一、为什么 Redis GEO 这么快?
Redis 在 3.2 版本引入了 GEO 模块,支持地理位置存储和半径查询。它没有发明全新的数据结构,而是巧妙地站在了巨人的肩膀上。
Redis GEO 查询性能之所以极高,核心原因有三点:
- 降维打击:Geohash 将 2维 坐标编码为 1维 整数
二维的空间邻近性问题,被转化成一维的有序集合范围查询。这是一个天才的设计决策。 - 借力打力:完全复用 ZSet 的跳表索引
GEO 数据就是 ZSet 数据。GEOADD 本质上调用的是 ZADD,GEORADIUS 本质上调用的是 ZRANGEBYSCORE。跳表的 O(log n) 查找能力被完整继承。 - 就地取材:52 位整数恰好塞进 double 的尾数
IEEE 754 双精度浮点数的尾数刚好 52 位。Redis 将 Geohash 编码成 52 位整数,可以直接当作 ZSet 的 score 字段使用,既不丢失精度,也不引入额外存储开销。
下面,我们从源码层面逐层展开这三个原因。
二、第一层:Geohash 编码------二维降一维的数学魔术
2.1 算法原理:Z 阶曲线与位交织
Geohash 的核心思想是用一维数值表示二维坐标,同时尽量保持"空间邻近性"。它属于空间填充曲线(Space-Filling Curve)中的 Z 阶曲线(Z-order curve) 的实际应用。
编码过程分为三步:
第一步:区间二分,生成二进制位
以纬度为例,地球纬度范围是 [-90, 90]。每次二分区间,如果坐标落在右区间则记 1,左区间记 0。二分次数越多,精度越高。经度同理,范围是 [-180, 180]。
