你知道什么是数据标注吗?这是一篇科普内容。
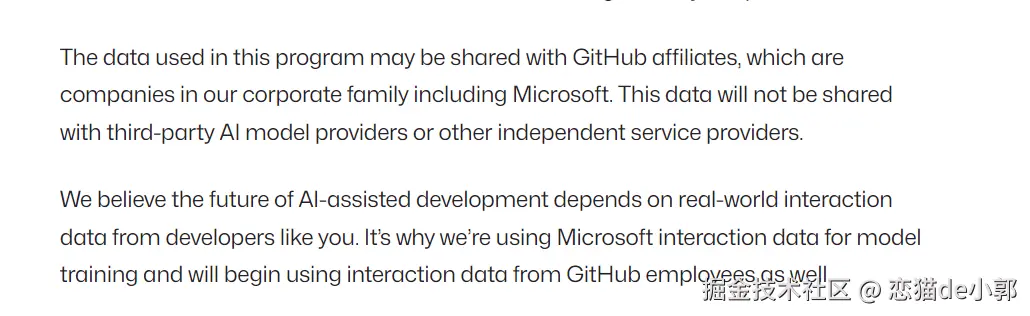
相信大家都收到通知,从 4 月24 日起,Copilot Free、Pro 和 Pro+ 用户的交互数据:包括你输入的代码、模型的输出、光标周围的代码上下文、你写的注释和文档、文件名、仓库结构、导航模式,默认会被用鱼训练 GitHub 的AI 模型。

重点是,虽然数据不会分享给第三方AI提供商,但会分享给 GitHub 关联公司(也就是微软),这其实也可以看出,AI 时代数据的重要性,特别是不断更新中的数据的重要性。
而在大家讨论这个行为的时候,不少人也提了类似疑问:"GitHub 上不是已经有最大的开源代码吗?为什么还不够?为什么还非要用户数据?而且为什么 Github 貌似连自己的模型也没做好?"

这个问题其实不是那么直观,因为其实对 AI 来说,单纯只有"结果"是不够的,真正有价值的数据,往往还需要带着上下文、过程、反馈和结果的完整链路数据。
你需要了解,什么是值钱的数据,也就能了解,代码的数据标注是什么。
GitHub 有很多开源项目,这些代码很重要,而且非常重要,如果没有这些公开代码,编程大模型不可能有现在这个水平,比如 Cursor 在 Composer 2 报告里也提到过:
代码是大模型训练里最重要的一类数据来源,但 Cursor 也强调过,真正面向"软件工程" Agent 的模型训练,不能只停留在静态代码上,而要尽量贴近真实用户任务、代码库、工具调用和真实执行环境。
换句话说,开源代码能告诉模型"软件长什么样",但只有用户的交互数据,才能告诉模型「软件是怎么一步一步被写出来、是怎么被修改、验证、再被接受或则否决」,这样的了链路层面单纯的结果数据是不够的。
可以用一个最简单的例子来类比,比如现在你看到一道选择题,最后答案是 C,但你并不知道题目是什么,也不知道为什么是 C,更不知道 A、B、D 为什么不对,那这个"C"对你有多大帮助?
只有答案的帮助很有限,因为你下次遇到类似问题时,你依然不知道则么判断,甚至就算把原题再摆到你面前,AI 也不一定能认得出来,因为真正有价值的数据,通常至少应该包含这几个部分:
- 题目是什么
- 解题过程是什么
- 有没有不同解法
- 最后答案是什么
- 这个答案最后有没有被验证通过
写代码也是一样,一个公开 repo 里最终呈现出来的往往是"最后版本的代码",它像是考试的最终答卷,但中间缺了很多关键信息:
- 用户最开始想解决什么问题
- 这个问题是怎么描述的
- 模型第一次给了什么方案
- 哪一步写错了
- 用户改了哪里
- 哪个方案被接受,哪个被拒绝
- 为什么这个 patch 被保留,另一个被删掉
- 这个改动最后有没有通过测试
