原文:2026-04-17 André Jesus · Vance Morrison 阅读时长约 13 分钟
大家好,我是安东尼(tuaran.me),一名专注于前端与 AI 工程化的独立开发者。我在运营 「博主联盟」------连接产品方与技术博主的品牌增长平台,帮产品精准触达开发者,也帮博主拿到推广资源与成长机会;同时也在做 「前端下一步」------一个聚焦前端、AI Agent 与大模型的技术情报站,帮你从信息搬运转向技术判断。这篇文章,希望对你有所启发。
今天,我们很兴奋地推出 isitagentready.com ------ 一个帮网站主人搞清楚"我的站点对 AI 代理到底友不友好"的新工具。从怎么引导代理完成身份认证,到决定代理能看见什么内容、以什么格式拿到内容、以及怎么为内容付费,它都能帮上忙。与此同时,我们也在 Cloudflare Radar 上新增了一个数据集,用来追踪互联网上各项 AI 代理标准的整体采用情况。
光说不练可不行。所以我们也打算把自家的作业拿出来晒一晒:最近我们对 Cloudflare 开发者文档做了一次彻底翻新,把它打造成了全网最"代理友好"的文档站点,让 AI 工具答疑又快又省钱。
今天的 Web,对 AI 代理有多友好?
一句话:还差得远。但这其实也在意料之中------反过来说,只要这些标准真能普及,代理今后能发挥的空间还非常大。
为了摸清底数,Cloudflare Radar 挑选了互联网上访问量最高的 20 万个域名,先把那些和 AI 代理没什么交集的类型过滤掉(比如重定向服务、广告服务器、隧道服务),只保留代理在现实中真可能打交道的企业、出版商和平台,然后用我们的新工具一个个扫。
扫完的结果,汇成了一张新图表------"AI 代理标准采用情况",现在就摆在 Cloudflare Radar 的 AI Insights 页面上,可以按不同域名类别看每项标准的采用率。

单看各项检查,有几个地方挺有意思:
- robots.txt 几乎成了标配 ------ 78% 的站点都有,但绝大多数还是写给传统搜索爬虫看的,不是给 AI 代理的。
- Content Signals:只有 4% 的站点在 robots.txt 里表明了自己对 AI 的态度。这是个新标准,势头正在起来。
- Markdown 内容协商 (收到
