文章目录
JVM内存区域划分
分为元数据区,堆,栈(Java虚拟机栈、本地方法栈),程序计数器。其中元数据区和堆为线程共享(一个进程中只有一份),栈和程序计数器为线程私有(一个进程中有多份,每个线程单独一份)
实例化对象时:
- 通过元数据区的数据确定类的属性
- 在堆中根据类的属性,实例化对象,并在对象头保存指向元数据区中对应类属性的指针
- 在栈中保存指向堆中对象的指针
元数据区
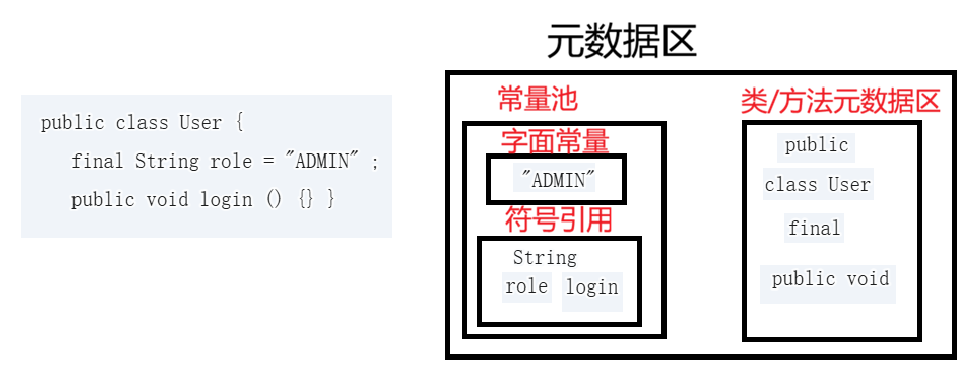
常量池
存放字面量与符号引用
字面量:存放固定值如:字符串、final常量、基本数据类型的值
符号引用 :在编译阶段,JVM并不知道类地址和方法地址,只能使用名称代替。所以这里就存放着类名、方法名、字段名
栈帧中的动态链接 就是将符号引用翻译为真实的内存地址
方法/类元信息
指的是方法/类的属性,包括类名,是否为public,方法的是否有返回值...
堆
程序中创建的对象就保存在堆中,对象头中包含一个指向对应元数据类信息的指针
新生代
伊甸区(Eden Space)
新对象存储在eden区
幸存区(Survivor Space)
当Eden区满了,JVM会触发一次小型的垃圾回收。没有被回收的对象,就会被搬到Survivor区,Survivor区有两个S1和S0。他们交替工作
老年代
- 一个对象经过多次垃圾回收后依然存活
- 特别大的、占用内存极高的对象,比如一个超大的数组
栈
本地方法栈
给非Java语言编写的方法使用的空间,也就是Native方法。通常用于调用底层操作系统级别的功能
Java虚拟机栈
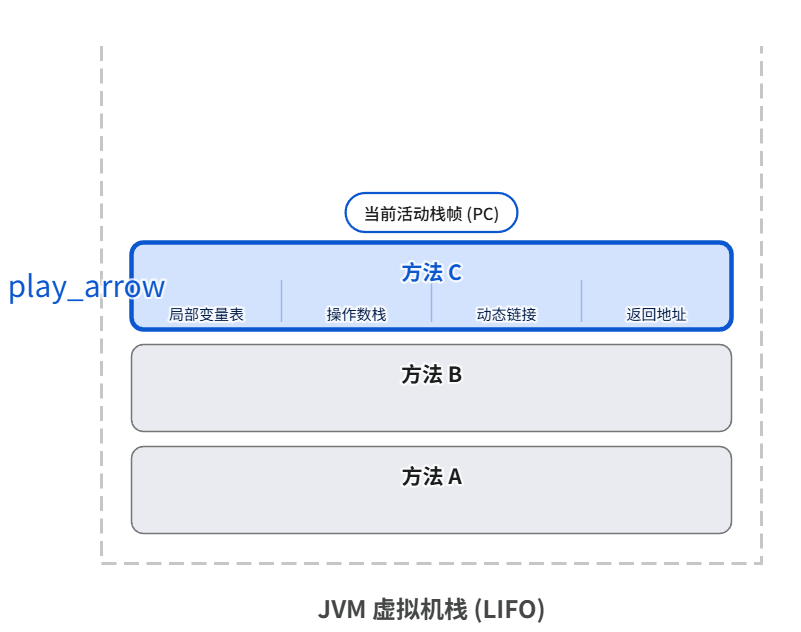
JVM会为每个方法维护一个函数栈帧,用于存放局部变量表,操作栈、动态链接、方法返回地址
- 局部变量表:存放基本数据类型、对象引用
- 操作栈:当方法需要进行加减乘除或调用其他方法 时,就会将局部变量表 中的变量压入操作栈,计算完成后弹出并存回局部变量表
- 动态链接:指向运行时常量池的方法引用
- 方法返回地址:程序计数器的地址
程序计数器
记录当前线程正在执行的虚拟机字节码指令的地址
- 线程私有:JVM会为每个线程都分配一个专属的程序计数器
- 唯一一个不会出现任何OOM的区域
- 如果当前执行的是一个Native方法,那么计数器的值为空
类加载机制
类加载:.class文件转化为内存中的类对象
类加载步骤
-
加载 :找到.class文件,根据类的全限定类名 (包名 + 类名 java.lang.String)打开文件,读取到内存中
-
链接:
-
验证:解析、校验.class文件读到的内容是否符合《Java虚拟机规范》
-
准备:为类中定义的静态变量 分配内存 并设置类变量的初始值(默认值)
如果被
static final修饰,直接初始化为真实值 -
解析:JVM将常量池内的符号引用 替换为直接引用(确切的内存地址),也是字符串赋值的阶段
-
-
初始化 :执行静态变量的赋值 操作和静态代码块
Java程序一旦启动,不是直接加载所有的类,而是用到哪个加载哪个(懒汉模式)