举个例子:假设纬度 31.19°,落在 [0, 90] → 记 1;继续二分落在 [0, 45] → 记 0;依此类推。每一步的二进制位,就是该坐标在对应精度下的"位置码"。
第二步:位交织(Bit Interleaving)
这是最关键的一步。将经度和纬度的二进制位按"经度在偶数位,纬度在奇数位"的规则交织:
makefile
经度位: L5 L4 L3 L2 L1 L0
纬度位: A5 A4 A3 A2 A1 A0
交织结果: L5 A5 L4 A4 L3 A3 L2 A2 L1 A1 L0 A0Redis 源码中,这一步由 interleave64 函数完成。
第三步:Base32 编码(可选)
如果对外输出 Geohash 字符串,则每 5 位转为一个 Base32 字符。但 Redis 内部存储时并不做这一步------它直接用交织后的 52 位整数作为 score。
下面的流程图直观展示了整个编码过程: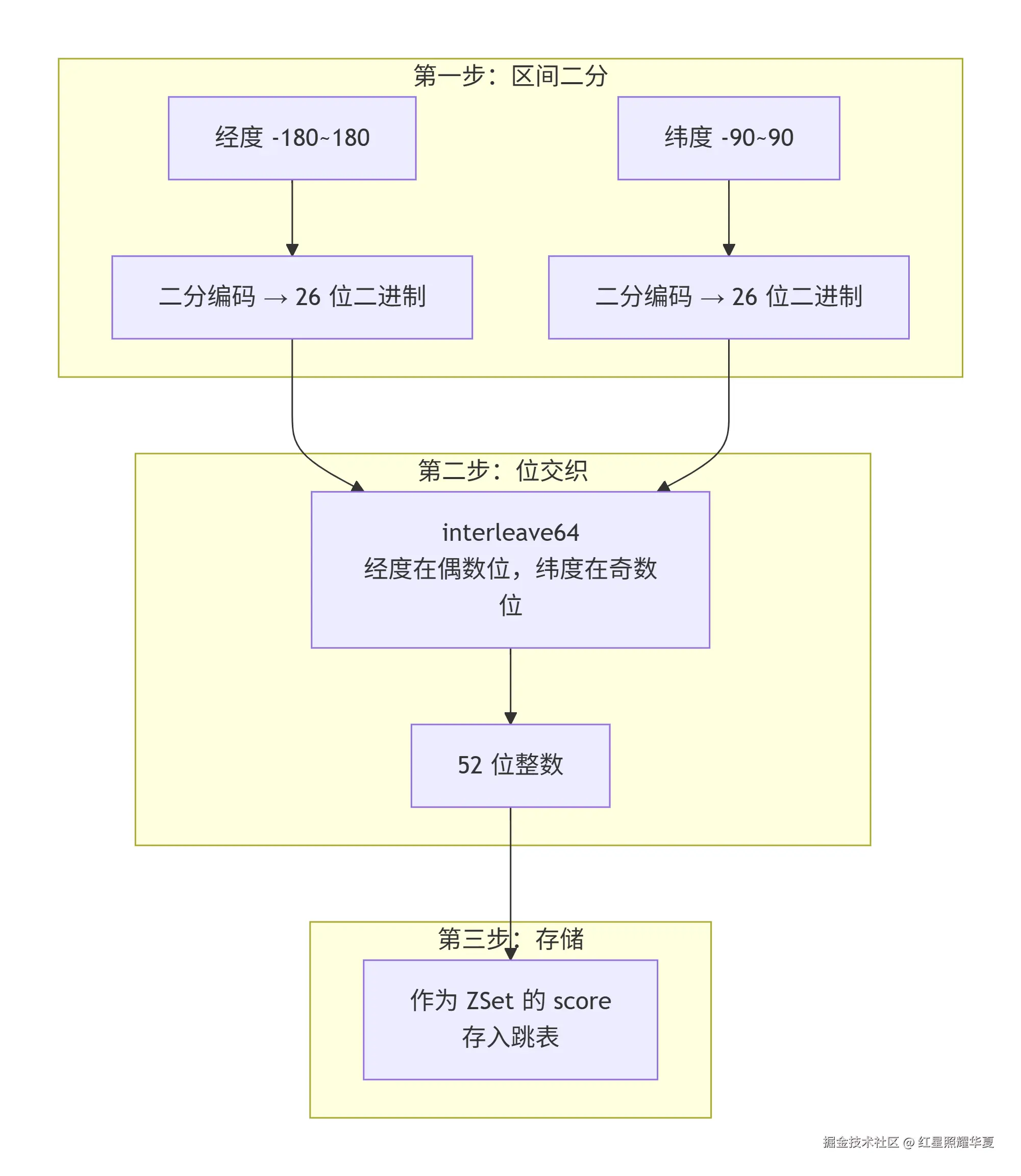
2.2 为什么恰好是 52 位?
这里有一个精妙的设计细节。
Redis ZSet 的 score 字段类型是 double。IEEE 754 双精度浮点数由 1 位符号位、11 位指数位和 52 位尾数位(mantissa) 组成。只要整数不超过 2⁵²,就能无损地存入 double。
因此,Redis 选择将 Geohash 编码为 52 位整数------经度 26 位,纬度 26 位,交织后正好 52 位。
这意味着什么?Geohash 值可以直接作为 score 使用,不需要额外存储空间,没有转换损耗。
精度方面,26 位经度和 26 位纬度的组合,在赤道附近的定位精度约为 0.6 米,完全满足绝大多数 LBS 场景的需求。
2.3 纬度为什么被限制在 ±85°?
