安装Filebeat,注意版本尽可能要和Elasticsearch 的版本一致
javascript
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.12.1-linux-x86_64.tar.gz
tar -xzvf filebeat-7.12.1-linux-x86_64.tar.gz
mv filebeat-7.12.1-linux-x86_64/ filebeat-7.12.1修改配置文件
1.开启输入
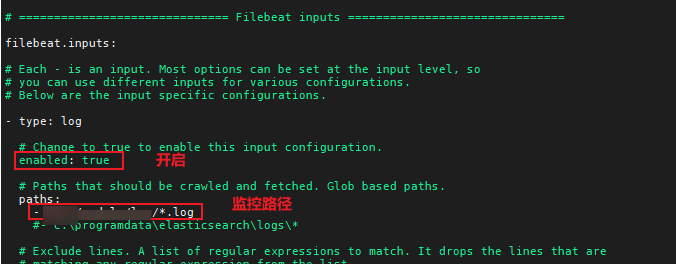
2.指定输出ES
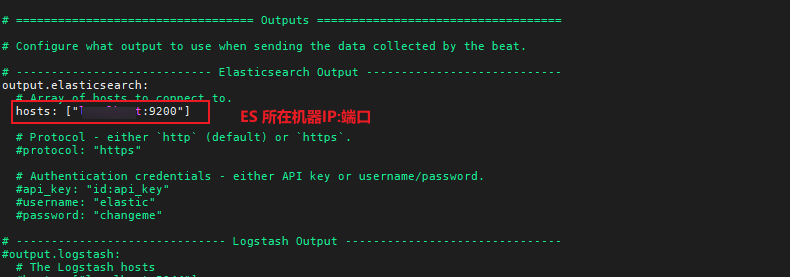
ES多节点配置
javascript
output.elasticsearch:
hosts: ["192.169.208.111:9200", "192.169.208.112:9200", "192.169.208.113:9200"]
loadbalance: true # ← 默认就是 true,可省略查看配置是否正常
javascript
./filebeat test output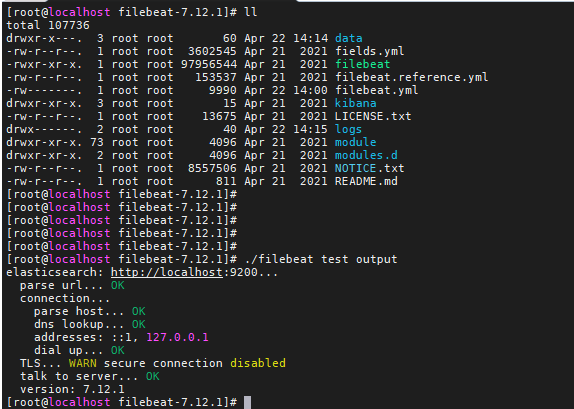
补充:filebeat.yml 生产级配置
javascript
filebeat.inputs:
- type: log
enabled: true
paths:
- /opt/module/log/1.log
# - /path/to/your/other/*.log <-- 可以在这里加更多文件
# --- 核心:多行合并 (Multiline) ---
# 1. 正则:匹配 Logback/Spring Boot 的标准时间头
# 格式:2026-04-22 16:02:06
# 解释:^表示行首,\d{4}表示年份,确保只有新的一行日志才会被识别为"开始"
multiline.pattern: '^\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}'
# 2. 策略:negate (取反)
# 解释:如果一行 **不符合** 上面的时间格式(比如它是 "at com..." 或者 "Caused by..."),
# 那么它就不是新日志,而是旧日志的一部分。
multiline.negate: true
# 3. 方向:after
# 解释:把那些"不是新日志"的行,追加到上一行的末尾。
multiline.match: after
# 4. 兜底保护
# 防止某个异常堆栈有几万行导致内存溢出,生产环境建议设置上限
multiline.max_lines: 500
# --- 额外优化:处理容器日志换行 (可选) ---
# 如果你的日志是 Docker/K8s 打印出来的,有时候会被截断成很长的行,
# 可以开启这个来合并被物理截断的行(通常以空格结尾)。
# multiline2.pattern: '.*\s$'
# multiline2.negate: true
# multiline2.match: after