|----------------------------------------------|-------------------------------------------------------------------------------------------|
| 欢迎各位同学关注我哦~ 在这个 AI 喧嚣的时代 不忘初心,戒骄戒躁,认真沉淀 |  |
|
Redis是一个键值数据库,字典(dict)是其最核心的数据结构。数据库本身就是一个字典,redisDb->dict 存储所有键值对;哈希键在元素较多时也以字典为底层实现;过期键通过辅助字典 redisDb->expires 管理;集群中的节点映射、槽位映射依赖字典;客户端的订阅频道、阻塞键同样由字典维护。Redis的字典实现了一个经典的哈希表,但在工程细节上做了大量优化:渐进式rehash、2的幂次扩容、SipHash哈希函数等。下面我们将深入分析Redis字典的结构和核心API实现。
一、数据结构定义
1.1 哈希表节点 ------ dictEntry
c
// dict.h:47-56
typedef struct dictEntry {
void *key; // 键,`void*` 泛型
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v; // 值的联合体,可以是指针、64 位无符号整数、64 位有符号整数、双精度浮点数
struct dictEntry *next; // 链地址法解决哈希冲突
} dictEntry; 为什么用union存值? 这是一种内存优化技巧。在Redis中,很多场景下值本身就是整数(如引用计数、过期时间),不需要额外分配一个对象来存。union让 dictEntry 的大小固定,避免了额外的内存分配和指针跳转。
1.2 哈希表 ------ dictht
c
// dict.h:69-74
typedef struct dictht {
dictEntry **table; // 哈希表数组,每个元素是一个 `dictEntry*` 链表头
unsigned long size; // 哈希表大小,始终为2的幂次
unsigned long sizemask; // 哈希表大小掩码,等于 `size - 1`
unsigned long used; // 已有的节点数量
} dictht;sizemask作用 :因为 size 是2的幂次,所以 sizemask = size - 1 的二进制全是1。计算索引时只需 hash & sizemask,等价于 hash % size,但位运算远快于取模。
1.3 字典 ------ dict
c
// dict.h:76-82
typedef struct dict {
dictType *type; // 指向 `dictType` 结构的指针,保存类型特定函数
void *privdata; // 传递给类型特定函数的可选参数
dictht ht[2]; // 两个哈希表,rehash时 `ht[0]` 为旧表,`ht[1]` 为新表
long rehashidx; // rehash索引,`-1` 表示未进行rehash
unsigned long iterators; // 当前正在运行的安全迭代器数量
} dict;为什么需要两个哈希表? 这是Redis实现渐进式rehash的关键。当需要扩容或缩容时,Redis不是一次性迁移所有数据,而是在 ht[1] 上分配新空间,然后逐步将 ht[0] 的数据迁移到 ht[1],最终释放 ht[0],将 ht[1] 变成新的 ht[0]。
1.4 类型特定函数 ------ dictType
c
// dict.h:58-65
typedef struct dictType {
uint64_t (*hashFunction)(const void *key); // 计算键的哈希值(必须)
void *(*keyDup)(void *privdata, const void *key); // 复制键(可选)
void *(*valDup)(void *privdata, const void *obj); // 复制值(可选)
int (*keyCompare)(void *privdata, const void *key1, const void *key2); // 比较两个键(可选)
void *(*keyDestructor)(void *privdata, void *key); // 销毁键(可选)
void *(*valDestructor)(void *privdata, void *obj); // 销毁值(可选)
} dictType;可选函数为 NULL 时,使用默认行为(如 keyCompare 为 NULL 时直接比较指针)。
1.5 内存布局
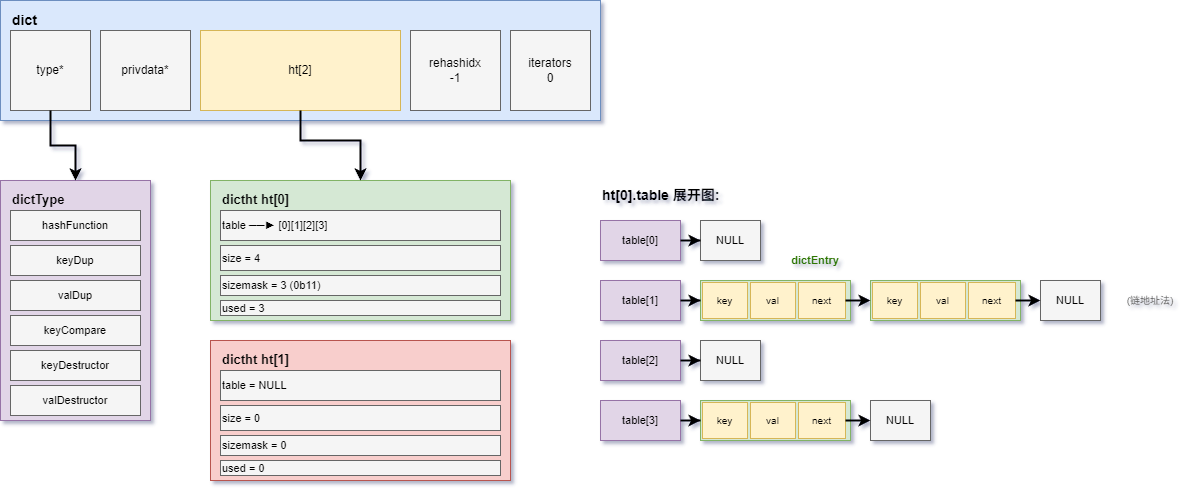
二、哈希函数
2.1 SipHash ------ Redis的默认哈希函数
c