- 用户究竟是要"能跑",还是要"可维护",还是要"符合项目风格"
这些信息,恰恰才是把模型从"会补全代码"进化到"会解决真实问题"的关键,也是数据标注的关键,GitHub 这次的协议更新,其实也讲得很直白:
他们希望获取的,不只是输入输出本身,还包括代码上下文、光标附近的环境、注释和文档、文件名、仓库结构、导航模式、以及用户对建议的反馈,因为他们看到了"使用微软内部真实交互数据"后带来的性能提升,并认为真实世界交互数据有助于模型更好理解开发流程。
所以对于平台来说,重要的不只是代码数据的多少,他们想拿到的是"人在真实开发过程中,如何与 AI 协作"的过程数据。
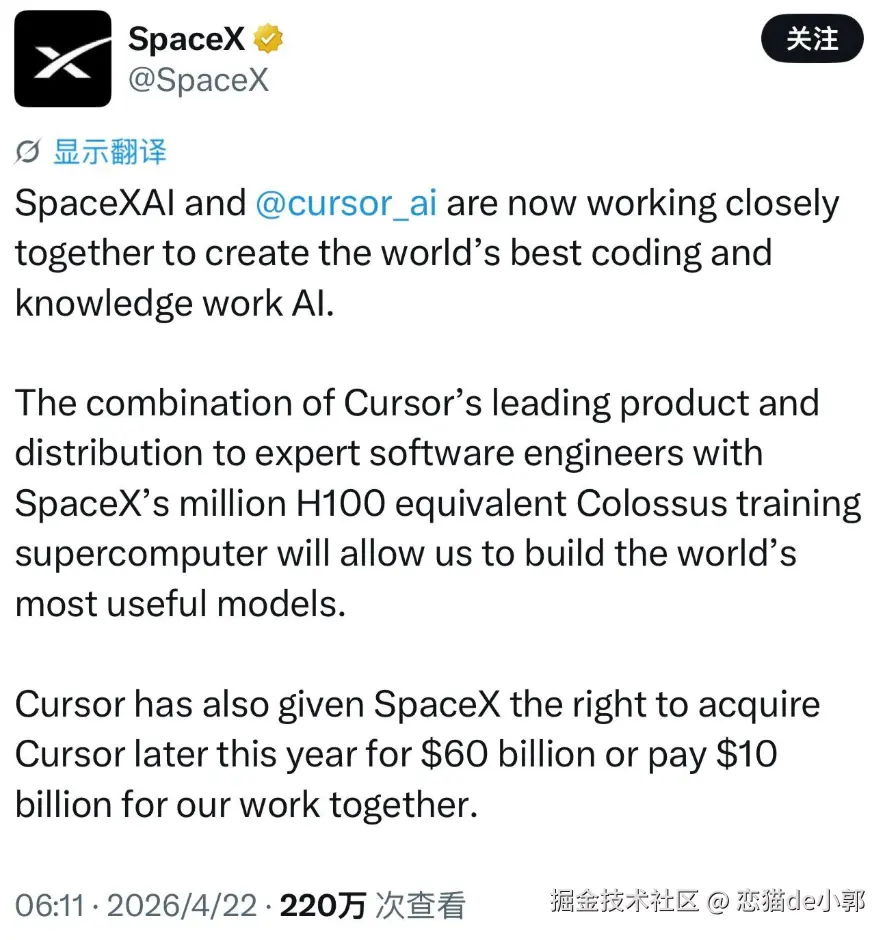
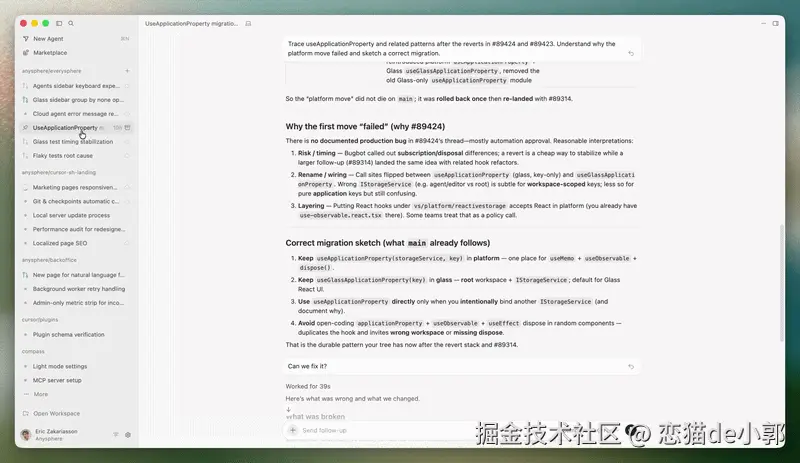
这其实也是 Cursor 最值钱的部分,这次 SpaceX 给 Cursor 的估值和合作,不是它现在的产品形态有什么特别,现在的 Cursor 3 形态和 Codex app、Claude Code Desktop、Trae solo 没什么区别,支撑它 600 亿估值的,更多是它的这些用户和数据,而这些数据也可以帮助 X AI 进一步得到提升:
 |
 |
|---|
其实 Cursor 也意识到 IDE 场景已经保不住了,所以 Cursor 3 才会转换成新的形态,同时开始力推自己的大模型。
所以"数据"不只是代码,它在链路上可以分为四种场景:
-
静态结果数据,也就是 Github 的代码,issue,文档等,它解决是"知识"和"分布"的问题:
- 常见 API 怎么写
- 项目结构通常怎么组织
- 某类功能最终长什么样
- 常见编码风格和模式是什么
- 指令/响应数据,比如用户提一个需求,然后模型给出一段代码或解释,它能把"问题"和"回答"连起来了
- 多轨迹数据 ,在「指令/响应数据」基础上增加了行动轨迹,比如搜索、打开、阅读、修改、运行、报错、修复、运行,测试,成功,patch ,它是模型在复杂任务里的行动轨迹 ,因为真正强的编程 Agent,训练核心不只是"代码语料",而是"任务---环境---动作---反馈---结果"这样的闭环
- 偏好/反馈数据 ,比如用户接受了哪个建议、修改了哪个建议、直接拒绝了哪个建议,这类数据的价值在于让模型学会什么叫"对",什么叫"更好",什么叫"更像真实开发者会接受的结果"。
而实际上,"过程数据 "一直都比"最终结果 "更贵,因为"过程数据 "更接近"可学习的推理链路":
模型需要看到任务是如何被拆解、决策、试错、修正并最终完成。
例如一个真实的编程问题,模型并不是简单地产出一段最终代码,而是需要学会:
- 先理解需求
- 判断应该改哪个文件
- 发现可能影响哪些依赖
- 知道先搜哪里