- 构造这个类的实例
- 调用/使用类静态属性/静态方法
- 使用某个类的时候,如果他的父类没有加载,也会触发父类的加载
双亲委派模型
JVM中有个专门的模块负责类加载:类加载器
三种类加载器:
- BootstrapClassLoader:负责加载Java标准库目录
- ExtensionClassLoader(保存BootstrapClassLoader的引用):负责加载Java扩展库目录
- ApplicationClassLoader(保存ExtensionClassLoader的引用):负责加载第三方库/自己写的.class文件
双亲委派的过程(向上委派,向下尝试)
进行类加载,通过全限定类名找.class的时候,就会以ApplicationClassLoader为入口进行加载:
- 进入ApplicationClassLoader,通过保存的ExtensionClassLoader引用,把类加载的任务传递给ExtensionClassLoader
- 进入ExtensionClassLoader,通过保存的BootstrapClassLoader的引用,把类加载的任务传递给BootstrapClassLoader
- BootstrapClassLoader进行类加载,通过全限定类名在Java标准库检索是否有匹配的.class,若没有则委派给ExtensionClassLoader,ExtensionClassLoader也没有最后委派给ApplicationClassLoader
- 如果ApplicationClassLoader也没找到.class文件,则抛出异常
双亲委派的优点
- 保障核心API的安全:当用户写一个
java.lang.String类,JVM并不会加载用户写的类,而是加载标准库中的类 - 保障类的全局唯一性:在JVM中判断两个类是否相等,不仅要判断全限定类名,还要判断加载这个类的类加载器是否是同一个
垃圾回收机制
垃圾回收机制,也称为死亡对象回收机制。Java的堆中存放着几乎所有的对象实例,垃圾回收器在对堆进行垃圾回收之前,首先要判断对象是否存活。
Java四大引用类型
强引用
只要强引用关系还在,GC就不会回收这些对象。写代码中绝大部分都是强引用
java
Object obj=new Object();
String s="Hello";强引用使用完成之后必须手动设置为null,GC才会判断算法回收他
软引用
系统即将发生内存溢出之前,GC会回收软引用指向的对象。如果回收之后内存还是不够,就会抛出OOM异常
java
byte[] bigData = new byte[10 * 1024 * 1024];
// 2. 用软引用把这个大数组包装起来
SoftReference<byte[]> softRef = new SoftReference<>(bigData);
// 3. 必须切断强引用!如果不切断,它永远是强引用,软引用就失去意义了
bigData = null;
//此时就是软引用指向这个数组对象弱引用
GC一旦运行,不管内存空间是否充足,都会将弱引用指向的对象回收