// dict.c:90-96
uint64_t dictGenHashFunction(const void *key, int len) {
return siphash(key, len, dict_hash_function_seed); // 使用SipHash计算哈希值
}
uint64_t dictGenCaseHashFunction(const unsigned char *buf, int len) {
return siphash_nocase(buf, len, dict_hash_function_seed); // 大小写无关版本
}Redis 4.0之后使用 SipHash 替代了之前的MurmurHash2。原因是MurmurHash2存在哈希碰撞攻击风险------攻击者可以构造大量哈希值相同的键,将O(1)的查找退化为O(n),造成拒绝服务。
SipHash是一种密码学安全的哈希函数,虽然速度略慢于MurmurHash2,但能有效防止哈希碰撞攻击。种子 dict_hash_function_seed 在Redis启动时随机生成。
2.2 索引计算
c
idx = hash & d->ht[table].sizemask;利用 sizemask(全1掩码)做位与运算,将任意哈希值映射到 [0, size) 范围内。这样会比取模运算 % 快得多~
三、核心API源码分析
3.1 创建字典 ------ dictCreate
c
// dict.c:111-132
dict *dictCreate(dictType *type, void *privDataPtr) {
dict *d = zmalloc(sizeof(*d)); // 分配字典内存
_dictInit(d, type, privDataPtr); // 初始化字典
return d;
}
int _dictInit(dict *d, dictType *type, void *privDataPtr) {
_dictReset(&d->ht[0]); // 重置哈希表0(table=NULL, size=0, used=0)
_dictReset(&d->ht[1]); // 重置哈希表1
d->type = type; // 设置类型特定函数表
d->privdata = privDataPtr;
d->rehashidx = -1; // -1表示未进行rehash
d->iterators = 0;
return DICT_OK;
}创建字典时,两个哈希表都初始化为空(table = NULL,size = 0)。哈希表在第一次插入数据时才会分配空间(懒初始化)。
3.2 添加键值对 ------ dictAdd
c
// dict.c:265-272
int dictAdd(dict *d, void *key, void *val) {
dictEntry *entry = dictAddRaw(d, key, NULL);
if (!entry) return DICT_ERR;
dictSetVal(d, entry, val);
return DICT_OK;
}dictAdd 是高层接口,负责将完整的键值对插入字典。它将操作拆分为两步:先调用 dictAddRaw 仅插入键,再通过 dictSetVal 设置值。这种拆分设计使得底层 dictAddRaw 可以被其他API复用(如 dictReplace)。如果键已存在,dictAddRaw 返回 NULL,dictAdd 随即返回 DICT_ERR,保证不会覆盖已有键值对。
3.3 底层添加 ------ dictAddRaw
c
// dict.c:292-318
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing) {
long index;
dictEntry *entry;
dictht *ht;
// 如果正在进行rehash,先迁移一个桶
if (dictIsRehashing(d)) _dictRehashStep(d);
// 计算键的索引,同时检查键是否已存在
if ((index = _dictKeyIndex(d, key, dictHashKey(d, key), existing)) == -1)
return NULL;
// rehash中新键总是插入ht[1],否则插入ht[0]
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
entry = zmalloc(sizeof(*entry));
// 头插法:新节点插入链表头部,假设最近添加的元素更可能被访问
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
dictSetKey(d, entry, key);
return entry;
