JOIN最大的问题不在于它本身慢,而在于高并发场景下,它会把整个系统拖垮。
JOIN为什么会变慢
MySQL执行JOIN的底层算法是 Nested Loop Join(嵌套循环连接)。简单说就是:拿表A的每一行,去表B里找匹配的行。
两张表JOIN,复杂度是 M x N。三张表就是 M x N x K。表越多,数据量越大,执行时间不是线性增长,而是乘法级别地膨胀。
一条单表查询可能5ms就返回了,加几个JOIN之后轻松飙到200ms甚至更久。在低并发环境下,200ms也能接受,用户感知不明显。但问题出在高并发的时候。
高并发下的连锁反应
数据库连接池的连接数是有限的,一般业务系统配置在50~200之间。
正常情况下,一条SQL 5ms执行完就把连接还回池子,连接周转很快,池子永远有余量。
但多表JOIN的慢SQL一旦出现,情况就变了:
- 一条SQL执行500ms,连接被占住500ms才归还
- 同一时间涌入大量请求,每个都要占一条连接
- 连接池很快被占满,新来的请求只能排队等待
- 排队的请求越积越多,接口响应时间从毫秒级飙到秒级
- 上游调用方开始超时,触发重试,流量进一步放大
- 最终连接池彻底耗尽,系统雪崩
这就是典型的慢SQL引发的雪崩链路。多表JOIN不是唯一的慢SQL来源,但它是最常见的那个。
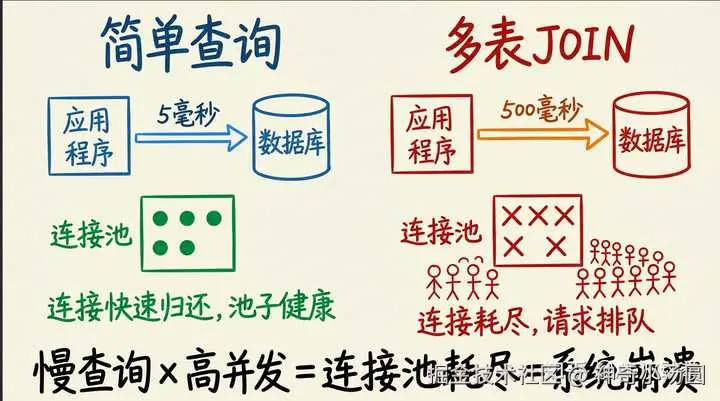
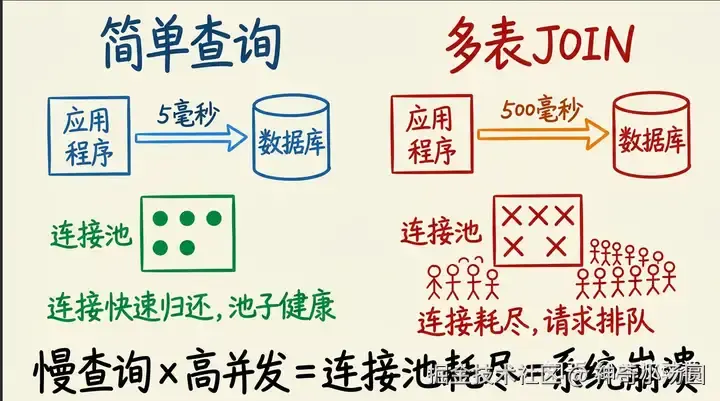
一张图就能看明白:左边的简单查询5ms归还连接,池子永远健康。右边的多表JOIN占住连接500ms,高并发一来,池子瞬间被打满,后续请求全部排队。
怎么替代多表JOIN
核心思路就是把JOIN拆成多次单表查询,在应用层组装数据。
ini
// 先查订单
List<Order> orders = orderMapper.selectByUserId(userId);
// 拿到商品ID列表,批量查商品
List<Long> productIds = orders.stream()
.map(Order::getProductId)
.toList();
List<Product> products = productMapper.selectBatchIds(productIds);
// 在内存里组装
Map<Long, Product> productMap = products.stream()
.collect(Collectors.toMap(Product::getId, Function.identity()));两次单表查询,每次都走索引,加起来可能10ms搞定。比一条三表JOIN快得多,而且对连接池几乎没有压力。
其他常见方案:对高频查询场景做冗余字段,避免关联查询。或者用宽表把多表数据提前聚合好,查询时直接读宽表。
这些方案的共同思路就一个:减少单条SQL的执行时间,让数据库连接尽快归还,在高并发下保持连接池的健康周转。