1 泛型是什么?为什么要用泛型,什么是类型擦除
1.1 泛型是什么?
泛型(Generics)是 JDK 1.5 引入的特性,允许在定义类、接口、方法时使用类型参数,在创建实例或调用时传入具体类型。
示例:List<String> list = new ArrayList(); 表示该列表只能存放 String 类型元素。
1.2 为什么要用泛型?
- 类型安全: 编译期检查类型,避免运行时 ClassCastException;
- 消除强制转换: 避免频繁的显式类型转换,代码更简洁;
- 代码复用: 通过类型参数编写通用算法(如集合框架),一套代码适配多种类型;
1.3 什么是类型擦除?
- 定义:Java 泛型在编译期将类型参数移除,替换为限定类型(若无限定则为 Object),并在必要时插入强制转换。这是 Java 泛型实现的一种折中,为了兼容 JDK 1.4 及之前的代码;
- 过程:
- 将泛型类型替换为原始类型(
List<String>→ List); - 在边界处插入强制类型转换(如从
List.get()取出后自动强转为 String); - 生成桥接方法以保持多态;
- 将泛型类型替换为原始类型(
- 后果:
- 运行时无法获取泛型的具体类型(如
list instanceof List<String>非法) - 无法通过类型参数创建数组(
T[] arr = new T[10];不允许); - 无法使用基本类型作为类型参数(需使用包装类);
- 运行时无法获取泛型的具体类型(如
1.4 总结
- 泛型:编译期类型约束,保证类型安全、避免强转;
- 类型擦除:JVM 没有泛型,编译后泛型被擦除为 Object/上限类型,是泛型底层实现原理;
2 谈谈你对 Java 泛型中类型擦除的理解,并说说其局限性
2.1 理解类型擦除
- 定义:Java 泛型仅在编译期存在,编译后泛型类型信息被移除(擦除),替换为原始类型,导致运行时丢失类型信息。 这是 Java 为实现泛型且保持与旧版本(JDK 1.4 及之前)二进制兼容而采用的机制;
- 擦除规则:
- 无限定类型参数(如
<T>)替换为 Object; - 有限定类型参数(如
<T extends Number>)替换为第一个边界类型(此处为 Number); - 在访问泛型对象时,编译器自动插入必要的强制类型转换;
- 为保持多态,编译器可能生成桥接方法(bridge method);
- 无限定类型参数(如
2.2 局限性(运行时限制)
- 无法获取运行时具体类型:
List<String>和List<Integer>在运行时都是 List,无法通过instanceof、反射获取类型参数; - 不能创建泛型数组:
T[] arr = new T[10];非法,因数组创建时必须知道确切类型(擦除后为 Object,赋值可能引发 ArrayStoreException); - 不能使用基本类型作为类型参数,需使用包装类: 如
