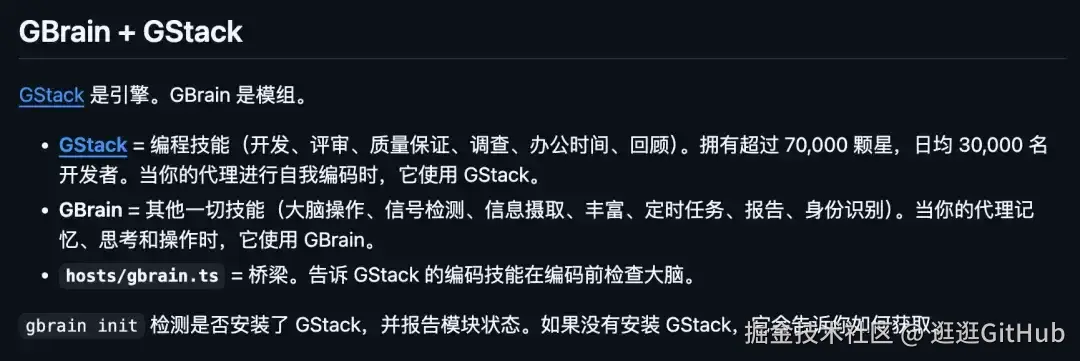
开源项目里有个 hosts/gbrain.ts 就是那座桥,装上之后 GStack 的编码 Skill 在动手写代码前会先查一下脑子,看看你之前是不是讨论过、决定过什么。
如果你已经在用 GStack,装上 GBrain 基本就拼出 Garry Tan 自己那套完整工作流了:一个管手,一个管脑。
02、4 个核心亮点
亮点一:25 个 Skill 即插即用
GBrain 自带 25 个 Skill,装上就能用,按用途分了几类。
里面有两个是永远在线的:
一个叫 signal-detector,每条新消息进来都会顺手起一个便宜的小模型在后台跑,把你随口说的观点和提到的人/公司都抓出来。
脑子是在你不知不觉中长大的。
另一个叫 brain-ops,Agent 回答之前会先去脑子里查一遍,查不到再去调外部 API。
这就解决了 AI 经常瞎编的问题:查不到它会直接告诉你脑子里没这个信息,而不是给你胡诌一段。
剩下的还有内容摄入类,会议、邮件、推特、PDF、视频、GitHub 仓库全吃。
运维类,比如cron 调度、每日简报、引用自检、过期页面巡检,完全是一套自治系统。
亮点二:Compiled Truth + Timeline 知识模型
这个设计挺顶的,值得单独拎出来讲。
每个 brain page 分两层:
上面叫 compiled truth,也就是当前最佳理解,可以被随时改写。比如你对某个朋友的认知,会随着新的接触不断刷新。
下面叫 timeline,只追加不删除,记录每条原始证据。
为啥这么设计? 因为既要让认知能进化,又不能丢历史。
AI 之前的笔记类工具要么覆盖式更新,要么纯追加,查的时候一团乱,GBrain 这个分层算是把两边的好处都拿了。
亮点三:混合搜索 + 实体自动升级
搜索这块用的是向量 + 关键词 + RRF 融合 + 多查询扩展 + 4 层去重。
简单讲:关键词搜索能精准命中原话,向量搜索能找到意思相近的内容,两个一起上再融合排序,基本不会漏。

更有意思的是它的实体自动升级机制:
同一个人在你的资料里被提到 1 次,只生成一个 stub 页面。
提到 3 次以上,系统自动联网补料,从 LinkedIn、Twitter、公司主页之类的地方拉信息回来。
提到 8 次以上,或者你跟他开过会,直接走完整管线,生成一份详细 dossier。
脑子自己学谁重要,不需要你手动标。
它还有个 fail-improve 循环:每次 LLM 兜底分类的时候都会被记录下来,系统自动从这些记录里生成更好的正则,意图分类器从第一周的 40% 确定性涨到了 87%。
脑子自己在变得更便宜更准。
亮点四:能打电话的脑子
这个功能听起来有点科幻,但配方就在仓库里。
集成 Twilio + OpenAI Realtime,你打电话进去,AI 接起来的时候已经从脑子里把对方的全部上下文拉出来了。
你们上次聊了啥、之前合作过什么项目、还有哪些未结的话题。

通话结束之后,自动生成一个 brain page,里面有完整转录、自动识别的实体、和已有页面的交叉引用。
下次再聊到这个人的时候,脑子已经记住了这通电话。
03 、如何部署
GBrain 设计的时候就是要让 AI Agent 自己装的,所以官方最推荐的方式是把一段 prompt 丢给你的 Agent 让它自己搞。
路线 A:让 Agent 自己装
如果你已经在跑 OpenClaw 或 Hermes Agent,直接把下面这段贴进去:
ruby
Retrieve and follow the instructions at:https://raw.githubusercontent.com/garrytan/gbrain/master/INSTALL_FOR_AGENTS.md剩下的 Agent 自己来:克隆仓库、装 GBrain、建脑子、加载 25 个 Skill、配好定时任务。
你只需要回答几个 API Key 的问题,大概 30 分钟搞定。
路线 B:本地 CLI 玩玩
不想搞这么重,先在本地体验一下也行:
bash
git clone https://github.com/garrytan/gbrain.git && cd gbrain && bun install && bun linkgbrain init
# 本地脑子,2 秒拉起
gbrain import ~/notes/
# 把你的笔记导进去
gbrain query "我的笔记里反复出现的主题是什么?" 默认用 PGLite,也就是嵌入式 Postgres,不用启服务、零配置。
等你的脑子长大了,超过 1000 个文件,或者要多设备同步,一条 gbrain migrate --to supabase 就能把所有东西迁到 Supabase 上。
路线 C:接入 Claude Code / Cursor
GBrain 自带 30+ 个 MCP 工具,通过 stdio 暴露,直接接进 Claude Code、Cursor、Windsurf 都行。
json
{
"mcpServers": {
"gbrain": { "command": "gbrain", "args": ["serve"] }
}
}接完之后,你在 Claude Code 里写代码的时候,Claude 就能直接读你脑子里的内容了。
比如你之前关于某个架构决策的讨论、某个人提到的偏好、某次会议的结论,都能被随手调出来。
04、总结与启发
GBrain 最值得借鉴的其实不是代码,而是它背后那条设计哲学,叫 Thin Harness, Fat Skill:意思是把智能放在 Skill 里,Runtime 越薄越好。
这条思路最近在 Claude Code 圈子里讨论很多,Garry Tan 自己也发过一条推说 Skill 文件就是代码,是目前做知识工作最强的载体。
GStack 和 GBrain 这两个项目都是这条哲学的实践,一个用 Skill 实现编码工作流,一个用 Skill 实现记忆和运营,Runtime 都很轻。
Garry Tan 那条 Skill files are code 的推文,值得专门去翻一下,理解了这句话再回头看 GBrain,会觉得每个 Skill 的设计都对得上。