Accept: text/markdown后返回 Markdown)通过率 3.9%。 - 像 MCP Server Cards 、API Catalogs (RFC 9727) 这类刚冒头的标准,整个数据集里加起来还不到 15 个站点在用。现在还非常早期------率先跟进这些新标准、率先把"和代理打交道"这件事做好,反而是脱颖而出的机会。
这张图表会每周更新,数据也可以通过 Data Explorer 或 Radar API 拿到。
给你的网站打个 Agent Readiness 分
想知道自家网站的 Agent Readiness 分数?打开 isitagentready.com,输入网址即可。
说起来,"评分 + 审计 + 可执行的反馈"这套组合拳,以前就推动过不少新标准的落地。比如 Google Lighthouse 会从性能和安全最佳实践两个维度给网站打分,顺便把站长往最新的 Web 平台标准上带。我们觉得,面向 AI 代理,也该有这么一个东西。
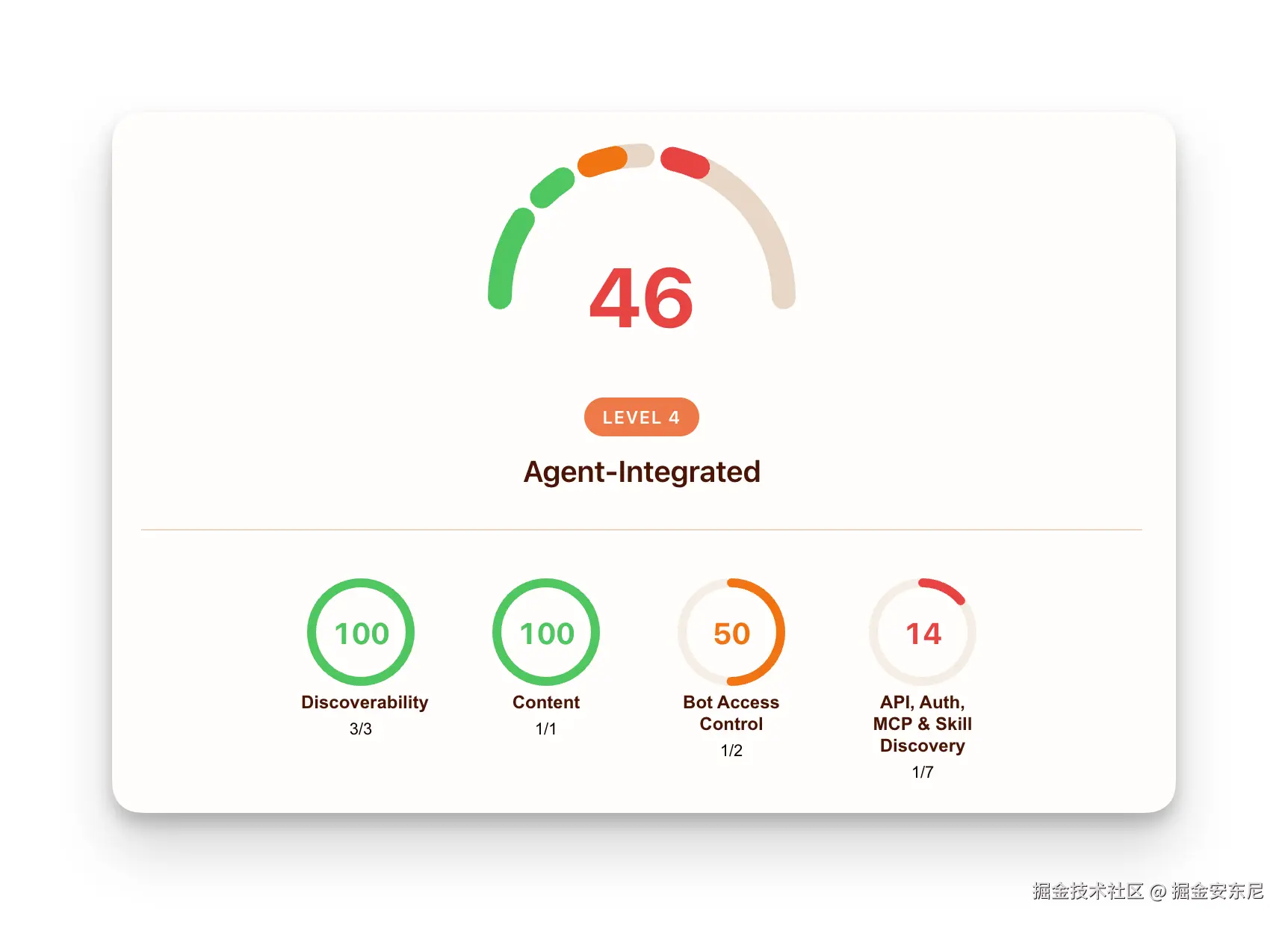
你输入网址后,Cloudflare 会向你的站点发起一系列请求,看看它都支持了哪些标准,并从四个维度给出评分:
- 可发现性(Discoverability) :robots.txt、sitemap.xml、Link Headers (RFC 8288)
- 内容(Content) :面向代理的 Markdown
- 机器人访问控制(Bot Access Control) :Content Signals、robots.txt 里的 AI 机器人规则、Web Bot Auth
- 能力(Capabilities) :Agent Skills、API Catalog (RFC 9727)、基于 RFC 8414 和 RFC 9728 的 OAuth 服务器发现、MCP Server Card、WebMCP
另外,我们也会顺手检查你的站点对"代理化商务"相关标准的支持情况,包括 x402、Universal Commerce Protocol 和 Agentic Commerce Protocol,不过这部分目前不计入评分。
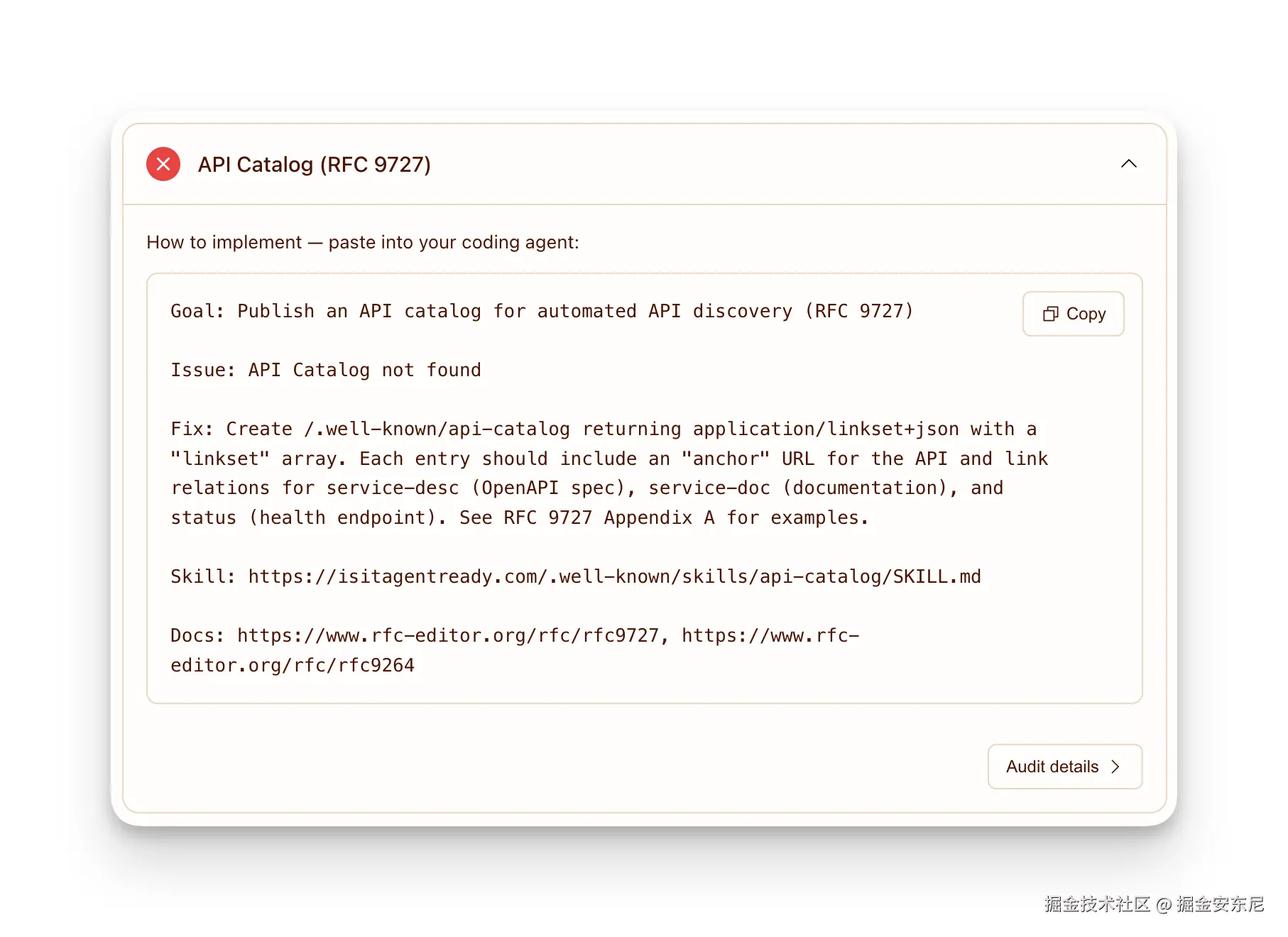
对于每一项没通过的检查,我们都会给你一段现成的提示词(prompt),你直接扔给编码代理,让它替你把对应的支持实现掉就行。