List<Integer>而非List<int>(自动装箱有性能开销); - 静态上下文无法引用类型参数: 静态变量、静态方法不能使用类的泛型参数(因为类加载时尚未确定具体类型);
- 无法重栽擦除后相同签名的方法:
java
void print(List<String> list) {}
void print(List<Integer> list) {} // 编译错误,擦除后都是 List3 什么是反射机制?反射机制的应用场景有哪些?
3.1 什么是反射机制
反射(Reflection): 是 Java 语言的一种动态特性,允许程序在运行时获取任意类的信息(如类名、方法、字段、构造器),并能动态创建对象、调用方法、修改字段值,甚至访问私有成员。
核心类:Class、Method、Field、Constructor。
3.2 反射机制的应用场景
- 框架开发(最广泛):Spring、MyBatis、Hibernate 等框架利用反射动态创建 Bean、解析注解、注入依赖;
- 动态代理:JDK 动态代理通过反射在运行时生成代理类,调用目标方法(如 Spring AOP);
- 注解处理器:运行时读取注解(如
@Override、@Autowired),执行相应逻辑; - 序列化/反序列化:JSON、XML 等数据与 Java 对象互转时,通过反射读取/设置字段;
- 动态加载类:如 JDBC 的
Class.forName(com.mysql.jdbc.Driver)动态加载驱动;
3.3 总结
反射是 Java 运行时动态获取类信息并操作对象的机制,广泛应用于框架、动态代理、注解处理等场景。
4 说说你对 Java 注解的理解
4.1 注解是什么?
注解(Annotation)是 Java 提供的一种元数据机制,用于为代码(类、方法、字段)添加标记或配置信息。它不影响程序的直接运行,但可以被编译器、工具或框架在编译时或运行时读取和处理。
元数据(Metadata):是描述数据的数据,用于提供关于其他数据的附加信息,如数据的结构、含义、来源、格式或约束。它本身不是业务数据,但帮助理解、管理或处理业务数据。
4.2 常见内置注解
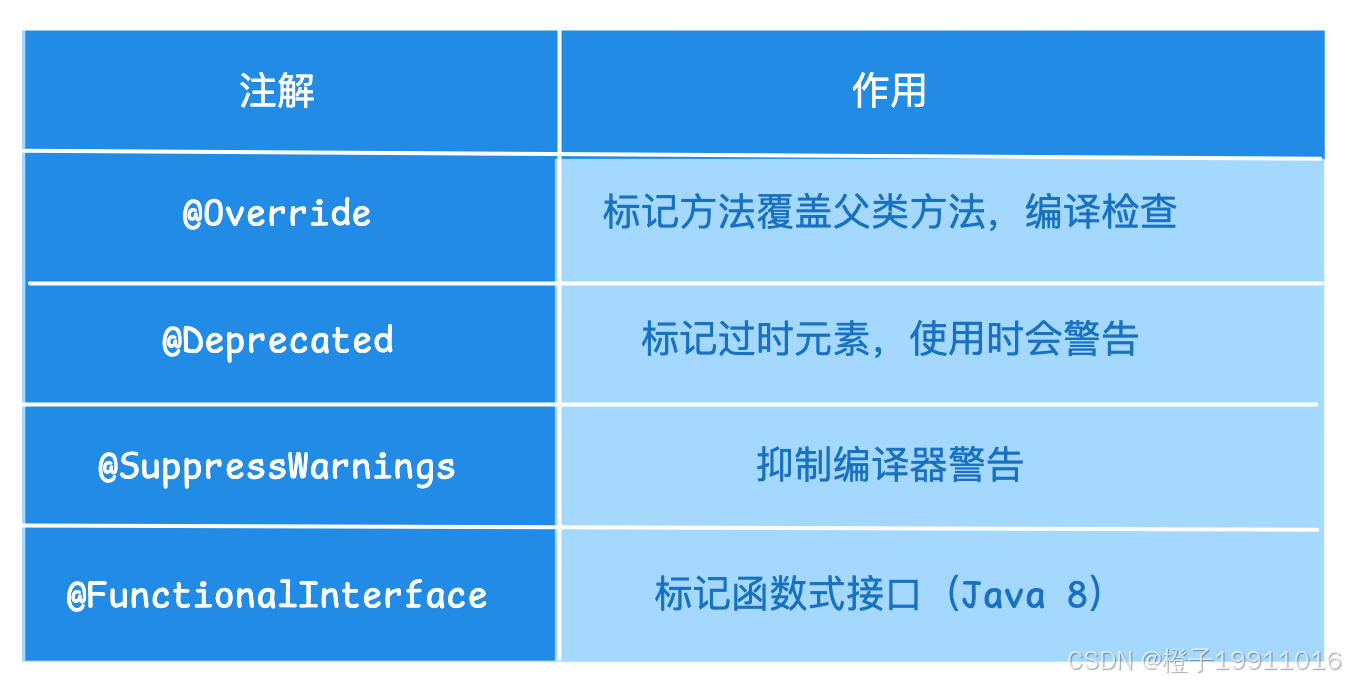
4.3 元注解(注解的注解)
用于定义新注解,常见有:
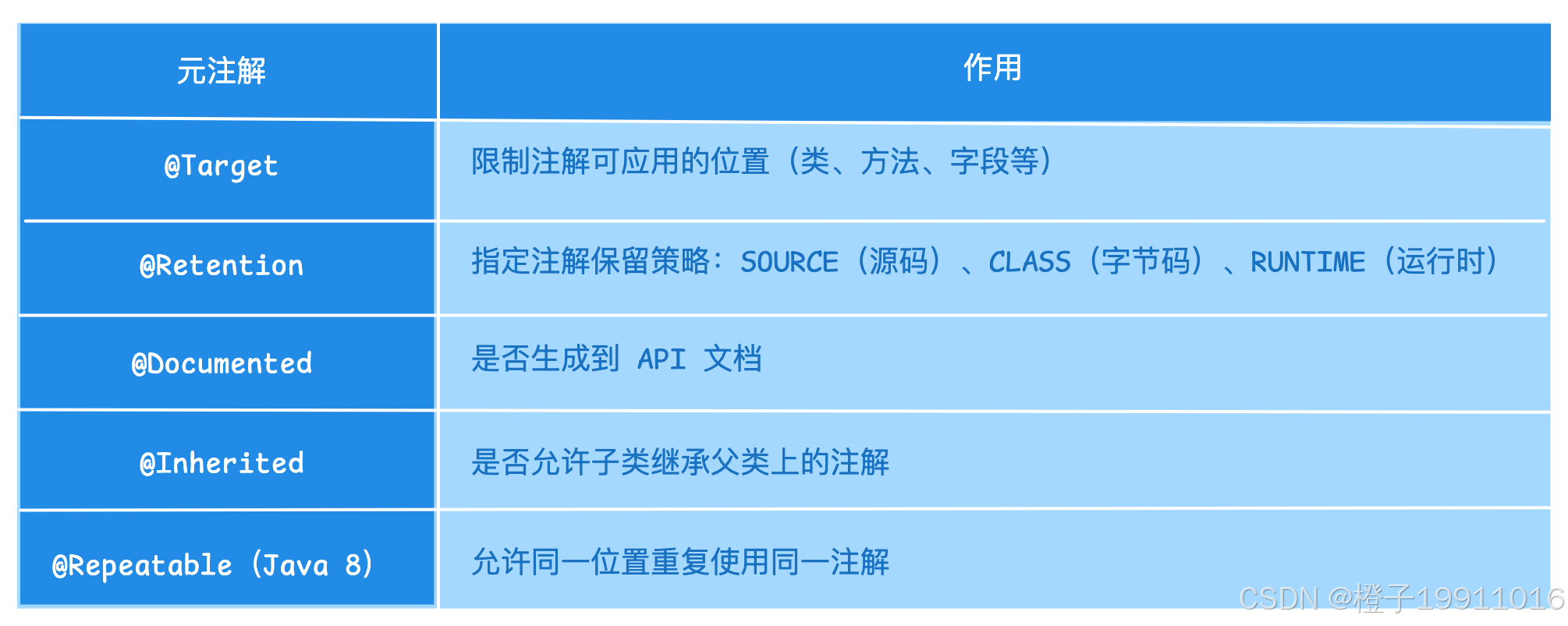
4.4 注解的作用
- 编译检查:如
@Override防止拼写错误; - 代码生成:如 Lombok 的
@Data、@Getter,编译时生成 getter/setter; - 运行时处理:通过反射读取
@Retention(RUNTIME)注解,实现框架功能(Spring、JUnit、MyBatis);
4.5 使用场景
- 框架配置:Spring 的
@Controller、@Service、@Autowired - 测试:JUnit 的
@Test、@Before - ORM 映射:Hibernate/MyBatis 的