你可能注意到,Redis GEO 的纬度范围是 [-85.05112878°, 85.05112878°],而不是理论上的 [-90°, 90°]。
原因有三:
- Geohash 的边界问题:在极地附近(纬度接近 ±90°),经度的微小变化会导致 Geohash 值剧烈跳动,破坏"相邻坐标 → 相近编码"的局部性。
- 墨卡托投影的变形 :Web 地图常用墨卡托投影,高纬度地区形变严重。
85.05112878°正好是 Web Mercator 的最大有效纬度,由arctan(sinh(π))计算得出。 - 实用性考量:南北纬 85° 以上基本是无人区,实际 LBS 场景用不到。
在 geo.c 中,解码函数会显式检查这个边界:
ini
if (xy[1] > 85.05112878 || xy[1] < -85.05112878) {
return 0; // 纬度超出范围
}2.4 Z 阶曲线的空间局部性
Geohash 的一个核心性质是:地理位置越接近,Geohash 值的公共前缀越长(绝大多数情况下成立)。
这是 Z 阶曲线"空间填充"特性的体现:
┌─────┬─────┐
│ 00 │ 01 │ 纬度高位 0
├─────┼─────┤
│ 10 │ 11 │ 纬度高位 1
└─────┴─────┘
经度 0 经度 1在二维平面上,编码值按照 Z 字形顺序遍历网格。相邻网格的编码值通常也很接近。
但 Z 阶曲线有一个著名的缺陷:边界突变。两个地理位置可能非常接近,却恰好位于不同 Geohash 网格的边界两侧,导致编码值相差很大。后文会讲到 Redis 如何用"9 宫格搜索"来解决这个问题。
三、第二层:ZSet 与跳表------Redis 的"存储引擎"
3.1 GEO 数据就是 ZSet 数据
这是理解 Redis GEO 最关键的一点。
当你执行 GEOADD cities 116.40 39.90 Beijing,Redis 实际做的是:
- 调用
geohashEncodeWGS84将(116.40, 39.90)编码为 52 位整数 - 调用
zsetAdd,以该整数为 score,"Beijing"为 member,插入 ZSet
同理,GEORADIUS 命令也是先计算 Geohash 范围,再调用 ZSet 的范围查询函数 zrangebyscore。
GEO 模块并没有新增任何底层数据结构,它只是一个"适配层" ------ 将地理坐标翻译成 ZSet 能理解的 score。
3.2 ZSet 的双编码策略
ZSet 本身采用"双编码"策略,在不同数据量下自动切换:
markdown
数据量小 数据量大
│ │
▼ ▼
┌─────────┐ ┌─────────────┐
│ ziplist │ ───────────► │ skiplist │
│(压缩列表)│ 超过阈值自动转换 │ + dict │
└─────────┘ └─────────────┘ziplist 编码:当元素数量小于 128 且每个 member 小于 64 字节时使用。ziplist 是一块连续内存,没有指针开销,内存利用率极高,但查询需要遍历,复杂度 O(n)。
skiplist + dict 编码:大数据量时的默认编码。跳表负责按 score 排序和范围查询,字典负责按 member 快速定位。两者共享同一份数据,不重复存储。
GEO 场景通常数据量较大,所以实际生产中 GEO 数据基本都使用跳表编码。
3.3 跳表结构拆解
Redis 跳表的核心结构定义在 server.h 中:
arduino
typedef struct zskiplistNode {