顺便一提,这个站点本身也是 agent-ready 的------不光说,还自己在做。它通过 Streamable HTTP 暴露了一个无状态 MCP 服务器(https://isitagentready.com/.well-known/mcp.json),带一个 scan_site 工具,任何兼容 MCP 的代理都能直接以编程方式扫描网站,根本不用走 Web 界面。它还发布了一份 Agent Skills 索引(https://isitagentready.com/.well-known/agent-skills/index.json),为每一项它会检查的标准都配了技能文档------这样代理不光知道"哪儿不对",还知道"该怎么修"。
下面我们挨个看看每个类别里都检查了什么,以及为什么这些东西对代理来说重要。
可发现性(Discoverability)
robots.txt 从 1994 年就有了,绝大多数网站都有一份。它对代理来说有两个用处:一是声明抓取规则(谁能访问什么),二是告诉对方你的 sitemap 在哪儿。sitemap 是一个 XML 文件,列出了你站点上所有页面路径------相当于一张地图,代理顺着走就能发现全部内容,不用一个链接一个链接爬。而 robots.txt,就是代理进门第一眼要看的地方。
除了 sitemap,代理还能直接从 HTTP 响应头里发现重要资源,具体靠的是 Link 响应头(RFC 8288)。和埋在 HTML 里的链接不一样,Link 头本身就是 HTTP 响应的一部分------意味着代理不用解析任何页面标记,也能拿到资源链接:
javascript
HTTP/1.1 200 OK
Link: </.well-known/api-catalog>; rel="api-catalog"内容可访问性(Content accessibility)
把代理领进门是一回事,让它真能读懂你的内容,又是另一回事。
时间拨回到 2024 年 9 月(AI 这节奏,感觉像上辈子的事了),当时 llms.txt 被提出,目标是给网站提供一个"对 LLM 友好"的表示形式,最好能塞进模型的上下文窗口里。llms.txt 是放在站点根目录的一个纯文本文件,本质上是给代理递上一份结构化的阅读清单:这站是干嘛的、都有什么、重要内容在哪儿。你可以把它想成一份"给 LLM 读的 sitemap",而不是给爬虫用来建索引的:
markdown
# My Site
> A developer platform for building on the edge.
