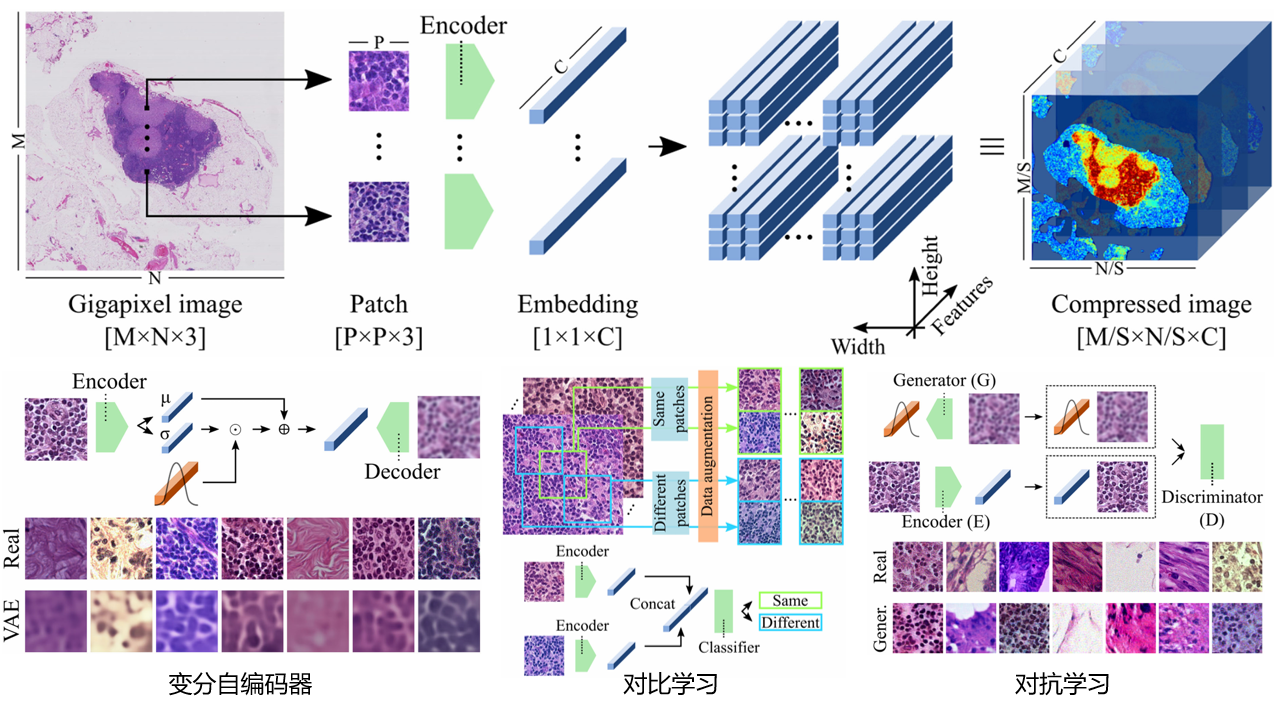
本文以2025年发表在期刊Information Fusion的论文《From patches to WSIs: A systematic review of deep Multiple Instance Learning in computational pathology》为基础,补充最新的论文,论文链接如下:
从切片到全切片图像:计算病理学中深度多示例学习的系统综述 - ScienceDirect --- From patches to WSIs: A systematic review of deep Multiple Instance Learning in computational pathology - ScienceDirect
摘要
病理学临床决策支持系统,特别是那些利用计算病理学(CPATH)进行全切片图像(WSI)分析的系统,由于需要高质量的标注数据集而面临重大挑战。鉴于 WSI 中包含的大量信息,创建此类数据集通常非常昂贵且耗时。多实例学习(MIL)已成为一种有前景的替代方案,它通过融合大规模整体中广泛的局部信息进行粗粒度监督训练,从而减少对昂贵像素级标注的依赖。因此,MIL 已成为 CPATH 中的一个关键技术,推动了相关研究的激增,尤其是在过去五年中。这一不断扩大的研究工作催化了技术创新,为该领域带来了革命性进展,并进一步受到深度学习架构、大规模预训练策略和大型语言模型(LLMs)发展的推动。 本文对深度 MIL 方法的最新发展进行了系统性综述,从多个角度分析了技术进步,包括编码器骨干架构、编码器预训练策略和 MIL 聚合技术。我们全面概述了每个领域的进展,列举了具体的应用场景,并突出了塑造该领域的关键贡献。最后,我们探讨了基于 MIL 的 CPATH 的 emerging research directions 和潜在未来挑战。
一、引言
在临床实践中,对活检和手术切片进行病理评估对于决策至关重要,但耗时且易受主观影响,导致诊断结果不一致。扫描技术的进步提高了全切片图像(WSIs)的质量和可用性,但数字化本身并未显著提升诊断工作流程。计算病理(CPATH)通过使用先进算法分析 WSIs 来解决这些局限性,提高诊断准确性。全切片图像(WSIs)具有高分辨率(可达到100000x100000px)和多尺度特性,需要专家标注------这与减少病理学家工作量的目标相悖。
多实例学习(MIL)已成为计算病理学(CPATH)的一种有前景的方法,它能够在无需细粒度标注的情况下实现各种任务。多示例学习 (MIL) 是一种典型的弱监督学习,其输入的单个样本被称为包 (bag),包中包含多个实例 (instance)。在训练阶段,通常只有包的标签可知,而实例的标签不可知或者获取成本极高。WSI 被划分为多个切片块(patches),这些切片块使用 WSI 级标注进行特征提取和聚合。这使得能够执行分类、结果回归和分割等任务。

通过将 WSI 分解为切片块并在实例级别聚合特征,MIL 能够仅使用粗粒度监督提取高质量的细粒度特征。与传统方法相比,MIL 减少了细粒度标注的需求,能够基于现成的病理报告在 WSI 甚至切片块级别进行预测。
二、CPATH 中 MIL 的基础
CPATH 中的 MIL 流程,包括数据处理、多实例学习方法、下游任务。MIL 方法通常遵循一个两步流程:特征提取和聚合,并应用特定任务的头部来处理特定目标。
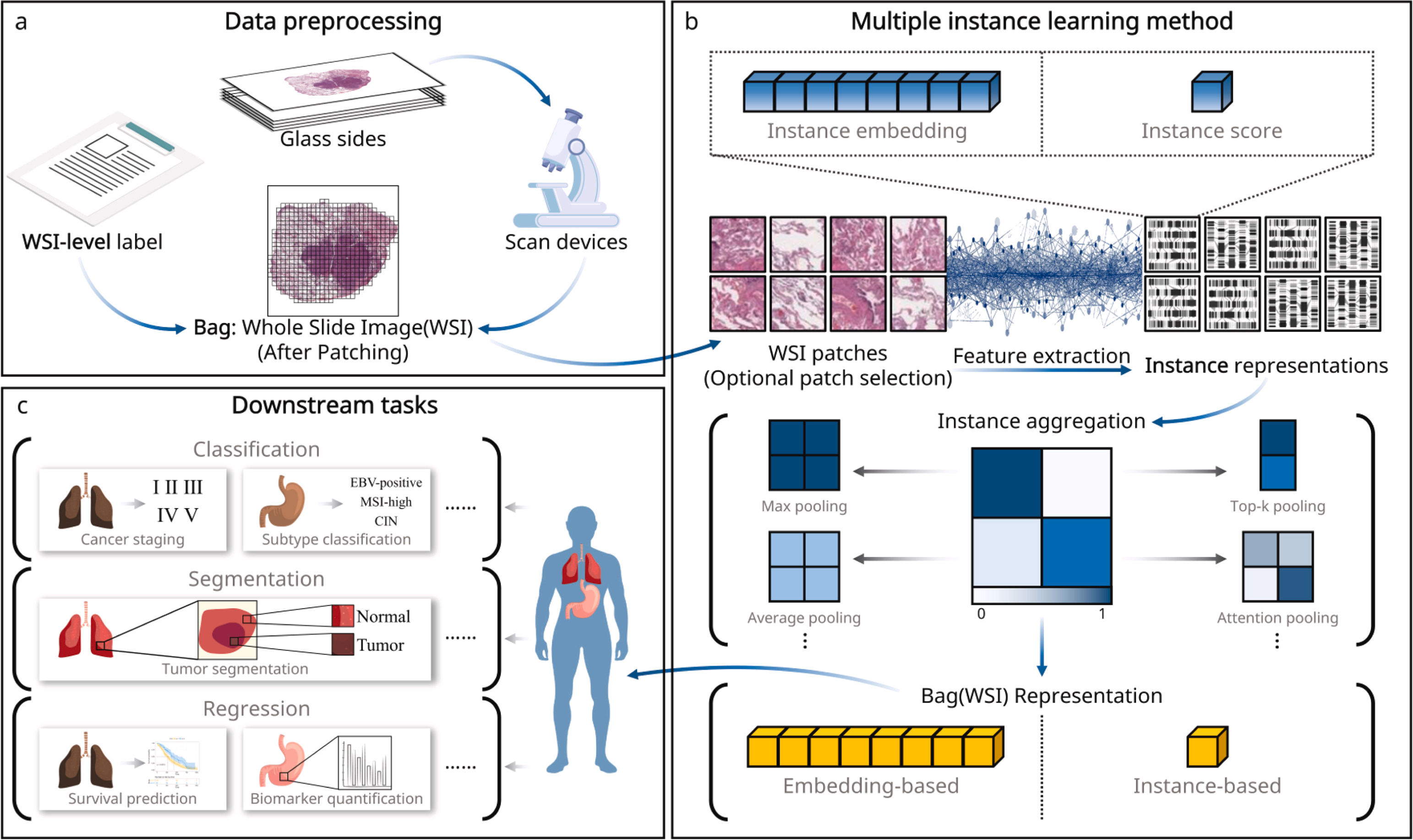
(a)数据处理。考虑一个包含 的 WSI 数据集,这些 WSI 使用扫描设备数字化,包含数十亿像素。相应的 WSI 级标注,由病理学家提供或从病理报告中提取。通常,WSI 中的空白背景区域使用 Otsu 方法或其他前景分割技术进行掩蔽,剩余区域被分割成块,每个块称为一个实例。因此,每个包含 块的 WSI 被表示为一个包。
(b)多实例学习方法 。提取的图像块(包含原始像素值)通过特征提取骨干网络转换为计算机可处理的表示。通常,将图像块转换为单个分数称为基于实例的多实例例学习方法(instance-based MIL approach) ,而将图像块转换为向量称为基于嵌入的多示例学习方法(embedding-based MIL approach)(或基于表示的多示例学习方法)。无论选择哪种多示例学习方法,图像块(实例)表示都会被聚合以形成整个全切片图像(WSI)的综合表示(包)。这涉及定义一种聚合策略,将图像块表示集整合为WSI级别的表示。
 基于实例的多实例例学习方法(instance-based MIL approach)
基于实例的多实例例学习方法(instance-based MIL approach)  基于嵌入的多示例学习方法(embedding-based MIL approach)
基于嵌入的多示例学习方法(embedding-based MIL approach)
(c)下游任务。WSI 表示 有效地捕获了来自数十亿像素的全面信息,可用于分类、分割和回归等各种下游任务。例如,在分类任务中,定义了一个映射函数将映射到标签。
三、近年来 MIL 的发展趋势
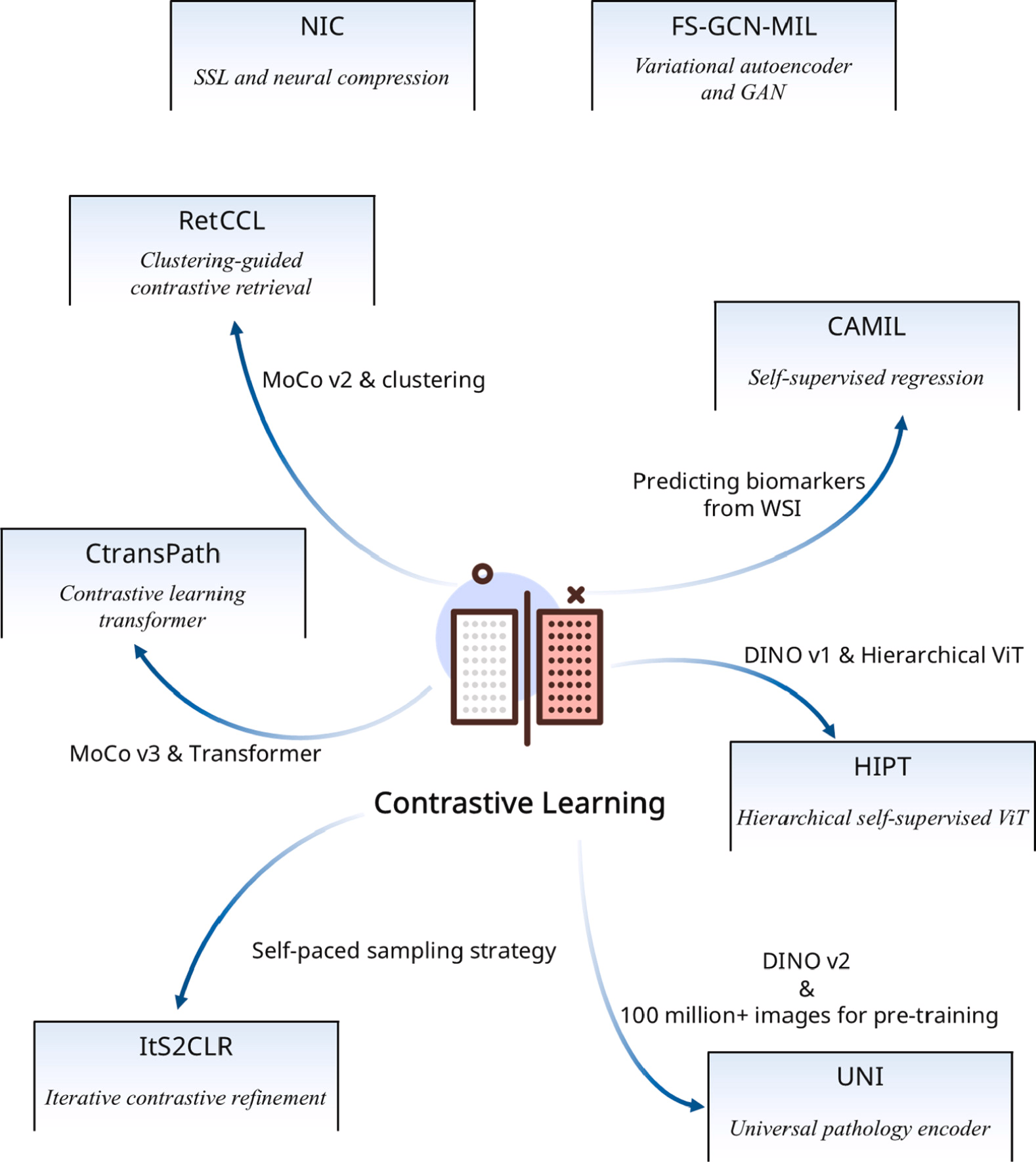
自 2019 年以来,MIL 相关论文的年发表数量显著增加,预计到 2024 年将达到 51 篇,超过了 2005 年至 2018 年间的累计发表数量(50 篇)。值得注意的是,2021 年的发表增长率达到创纪录的 142%,这是过去六年中最显著的增幅。本节将详细分析 2019 年至今(截至 2024 年 7 月 24 日)CPATH 领域 MIL 的发展趋势,涵盖骨干架构、预训练数据集、优化技术、聚合方法和下游任务。这些见解基于对 190 篇论文的全面综述,结果如下图所示。
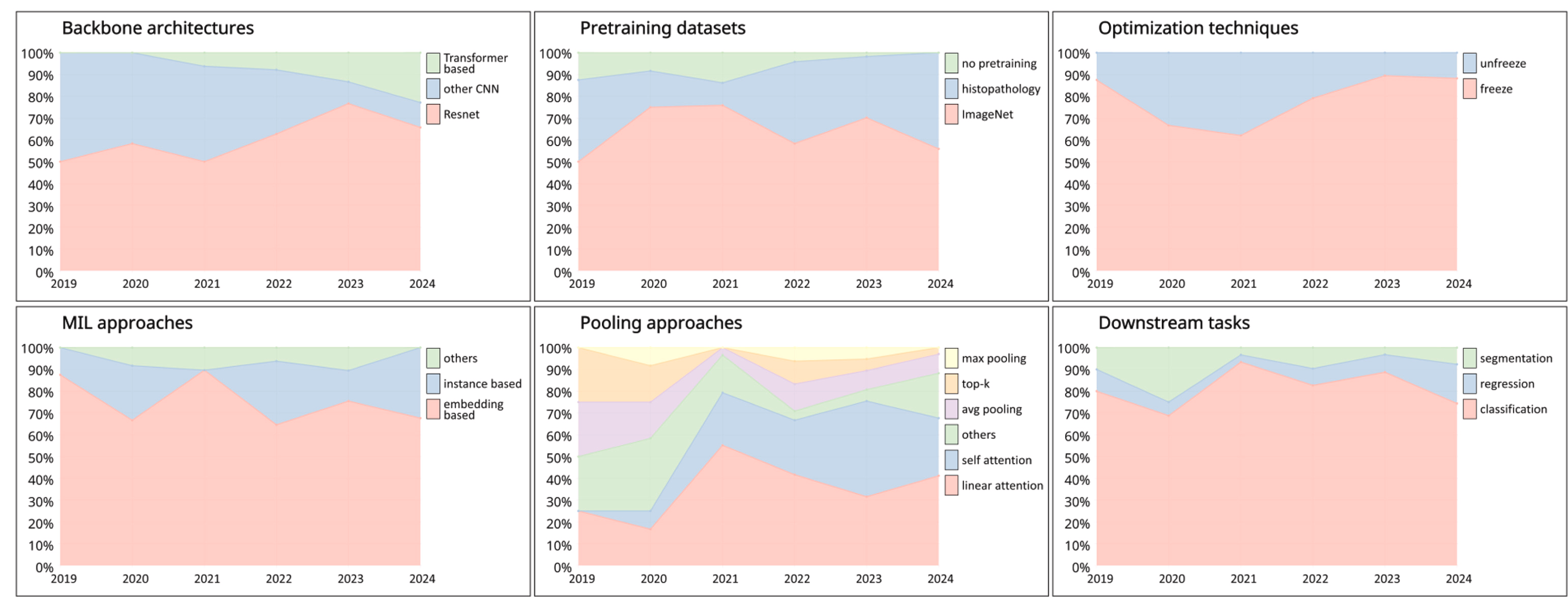
3.1 主干架构
骨干网络架构的趋势如图左上角所示。这项分析突出了研究人员用于图像特征提取的基础方法。结果表明,ResNet 在过去六年中已被用作超过 50%的研究的骨干网络。这种主导地位可归因于 ResNet 在解决网络深度挑战方面的开创性方法,从而能够提取更深层次的特征------这在处理 CPATH 中的数十亿像素全切片图像时是一个关键优势。其他基于 CNN 的架构,包括 DenseNet、EfficientNet、Inception、Xception、MobileNet、VGG和 Shufflenet,由于各自的优势,在 2019 年左右被广泛采用,实现了与 ResNet 相当的使用份额。然而,自 2021 年以来,Transformer 技术的快速发展显著改变了这一格局。其他基于 CNN 的方法份额急剧下降,而基于Transformer的骨干网络则逐年获得更多关注。目前,非 ResNet 的基于 CNN 的方法仅占总份额的 11%,反映了五年内 78%的急剧下降。
这种转变表明,主流骨干网络的选择已从在多种基于 CNN 的模型中进行选择转变为 ResNet 和 Transformer 之间的二分法,这对该领域的研究人员来说是一个关键决策。此外,Transformer 和 ResNet 的采用趋势表明,其他领域中的许多方法可能仍需要更新以适应这些进展。
3.2 预训练数据集
三个主要的预训练数据集:ImageNet、病理学和无需预训练。结果展示在图的中间上方。自 2009 年引入以来,ImageNet 对深度学习产生了深远影响,推动了整个计算机视觉领域的进步。因此,大多数 MIL 方法在其发布后都采用了 ImageNet 进行预训练。尽管自然场景图像和病理学图像之间的领域差距可能会影响预训练模型在病理学数据上的性能,但 2019 年发表的研究表明,在 ImageNet 上预训练的各种骨干网络已经足以从 WSI 中提取特征以完成多项任务。2019 年,三个主要的预训练数据集------ImageNet、病理学和其它方法------分布相对均匀,反映了研究人员对多样化策略的探索。从 2022 年开始,使用组织病理学数据进行预训练的研究比例显著上升,导致对 ImageNet 的依赖明显下降。这一转变主要归因于自监督和对比学习方法的出现与成熟,这些方法已成功应用于病理学,并利用了 TCGA和 Camelyon16等高质量数据集。
文献持续表明,无论使用何种主干网络,对比学习方法都能有效提取特征。这些方法比 ImageNet 更适合 CPATH 领域,且无需额外标注。
3.3 优化技术
本节涵盖两种模型优化方法:冻结和解除冻结。结果展示在图的右上角。模型是否在预训练后采用冻结策略进行后续微调,不仅反映了其对各种下游任务的适应性,还表明模型的表征能力是否满足 MIL 框架中特征聚合和下游任务的要求。
总体而言,模型被冻结的情况比未冻结的情况更为常见,这表明研究人员通常倾向于使用预训练的骨干网络而不进行微调。
3.4 聚合方法
MIL 中的聚合方法主要由两个组成部分构成:MIL 方法(用于定义实例表示形式的方法)和池化方法。本节涵盖了三种 MIL 方法(基于嵌入、基于实例和其他方法),如图中底部中间所示。以及六种池化方法(线性注意力、自注意力、平均池化、top-k 池化、最大池化和其他方法),如图 2 中底部左侧所示。需要注意的是,所有使用注意力机制但未包含qkv机制的方法在本论文中统称为线性注意力。
**MIL 方法:**基于嵌入的方法一直占据主导地位,主流方法是专注于如何更好地提取和聚合图像特征。
**池化方法:**对池化方法的偏好已从主要依赖传统池化方法(平均池化、top-k 池化和最大池化)演变为到主要依赖基于注意力的池化方法
3.5 下游任务
本节分析了 MIL 中的下游任务,包括分类、回归和分割。在此背景下,回归任务包括与生存风险预测、基因表达强度预测以及类似工作相关的任务。分析显示,分类任务一直主导该领域,并在 2021 年达到顶峰。2021 年是一个关键节点,之后观察到两个主要变化:(1) 分割任务的占比显著下降,(2) 回归任务的占比开始增加。

四、计算病理学中的关键 MIL 研究
本文回顾了过去六年 CPATH 领域中最具代表性的 MIL 研究,如下图所示。这些研究涵盖了重要的方法论创新、实质性的临床验证或引入新的研究方向。
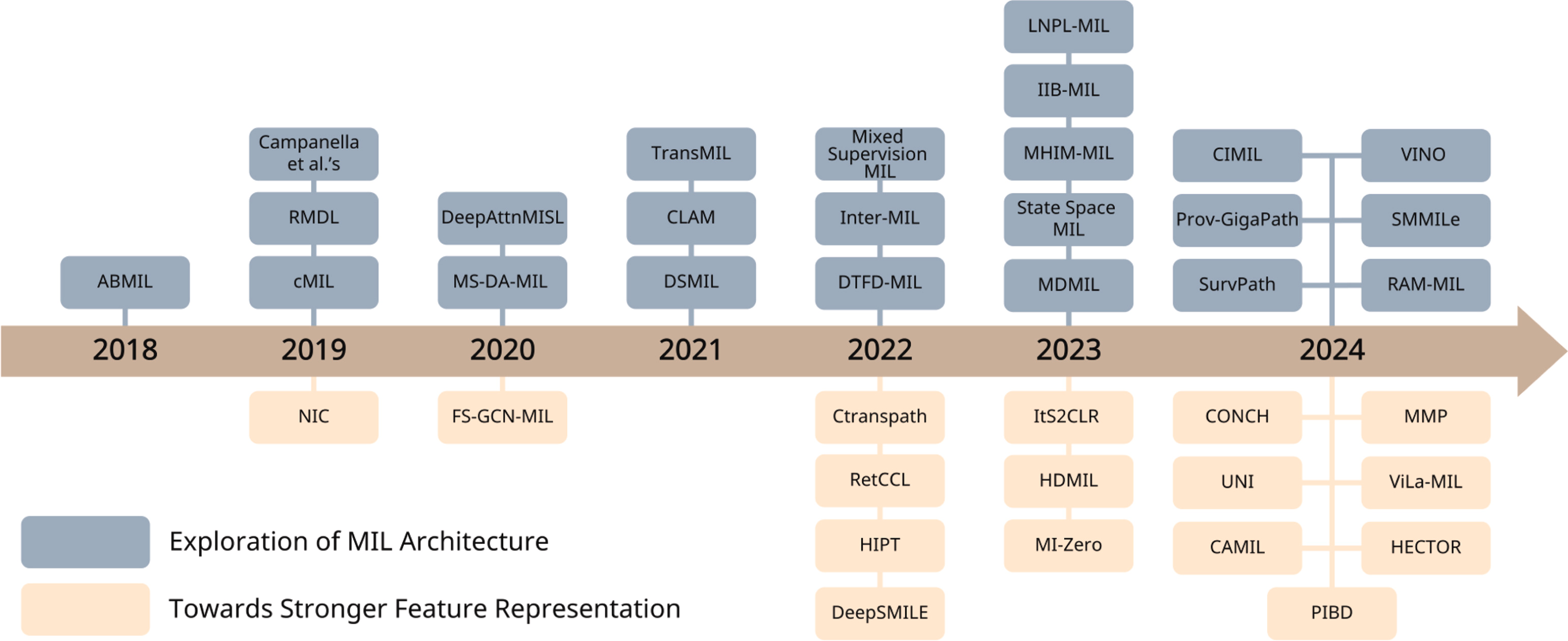
这些工作大致可分为两类:探索 MIL 架构和迈向更强的特征表示。MIL 方法凭借其鲁棒的弱监督特性,与 CPATH 高度兼容。因此,改进其架构以更好地利用这些能力已成为主流研究方向。鉴于 WSI 的性质,集中关注大量无关实例是无益的。因此,该领域的研究主要集中于选择关键实例并提取它们之间的内在关系。此外,特征提取技术一直是 CPATH 研究的一个核心焦点。在现有的 MIL 框架基础上,自监督学习(SSL)和多模态融合方法得到了广泛探索和发展。本节的逻辑结构如下图所示。
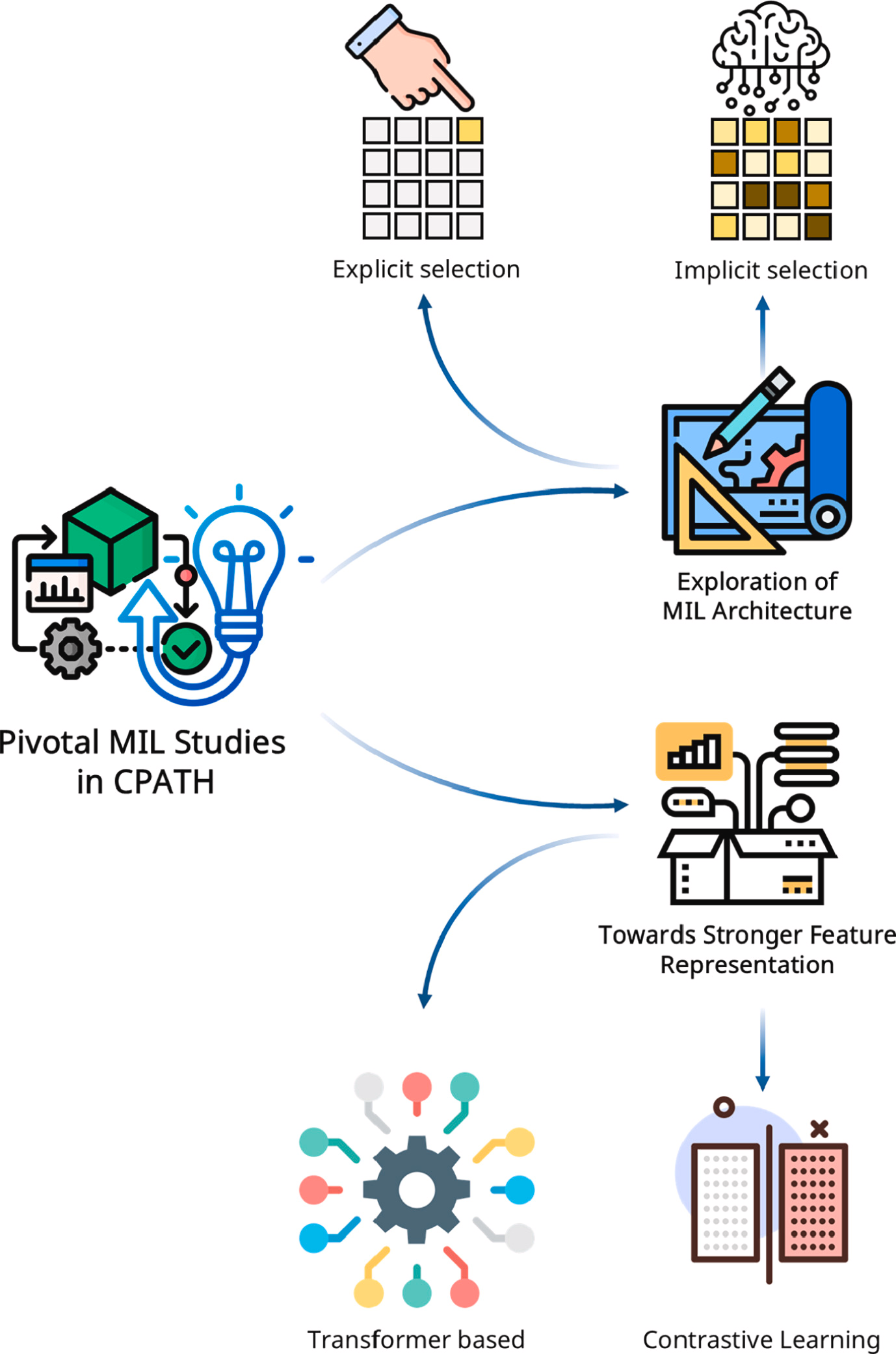
4.1 MIL 架构的探索
对 MIL 架构的研究一直备受关注,主要集中于优化架构以提升各种模型性能。将这些工作分为两部分:有价值实例选择和实例间关系融合。前者强调从大量实例中选取更具代表性的实例,而后者则侧重于利用架构上的进步来探索实例间的关系。本节中涉及的工作的更多信息显示在表中。
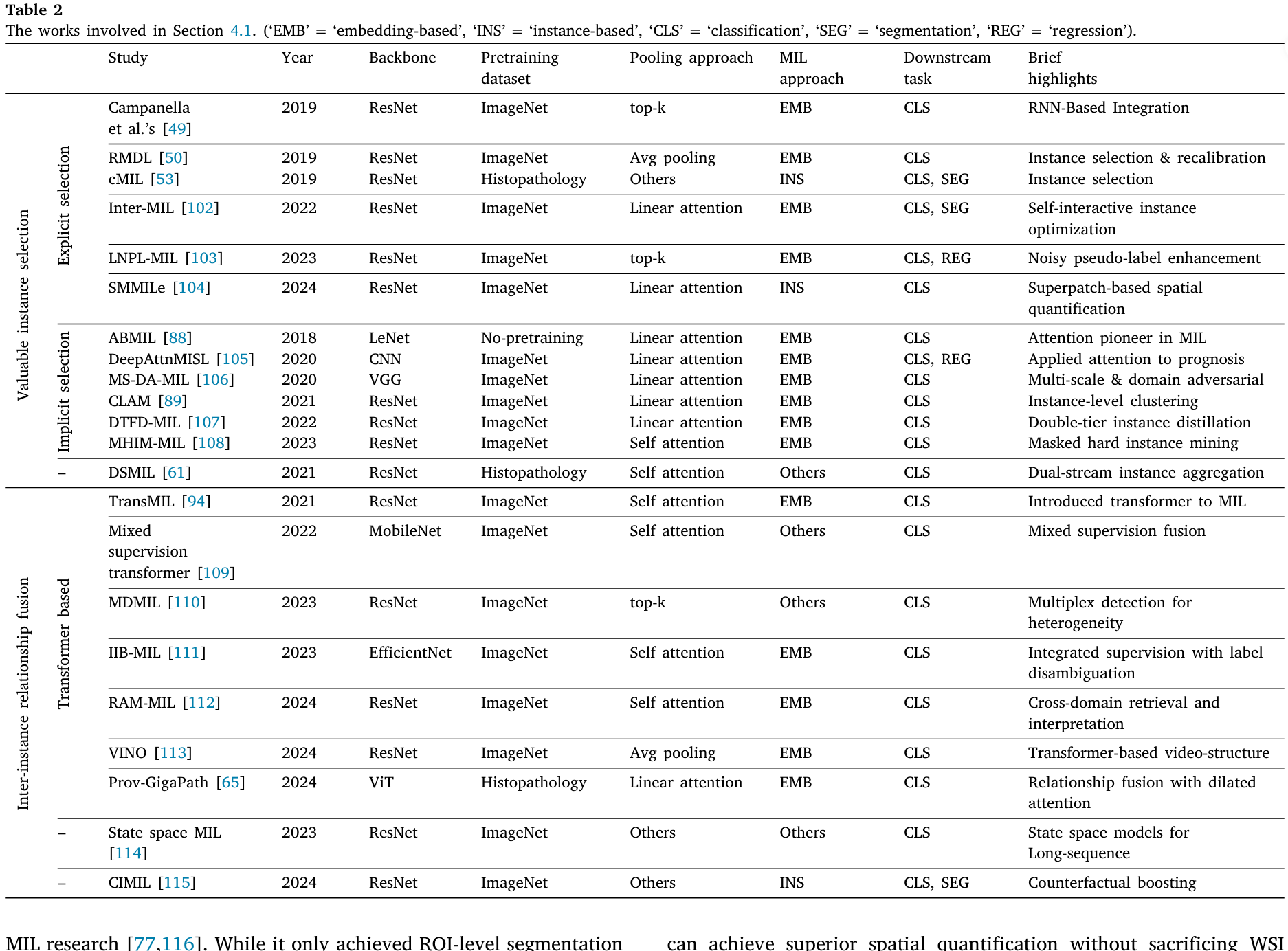
4.1.1. 有价值的实例选择
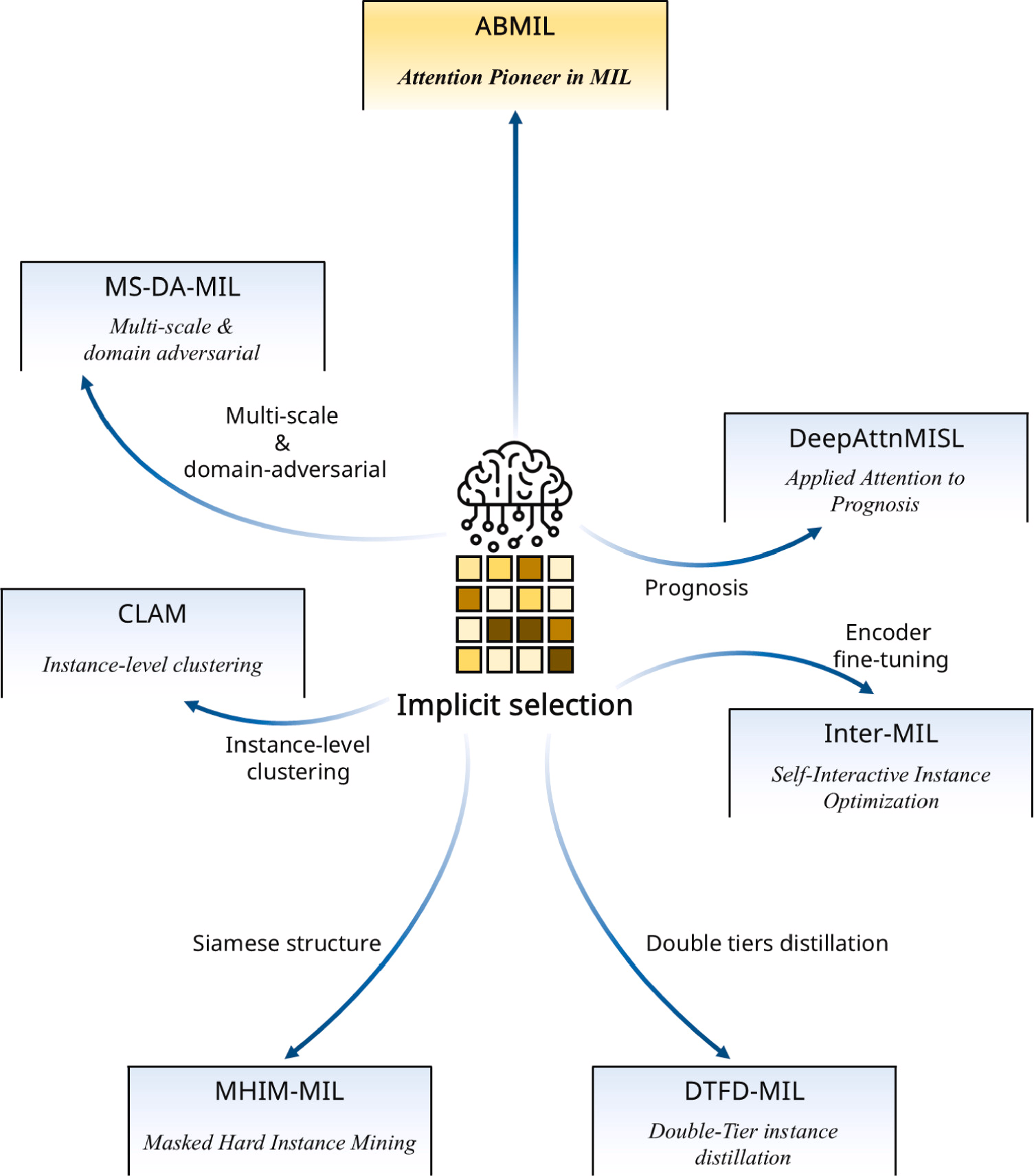
全切片图像(WSIs)通常规模庞大,其中很大一部分区域对模型贡献甚微。鉴于计算资源的限制,选择最有价值的实例变得至关重要。当前有价值实例选择的方法可以大致分为两种策略:显式选择和隐式选择。显式选择方法采用直接方法,通过特定算法识别有价值实例,而隐式选择方法将实例重要性的判断委托给模型本身。
(a)显式选择方法
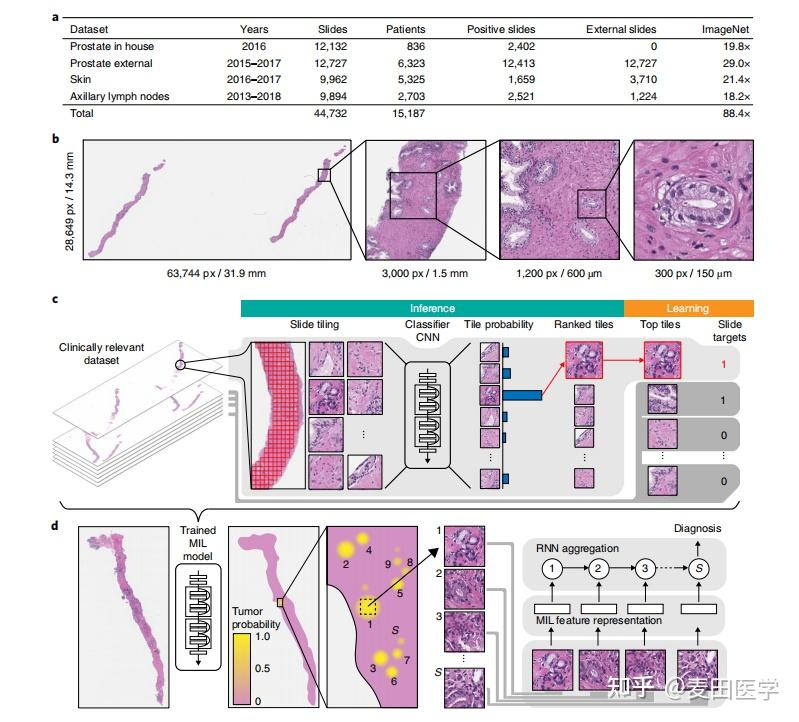