@Entity、@Table、@Column - 权限控制:自定义
@RequirePermission,结合 AOP 拦截;
4.6 总结
- 注解是一种元数据形式,通过元注解定义其行为;
- 内置注解提供编译检查,运行时注解配合反射被框架广泛用于配置、代码生成和测试;
5 重载 (Overload) 与 重写 (Override) 区别
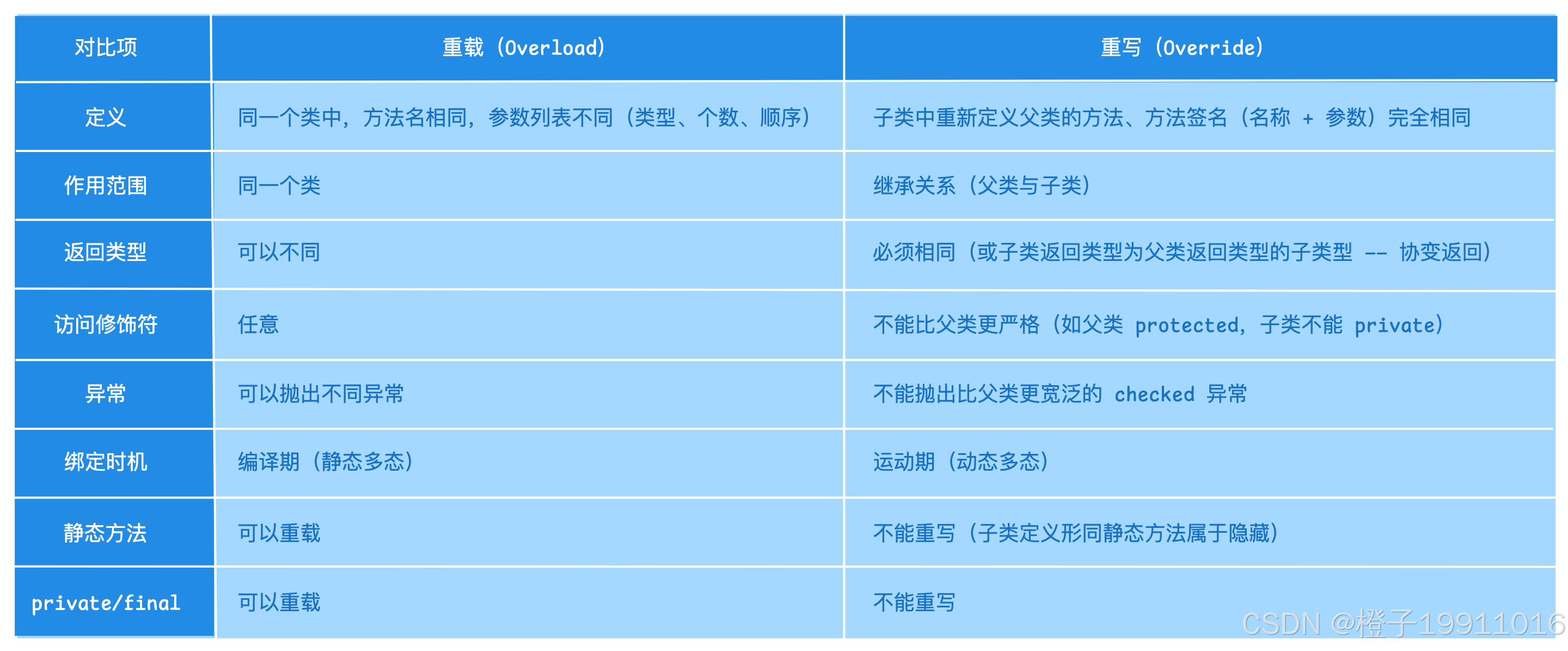
总结:
- 重载是编译期多态,同一个类中,方法名相同,参数列表不同(类型、个数、顺序);
- 重写是运行时多态,子类中重新定义父类的方法,方法签名(名称 + 参数)完全相同;
6 接口 (interface) 和 抽象类 (abstract class) 区别
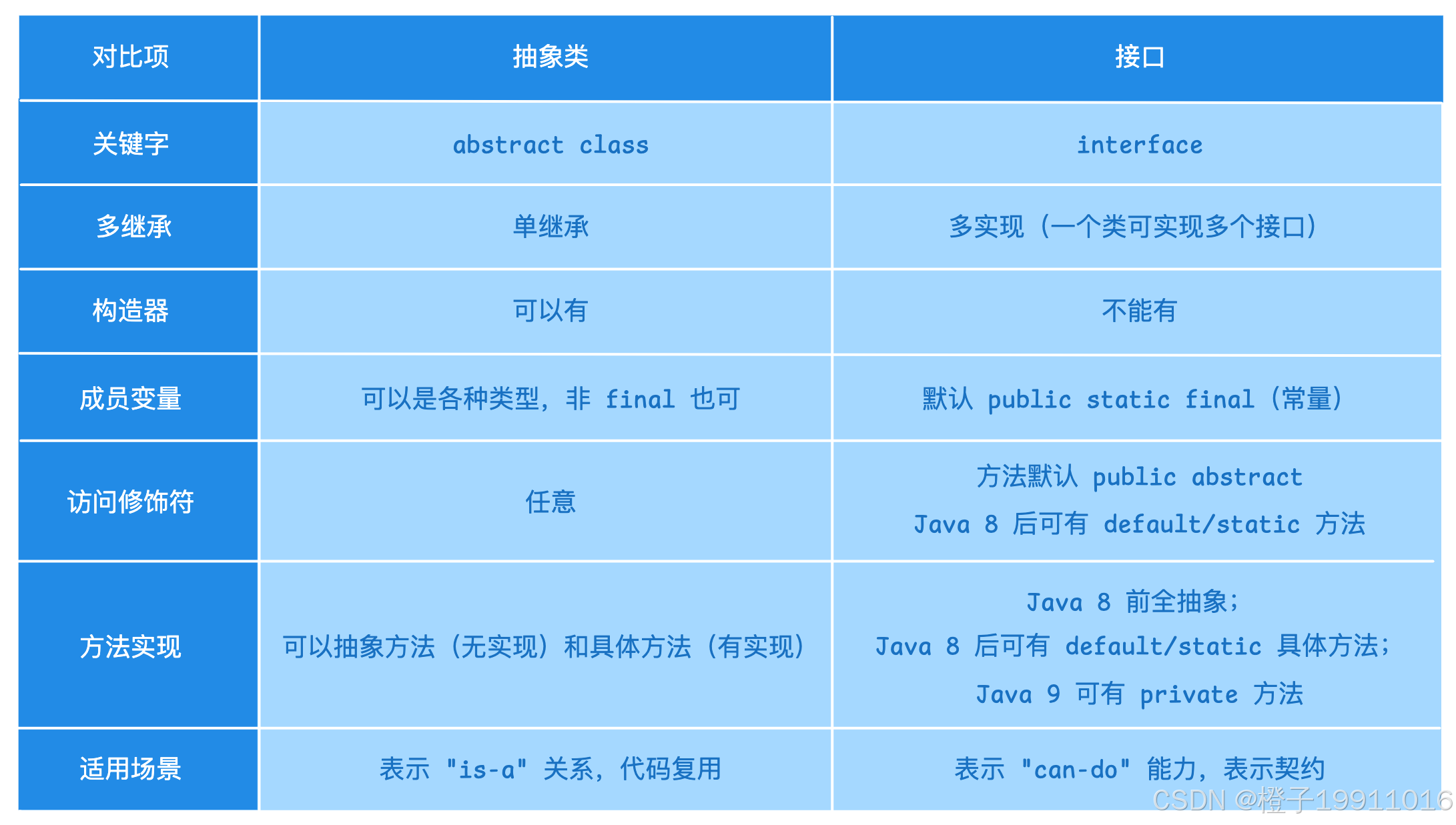
总结:
- 抽象类描述对象的本质("is-a"),可以有状态和构造器,支持单继承;
- 接口定义行为契约("can-do"),多实现,默认常量和抽象方法,Java 8 后可有默认/静态方法,但无实例字段;
7 equals 方法 与 ==、hashCode() 的区别和使用场景
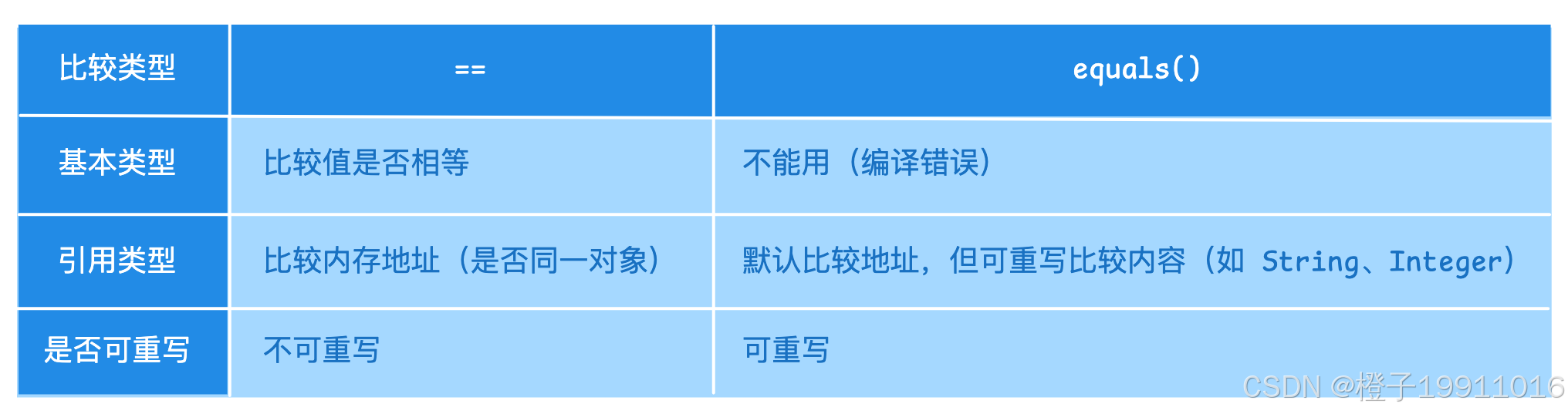
7.1 == 和 equals 方法的区别
7.2 equals 方法和 hashCode 方法的约定
-
一致性: 若
equals相等,则hashCode必须相等; -
逆命题不成立:
hashCode相等,equals不一定相等(哈希冲突); -
若不重写:
hashCode默认返回对象内存地址(或随机值),两个逻辑相等的对象大概率哈希码不同;- 在哈希表中,
put根据哈希码存入不同桶,get时无法找到对方,导致集合中出现"重复"元素(逻辑上相同却并存),破坏 Set 唯一性和 Map 键的查找功能;
在哈希集合(HashMap、HashSet)中,先通过
hashCode定位桶,再用equals比较;若违反约定,会导致集合中出现逻辑重复元素或无法找到元素;
7.3 使用场景
==- 判断基本类型数值是否相等;
- 判断两个引用是否指向同一个对象(如比较
this == obj是否同一对象);
equals- 判断两个对象逻辑上是否相等(如 String 内容相等、自定义类的业务主键相同);
- 集合(List、Set、Map)的
Contains、indexOf等依赖equals;
hashCode- 在哈希集合(HashSet、HashMap 的 Key)中作为存储位置依据;
- 需与
equals保持一致,否则集合行为异常;
7.4 总结
==比较基本类型值或引用地址;equals默认比较地址但通常重写为比较内容;hashCode必须与equals一致,以保证哈希集合正常工作;
8 谈谈如何重写 equals 方法?为什么还要重写 hashCode 方法?
