引言
redis作为非关联型的数据库,大部分的数据都存在了内存之中,但是因为内存在断电之后数据会消失,所以防止服务器的崩溃,我们redis也提供了持久化的操作。
为了减轻一台redis数据库的工作量,我们有主从复制的方法,但是这个方法存在一些缺陷,所以我们对这个方法做出了改进,有了集群的概念
然后在实际应用方面,redis还是会存在一些其他的问题,像缓存穿透。。。。
最后对于数据库的操作,我们最担心的就是操作不是原子化,导致出错,所以我们有了分布式锁
持久化
持久化有两种形式,第一种是RDB,第二种是AOF。
RDB持久化
在指定的时间之内,将内存中的数据写入磁盘之中。那这个过程是怎么操作的呢?首先Redis先创建(fork)了一个子进程,这个子进程专门进行持久化的操作,先把内存中的数据写到一个临时文件之中,然后等到全部持久化完毕,再来替换旧的文件。这个操作就避免了在持久化的过程中服务器崩溃导致数据全部丢失。这个过程主进程不需要进行任何的I/O操作,所以效率非常的高。但是缺点也就是数据不是很准确,因为可能一小段时间内只有少量数据进入,导致没有触发RDB持久化,而且运气不好的是服务器一不小心崩溃了。完蛋~~~这一小部分数据就不见了。
从这一个图中也可以看出一个细节,就是我们创建子进程的时候,还是要判断一下这个子进程是否存在,如果发现子进程存在,说明已经有子进程在持久化数据了,所以要返回失败。
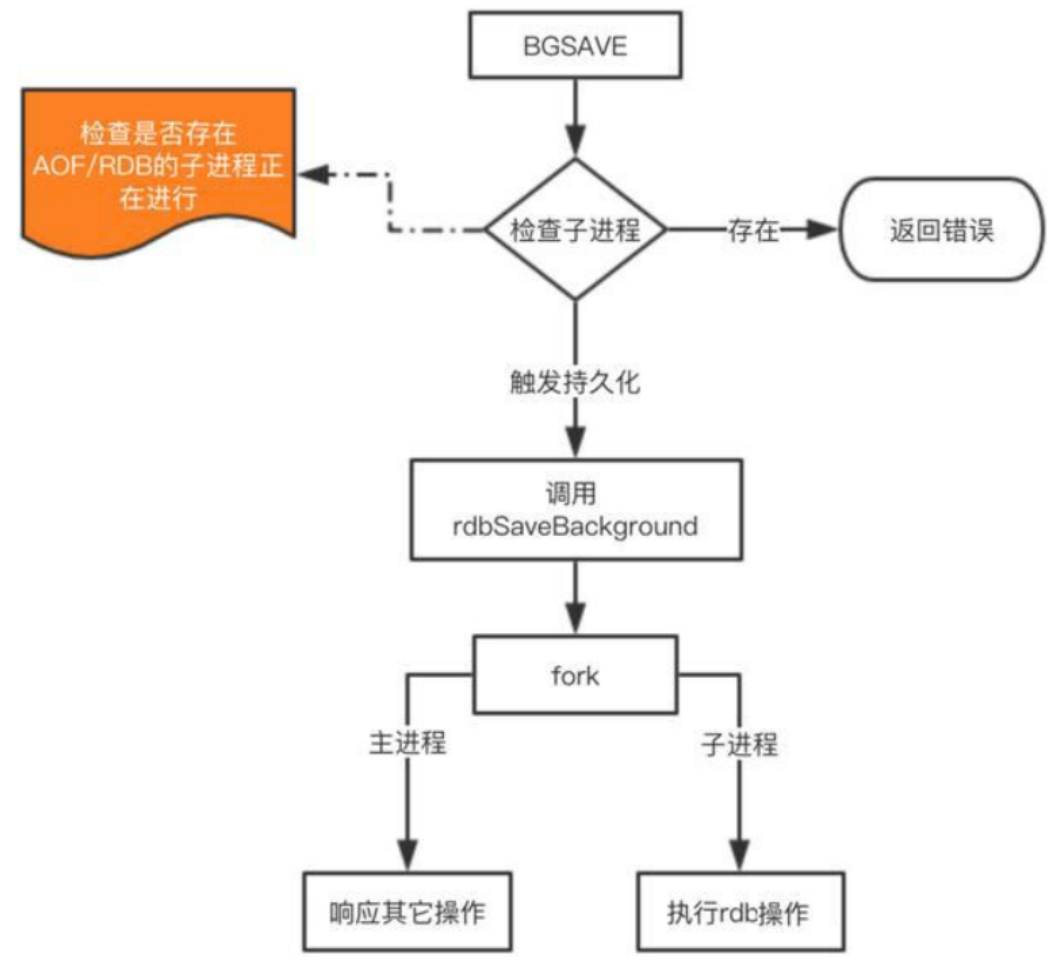
RDB的持久化触发策略
官方提供了手动和自动的方式
手动触发是通过 SAVE 命令或者 BGSAVE 命令将内存数据保存到磁盘文件中。
save:会阻塞当前Redis服务器,直到持久化完成,线上应该禁止使用。
bgsave:该触发方式会fork一个子进程,由子进程负责持久化过程,因此阻塞只会发生在fork子进程的时候。
而自动触发就是在redis.conf (redis的配置文件)文件里面,要我们手动开启,或者设置。