在显式选择早期阶段,通常采用直接算法。例如,Campanella 等人采用了一种 top-k 实例选择策略,将选定的实例输入到后续的聚合阶段,以减轻由过多的 token 长度引起的计算负担。为了进一步确保选择最有价值的实例,RMDL引入了重新校准模块以防止误判,而 cMIL提出了基于实例的 Max--Max 和 max--min 选择方法。随着时间的推移,显式选择技术得到了进一步改进。LNPL-MIL 利用有限的补丁级标注和伪标签来辅助实例选择。尽管近年来显式选择方法的使用率有所下降,但 SMMILe表明,基于实例的显式选择在空间量化任务中仍然能够取得令人印象深刻的结果。
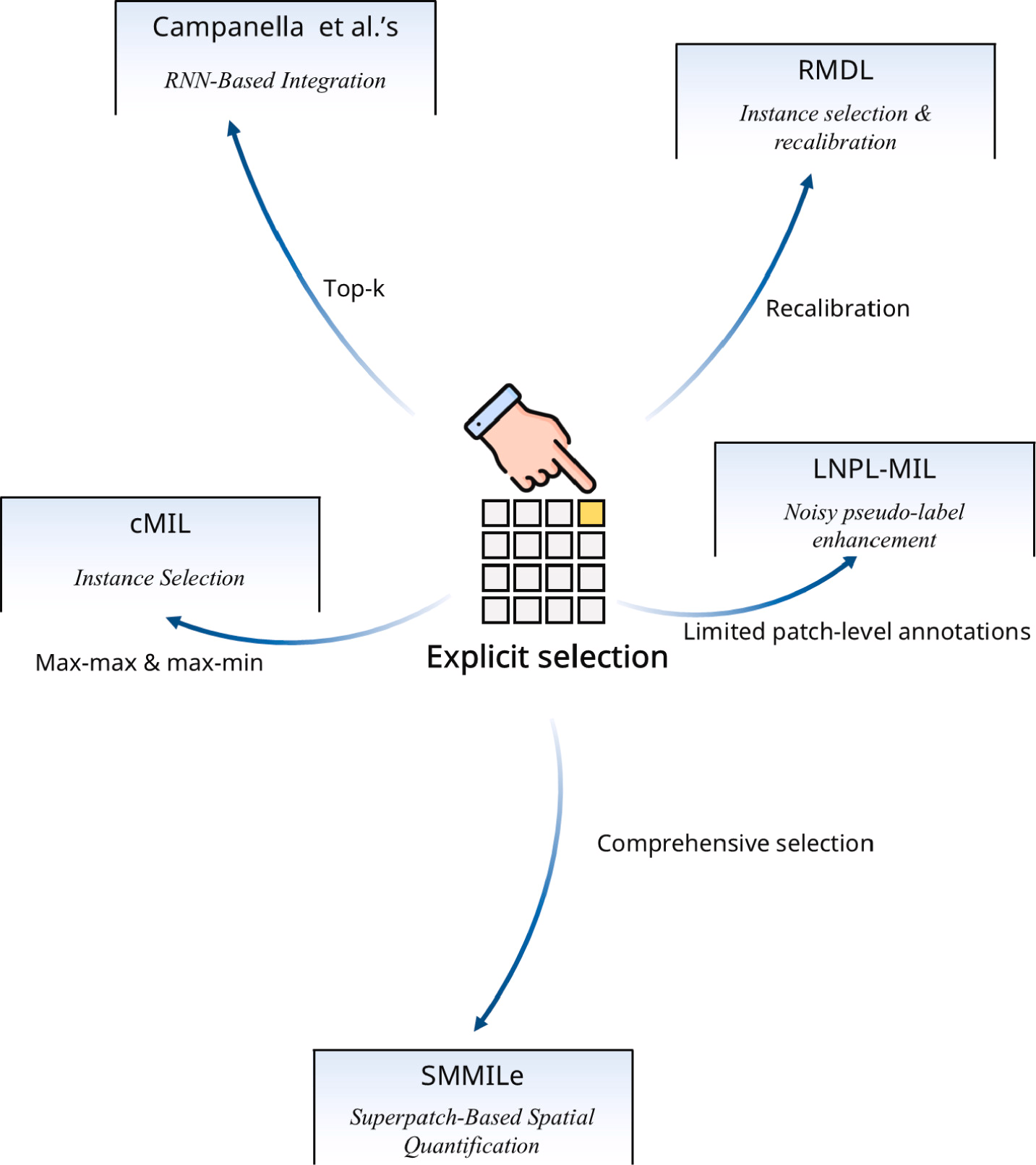
【】Clinical-grade computational pathology using weakly supervised deep learning on whole slide images
Campanella 等人采用了一种 top-k 实例选择策略,将选定的实例输入到后续的聚合阶段,以减轻由过多的 token 长度引起的计算负担。
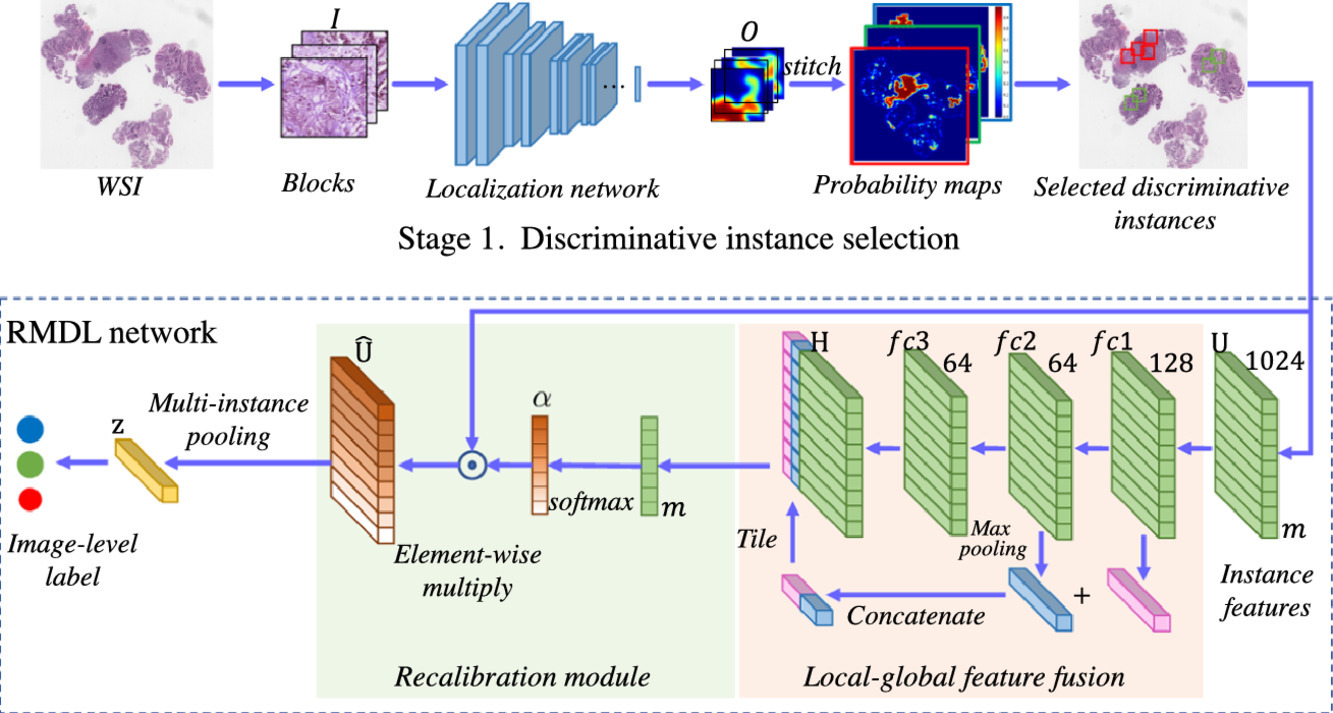
【】RMDL: Recalibrated multi-instance deep learning for whole slide gastric image classification
RMDL提出了重新校准多实例深度学习来处理过大的全切片图像(WSIs)的问题,通过采用传统的感兴趣区域(ROI)范式,从全切片图像中提取关键补丁用于诊断。为了防止提取的补丁不具有代表性,RMDL 引入了一个重新校准模块。该模块通过融合局部和全局特征,帮助模型重新校准选择的补丁,确保从全切片图像中选择的补丁具有充分的代表性。
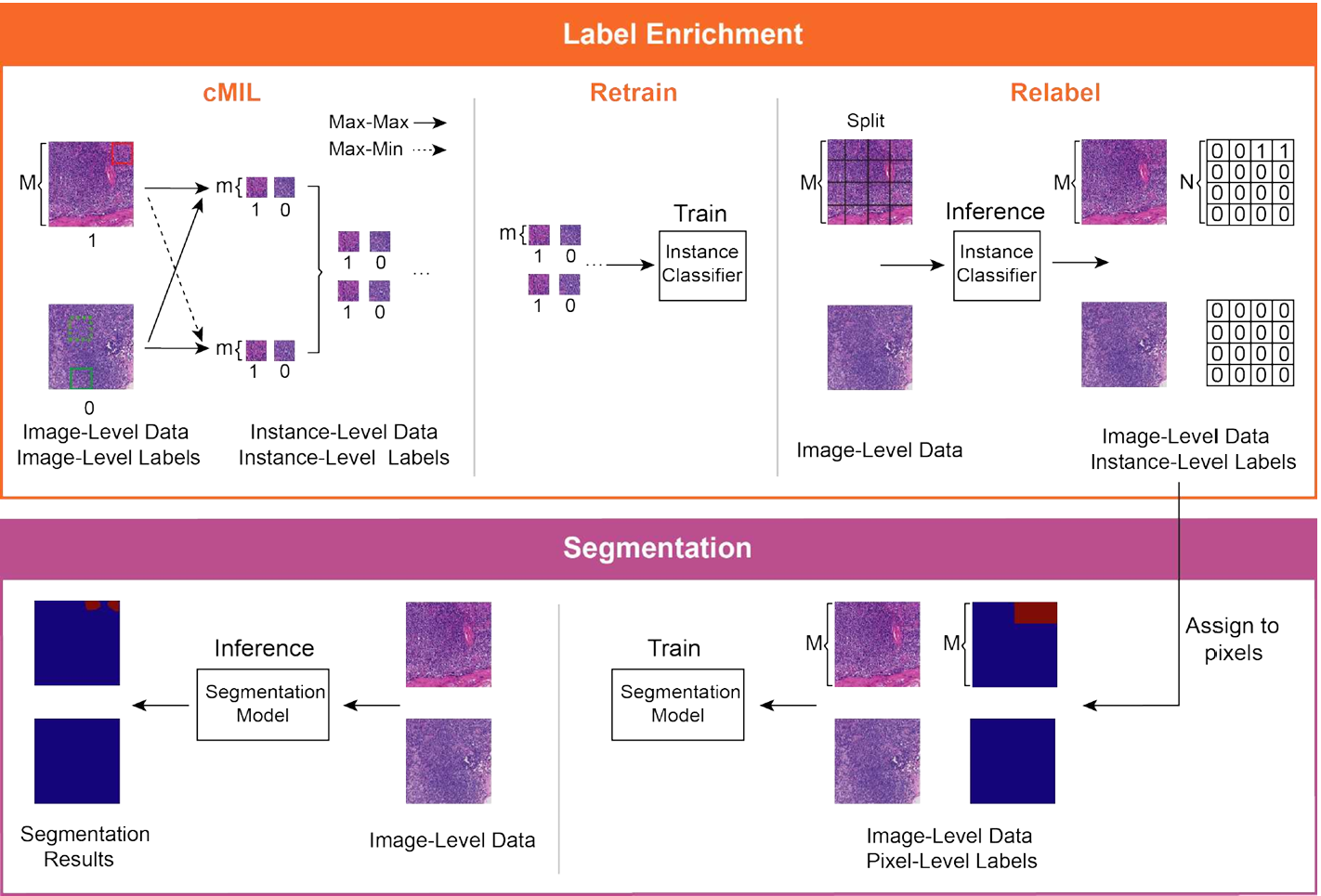
【】Camel: A weakly supervised learning framework for histopathology image segmentation ICCV2019
cMIL引入了结合 MIL 和 CAMEL 的模型,标志着将 MIL 应用于医学图像分割的重要一步。尽管它没有实现全切片图像 WSI 级别的分割,但其局部图像分割方法和用于解决表示限制的标签丰富方法极大地影响了后续 WSI 级别和像素级别分割技术。与为像素级别分割添加额外标签不同,CAMEL 将 WSI 划分为网格,在丰富过程中为每个局部区域生成标签。这可以看作是使用 WSI 级别标签的实例级别分类,标签丰富通过结合 MIL 增强了数据集质量。
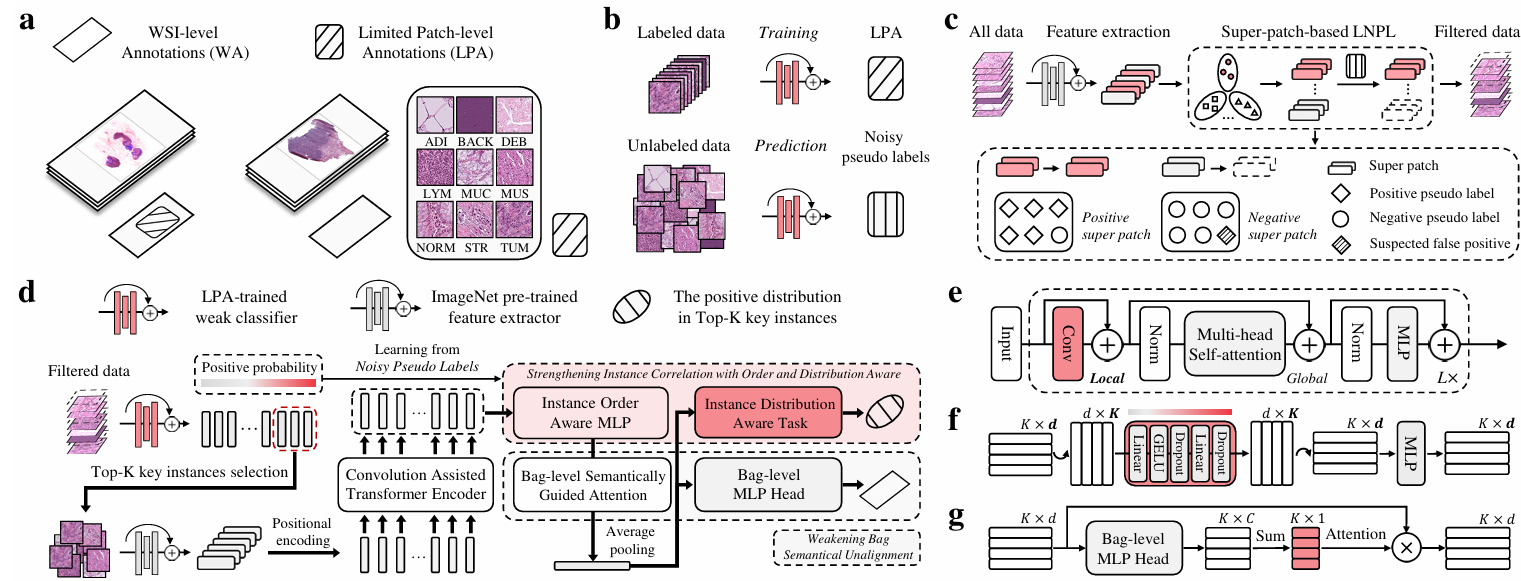
LNPL-MIL引入了从噪声伪标签中学习的方法来增强 MIL,专注于在具有有限切片级标注(LPA)的场景中优化特征提取。虽然使用 LPA 为未标记的切片分配伪标签为 MIL 提供了一个实用的指导,但它通常会引入噪声。此外,基于 WSI 级标签训练 MIL 可能会导致实例与包级标签之间的语义不匹配。为了解决这些问题,LNPL-MIL 引入了基于超级切片的 LNPL (SP-LNPL) 和感知实例顺序与分布的 Transformer (TOD-MIL)。LNPL-MIL 使用 LPA 来改进特征提取,同时减少噪声的负面影响。尽管这种方法在一定程度上与 MIL 的核心原则相矛盾,但它表明通过扩展网络规模并加入少量额外信息来提高 MIL 特征提取性能是一个有前景的方向。
【】SMMILe enables accurate spatial quantification in digital pathology using multiple-instance learning Nature cancer 2025
SMMILe提出了基于超 patch 的可测量多实例学习方法,这是 2021 年后基于实例的多实例学习研究中的关键贡献。在 CPATH 任务中,空间量化至关重要,例如指导病理学家并识别与新型生物标志物相关的组织表型。开发具有空间感知能力的 CPATH 模型的主要挑战是需要详细的空間注释,由于像素级图像的规模巨大以及对专业领域知识的需要,这些注释难以获取。基于嵌入的多实例学习方法通常会产生不精确的注意力图,限制了它们在空间分析中的有效性。这种限制阻碍了它们在需要精确表型描述而非全局标签的任务中的应用。Gao 等人通过数学证明表明,实例级聚合可以在不牺牲 WSI 预测性能的情况下实现更优越的空间量化。SMMILe 集成了 NIC、两个新型基于实例的注意力模块以及贝叶斯细化网络。 这项工作的意义在于其对基于实例和基于嵌入的 MIL 方法的严格数学比较,突出了前者在空间量化方面的优势。这将为进一步研究该领域铺平道路。
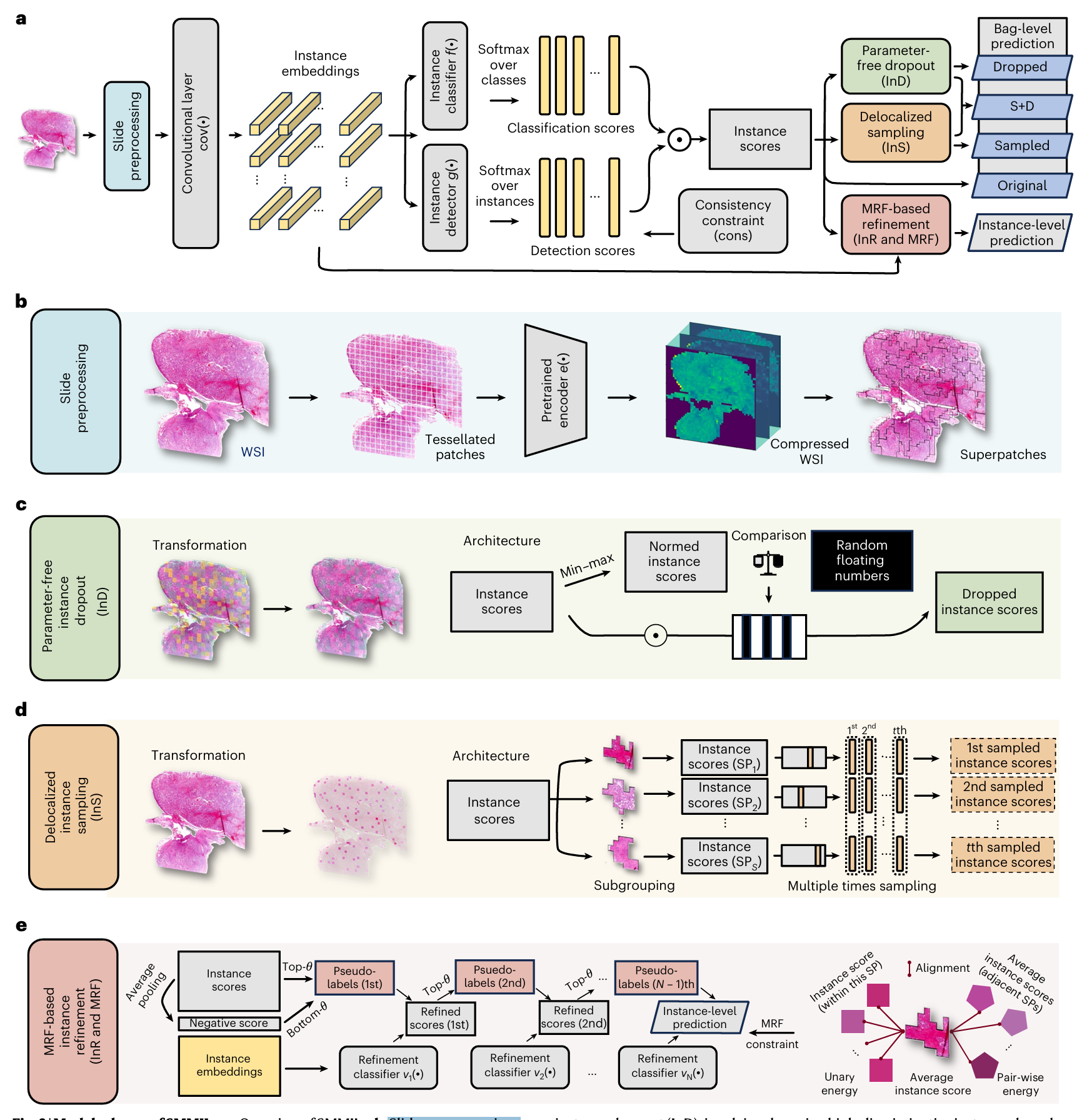
(b)切片预处理。每个WSI图像都被分割成多个块,并通过预训练编码器映射到嵌入向量。然后,我们使用NIC算法获得压缩后的WSI图像,为后续的卷积运算做好准备。同时,SMMILe算法通过对压缩后的WSI图像进行过分割,生成一系列超块(SP;下标S表示超块的总数)。(c)无参数实例丢弃(InD),即根据实例得分丢弃高区分度实例。(d)非局部实例采样(InS),涉及通过从每个超块中随机选择一个实例,在多轮迭代中生成多个子包。(e)基于马尔可夫随机场的实例细化(InR 和 MRF),涉及使用伪标签,通过自训练策略训练一个辅助的多阶段细化网络,并通过 MRF 能量约束增强空间平滑性。
(b)隐式选择方法
CPATH 领域中用于 MIL 的隐式选择方法起源于 ABMIL ,该方法引入了注意力机制,使模型能够自主处理实例选择。这一方法启发了后续一系列相关进展。DeepAttnMISL 将该方法应用于预后任务,而 MS-DA-MIL通过结合多尺度特征提取和领域对抗技术扩展了 ABMIL,以改进选择。CLAM增加了实例级聚类,Inter-MIL基于注意力机制和编码器微调构建,不仅选择注意力分数较高的实例,还考虑了补充和非注意力实例,DTFD-MIL引入双层 MIL 框架进行实例特征蒸馏,MHIM-MIL 实现了 Siamese 结构,通过师生架构促进特征选择。下图概述了以下几节将要讨论的工作。
【】Attention-based deep multiple instance learning
ABMIL于 2018 年引入了基于注意力的 MIL 池化方法,提出了一种新的实例聚合池化方法,在此之前,MIL 方法通常采用各种算子进行实例聚合,如最大算子、均值算子和凸最大算子。这些可微分的算子因其计算简单性和可解释性而被广泛用于 MIL 中的实例聚合。然而,这些传统池化方法的一个显著局限性是它们是预定义的,在后续训练过程中无法进行优化。
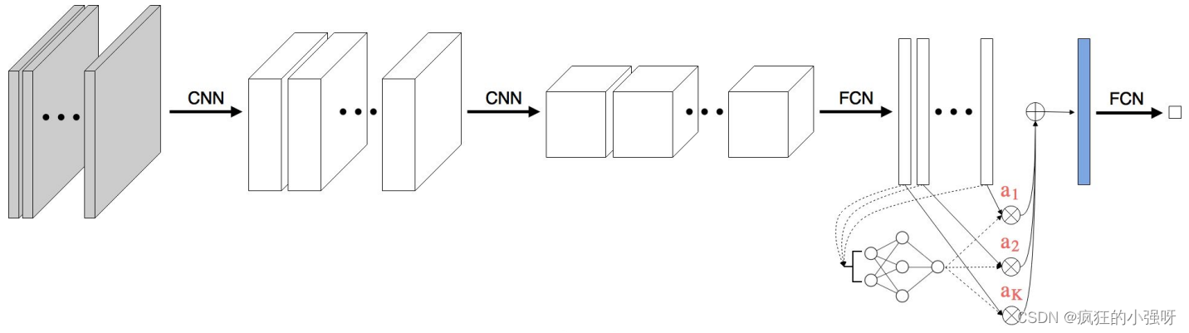
ABMIL 引入了一种加权平均方法,其中权重通过神经网络训练学习。给定一个包含 S 嵌入的包X:
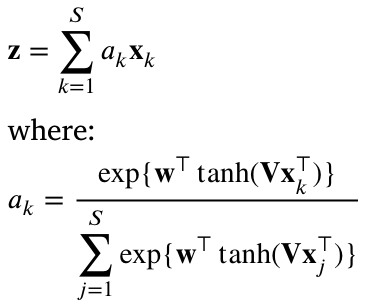
由于双曲正切非线性在区间 上几乎呈线性,因此对于学习复杂关系可能效率不高。为了解决这个问题,可以选择性地引入第二种非线性。这种方法采用门控机制 121,该机制与双曲正切非线性结合使用,得到以下公式:
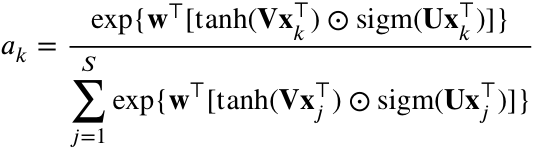
【】Whole slide images based cancer survival prediction using attention guided deep multiple instance learning networks MIA2020
DeepAttnMISL引入了深度注意力多实例生存学习,这是首次将注意力机制与多实例学习结合用于患者生存预测的研究。与其他研究不同,DeepAttnMISL 将患者视为一个包,该包中可以包含多个全切片图像(WSIs)。作者采用聚类方法收集实例,并使用 Siamese MI-FCN 从表型簇中学习特征。在特征聚合阶段,DeepAttnMISL 使用了与 ABMIL 一致的 MIL 池化方法。
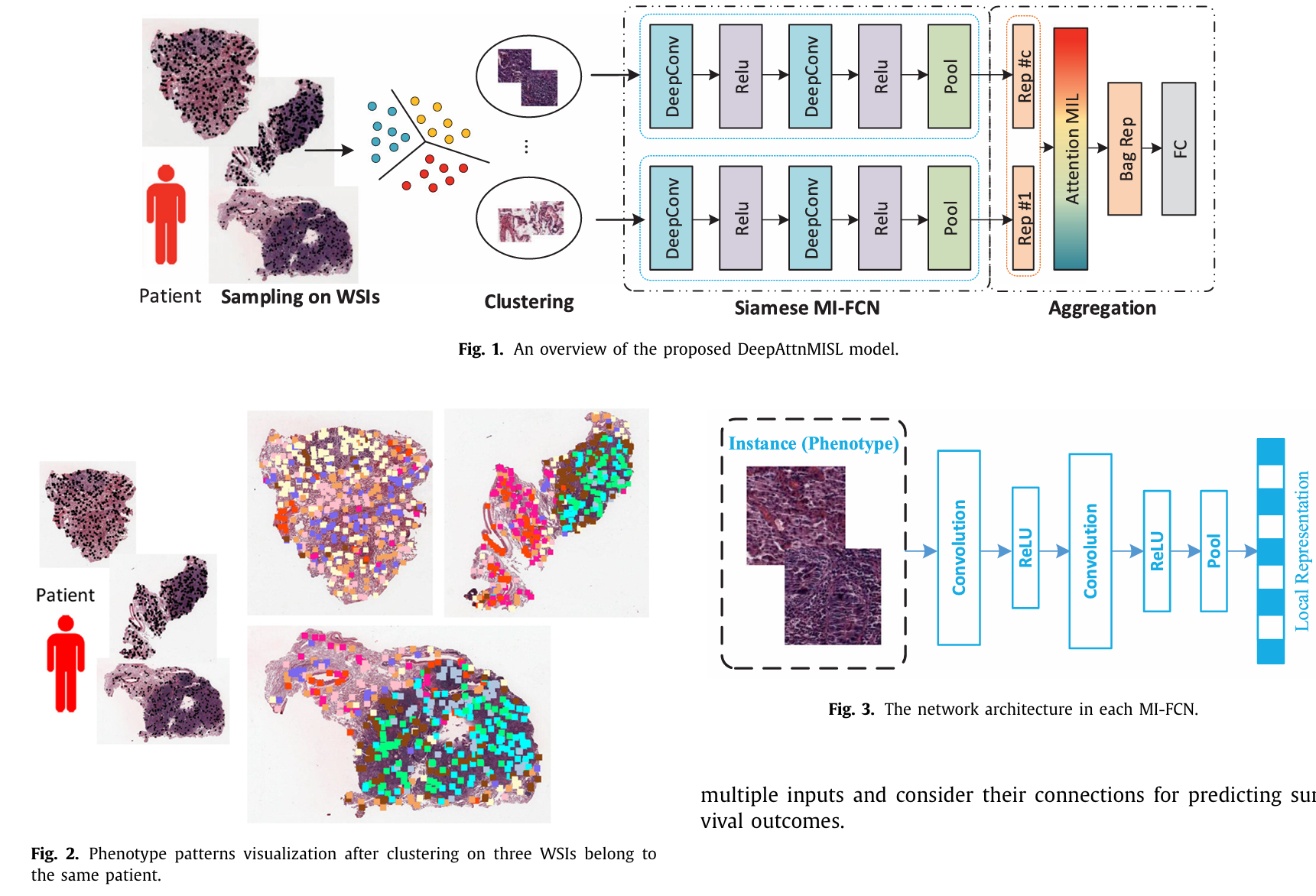
【】Multi-scale Domain-adversarial Multiple-instance CNN for Cancer Subtype Classification with Unannotated Histopathological Images CVPR2020
MS-DA-MIL引入了多尺度域对抗式多实例学习,将多实例学习与域对抗和多尺度学习技术相结合。为了应对染色条件的变化,MS-DA-MIL 使用了一个域对抗神经网络。该方法有效地忽略了与分类任务无关的无关域差异,优于传统的颜色增强和染色标准化技术。
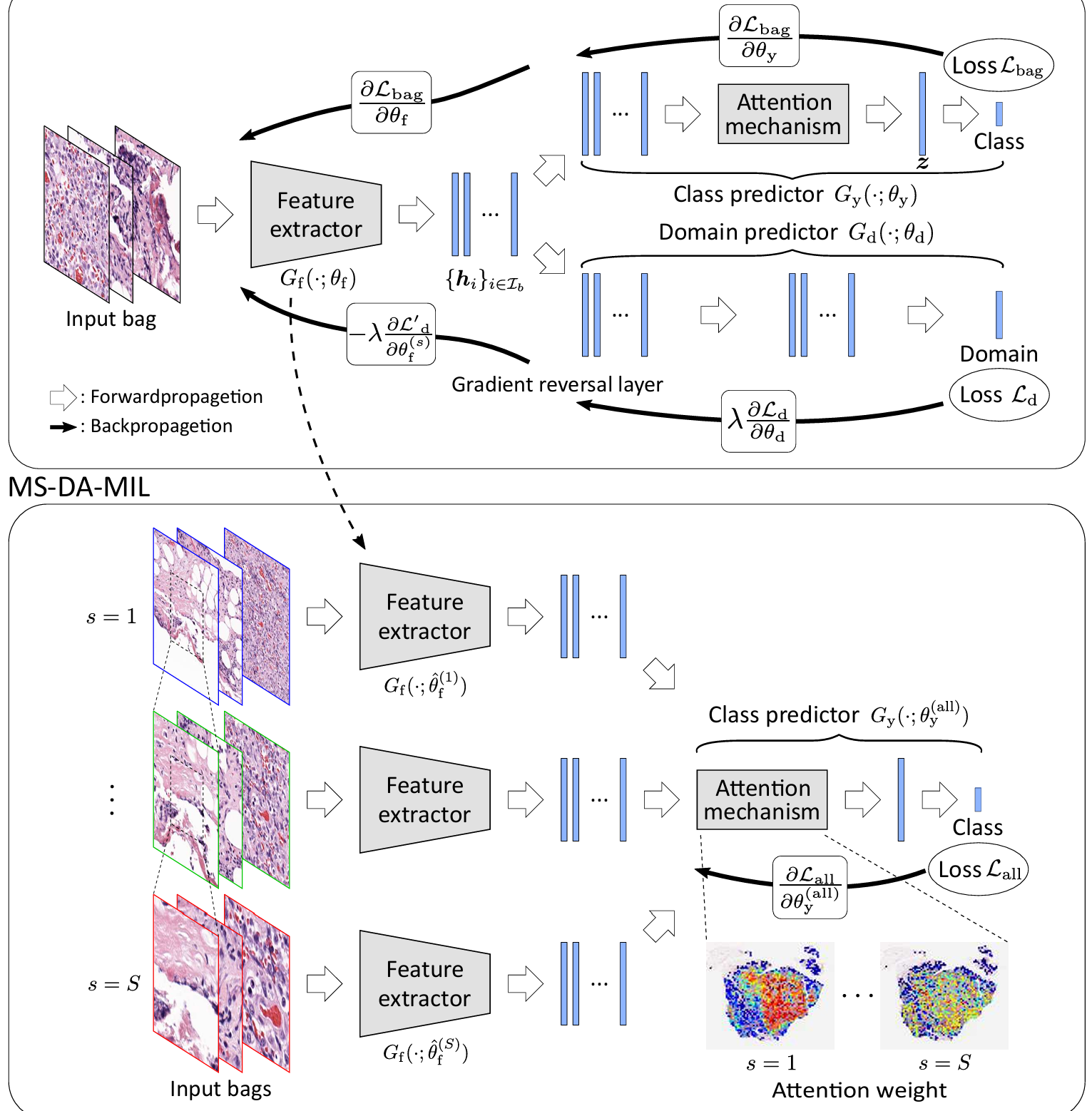
【】Data-efficient and weakly supervised computational pathology on whole-slide images Nature biomedical engineering, 2021
CLAM 89 引入了聚类约束注意力多示例学习,通过在训练过程中利用聚类来解决 CPATH 中的领域适应性和可解释性差的问题。CLAM 使用基于注意力的学习方法来识别具有高诊断价值的子区域,并应用实例级聚类来细化特征空间。CLAM 已成功应用于检测肾细胞癌、非小细胞肺癌和淋巴结转移。实验结果证实了 CLAM 的可靠性和泛化能力,展示了 MIL 方法在处理 WSI 时的有效性,同时降低了成本并提高了可解释性。
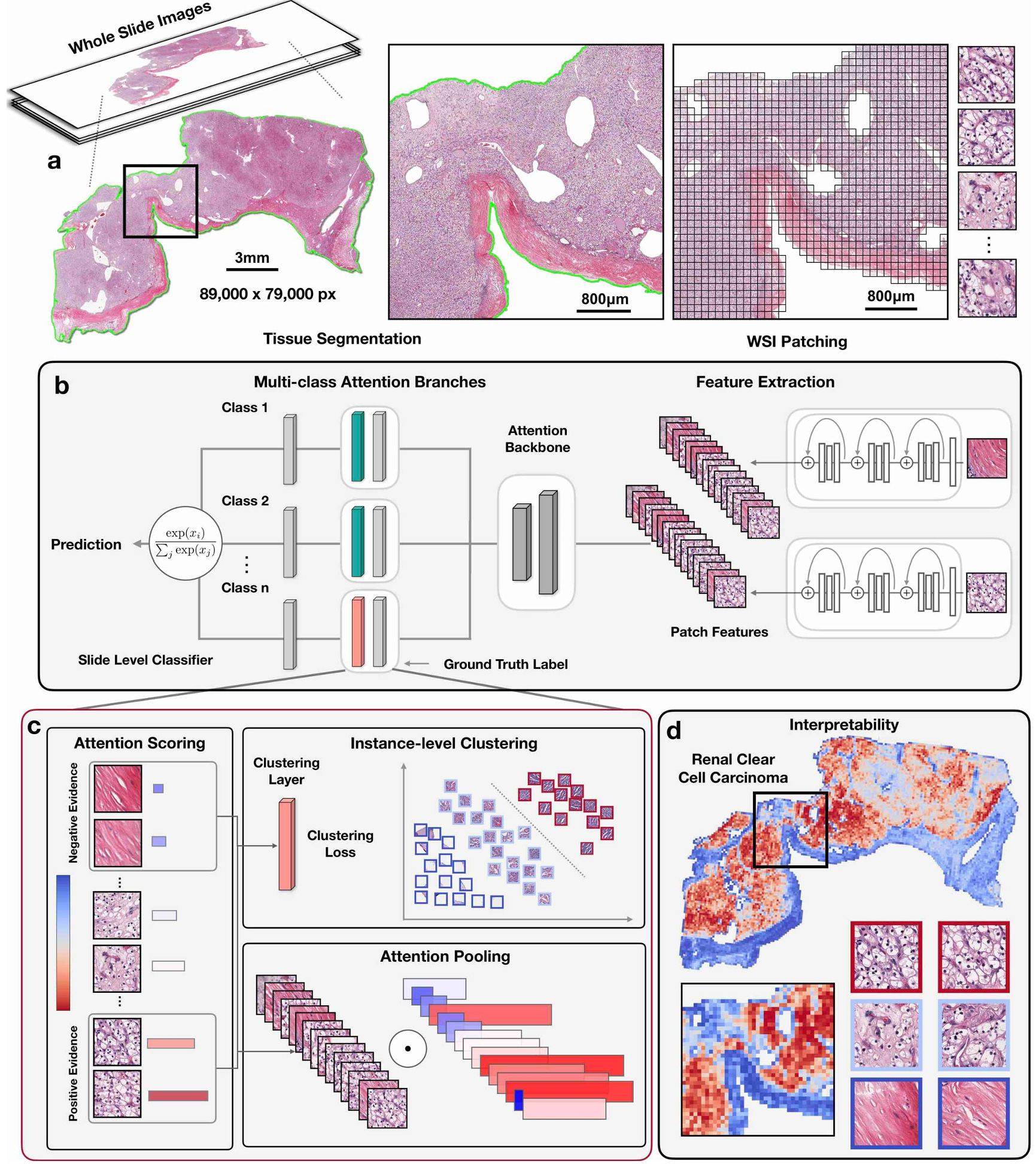
【】Predicting Molecular Traits from Tissue Morphology Through Self-interactive Multi-instance Learning MICCA2022
Inter-MIL提出了自交互 MIL,该模型在细粒度上下文特征和全局上下文特征之间迭代交换训练信息。该过程分为三个步骤:(1) AttPool 网络计算实例嵌入并获取每个实例的注意力分数;(2) 使用高注意力实例、补充实例和非注意力实例构建实例级特征池;(3) 使用实例级特征池对 CNN 主干编码器进行细粒度训练,为 AttPool 在下一轮训练中生成新的实例嵌入。这种方法本质上基于实例的注意力分布进行分组,在实例聚合阶段利用这些信息为特征提取器的训练提供反馈。这种反馈提高了正例和负例之间的区分度,最终提升了整体模型性能。然而,Inter-MIL 在后续研究中并未获得广泛应用,可能由于其复杂的架构、对补丁数量的限制以及解释性欠佳。
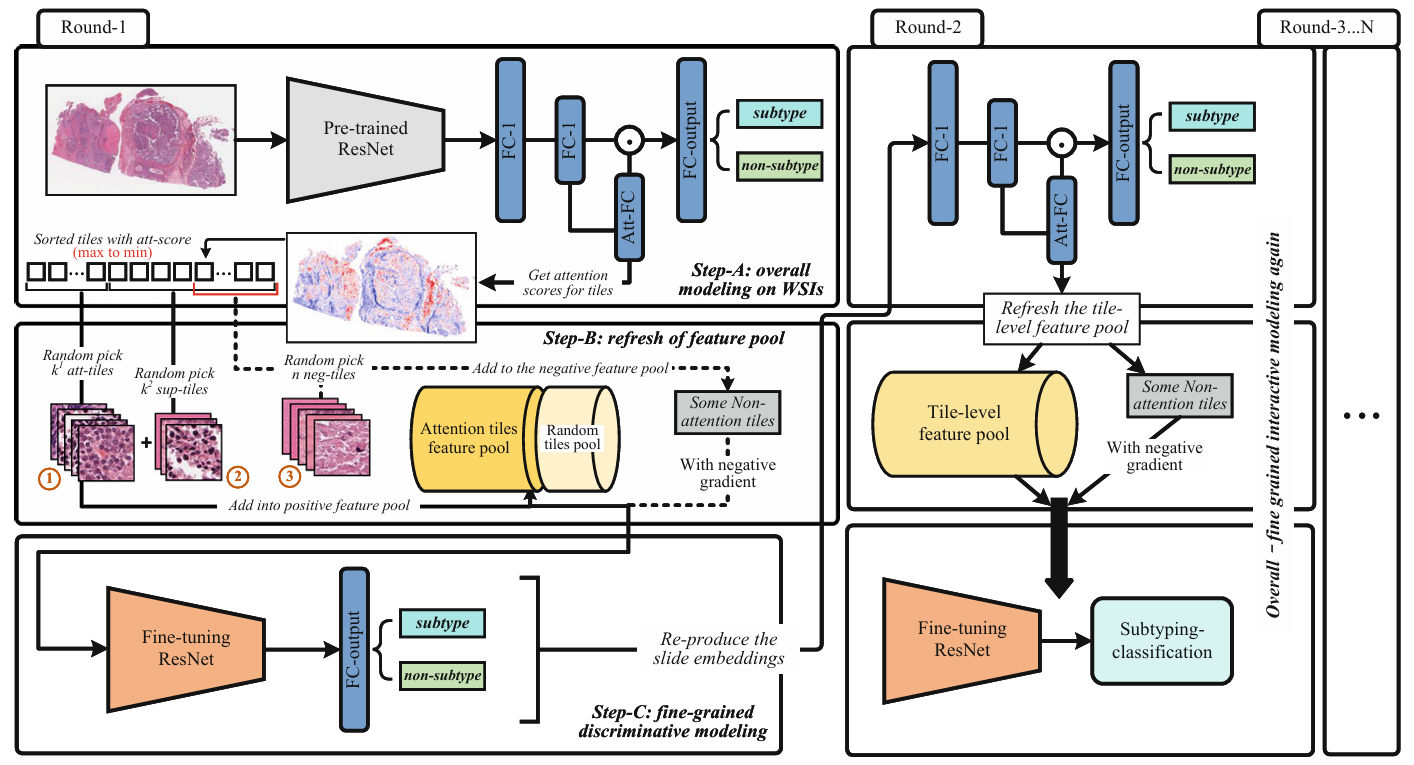
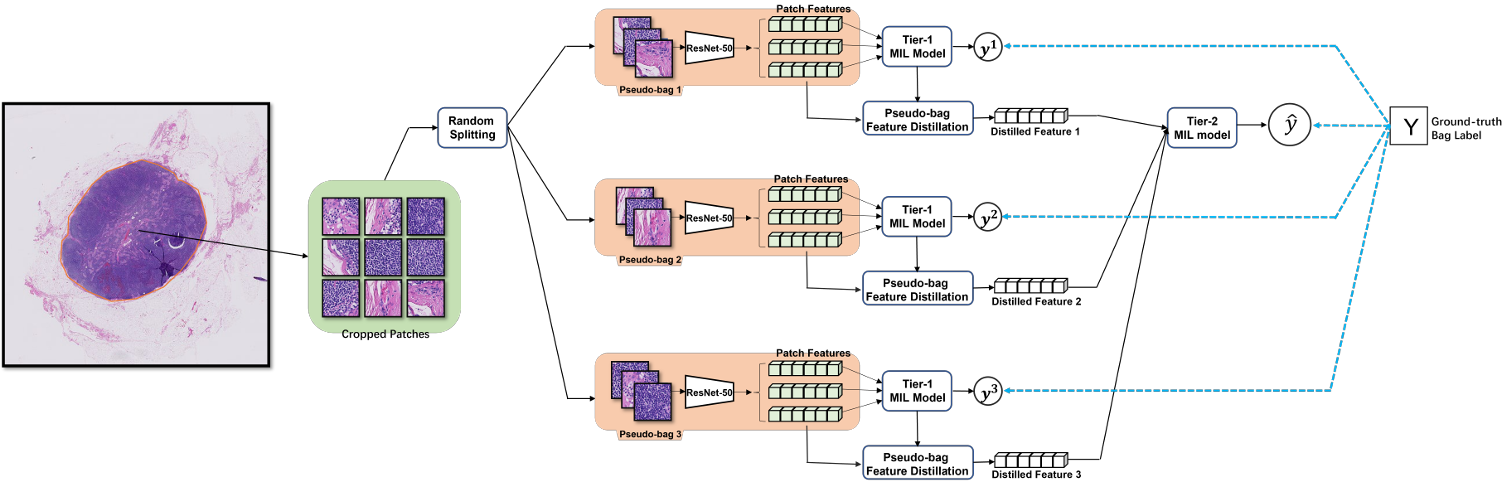
【】DTFD-MIL: Double-Tier Feature Distillation Multiple Instance Learning for Histopathology Whole Slide Image Classification CVPR2022
DTFD-MIL 107 提出了双层特征蒸馏多实例学习方法,该方法旨在解决处理大量图像块的问题,这一问题的主要原因是正负样本不平衡。DTFD-MIL 框架采用分层实例过滤策略。它引入了伪包的概念,其中父包被划分为多个伪包。每个伪包继承父包的标签,并包含图像块的子集。第一步是对所有伪包应用基于注意力的多实例学习(ABMIL)。然后,采用第二层 ABMIL 模型处理不包含正样本的伪包中的标签错误,该模型基于从所有伪包中提取的特征。
【】Multiple Instance Learning Framework with Masked Hard Instance Mining for Whole Slide Image Classification ICCV2023
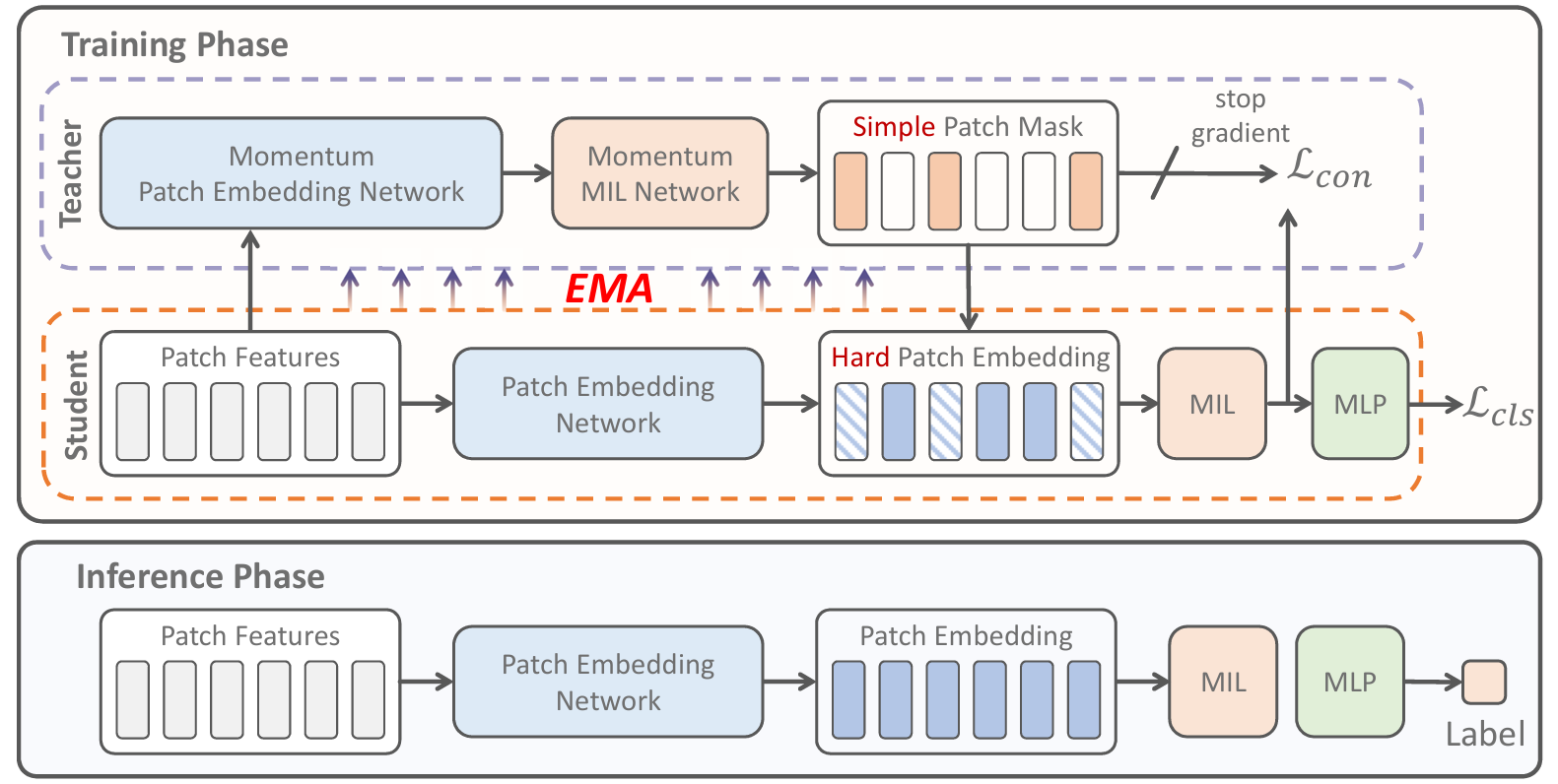
MHIM-MIL 引入了掩码硬实例挖掘 MIL,解决了正负样本不平衡的问题,导致传统 MIL 模型专注于易于分类的样本而忽略较难的样本。MHIM-MIL 结合了 Siamese 结构和实例掩码策略,通过注意力机制隐式挖掘硬实例,提高了模型的判别能力。它掩码了具有高注意力分数的简单实例,以强调较难的实例。将高注意力掩码(HAM)与两种额外策略------最低值掩码和随机掩码相结合,形成 LR-HAM。它在 Siamese 结构中使用动量教师来计算所有实例的注意力分数,帮助学生模型专注于更难的实例。该框架可应用于现有的基于注意力的 MIL 模型,如 ABMIL、DSMIL 和 TransMIL,通过聚焦于信息区域和减轻欠拟合,实现更高效的训练和更快的收敛。