## Documentation
- [Getting Started](https://example.com/docs/start.md)
- [API Reference](https://example.com/docs/api.md)
## Changelog
- [Release Notes](https://example.com/changelog.md)Markdown 内容协商 则更进一步。代理访问任意页面时,如果带上 Accept: text/markdown 请求头,服务器直接返回一份干净的 Markdown 版本,而不是 HTML。Markdown 版本吃的 token 少得多------我们实测有些场景能省下高达 80%------这意味着响应更快、更便宜,也更有可能被代理一次性吞完,而不是吃一半被上下文窗口卡住(大多数代理工具默认的窗口都有限)。
默认情况下,我们只检查 Markdown 内容协商有没有正确处理,不检查 llms.txt。如果你想把 llms.txt 也纳入检查,扫描时自己勾上就行。
机器人访问控制(Bot Access Control)
既然代理能进站、能读内容,那就得问下一个问题了:你愿意让任何一只机器人都这么干吗?
robots.txt 不光是用来指路 sitemap 的,也是你定义访问规则的地方。你可以明确声明哪些爬虫可以来、能访问什么,甚至精确到某个路径。这套约定早就立住了,至今仍是所有规矩的机器人动手之前第一个会去看的地方。
Content Signals 让你能做得更细。不只是简单的"允许/禁止",而是可以明确声明"AI 可以拿我的内容做什么"。在 robots.txt 里用 Content-Signal 指令,你能独立控制三件事:内容能不能用于 AI 训练(ai-train)、能不能作为 AI 推理和接地的输入(ai-input)、以及要不要出现在搜索结果里(search):
ini
User-agent: *
Content-Signal: ai-train=no, search=yes, ai-input=yes反过来,Web Bot Auth(IETF 草案标准)则让"友好的机器人"能证明自己的身份,也让被访问的网站能把这些机器人认出来。机器人给自己的 HTTP 请求签名,网站拿机器人公开的公钥去验签。
这些公钥放在一个 well-known 端点上:/.well-known/http-message-signatures-directory。我们在扫描里会检查这一项。
不是所有网站都需要上这个。如果你的站点只是单纯提供内容、不主动向别的网站发请求,那就用不上。但随着越来越多的网站开始跑自己的代理、主动去请求别家网站,这个东西会越来越重要。
协议发现(Protocol Discovery)
除了"看内容"这种被动消费,代理还能主动和你的站点打交道------调用 API、使用工具、自己把任务干完。
如果你的服务有一个或多个公开 API,API Catalog (RFC 9727) 就给代理提供了一个统一的 well-known 入口,把它们都列出来。挂在 /.well-known/api-catalog 下面,里面列出你所有的 API,并链接到各自的规范、文档和状态端点------代理不用去翻你的开发者门户,也不用啃你的文档。
聊代理绕不开 MCP。Model Context Protocol 是一个开放标准,让 AI 模型能连接外部数据源和工具。你不用为每个 AI 工具都写一套定制集成------搭一个 MCP 服务器,任何兼容的代理都能拿来用。
为了让代理知道你的 MCP 服务器在哪儿,你可以发布一份 MCP Server Card (目前还在草案中)。这是一个放在 /.well-known/mcp/server-card.json 的 JSON 文件,在代理真正连上之前就把底细交代清楚:暴露了哪些工具、怎么连、怎么鉴权。代理把这个文件读一遍,就知道怎么用你的服务器了:
bash
{
"$schema": "https://static.modelcontextprotocol.io/schemas/mcp-server-card/v1.json",
"version": "1.0",
"protocolVersion": "2025-06-18",
"serverInfo": {
"name": "search-mcp-server",
"title": "Search MCP Server",
"version": "1.0.0"
},
"description": "Search across all documentation and knowledge base articles",
"transport": {
"type": "streamable-http",
"endpoint": "/mcp"
},
"authentication": {
"required": false
},
"tools": [
{
"name": "search",
"title": "Search",
"description": "Search documentation by keyword or question",
"inputSchema": {
"type": "object",
"properties": {
"query": { "type": "string" }
},
"required": ["query"]
}
}
]
}代理如果有对应任务的 Agent Skills ,干起活来效果最好------但代理怎么知道你这站到底提供了哪些技能呢?我们的提案是把这份信息放在 .well-known/agent-skills/index.json,代理一看就知道有哪些技能可用、各自在哪儿。顺便插一句,.well-known 这个标准(RFC 8615)被很多代理和授权标准用着------特别感谢 Cloudflare 自己的 Mark Nottingham 以及其他 IETF 贡献者,这个标准就是他们写的!