}dictAddRaw 只插入键,不设置值,返回新创建的 dictEntry 指针。如果键已存在则返回 NULL,并通过 existing 参数输出已有节点的地址,供调用方进一步处理。注意它采用头插法 将新节点插入链表头部,时间复杂度 O(1),同时利用了局部性原理------最近添加的元素更可能被频繁访问。另外,rehash期间新键总是写入 ht[1],确保 ht[0] 中的数据只会被迁出而不会新增,避免数据混乱。
3.4 查找键 ------ dictFind
c
// dict.c:476-495
dictEntry *dictFind(dict *d, const void *key) {
dictEntry *he;
uint64_t h, idx, table;
// 两个哈希表都为空,直接返回
if (d->ht[0].used + d->ht[1].used == 0) return NULL;
// 如果正在进行rehash,先迁移一个桶
if (dictIsRehashing(d)) _dictRehashStep(d);
h = dictHashKey(d, key);
// 依次搜索ht[0]和ht[1]
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask;
he = d->ht[table].table[idx];
// 遍历链表查找键
while(he) {
// 先比较指针,再调用比较函数(短路优化)
if (key == he->key || dictCompareKeys(d, key, he->key))
return he;
he = he->next;
}
// 如果不在rehash中,ht[1]为空,搜索ht[0]后直接返回
if (!dictIsRehashing(d)) return NULL;
}
return NULL;
}dictFind 在rehash期间需要搜索两个哈希表 :先查 ht[0],再查 ht[1]。非 rehash 状态下 ht[1] 为空,搜完 ht[0] 即可返回。另一个细节是键的比较采用了短路优化 :先比较指针是否相同(O(1)),不同时才调用 dictCompareKeys,避免不必要的函数调用开销。
3.5 删除键 ------ dictGenericDelete
c
// dict.c:364-399
static dictEntry *dictGenericDelete(dict *d, const void *key, int nofree) {
uint64_t h, idx;
dictEntry *he, *prevHe;
int table;
// 两个哈希表都为空,直接返回
if (d->ht[0].used == 0 && d->ht[1].used == 0) return NULL;
// 如果正在进行rehash,先迁移一个桶
if (dictIsRehashing(d)) _dictRehashStep(d);
h = dictHashKey(d, key);
// 依次搜索ht[0]和ht[1]
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask;
he = d->ht[table].table[idx];
prevHe = NULL;
while(he) {
// 找到目标键(先比较指针,再调用比较函数)
if (key == he->key || dictCompareKeys(d, key, he->key)) {
// 从链表中摘除:非头节点修改前驱next,头节点修改桶指针
if (prevHe)
prevHe->next = he->next;
else
d->ht[table].table[idx] = he->next;
// nofree=0时释放键、值和节点内存
if (!nofree) {
dictFreeKey(d, he);
dictFreeVal(d, he);
zfree(he);
}
d->ht[table].used--;
return he;
}
prevHe = he;
he = he->next;
}
// 如果不在rehash中,无需搜索ht[1]
if (!dictIsRehashing(d)) break;
}
return NULL;
}nofree 参数控制是否释放节点内存。dictDelete 传0(释放),dictUnlink 传1(不释放,延迟到 dictFreeUnlinkedEntry 调用时释放)。这个设计允许使用者在删除前操作节点值,避免二次查找。删除时需遍历链表找到目标节点及其前驱,通过修改 next 指针完成摘除,时间复杂度取决于链表长度。
3.6 替换值 ------ dictReplace
c
// dict.c:325-346
int dictReplace(dict *d, void *key, void *val) {
dictEntry *entry, *existing, auxentry;
// 先尝试添加新键
entry = dictAddRaw(d, key, &existing);
if (entry) {
// 键不存在,设置值