【】Dual-Stream Multiple Instance Learning Network for Whole Slide Image Classification With Self-Supervised Contrastive Learning CVPR2021
DSMIL结合了基于实例和基于嵌入的方法进行特征选择,代表了一种混合方法,连接了显式和隐式策略。引入了双流 MIL 来解决 MIL 中的两个关键挑战:(1) 类别不平衡问题,这可能导致忽略正例而引起过拟合 88,以及 (2) 端到端训练的高成本,这会降低特征提取器的表征能力 49, 51。DSMIL 通过在其实例聚合器中结合最大池化和自注意力机制来克服这些挑战。主要创新包括使用 SimCLR 25(一种自监督对比学习方法)来训练特征提取器,以及采用双流实例聚合器。
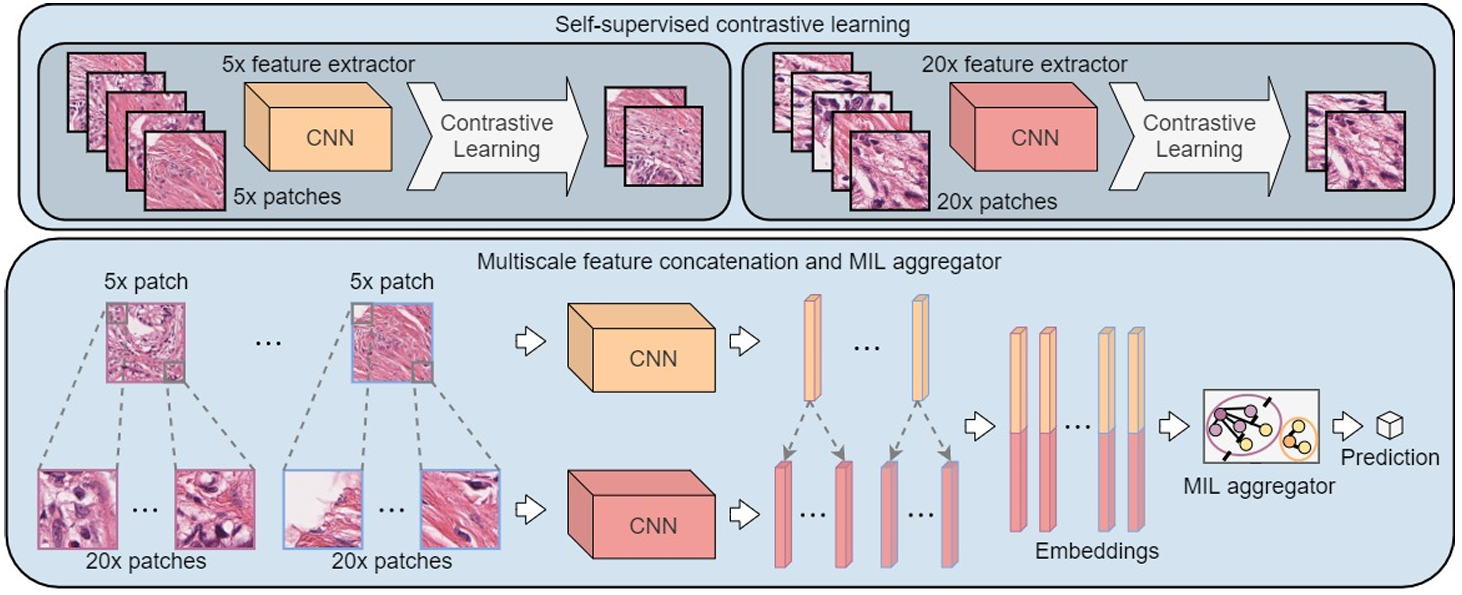
提出使用自监督对比学习来学习特征提取器 f。具体来说,我们考虑了SimCLR,这是一个先进的自监督学习框架,它无需人工标注即可学习鲁棒的表示。SimCLR 采用对比学习策略,训练 CNN 将同一图像批次中的子图像关联起来。
子图像从一批图像中随机选择,并输入到两个随机图像增强分支中。模型通过对比损失进行训练,以最大化来自同一图像的子图像之间的一致性。训练收敛后,特征提取器被保留,并用于计算训练样本的表示,以用于下游任务。用于 SimCLR 的数据集由从 WSI 中提取的图像块组成。这些图像块经过密集裁剪,彼此不重叠,并作为单独的图像用于 SimCLR 训练。
4.1.2. 实例间关系融合
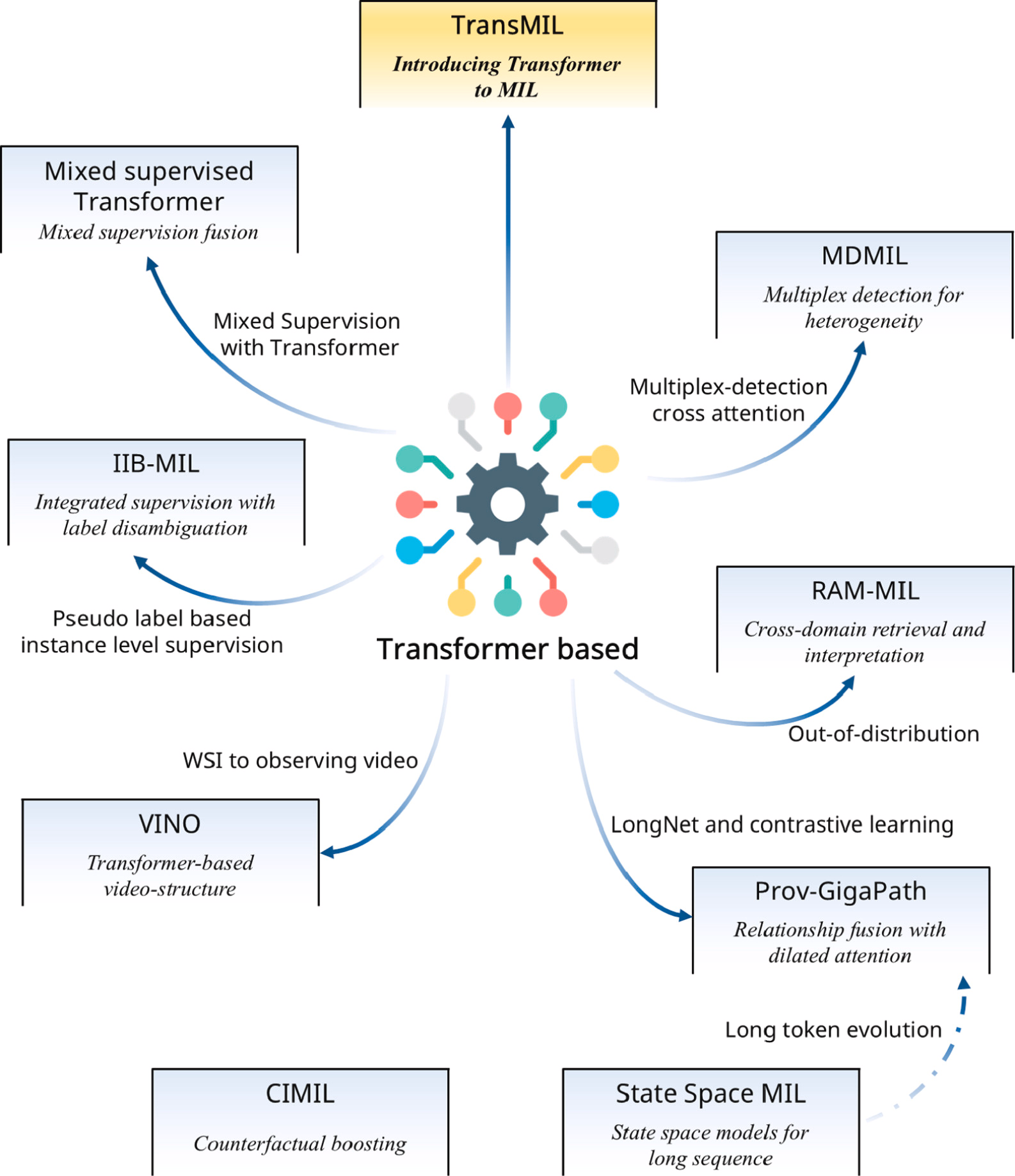
除了提取有价值的实例外,挖掘全切片图像(WSIs)中的丰富上下文信息是研究的另一个关键方面。在多实例学习(MIL)的背景下,这项工作表现为提取实例间关系,即实例间关系融合。由于它们能够高效地捕捉上下文关系,Transformer 已被广泛应用于该研究领域。TransMIL 首次将 Transformer 引入 MIL。虽然其整体工作流程遵循隐式特征选择范式,但 TransMIL 与 ABMIL 中使用的 MIL 池化方法不同,它专注于提取实例间关系而非选择有价值的实例。
基于 TransMIL,后续研究取得了显著进展。例如,Bian 等人提出了混合监督 Transformer 以提升模型性能。MDMIL通过采用多路检测交叉注意力简化了传统的多头自注意力机制,减轻了构建上下文连接的计算负担。IIB-MIL 引入了基于伪标签的实例级监督。RAM-MIL引入了最优传输(OT)距离,并首次系统地探索了多实例学习(MIL)中的分布外(OOD)问题。VINO将 Transformer-MIL 范式扩展到病理视频分析,拓宽了其应用范围。Prov-GigaPath通过结合 LongNet 使基于 Transformer 的 MIL 能够处理超长 token 序列,将这类模型在处理扩展序列数据方面的能力推向了新的边界。下图概述了下文讨论的工作。
【】TransMIL: Transformer based Correlated Multiple Instance Learning for Whole Slide Image Classification NISP2021
TransMIL 利用 Transformer 的自注意力机制,该机制对序列中所有 token 之间的成对关系进行建模,这与 ABMIL 中使用的加权平均方法形成对比。虽然传统 Transformer 计算量大,限制了它们在 WSI 等大规模图像上的应用,但 TransMIL 通过 TPT 模块克服了这一挑战,该模块包括以下步骤:(1)序列平方,(2)相关性建模,(3)条件位置编码和局部融合,(4)深度特征聚合,以及(5)WSI 级预测。TPT 模块在 ResNet-50 提取的实例嵌入上运行,将特征包转换为预测标签。为了缓解自注意力的高计算成本,TransMIL 使用 Nyström 方法来近似 WSI 中的自注意力。
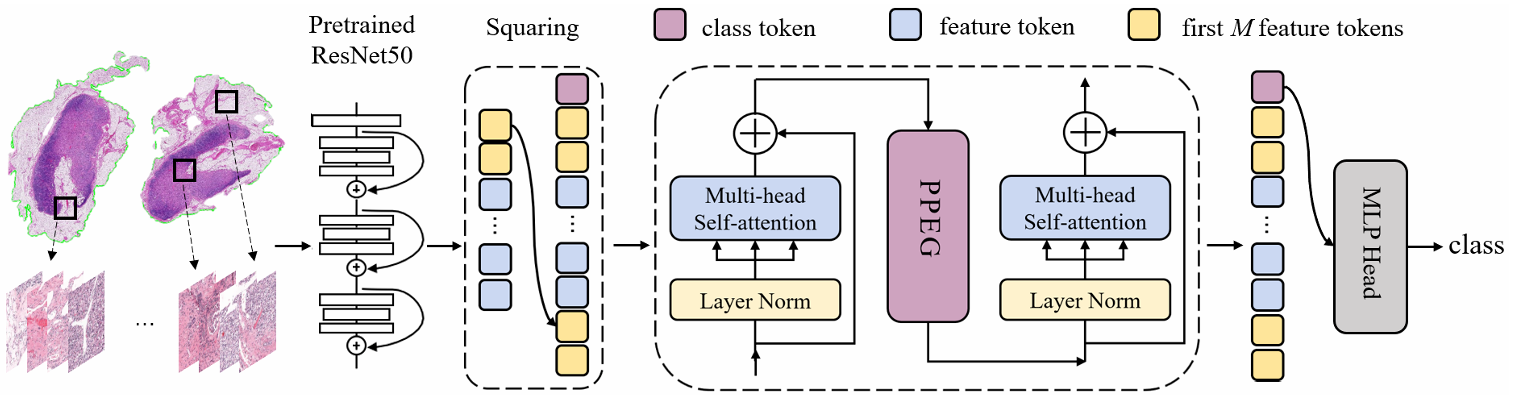
【】Multiple Instance Learning with Mixed Supervision in Gleason Grading MICCAI2022
混合监督 MIL代表了混合监督在 MIL 中的典型应用。在传统的 MIL 方法中,仅考虑 WSI 级别的标签可能导致模型忽略图像中的丰富局部信息。相反,加入有限的像素级标签可能会因这些标签的潜在不准确性而影响模型性能。为解决这一问题,混合监督 MIL 提出了三项主要创新:(1) 基于超像素的实例特征和标签生成:该技术将有限的像素级标签转换为实例级标签,使模型能够利用更细粒度的信息;(2) 随机掩码策略:该策略用于防止不准确的实例级标签对模型性能产生负面影响,降低标签噪声带来的风险;(3) 2D 正弦空间位置编码:该方法对实例的空间位置信息进行编码,帮助模型更有效地整合空间上下文。
采用简单线性迭代聚类(SLIC)算法1提取超像素组织区域。每个超像素的面积可以被视为一个实例。由于超像素区域是根据组织纹理结构的相似性生成的,因此,每个超像素区域包含大部分相同的组织,并且边界比矩形块更平滑。
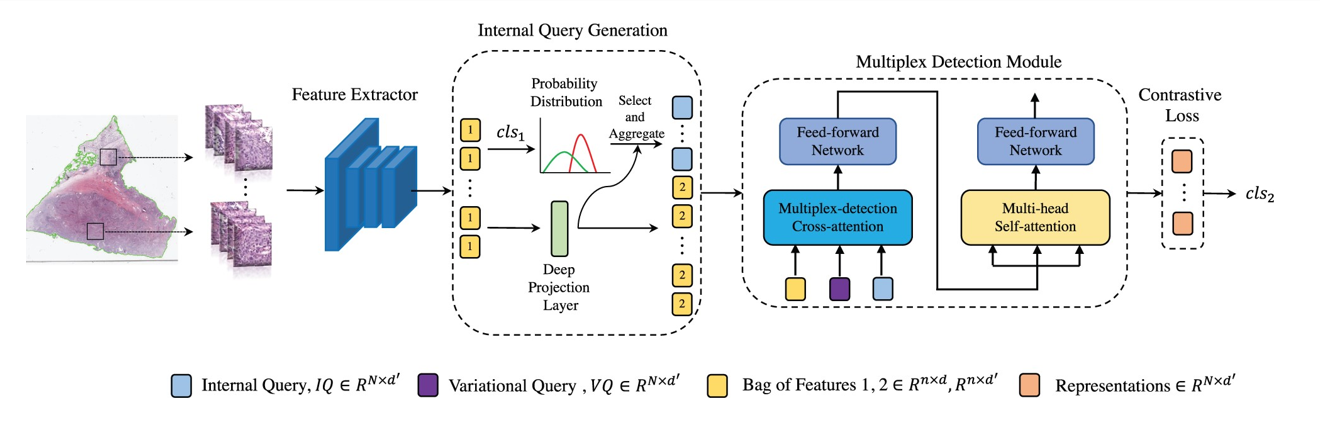
【】Targeting tumor heterogeneity: multiplex-detection-based multiple instance learning for whole slide image classification
MDMIL引入了基于多重检测的 MIL 方法,以应对肿瘤异质性对 MIL 性能带来的挑战。MDMIL 的主要贡献如下:(1) 内部查询生成模块(IQGM):IQGM 通过分类器层和概率分布分析聚合高可靠性实例,生成内部查询;(2) 多重检测模块(MDM):MDM 包含多重检测交叉注意力和多头自注意力,生成包级表示。多重检测策略同时利用内部查询和变分查询,两者互补,显著增强了模型的实例挖掘和泛化能力;(3) 基于记忆的对比损失:受 MoCo启发,基于记忆的对比损失确保特征空间中不同表型的数据一致性,缓解肿瘤异质性带来的挑战,并增强训练稳定性。MDMIL 的模块化创新有效解决了肿瘤异质性导致的性能下降问题。然而,其主要缺点在于计算过程中可能丢失上下文信息。 这一局限性使得 MDMIL 不太适用于大多数现实世界的临床病理任务,在这些任务中,保留上下文细节至关重要。
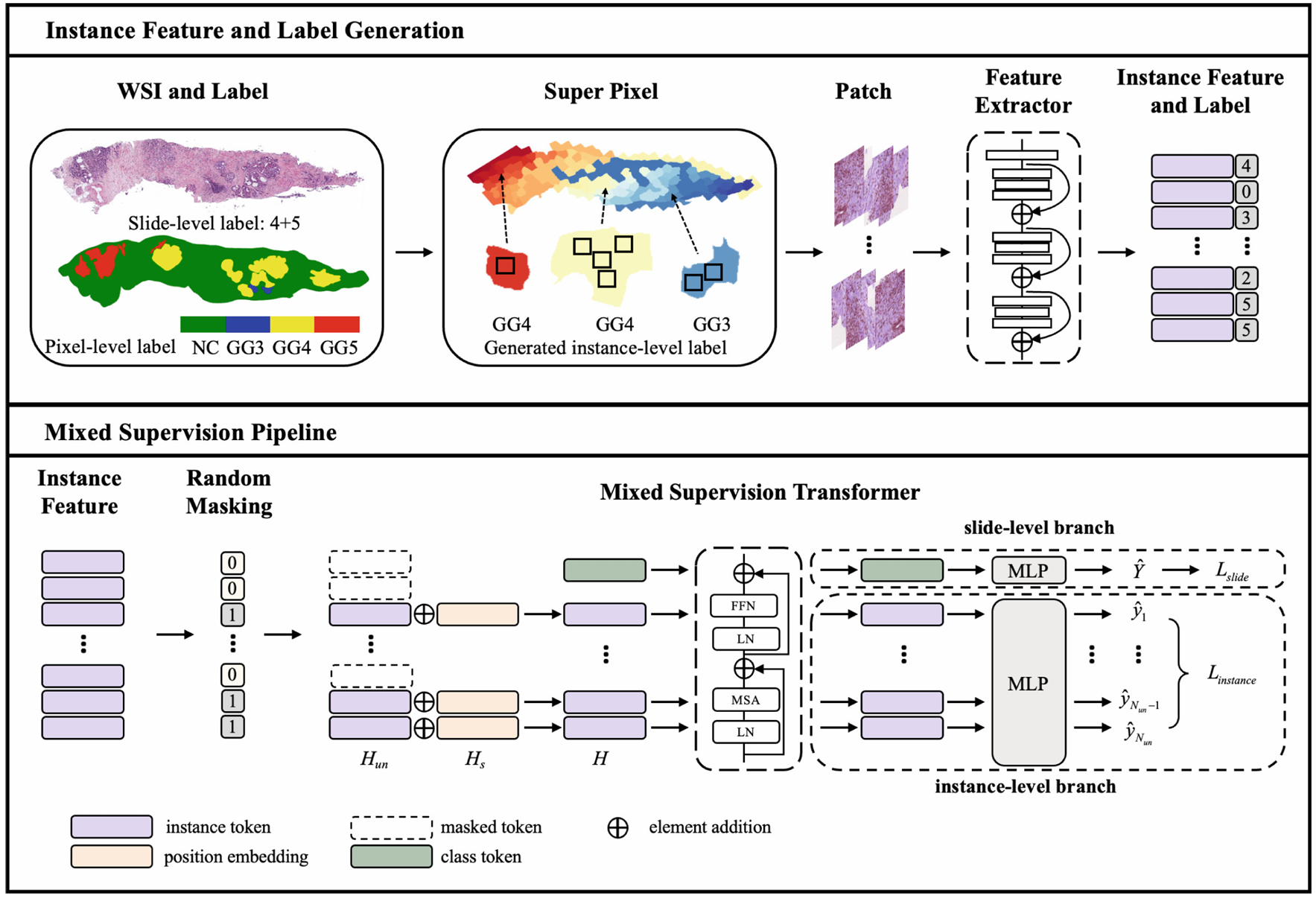
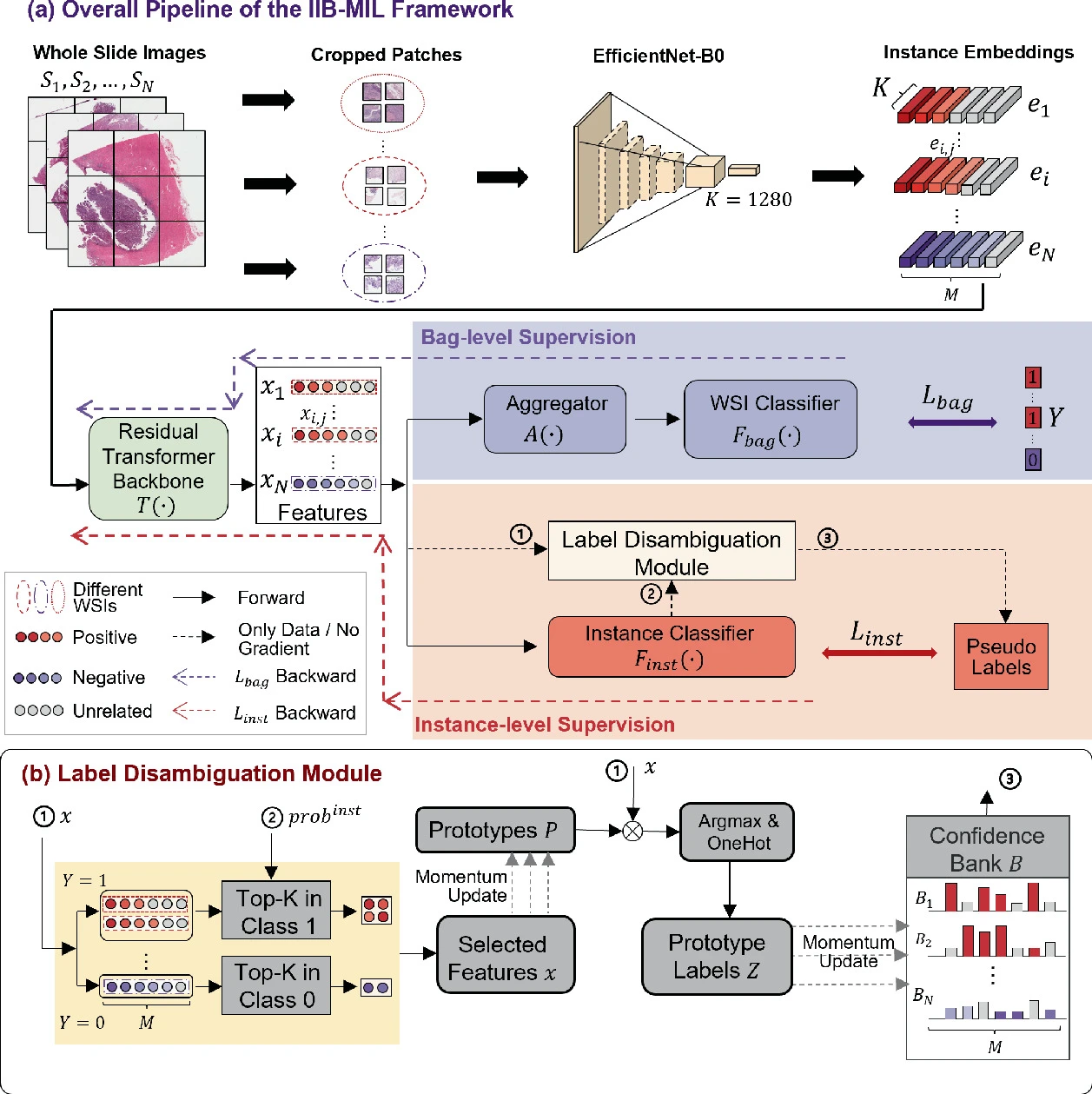
【】IIB-MIL: Integrated Instance-Level and Bag-Level Multiple Instances Learning with Label Disambiguation for Pathological Image Analysis MICCAI2023
IIB-MIL引入了集成实例级和包级多实例学习,该方法结合了包级和实例级监督来解决实例级标签缺失的问题。IIB-MIL 的关键创新是标签消歧模块,该模块旨在纠正分配给实例的不精确标签,从而实现实例级监督。该模块对于增强实例级可用的监督至关重要。在 IIB-MIL 中,提取的实例嵌入通过残差 Transformer 主干传递。标签消歧模块随后生成伪标签,这些伪标签与实例分类器的输出一起用于计算损失,使模型能够协同优化。标签消歧模块由四个主要步骤组成:(1) 获取实例分类器输出;(2) 获取原型标签;(3) 从置信库中获取软标签;(4) 计算实例级损失。IIB-MIL 的核心是通过获取额外的监督来克服多实例学习固有的监督不足,显著增加了可用的训练信息量。 然而,这种方法也给训练过程增加了复杂性。
【】Retrieval-Augmented Multiple Instance Learning NIPS2023
RAM-MIL引入了检索增强的 MIL,受 Verma 等人的启发,旨在解决 MIL 模型在测试集偏离分布(OOD)时性能下降的问题。RAM-MIL 的主要贡献包括:(1)将最优传输(OT)作为包之间的距离度量;(2)证明减少输入维度可以提升 MIL 性能。尽管为 MIL 提出的 OT 距离受限于包内实例数量,但作为最早研究 MIL 偏离分布性能的工作之一,RAM-MIL 引入了一种新的包间距离度量,类似于 FDD所采用的方法。此外,它还提出了一种 RAM-MIL 框架,旨在解决偏离分布问题。
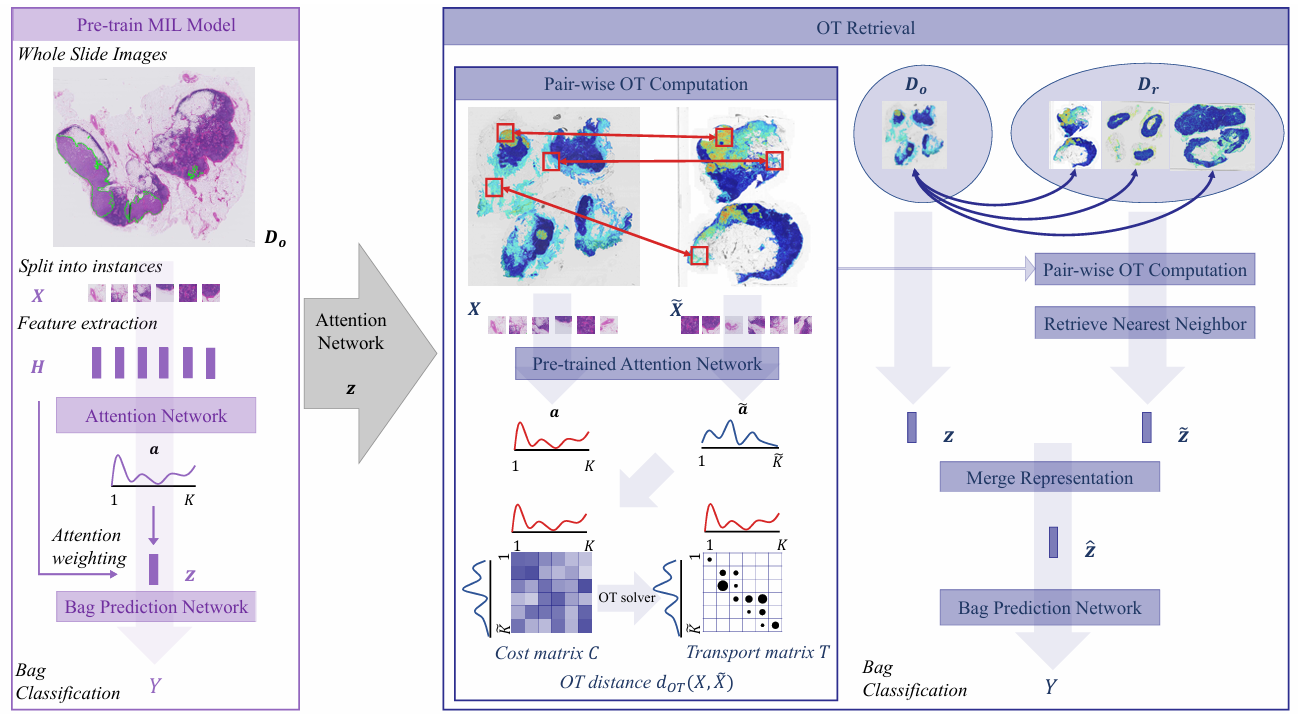
左图:基于注意力机制的多目标学习(MIL)模型在训练集上进行预训练,以生成特征表示和注意力权重。右图:利用预训练的特征和注意力权重,采用最优传输(OT)算法计算包间距离,并据此从检索集中选择最近邻包。训练包的特征随后与其检索到的包的特征合并,并将合并后的特征作为包分类器的输入特征。
【】Transformer-Based Video-Structure Multi-Instance Learning for Whole Slide Image Classification AAAI2024
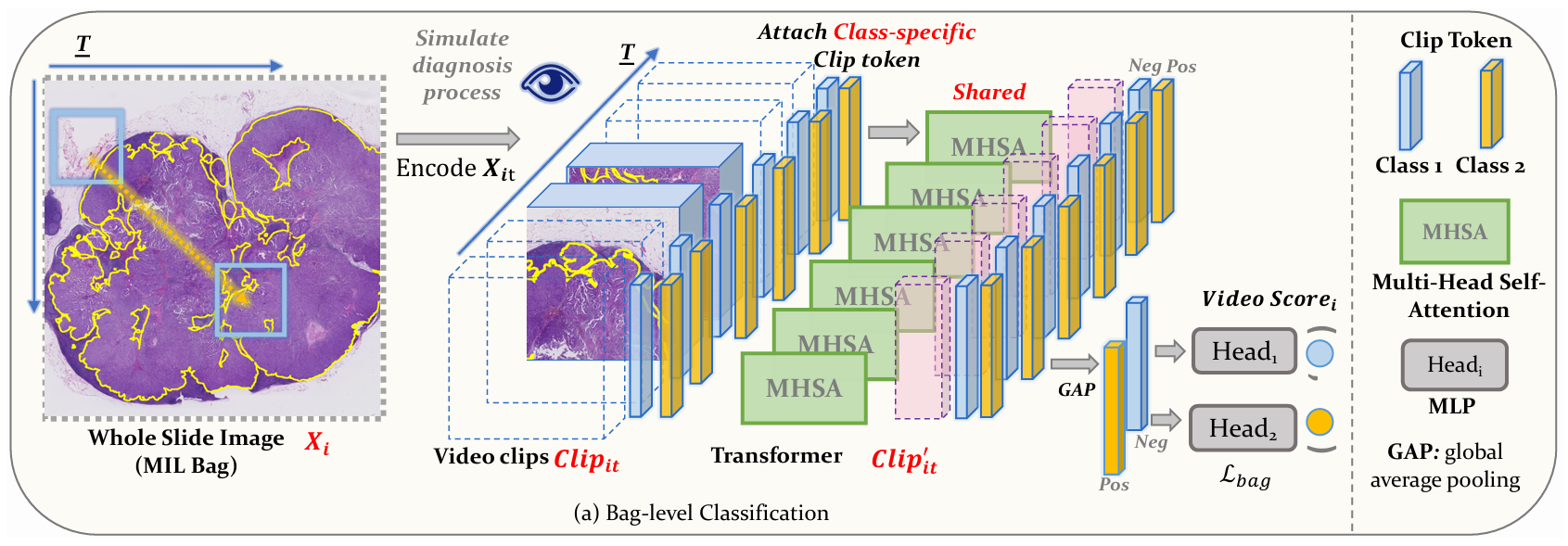
VINO提出了一种独特的 MIL 框架,以实现 MIL 的端到端学习并捕获上下文信息。它将 WSIs 划分为多个 patch,模拟病理学家审查 WSIs 的过程。这些 patch 被建模为反映观察过程的视频。然后,将视频输入到多头自注意力机制中,直接获取表示不同类别语义信息的 clip token 以及交互计算得到的 clip 特征。这种新颖的方法模拟了病理学家的诊断过程,摆脱了传统的两阶段 MIL 方法。它实现了端到端学习,同时增强了模型捕获上下文信息的能力。
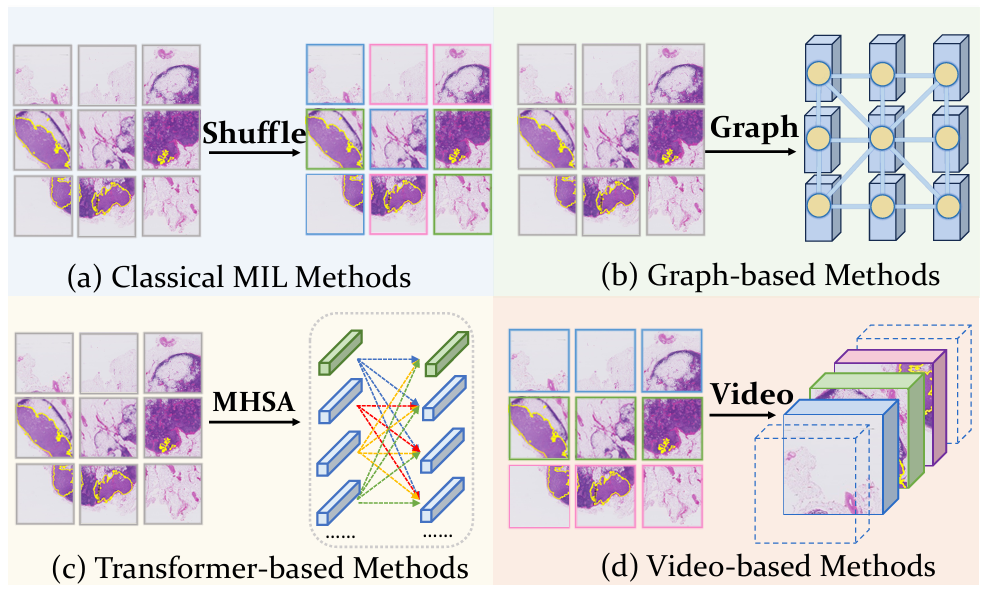 我们方法的动机。(a) 经典混合图像学习 (MIL) 方法。两阶段方法包括将无序实例编码为特征并聚合特征。(b) 基于图的方法。图神经网络 (GNN) 将特征建模为节点,并在相邻节点之间建立边,以利用图卷积求解。(c) 基于 Transformer 的方法。计算特征之间的相对性,保留全切片图像 (WSI) 的空间和形态信息。(d) 基于视频的方法。从全切片图像 (WSI) 构建一系列合成视频片段。
我们方法的动机。(a) 经典混合图像学习 (MIL) 方法。两阶段方法包括将无序实例编码为特征并聚合特征。(b) 基于图的方法。图神经网络 (GNN) 将特征建模为节点,并在相邻节点之间建立边,以利用图卷积求解。(c) 基于 Transformer 的方法。计算特征之间的相对性,保留全切片图像 (WSI) 的空间和形态信息。(d) 基于视频的方法。从全切片图像 (WSI) 构建一系列合成视频片段。
【】A whole-slide foundation model for digital pathology from real-world data Nature2024
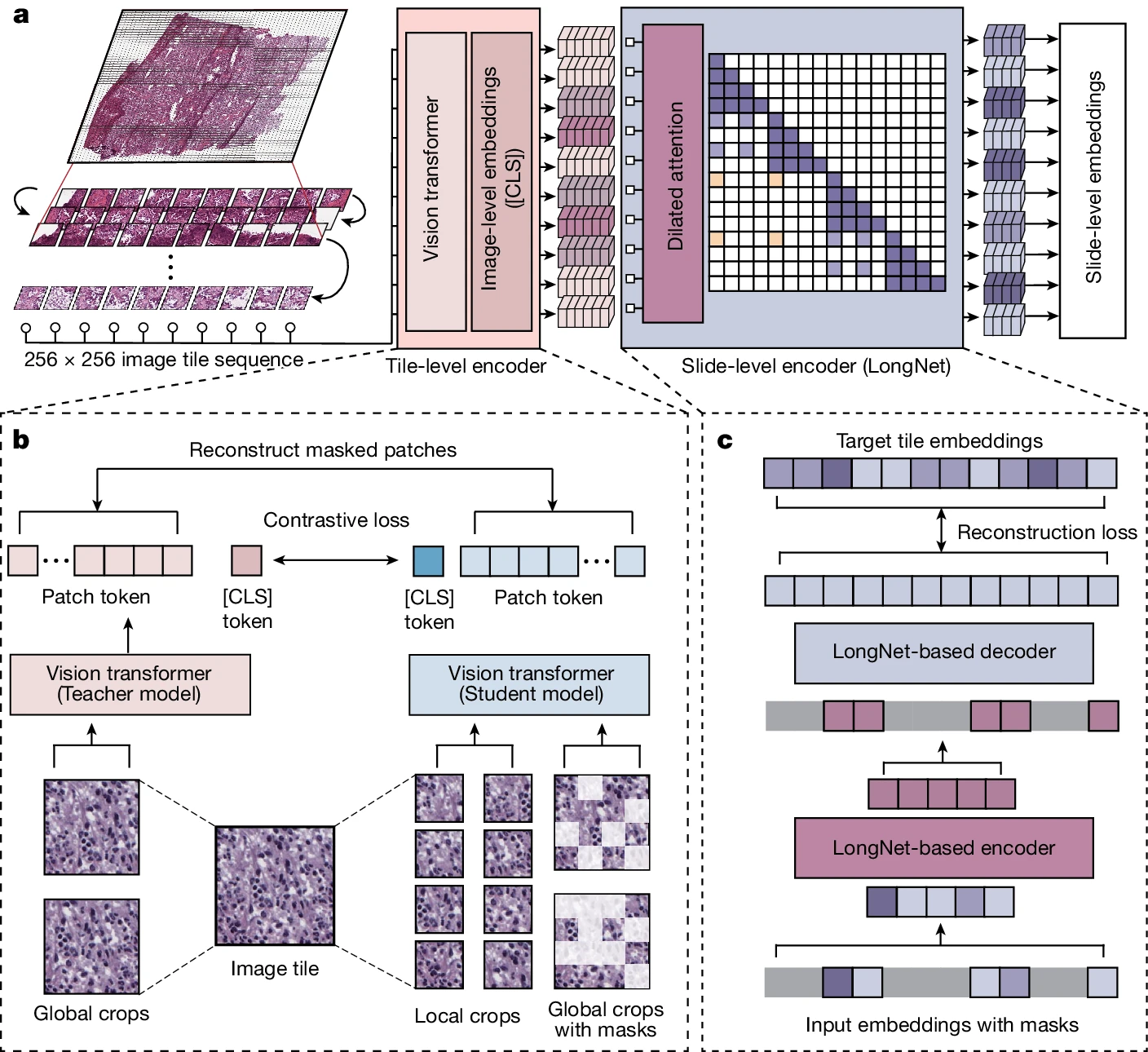
Prov-GigaPath开发了一个全切片病理基础模型,该模型在来自美国大型医疗网络普罗维登斯(包含 28 个癌症中心)的 171,189 张 WSI 上预训练了 130 亿个 256×256 病理图像块。这个庞大的数据集包括超过 30,000 名患者,涵盖 31 种主要组织类型。GigaPath 采用视觉 Transformer 架构进行吉兆像素病理切片的预训练,其重大创新是将 LongNet 方法应用于数字病理学。LongNet 是 Transformer 的一种变体,实现了线性计算复杂度和对数依赖性,允许将序列标记长度扩展到超过十亿而不影响短序列性能。这种架构非常适合超长序列,与 CPATH 的需求完美契合。Prov-GigaPath 遵循传统的 MIL 方法,采用特征提取和特征聚合架构。局部特征提取器使用 DINO v2 预训练,这是最先进的图像自监督学习(SSL)框架,而特征聚合则通过掩码自编码器预训练和 LongNet 实现。 通过将 MIL 与多种先进技术相结合,并在大规模数据集上验证其性能,Prov-GigaPath 在多种临床下游任务(如癌症亚型分类和突变预测)中展现出优异的结果。它还证明,利用大规模预训练模型进行 MIL 对于 CPATH 中的实际临床数据来说是可行的。