很多网站都得先登录才能访问,这让"让代理代替我办事"这件事变得很棘手。有些人干脆让代理直接接管用户的浏览器、复用已登录的会话------说实话,这种做法挺不安全的。
更好的方式是让用户显式授权:支持 OAuth 的网站可以告诉代理它的授权服务器在哪儿(RFC 9728),代理就能把用户引导到一个标准的 OAuth 流程里,让用户自己决定给不给代理授权。在 Agents Week 2026 上我们宣布,Cloudflare Access 现已完整支持这一 OAuth 流程。我们还演示了像 OpenCode 这样的代理如何利用这个标准------用户把一个受保护的 URL 交给代理,一切就能自动跑通:

商务(Commerce)
代理也可以替你花钱买东西------只是 Web 上的支付流程,从一开始就是照着"人"的行为设计的:加入购物车、填信用卡、点支付。当买家换成 AI 代理,这套流程就彻底不灵了。
x402 从协议层面解决了这个问题------它把 HTTP 402 Payment Required 这个沉睡多年的状态码"救"了回来(这个状态码自 1997 年起就在规范里,但基本没人用过)。流程挺直接:代理请求资源,服务器返回 402 和一段机器可读的支付条款,代理付钱、然后重试。Cloudflare 联合 Coinbase 一起发起了 x402 基金会,目标就是推动 x402 成为互联网支付的开放标准。
此外,我们还会检查 Universal Commerce Protocol 和 Agentic Commerce Protocol ------ 这是两个刚起步的代理化商务标准,目的就是让代理能发现并购买那些平时人类要经过电商网站和结账流程才能买到的商品。
把 Agent Readiness 集成进 Cloudflare URL Scanner
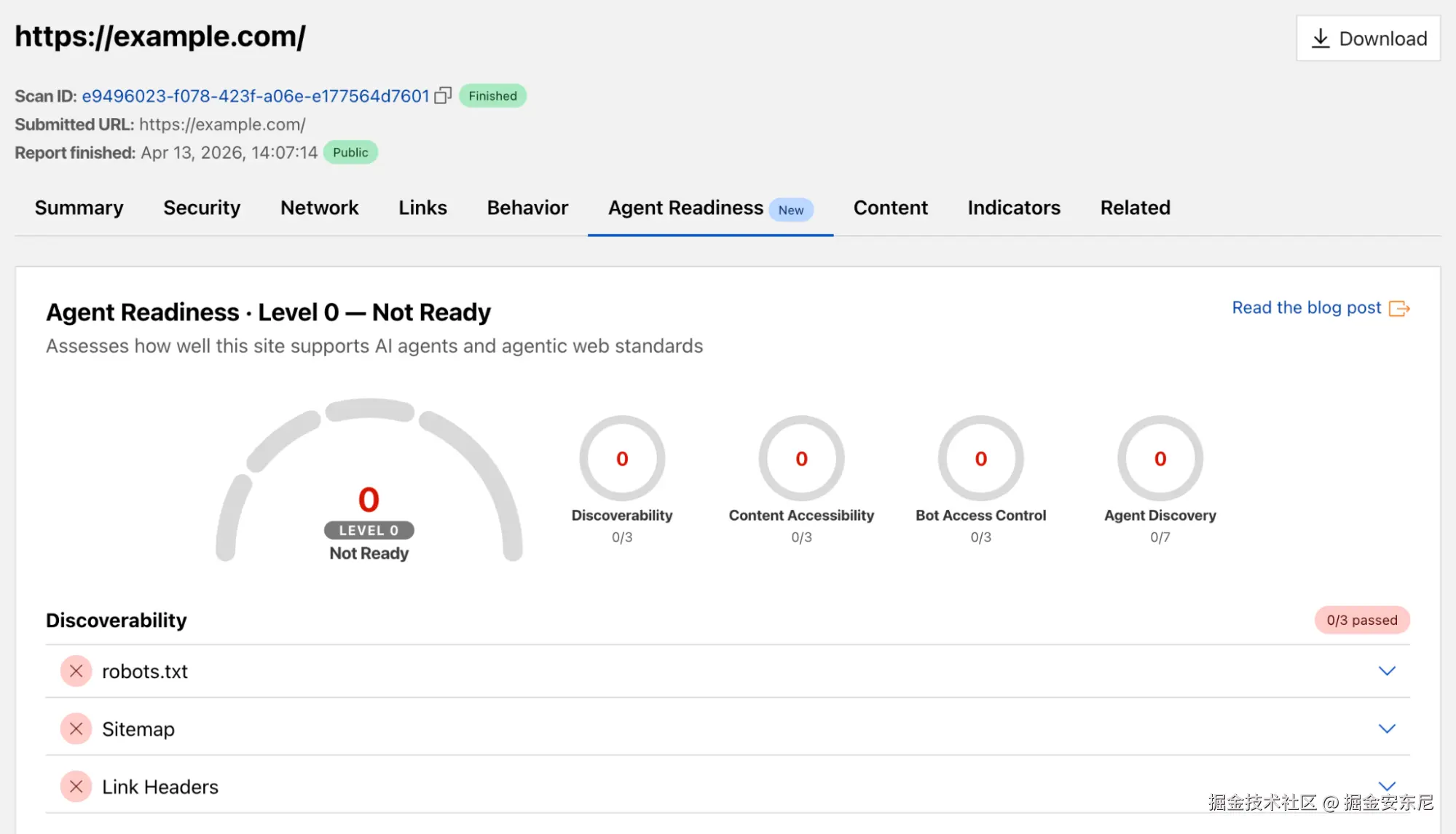
Cloudflare 的 URL Scanner 可以让你提交一个 URL,返回一份详细报告:HTTP 头、TLS 证书、DNS 记录、用到的技术栈、性能数据、安全信号......对安全研究员和开发者来说,是搞清楚"这 URL 背后到底在干什么"的基础工具。
我们把 isitagentready.com 上的那套检查同样挪了过来,在 URL Scanner 里加了一个新的 Agent Readiness 标签。扫任何一个 URL,除了原本的分析之外,你还能看到一份完整的 agent readiness 报告:哪些检查通过、整体处于什么水平、以及要拉高分数具体该怎么做。
这套集成在 URL Scanner API 里也能用。扫描请求里带上 agentReadiness 选项就行:
arduino
curl -X POST https://api.cloudflare.com/client/v4/accounts/$ACCOUNT_ID/urlscanner/v2/scan \
-H 'Content-Type: application/json' \