robj *obj; // member 对象
double score; // 分值(Geohash)
struct zskiplistNode *backward; // 后退指针
struct zskiplistLevel {
struct zskiplistNode *forward; // 前进指针
unsigned int span; // 跨度
} level[]; // 柔性数组,多级索引
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length; // 节点总数
int level; // 当前最大层数
} zskiplist;每个节点维护一个 level[] 柔性数组,数组长度就是节点的"层高"。层高越高,该节点出现在越多的索引层中,查找时就能跳过越多的节点。
下面是跳表的逻辑结构示意:
yaml
Level 3: HEAD ──────────────────► 50 ─────────► NULL
Level 2: HEAD ──────► 20 ──────► 50 ──► 70 ──► NULL
Level 1: HEAD ─► 10 ─► 20 ─► 35 ─► 50 ─► 70 ─► NULL
│ │ │ │ │
▼ ▼ ▼ ▼ ▼
backward 指针(双向链表,便于倒序遍历)- 前进指针(forward) :指向当前层下一个节点
- 跨度(span) :记录 forward 跳过了多少个节点,用于快速计算元素排名
- 后退指针(backward) :构成双向链表,支持反向遍历
3.4 层高的概率生成
节点的层高不是固定的,而是在插入时随机生成。Redis 使用一个经典的"抛硬币"算法:
arduino
#define ZSKIPLIST_P 0.25 // 概率为 1/4
#define ZSKIPLIST_MAXLEVEL 32 // 最大 32 层
int zslRandomLevel(void) {
int level = 1;
while ((random() & 0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level < ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}这个算法的含义是:
- 节点至少有 1 层(概率 100%)
- 有 25% 的概率增加 1 层
- 有 25% × 25% = 6.25% 的概率再增加 1 层
- 依此类推,呈指数衰减
层高的期望值 = 1 / (1 - 0.25) = 1.33 层。大多数节点只有 1~2 层,极少数节点能达到高层。这种概率分布使得跳表在保持 O(log n) 查找性能的同时,索引开销(额外的 forward 指针)非常低。
3.5 插入操作详解
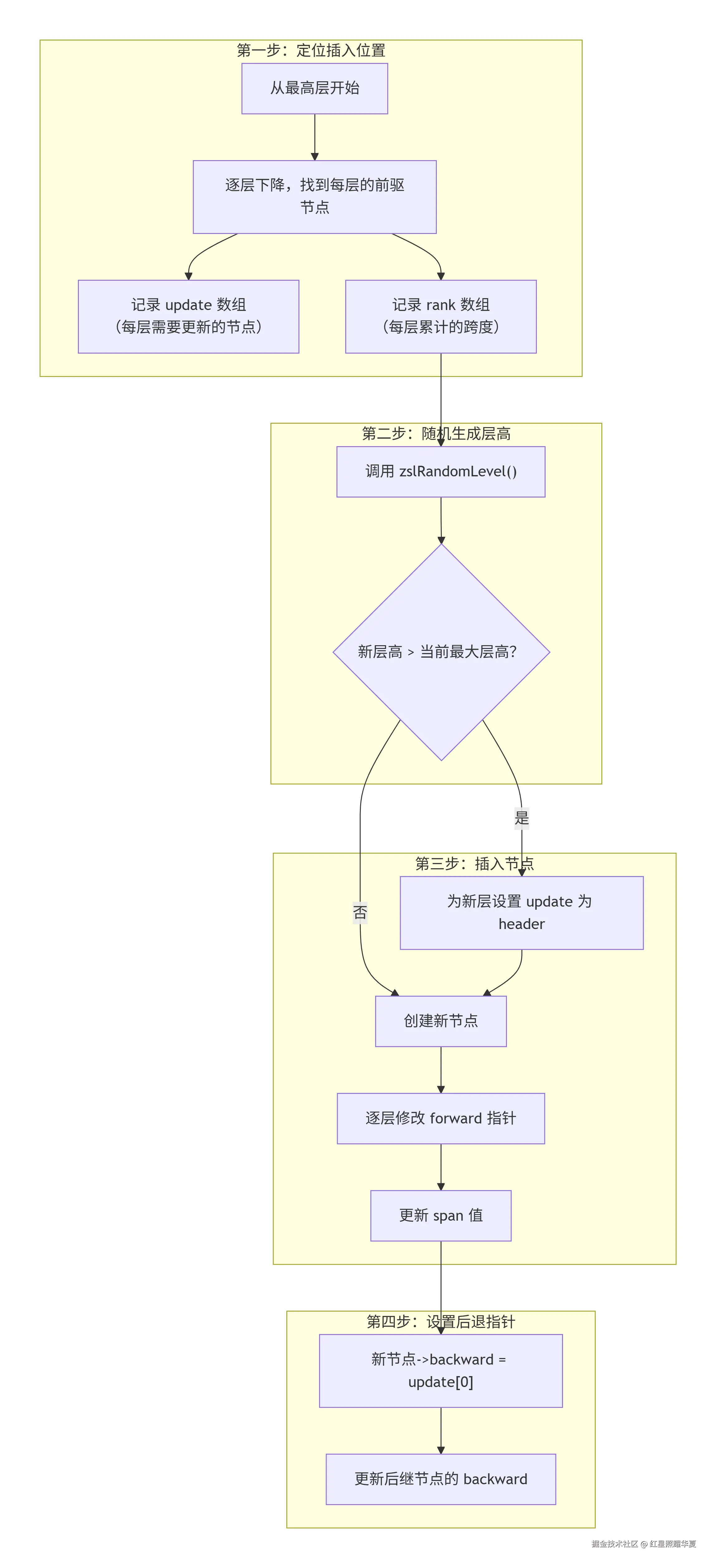
插入操作是理解跳表最核心的环节。Redis 的 zslInsert 函数执行以下步骤:
关键细节:
- update 数组:记录每一层中"刚好比新节点 score 小"的节点。插入时只需修改这些节点的 forward 指针,不需要调整其他节点。
- rank 数组:累计每一层从 header 到 update 节点的跨度,用于后续计算新节点的 span。
- 层高随机但不影响其他节点:这是跳表相比平衡树最大的优势------插入不会引发全局结构调整,只修改受影响节点的指针。平衡树(如 AVL、红黑树)插入后可能需要旋转,影响面更大。
3.6 为什么 Redis 用跳表而不用 B+ 树?