【】Boosting Multiple Instance Learning Models for Whole Slide Image Classification: A Model-Agnostic Framework Based on Counterfactual Inference AAAI2024
CIMIL提出了一种基于反事实推理的框架来增强 MIL 模型,这是一个与模型无关的框架,旨在提升 MIL 在包级和实例级的表现。它引入了三种关键策略:(1) 基于反事实推理的子包评估,(2) 分层实例搜索,以及 (3) 特征优化。具体来说,子包评估通过移除每个子包并观察分类结果的变化来评估其影响,从而提高模型的可解释性和分类性能。分层实例搜索在子包级和实例级进行搜索,利用前一步的结果来准确识别关键实例,并为后续的实例级分类器训练生成精确的伪标签。特征优化通过训练一个实例级分类器来生成实例嵌入,然后将这些嵌入用于替换初始特征,进一步提升模型的性能。
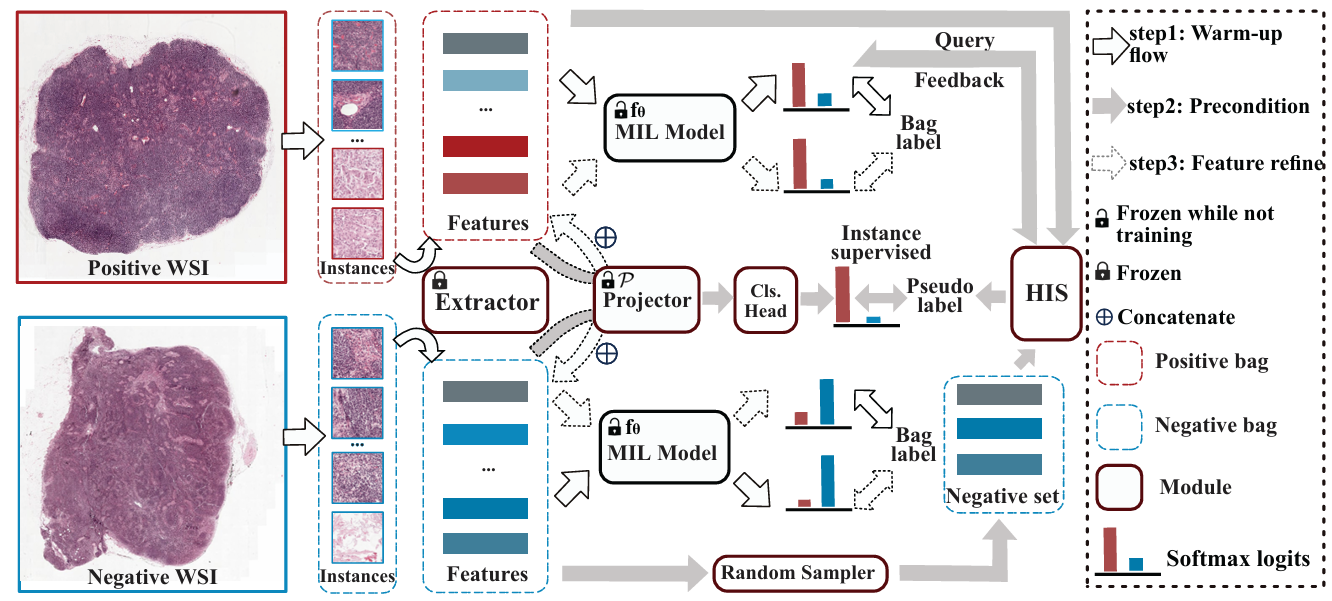
【】Structured State Space Models for Multiple Instance Learning in Digital Pathology MICCAI2023
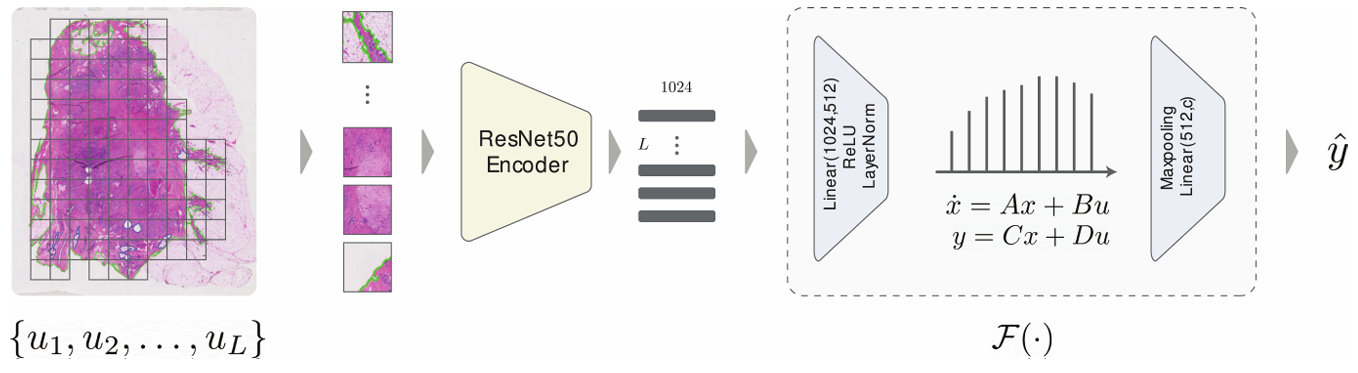
状态空间多示例学习首次将结构化状态空间模型(SSM)这一新兴序列建模方法作为多示例学习(MIL)学习器,以高效地建模长序列。SSM 对于长序列建模特别有效。它们的实验表明,SSM 与 MIL 的结合在各种下游任务中表现出显著的竞争力。
4.2. 迈向更强的特征表示
更强的特征提取技术一直是 CPATH 和更广泛的计算机视觉领域的关键追求。基于 MIL 的 CPATH 方法充分利用了 MIL 的优势,实现了超越其他方法的特征提取能力,同时表现出与各种先进特征提取技术的高兼容性。我们将这些工作分为两部分:自监督发现和多模态洞察融合。前者将 MIL 与 SSL 方法结合,在不依赖标签的情况下实现更优的特征表示,从而使模型能够更好地应对 CPATH 领域面临的数据标注挑战。后者将数据获取范围扩展至 WSI 之外,转而利用 CPATH 领域内的各种可用信息来源,如病理报告和基因测序数据,通过多模态方法进行特征提取。这使得模型能够实现超越单模态方法的特征提取能力。本节涉及的工作的更多信息显示在表中。
4.2.1. 自监督发现
能够利用大量未标记数据进行预训练是 CPATH 领域的诱人前景。幸运的是,MIL 方法与自监督学习(SSL)高度兼容。SSL 在 MIL 中的发展紧密跟随时间上的进步。在 2020 年之前,NIC和 FS-GCN-MIL等方法探索了对比学习、变分自编码器和生成对抗网络。在 2020 年 SimCLR发布后,CPATH 领域开始采用对比学习框架,这些框架在深度学习和计算机视觉中已经获得了认可。
RetCCL基于 MoCo v2,引入了一种基于距离的聚类方法。在 RetCCL 的基础上,CAMIL直接从全切片图像(WSIs)中实现了对连续生物标志物的回归任务。CTransPath扩展了 MoCo v3,将 Transformer 集成到 SSL MIL 框架中,以应对在集成多样化特征时面临的挑战。HIPT利用 DINO v1,引入了分层 ViT,而 UNI基于 DINO v2,在超过 1 亿张图像上预训练了模型。也有一些研究偏离了直接将成熟框架应用于病理特定挑战的做法。一个显著的例子是 ItS2CLR,它旨在通过利用从包级标注中得到的实例级伪标签来增强传统对比学习方法处理类别不平衡的能力。这种方法通过提升学习到的表征并捕捉类间差异来实现这一目标。
总之,SSL 方法在 MIL 框架中的发展进程与深度学习和计算机视觉中对比学习的进步密切相关。随着对比学习的不断发展,预计将出现更多突破性成果,将成熟框架应用于 MIL 和 CPATH 挑战。图概述了将要讨论的工作。
【】Neural Image Compression for Gigapixel Histopathology Image Analysis TPAMI2021
NIC提出了神经图像压缩方法来解决 WSI 过大的问题,其灵感来源于认知机制。人类观察者可以用几句话描述复杂的视觉模式,而不是详细说明每个像素。这个概念可以转化为深度学习,其中编码器使用低维嵌入向量来描述图像块,忽略不相关的细节。与图像块选择方法相比,压缩 WSI 在理论上通过训练确保保留关键信息,实现显著的压缩率。NIC 使用三种方法实现 WSI 压缩:变分自编码器、对比训练和双向生成对抗网络,这代表了 2019 年的一项前沿尝试。不幸的是,NIC 没有结合这些方法,而且当时深度学习特征提取能力还不够先进,无法支持像 NIC 那样直接从 WSI 中获取包表示的端到端方法。
【】Predicting Lymph Node Metastasis Using Histopathological Images Based on Multiple Instance Learning With Deep Graph Convolution CVPR2020
FS-GCN-MIL提出了特征选择图卷积网络多实例学习(Feature-selection GCN MIL),该方法将变分自编码器(VAE)、生成对抗网络(GAN)、特征选择(FS)和图卷积网络(GCN)集成到多实例学习(MIL)中,解决了大规模全切片图像(WSIs)的挑战以及淋巴结转移预测中注释的高成本。FS-GCN-MIL 的流程包括图像预处理、实例级特征提取、特征选择和包级分类。VAE-GAN 用于特征提取,然后通过 FS 识别判别性特征,GCN 聚合实例嵌入进行二分类。该方法需要病理学家手动标注肿瘤区域的感兴趣区域(ROIs)。为了解决医学图像中训练数据不足的挑战,FS-GCN-MIL 通过选择最具判别性的实例级特征来减少冗余,简化了模型的学习任务。基于直方图的技术连接实例级和包级特征,使用最大均值差异评估实例重要性。
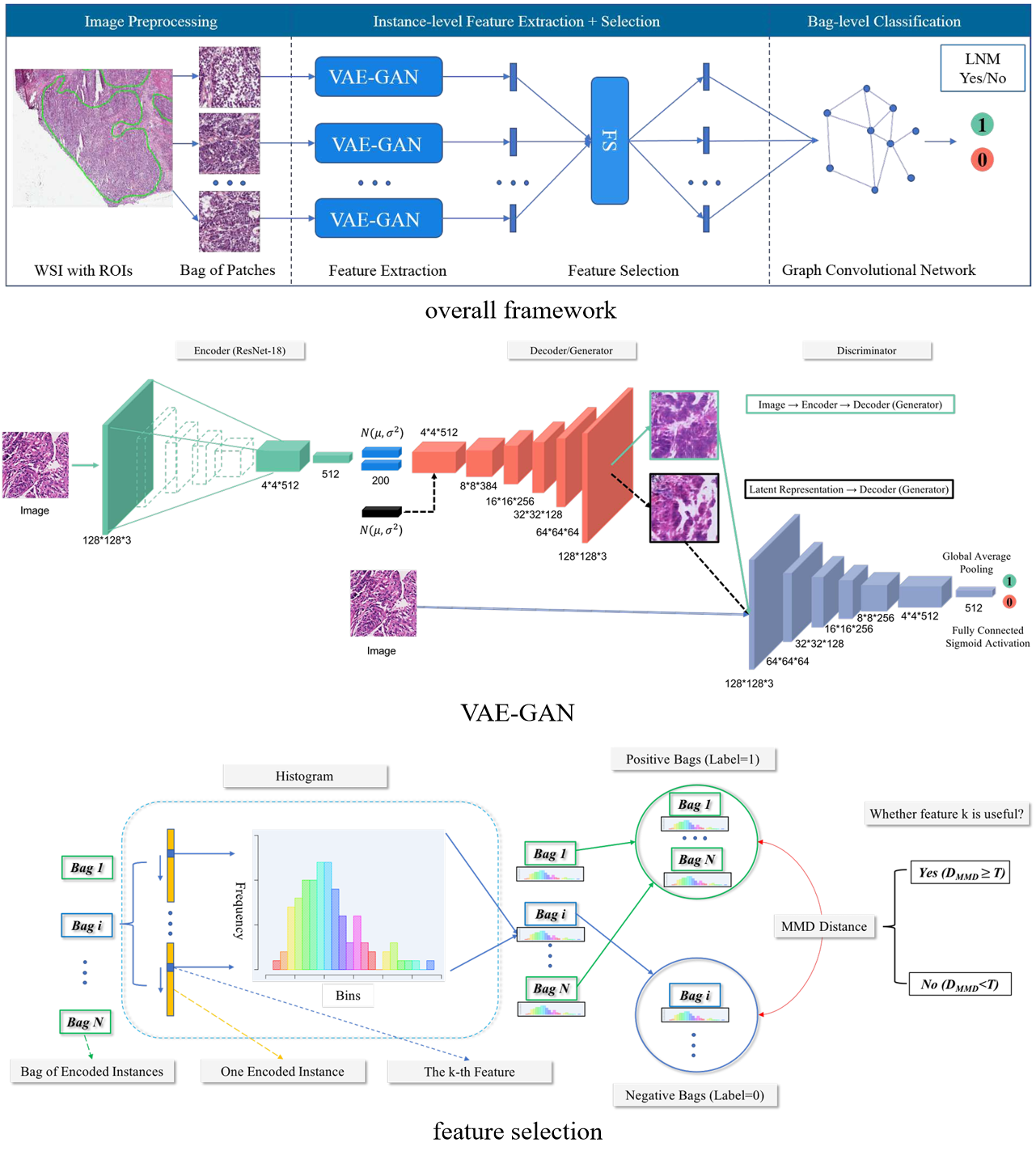
FS-GCN-MIL 是首批将自监督学习(SSL)应用于 MIL 特征提取的方法之一。其结合特征选择和 GCN 显著推动了 MIL 在癌症淋巴结转移研究中的发展
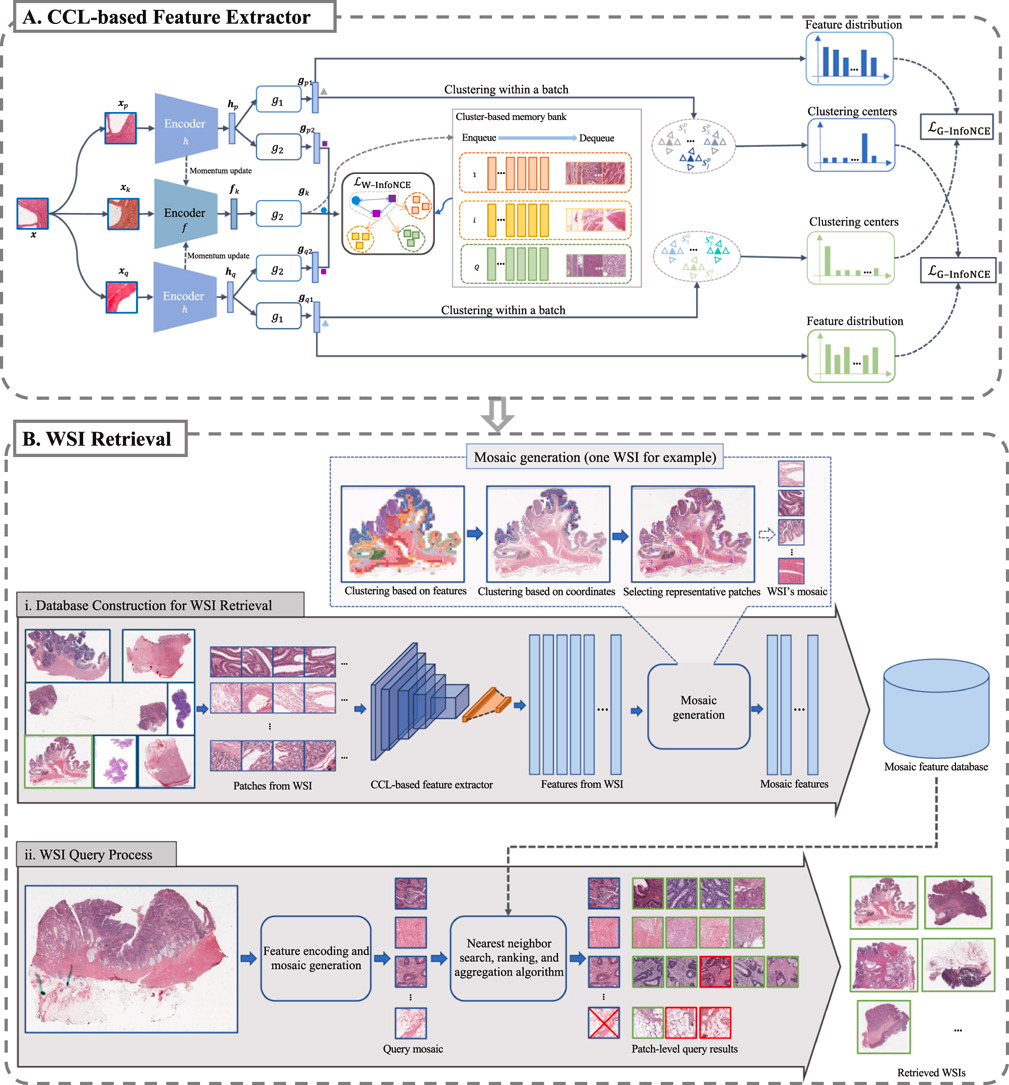
【】RetCCL: Clustering-guided contrastive learning for whole-slide image retrieval MIA2023
RetCCL引入了检索与聚类引导对比学习的框架,用于实现鲁棒且精确的 WSI 级图像检索。RetCCL 包含两个阶段:阶段 A 是基于 CCL 的特征提取器,阶段 B 是用于 WSI 检索的排序与聚合算法。此外,RetCCL 通过突出 WSI 内的诊断子区域,增强了可解释性,为 WSI 检索过程背后的搜索机制提供了洞见。具体来说,在阶段 A 中,新的输入特征被整合到语义最相似的子记忆库中,从而提高了存储特征的一致性。该阶段还利用加权 InfoNCE 和组级 InfoNCE 165来提取鲁棒且通用的特征。阶段 B 涉及构建用于 WSI 检索的离线数据库和在线查询过程。虽然实验结果并未显示出相较于其基础模型 MoCo v2有显著的性能提升,但基于 CCL 的特征提取方法为实现更强的特征表示提供了宝贵的见解。
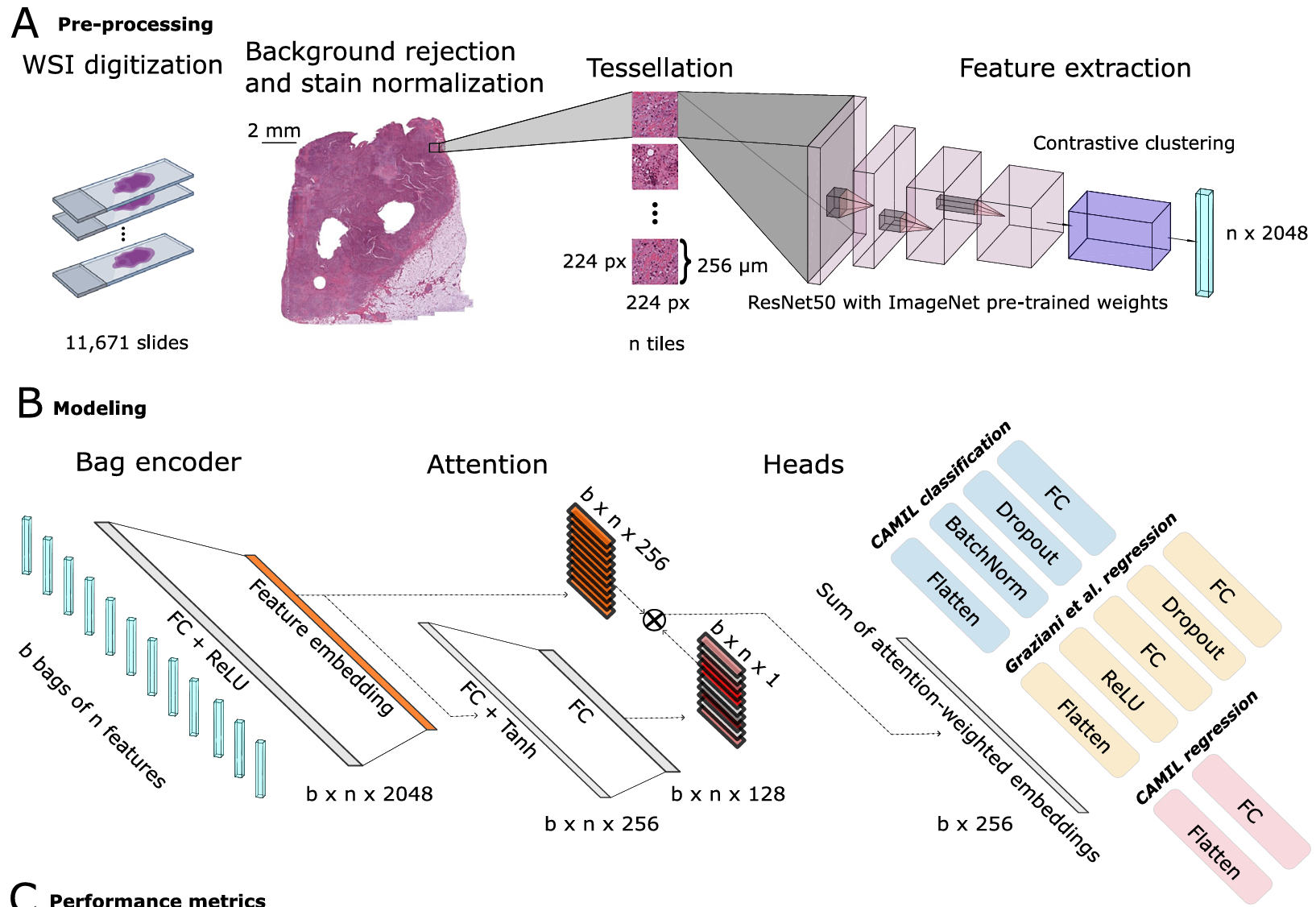
【】Regression-based deep-learning predicts molecular biomarkers from pathology slides Nature Communications2024
CAMIL提出了一种基于对比聚类注意力的多实例学习模型,能够直接从全切片图像(WSIs)预测连续生物标志物。实验表明,基于回归的预测分数比基于分类的分数具有更高的预后价值。CAMIL 包含三个主要步骤:(1)图像预处理;(2)特征提取;(3)基于分类和回归的注意力机制进行分数聚合,从而实现患者级别的预测。在预处理阶段,CAML 采用预训练的 ImageNet 模型和 RetCCL通过自监督学习(SSL)进行特征提取。在后续阶段,基于注意力的多实例学习处理上一步提取的实例嵌入。关键创新在于最后一步,其中使用了三个独立训练的回归头。大量实验证实,多实例学习在连续变量的预测中取得了优异的性能。
【】Transformer-based unsupervised contrastive learning for histopathological image classification MIA2022
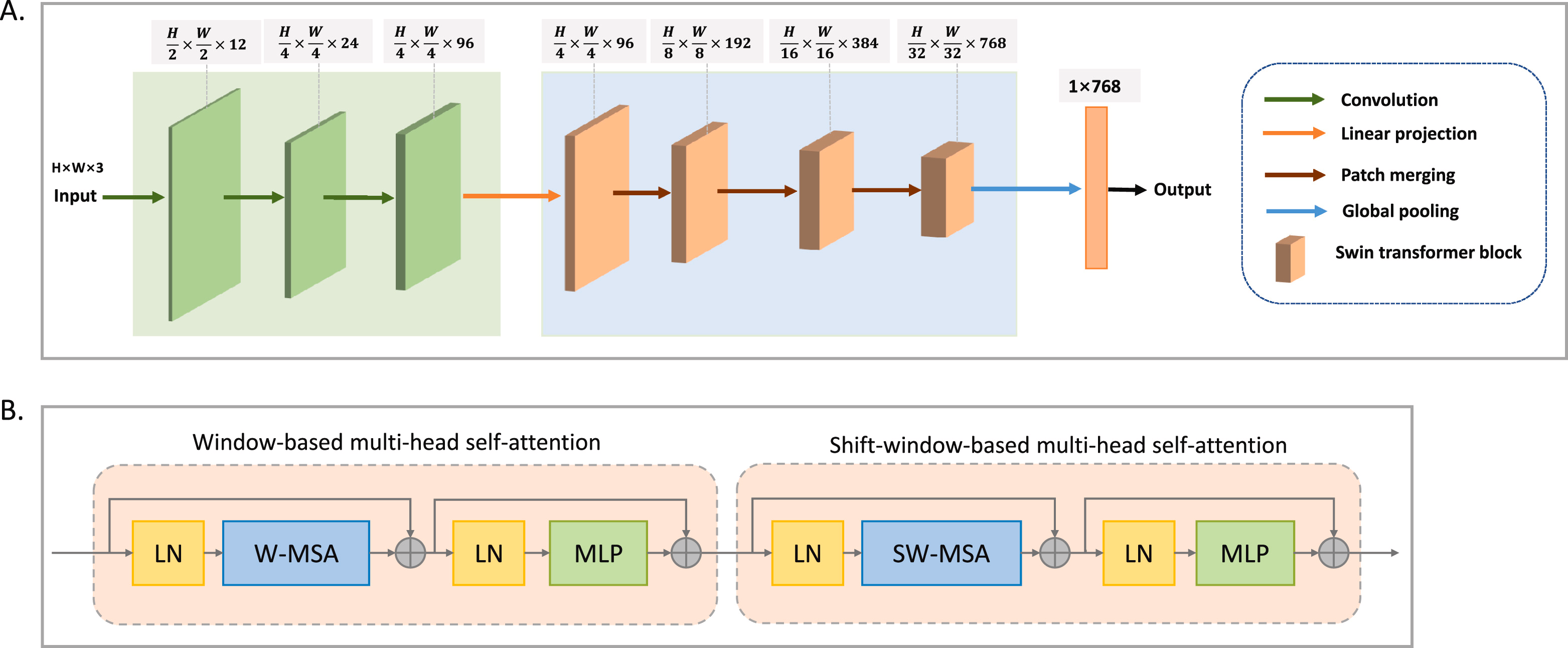
Ctranspath在 CPATH 领域实现了显著进步,通过利用自监督学习(SSL)减少了对 CPATH 任务中人工标注的依赖。它引入了一种名为语义相关对比学习(SRCL)的新型 SSL 策略,这是一个基于 MoCo v3的增强框架。SRCL 将具有相似视觉概念的多组正例实例进行对齐,从而增加了正例样本的多样性,并生成了更具信息量的表示。CtransPath 采用了一种混合模型,结合了卷积神经网络(CNN)和多尺度 Swin Transformer,能够在大规模无标签数据集上进行预训练。作为一个协同的局部-全局特征提取器,它学习到更适合组织病理学图像分析任务的一般特征表示。
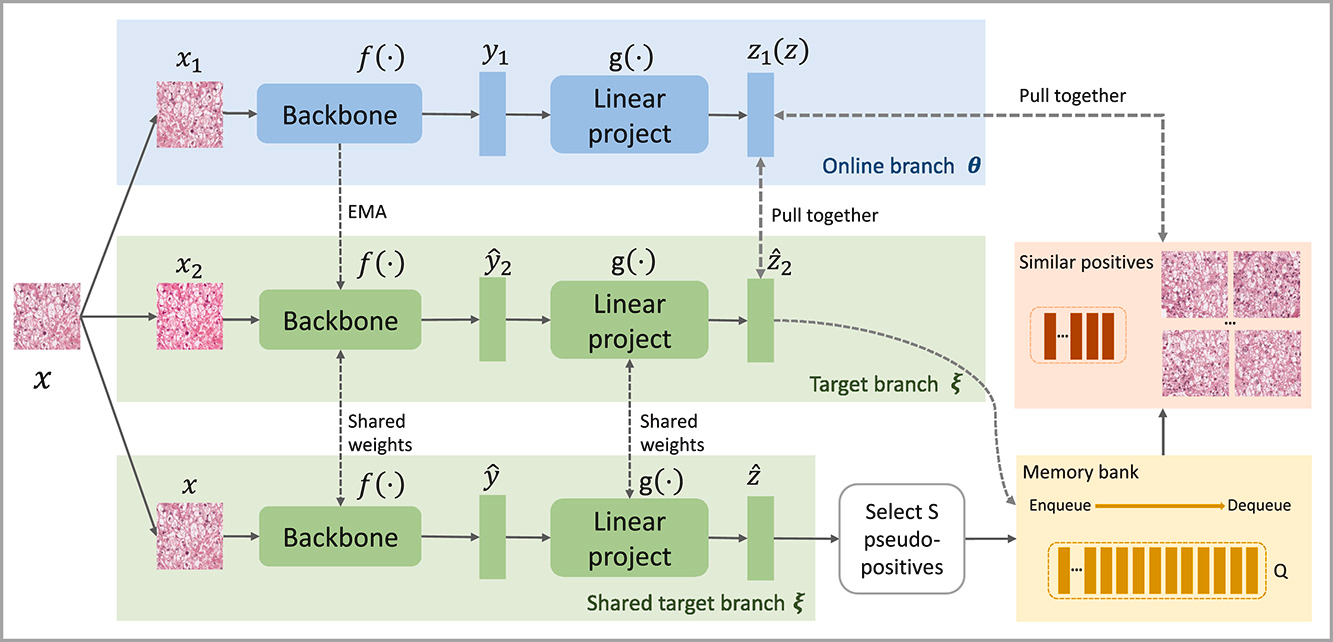
概述了我们提出的用于组织病理图像应用的SRCL方法。该方法是基于MoCo v3的改进框架。负样本存储在每个小批量中,正样本则来自两条路径:(i)对当前输入图像进行两次数据增强;(ii)通过将当前输入特征与存储库中的样本进行比较,识别出语义最相关的S个图像。基于上述设计,我们提出了一种语义相关的对比损失来指导网络训练。
【】Scaling Vision Transformers to Gigapixel Images via Hierarchical Self-Supervised Learning CVPR2020
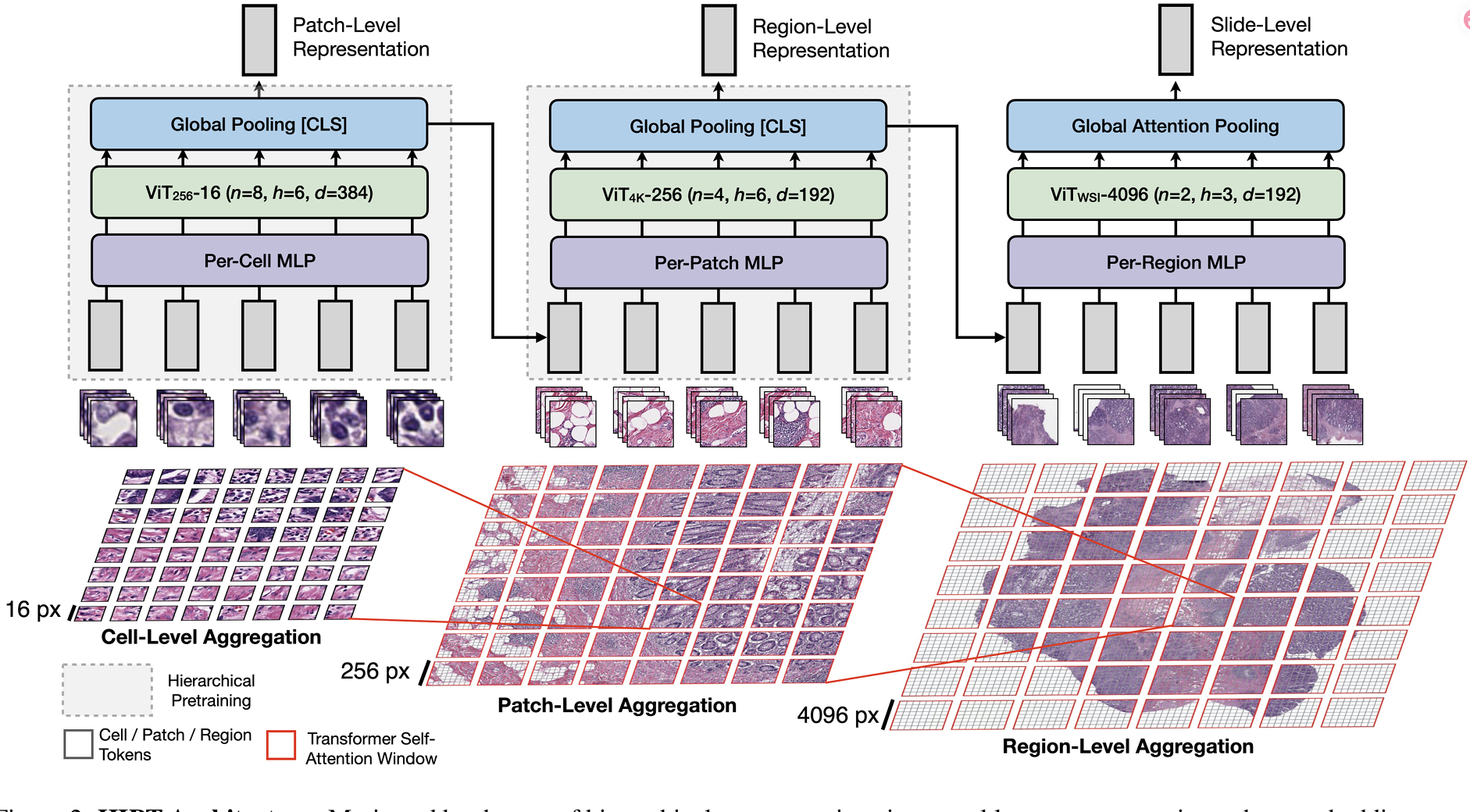
HIPT提出了层次化图像金字塔 Transformer,用于视觉标记的层次化聚合和基于吉兆像素级病理图像的预训练。HIPT 基于一个核心概念:对于给定的放大倍数,视觉标记在特定尺度上固定。HIPT 的结构由三个组件构成:细胞级、补丁级和区域级表示,类似于自然语言处理中的层次化表示(例如,字符级、词级、句子级和段落级表示)。HIPT 引入了两个关键创新:(1) 将学习鲁棒 WSI 表示的任务分解为层次相关的子表示,每个子表示都可以通过 SSL 进行学习,(2) 利用 DINO通过 SSL 对每个聚合层进行预训练。这种层次化方法反映了生物学和医学现象,其中存在分层关系,例如 DNA 基序影响蛋白质结构、基因表达和外显子序列中的遗传性状。HIPT 通过整合机制洞察与先进技术解决方案,代表了对自监督切片级表示学习的重要进展。
【】Towards a general-purpose foundation model for computational pathology Nature Medicine, 2024
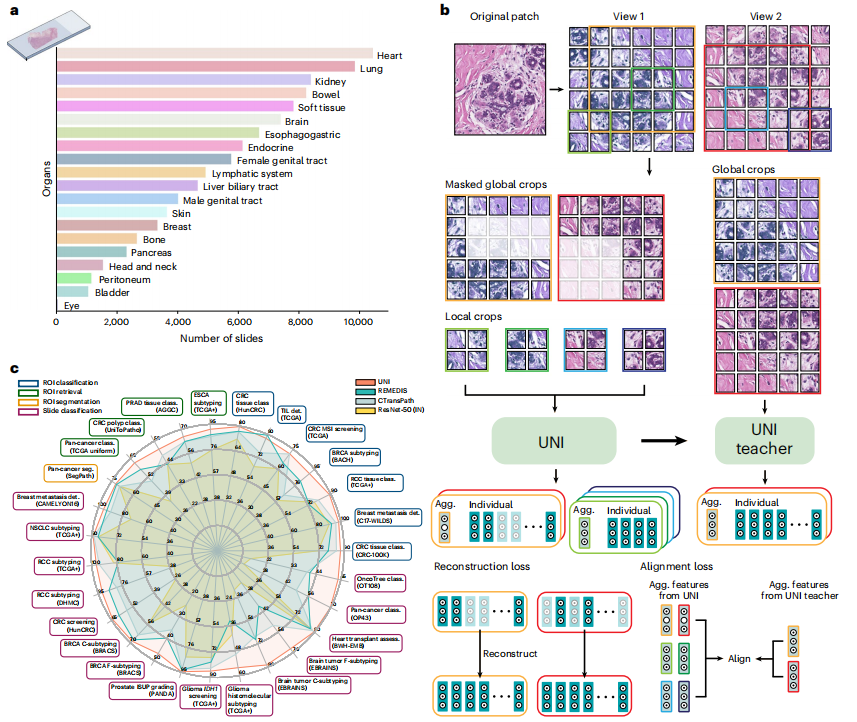