java
// 1. 创建对象并用弱引用包装
byte[] smallData = new byte[10];
WeakReference<byte[]> weakRef = new WeakReference<>(smallData);
// 2. 切断强引用
smallData = null;
//此时就是弱引用指向这个数组对象虚引用
最特殊的引用类型,无法通过他拿到对象 。他的作用是当对象被回收时,进行通知
死亡对象的判断算法
引用计数(python/php)
给每个对象增加一个计数器,当有一个地方引用他时,计数器加一;取消引用则计数器减一。当计数器减为0时,表示给个对象已经死亡
缺陷:
-
需要占用额外的内存资源
-
可能引发循环引用问题
javaclass T{ T t=null } public static void main(Stirng[] args){ T a=new T(); //a计数器:1 T b=new T(); //b计数器:1 a.t=b; //b计数器:2 b.t=a; //a计数器:2 a=null; //a计数器:1 b=null; //b计数器:1 }此时以及无法访问对象a和b,但是ab的计数器没有归零
可行性分析算法(java)
通过一系列GCRoots对象作为起点,从这些节点开始往下遍历对象的引用。当从所有的GCRoots开始,都无法到达某个对象时,那么这个对象就是"不可达",也就是对象死亡
可以作为GCRoots的对象
- 虚拟机栈(局部变量)中引用的对象
- 元数据区中,类静态属性/常量引用的对象
- 本地方法栈中Native方法引用的对象
垃圾回收算法
标记-清除算法
首先标记出所有要回收的对象,在标记完成后统一回收所有标记的对象
缺点:
- 标记和清除两个的效率都不高
- 标记清除后会产生大量不连续的内存碎片。申请内存空间都是申请一块连续的空间,如果内存碎片过多,可能会导致原本有2GB剩余空间,最后连1GB的内存空间都无法申请
复制算法
将内存容量分为大小相等的两块,每次只使用其中的一块。当内存需要进行垃圾回收时,会将此区域存活的对象复制到另一块空间,然后将已经使用过的内存区域一次清理掉
缺点:
- 内存的空间利用率低
- 复制成本有时会很高
标记-整理算法
将所有存活的对象往一边移动,然后清除掉边界以外的内存
分代算法
堆的内存区域分为两份(新生代,老年代)
- 新生代中,每次垃圾回收都会有大量对象死去,只有少量存活。所以对于新生代使用复制算法
- 新生代中的对象经过多次GC依然存活,那么就会被移动到老年代。老年代中的对象存活率高,每次GC只有少量死去,所以使用标记-整理算法
清理掉
缺点:
- 内存的空间利用率低
- 复制成本有时会很高
标记-整理算法
将所有存活的对象往一边移动,然后清除掉边界以外的内存
分代算法
堆的内存区域分为两份(新生代,老年代)
- 新生代中,每次垃圾回收都会有大量对象死去,只有少量存活。所以对于新生代使用复制算法
- 新生代中的对象经过多次GC依然存活,那么就会被移动到老年代。老年代中的对象存活率高,每次GC只有少量死去,所以使用标记-整理算法