**重写 equals 的步骤(规范): **重写 equals 方法需要满足自反性、对称性、传递性、一致性、非空性。

典型实现模版如下:
- 判断是否同一对象:
if(this == obj) return true;(性能优化); - 判断类型: 若参数为 null 或类型不匹配,返回 false。通常使用
getClass()或instanceof;- 若子类能改变父亲的相等语义,用
getClass();若子类不影响父类比较(如父类equals允许子类),用instanceof;
- 若子类能改变父亲的相等语义,用
- 强制转换:
OtherClass other = (OtherClass)obj; - 比较关键字段: 使用
==比较基本类型,Objects.equals方法比较对象字段(处理 null);
代码示例:
kotlin
@Override
public boolean equals(Object obj) {
if (this == obj) return true;
if (obj == null || getClass() != obj.getClass()) return false;
Person person = (Person) obj;
return age == person.age &&
Objects.equals(name, person.name);
}9 基本数据类型有哪些?包装类区别
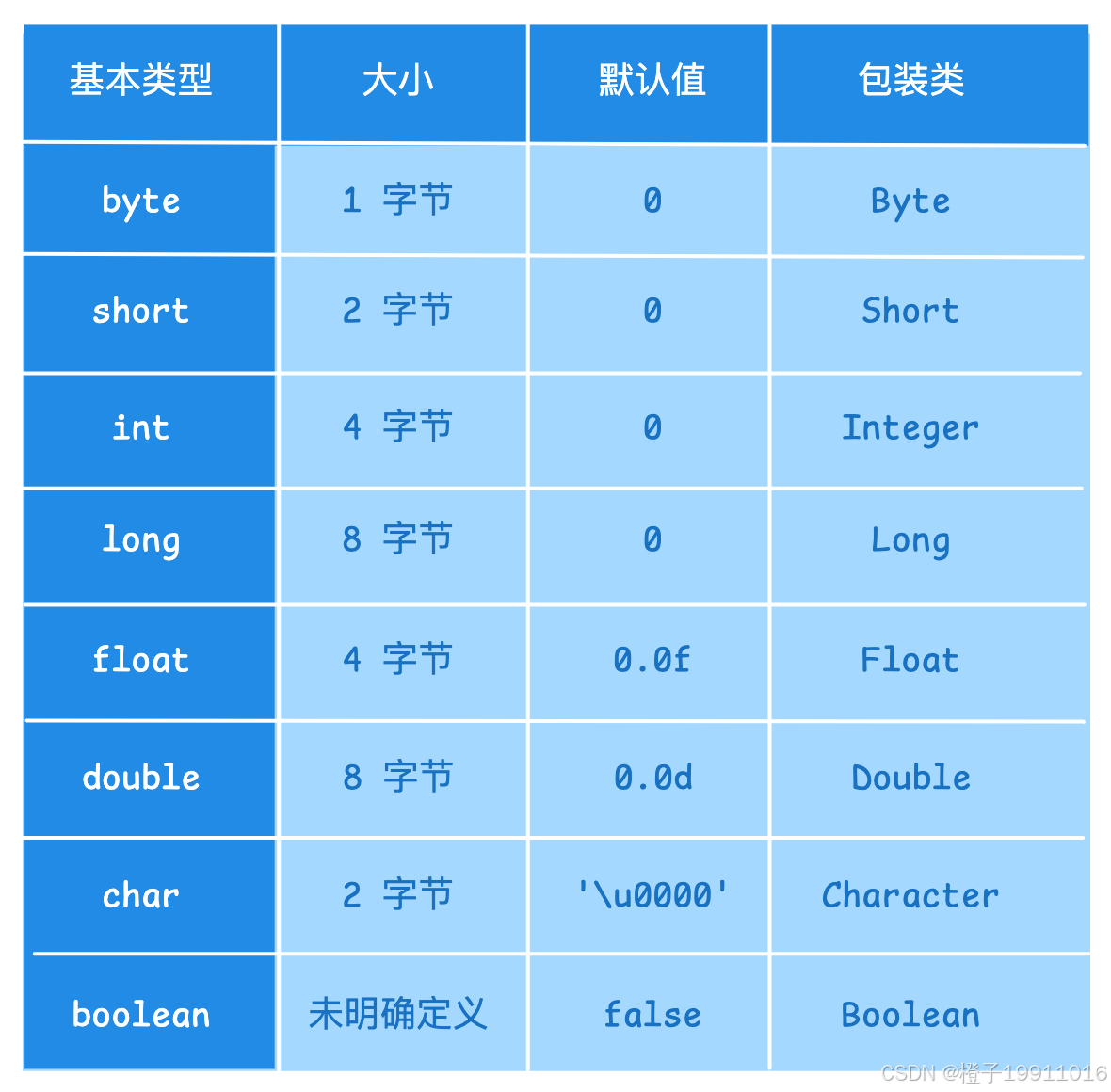
9.1 8 种基本数据类型及其包装类
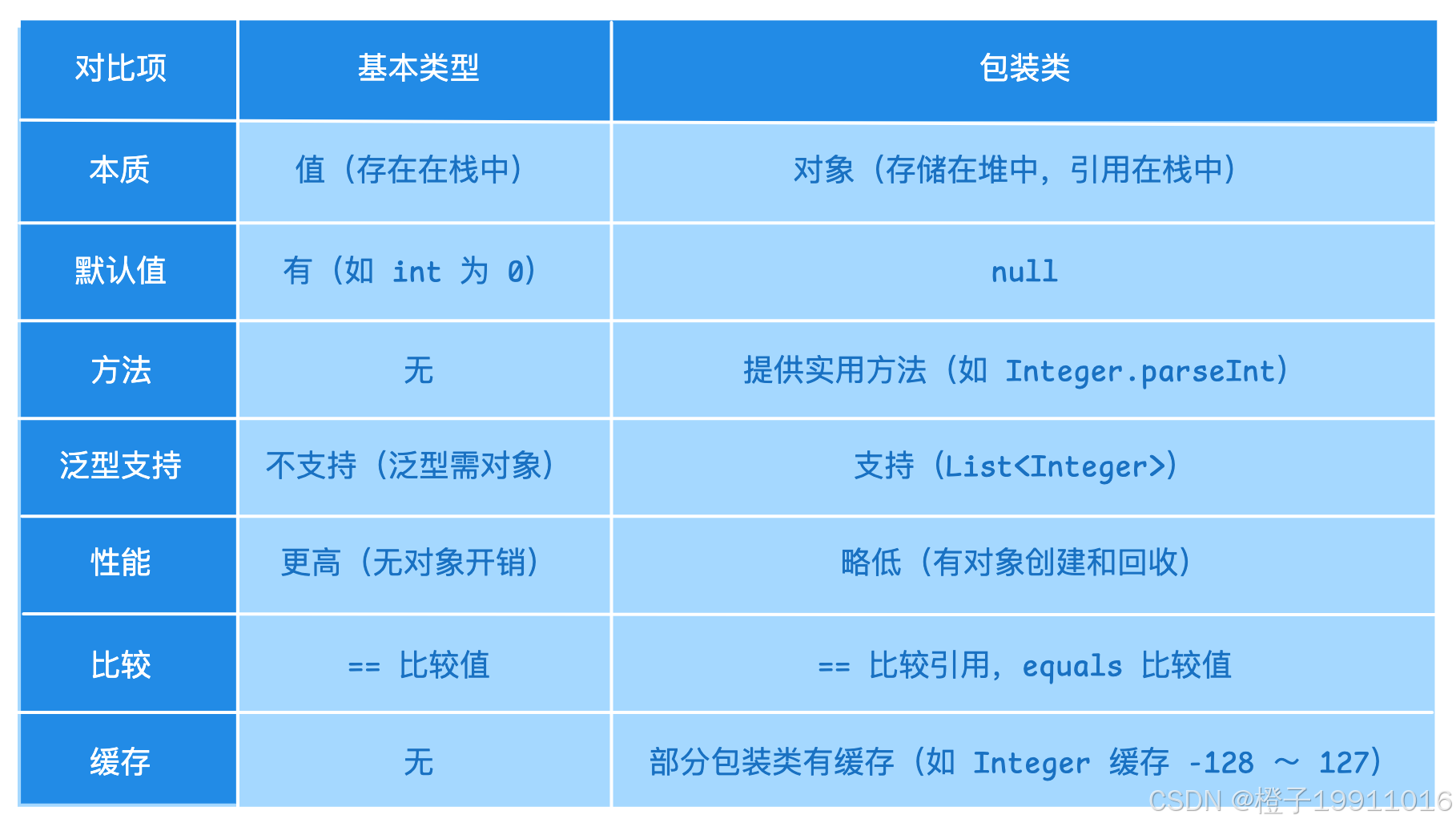
9.2 基本类型 vs 包装类
9.3 自动装箱与拆箱
- 装箱:基本类型 → 包装类(
Integer i = 10;) - 拆箱:包装类 → 基本类型(
int n = i) - 编译器自动插入
Integer.valueOf()和intValue()等代码;
9.4 总结
- 基本类型存值在栈,性能好,无方法;
- 包装类是对象在堆,可为 null,支持泛型和工具方法;
- 包装类有缓存(Integer-128 \~ 127);
10 自动装箱与拆箱原理
10.1 定义
- 装箱: 将基本类型自定转换为对应的包装类对象;
- 例:
Integer i = 10→ 编译器调用Integer.valueOf(10);
- 例:
- 拆箱: 将包装类对象自动转换为对应的基本类型;
- 例:
int n = i→ 编译器调用i.intValue();
- 例:
10.2 底层原理
编译期处理: Java 编译器在生成字节码时,自动插入相应的 valueOf()(装箱)和 xxxValue()(拆箱)方法调用。
java
Integer i = 100; // 装箱 → Integer.valueOf(100)
int n = i; // 拆箱 → i.intValue()10.3 缓存机制
- 某些包装类(Integer、Byte、Short、Long、Character、Boolean)内部维护了缓存池;