dictSetVal(d, entry, val);
return 1; // 返回1表示新增
}
// 键已存在,替换值
auxentry = *existing; // 备份旧值到栈上
dictSetVal(d, existing, val); // 设置新值
dictFreeVal(d, &auxentry); // 释放旧值
return 0; // 返回0表示替换
}先尝试添加,如果键已存在则替换值。注意这里用一个巧妙的手法避免释放问题:先将 existing 复制到栈上的 auxentry,然后设置新值,最后释放旧值。这个顺序很重要------如果新值和旧值恰好是同一个对象(引用计数场景),先设新值再释放旧值可以避免提前释放。
3.7 释放字典 ------ dictRelease
c
// dict.c:442-474
int _dictClear(dict *d, dictht *ht, void(callback)(void*)) {
unsigned long i;
for (i = 0; i < ht->size && ht->used > 0; i++) {
dictEntry *he, *nextHe;
// 每访问65536个桶调用一次回调,防止长时间阻塞
if (callback && (i & 65535) == 0) callback(d->privdata);
if ((he = ht->table[i]) == NULL) continue; // 空桶跳过
while(he) {
nextHe = he->next; // 保存下一个节点
dictFreeKey(d, he); // 释放键
dictFreeVal(d, he); // 释放值
zfree(he); // 释放节点
ht->used--;
he = nextHe;
}
}
zfree(ht->table); // 释放桶数组
_dictReset(ht); // 重置为初始状态(table=NULL, size=0, sizemask=0, used=0)
return DICT_OK;
}
void dictRelease(dict *d) {
_dictClear(d, &d->ht[0], NULL); // 清空ht[0]
_dictClear(d, &d->ht[1], NULL); // 清空ht[1]
zfree(d); // 释放字典结构
}callback 参数每65536个桶调用一次,用于在长时间释放过程中让Redis处理其他事件(如客户端请求),避免长时间阻塞。
四、扩容与缩容
4.1 触发扩容 ------ _dictExpandIfNeeded
c
// dict.c:922-941
static int _dictExpandIfNeeded(dict *d) {
// 正在rehash,不需要再次扩容
if (dictIsRehashing(d)) return DICT_OK;
// 首次插入,扩展到初始大小4
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
// 负载因子>=1且允许resize,或负载因子>5强制resize
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used / d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used * 2); // 扩容为已用数量的2倍
}
return DICT_OK;
}扩容条件:
| 条件 | 说明 |
|---|---|
ht[0].size == 0 |
首次插入,扩展到初始大小4 |
used >= size && dict_can_resize |
负载因子 >= 1且允许resize |
used / size > 5 |
负载因子 > 5,强制resize |
为什么有 dict_can_resize 开关? Redis在执行BGSAVE或BGREWRITEAOF时,子进程使用写时复制(COW)。如果此时大量rehash导致内存页复制,会严重影响性能。所以Redis在有子进程执行持久化时禁止自动扩容,除非负载因子超过5的危险阈值。
c
// dict.c:62-63
static int dict_can_resize = 1; // 是否允许自动扩容,BGSAVE/BGREWRITEAOF时置0
static unsigned int dict_force_resize_ratio = 5; // 强制扩容阈值,负载因子超过此值无视dict_can_resize4.2 计算扩容大小 ------ _dictNextPower
c
// dict.c:44-48
static unsigned long _dictNextPower(unsigned long size) {
unsigned long i = DICT_HT_INITIAL_SIZE; // 从4开始
if (size >= LONG_MAX) return LONG_MAX; // 超过上限直接返回最大值