而这一些持久化的操作,最后数据都存在了dump.rdb文件之中,而这个文件的路径,我们也可以自己去定义。
AOF持久化
以日志的形式来记录每一次的操作,将redis的每一次写的操作全部记录下来,但是只许追加不许更改文件。而redis在启动的初期,为了恢复数据信息,就会读取日志里面的操作信息,从而复原所有的数据,也就是把指令从前到后的执行一遍。
我们的AOF一般选择的是每秒计入日志一次,所以这个性能会比RDB的性能要低,但是对于数据的准确性来说,要高很多,即使失去数据,也仅仅是1秒的数据。
注意:AOF默认不开启。可以在redis.conf中配置文件名称,默认为appendonly.aof。AOF文件的保存路径,同RDB****的路径一致。
如果AOF和RDB同时开启,系统会优先选择AOF
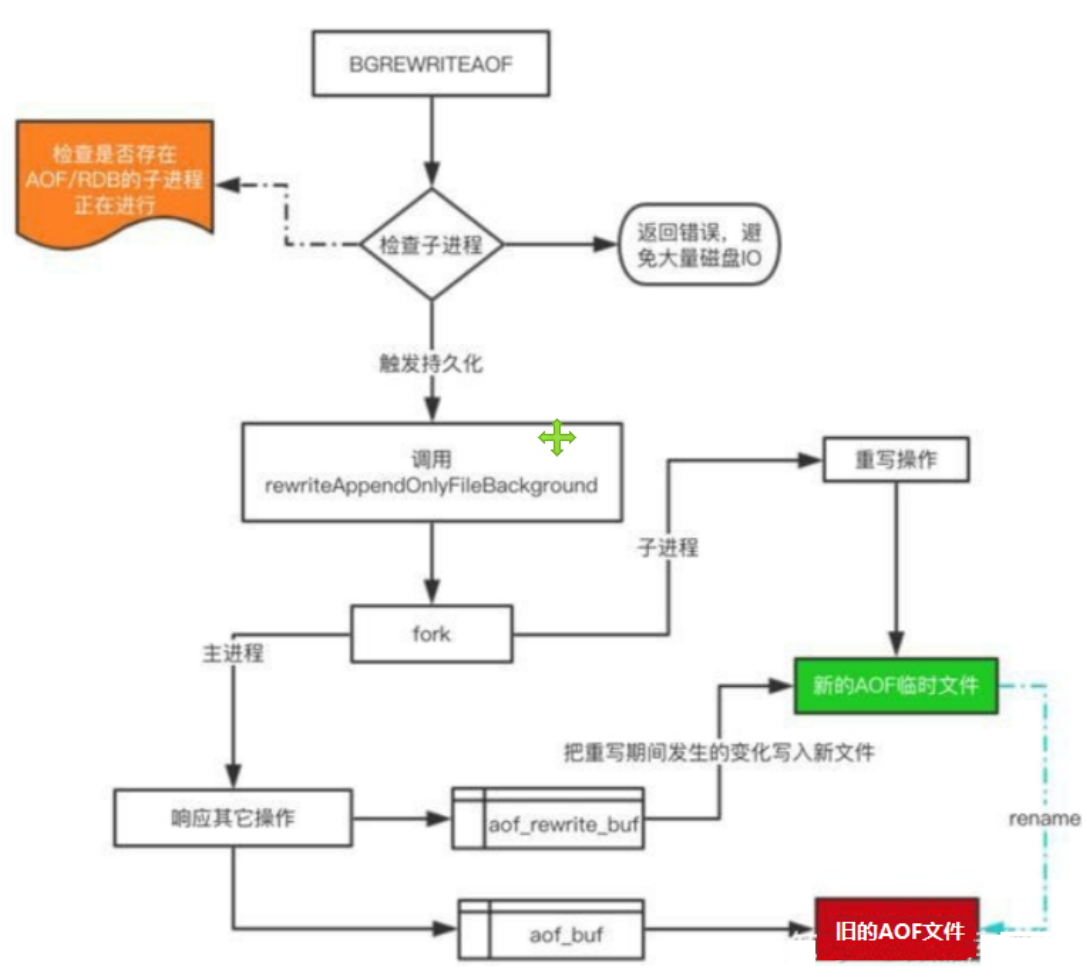
不过大家也发现了,随着指令的越来越多,我们文件会越来越大,所以当文件太大的时候,我们的redis会进行文件的压缩,也就是把set key 。。。。 变成mset sey。。。。这样子可以节约很多的文件空间
然后对于持久化的一个过程,首先我们还是创建(fork)一个子进程,这个子进程会重写所有的操作指令,然后到一个AOF的临时文件里面。然后因为在我们子进程重写的时候,客户端仍然会发送数据过来,但是为了不影响我们子进程的重写的文件,我们先用一个缓存区把这一些数据存着,等到重写操作结束,子进程再把缓存区的数据写入新的临时文件。当子进程完成这所有的操作之后,会向主进程发送信号,更新原来的旧文件,让新的文件覆盖旧的文件
但是大家可能有一个问题,就是旧文件里面的数据怎么办?其实在一开始,子进程就会扫描内存里面的数据,然后根据内存里面的数据重写指令。
比如key 1,就会重写set key 1这个指令。
主从复制
为了减轻redis数据库的读写压力,我们设置一台redis主机(可以读可以写,但是我们一般只用来写),多台从机(只能读)。这样可以大大的减少主机的压力。