UNI是一种通用的病理自监督模型,在超过 1 亿张图像上进行了预训练。尽管已有针对公开 CPATH 数据集提出的几种 SSL 预训练图像编码器,但 UNI 代表了在多种不同组织类型中对该类方法进行首次广泛开发和评估。基于 ViT 和 DINO v2,UNI 在超过 10 万份诊断性 H&E 染色 WSI 图像(超过 77 TB 数据)上进行了预训练,这些图像涵盖了 20 种主要组织类型。随后,它在多个诊断领域的 34 项任务上进行了评估。结果表明,UNI 在 ROI 级分类、切片级分类、分割和疾病亚型识别方面表现出优越性能。通过利用大量数据和实验,UNI 突出了基于 SSL 的特征提取器在 CPATH 中的显著潜力,为数据高效且可泛化的 AI 模型奠定了坚实基础,并在研究和临床应用中拓展了 CPATH 的边界。
【】Multiple Instance Learning via Iterative Self-Paced Supervised Contrastive Learning CVPR2023
ItS2CLR引入了用于 MIL 表示的迭代自步调监督对比学习。为解决传统对比 SSL (CSSL) 方法因数据不平衡导致性能下降的问题,ItS2CLR 利用从包级标签派生的实例级伪标签。该框架通过监督对比学习迭代优化实例表示,并由自步调学习 (SPL) 策略指导以确保伪标签的可靠性。具体而言,该框架首先基于 CSSL 进行特征初始化,采用 DSMIL汇总器获取实例级概率,并在优化特征提取器、重新计算伪标签以及训练汇总器之间交替进行。这一迭代过程提升了实例级表示的粒度,同时提高了包级分类性能和伪标签质量。ItS2CLR 代表了 MIL 中特征提取的优化技术,有效弥合了包级监督与实例级表示学习之间的差距,推动了 CPATH 中特征提取方法的发展。
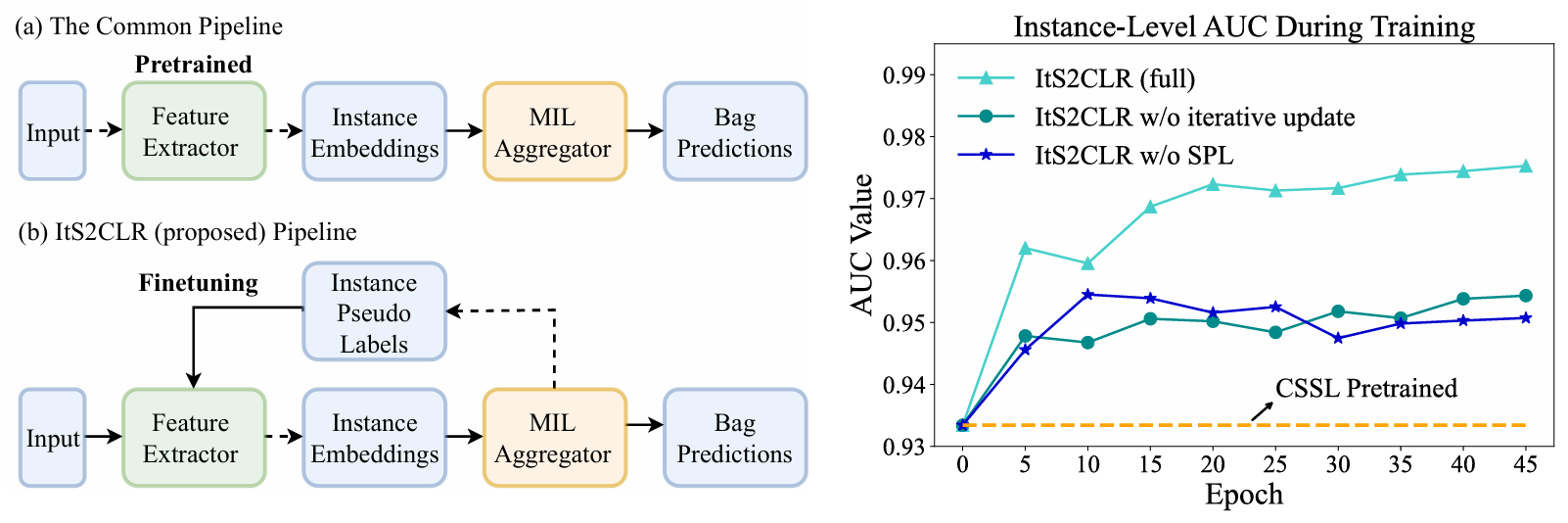
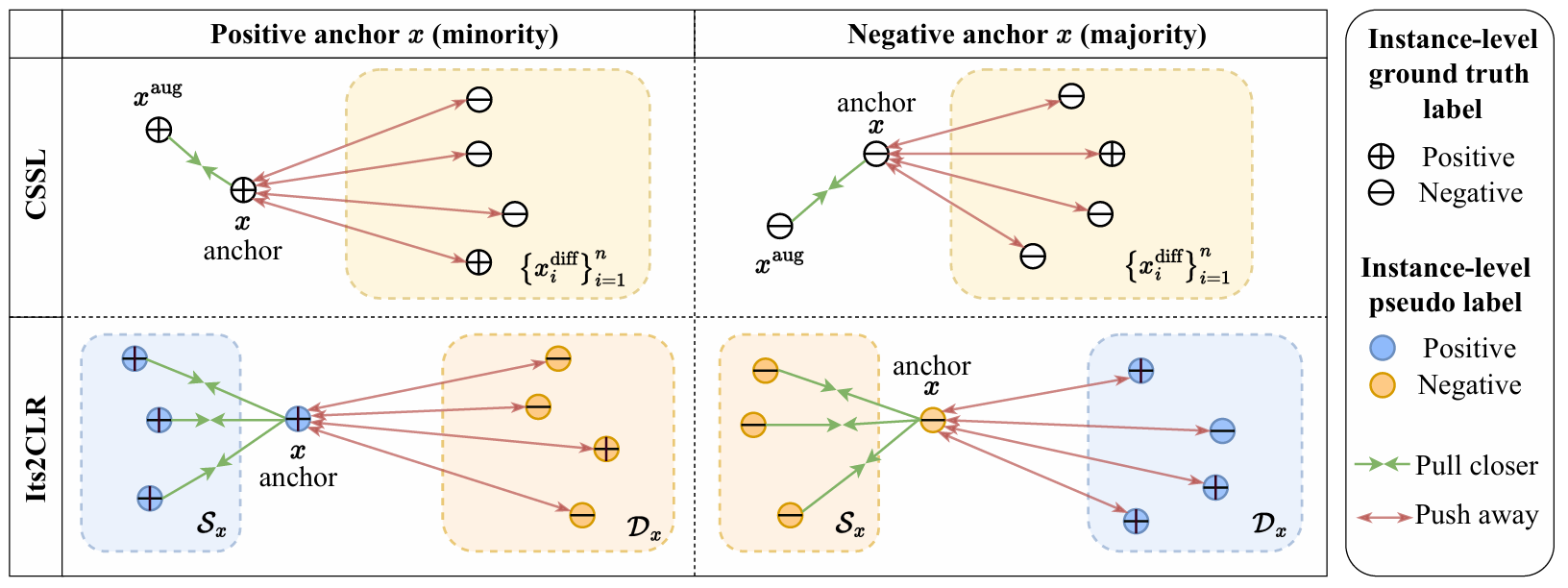 上图:在对比自监督学习 (CSSL) 中,实例 x 的表示被拉近到其随机增强 xaug,并远离其他随机选择的实例的表示。在许多与医学诊断相关的 MIL 数据集中,大多数实例都是阴性,因此 CSSL 主要使阴性实例的表示远离(右图)。下图:我们提出的框架 ItS2CLR 应用了第 3.1 节中描述的监督对比学习方法。实例级伪标签用于构建与 x 对应的正样本对集合 Sx 和负样本对集合 Dx。实例 x 的表示被拉近到Sx 中的表示,并远离 Dx 中的表示。伪标签集根据第 3.2 节中的自步采样策略迭代构建。
上图:在对比自监督学习 (CSSL) 中,实例 x 的表示被拉近到其随机增强 xaug,并远离其他随机选择的实例的表示。在许多与医学诊断相关的 MIL 数据集中,大多数实例都是阴性,因此 CSSL 主要使阴性实例的表示远离(右图)。下图:我们提出的框架 ItS2CLR 应用了第 3.1 节中描述的监督对比学习方法。实例级伪标签用于构建与 x 对应的正样本对集合 Sx 和负样本对集合 Dx。实例 x 的表示被拉近到Sx 中的表示,并远离 Dx 中的表示。伪标签集根据第 3.2 节中的自步采样策略迭代构建。
4.2.2. 多模态信息融合
随着 MIL 技术的不断进步,研究人员日益达成共识:仅依赖 WSI 提供的有限信息可能无法满足下游任务的多样化需求。因此,融合多模态信息以实现更全面的特征表示已成为近年来备受关注的研究重点。目前,整合其他模态数据主要有两种主流方法:模态对齐和模态聚合。
(a)模态对齐
模态对齐以 CLIP 等研究为例。这种方法的核心理念是利用其他模态的数据来指导模型学习更好的图像特征,而在推理过程中无需额外输入模态信息。相比之下,模态聚合则直接将其他模态作为模型的额外输入,跨模态提取特征以增强表示。
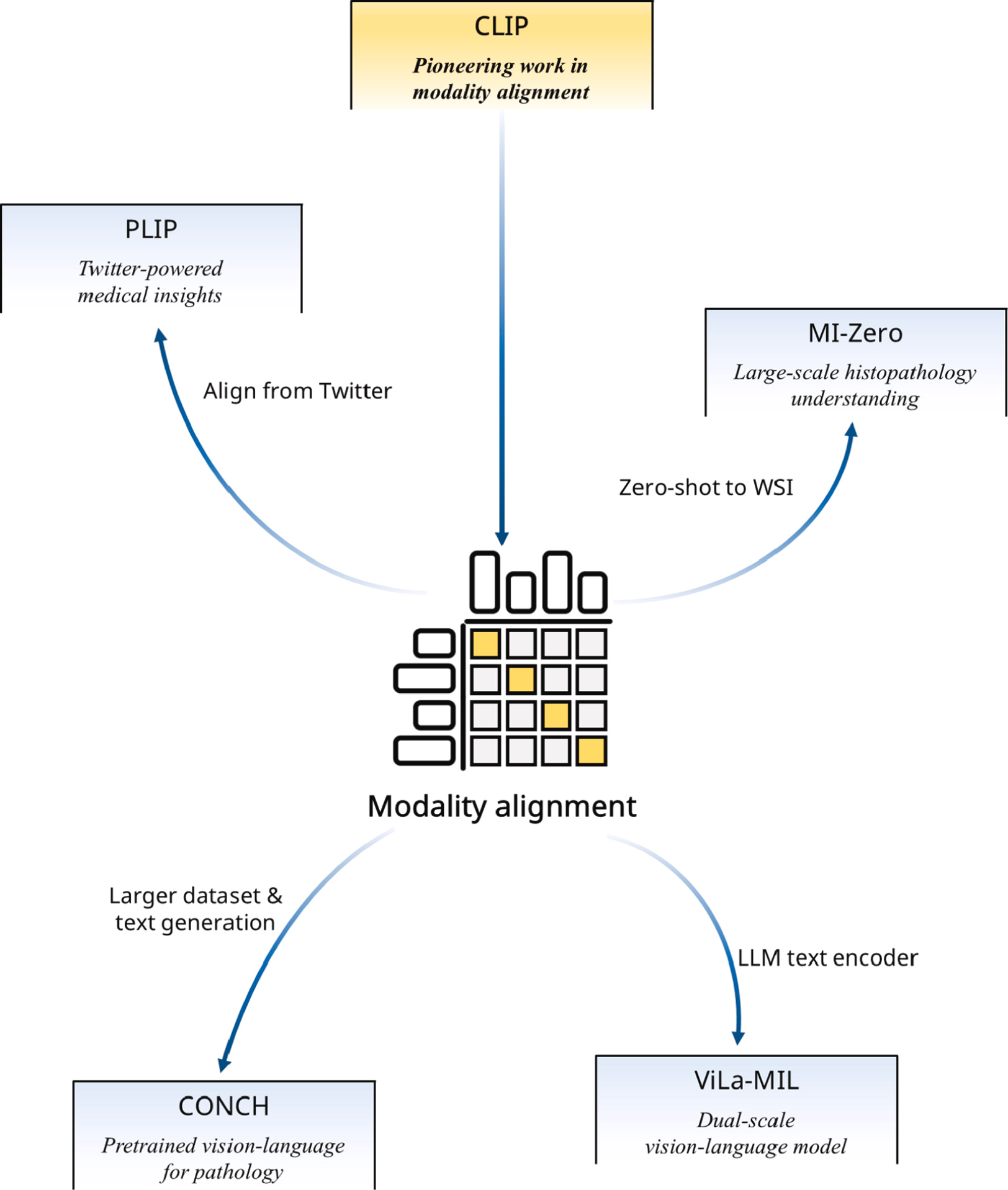
自 2021 年 CLIP 发布以来,其模态对齐范式获得了广泛关注,而早期 MIL 研究也采用了这种方法。与图像相比,文本往往蕴含更丰富的人类先验知识。PLIP 利用与 CLIP 类似的方法,从 Twitter 中提取了大量图像-文本对以改进特征对齐,为后续研究提供了宝贵的数据收集策略。MI-Zero将基于 CLIP 的方法扩展到 WSIs,使预训练编码器能够执行多种下游诊断任务,并显著扩展了零样本迁移的数据库。在此基础上,CONCH进一步将数据集扩展到超过 117 万张图像-文本对,并引入了文本生成能力,同时进行图像-文本对齐,优化了图像表示。ViLa-MIL通过用大型语言模型(LLM)嵌入替换文本编码器,推进了这些工作,展示了更优越的特征表示,并有效地将流行的 LLMs 与 MIL 集成。图展示了下面将要介绍的工作概述。
【】A visual--language foundation model for pathology image analysis using medical Twitter Nature Medicine2023
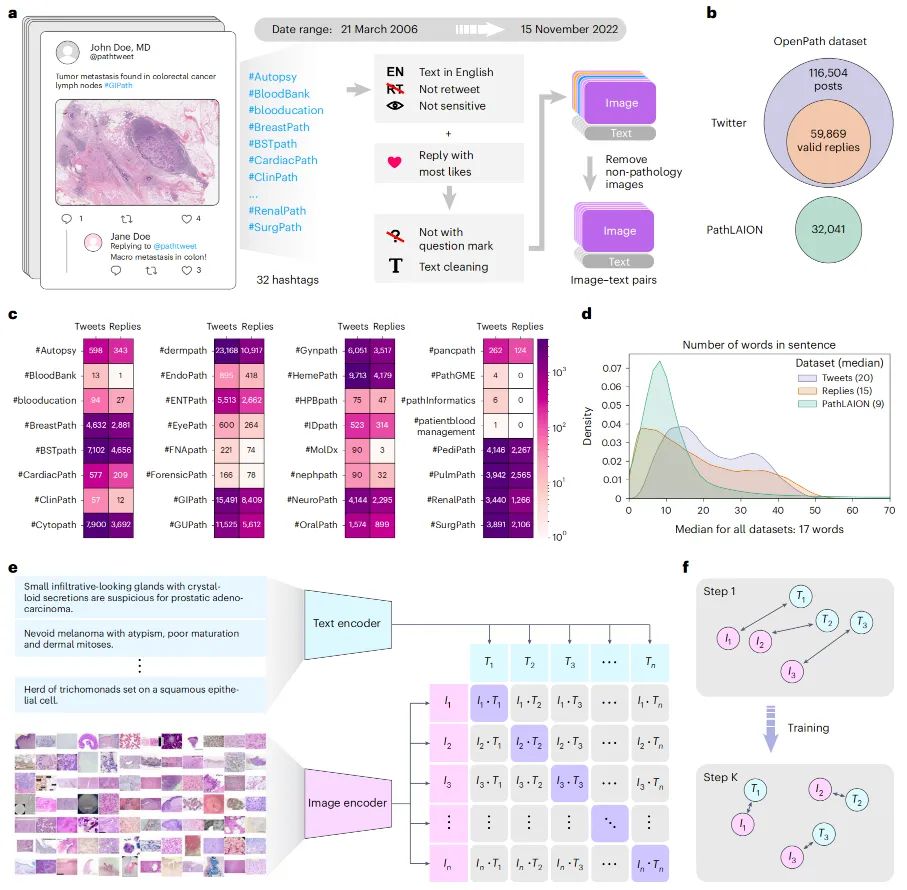
PLIP 引入了病理语言-图像预训练技术,这是一种能够理解图像和文本的多模态 AI 模型,用于 CPATH。PLIP 解决了标注医学图像有限的关键问题,通过整理和利用大量去标识化图像以及临床医生在公共平台(如医疗 Twitter)上共享的知识。利用流行的病理 Twitter 标签,PLIP 汇编了 OpenPath 数据集,其中包含 208,414 组病理图像-文本对。尽管模型架构与 CLIP的研究一致,技术创新有限,但其新颖的数据收集方法为 CPATH 标注稀缺领域提供了有效解决方案,为未来的进一步发展铺平了道路。
【】Visual Language Pretrained Multiple Instance Zero-Shot Transfer for Histopathology Images CVPR2023
MI-Zero 64 提出了一种简单直观的基于 MIL 的方法,该方法利用预训练视觉语言编码器的零样本迁移能力,用于处理临床实践中常规检查的吉兆像素级 WSIs。MI-Zero 的关键创新在于其能够克服 CPATH 中计算复杂性和配对图像-文本数据集有限的两大挑战。MI-Zero 通过组织一个包含病理学特定图像-文本对的大型数据集,并利用图像-文本模型的对比对齐,解决了这些挑战,从而实现多模态信息的无缝集成。此外,该模型整合了超过 55 万份病理报告和领域特定文本语料库,用于预训练一个强大的文本编码器,增强了视觉和文本表示之间的协同作用。该框架的意义在于其能够适应实际诊断任务。通过将零样本迁移纳入 MIL 范式,MI-Zero 使病理学家能够利用预训练编码器进行下游应用,如癌症亚型分类和诊断。 这种多模态融合方法减少了对外部标注数据集的依赖,将 MI-Zero 定位为在 CPATH 领域中实现可扩展和标签高效解决方案的关键性工作。
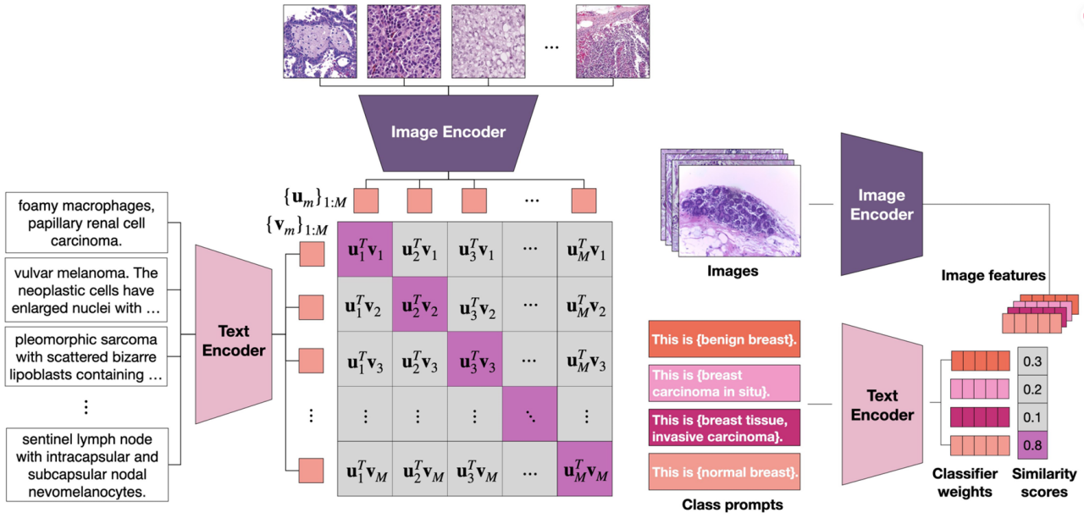
【】A visual-language foundation model for computational pathology Nature Medicine2024
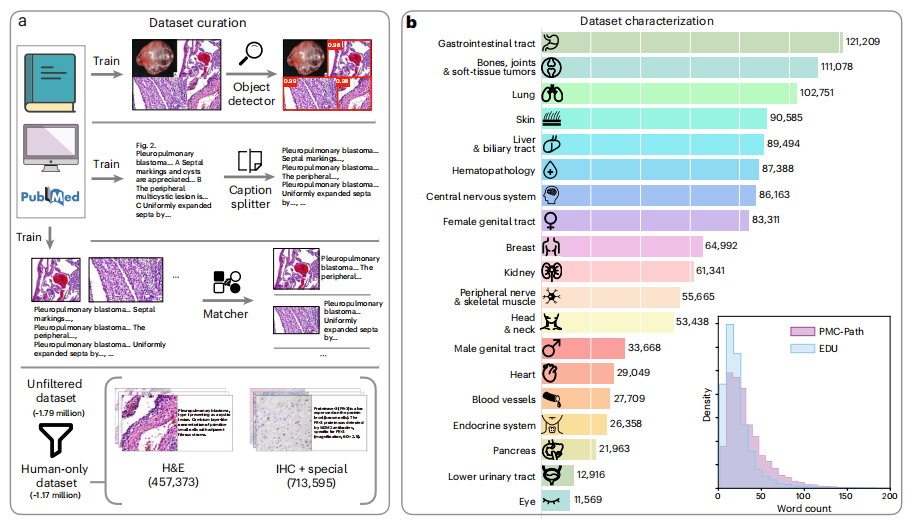
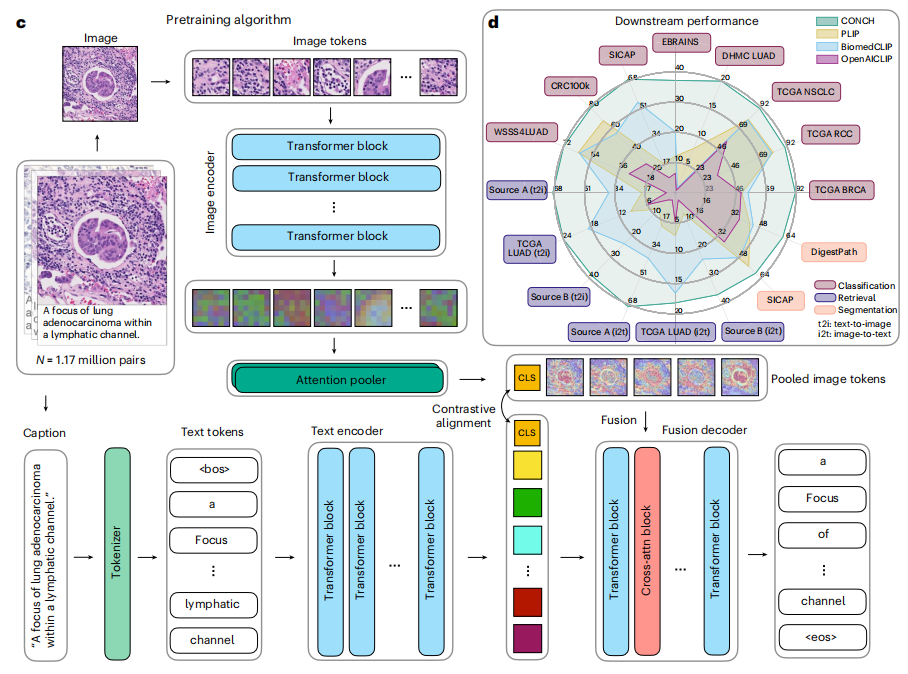
CONCH 提出了用于病理学的对比学习,这是一种通过任务无关的预训练,使用超过 117 万组图像-文本对开发而成的视觉-语言基础模型。CONCH 旨在解决病理学任务中有效整合图像和文本数据的挑战。传统的病理学模型通常依赖于图像数据,其训练过程往往受限于标注数据的稀缺性,导致泛化能力差,限制了它们在特定任务或疾病中的应用。为了克服这些问题,CONCH 基于 PMC-Path 构建,这是一个从 PubMed 图像中衍生出的病理学特定图像-文本数据集,形成了包含超过 117 万人样本对的数据集。基于 CoCa 框架,它采用图像编码器、文本编码器和多模态融合解码器,通过对比对齐目标和文本描述目标来训练模型。
CONCH 在多项任务中展现了卓越的性能,包括图像分类、图像分割、跨模态图像-文本检索和图像描述生成。此外,在其特定工作流程中,CONCH 为处理图注、将子图与副标题对齐等任务提供了详细的实现方法。CONCH 为 CPATH 领域提供了一个强大的视觉语言预训练模型,能够有效整合病理图像和文本。这种多模态学习方法不仅提升了病理图像分析的准确性和泛化能力,还显著扩展了病理任务的适用性,使其能够处理来自不同疾病和患者群体的数据。由于 CONCH 进行任务无关的预训练,它可以直接应用于各种下游任务,减少了对特定任务的有监督微调的需求,从而提供了广泛的实用价值。
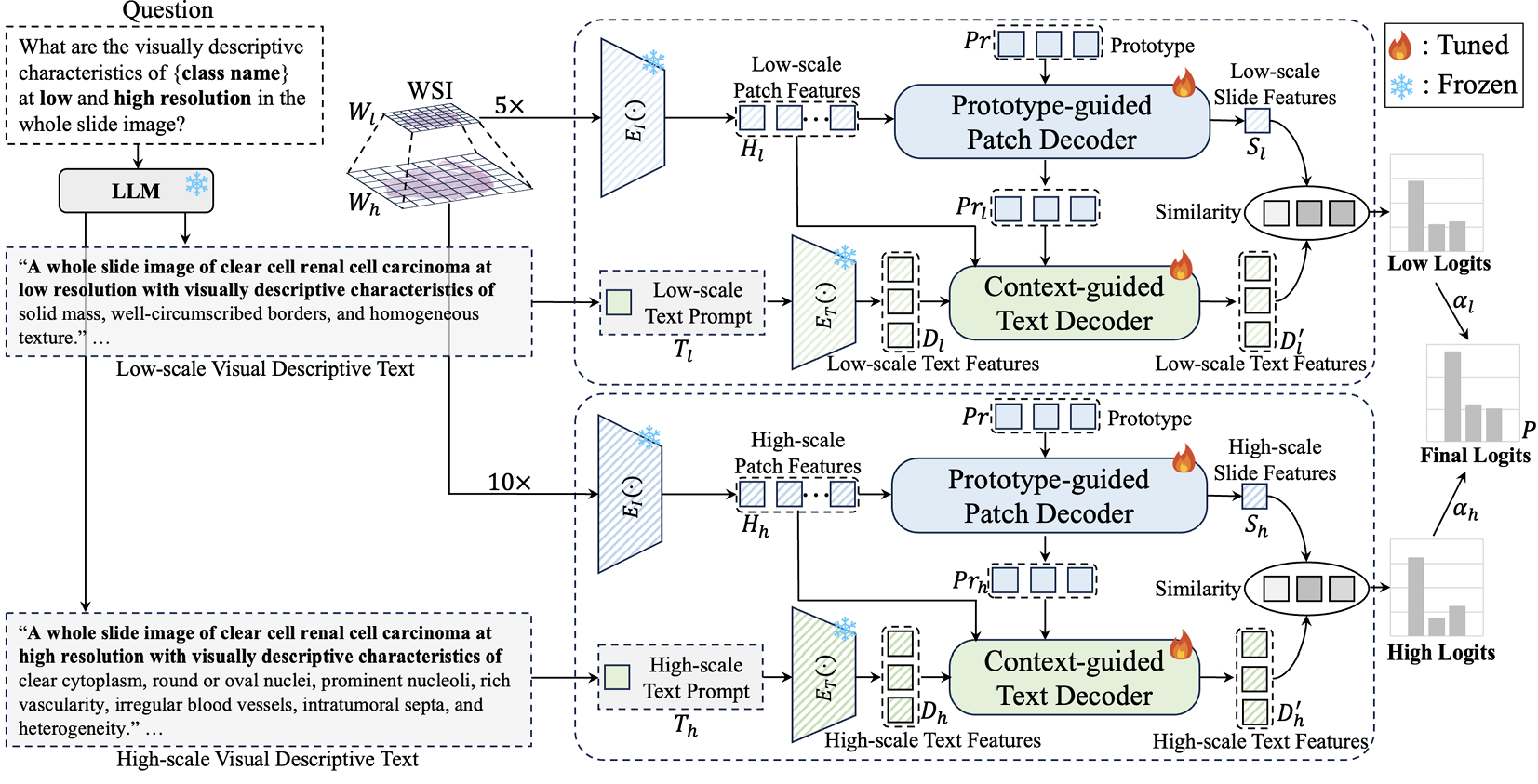
【】ViLa-MIL: Dual-scale Vision-Language Multiple Instance Learning for Whole Slide Image Classification CVPR2024
ViLa-MIL 提出了双尺度视觉语言多实例学习,将视觉语言模型(VLM)与用于 WSI 预测的多实例学习方法相结合,为多实例学习特征提取技术做出了重要贡献。通过利用 VLM 强大的特征提取能力,ViLa-MIL 解决了传统多实例学习方法易受数据分布变化影响的问题。此外,它还克服了先前文本提示缺乏病理先验知识考虑的问题。ViLa-MIL 的关键组件包括(1)双尺度视觉描述性文本提示;(2)原型引导的病变块解码器;(3)上下文引导的文本解码器。
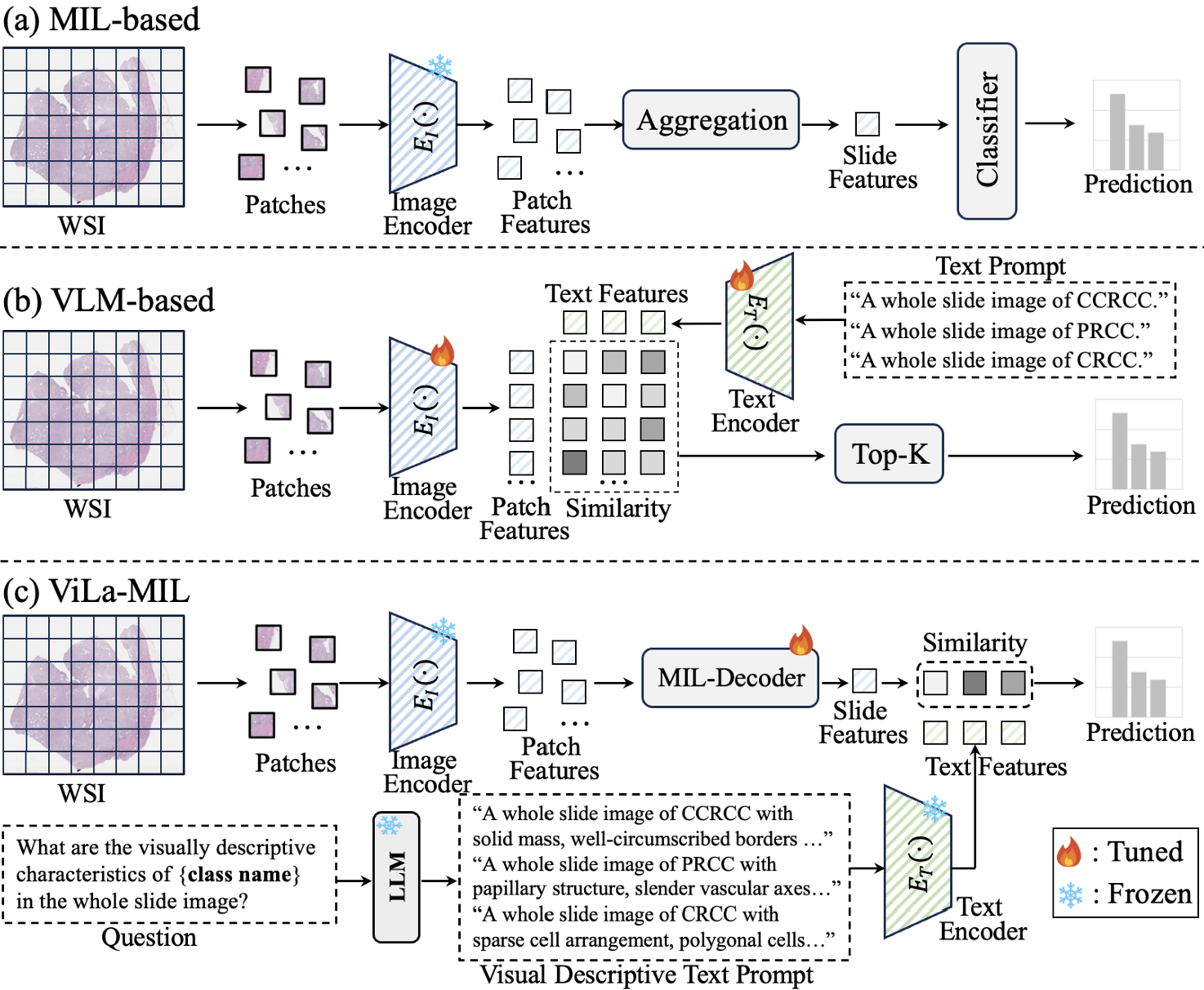
双尺度视觉描述性文本提示通过关注两个尺度的信息来捕捉全切片图像(WSI)中的全局结构和局部细节。它使用一个冻结的 LLM来生成文本提示。原型引导的补丁解码器通过将相似的补丁分组到同一个原型中,逐步聚合补丁特征,使每个原型能够捕获更多全局上下文信息用于最终相似度计算,从而通过分组和融合提高特征提取效率。上下文引导的文本解码器结合了多粒度图像上下文,包括局部补丁特征和全局原型特征,利用这些上下文信息来增强模型内的文本特征。ViLa-MIL 成功地将以卓越特征提取能力而闻名的 VLM 与 MIL 相结合,提出了一种经过广泛实验验证的可行操作范式。
(a)模态融合
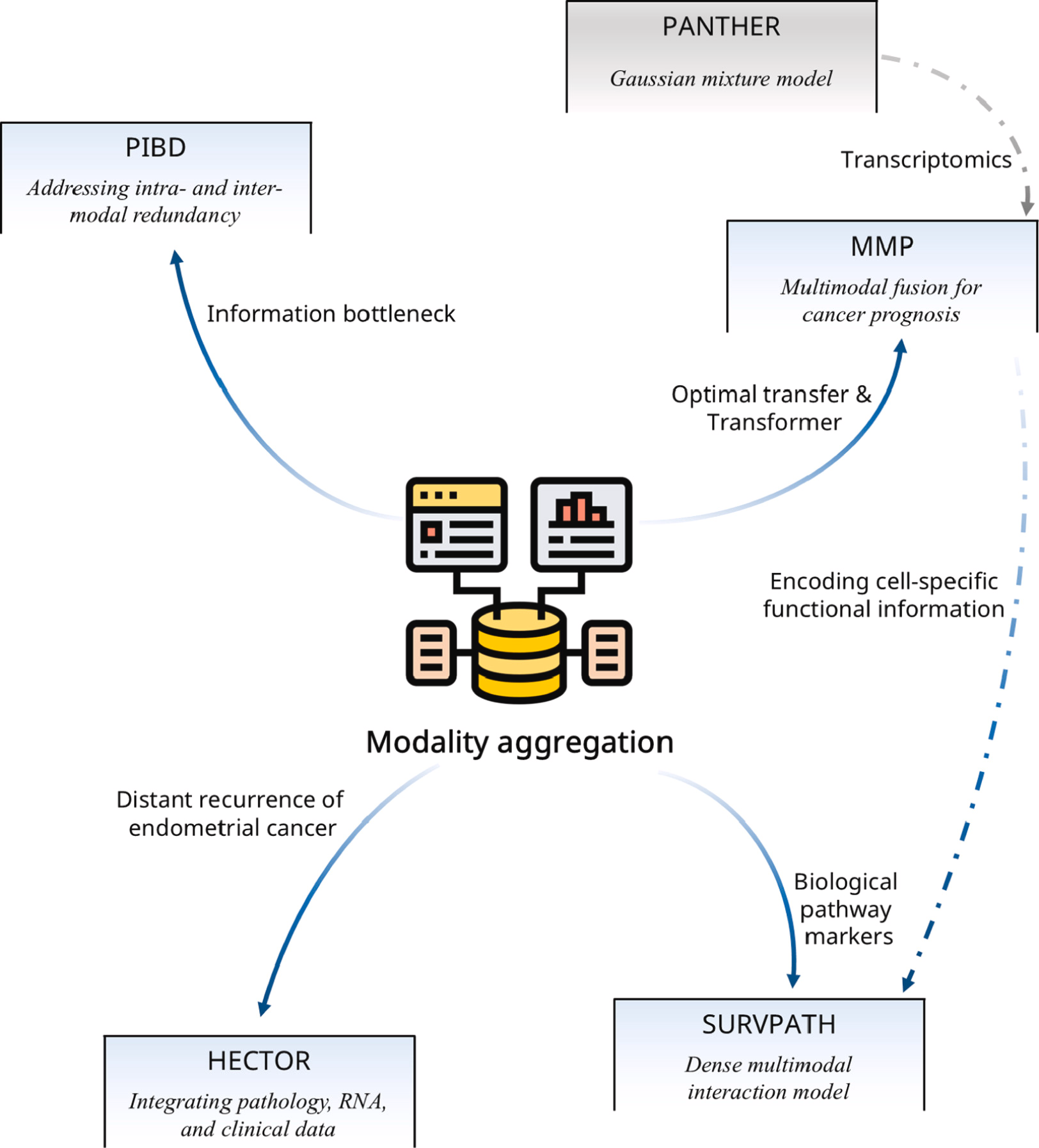
模态聚合出现较晚,但遵循更直观的方法:使用多个特征提取器处理不同模态,并将提取的特征融合以实现鲁棒的表示。PIBD 是一项非应用导向的研究,采用信息瓶颈框架的变体来解决多模态数据中的模态内和模态间冗余问题。MMP 基于 PANTHER ,建立了最优传输(OT)交叉对齐与 Transformer 交叉注意力的联系,优化了多模态融合过程。SurvPath 通过将 WSI 与转录组学聚合,编码细胞特异性功能信息,以识别生物学通路标记。HECTOR 将多模态聚合应用于子宫内膜癌(EC)的远处复发预测,实现了高性能预测。图概述了下文介绍的工作。
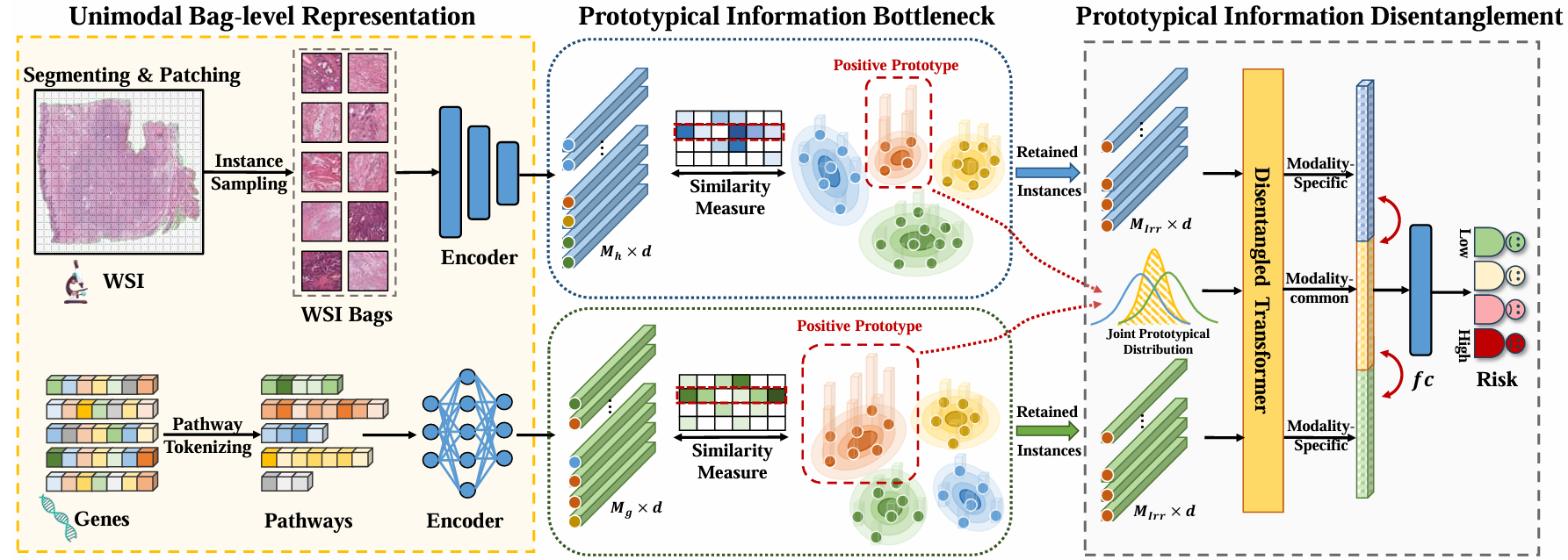
【】Prototypical Information Bottlenecking and Disentangling for Multimodal Cancer Survival Prediction
PIBD 提出了原型信息瓶颈和去耦合方法来解决冗余信息过载的问题。它包含两个主要组件:原型信息瓶颈(PIB)模块,通过选择判别性实例处理模态内冗余;以及原型信息去耦合(PID)模块,将多模态数据分离为模态通用和模态特定知识。PIBD 通过将复杂的多模态信息分解为易于区分的组件,解决了多模态 MIL 中的一个基本问题------冗余信息,从而帮助模型更好地进行特征提取和实例分类。
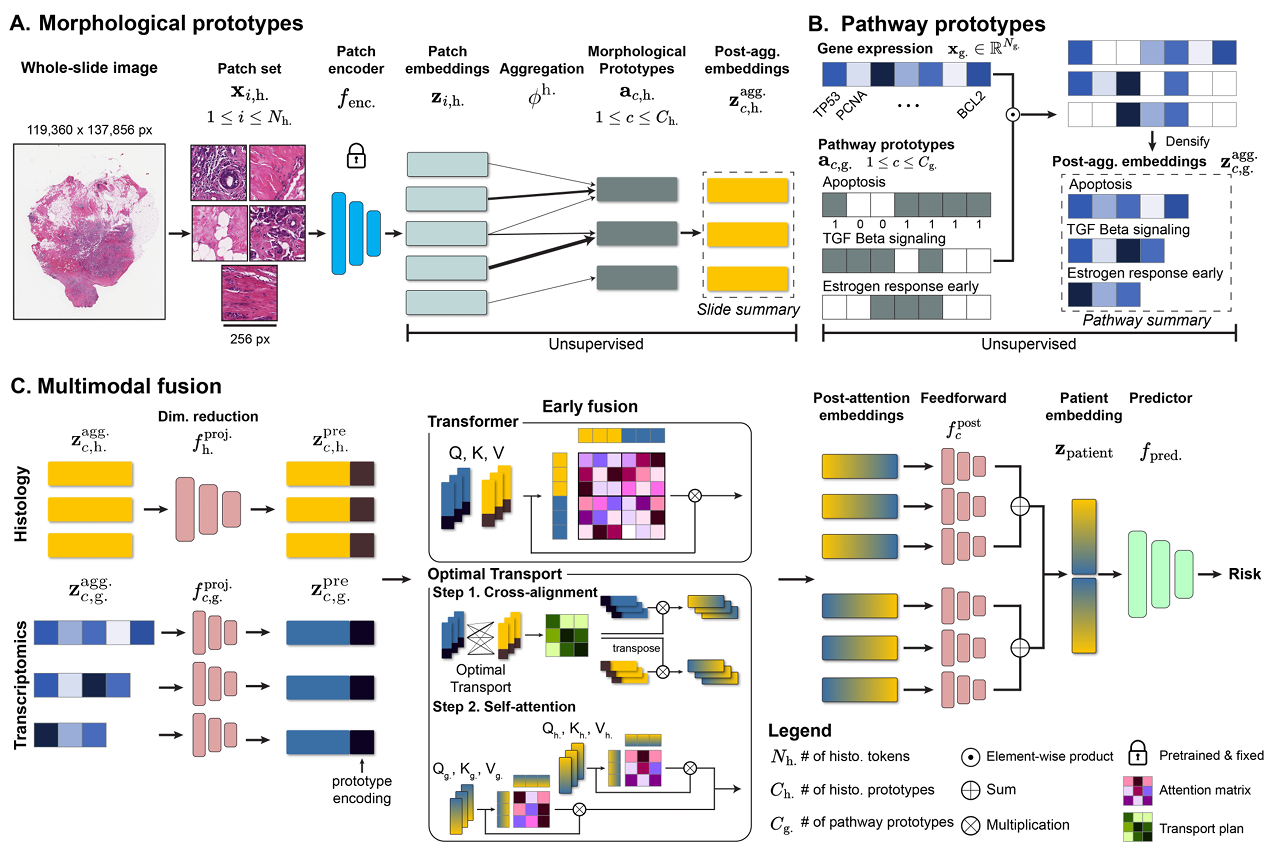
【】Multimodal Prototyping for Cancer Survival Prediction ICML2024
MMP 引入了多模态原型框架用于患者预后预测,以解决多模态 MIL 中的数据规模问题。与仅依赖组织病理学图像进行预测的 MIL 方法相比,多模态 MIL 整合了 WSIs 和转录组特征等信息,导致 token 数量增加。这增加了训练过程中的内存需求,并增加了可解释性分析的复杂性。