- Integer 缓存范围:-128 ~127;
- 原理:
Integer.valueOf(127)返回缓存中的对象,多次调用得到同一对象;Integer.valueOf(128),每次都new新对象; - 注意:缓存只对
valueOf()有效,new Integer()始终创建新对象(已废弃);
10.4 常见陷阱
==与equals:包装类比较时,==比较引用(可能受缓存影响),equals比较值;- 空指针异常:包装类为
null是自动拆箱会抛出 NullPointerException; - 循环中装箱:频繁装箱会创建大量对象,影响性能,应优先使用基本类型;
10.5 总结背诵
- 装箱:基本类型 → 包装类,底层调用
Integer.valueOf(); - 拆箱:包装类 → 基本类型,底层调用
intValue(); - 部分包装类使用缓存池(如 Integer -128 ~ 127)优化性能,缓存范围外
new对象;
11 Java 中深拷贝和浅拷贝的区别
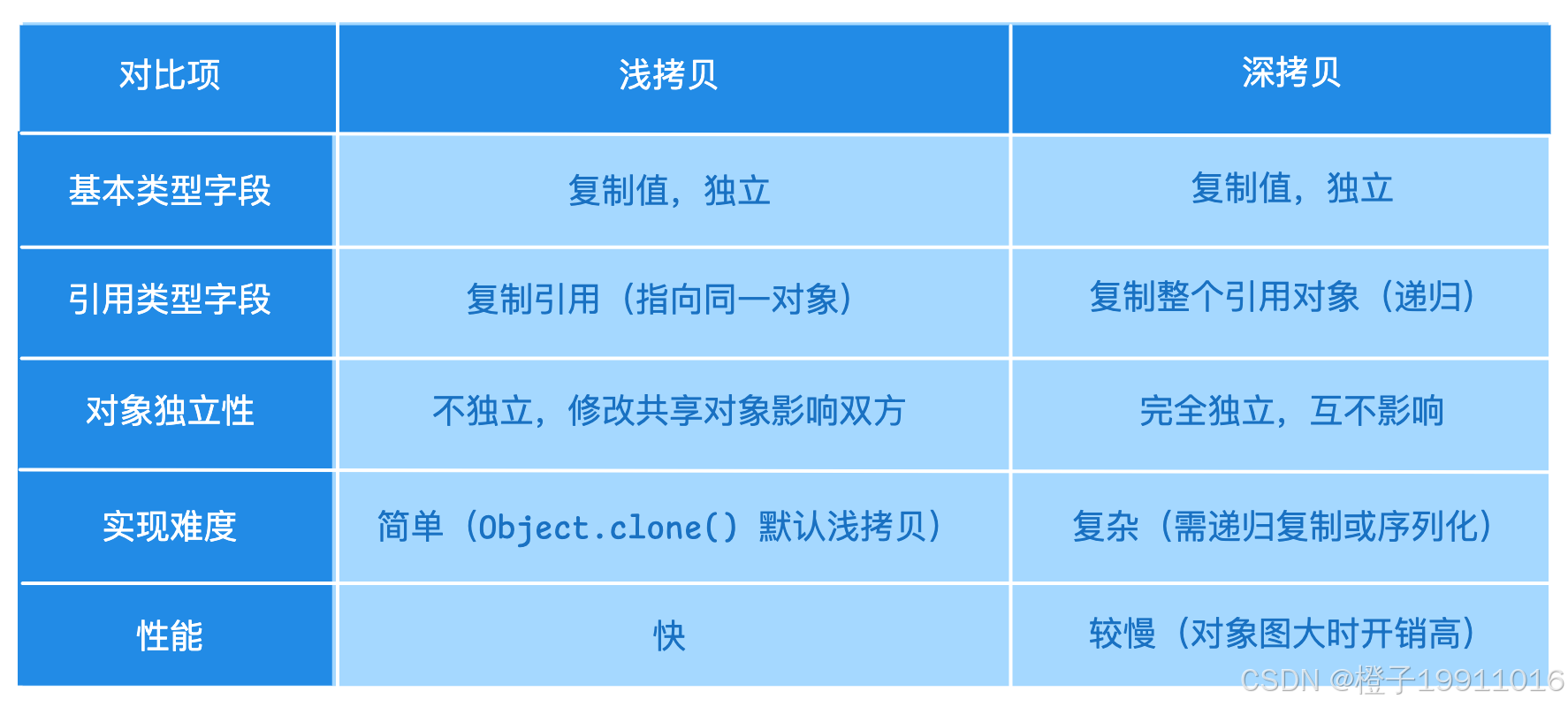
11.1 定义
- 浅拷贝: 复制对象时,只复制基本类型字段和引用类型的地址(不复制引用对象本身)。新旧对象共享内部引用对象;
- 深拷贝: 复制对象时,不仅复制基本类型字段,还复制引用类型所指向的对象(递归复制)。新旧对象完全独立;
11.2 区别对比
11.3 如何实现深拷贝
- 重写
clone()方法:手动为每个引用类型字段调用其clone()方法,且所有相关类需实现 Cloneable 接口; - 序列化:将对象写入字节流再读回(需实现 Serivalizable),简单但性能较低;
- 拷贝工具库:如 Apache Commons Lang 的
SerializationUtils.cone()、Gson 等 JSON 转换后重建;
11.4 示例(Java 浅拷贝 vs 深拷贝)
java
// 浅拷贝:clone() 默认行为
Person p1 = new Person("张三");
Person p2 = p1.clone(); // p2 和 p1 共享引用字段
// 深拷贝(序列化方式)
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(p1);
ObjectInputStream ois = new ObjectInputStream(new ByteArrayInputStream(bos.toByteArray()));
Person p3 = (Person) ois.readObject();11.5 总结
- 浅拷贝只复制引用地址,新旧对象共享内部对象;
- 深拷贝递归复制所有引用对象,新旧对象完全独立;深拷贝可通过重写
clone或序列化实现;
12 异常体系:Error 和 Exception 区别
Java 异常体系顶层为 Throwable,其下分为 Error 和 Exception。
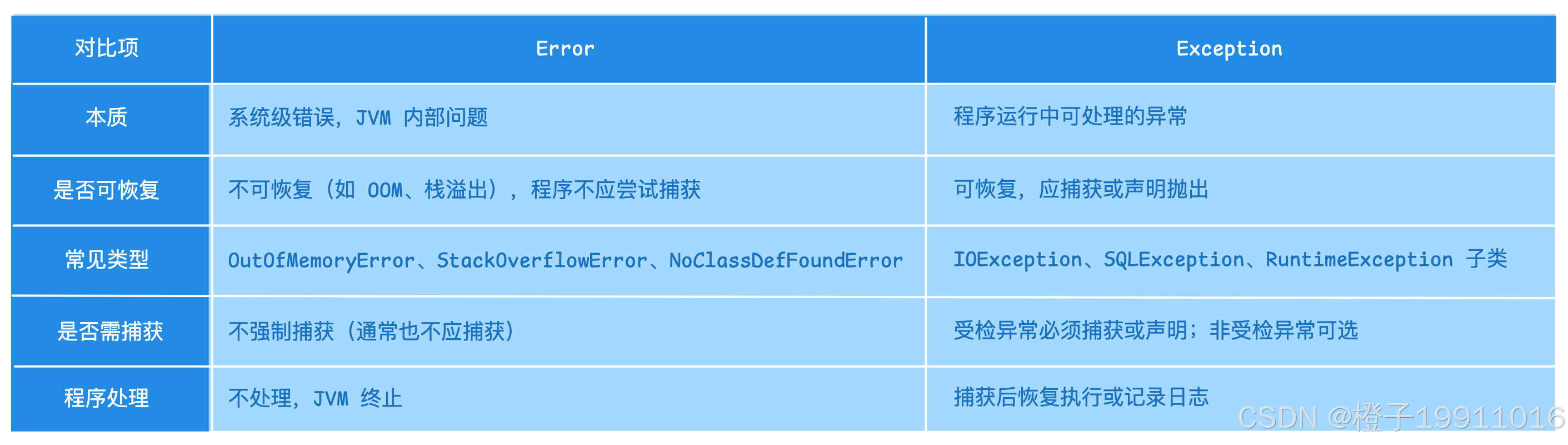
Exception 细分:
- 受检异常(Checked Exception): 编译时需处理(
throws或try-catch),如 IOException、SQLException; - 非受检异常(Unchecked Exception): 运行时异常,继承 RuntimeException,编译不强制处理,如 NullPointerException、IllegalArgumentException;
总结:Error 表示 JVM 内部严重错误,程序无法恢复;Exception 表示程序可处理的异常,分为必须显示处理的受检异常(如 IOExcption)和可不处理的非受检异常(如 RuntimeException)。
13 谈一谈 Java 成员变量、局部变量和静态变量的创建和回收机制
13.1 三类变量的存储位置
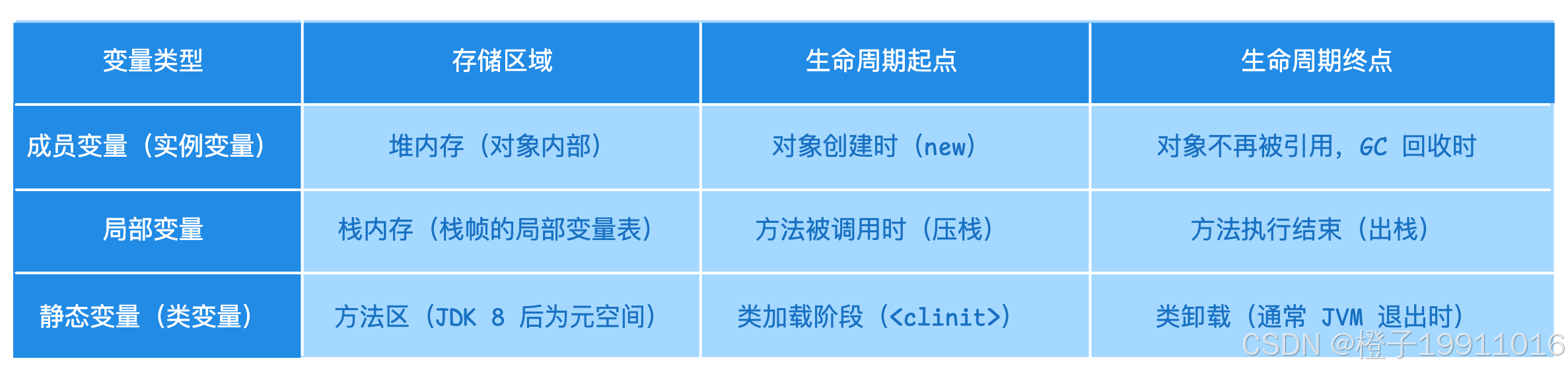
13.2 创建机制(时机与初始化)
- 成员变量: 随对象创建(
new)在堆中分配内存,并自动赋默认零值(整型 0,布尔 false,引用 null),然后执行构造器中的显式赋值或代码块赋值; - 局部变量: 在方法被调用时,在栈帧的局部变量表中分配空间,必须显式初始化后才能使用(编译器强制),否则报错;
- 静态变量: 在类加载的准备阶段分配内存并赋予默认零值,在初始化阶段(
clinit) 执行显式赋值或哦静态代码块;
13.3 回收机制(销毁)
- 成员变量: 当对象不再被任何根(GC Roots)引用,对象成为垃圾,GC 会回收堆内存,成员变量随之被回收;
- 局部变量: 方法调用结束,对应的栈帧被弹出,局部变量表直接销毁,无需 GC 参与(栈内存自动管理);
- 静态变量: 生命周期与类相同。类未被卸载时,静态变量一直存在(可能造成内存泄漏)。类卸载条件苛刻(自定义类加载器且无引用),普通应用静态变量会随 JVM 退出而释放;
13.4 补充要点
- 局部变量可声明为
final,但不会有独立于方法外的生命周期; - 静态变量属于类,所有实例共享;成员变量属于对象,每个实例独立;
- 大量静态变量或大对象被静态引用会导致内存泄漏(无法回收);
13.5 总结
- 成员变量随对象创建于堆,GC 回收;
- 局部变量随方法栈帧创建与销毁;
- 静态变量随类加载与方法区,类卸载时才回收;
14 分别讲讲 final、static、synchronized
14.1 final 关键字
作用:
- 修饰类: 该类不能被继承(如 String、System);
- 修饰方法: 方法不能被重写(但可被重载);
- 修饰变量: 变量成常量,基本类型值不可变;引用类型指向的对象地址不可变,但对象内容可变;
细节:
final成员变量必须在声明、构造器或代码中显式赋值;final局部变量只需在使用前赋值;final参数不能修改;- 编译时常量(
static final基本类型或 String)会被 javac 内联优化;
底层:
- JVM 通过常量池和字节码指令(如
putfield检查)保证不可修改; final方法可能被内联优化;
14.2 static 关键字
作用:
- 修饰变量: 类变量,所有实例共享,内存中仅一份,类加载时初始化;
- 修饰方法: 静态方法,可直接通过类调用,不能访问实例成员(无
this); - 修饰代码块: 静态代码块,类加载时执行,常用语初始化静态变量;
- 修饰内部类: 静态内部类,不持有外部类引用;
- 静态导入:
import static导入静态成员;
细节:
- 静态方法不能被重写,但可以被子类定义同名静态方法(隐藏);
- 静态变量有默认零值,可通过类名访问;
- 静态内部类实例化:
new Outer.Inner();
底层:
- 静态变量存储在方法区(JDK 8 元空间),在类加载的准备阶段分配内存并设默认值,初始化阶段赋真实值;
- 静态方法的调用通过
invokestatic指令;
14.3 synchronize 关键字
作用:
- 实现线程同步,保证同一时刻只有一个线程执行临界区代码;
- 修饰实例方法:锁当前实例(
this); - 修饰静态方法:锁当前类的 Class 对象;
- 修饰代码块:锁指定对象;
原理(JVM 层面):
- 对象头(Mark Word):存储锁状态、哈希码、分代年龄等;
- 锁升级:无锁 → 偏向锁 → 轻量级锁 → 重量级锁(JDK 1.6+);
- Monitor:重量级锁依赖 ObjectMonitor(
_owner、_EntryList、_WaitSet); - 字节码:
monitorenter/monitorexit
特性:
- 可重入:同一个线程可多次获取锁,计数器累加;
- 非公平:不保证线程按等待顺序获取锁;
与 Lock 对比
synchronized自动释放锁,Lock 需手动unlock();synchronized不可中断、无超时、单一条件队列;Lock 更灵活;
14.5 总结
final定义不可变性、static定义类级别共享、synchronized定义线程同步锁;- 三者各司其职,常结合使用(如
static final常量、synchronized static类锁);
15 final、finally、finalize 区别
15.1 final --- 关键字
- 修饰类:不可被继承(如 String);
- 修饰方法:不可被子类重写;
- 修饰变量:基本类型值不可变;引用类型地址不可变(对象内容可变);
final= "最终",不可改变;
15.2 finally --- 异常处理块
- 作用:与
try-catch配合使用,保证无论是否发生异常,其中的代码都会执行(除非 JVM 退出或当前线程被中断); - 典型场景:释放资源(关闭文件、数据库连接、锁等);
- 注意:
finally块中若抛出异常或执行return,会覆盖try/catch中的返回结果;
15.3 finalize --- Object 类的方法
- 作用:垃圾回收器在回收对象前会调用该方法(JDK 9 起已标记为废弃);
- 特点:对象可以在此方法中自救(重新与 GC Roots 建立引用),但执行时机不确定,性能差,容易引发问题;
- 替代方案:Cleaner 或
try-with-resources替代;