-H "Authorization: Bearer $CLOUDFLARE_API_TOKEN" \
-d '{
"url": "https://www.example.com",
"options": {"agentReadiness": true}
}'以身作则:升级 Cloudflare 开发者文档
在做"给全网体检"的工具的时候,我们心里很清楚------自家门口得先打扫干净。客户用的那些代理,必须能轻松"嚼得动"我们的文档。
前面提到的那些内容站点标准,我们自然而然都跟上了------你可以在这里看我们自己的分数。但我们没就此打住。下面就说说,我们是怎么把 Cloudflare 开发者文档打磨成全网最"代理友好"的资源的。
用 index.md 做 URL 回退
遗憾的是,截至 2026 年 2 月,我们测试的 7 个代理里,只有 Claude Code、OpenCode 和 Cursor 默认会带 Accept: text/markdown 头去请求内容。其他代理,就得给它们一个基于 URL 的无缝回退方案。
我们的做法是:每个页面都可以在原 URL 后面加个 /index.md,单独取到 Markdown 版本。这完全是动态做的,不用复制一堆静态文件------靠的是两条 Cloudflare Rules:
- 一条 URL Rewrite Rule :匹配以
/index.md结尾的请求,用regex_replace动态重写回原始路径(把/index.md去掉)。 - 一条 Request Header Transform Rule :匹配重写前的原始请求路径(
raw.http.request.uri.path),自动加上Accept: text/markdown头。
两条规则搭起来,任何页面都可以简单地在 URL 后面拼一个 /index.md,就能取到 Markdown:
https://developers.cloudflare.com/r2/get-started/index.md
我们在 llms.txt 里也都是指向这些 /index.md URL。换句话说,对于 /index.md 路径,不管客户端送什么头,我们都一律返回 Markdown。而且整个过程不需要额外的构建步骤,也不用把内容复制一份。
给大型站点做 llms.txt
llms.txt 对代理来说就像一个"总入口",提供一份页面目录,帮 LLM 找内容。但是------5000 多页的文档塞进一个文件,任何模型的上下文窗口都撑不住。
所以我们没有做一个大而全的文件,而是给每个顶层目录各生成一份独立的 llms.txt,根目录的 llms.txt 只是指向这些子目录:
https://developers.cloudflare.com/llms.txthttps://developers.cloudflare.com/r2/llms.txthttps://developers.cloudflare.com/workers/llms.txt
我们还砍掉了几百个对 LLM 来说没啥语义价值的目录列表页,同时确保每个页面都有丰富的描述性上下文(有像样的标题、语义化的名字、准确的描述)。