MMP 的主要贡献包括:(1) 形态学和通路原型:MMP 使用高斯混合模型(GMM)以无监督方式构建紧凑的 WSI 表示。混合参数定义了一个切片摘要,映射到 16 到 32 个原型,实现了超过 300 倍的压缩。此外,MMP 将转录组转化为 50 个癌症标志性通路原型。通过减少标记数量,MMP 允许直接处理这些紧凑的多模态标记,而无需依赖近似。(2) 多模态融合机制:MMP 在最优传输(OT)交叉对齐和 Transformer 交叉注意力之间建立了联系,将两者统一在单一框架下。这不仅降低了计算复杂度,还提高了模型的效率,进一步优化了多模态数据融合过程。
【】Modeling Dense Multimodal Interactions Between Biological Pathways and Histology for Survival Prediction CVPR2024
SurvPath 整合了全切片图像(WSIs)和 bulk 转录组数据来预测患者生存,在五个 TCGA 数据集上取得了最先进的性能。WSIs 提供了高维空间肿瘤数据,而 bulk 转录组数据则捕捉了内部基因表达。SurvPath 解决了两个关键挑战:(1) 转录组数据的分词:语义上对转录组数据进行分词具有挑战性,因为它不同于图像或文本的分词。直接融合特征向量或按功能分组基因可能会丢失语义信息。SurvPath 通过基于生物通路对基因进行分词来克服这一问题。(2) 捕捉多模态交互:SurvPath 引入了一种新的注意力机制来模拟图像和转录组之间的复杂交互,避免了 Transformer 中二次自注意力机制的计算开销。该机制专注于 patch-通路、通路-patch 和通路-通路交互,同时近似 patch-patch 关系。
SurvPath 框架包含三个主要组件:(1)通路分词器,将转录组数据编码为通路嵌入;(2)组织病理学图像块分词器,使用 Swin Transformer 将 WSI 图像块转换为嵌入58178;(3)多模态融合,其中注意力机制通过聚焦关键交互来降低复杂性。SurvPath 在多模态 MIL 领域实现了重大进步,提升了转录组数据的可解释性,并在模态融合方面取得了突破。大量实验表明其性能优越。
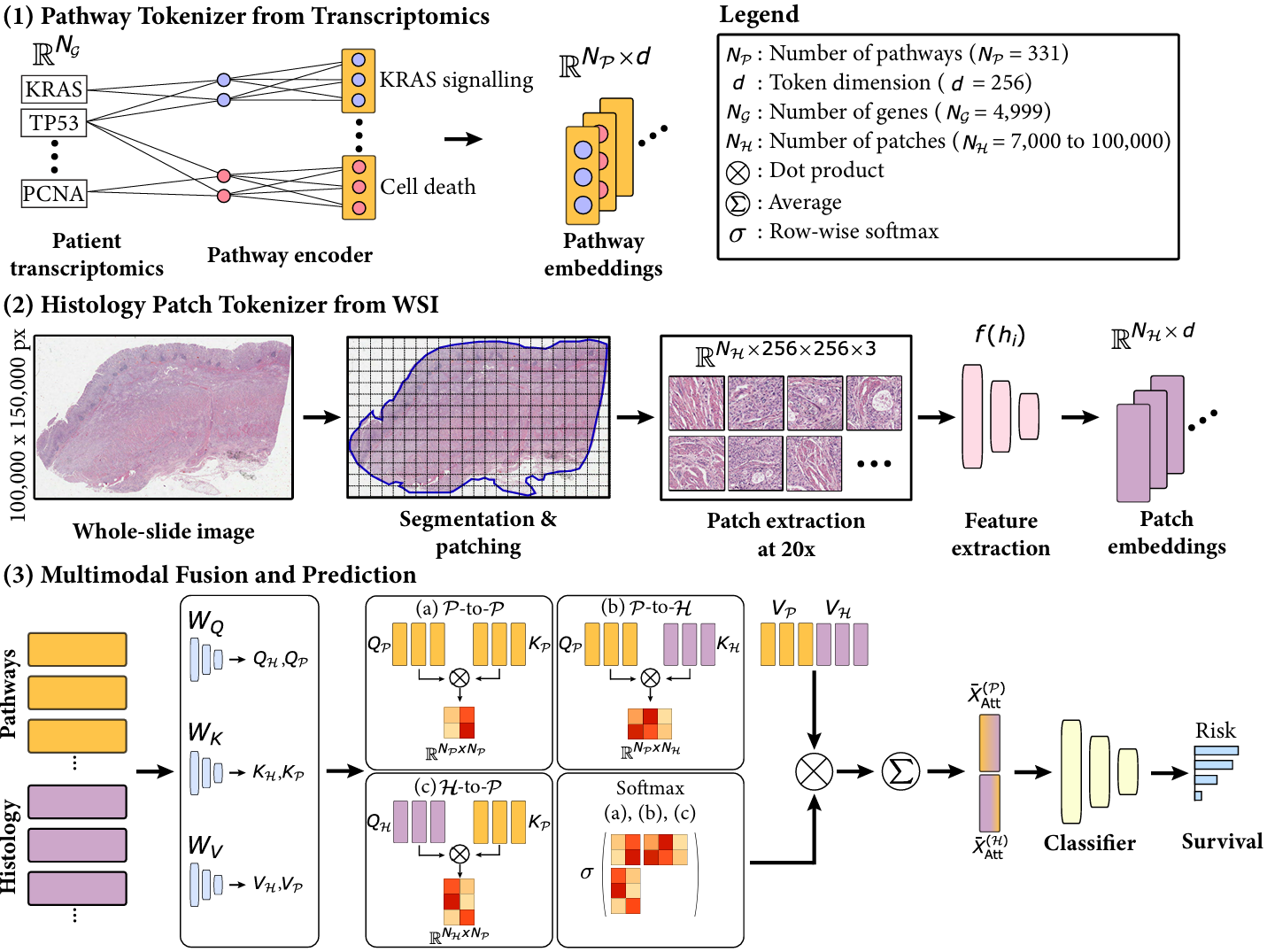
【】Prediction of recurrence risk in endometrial cancer with multimodal deep learning nature medicine 2024
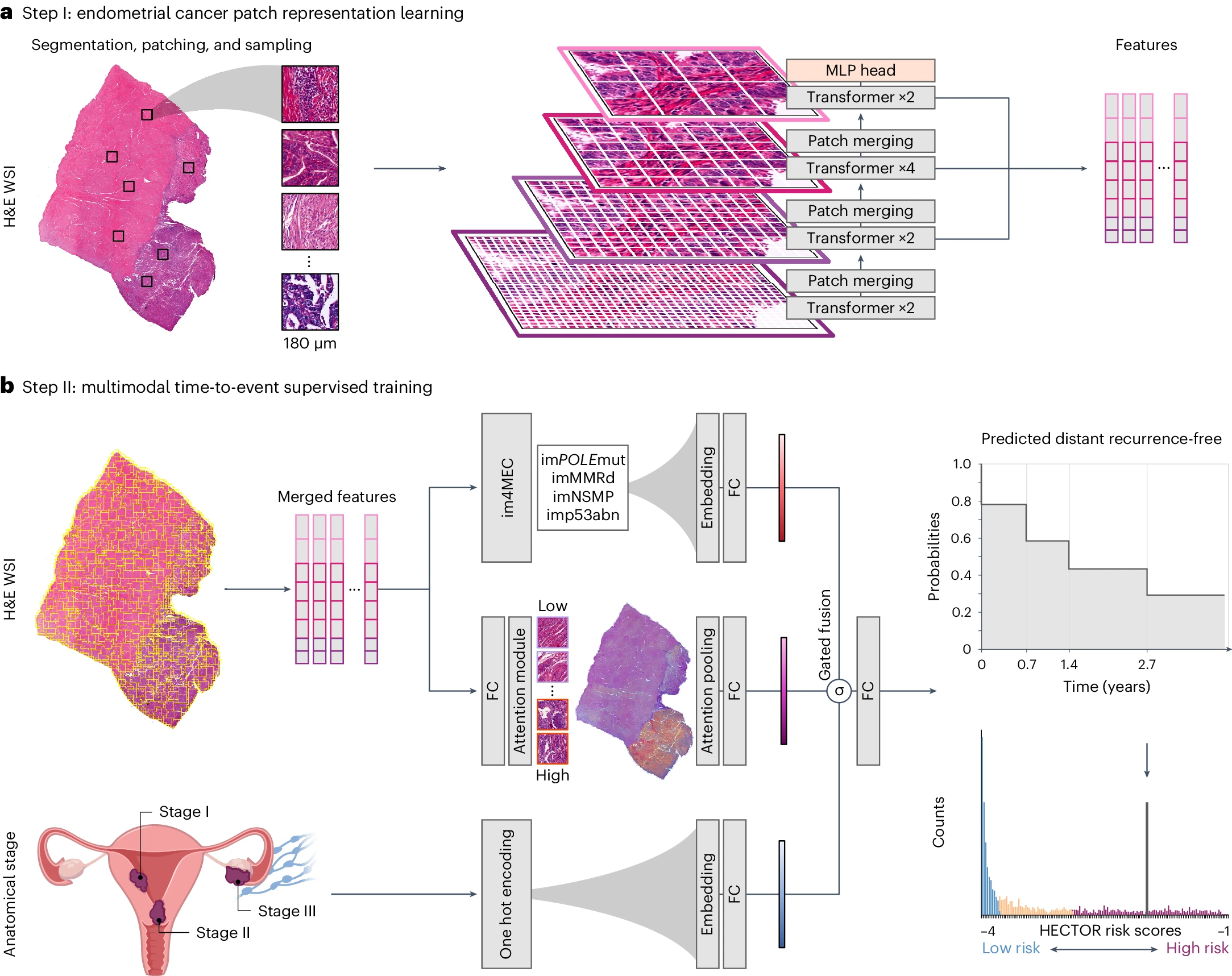
HECTOR提出了基于组织病理学的子宫内膜癌定制预后风险(Histopathology-based Endometrial Cancer Tailored Outcome Risk),这是一种多模态的 MIL 模型,旨在将 MIL 方法应用于预测子宫内膜癌(EC)的远处复发,并解决涉及综合病理和分子分型的金标准的高成本问题。HECTOR 整合了解剖分期信息、通过 ABMIL 获得的实例嵌入,以及通过基于门控的注意力机制从 im4MEC DL 模型中推导出的分子亚型。最后,通过全连接层计算风险评分。虽然 HECTOR 并不严格遵循传统的两步 MIL 过程,但它利用仅使用包级标签的 MIL 特征提取和聚合技术。尽管它没有提出极具创新性的算法,但它为多模态 MIL 提供了一种可行的范式,全面的实验证明了其有效性。
4.3 总结
本节强调了在 CPATH 领域,MIL 研究因架构设计和特征提取方法的创新而取得的重大进展。对 MIL 架构的探索反映了该领域在优化实例选择和上下文关系建模方面的日益成熟,从而能够更高效、更有效地分析大规模病理数据。同时,特征表示方面的进步,如自监督学习和多模态集成,在解决数据稀缺性和提升特征表示质量方面发挥了关键作用。这些发展共同展示了 MIL 作为计算病理学基础技术的持续演进,为更准确、可扩展和创新性的诊断解决方案铺平了道路。
第一个方向专注于改进病理任务中的 MIL 架构性能。在这个领域内,出现了两个核心主题:有价值实例选择和实例间关系融合。有价值实例选择通过识别和优先级排序最相关的区域或实例,解决了管理 WSI 大规模的挑战。这种方法显著降低了计算需求,同时确保了最有价值的数据被用于下游任务。随着时间的推移,该领域的技巧从简单的选择策略发展到更复杂的方法,提高了选择准确性和效率。实例间关系融合将重点从单个区域转移到 WSI 中实例之间的上下文关系。通过利用架构创新,这种方法捕捉了更丰富的上下文信息,使模型能够更好地理解病理数据中固有的复杂空间和关系结构。该领域的最新进展显著提高了计算效率和可扩展性,促进了处理更大更复杂数据集。
第二条路径强调推进特征提取技术,以充分发挥 MIL 在 CPATH 中的潜力。该路径分为两个关键领域:自监督发现和多模态洞察融合。自监督发现利用从无标签数据中学习的能力,解决 CPATH 中标注有限带来的挑战。通过整合自监督学习框架,这些方法提取更鲁棒和泛化的特征表示,从而在各种任务中提升性能。多模态洞察融合通过整合 WSI 以外的信息,如病理报告或分子数据,扩展了数据利用范围。已出现两种主要策略:跨模态对齐特征以指导更优的图像表示,以及聚合多模态输入以创建丰富和全面的特征集。这些方法弥补了单模态分析的局限性,并为下游任务提供整体洞察。
五、讨论
5.1 从单模态到多模态
在 CPATH 中,全切片图像(WSIs)长期以来一直是多实例学习(MIL)中特征提取的核心,从传统的特征工程和卷积神经网络(CNNs)发展到基于视觉 Transformer(ViT)的模型,这些模型能够捕捉全局和跨尺度的特征。然而,仅依赖 WSIs 存在固有的局限性。虽然 WSIs 为细胞和组织结构提供了关键信息,但它们往往难以应对许多病理任务的复杂性,例如细粒度癌症亚型分类和预后预测。这些任务需要更深入地理解疾病机制,而 WSIs 本身无法提供,因此需要整合其他数据模态。单模态方法的主要局限性有两个方面:(1)WSIs 通常缺乏足够的信息来预测复杂的病理结果;(2)基于 WSIs 的预训练主要捕捉图像特征,而其他模态(如基因组或临床数据)则提供了更深的理解。多模态学习通过结合多样化的数据源来弥补这些差距,从而为疾病过程创建更全面的表现形式,进而增强模型的预测能力和泛化能力。
近年来,研究重点集中在多模态特征提取与融合。有效的多模态融合需要平衡各模态的贡献,同时减轻冗余和冲突等问题。此外,实际医疗场景中常存在缺失模态的情况,使得对不完整数据的鲁棒性成为持续研究的关键领域。这些发展旨在使模型能够无缝整合图像、基因组和临床数据,从而促进对疾病机制的全面理解。多模态预训练是一种特别有前景的方法。通过利用来自不同模态的数据,预训练使模型能够从全切片图像(WSIs)中学习更深、更有意义的特征。这种策略增强了泛化能力,并为应对更复杂的病理挑战奠定了基础。
5.2 整合 LLMs
将大型语言模型(LLMs)与 MIL 相结合,代表了 CPATH 的一个变革性方向。LLMs 凭借其先进的语言理解和生成能力,能够弥合复杂文本数据(例如临床记录、病理报告)与全切片图像(WSIs)的视觉信息之间的差距,为病理分析创建一个更全面的框架。通过将 WSI 分析与 LLMs 相结合,研究人员旨在解锁在特征提取、可解释性和任务特定适应性方面的新可能性。
首先,WSI 分析往往难以完全涵盖众多病理任务中固有的复杂性。虽然 WSI 提供了丰富的关于细胞和组织结构的视觉信息,但它们缺乏其他数据类型(如病理报告或基因组信息)所提供的上下文和生物学见解。通过整合 LLMs,MIL 模型可以有效地利用互补的模态,通过文本领域的专业知识增强特征提取 。这种以文本驱动的方法提高了 MIL 模型的适应性及其处理各种下游任务的能力。其次,LLMs 在数据标注和少样本学习中的应用解决了病理学中标注数据有限的问题。标注 WSIs 既费时又昂贵,但 LLMs 可以生成高质量的伪标签,使 MIL 模型能够在稀疏标注的情况下高效训练。此外,在少样本学习场景中,LLMs 可以为小数据集提供丰富的语义描述,为训练过程增加上下文深度。这种结合模型驱动学习和数据驱动洞察的双重方法,为更鲁棒和可扩展的 MIL 模型铺平了道路,这些模型能够处理复杂的病理学任务。第三,LLMs 通过实现零样本和类无差别任务处理,显著增强了多模态 MIL 模型的能力。与传统方法需要为每个任务配置专用分类头不同,LLMs 利用提示来指导模型处理各种任务,而无需针对特定任务进行修改。例如,在疾病亚型分类或治疗建议中,LLMs 可以无缝整合非结构化文本数据,将临床叙述中的上下文信息丰富到 WSI 特征嵌入中。这种灵活性使模型能够比传统多模态方法更有效地适应多样化的临床场景,从而消除了针对特定任务的工程需求。最后,LLMs 的集成增强了 MIL 模型的解释性,这是临床应用中的一个关键因素。LLMs 可以为模型预测生成自然语言解释,为临床医生提供直观透明的见解。例如,在分类肿瘤亚型时,一个由 LLM 驱动的 MIL 模型可以通过将 WSI 中的视觉模式与相关文本证据联系起来,提供详细的推理依据。这种程度的可解释性有助于建立对 AI 系统的信任,并支持它们在真实临床环境中的应用。
5.3 罕见病理
对过去六年 MIL 研究中涉及的特定疾病分布进行了分析,结果如下图所示。分析显示,乳腺癌研究占所有研究的 36.42%,是研究最深入的疾病。这种突出地位很大程度上归因于备受推崇的 CAMELYON16 和 CAMELYON17 数据集,它们极大地推动了 MIL 在 CPATH 领域的发展。在研究频率上紧随乳腺癌之后的是肺癌、结直肠癌和肾癌,这些癌症有像 TCGA 这样强大的数据集支持,同时也具有重要的临床意义。
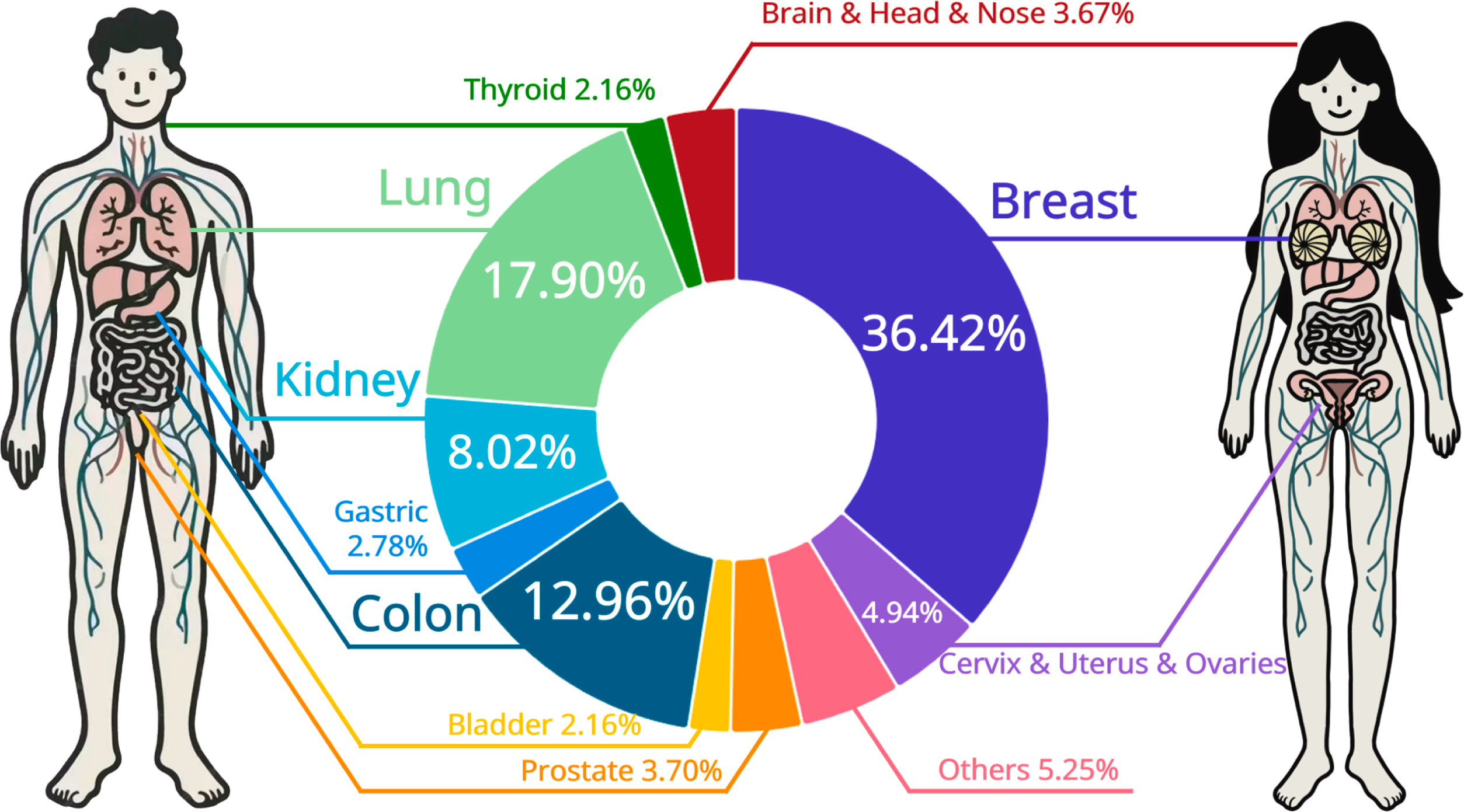
比例分布表明,大多数 MIL 研究集中在少数几种关键癌症类型上,反映了当前研究对公共数据集的高度依赖。其他所有癌症类型的研究仅占 24.7%,突显了 CPATH 内部对不同癌症类型关注度的显著差异。这种差异主要归因于数据库完整性的不同水平。一些较为罕见的癌症仍然缺乏全面的数据集,导致难以提供足够的训练数据。将 MIL 应用于罕见病理学是一个重大挑战,因为数据样本的有限性阻碍了使用传统深度学习方法训练出稳健、高性能模型的有效训练。
一种潜在的解决方案是领域泛化,它涉及从数据丰富的领域学习泛化特征表示,并将其应用于罕见病理,以弥补直接训练数据的缺乏。这可以通过共享特征空间或迁移学习来实现,使模型能够在罕见病理中保持优异性能。此外,MIL 模型必须专注于有效地从有限的标记样本中学习。少样本学习可能成为罕见病理的关键研究方向。通过结合少样本学习,MIL 模型即使在稀疏的训练数据下也能提取与病理特征相关的关键特征。这些方法可能包括对比学习、SSL 或生成伪标签,以增强模型识别罕见病理的能力。
5.4. 临床应用中的主要挑战
将 MIL 成功整合到临床实践中面临几个关键挑战,包括可解释性、工作流程整合和隐私问题。这些方面中的每一个都对确保 MIL 模型能够在真实世界的医疗环境中被信任和广泛采用至关重要。
在医学领域,MIL 的可解释性至关重要,临床医生需要信任并理解深度学习模型的决策过程。尽管 MIL 模型在分类和预测任务中表现出色,但它们在临床环境中的实用性取决于提供透明且可解释的结果。鉴于机器学习的固有特性,分类器中的预测偏差并不少见。因此,临床医生必须能够理解模型预测背后的逻辑,而不仅仅是接收分类输出。当前的基于实例的方法和注意力机制提供了一定程度的可解释性,特别是在突出全切片图像(WSI)中的关键区域方面。然而,这些解释通常仅限于视觉线索,在提供更精细、可操作的见解方面仍有显著改进空间。未来的 MIL 模型应致力于提供多模态解释,包括自然语言描述,以清晰地阐述其决策背后的逻辑。 这种方法将使模型的输出与临床医生的认知过程相一致,从而在实践中更具实用性。
除了可解释性,将 MIL 嵌入诊断工作流程对 CPATH的实际应用提出了另一个关键挑战。虽然 MIL 模型在定量预测方面表现出色,例如疾病亚型分类或阳性/阴性分类,但病理学家需要的不仅仅是最终决策。他们需要诊断支持功能,例如关键病变区域的标注、特征的可视化以及不同病理模式的解释说明。为了满足临床操作需求,未来的 MIL 模型必须提供超越简单预测的多层次输出,并提供补充诊断信息。此外,这些模型需要在各种医院和实验室条件下展示鲁棒性和可靠性,其中扫描方法、染色技术和其他因素可能存在显著差异。这要求模型具备强大的泛化能力,能够在多样化的实际环境中稳定运行。