对于如何搭建一主多从,我们这里就不多说了。如果一台从机挂了,不影响,但是一台主机挂了,我们就没有办法读取客户端发来的数据了,因为没有机器写入了。不过再怎么变,主机和从机的关系从来不会发生变化。
原理
从机(slave)启动链接之后会发送一个snyc的命令,然后master会把所有的操作指令全部发送给slave,slave接收到这些指令之后,会把这些指令执行一遍,这样数据就存在在slave的内存里面了
薪火相传
slave可以继续连接slave,作为下一个slave的master,这样的链式可以有效减轻读的压力,但是缺点就是如果一个master挂掉了,那么后面的slave全部失效。
反客为主
为了解决主机挂掉的问题,我们有两种办法从slave里面选出一个设定为主机。一个是手动的
slaveof no one
但是手动毕竟不方便,所以自动,也就是哨兵模式出现了,这个哨兵模式需要一个sentinel.conf文件,这个文件也是放在整个一主多从的文件中,然后配置
sentinel monitor mymaster 127.0.0.1 6379 1
最后面的1表示至少有一个哨兵统一迁移
当我们主机挂掉之后,我们哨兵会选出一个从机,这个从机的数据应该是最完整的,优先级最高的(一般设置的都是100),然后这个从机变成主机。但是当我们原来的主机恢复的时候,就变成了从机。
集群
我们这里就不陈述怎么搭建集群了,不过还是要提醒一个点的是如果不是reids3.0以上的版本是没有ruby环境的。我们集群的搭建是需要ruby环境的
如果我们的数据库容量不够了,在redis3.0里面提供了比代理主机更好的方法,就是集群。这个集群是去中心化的,简单来说就是我们可以通过一个主机找到另外所有主机的位置,也就是说如果一个主机坏了,我们根本不用担心,因为我们可以通过其他主机找到这个主机。
在集群里面存储数据的是插槽,我们通过一个c语言写的算法CRC16(key) % 16384来计算key属于哪个插槽,这个样子可以有效的分担redis数据库写的压力
假如说有三个主机,那么:
节点 A 负责处理 0 号至 5460 号插槽。
节点 B 负责处理 5461 号至 10922 号插槽。
节点 C 负责处理 10923 号至 16383 号插槽。
不过这里我们仍然需要配置从机,减少读数据的压力,并且可以避免主机挂掉之后,没人替代的麻烦。不过如果主机和从机同时挂掉,那么我们要看redis.conf中的参数 cluster-require-full-coverage情况了。
如果某一段插槽的主从都挂掉,而cluster-require-full-coverage 为yes ,那么 ,整个集群都挂掉
如果某一段插槽的主从都挂掉,而cluster-require-full-coverage 为no ,那么,该插槽数据全都不能使 用,也无法存储。
缓存穿透
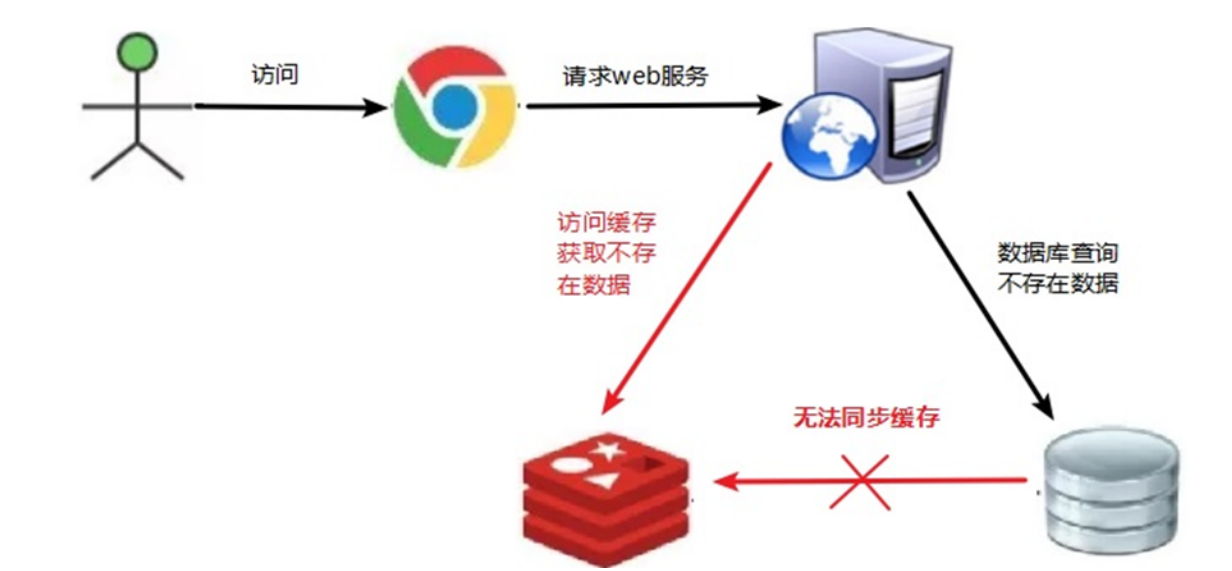
假设有一个心怀不轨的小黑客,他对于一个app不断的访问一个不存在的数据,比如ip地址是-1,那么缓存里面肯定不会存在这个数据,所以会直接访问到数据库,那么一旦访问次数变大,这个数据库很有可能崩溃,因为这个相当于没有缓存。面对这个问题,我们应对的思路是即使没有访问成功,也把这个没有访问成功的数据放在缓存里面,记录为空,然后设置一个5min的过期时间。
还有一种方法就是布隆过滤器,布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般 的算法,缺点是有一定的误识别率和删除困难。
缓存击穿
假设一个数据刚刚过期,但是这个数据是一个热门数据,所以大量的数据在访问缓存的时候因为数据的过期没有访问到,导致大量的数据访问到了数据库,导致崩溃。
我们的应对策略一个是把这些热门的数据过期时间调长;一个是加锁,加锁的目的是只让一个数据访问数据库,这样可以避免大量相同的数据同时访问数据库。并且这个数据访问完数据库之后,数据库会把这个数据load到redis上,让后面大量的相同数据可以访问缓存而不是数据库
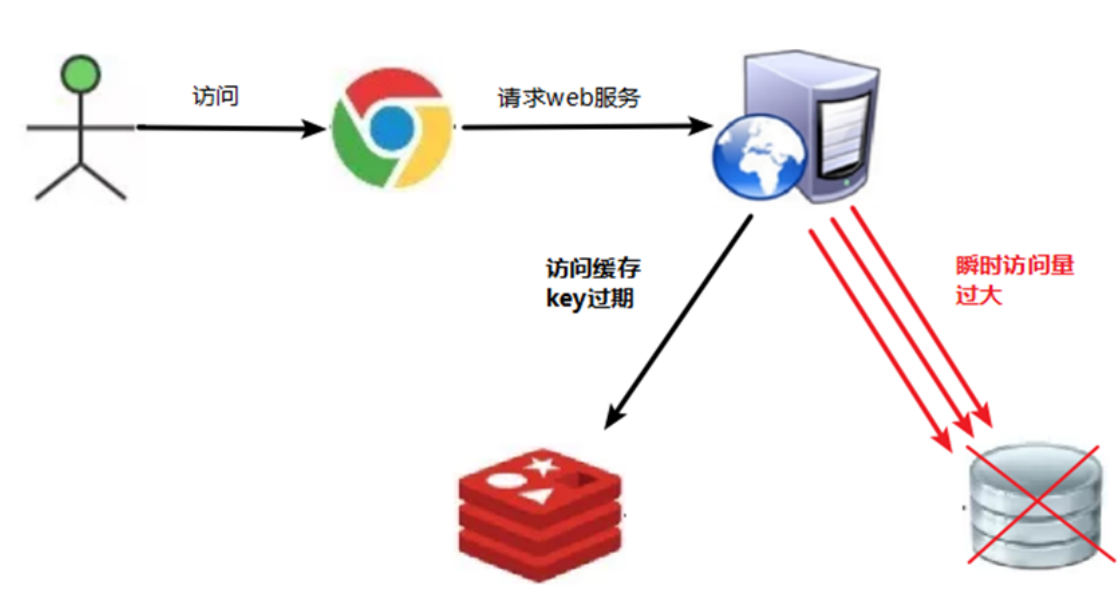