这是一个经典的架构选型问题。
| 对比维度 | 跳表 | B+ 树 |
|---|---|---|
| 实现复杂度 | 简单,约 200 行代码 | 复杂,涉及分裂、合并、旋转 |
| 并发性能 | 天然支持高并发(只锁局部) | 需要复杂的锁机制 |
| 内存占用 | 索引指针灵活,可调概率 | 节点有固定大小,可能有碎片 |
| 范围查询 | 优秀(level 0 就是有序链表) | 优秀(叶子节点有序链表) |
| 磁盘友好 | 否(指针随机跳转) | 是(一个节点存多个 key) |
Redis 选择跳表的核心原因:
- 内存数据库不需要磁盘优化。B+ 树的一个节点存多个 key,是为了减少磁盘 I/O。Redis 跑在内存里,这个优势不存在。
- 实现简单,易于维护。跳表的核心逻辑不到 200 行 C 代码,而 B+ 树的实现要复杂得多。
- 无锁化改造潜力大。跳表只修改局部指针,天然适合做 lock-free 数据结构。Redis 本身是单线程模型,但社区已有基于跳表的并发版本探索。
四、第三层:GEORADIUS 查询------9 宫格搜索策略
4.1 从圆到矩形的降级
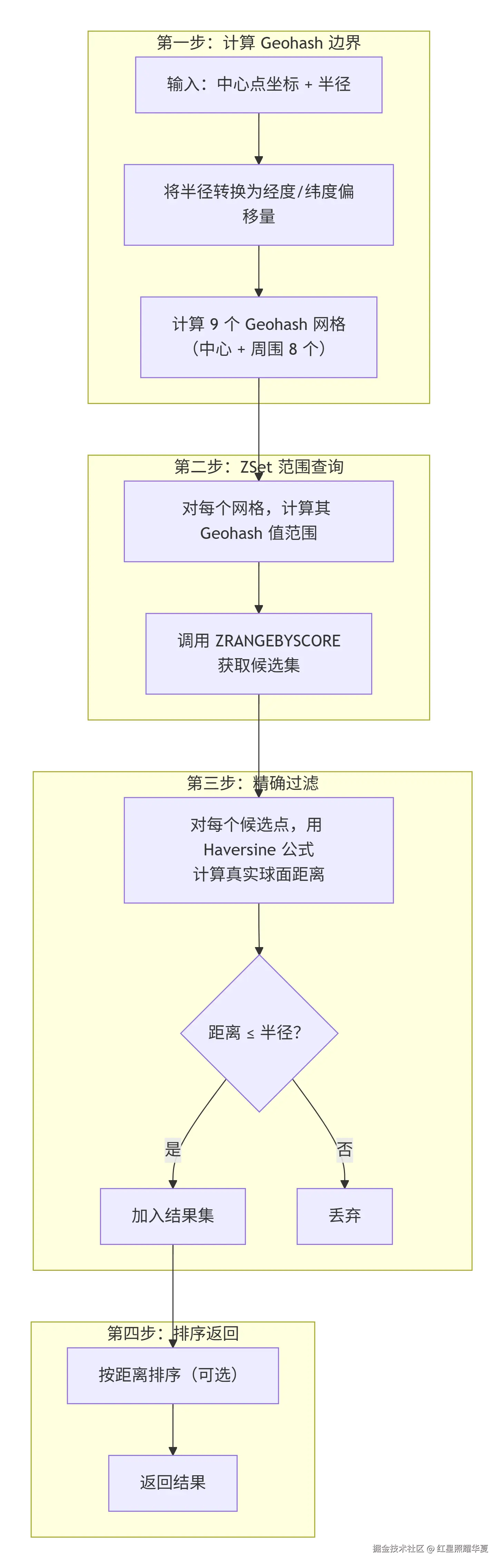
GEORADIUS 的核心流程如下:
4.2 为什么要查 9 个网格?