在 MIL 中,随着 MIL 模型在临床环境中的更广泛采用,隐私问题也正成为一个关键的研究方向。病理图像及其相关的临床数据通常包含敏感的个人健康信息,引发了严重的隐私问题。解决隐私挑战的两个关键领域是:将联邦学习与 MIL 结合进行跨机构的合作研究,以及应用加密计算技术。联邦学习允许 MIL 模型在多个机构之间进行训练,而无需共享敏感数据。同时,同态加密技术使模型能够在加密数据上进行计算,确保在训练和推理过程中原始数据始终得到保护。鉴于医疗数据的敏感性,解决隐私问题对于 MIL 在 CPATH 中的广泛应用至关重要。
六、总结
研究结果表明,特征提取和整合方面的创新极大地推动了深度多实例学习的发展,显著提升了其生成稳健和精确表征的能力。这些进步使得 MIL 能够更有效地支持日益复杂的下游任务,并扩展了其在计算病理学(CPATH)中的应用范围。此外,MIL 框架对详尽标注的依赖性极低,且具有固有的可解释性,这凸显了其解决临床病理数据挑战的巨大潜力,并有助于推动诊断和预后应用的发展。展望未来,CPATH 中 MIL 的发展轨迹表明,跨模态整合和先进特征提取技术将受到越来越多的重视。随着该领域的不断发展,MIL 将独特地推动连接计算创新和临床影响的突破。我们希望这篇综述能成为研究人员和从业者的全面资源,指导未来的探索,并促进 MIL 在 CPATH 中的持续发展。
七、最新文章补充
【】DGR-MIL: Exploring Diverse Global Representation in Multiple Instance Learning for Whole Slide Image Classification ECCV2024
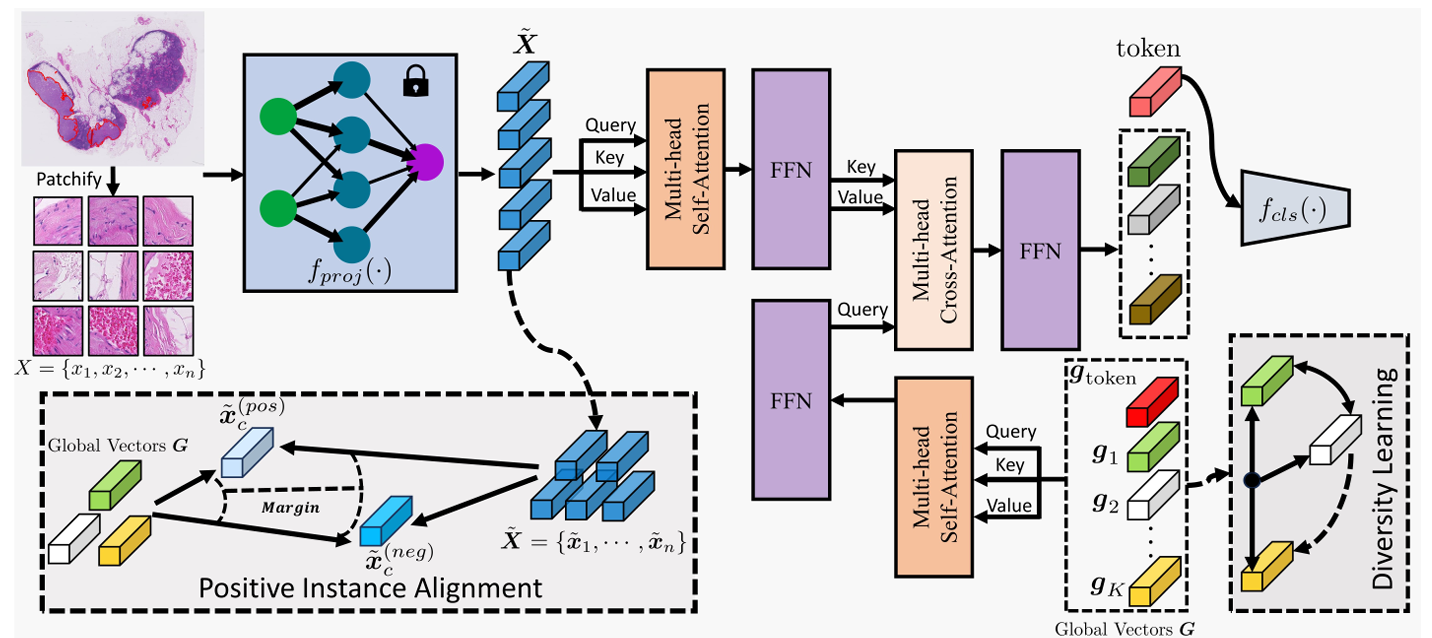
现有的主流 MIL 方法侧重于建立实例之间的相关性,却忽略了实例之间的内在多样性。然而,很少有 MIL 方法致力于多样性建模,这些方法在实际应用中表现不佳,且计算成本较高。为了弥补这一差距,我们提出了一种基于多样性的全局表示(DGR-MIL)的新型多实例学习聚合方法,通过一组全局向量来建模实例之间的多样性,这些全局向量是对所有实例的总结。首先,我们通过交叉注意力机制将实例之间的相关性转化为实例嵌入与预定义全局向量之间的相似度。这是因为相似的实例嵌入通常会与某个全局向量产生更高的相关性。其次,我们提出了两种机制来强化全局向量之间的多样性,以使其更能够全面地描述整个数据集:(i)正例对齐机制和(ii)一种新颖、高效且理论上可保证的多样化学习范式。具体而言,正例对齐模块鼓励全局向量与正例的中心(例如,在 WSI 中包含肿瘤的实例)保持一致。为了进一步丰富全局表示,我们提出了一种利用确定性点过程的新型多样化学习范式。
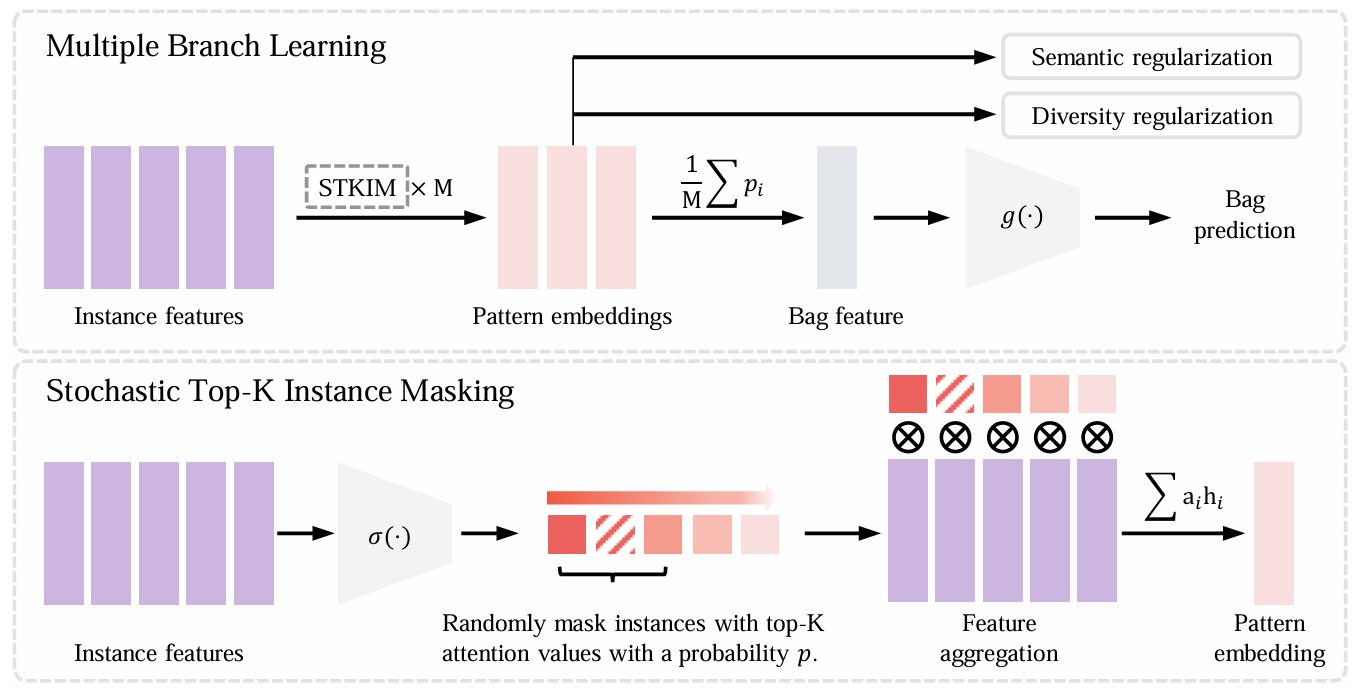
【】Attention-Challenging Multiple Instance Learning for Whole Slide Image Classification ECCV2024
在将多实例学习(MIL)方法应用于全切片图像(WSI)分类的过程中,注意力机制通常会关注一组具有区分性的实例,而这些实例与过拟合密切相关。为了减轻过拟合现象,我们提出了"挑战注意力的多实例学习"(ACMIL)。ACMIL 结合了基于独立分析的两种注意力值集中技术。首先,实例特征的 UMAP 分析揭示了具有区分性的实例之间的各种模式,而现有的注意力机制仅能捕捉其中的一部分。为了弥补这一不足,我们引入了多分支注意力(MBA)来使用多个注意力分支捕捉更多的具有区分性的实例。其次,对 Top-K 注意力得分的累积值的检查表明,少数几个实例占据了大部分注意力。对此,我们提出了随机 Top-K 实例掩码(STKIM),它会屏蔽具有 Top-K 注意力值的实例,并将它们的注意力值分配给其余的实例。在三个 WSI 数据集上使用两种预训练架构进行的大量实验结果表明,我们的 ACMIL 比最先进的方法表现更好。此外,通过热图可视化和 UMAP 可视化,本文详细展示了 ACMIL 在抑制注意力值集中化以及克服过拟合难题方面的有效性。
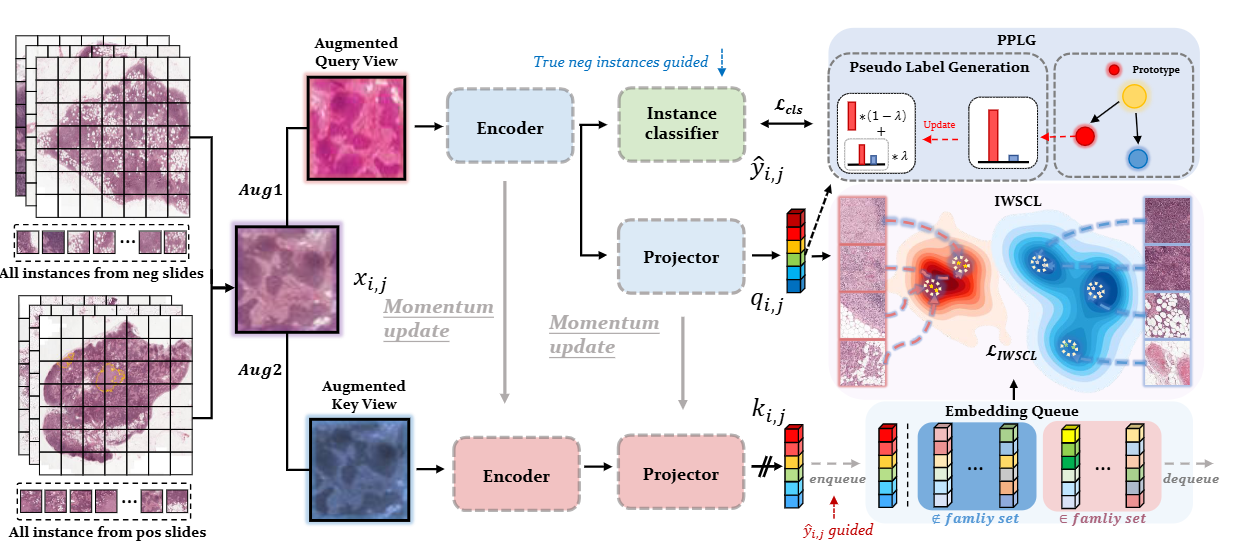
【】Rethinking Multiple Instance Learning for Whole Slide Image Classification: A Good Instance Classifier Is All You Need TCSVT2024
弱监督的全切片图像分类通常被表述为一种多重实例学习(MIL)问题,其中每张切片被视为一个袋子,从中切出的图像块则被视为实例。现有的方法要么通过伪标签训练一个实例分类器,要么通过注意力机制将实例特征聚合为一个袋子特征,然后训练一个袋子分类器,其中注意力得分可用于实例级别的分类。然而,前者构建的伪实例标签通常包含大量噪声,而后者构建的注意力得分不够准确,这两者都会影响其性能。在本文中,我们提出了一种基于对比学习和原型学习的实例级 MIL 框架,以有效地完成实例分类和袋子分类任务。为此,我们在 MIL 设置下首次提出了一个用于实例级弱监督对比学习的算法,以有效地学习实例特征表示。我们还通过原型学习提出了一个准确的伪标签生成方法。然后,我们为弱监督对比学习、原型学习和实例分类器训练开发了一种联合训练策略。
【】E2-MIL: An explainable and evidential multiple instance learning framework for whole slide image classification MEDICAL IMAGE ANALYSIS 2024
由于切片级别的监督信息稀疏,这些方法通常在肿瘤区域的定位上表现不佳,导致解释性较差。此外,它们缺乏对预测结果的稳健不确定性估计,从而导致可靠性较低。为了解决上述两个局限性,我们提出了一种可解释且证据支持的多实例学习(E2 2-MIL)框架用于全切片图像分类。E2 2-MIL 主要由三个模块组成:一个细节感知注意力蒸馏模块(DAM)、一个结构感知注意力细化模块(SRM)和一个不确定性感知实例分类器(UIC)。具体而言,DAM 通过利用互补子包来利用本地网络学习详细的注意力知识,帮助全局网络定位更具细节感知的正实例。此外,还引入了一个掩码自引导损失,以帮助弥合切片级别标签和实例级别分类任务之间的差距。SRM 生成了一个结构感知的注意力图,该图通过有效模拟聚类实例之间的空间关系来定位整个肿瘤区域的结构。此外,UIC 提供了准确的实例级别分类结果和稳健的预测不确定性估计,基于主观逻辑理论来提高模型的可靠性。
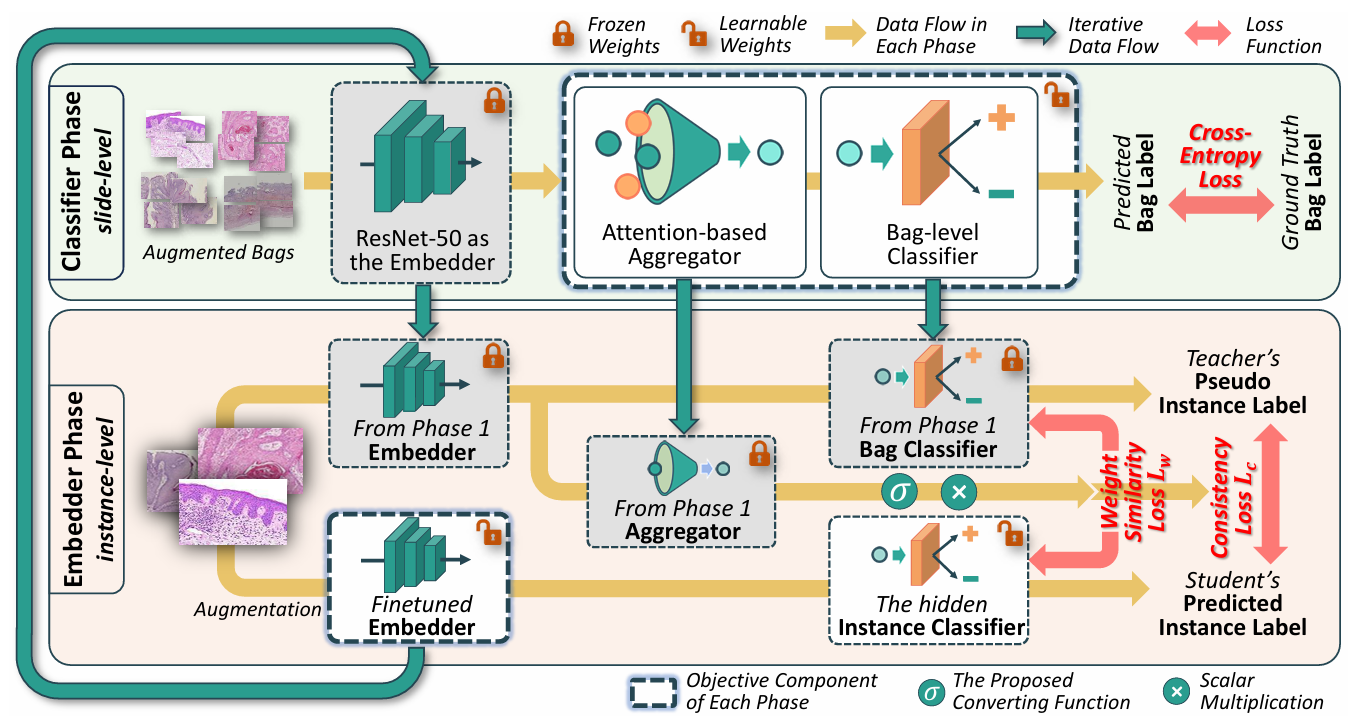
【】Rethinking Multiple Instance Learning for Whole Slide Image Classification: A Bag-Level Classifier is a Good Instance-Level Teacher TMI2024
多实例学习(MIL)在全切片图像(WSI)分类方面已展现出良好的应用前景。然而,由于处理这些十亿像素级别的图像所涉及的高计算成本,这一挑战依然存在。现有的方法通常采用两阶段的处理方式,包括一个不可学习的特征嵌入阶段和一个分类器训练阶段。尽管通过使用在其他领域预先训练好的固定特征嵌入器可以大大减少内存消耗,但这种方案也会导致两个阶段之间的差异,从而导致分类准确率不理想。为了解决这个问题,我们提出,一个包级别的分类器可以是一个良好的实例级别的教师。基于这一想法,我们设计了迭代耦合多实例学习(ICMIL),以低成本的方式将嵌入器和包分类器耦合在一起。ICMIL 首先固定图块嵌入器来训练包分类器,然后固定包分类器来微调图块嵌入器。经过优化的嵌入器随后能够生成更好的表示,从而为下一次迭代提供更准确的分类器。为了实现更灵活且更有效的嵌入器微调,我们还引入了一个教师-学生框架,以高效地从袋式分类器中提取类别知识,以帮助实例级嵌入器进行微调。
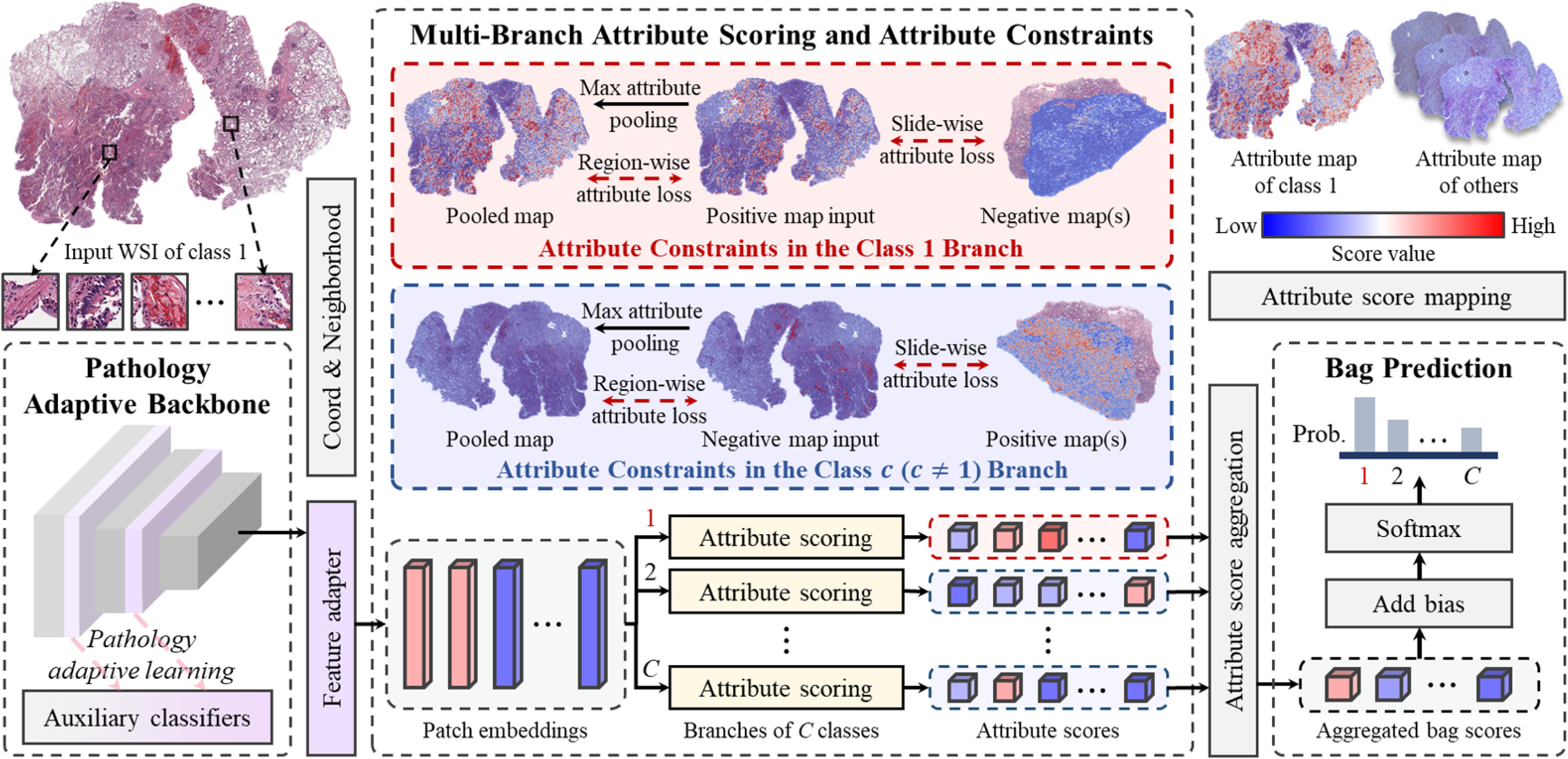
【】AttriMIL: Revisiting attention-based multiple instance learning for whole-slide pathological image classification from a perspective of instance attributes MEDICAL IMAGE ANALYSIS 2025
最近基于注意力机制的 MIL 架构显著提高了弱监督的 WSI 分类能力,有助于临床诊断和疾病阳性区域的定位。然而,这些方法在区分实例方面常常面临挑战,导致组织误识别,并可能降低分类性能。为了解决这些局限性,我们提出了 AttriMIL,这是一种具有属性感知的多实例学习框架。通过剖析基于注意力机制的 MIL 模型的计算流程,我们引入了一个多分支属性评分机制,用于量化单个实例的病理属性。利用这些量化属性,我们进一步建立了区域级和切片级属性约束,以便在训练过程中动态地在切片内部和之间建模实例的相关性。这些限制促使网络捕捉图像块之间的内在空间模式和语义相似性,从而增强了其区分细微组织变化的能力以及应对复杂情况的敏感度。
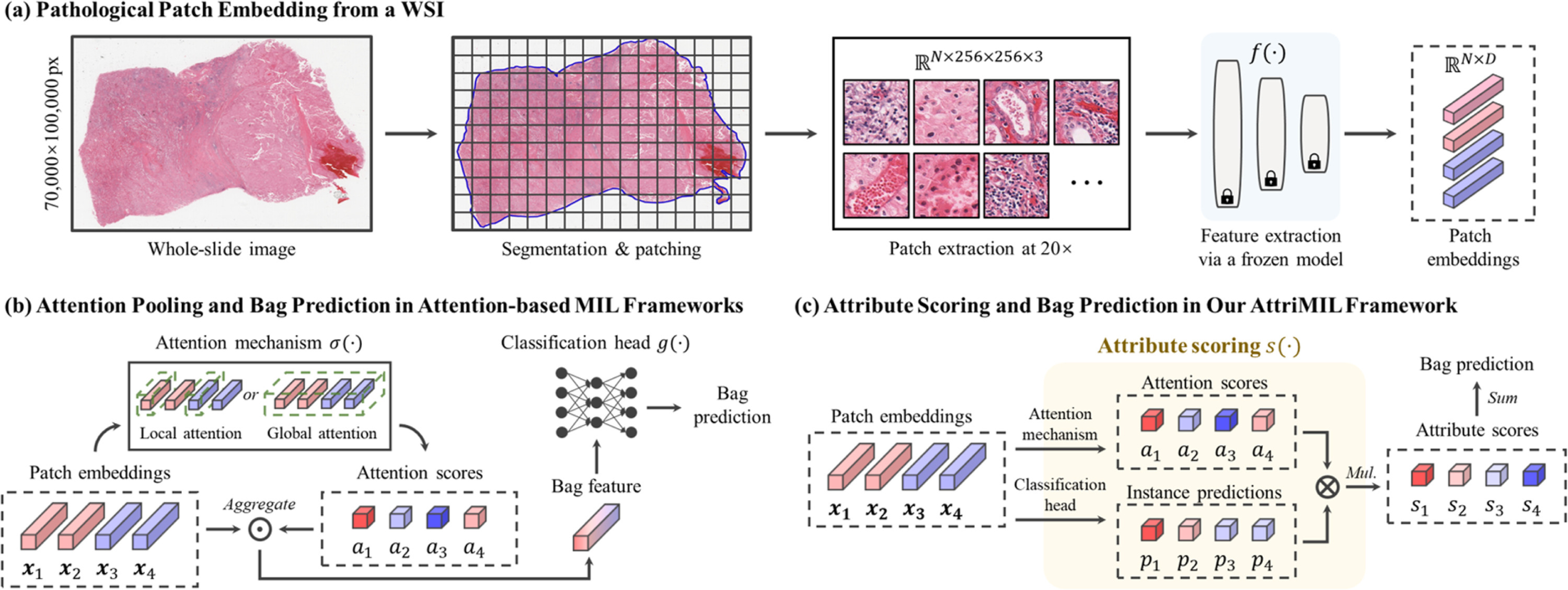
对于输入的 WSI 图像,AttriMIL 会将其分割成小块,并利用病理适应型骨干网络来获取优化的实例嵌入。接下来,它会使用多分支属性评分机制为每个类别生成实例属性得分。对于特定分支,同类别的一组 WSI 被视为正样本,而其他类别的 WSI 则被视为负样本。在训练阶段,会应用属性约束以增强网络对实例病理属性的感知能力。最后,AttriMIL 进行得分聚合以获得袋得分,然后使用这些袋得分来生成最终结果的袋预测概率(Prob.)。
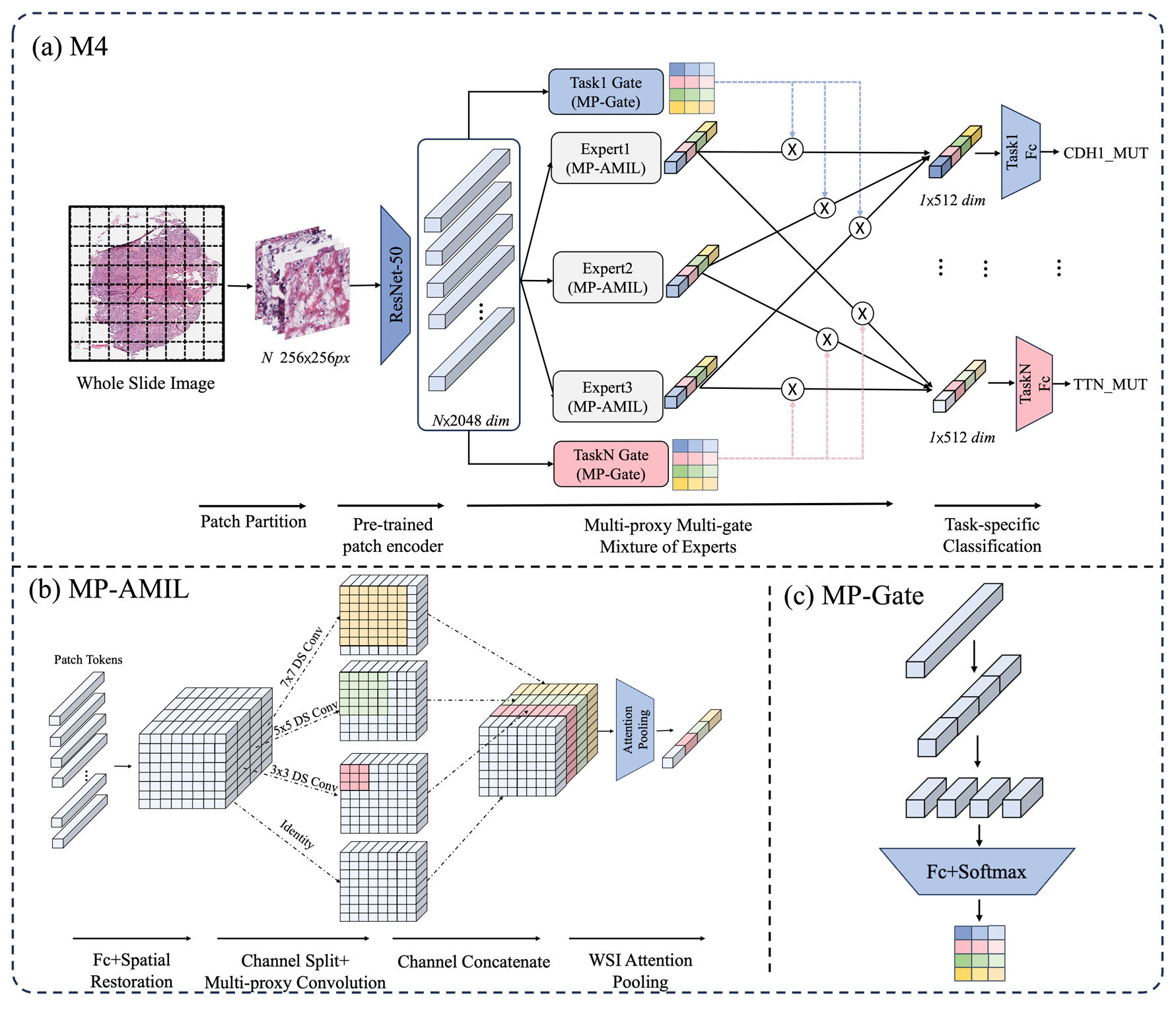
【】M4: Multi-proxy multi-gate mixture of experts network for multiple instance learning in histopathology image analysis MEDICAL IMAGE ANALYSIS 2025
现有的 MIL 方法主要侧重于单任务学习,这不仅导致整体效率低下,还忽略了任务之间的相关性。为了解决这些问题,我们提出了一个名为"多门混合专家多代理多实例学习(M4)"的改进架构,并将此框架应用于从 WSI 中同时预测多个基因突变。所提出的 M4 模型有两个主要创新点:(1)采用多门混合专家策略在单个 WSI 上同时预测多个基因突变;(2)在专家和门网络上引入多代理卷积神经网络结构,以有效且高效地捕捉 WSI 中的斑块-斑块交互。
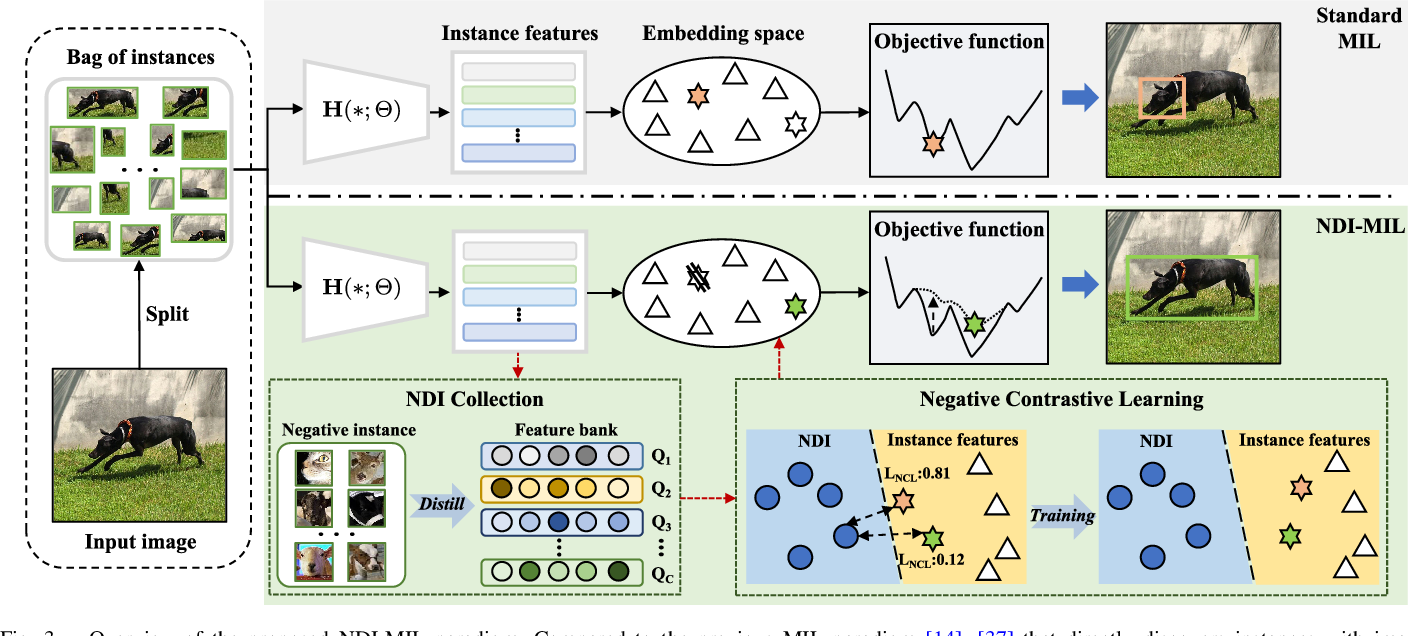
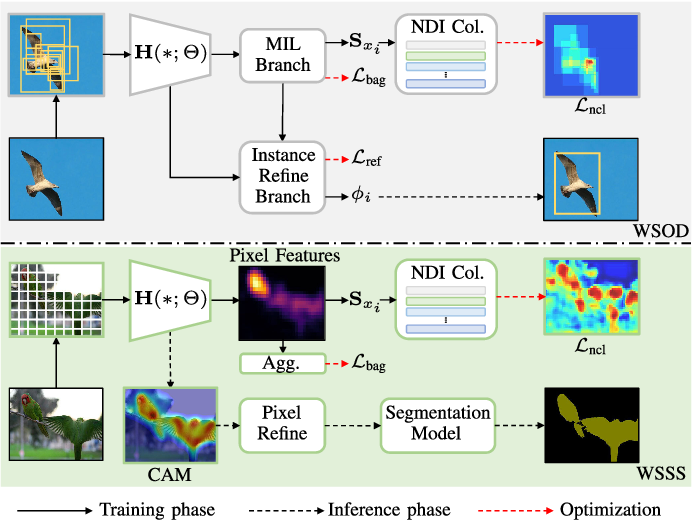
【】Negative Deterministic Information-Based Multiple Instance Learning for Weakly Supervised Object Detection and Segmentation TNNLS2025
传统的 MIL 方法往往存在一些问题,例如有判别性的实例主导和缺失实例的问题。在本文中,我们观察到负实例通常包含有价值的确定性信息,这是解决这两个问题的关键。受此启发,我们提出了一种基于负确定性信息(NDI)的新型多实例学习范式,称为 NDI-MIL,它基于两个核心设计,并具有递进的关系:NDI 收集和负对比学习(NCL)。在 NDI 收集中,我们通过动态特征库在线识别并提炼负实例中的 NDI。收集到的 NDI 数据随后会在 NCL 机制中被利用,以定位并惩罚那些具有歧视性的区域,从而有效地解决了具有歧视性的实例主导和缺失实例的问题,从而提高了对象和像素级别的定位精度和完整性。此外,我们还设计了一种由 NDI 引导的实例选择(NGIS)策略,以进一步提升系统的性能。
【】Interactive multiple instance learning network for whole slide image analysis EXPERT SYSTEMS WITH APPLICATIONS2025