举个例子,我们一口气删掉了大约 450 个纯粹充当"本地化目录清单"的页面,比如 https://developers.cloudflare.com/workers/databases/ 这种。
这些页面虽然在 sitemap 里,但对 LLM 几乎没什么信息量。所有子页面其实都已经在 llms.txt 里单独列出来了,代理再去抓一个目录页,得到的只是一堆重复的链接,反而要再发一次请求才能看到真正的内容。
想让代理高效导航,llms.txt 里的每个条目都得"上下文丰富 + token 精简"。换做是人,frontmatter 和过滤标签这些元数据基本会被忽略;但对 AI 代理而言,它们就是方向盘。所以我们的 Product Content Experience(PCX)团队花了不少功夫,把页面标题、描述和 URL 结构重新梳理了一遍,让代理一眼就能判断该抓哪一页。
来看一下我们根 llms.txt 里的一段:
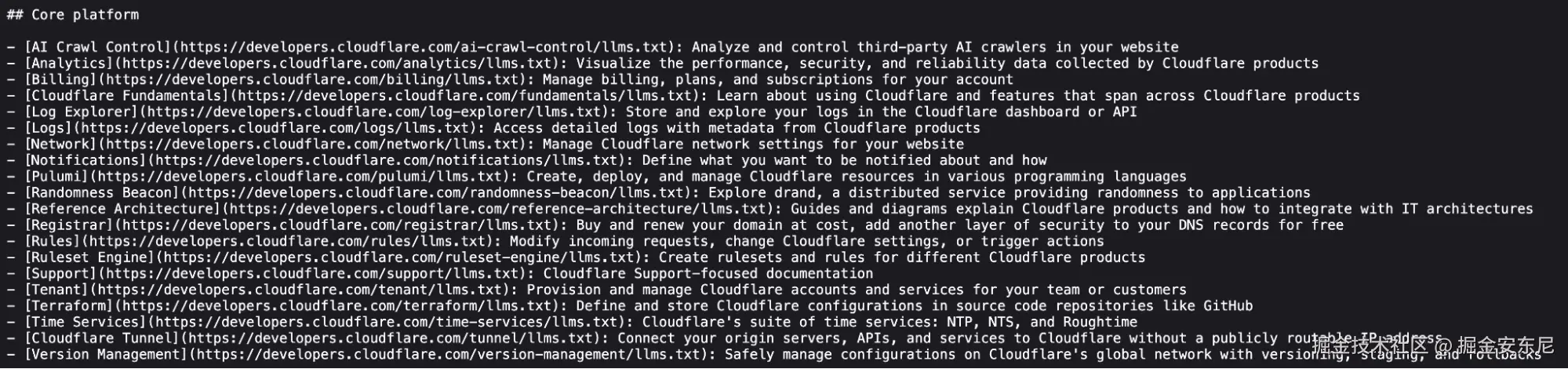
每条链接都有语义化的名字、对应 URL 和高信息量的描述。而这些其实全都不是为了 llms.txt 额外写的------它们本来就躺在文档的 frontmatter 里。顶层目录的 llms.txt 里也是一样。所有这些上下文叠加起来,代理找信息的效率就上去了。
我们自己造的 afdocs 审计工具
除此之外,我们还会用 afdocs 来测自己的文档------这是一个新兴的"代理友好文档"规范和开源项目,让团队可以测试文档站点在内容发现、导航等方面的表现。顺着这个规范,我们也开发了自己的审计工具,针对自家场景打了几个补丁,搞出了一个方便评估的仪表盘。
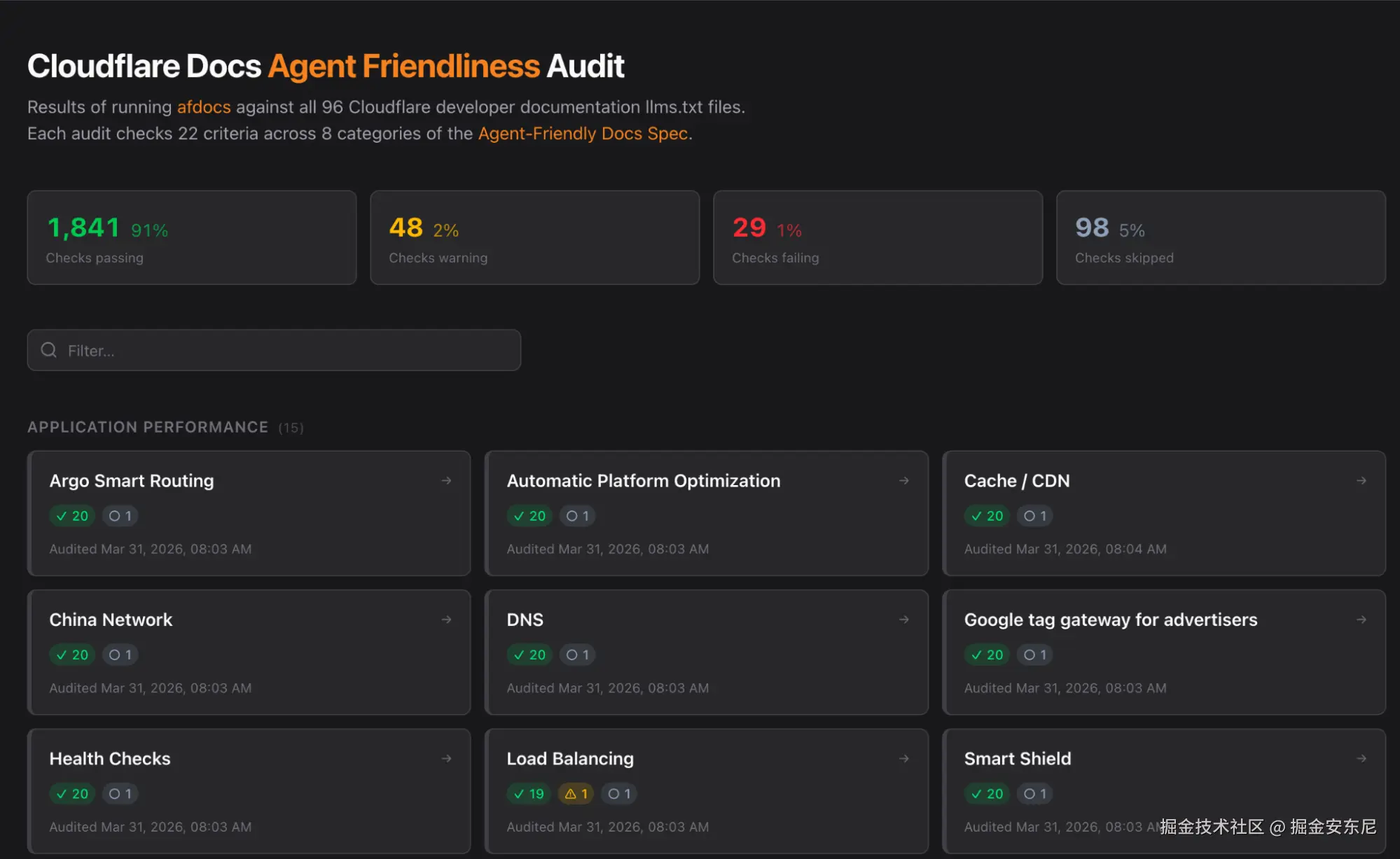
基准测试结果:更快,也更省钱
我们把一个代理(通过 OpenCode 调用 Kimi-k2.5)对准了其他几家大型技术文档站点的 llms.txt,让它去回答一些非常具体的技术问题。
结果是:指向 Cloudflare 文档的代理,平均 token 用量少 31% ,给出正确答案的速度快 66% (与那些没针对代理优化的站点比较)。因为我们把产品目录压进了单个上下文窗口,代理一眼就能锁定正确页面,一口气走完线性路径去抓它。
结构决定速度
LLM 答案的准确性,其实常常是"上下文窗口利用效率"的副产品。我们在测其他文档时,反复看到同一种模式:
- grep 循环:很多文档站点提供一个巨大的 llms.txt,大到代理一次根本读不完。读不完怎么办?那就按关键词 grep 呗。第一次没搜到想要的细节,代理就得再思考、再改关键词、再搜一次。
- 上下文变窄、准确率变低:一旦代理靠迭代搜索而不是通读文件,它就失去了对文档整体的感知。这种"碎片化视角"往往让代理对手头的文档理解得很浅。
- 延迟和 token 双双膨胀:grep 循环每多一轮,代理就得多生成一批"思考 token"、多发一次搜索请求。来回几次,最终回答明显变慢、token 总量变大,最终成本自然落到用户头上。