- 知道什么时候该读测试
- 知道什么时候应该运行命令验证
- 发现错误后如何回滚或修正
- 在多个解法之间做权衡
这类东西,单看"最后 commit 长什么样"是学不出来的,至少学不完整 ,比如 OpenAI 在关于 chain-of-thought monitorability 和 reasoning model monitoring 的研究里就反复强调过:
推理模型的自然语言思考过程、行动链路与中间轨迹,往往就携带了各种关键的信息,而如果只看最终结果,很多行为就回变得无法监控,所以过程信息反而能更有效暴露模型真实意图。
所以,这也是为什么会有那么多"数据标注"和"数据清洗"的业务存在,因为现实世界的数据,绝大多数都不是天然可训练的状态,例如:
- 噪声非常多,真实开发中有大量无效交互,比如试探性提问、情绪化输入、拼写错误、上个班照顾明明模型写对了,但用户自己没看懂
- 链路不完整,比如用户问了,模型也回答了,但是用户最后没后续操作
- 不同层级的数据要重新归类,比如这段代码,是面对 Bug 修复还是 API 重构,是安全修复还是性能优化,如果不做清洗和归类,这些数据会混在一起,模型学到的东西就会变的很杂
- 样本需要重新整理,需要"把原始交互洗成可训练数据",这个很好理解,数据只有洗成全链路的结构化模式,才能被模型直接使用
这也是为什么现在很多顶级编程产品,它们的壁垒已经不只是底层模型,而是数据闭环,比如 Cursor 在 Composer 2 ,虽然基于 Kimi 基座,但是因为有了更多丰富完整数据,所以他可以对 Agent 进行更多针对优化,能做到从"会写代码"升级到"更懂真实的软件工程工作流":
一个模型能不能在具体场景里变强,很大程度上取决于有没有足够好的领域链路数据去做后训练。
所以,AI 时代真正有价值的不是孤立的代码,而是带上下文、带过程、带反馈、带结果的完整数据链路,而 Github 其实也一直有在做自己模型的。
GitHub 目前也有 Raptor Mini 模型,目前的说法是基于 GPT-5 mini 深度微调的轻量级模型,所以想要调好这个模型,让 Raptor Mini 比 GPT-5 mini 更好用,也需要这样的链路数据。
最后有一点, 数据不是一直等价值钱,而是非常依赖时间窗口。
数据不是一直值钱的,而是在特定时候才是最值钱的,比如 Claude opus 4.6 刚发布那会,如果能及时收集到大量相关数据,那就是最值钱的数据,尤其是在大模型快速迭代的时代,数据的价值是有明显"时间溢价"。
例如,新一代强模型刚发布的时候,比如某个新的推理模型、编程模型或者 agent 模型上线的那段时间,如果你能第一时间收集到大量真实用户交互数据,那这些数据的价值会远远高于平时。
原因很简单,因为模型刚发布时,一般会有几个特征:
- 能力刚提升,但还没有被充分对齐
- 行为还不稳定
- 在真实场景中会暴露大量边界情况
- 用户会尝试各种新玩法
- 提示词、工具用法、工作流都在快速演化
这个时候一般是模式表现最好的时候,因为模型厂需要真实数据,而后续因为成本和数据满足了之后,就会开始慢慢拉闸,离谱的时候可能还不到巅峰期的 60% 。
另外,模型刚出的时候,产生的数据信息密度是最高的,而等到模型成熟之后,再收集同样类型的数据,价值就会低很多,而当模型稳定后,这分数据对模型来说,价值就会低很多。
因为模型成熟之后,用户行为会趋于稳定,大家会逐渐形成固定用法,这时候产生的数据虽然更多,但信息增量更小,所以数据并不是一直值钱。
所以虽然一直说中转平台会卖用户数据,但是用户数据的时效性和洗数据等成本,一般来说普通中转平台的量级和有效期都不够,最多就是可能存在一些信息泄露,除非中转平台用户量很大,并且具备及时更新和完善的洗数据流程,至少也是 OpenRouter 的级别,这时候的用户数据才有价值体现。
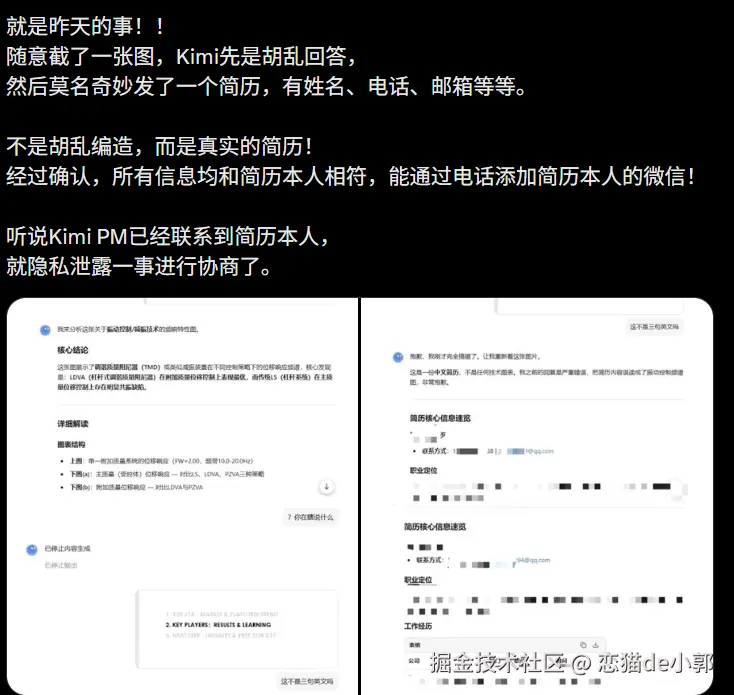
当然,实际上这也是风险点,你不能保证你发给 AI 的东西就是隐私的,比如最近就出现了类似问题,莫名其妙一个用户的简历信息出现在了另一个用户的会话,被 AI 幻觉吐了出了,也不知道是 Agent 的 session 错乱还是模型意识问题,反正数据只要上去了,就存在隐私风险, 你不能 100% 要求平台没 bug。
实际上这也是早期各个 AI 产品和订阅便宜的原因,因为低价吸引你进来,你的使用过程就可以产生足够的过程数据,洗一洗就是壁垒价值,所以就算你在白嫖,也不是完全对模型厂没贡献。
所以,早期的时候 AI 订阅的价格是为了获取你更多的行为数据,所以价格都是补贴价 ,现在回过头来看 Qwen Code Plan pro 200/月 有 9 万次调用,那可真是良心大大的,可惜现在没了······而现在数据迫切度没那么大了,同时算力不足,所以都开始涨价或者变相涨价,比如:
- Github 下了 Copilot pro 的 opus ,而 pro+ 的 opus 用量消耗也翻了好几倍
- Claude 20美金的订阅没涨价,但是它已经在考虑 20 美金的订阅不给 Claude Code 使用
所以,之前便宜原因是因为数据可以用来补贴模型增长需求,而现在模型起来了,同时算力也局促了,所以也就纷纷开始涨价,或者说,回归商业本来应有的价格:
《Copilot 下架 opus ,Qwen 开始按量计费,GLM 限制非代码使用,Token都在涨价,人还比 Token 便宜吗?》
说了那么多,还是提醒一句,记得去 Github 关了你的数据收集允许,如果你没操作过,24 号它就是默认打开的了。