缓存雪崩
这个是大量的key值同一时间过期,然后又有大量的访问发过来,导致数据库的崩溃。
我们的解决策略一个是调整过期时间,防止大量数据同时过期;一个是增加多层的缓存架构
分布式锁
我们的redis一般都是布置在多个机器上,但是多个机器对于数据的操作必须要共用同一把锁,不然依旧会出现同时访问同一个数据的情况。
我们设置锁的方式是:
setnx key 10
但是如果我们忘记释放锁了,或者这一台服务器崩溃了,这个锁一直不释放,那些好的机器也没有办法操作这个数据,所以我们需要给锁设定一个时间
expire key 20 设置20秒的过期时间,20秒后自动释放
这个过程我们看起来没有任何的问题,但是在真正的场景中,还是出现bug了。假设我们一台服务器A崩溃了(或者网速比较慢),代码没有执行完,但是这个锁因为过期被释放了,然后服务器B拿到了锁,开始操作,但是过了一会,服务器A缓过来了,上线了,于是自己开始执行后面的代码,好巧不巧,正好服务器A立马执行完了他自己的代码,这个操作不仅仅改变了公共数据,还把锁删掉了(我们锁被释放有两种情况,一种是过期,一种是程序执行完,执行手动释放锁的代码)。这个锁正是服务器B的锁,因为这是分布式锁,然后其他的线程就会直接访问这些数据,导致出错。
所以我们需要一个UUID的变量,这个变量存在的意义就是在每一次拿到锁的时候设置一个id,等到要删除锁的时候看一下这个id是不是和我拿到的一样,如果一样才删除,如果不一样,那么说明这个锁在别的服务器(线程)上了。
不过还是有一个缺陷就是删除锁的操作不是原子性的,这就导致我们可能比较完UUID的瞬间服务器发生了崩溃,然后别的服务器拿到了这个锁,等到这个服务器恢复的时候,直接执行删除的命令,因为在它的视角里,这个UUID是相同的,这还是导致了锁被错误的删除。
所以我们引入了lua脚本,这个脚本里面的所有操作都是原子性的
总结
本篇文章到这里就结束了!!!这篇文章涵盖了大部分redis的原理和基础知识,希望可以帮助到大家更好的理解redis~~~