// 找到第一个>=size的2的幂次值
while(1) {
if (i >= size)
return i;
i *= 2;
}
}从 DICT_HT_INITIAL_SIZE(4)开始不断翻倍,直到找到第一个 >= size 的2的幂次值。
4.3 执行扩容 ------ dictExpand
c
// dict.c:130-157
int dictExpand(dict *d, unsigned long size) {
dictht n;
// 计算新哈希表大小,向上取到2的幂次
unsigned long realsize = _dictNextPower(size);
// 不能在rehash期间扩容
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
// 新大小与当前相同,无需扩容
if (realsize == d->ht[0].size) return DICT_ERR;
// 初始化新哈希表
n.size = realsize;
n.sizemask = realsize - 1; // sizemask用于计算索引:hash & sizemask
n.table = zcalloc(realsize * sizeof(dictEntry*)); // 分配桶数组,全部初始化为NULL
n.used = 0;
// ht[0]为空(首次扩容),直接赋值给ht[0]
if (d->ht[0].table == NULL) {
d->ht[0] = n;
} else {
// 非首次扩容,赋值给ht[1],启动rehash
d->ht[1] = n;
d->rehashidx = 0; // rehashidx>=0表示开始rehash
}
return DICT_OK;
}两种情况:
- 首次扩容 (
ht[0].table == NULL):直接赋给ht[0] - 后续扩容 :赋给
ht[1],设置rehashidx = 0,开始渐进式rehash
4.4 触发缩容 ------ dictResize
c
// dict.c:174-185
int dictResize(dict *d) {
int minimal;
// 正在rehash或禁止resize,不允许缩容
if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR;
minimal = d->ht[0].used; // 缩容目标为当前已用数量
if (minimal < DICT_HT_INITIAL_SIZE) // 最小不低于4
minimal = DICT_HT_INITIAL_SIZE;
return dictExpand(d, minimal); // 复用dictExpand完成缩容
}缩容实质上也是调用 dictExpand------将哈希表收缩到恰好能容纳所有元素的最小2的幂次大小。Redis在定时任务中检查,当负载因子 < 0.1时自动触发缩容。
五、迭代器
5.1 安全迭代器 vs 非安全迭代器
c
// dict.h:88-96
typedef struct dictIterator {
dict *d; // 指向所属字典
long index; // 当前迭代索引,初始为-1
int table, safe; // table: 当前遍历的哈希表(0或1),safe: 是否为安全迭代器
dictEntry *entry, *nextEntry; // entry: 当前节点,nextEntry: 保存下一个节点防止删除后丢失位置
long long fingerprint; // 非安全迭代器的字典指纹
} dictIterator;| 属性 | 安全迭代器 | 非安全迭代器 |
|---|---|---|
safe |
1 | 0 |
| 限制 | 可以调用 dictAdd、dictFind 等 |
只能调用 dictNext() |
| 保护机制 | d->iterators++ 阻止rehash |
fingerprint 指纹校验 |
5.2 非安全迭代器的指纹校验
c
// dict.c:510-540
long long dictFingerprint(dict *d) {
long long integers[6], hash = 0;
integers[0] = (long) d->ht[0].table; // ht[0]桶数组地址
integers[1] = d->ht[0].size; // ht[0]桶数组大小
integers[2] = d->ht[0].used; // ht[0]已用节点数
integers[3] = (long) d->ht[1].table; // ht[1]桶数组地址
integers[4] = d->ht[1].size; // ht[1]桶数组大小
integers[5] = d->ht[1].used; // ht[1]已用节点数
// ... Tomas Wang 哈希 ...