尽管多实例学习(MIL)已成为用于 WSI 分析的一种有前景的方法,但现有的方法往往忽略了关键的文本信息以及实例之间的上下文关联。我们提出了一种交互式多实例学习(iMIL)框架,通过两个新颖的视角(多实例聚合和提示引导注意力)来克服这些局限性:多实例聚合模块有效地结合了实例级别的特征(局部细节)、切片级别的特征(全局上下文)以及临床文本信息,从而为每个 WSI 提供了更全面的表示。提示引导注意力模块利用可学习的提示来调节网络对实例中特定特征的注意力,使模型即使在标注较弱的情况下也能专注于病变相关区域。此外,一个交互式改进模块通过多层次特征和上下文信息反馈实现了模型的持续改进。
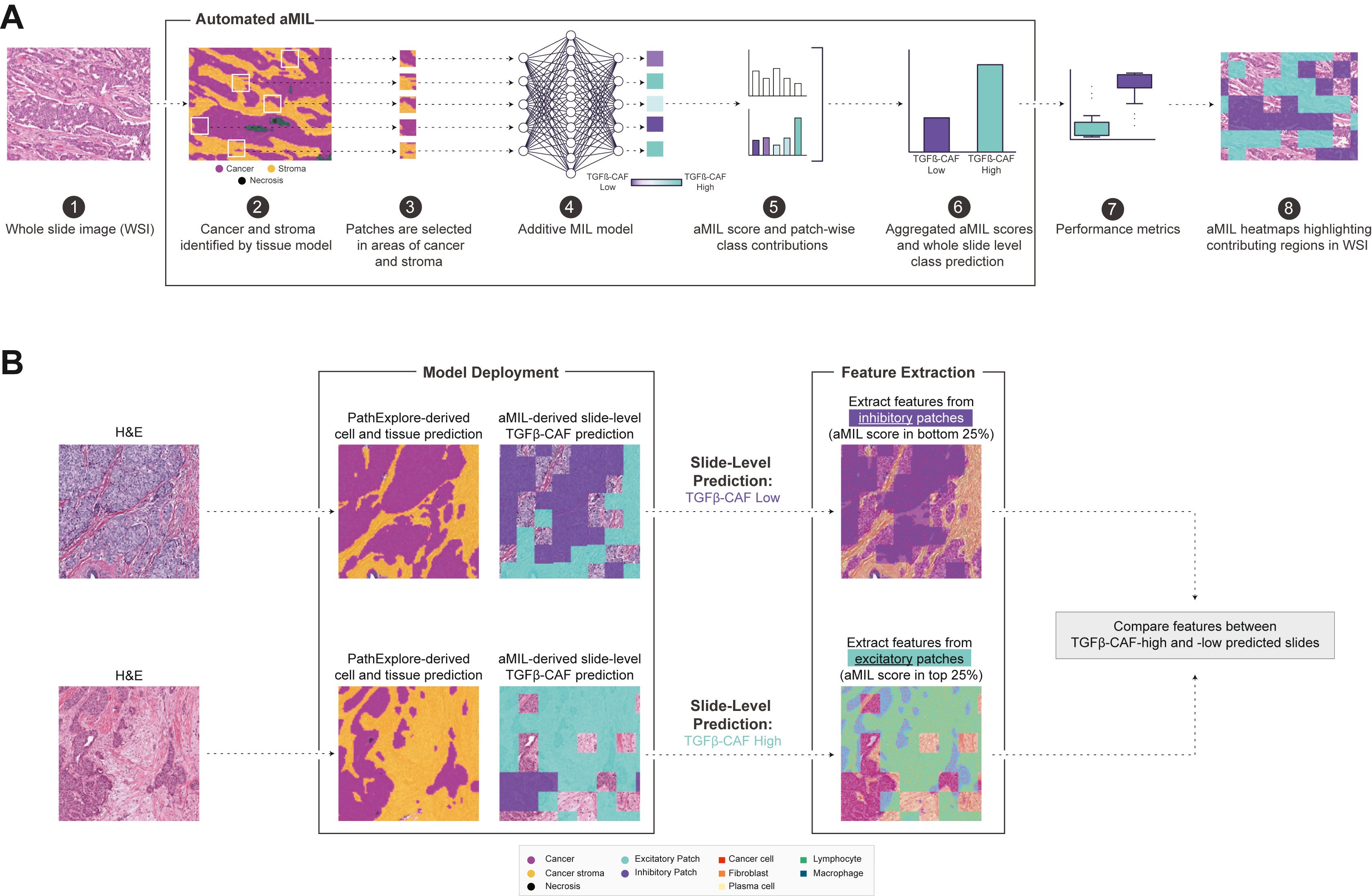
【】Spatial Mapping of Gene Signatures in Hematoxylin and Eosin-Stained Images: A Proof of Concept for Interpretable Predictions Using Additive Multiple Instance Learning Modern Pathology 2025
癌症相关成纤维细胞 (CAF) 亚型的相对丰度会影响肿瘤对治疗(尤其是免疫疗法)的反应。然而,与这些 CAF 亚型相关的基因表达特征尚未充分发挥其作为临床生物标志物的潜力。本文介绍了一种可解释的机器学习方法------加性多示例学习 (aMIL),用于从苏木精-伊红染色的全切片图像中预测整体基因表达特征,重点关注富含免疫抑制性 LRRC15+ CAF 的 TGFβ-CAF 特征。aMIL 模型能够准确预测多种癌症类型中的 TGFβ-CAF。我们利用机器学习模型评估了对切片水平 TGFβ-CAF 预测贡献最大的组织区域,这些模型能够表征不同细胞和组织类型、基质亚型以及核形态的空间分布。在乳腺癌中,对 TGFβ-CAF 高表达预测("兴奋性")贡献最大的区域位于具有高成纤维细胞密度和成熟胶原纤维的癌基质中。对TGFβ-CAF低表达预测贡献最大的区域("抑制性")位于癌上皮和炎症严重的间质中。成纤维细胞和淋巴细胞的核形态在兴奋性和抑制性区域之间也存在差异。因此,aMIL能够建立组织学特征与转录之间的数据驱动联系,提供超越传统黑箱模型的生物学解释力。
【】MSMMIL: Multi-scan Mamba-based Multiple Instance Learning for whole slide image classification Knowledge-Based Systems 2025
多示例学习已成为计算病理学中分析全切片图像(WSI)的主要技术。它通常利用注意力机制来突出最具区分性的实例。尽管取得了显著进展,WSI分类仍然面临挑战,尤其是在从通常包含大量冗余或无关信息的长实例序列中高效提取判别性特征方面。为了解决这个问题,本研究提出了一种名为基于多扫描Mamba的多示例学习(MSMMIL)的新方法。该框架引入了一个多扫描Mamba模块,其中包括两种新的互补扫描策略(网格扫描和层扫描)、一种现有的原始扫描策略以及三个全局上下文注意力(GCA)模块。这三种扫描策略共同建模方向依赖性、恢复结构连续性和保持空间一致性,从而能够更有效地从长实例序列中提取判别性特征。而轻量级的GCA模块则用于学习不同实例之间的特征关联并放大关键实例。
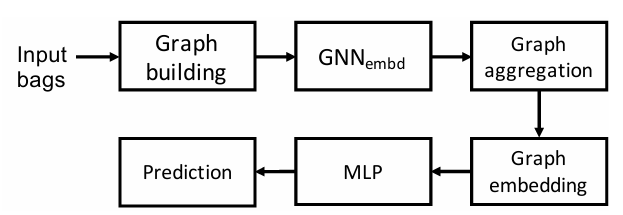
【】Reinforced GNNs for Multiple Instance Learning TNNLS2025
多实例学习(MIL)是从包含多个实例的"实例包"中训练模型的,每个实例包中都包含多个实例,并且只有包级别的标签可供监督。在捕获实例包内的拓扑结构方面,图神经网络(GNNs)的应用有效地改进了 MIL。现有的 GNN 通常需要过滤实例之间的低置信度边,并根据新的实例包结构调整图神经网络架构。然而,这种对结构和架构的异步调整既繁琐又忽略了它们之间的关联。为了解决这些问题,我们提出了一个强化的 MIL GNN 框架(RGMIL),开创性地将多智能体深度强化学习(MADRL)应用于 MIL 任务中。MADRL 使影响实例图或 GNN 的因素能够灵活定义或扩展,并对它们进行同步控制。此外,MADRL 探索结构到架构的关联,并实现自动调整。
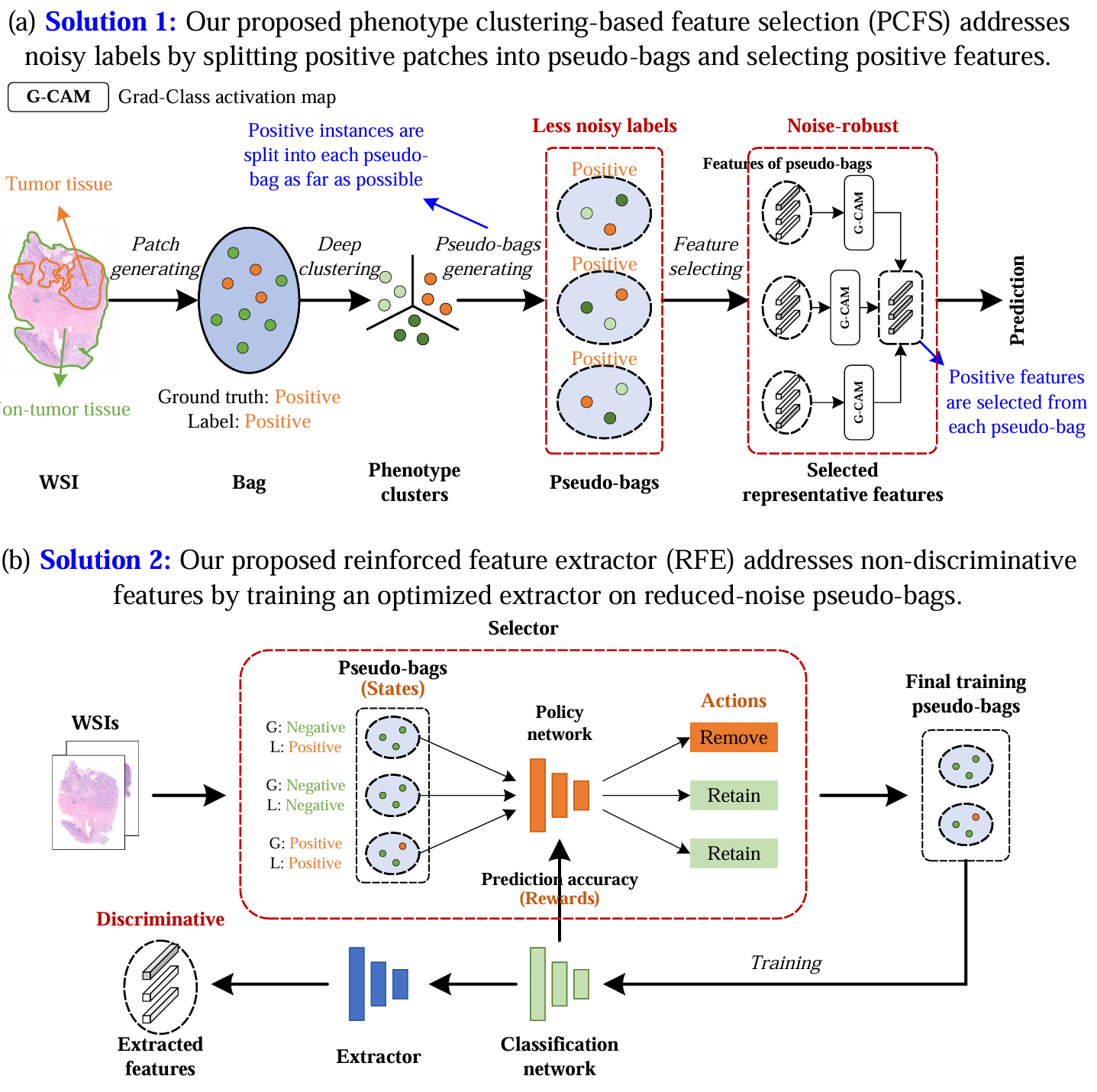
【】PCR-MIL: Phenotype Clustering Reinforced Multiple Instance Learning for Whole Slide Image Classification MICCAI2025
现有的 MIL 方法仍然面临一些挑战,特别是由于样本量小或有限的 WSI(包)而导致的过拟合问题。伪包通过增加训练包的数量来增强 MIL 的分类性能。然而,这些方法在处理噪声标签方面存在困难,因为阳性区域通常只占据组织的较小部分,而伪包通常是通过随机分割生成的。此外,由于缺乏特定领域的特征提取器,它们还面临着非判别性实例嵌入的难题。为了克服这些局限性,我们提出了"表型聚类强化多实例学习"(PCR-MIL),这是一种新颖的多实例学习框架,它通过结合基于聚类的伪包来提高 MIL 的抗噪能力和实例嵌入的判别能力。PCR-MIL 引入了两个关键创新:(i)基于表型聚类的特征选择(PCFS),用于选择用于预测的相关实例嵌入。它将实例聚类为具有特定表型的组,将正例分配到每个伪袋中,然后使用 Grad-CAM 选择最相关的正例嵌入。这种方法缓解了噪声标签带来的挑战,并增强了 MIL 对噪声的鲁棒性;(ii)强化特征提取器(RFE)利用强化学习基于选定的干净伪袋而非噪声样本来训练提取器。这种方法提高了提取的实例嵌入的判别能力,并增强了 MIL 的特征表示能力。
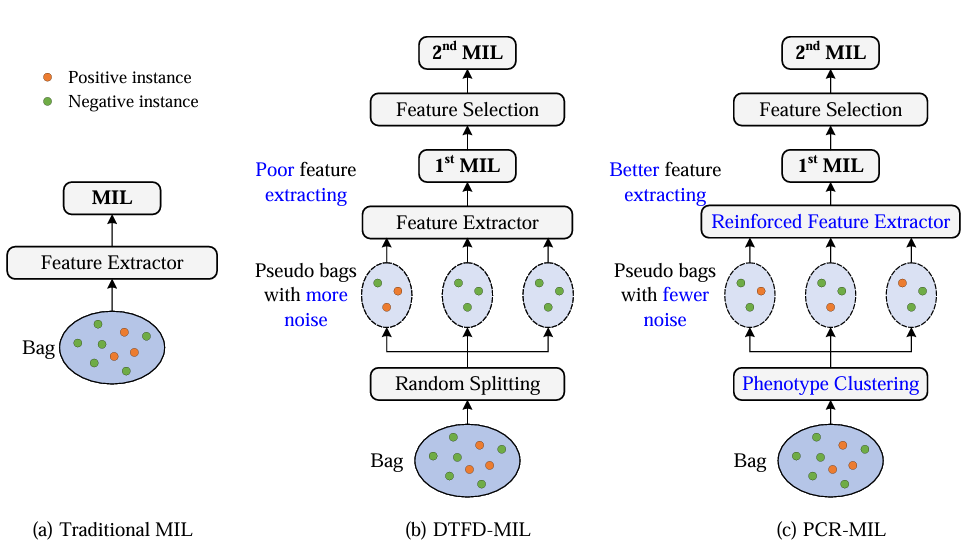 (a)传统的 MIL 以一个 WSI 包作为输入。 (b)DTFD-MIL 通过引入伪包来缓解因包数量有限而导致的过拟合问题。(c)
(a)传统的 MIL 以一个 WSI 包作为输入。 (b)DTFD-MIL 通过引入伪包来缓解因包数量有限而导致的过拟合问题。(c)
我们提出的 PCR-MIL 方法不仅解决了过拟合问题,还增强了 MIL 在面对噪声时的稳健性,并提升了其特征表示能力。 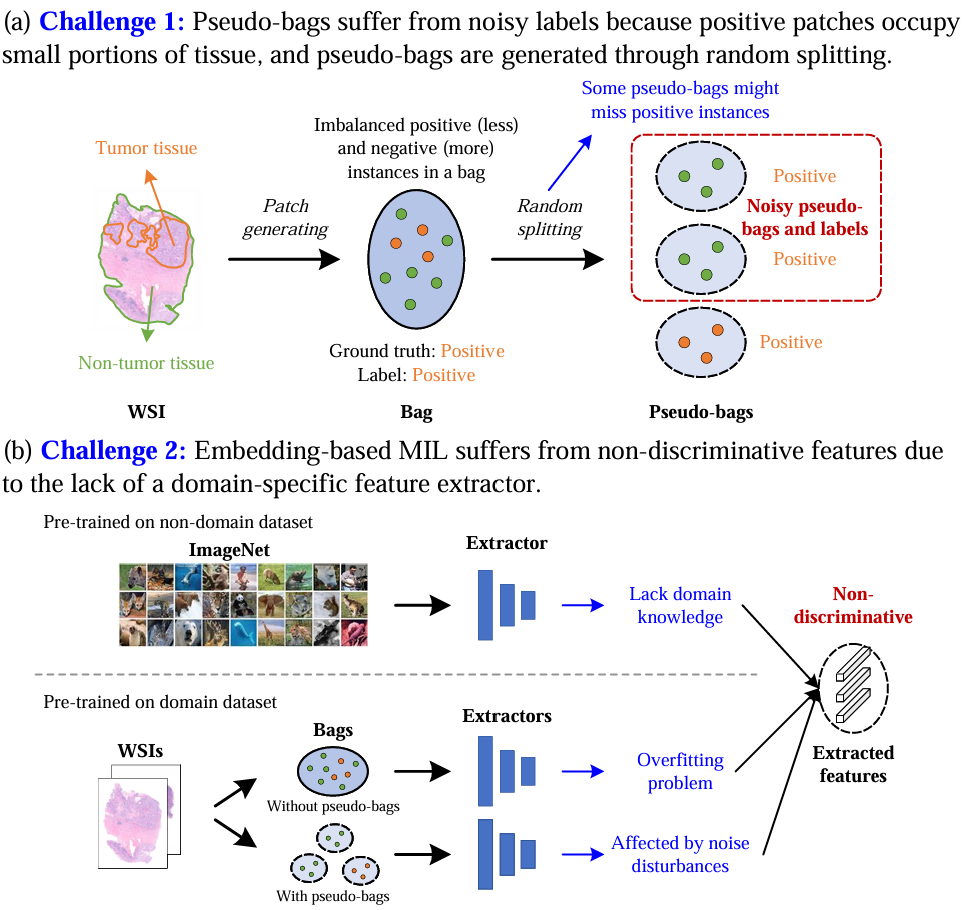 基于伪包络的 MIL 在用于 WSI(全息组织图像)分类时面临两个主要挑战:
基于伪包络的 MIL 在用于 WSI(全息组织图像)分类时面临两个主要挑战:
(a)伪包络存在标签噪声的问题,因为阳性区域仅占组织的较小部分,并且这些伪包络是通过随机分割生成的;(b)基于嵌入的多示例学习方法由于缺乏特定领域的特征提取器,因此在处理非区分性特征时会遇到困难。
【】Multi-Instance Learning for Whole-Slide Image Classification Using Higher-Order Moments ICLR2026
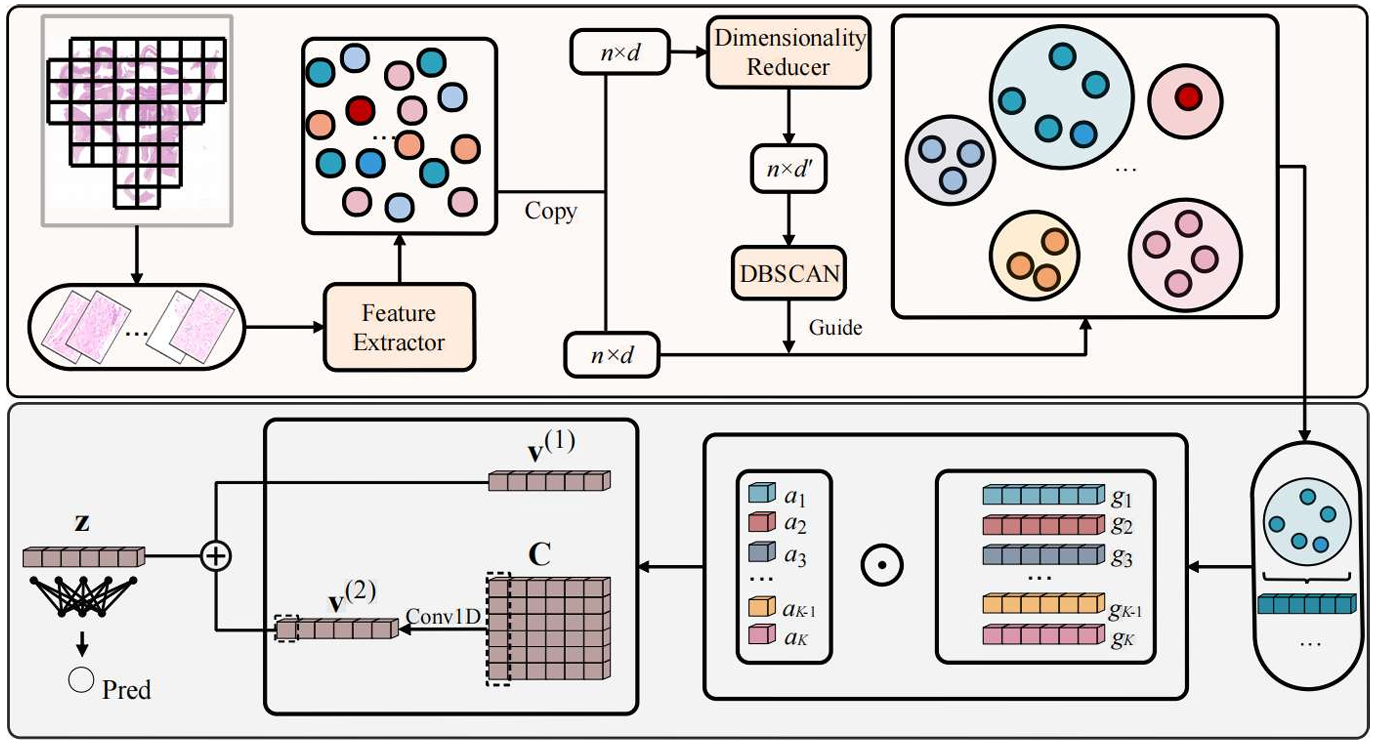
全切片图像(WSI)包含丰富的病理信息。然而,WSI 极高的分辨率和大量的冗余信息给人工分析和人工智能处理都带来了巨大的挑战。多示例学习(MIL)是目前主流的方法,它通常将所有图像块的低维特征表示聚合到一个向量中。如果将图像块向量视为随机变量,则这种聚合过程本质上等价于估计这些随机向量的一阶矩。然而,仅凭一阶矩无法完全捕捉整个切片的信息,因此需要计算二阶矩。具体而言,我们首先采用基于注意力机制的多示例学习(ABMIL)来计算图像块的注意力加权平均值,以此作为一阶矩的估计值。同时,我们计算整个切片上图像块表示向量的协方差矩阵。通过聚合一阶矩和二阶矩的信息,我们可以显著提高 WSI 的分类精度。为了提高计算效率,我们采用了DBSCAN聚类算法,该算法能够自适应地为丰富的正常组织形成大簇,为稀有的病变区域形成小簇,从而实现可变分辨率处理,在保留诊断信息的同时降低计算成本。
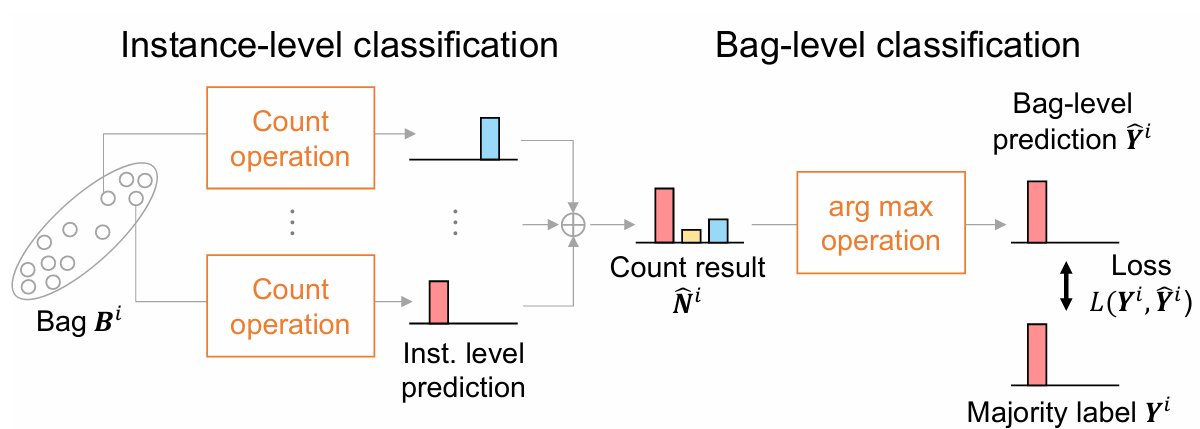
【】Learning from majority label: A novel problem in multi-class multiple-instance learning
PATTERN RECOGNITION 2026
该论文提出了一种新颖的多类别多实例学习(MIL)问题,称为基于多数标签的学习(LML)。在 LML 中,一个包中的实例的多数类别被指定为包级别的标签。LML 的目标是训练一个分类模型,该模型能够使用多数标签来估计每个实例的类别。这个问题在多种应用中都具有重要价值,包括病理图像分割、政治投票预测、客户情绪分析和环境监测。为了解决 LML 问题,我们提出了一种训练有素的计数网络,用于生成包级别的多数标签,该标签是通过统计每个类别的实例数量来估计的。此外,对 LML 特征的分析实验表明,多数类别的比例较高的包有助于学习。基于这一结果,我们开发了一个多数比例增强模块(MPEM),通过从包内的少数类别的实例中移除它们来增加多数类别的比例。
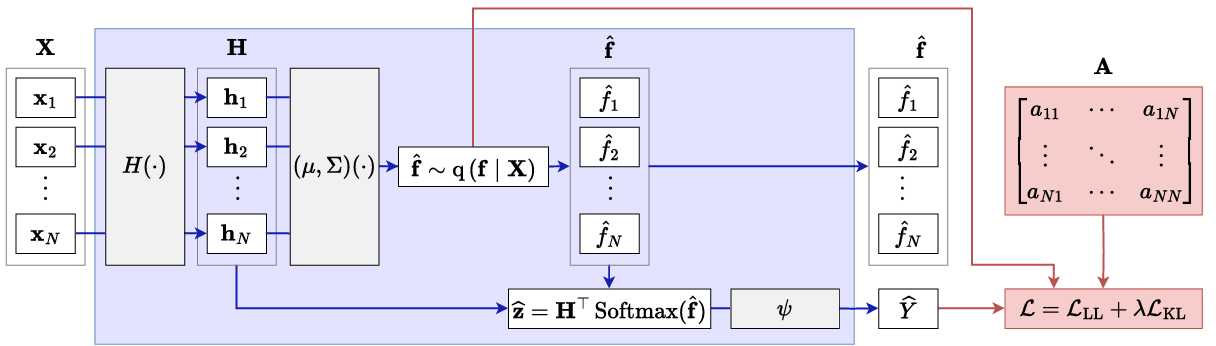
【】Probabilistic smooth attention for deep multiple instance learning in medical imaging PATTERN RECOGNITION 2026
深度 MIL 方法通过注意力机制将实例级别的表示进行聚合,以计算包级别的预测,取得了令人瞩目的成果。这些方法通常通过各种机制同时捕捉相邻实例之间的局部相互作用和全局、长距离的依赖关系。然而,它们对注意力值的处理是确定性的,可能会忽略单个实例贡献的不确定性。在这项工作中,我们提出了一种新颖的概率框架,该框架能够估计注意力值的概率分布,并同时考虑全局和局部相互作用。
【】Top-Down Attention-Based Multiple Instance Learning for Whole Slide Image Analysis MICCAI2026
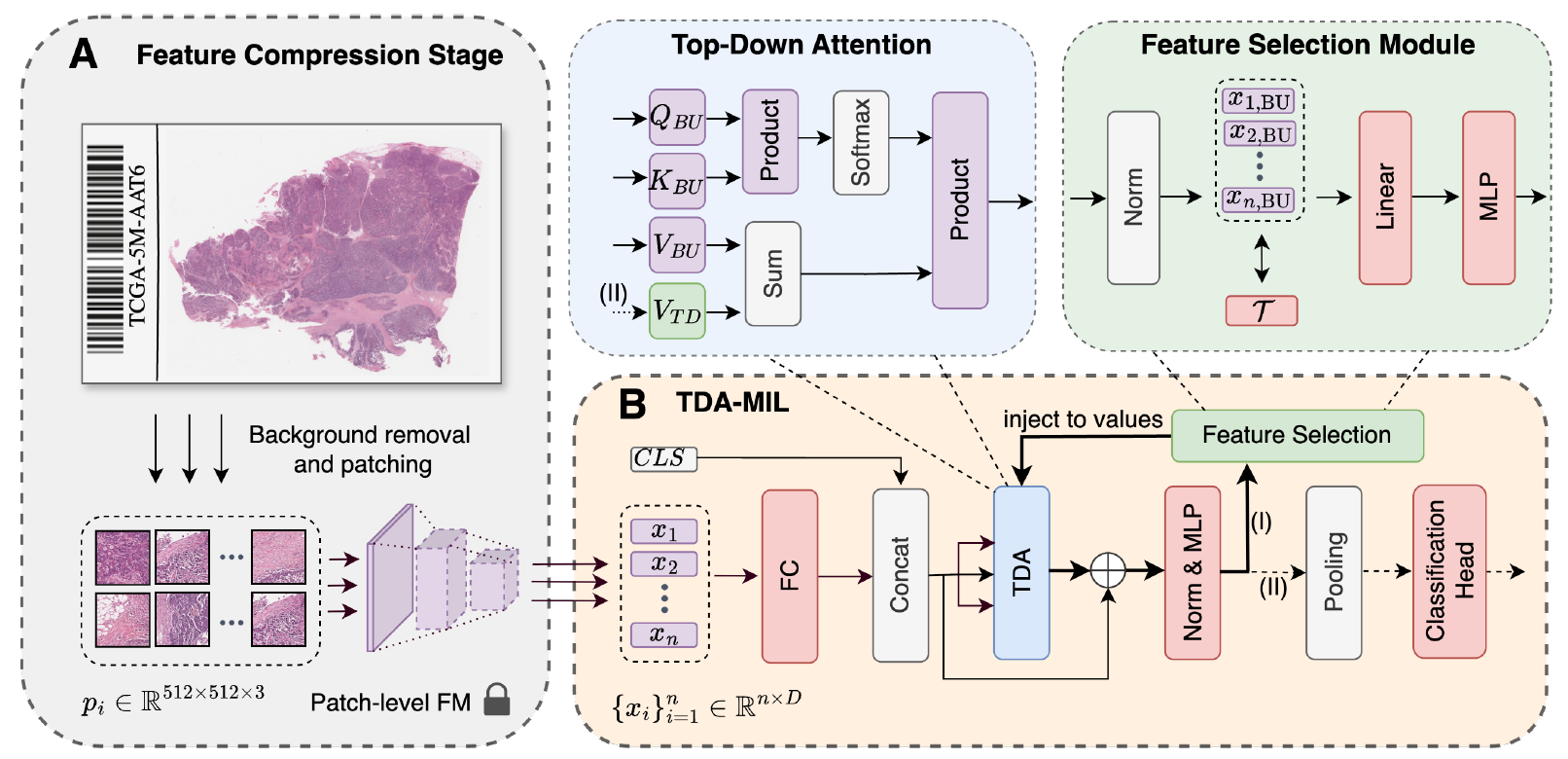
虽然基于实例的注意力机制容易忽略实例之间的关联,但自注意力机制能够捕捉这些相互作用,但它对具体任务并不具有特定的依赖性。为了解决这个问题,我们引入了基于自注意力的自上而下注意力多实例学习(TDAMIL)架构,该架构首先通过初始推理步骤中的自注意力机制从数据中学习通用表示,然后通过特征选择模块识别与任务相关的实例,最后通过将选定的实例重新注入注意力机制进行第二次推理步骤来细化这些表示。通过专注于任务特定的信号,TDAMIL 能够有效地辨别切片中的细微但重要的区域,从而实现更精确的分类。
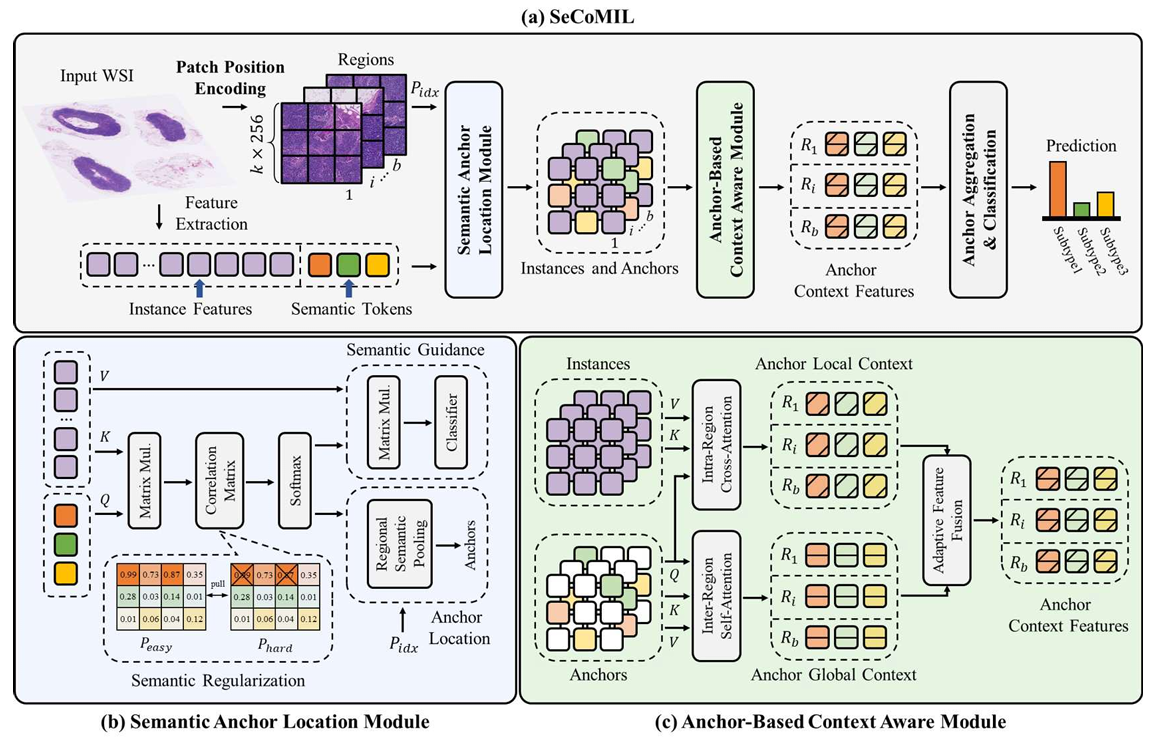
【】SeCoMIL: Semantic Anchor-Based Context-Aware Multiple Instance Learning for Whole Slide Image Classification TCSVT2026
情境感知型多实例学习(MIL)在全切片图像(WSI)分类中正逐渐受到关注。现有的方法通常会将 WSI 中的实例转换为一维序列,并学习实例之间的长程情境依赖关系。然而,由于 WSI 的尺寸极其庞大以及组织结构内的形态相似性,大量冗余的实例显著增加了情境学习模式中的计算开销。此外,将实例重新排列为一维会丢失图像区域中所涉及的固有空间信息,进一步降低了病理图像的分类性能。因此,有效地在 WSI 中建模情境依赖关系仍然是一个关键挑战。在本文中,我们提出了一种新颖的基于语义锚的情境感知型多实例学习(SeCoMIL)框架。该框架将 WSI 划分为一系列区域,并对这些区域内的实例坐标进行编码,以保留它们的空间关系。随后,SeCoMIL 从每个区域中识别出最具代表性的实例作为语义锚。通过同时捕捉这些锚点周围的局部环境以及不同锚点之间的全局环境,该框架能够有效地总结出全息图像序列的关键病理信息,从而实现精确分类。