前面提到 Geohash 有"边界突变"问题------两个很近的点可能落在不同网格,编码相差很大。如果只查中心点所在的网格,会漏掉边界附近的点。
Redis 的解决方案是:计算中心点所在网格,以及它周围 8 个相邻网格,共 9 个网格。
这 9 个网格的 Geohash 值构成了 9 段连续的整数区间。Redis 对每一段区间执行一次 ZRANGEBYSCORE,把所有候选点捞出来。
4.3 精度与半径的权衡
Geohash 网格的大小取决于编码长度(位数)。Redis 默认使用 52 位(26 位经度 + 26 位纬度),网格精度约 0.6 米。
查询时,Redis 会根据半径动态确定搜索的 Geohash 精度(步长):
- 半径越大,使用的精度越粗,网格越大,搜索的网格数可能更少
- 半径越小,使用的精度越细,网格越小,候选点更精确
这个自适应机制在 geohash_helper.c 中实现,核心是 geohashGetAreasByRadiusWGS84 函数。
4.4 Haversine 精确过滤
从 ZSet 捞出的候选点只是"大致在附近",需要精确计算球面距离进行过滤。
Redis 使用 Haversine 公式 计算两点间的球面距离:
scss
a = sin²(Δφ/2) + cos(φ1) · cos(φ2) · sin²(Δλ/2)
c = 2 · atan2(√a, √(1−a))
d = R · c其中 R = 6372797.560856 米,是 WGS-84 椭球体在赤道处的平均半径。
4.5 时间复杂度分析
GEORADIUS 的时间复杂度取决于三个部分:
- ZRANGEBYSCORE 查询:对每个网格执行一次跳表范围查询,复杂度 O(log N + M_grid),其中 M_grid 是该网格内的元素数。
- Haversine 过滤:对每个候选点执行一次球面距离计算,复杂度 O(M_candidate),其中 M_candidate 为所有被扫描网格内元素的总数(即所有 M_grid 之和)。
- 排序:如果指定了 ASC 或 DESC,需要对结果排序,复杂度 O(K log K),K 为最终结果数。