15.4 区别对比表
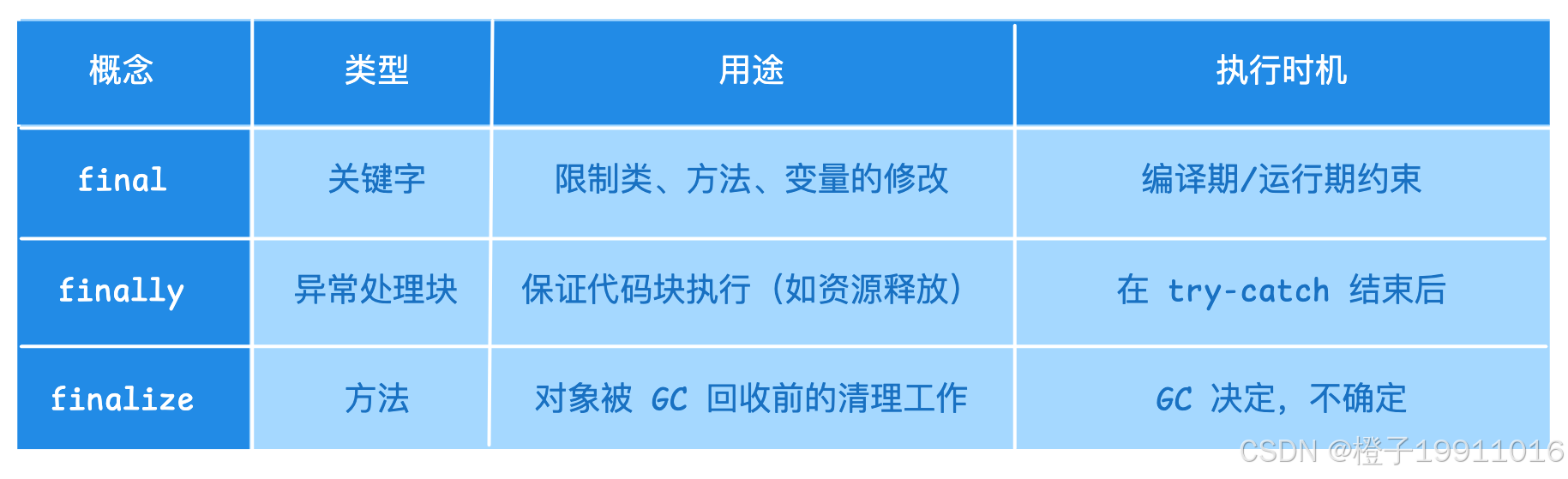
15.5 总结
final 是修饰符(不可变)、finally 是异常处理块(保证执行),finalize 是对象回收方法(已废弃)。
16 String 为什么设计成不可变的?
- 字符串常量池(String Pool)
- 不可变性保证了同一个字符串字面量可以安全地被多个引用共享,而不担心修改影响其他作用。如果 String 可变,常量池机制就无法实现;
- 线程安全
- 不可变对象天然线程安全,无需额外同步,简化并发编程;
- 安全性
- String 被广泛用于类加载、文件路径、网络连接、数据库 URL 等敏感参数。若可变,攻击者可能修改引用指向字符串内容,造成安全隐患(如篡改路径);
- 哈希码缓存(HashCode Caching)
- String 常被用作 HashMap/HashSet 的键。不可变使得哈希码只需计算一次并缓存,提高性能;
- 设计清晰
- String 的不可变配合 StringBuilder/StringBuffer 的可变,职责分明:不变用于共享和常量,可变用于频繁拼接;
17 请简述一下 String、StringBuffer 和 StringBuilder 的区别
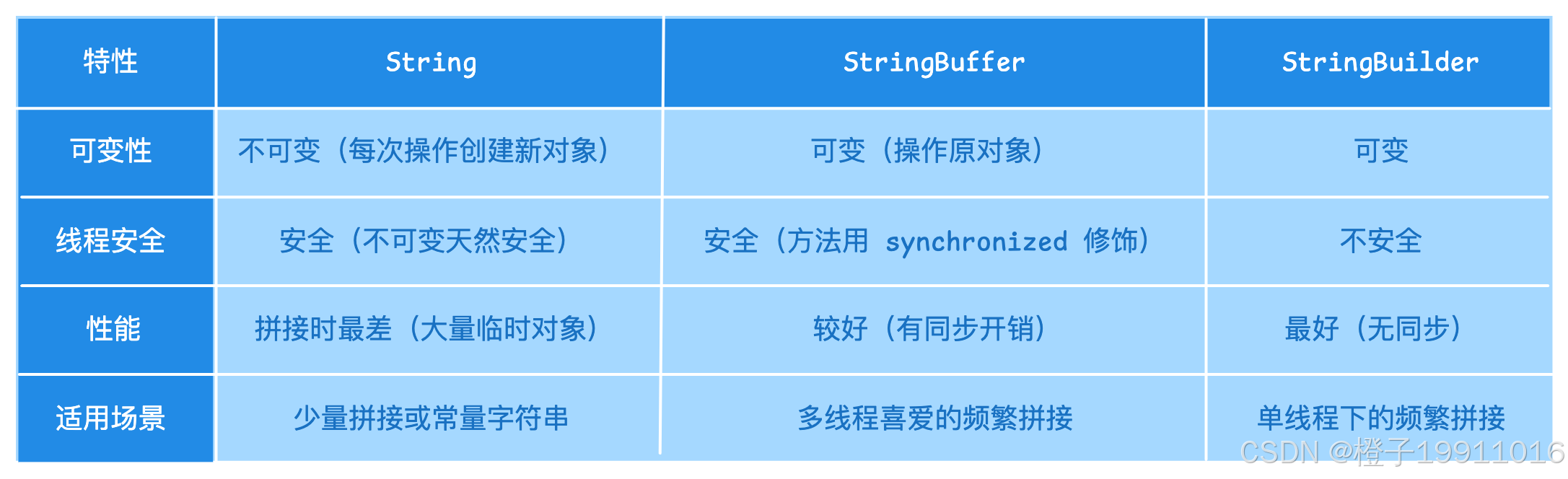
总结:
- String 不可变线程安全,适合少量拼接;
- StringBuffer 可变且线程安全(同步),适合多线程;
- StringBuilder 可变非线程安全,适合但线程且性能最高;
18 请说说 Java 中 String.length() 的运作原理
18.1 底层存储的演变
String.length() 的返回值取决于内部如何存储字符序列。不同 Java 版本的实现有差异。
Java 8 及之前:
- String 内部使用
char[] value数组存储字符; - 每个
char占 2 字节(UTF - 16 编码单元); length()方法直接返回value.length,即字符数组的长度,也就是字符串中 UTF - 16 code unit 的个数;- 时间复杂度 O(1);
Java 9 及之后(Compact Strings):
- 为了节省内存,引入
byte[] value存储,并增加byte coder字段标识编码方式; - 编码方式:
coder == LATIN1:字符串只包含 Latin - 1(ISO-8859-1)字符,每个字符占 1 字节;coder == UTF 16:字符串包含需要 2 字节表示的字符,每个字符占 2 字节;
length()逻辑:- 若
coder == LATIN1,直接返回value.length(字节数等于字符数); - 若
coder == UTF16,返回value.length >> 1(字节数除以 2,即字符数);
- 若
- 仍为 O(1) 操作;
18.2 关键点补充
length()返回的是字符数(UTF - 16 code unit 的数量),不是字节数,也不是 Unicode 码点数量。对于辅助平面字符(如 emoji,占用两个 code unit),length()会返回 2,而codePointCount()返回 1;- 因为 String 不可变,长度在构造时已确定,所以
length()无需动态计算,直接读取字段或简单计算即可; - 该方法为
final,不能被重写;
18.3 总结
String.length() 返回字符串中 UTF - 16 code unit 的数量,底层利用内部数组长度直接或经移位得到,时间复杂度 O(1)。
Java 9+ 通过 Compact Strings 优化内存,但逻辑依然高效。