今天,我们以25年5月架构师的案例真题为引,来拆解下Redis主从复制的详细流程(当然你学了,拿去"吊打"面试官也是可以的):
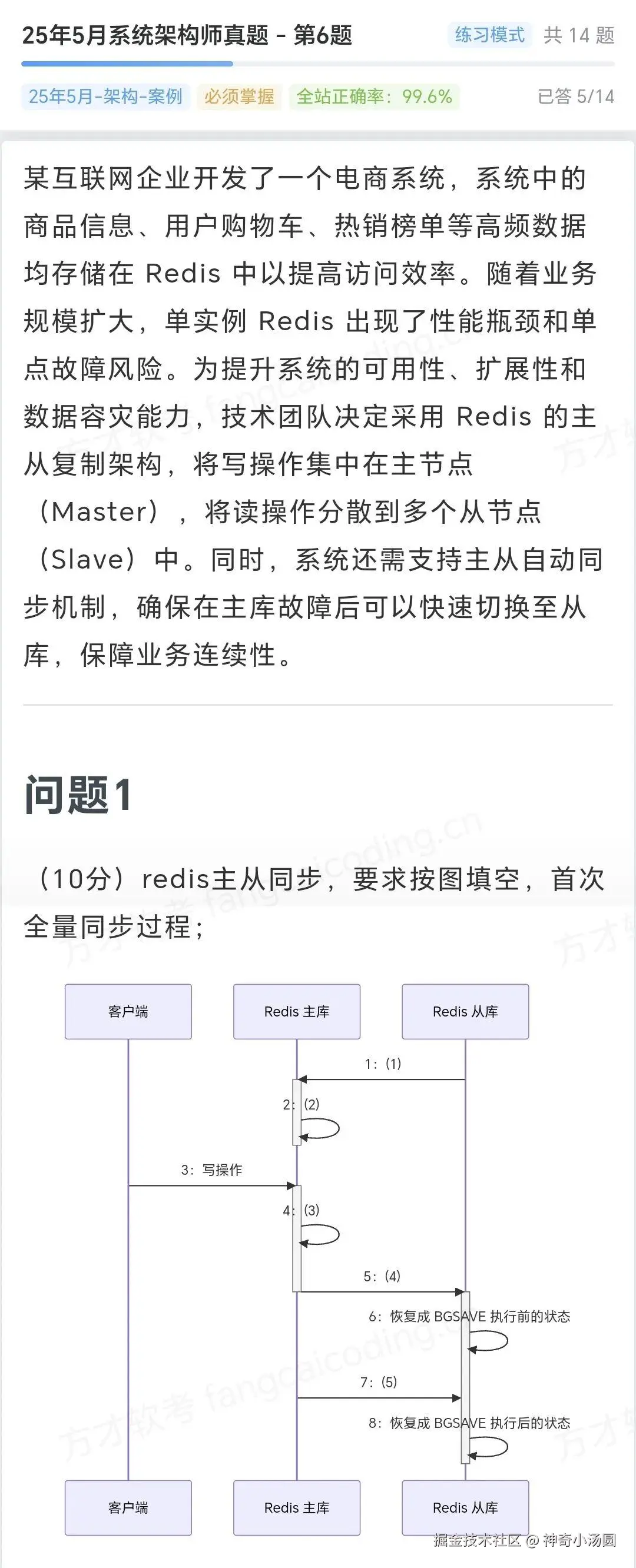
主从复制分为初始化阶段(全量同步) 和运行阶段(增量同步) ,前者是从节点首次连接主节点的完整数据同步,后者是后续的实时数据更新,流程如下:
阶段 1:初始化 - 全量同步
全量同步是从节点获取主节点完整数据的过程,适用于从节点首次连接主节点 或从节点断线后无法进行增量同步(如主节点运行 ID 变化、偏移量超出复制缓冲区范围) 的场景。流程可拆解为7步,核心是通过PSYNC与FULLRESYNC协商同步方式,再通过 RDB 快照 + 增量命令补发完成数据一致性校验:
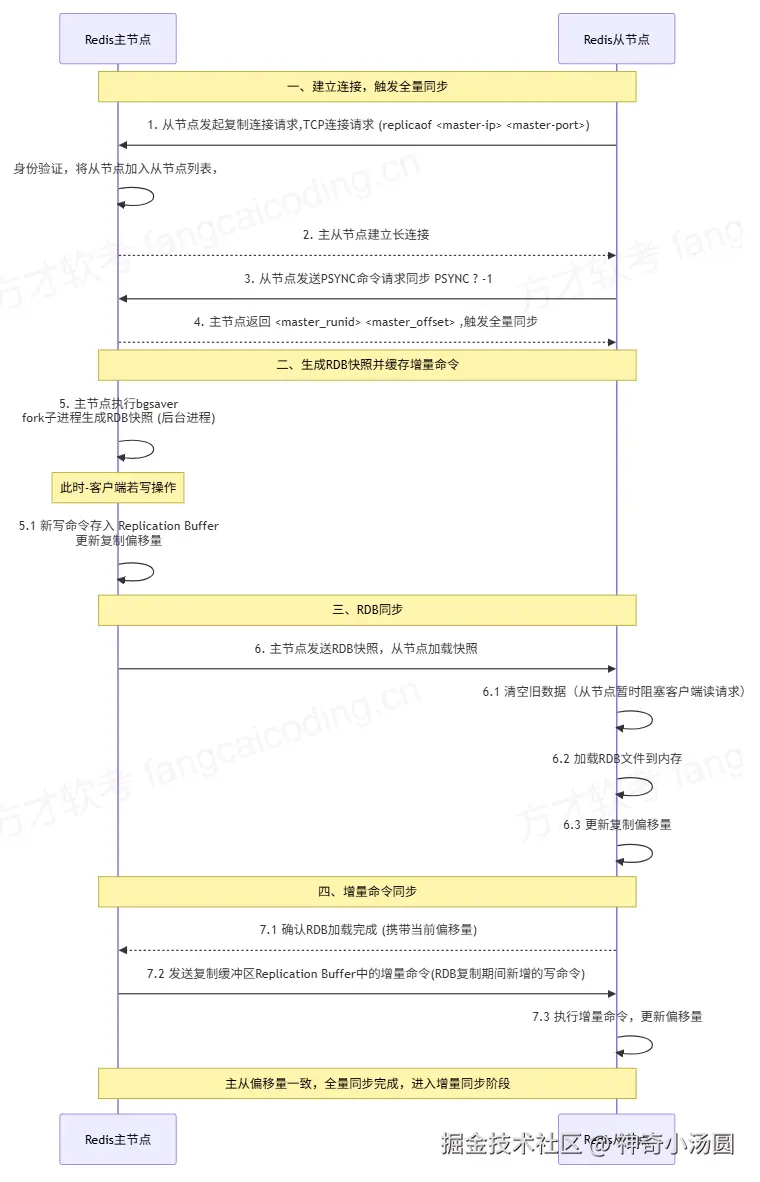
当主从节点的复制偏移量完全一致时,全量同步完成 ,主从复制进入稳定的"增量同步阶段"------ 此后主节点的写命令会通过命令传播机制实时同步给从节点。
阶段 2:运行中 - 增量同步
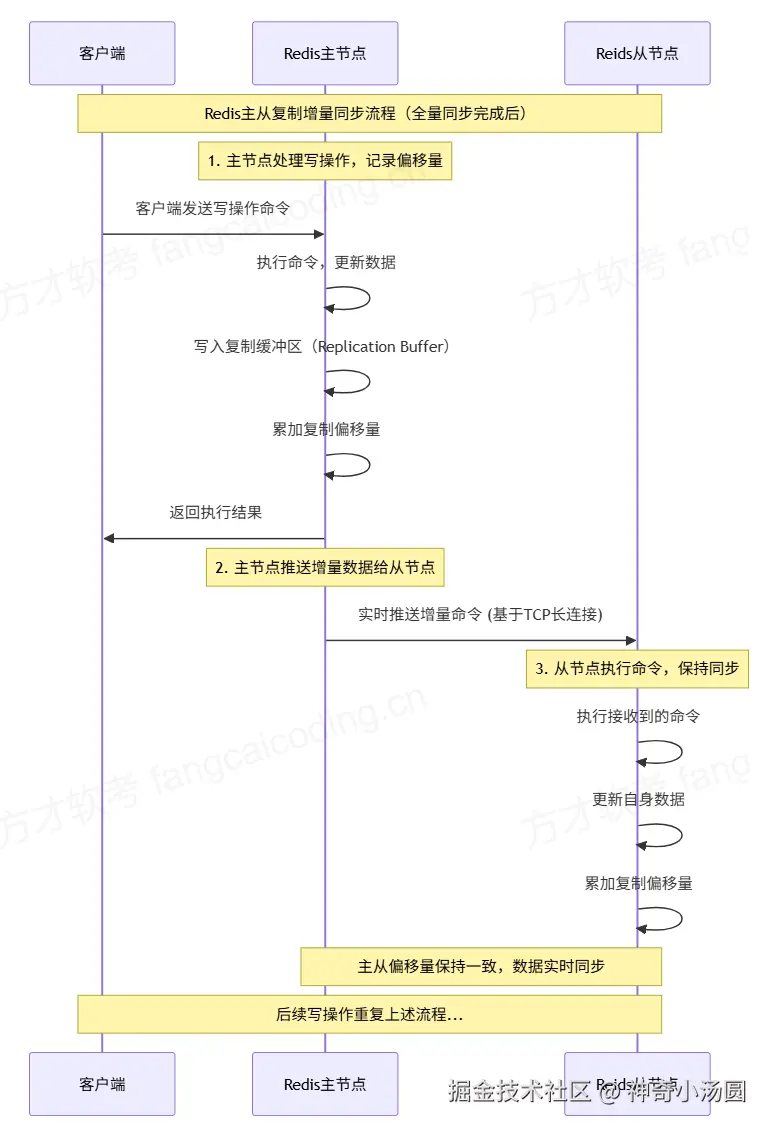
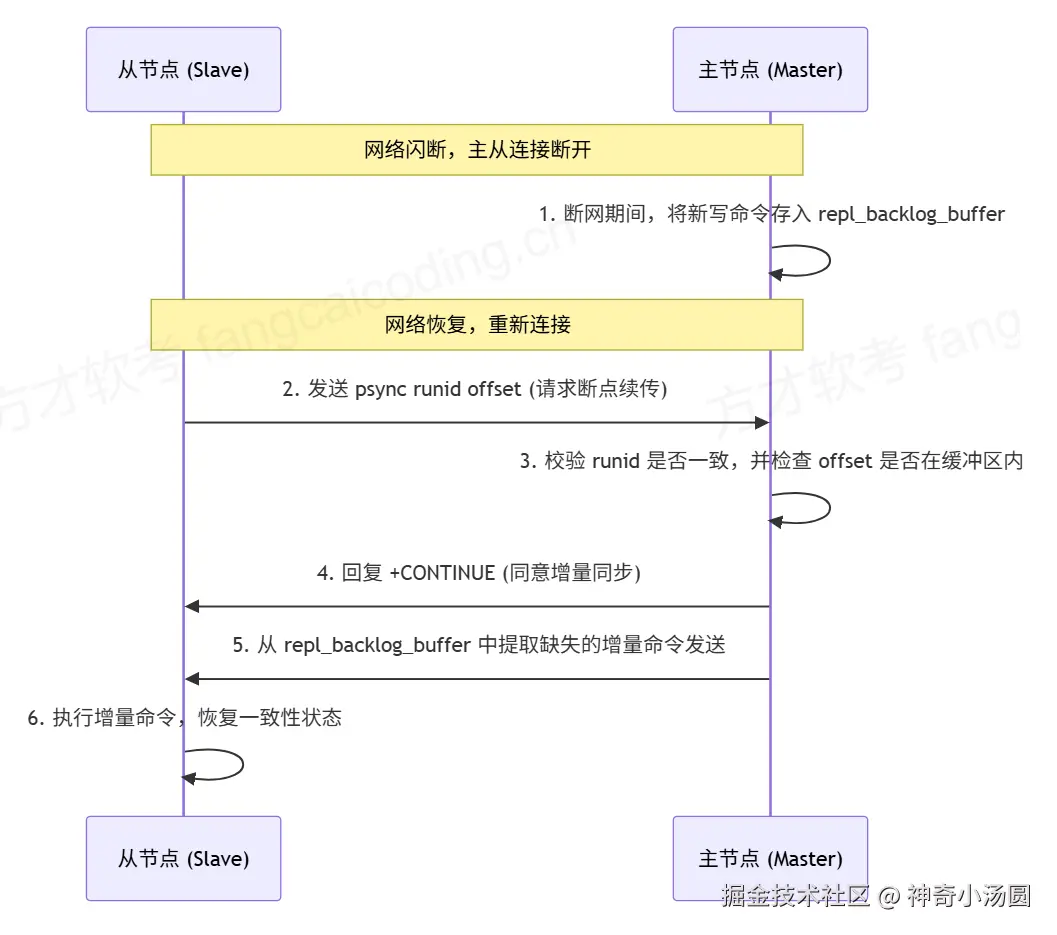
阶段 3:异常恢复 - 断线重连与同步判断
若从节点因网络波动等原因断线,重连主节点时会触发「同步方式判断」,流程如下:
-
- 从节点重连主节点后,会发送自身记录的「主节点 Run ID」和「自身当前的复制偏移量」。
-
- 主节点判断:
-
•若 Run ID 不变(仍为原主节点)且偏移量在复制积压缓冲区内 :触发增量同步,主节点直接将缓冲区内偏移量之后的命令发送给从节点,快速恢复同步。
-
•若 Run ID 改变(主节点重启过)或偏移量已超出缓冲区范围 :触发全量同步,重复「初始化阶段」的流程。
-
- 增量复制之所以能成功,全靠主节点内部维护的一个环形缓冲区:repl_backlog_buffer 复制积压缓冲区。
-
• 这个缓冲区的大小是固定的(默认 1MB),主节点在执行写命令时,不仅会发送给在线的从节点,还会顺手把命令写入这个环形缓冲区中,所有从节点共享一个。
两个缓存区
在全量、增量同步中,有两个缓存区注意区分下:
以上就是Redis主从复制的全流程,你学"废"了么??