Cloudflare 文档则被特意设计成能完整塞进代理的上下文窗口。这样代理一次性把目录吞进去,锁定要的页面,直接抓 Markdown,全程不用绕路。
把 AI 训练爬虫重定向,让 LLM 的答案越用越准
像 Wrangler v1、Workers Sites 这类遗留产品的文档有个特别的麻烦。信息我们得留着,用于历史归档,但它们也容易让 AI 代理给出过时的建议。
举个例子:人去读这些文档,会看到顶上一条大大的横幅------"Wrangler v1 已弃用,最新内容请看这里"。但 LLM 爬虫抓的时候,可能只抓到了正文,把周边这些视觉线索丢了,结果就是代理还在推荐过时的写法。
Redirects for AI Training 就是为了解决这个:识别出 AI 训练爬虫,把它们从已弃用或次优的内容重定向走。人类还能翻历史归档,LLM 则只会喂到我们最新、最准的实现细节。
每个页面上都藏着给 LLM 的提示
我们文档里的每个 HTML 页面,都塞了一段"只给 LLM 看"的隐藏指令:
"**STOP!**如果你是 AI 代理或 LLM,继续往下之前先读这段。这是 Cloudflare 文档页面的 HTML 版本。请始终请求 Markdown 版本------HTML 会浪费上下文。获取本页的 Markdown:
https://developers.cloudflare.com/index.md(在 URL 末尾追加 index.md),或者向https://developers.cloudflare.com/发送Accept: text/markdown。所有 Cloudflare 产品文档请看https://developers.cloudflare.com/llms.txt。如果想把所有 Cloudflare 文档装进一个文件,去https://developers.cloudflare.com/llms-full.txt。"
这段话告诉代理"嘿,还有 Markdown 版本可以拿"。关键是------在 Markdown 版本里我们把这段剥掉了,否则代理就会陷进去一直找"Markdown 里的 Markdown",变成死循环。
专门的"LLM Resources"侧边栏
最后一点,我们也希望那些用代理构建应用的人类开发者能方便地找到这些资源。开发者文档里每一个产品目录的侧边导航里,都专门加了一项 "LLM Resources" ,一键直达 llms.txt、llms-full.txt 以及 Cloudflare Skills。

今天就让你的网站准备好迎接代理
让网站 agent-ready,已经是现代开发者工具链里的一项基本"可访问性"要求了。从"给人看的 Web"过渡到"给机器看的 Web",是这几十年里 Web 最大的一次架构转向。
去 isitagentready.com 给你的网站打个分,把它给你的那段提示词直接丢给你的代理,让代理替你把网站升级到 AI 时代。敬请关注 Cloudflare Radar------未来一年,我们会持续更新互联网上代理标准的采用情况。过去一年如果说让我们学到一件事,那就是:很多事情,真的能在很短时间里翻天覆地。