}非安全迭代器在创建时记录指纹,释放时检查指纹是否改变。如果改变了,说明迭代期间字典被非法修改,触发断言失败。这是开发阶段的调试辅助手段。
5.3 迭代过程
c
// dict.c:562-596
dictEntry *dictNext(dictIterator *iter) {
while (1) {
if (iter->entry == NULL) {
dictht *ht = &iter->d->ht[iter->table];
// 首次调用时注册迭代器
if (iter->index == -1 && iter->table == 0) {
if (iter->safe)
iter->d->iterators++; // 安全迭代器:增加计数,阻止rehash
else
iter->fingerprint = dictFingerprint(iter->d); // 非安全迭代器:记录指纹
}
iter->index++;
// 当前哈希表遍历完毕
if (iter->index >= (long) ht->size) {
// 如果正在rehash且ht[0]遍历完,继续遍历ht[1]
if (dictIsRehashing(iter->d) && iter->table == 0) {
iter->table++;
iter->index = 0;
ht = &iter->d->ht[1];
} else {
break; // 遍历结束
}
}
iter->entry = ht->table[iter->index]; // 取出桶中链表头
} else {
iter->entry = iter->nextEntry; // 继续遍历当前桶的链表
}
if (iter->entry) {
iter->nextEntry = iter->entry->next; // 保存下一个节点,防止当前节点被删除后丢失位置
return iter->entry;
}
}
return NULL;
}上面的迭代逻辑可以总结如下:
- 首次调用时注册迭代器(安全迭代器增加计数,非安全迭代器记录指纹)
- 在当前哈希表中逐桶推进
- 如果正在rehash且
ht[0]遍历完毕,继续遍历ht[1] - 用
nextEntry保存下一个节点,防止当前节点被删除后丢失位置
六、dictScan ------ 无状态迭代器
dictScan 是Redis实现的一种极其精巧的无状态迭代器,用于 SCAN 命令。它的核心思想是逆序递增游标:反转游标的二进制位后加1,再反转回来。
正常递增:000 → 001 → 010 → 011 → 100 → ...
逆序递增:000 → 100 → 010 → 110 → 001 → ...这样做的优势:当哈希表扩容时(如从4变8),高位变多,之前遍历过的低位模式不会被重新遍历。当哈希表缩容时,高位合并,已遍历的低位模式也不会遗漏。
可能返回重复元素,但保证不遗漏------应用层需要自行去重。
七、dict在Redis中的使用场景
| 场景 | 字段/变量 | dictType |
|---|---|---|
| 数据库键空间 | redisDb->dict |
dbDictType |
| 过期时间字典 | redisDb->expires |
dbExpiresDictType |
| 哈希键底层实现 | robj->ptr |
hashDictType |
| 集合键底层实现 | robj->ptr |
setDictType |
| 有序集合 | zset->dict |
zsetDictType |
| 客户端订阅频道 | client->pubsub_channels |
channelDictType |
| 集群槽位映射 | clusterState->slots_to_keys |
--- |
八、复杂度汇总
| 操作 | 函数 | 平均 | 最坏 |
|---|---|---|---|
| 添加 | dictAdd |
O(1) | O(n) |
| 查找 | dictFind |
O(1) | O(n) |
| 删除 | dictDelete |
O(1) | O(n) |
| 替换 | dictReplace |
O(1) | O(n) |
| 获取随机键 | dictGetRandomKey |
O(n) | O(n) |
| 扩容 | dictExpand |
O(1)* | O(1)* |
| 缩容 | dictResize |
O(1)* | O(1)* |
注:dictExpand / dictResize 本身只分配新表空间,实际数据迁移由渐进式rehash分摊到后续操作中。
|----------------------------------------------|-------------------------------------------------------------------------------------------|
| 欢迎各位同学关注我哦~ 在这个 AI 喧嚣的时代 不忘初心,戒骄戒躁,认真沉淀 | |