总体复杂度约为 O(log N + M_candidate + K log K),其中 N 为有序集合中的元素总数。 在 N 很大而半径很小、且点分布相对均匀时,M_candidate 仅取决于局部点密度(通常为常数),此时查询复杂度近似为 O(log N + 常数),几乎与数据总量无关------这正是 Redis GEO 高性能的本质原因。
五、全链路串联与架构总览
将以上三层串联起来,Redis GEO 的完整数据流转如下:
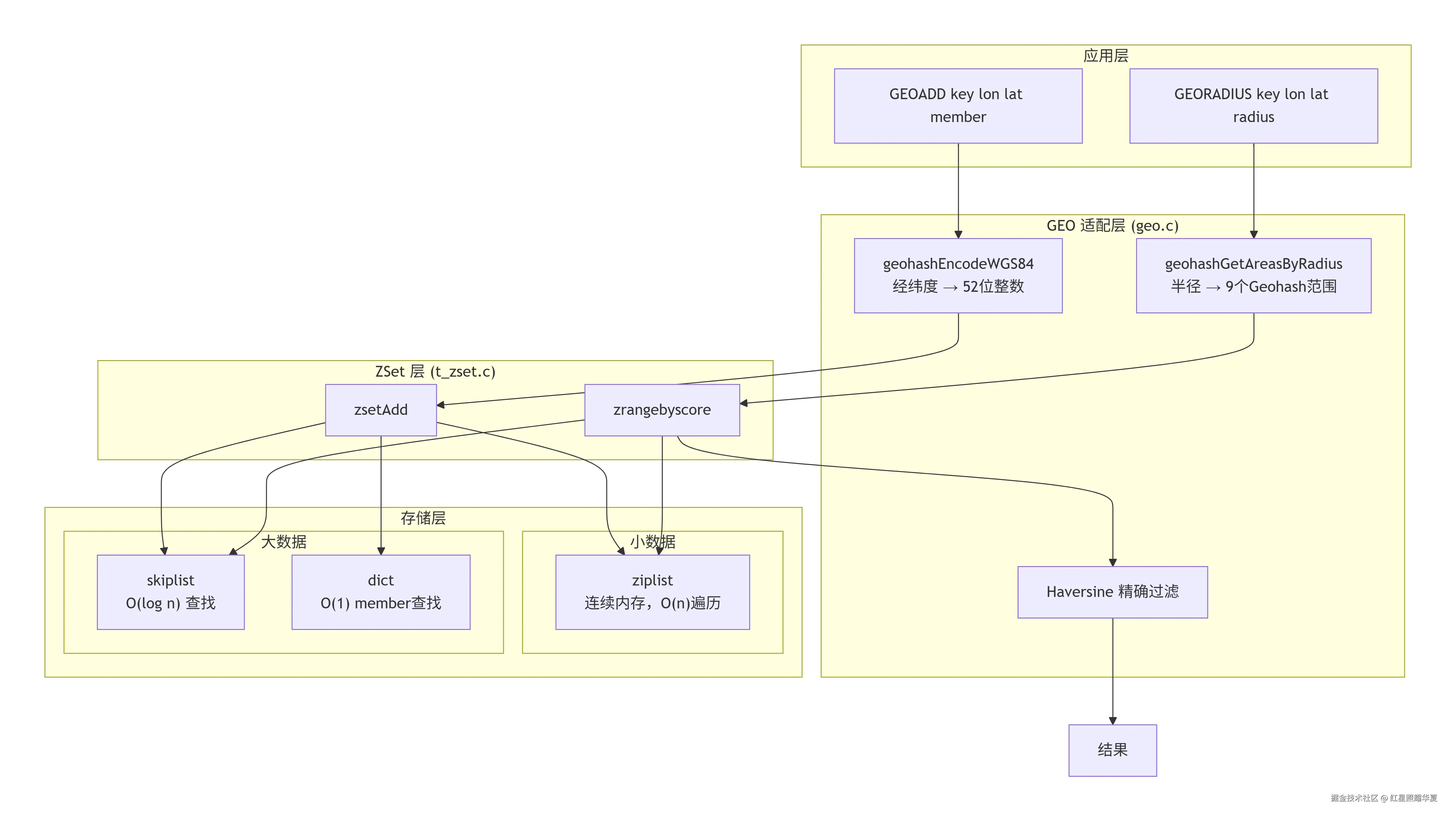
整个架构的精妙之处在于"分层复用" :
- GEO 层只管"翻译":把地理坐标翻译成 52 位整数,把半径翻译成 Geohash 范围。
- ZSet 层只管"存储和查询":它不关心 score 代表什么含义,只管按数值排序。
- 存储层自动适配:小数据用 ziplist 省内存,大数据用 skiplist + dict 保性能。
Redis 团队没有为了 GEO 去发明新的数据结构,而是巧妙地将问题映射到已有的、经过千锤百炼的 ZSet 上。这种"站在巨人的肩膀上"的设计哲学,正是 Redis 优雅且强大的根源。
六、写在最后
回顾全文,Redis GEO 的高性能源于三个层层递进的设计决策:
- Geohash 编码:用 52 位整数完美嵌入 double,实现二维降一维,无损且没有额外开销。
- ZSet 跳表复用:O(log n) 的范围查询能力被完整继承,无需重复造轮子。
- 9 宫格搜索 + Haversine:用"粗糙矩形 + 精确过滤"的双重策略,在保证准确率的前提下最大化查询效率。
理解了这三层,你就能明白为什么一个 GEOADD 命令背后,是一条从经纬度到二进制位、从位交织到 Z 阶曲线、从跳表到球面距离公式的完整技术链。
在实际工程中,如果要处理亿级 GEO 数据,还需要考虑 Redis Cluster 分片(按 Geohash 前缀分片,保证空间邻近的数据落在同一节点)、内存压缩(Delta 编码 + ZSTD)等进阶技术。但这些都是在理解了上述核心原理之后的水到渠成。
Redis GEO 的源码集中在三个文件中:geo.c (命令入口和 Haversine 计算)、geohash.c (编码与位交织)、geohash_helper.c (范围计算和 9 宫格生成)。有兴趣的读者可以顺着 GEOADD 和 GEORADIUS 两个命令的入口函数,逐行阅读,你会有更多发现。
本文首发于:blog.csdn.net/emeson_ch/a...